
© Evgeny Atamanenko, 123RF
Wer Maria DB hochverfügbar betreiben möchte, hat mehrere Möglichkeiten. Eine davon ist die Kombination aus DRBD und Pacemaker, die zwar schon ein paar Jahre auf dem Buckel hat, aber noch immer ausgezeichnet funktioniert.
Wer ausnahmslos hippe Cloud- und Container-Setups hochzieht, muss sich fast wie im Paradies vorkommen: In jener Welt sind Applikationen “cloud-ready” und damit implizit hochverfügbar. Sie überleben den Ausfall einzelner Komponenten ohne Probleme, ohne dass der Admin irgendwas tun muss – außer die Applikation richtig auszurollen.
Solche Applikationen gibt es tatsächlich – aber es gibt eben auch die andere Art von Anwendung, also jene, die dem Cloud-Apologeten kalte Schauer über den Rücken laufen lässt: Klassische Datenbanken oder Server-Anwendungen, die implizit überhaupt keine Hochverfügbarkeit anbieten können.
Paradebeispiel Maria DB
Ein perfektes Beispiel dafür ist Maria DB. Die Ursprünge der Datenbank bei MySQL datieren in einer Zeit, in der von Clouds noch keine Rede war. Die Architektur von Maria DB fußt auf simplen Prinzipien: Lokal läuft ein Dienst, der im Hintergrund die vorhandenen Datenbanken verwaltet und zur Außenwelt einen Unix-Socket oder einen TCP-Port öffnet, mit dem sich Clients dann verbinden. Keine Rede beim normalen Maria DB hingegen von Hochverfügbarkeit: Fällt der Server aus, auf dem Maria DB läuft, ist die Datenbank einfach weg.
Klar: Auch für Maria DB gibt es mittlerweile mehrere HA-Aufsätze, die sowohl funktionierende Multi-Master-Cluster versprechen als auch das Problem der Hochverfügbarkeit in den Griff bekommen wollen. Galera ist die am weitesten verbreitete Option. Doch ein Galera-Setup ist komplex und es gibt manchen Fallstrick, in dem sich der Admin schneller verheddern kann, als ihm lieb ist. Hinzu kommt, dass Galera mindestens drei Datenbankknoten braucht. Wer also lediglich eine simple, aber hochverfügbare Maria DB benötigt, bindet sich mit Galera einigen Overhead ans Bein.
Altbekannte Alternative
Es ist nicht so, als sei Hochverfügbarkeit für Maria DB nur mit Galera & Co. zu erreichen. Im Gegenteil: Lange vor dem Aufkommen von Clouds und den Clusterlösungen gab es mit dem Duo aus DRBD und Pacemaker bereits eine Option, Maria DB hochverfügbar zu machen. DRBD kümmert sich als Quasi-Raid-1 für Netzwerke um die Replikation der Daten von Datenbanken. Pacemaker stellt sicher, dass die Datenbank tatsächlich läuft, und sorgt beim Ausfall eines Knotens dafür, dass der Dienst auf dem zweiten Clusterknoten mitsamt einer IP-Adresse erneut gestartet wird. Dieser Artikel erklärt, wie Admins auf Basis von Centos 7 und Red Hats PCS eine HA-Maria-DB bauen und betreiben können.
Voraussetzungen schaffen
Für ein Zwei-Knoten-Setup mit DRBD sind zunächst natürlich zwei Server nötig. Wird die Datenbank nicht für Hochleistungsaufgaben benötigt, müssen diese nicht zwangsläufig die neueste Hardware haben. Empfehlenswert sind jedoch SSDs für die Datenbanken sowie eine zusätzliche Netzwerkkarte pro Server, um für die Replikation von DRBD eine direkte Netzwerkverbindung zu schaffen.
Es ist außerdem sinnvoll, auf ordentliche HA-Verkabelung zu achten: Jeder Server sollte an zwei unterschiedlichen Stromkreisen hängen und mit zwei Switches verbunden sein. Freilich spielt hier auch das Thema Geld eine Rolle – je mehr Komponenten eines Setups hochverfügbar sind, desto teurer wird es durch den doppelten Kauf von Hardware.
Wenn die benötigten Server im Rack hängen und ordentlich verkabelt sind, geht es in Schritt 1 um die Grundinstallation. Ratsam ist es, die neueste Version von Centos zu nutzen, bei Redaktionsschluss war das Centos 7.4. Denn Centos enthält beinahe alle nötigen Pakete für ein solches Setup bereits ab Werk. Die Pakete, die noch fehlen, sind entweder Bestandteil des Extras-Repository oder in den EPEL (Extra Packages for Enterprise Linux) zu finden.
Wichtig: Gleich zu Beginn sollten Admins auch die BMC-Karten des Servers konfigurieren, sodass der Zugriff per IPMI over LAN oder RCMP+ möglich wird. Andere BMC-Protokolle wie I-DRAC von Dell oder ILO von IBM unterstützt Pacemaker ebenfalls. Die benötigten IP-Adressen sowie den Login und das Passwort für die BMC-Schnittstellen beider Server jedenfalls sollte der Admin parat haben.
Centos richtig installieren
Bei der Installation des Betriebssystems beachtet der Admin am besten gleich ein paar Faktoren. Diese beziehen sich vorrangig auf die Partitionierung der verfügbaren Speichergeräte: Ein LVM-basiertes Setup ist gerade im Kontext mit DRBD praktisch. Denn eine einzelne DRBD-Ressource erwartet ein separates Blockgerät im Hintergrund, ihr so genanntes Backing Device. Weil LVs, also Logical Volumes, genau solche Blockgeräte sind, lassen sie sich hervorragend als Backing Device für DRBD verwenden.
Sinnvoll ist es, »/boot« auf eine eigene Partition am Anfang der Festplatte zu legen und den restlichen Platz in ein PV für LVM zu packen, darin eine Volume Group (VG) namens »system« und eine namens »var« anzulegen und das Wurzelverzeichnis »/« sowie das Verzeichnis »/var« auf diesen unterzubringen. Jeweils 20 GByte sollten für diese Ordner auf normalen Servern ausreichen. Der ganze restliche Platz steht danach in der Volume Group »system« zur freien Verfügung.
Hat der Admin später Bedarf für eine zweite DRBD-Ressource, legt er für diese in jener Volume Group auf beiden Hosts einfach ein zusätzliches Logical Volume an. Angst vor Platznot ist übrigens unbegründet: Logical Volumes lassen sich zu jeder Zeit vergrößern. Und sowohl Ex 4 als auch XFS, das auf dem DRBD Device zum Einsatz kommen sollte, ermöglichen Online Resizing.
DRBD einrichten
Wenn das Betriebssystem installiert und grundlegend konfiguriert ist, geht es mit der Einrichtung von DRBD weiter. Zwar ist DRBD 8 schon seit Jahren Teil des Linux-Kernels, wie üblich ist der Centos-7-Kernel jedoch so alt, dass die darin integrierte DRBD-Version prähistorischen Charakter hat. Glück im Unglück: Die Paketmaintainer des EPEL-Verzeichnisses springen in die Bresche und bieten eine jüngere Version, nämlich DRBD 8.4, als Paket an.
Damit es den Weg auf die eigenen Systeme findet, aktiviert der Admin also zunächst EPEL – die folgenden Befehle sind auf beiden Systemen mit den Rechten von Root auszuführen, wie alle Befehle in diesem Artikel, falls nicht ausdrücklich an der jeweiligen Stelle anders beschrieben. EPEL bekommt der Admin so:
rpm --import https://www.elrepo.org/Y-elrepo.org rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
Danach steht die Installation von DRBD auf dem Plan. Hierzu installiert der Admin per »yum« die Pakete »drbd84-utils« sowie »kmod-drbd84«. Die Ausgabe von »lsmod | grep drbd« sollte anschließend ergeben, dass DRBD nun im Kernel geladen ist (Abbildung 1).
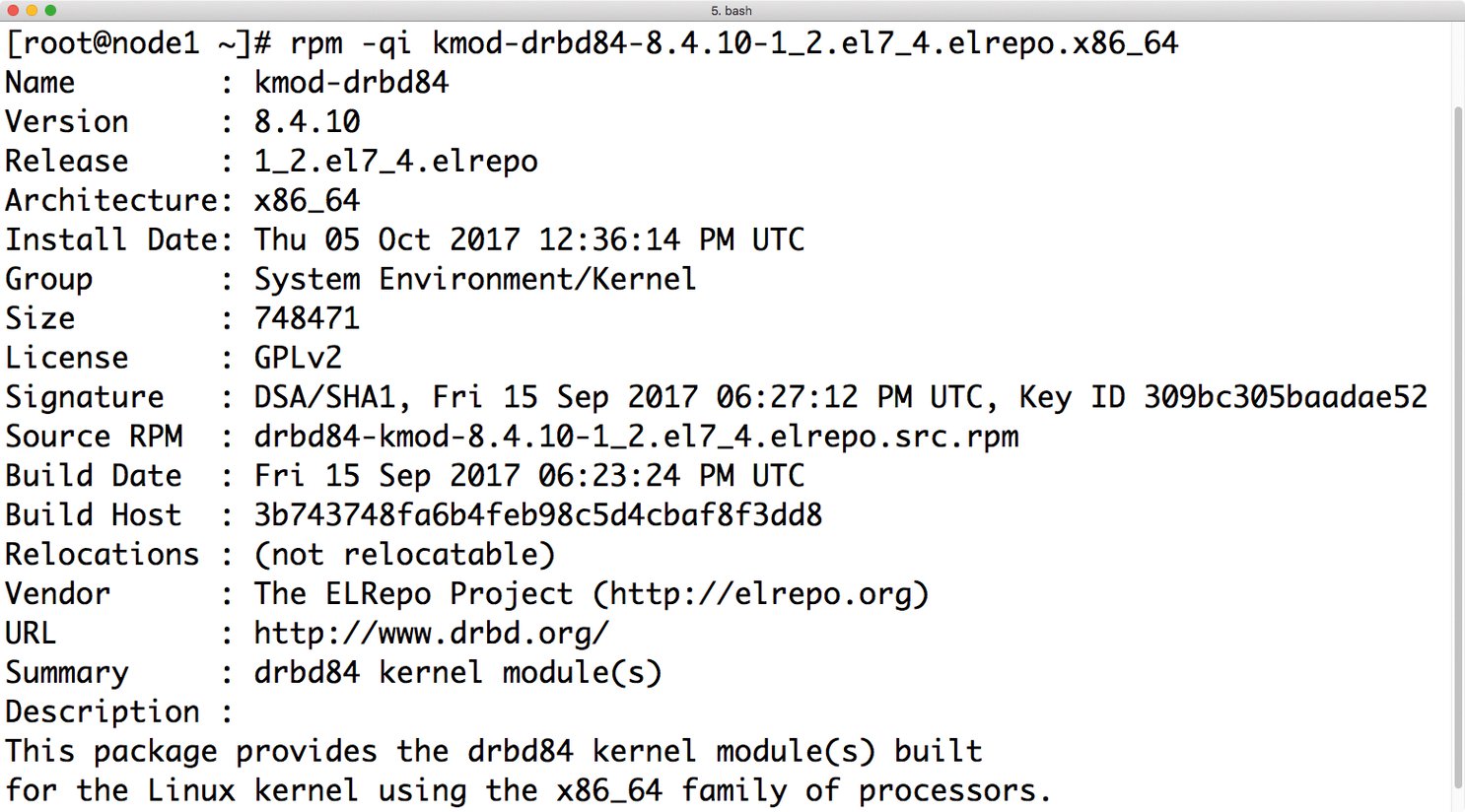
Abbildung 1: EPEL liegt ein DRBD-8.4-Modul in einer aktuellen Version bei, mit dem sich gut arbeiten lässt.
Eine DRBD-Ressource konfigurieren
Verglichen mit den Klimmzügen, die beim Setup eines verteilten Speichers wie Ceph nötig sind, gestaltet sich die Konfiguration von DRBD 8.4 nicht sehr komplex. Die Datei »/etc/drbd.conf« enthält lediglich Verweise auf Dateien in »/etc/drbd.d«, namentlich »global_common.conf« sowie alle Dateien, deren Dateiname mit ».res« endet. In »global_common.conf« empfiehlt es sich, den Wert bei »usage-count« von »yes« auf »no« zu setzen – andernfalls nimmt DRBD auf dem Host an einer Umfrage des DRBD-Anbieters Linbit teil, die die DRBD-Verbreitung erheben soll.
Danach geht es ans Eingemachte: Die Datei »/etc/drbd.d/Maria DB.res« legt die Konfigurationsparameter der Maria-DB-Ressource fest, die idealerweise ebenso »Maria DB« heißen sollte. Ein funktionierendes Beispiel findet sich in Listing 1. Die darin genutzten Werte bei »disk«, »address« sowie die Namen der beteiligten Hosts passt der Admin an seine lokalen Begebenheiten an. Wichtig ist weiter, dass der Eintrag der »on«-Zeilen mit der Ausgabe des Kommandos »hostname« übereinstimmt.
Listing 1
Maria DB.res
01 ...
02 resource MariaDB
03 {
04 startup {
05 wfc-timeout 30;
06 outdated-wfc-timeout 20;
07 degr-wfc-timeout 30;
08 }
09 net {
10 cram-hmac-alg sha1;
11 shared-secret sync_disk;
12 }
13 syncer {
14 al-extents 257;
15 on-no-data-accessible io-error;
16 }
17 on server1.local {
18 device /dev/drbd0;
19 disk /dev/system/MariaDB;
20 address 192.168.0.1:7788;
21 meta-disk internal;
22 }
23 on server2.local {
24 device /dev/drbd0;
25 disk /dev/system/MariaDB;
26 address 192.168.0.2:7788;
27 meta-disk internal;
28 }
29 }
30 ...
Unbedingt enthalten sein sollte auch »on-no-data-accessible io-error«, denn diese sorgt dafür, dass DRBD Fehler des darunterliegenden Blockgeräts an das Dateisystem weitergibt, statt diese zu verschlucken – so kommt es nicht zu schleichendem Datenfraß durch dahinsiechende HDDs oder SSDs. Gegebenenfalls anpassen sollte der Admin den Wert von »shared-secret«. Außerdem geht das Beispiel davon aus, dass das Backing Device das Logical Volume »Maria DB« der Volume Group »system« ist – kommen hier andere Namen zum Einsatz, sind auch die Werte bei »disk« anzupassen.
Die Firewall aufbohren
In der beispielhaften »Maria DB.res« steht in den »address«-Zeilen hinter dem Doppelpunkt eine Port-Angabe. Diese Ports benutzt DRBD, um auf beiden Clusterknoten seinen Netzwerksocket zu öffnen. Blöd nur, dass Centos 7 ab Werk mit Firewalld daherkommt und eingehende Ports zugenagelt sind. Um DRBD die Synchronisation zwischen zwei Clusterknoten zu ermöglichen, ist es notwendig, die Firewall aufzubohren.
Beide Knoten nutzen im Beispiel den Port 7788, für sie gilt der folgende Befehl:
firewall-cmd --permanent --zone=public --add-port=7788/tcp
Danach steht noch ein Neustart von Firewalld an:
systemctl restart firewalld.service
Anschließend können beide Server über Port 7788 miteinander kommunizieren, und der erfolgreichen DRBD-Synchronisation steht nichts mehr im Wege.
DRBD synchronisieren
Die Systemkonfiguration ist damit für DRBD vorbereitet, weiter geht es mit dem initialen Starten der Ressource. Weil DRBD Metadaten verwendet, legt der Admin diese zunächst auf beiden Knoten an: »drbdadm create-md Maria DB«. Dann aktiviert er die Ressource auf beiden Seiten des Clusters: »drbdadm up Maria DB«.
Der Befehl »cat /proc/drbd« sollte nun eine DRBD-Ressource zeigen, die auf beiden Seiten des Clusters im Zustand »Connected« ist, auf beiden die Rolle »Secondary« hat und als Diskstate »Inconsistent«. Weil bisher die Ressource auf keinem der beiden Knoten im »Primary«-Status war, weiß DRBD nicht, welche Seite aktuelle Daten enthält. Da aktuell ja noch gar keine Daten auf der DRBD-Ressource liegen, schließt der Admin die Einrichtung der DRBD-Ressource ab, indem er auf einem der beiden Knoten den Befehl
drbdadm primary --force Maria DB
ausführt. Ein erneuter Blick auf »/proc/drbd« (Abbildung 2) verrät, dass einer der Knoten im »Primary«-Status ist und den Inhalt seiner Platte – also lauter Nullen – gerade auf den anderen Clusterknoten kopiert. Die Ausgabe von »drbd-overview« liefert ähnliche Informationen, obgleich Linbit explizit darauf hinweist, dass »drbd-overview« veraltet ist – für den Augenblick funktioniert es aber noch (Abbildung 3).
Abbildung 2: »/proc/drbd« liefert einen Überblick über die aktiven DRBD-Ressourcen, ist aber nicht sehr übersichtlich.
Abbildung 3: »drbd-overview« zeigt »/proc/drbd« schöner an, gehört laut Hersteller aber zum alten Eisen.
Die Konfiguration der DRBD-Ressource ist damit abgeschlossen. Doch ist sie noch nicht sinnvoll nutzbar, weil sie kein Dateisystem enthält. Das ändert der Admin im nächsten Schritt, indem er mit »mkfs.xfs /dev/drbd0« ein XFS-Dateisystem anlegt. Den Befehl führt er auf demselben Knoten aus, auf dem er zuvor DRBD in die Primary-Rolle geschaltet hat.
Pacemaker aufsetzen
Der schönste replizierte Speicher ist nichts wert, wenn er nicht von einer Applikation genutzt und von einem Clustermanager verwaltet wird. Im nächsten Schritt geht es deshalb darum, Pacemaker auf der Basis von Corosync auf beiden Clusterknoten flottzubekommen. Das ist in den vergangenen Jahren erheblich leichter geworden, weil Red Hat einige Arbeit in den Clusterstack gesteckt hat. Zunächst installiert man Pacemaker per:
yum install pacemaker pcs resource-agents
Anschließend setzt der Admin das Passwort des Nutzers »hacluster« durch »echo Passwort | passwd –stdin hacluster«. PCS, Red Hats Werkzeug für die Konfiguration von Pacemaker, muss das Passwort ebenfalls kennen, hier genügt es aber, den Befehl nur auf einem Host aufzurufen:
pcs cluster auth knoten1 knoten2 -u hacluster -p PASSWORD --force
Wie zuvor bei DRBD sollten die Hosts hier über ihren vollständigen Hostnamen in PCS referenziert sein.
Schließlich nutzt der Admin PCS auf einem Knoten, um Corosync als Grundlage für Pacemaker zu konfigurieren:
pcs cluster setup --force --name pacemaker1 knoten1 knoten2
Auch hier wieder mit Hostnamen und Domain. Danach lässt sich Pacemaker auf beiden Clusterknoten starten: »pcs cluster start –all«, dabei genügt es, den Befehl auf einem Knoten zu verwenden. Die Ausgabe von »pcs cluster status« sollte im Anschluss einen Pacemaker-Cluster zeigen, bei dem beide Knoten im Status »Online« sind (Abbildung 4).
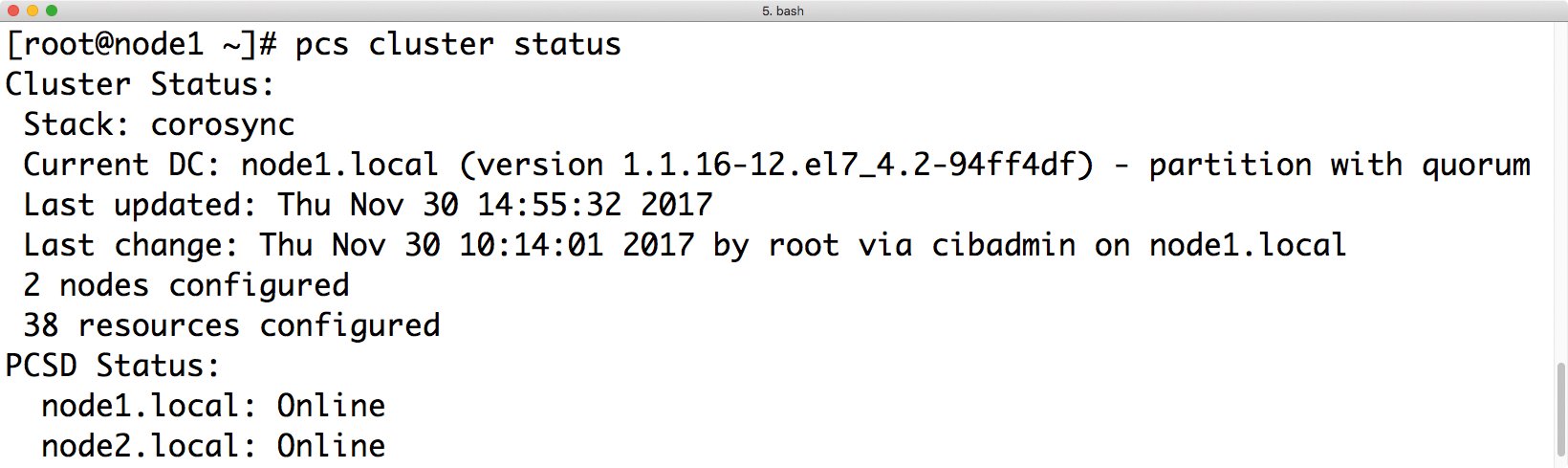
Abbildung 4: Mittels »pcs cluster status« lässt sich der aktuelle Status des Clusters überprüfen.
Schrittmacher-Tuning
Ab Werk hat Pacemaker ein paar Eigenschaften, die im laufenden Betrieb eher stören. Fällt etwa ein Clusterknoten aus, schwenkt Pacemaker alle Ressourcen auf den verbliebenen Cluster-Partner. Erscheint der andere Knoten wieder online, würde Pacemaker in der Standardkonfiguration alle Ressourcen zurück umziehen. Das Auto-Fail-Back genannte Verfahren sorgt für unnötige Downtime und sollte deshalb von Anfang an deaktiviert werden. Der Befehl
pcs resource defaults migration-threshold=1
erledigt das. Ebenso lästig ist die Tatsache, dass Pacemaker in der Werkseinstellung den Dienst verweigert, wenn der Cluster kein Quorum mehr hat. Quorat ist die Partition eines Clusters bekanntlich, wenn sie die Mehrheit der Knoten des Clusters vereint.
Bei einem Zwei-Knoten-Cluster ist das nicht möglich: Fällt einer der beiden Knoten aus, hält der andere aufgrund mathematischer Notwendigkeit nur noch genau 50 Prozent des Clusters, aber nicht mehr. Pacemaker würde den anderen Clusterknoten dann nicht aktivieren. Das lässt sich mit »pcs property set no-quorum-policy=ignore« verhindern.
Weiter geht es mit dem Cluster-Setup: Da auf beiden Knoten Pacemaker als Clustermanager aktiv ist, stehen die benötigten Dienste auf dem Plan. Dabei geht es um mehrere Komponenten:
- Die DRBD-Ressource, für die es in Pacemaker einen eigenen Typ gibt, nämlich die »Master-Slave-Ressource«.
- Eine Dateisystem-Ressource, die das auf DRBD liegende Dateisystem so in das Dateisystem des Hosts einhängt, dass es nutzbar wird – im Beispiel von Maria DB also nach »/var/lib/mysql«.
- Die Maria-DB-Ressource selbst, die Maria DB startet.
- Eine Ressource für eine IP-Adresse, die zusammen mit der Maria-DB-Datenbank von einem Host auf den anderen schwenken kann. Das ist notwendig, wenn man seine Clients nach einem Fail-over nicht umkonfigurieren will, dann ist eine Cluster-IP oder Service-IP nötig. Im Beispiel kommt 192.168.0.3 dafür zum Einsatz.
DRBD und Maria DB in Pacemaker integrieren
Die folgenden Befehle sind lediglich auf einem Clusterknoten auszuführen. Die per PCS gemachten Änderungen übernimmt Pacemaker automatisch in die Cluster Information Base (CIB), eine XML-Datei, welche die zu einem Cluster gehörenden Pacemaker-Instanzen automatisch untereinander synchron halten. Los geht es mit der Cluster-IP:
pcs resource create p_cluster-ip ocf:heartbeat:IPaddr2 ip=192.168.0.3 cidr_netmask=24 op monitor interval=30s
Der Befehl »crm_mon -1 -rf« sollte die neue Ressource nun als aktiv anzeigen. Der Befehl »ip a« auf beiden Clusterknoten sollte sie auf einem der beiden Knoten als tatsächlich vorhanden belegen.
DRBD in den Cluster integrieren
Im Anschluss integriert der Admin DRBD in den Cluster. Der Resource Agent, der sich in Pacemaker um DRBD kümmert, kommt direkt von Hersteller Linbit und unterstützt die so genannte Master-Slave-Funktion. Dabei weiß Pacemaker, dass eine Ressource auf mehreren Knoten gleichzeitig aktiv sein kann, aber in unterschiedlichen Arten – bei DRBD im Zustand Primary oder Secondary. Um DRBD in den Cluster zu integrieren, genügen die Befehle aus Listing 2.
Listing 2
DRBD-Integration
01 pcs cluster cib drbd_cfg 02 pcs -f drbd_cfg resource create drbd_MariaDB ocf:Linbit:drbd \ 03 drbd_resource=MariaDB op monitor interval=60s 04 pcs -f drbd_cfg master ms_drbd_MariaDB drbd_MariaDB \ 05 master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 \ 06 notify=true 07 pcs cluster cib-push drbd_cfg
Ein erneuter Blick auf »crm_mon -1 -rf« zeigt anschließend noch, dass es im Cluster nun sowohl die DRBD-Ressource als auch das zugehörige Master-Slave-Set gibt. Auf einem Knoten ist die Ressource im Mode »master«, auf dem anderen im Modus »slave«.
Maria DB installieren
Danach steht die Installation von Maria DB an: Auf beiden Systemen genügt es, das Paket »Maria DB-server« per Yum zu installieren. Auf dem Server, auf dem sich DRBD gerade im primären Modus befindet, sollte der Admin zudem auch »systemctl start Maria DB« ausführen, um Maria DB erstmalig zu initialisieren. Anschließend lässt es sich per »systemctl stop Maria DB« wieder stoppen.
Einen Pferdefuß gibt es noch: Die DRBD-Ressource wird später nach »/var/lib/mysql« eingehängt, weil Maria DB dort die eigenen Datenbanken erwartet. Damit das funktioniert, muss die frisch initialisierte Maria DB erst auf die DRBD-Ressource. Außerdem müssen die Dateisystem-Berechtigungen bei der DRBD-Ressource passen.
Zunächst legt der Admin sich also ein temporäres Verzeichnis an und hängt auf dem Host, auf dem die DRBD-Ressource im Primary-Modus liegt, diese dort ein – im Beispiel »/srv/mysql«. Danach kopiert er die leere Maria-DB-Datenbank per »cpio« dorthin: Das erledigt der Befehl:
cd /var/lib/mysql && find | cpio -padmuv /srv/mysql
Das Korrigieren der Dateisystem-Berechtigungen erfolgt per »chown -R mysql:mysql /srv/mysql«, während DRBD eingehängt ist. Nun hängt der Admin »/srv/mysql« wieder aus und fährt mit der Konfiguration fort.
Übrigens: Der beschriebene Vorgang setzt voraus, dass Benutzer und Gruppe »mysql« auf beiden Hosts die gleiche UID und GID haben. Setzt der Admin beide Systeme parallel und im Gleichschritt neu auf, passiert das automatisch. Soll auf schon existierenden Systemen Maria DB nachgerüstet und per Pacemaker verclustert werden, kann es sinnvoll sein, Benutzer und Gruppe bereits vor der Installation des Pakets mit identischen UID und GID anzulegen.
Auf beiden Hosts sollte der Admin zusätzlich dafür sorgen, dass Maria DB am Ende auf der passenden IP – der Cluster-IP – lauscht. Dazu schreibt er
[mysqld] bind-address=192.168.0.3
in eine Datei namens »/etc/my.cnf.d/server.conf«.
Dateisystem und Maria DB im Cluster
Danach fügt der Admin das Dateisystem sowie die Maria-DB-Datenbank, die Pacemaker im Beispiel via »systemd«-Schnittstelle ansteuert, in den Cluster ein (Listing 3).
Listing 3
Maria DB einfügen
01 pcs cluster cib MariaDB_cfg 02 pcs -f MariaDB_cfg resource create p_MariaDB_fs ocf:heartbeat:Filesystem \ 03 device="/dev/drbd0" directory="/var/lib/mysql" fstype=xfs \ 04 op monitor interval=60s \ 05 --group g_MariaDB 06 pcs -f MariaDB_cfg resource create p_MariaDB systemd:MariaDB \ 07 op monitor interval=20s timeout=10s \ 08 op start interval=0s timeout=60s \ 09 op stop interval=0s timeout=60s \ 10 --group g_MariaDB
Die Befehle legen in Pacemaker eine Gruppe »g_Maria DB« an und darin die beiden Ressourcen für das Dateisystem und den Dienst selbst. Gruppen sind eine bequeme Einrichtung: Die zu einer Gruppe gehörenden Ressourcen startet Pacemaker automatisch auf demselben Host und in der Reihenfolge, in der sie in der Gruppe angelegt sind. So ist gesichert, dass Pacemaker Maria DB nicht auf dem Host startet, auf dem das passende Dateisystem gar nicht eingehängt ist.
Dasselbe Problem ergibt sich nochmals an anderer Stelle: Zwar gibt es im Cluster bereits die Cluster-IP und auch die DRBD-Konfiguration. Noch ist die gerade angelegte Gruppe mit diesen aber nicht verbunden. Denkbar wäre es also, dass die Cluster-IP am Ende auf einem anderen Host läuft als Maria DB. Außerdem ist auch die Reihenfolge von Bedeutung: Zunächst muss Pacemaker auf einem Host DRBD in den Primary-Modus schalten und erst im Anschluss sollte die Maria-DB-Gruppe zusammen mit der Cluster-IP funktionieren. Um diesen Effekt zu erreichen, sind noch ein paar Constraints nötig – Handlungsanweisungen für den Cluster (Listing 4).
Listing 4
Constraints
01 pcs -f MariaDB_cfg constraint colocation add DB with g_Maria ms_drbd_MariaDB \ 02 INFINITY with-rsc-role=Master 03 pcs -f MariaDB_cfg constraint order promote ms_drbd_MariaDB then start \ 04 g_MariaDB 05 pcs -f MariaDB_cfg constraint colocation add g_MariaDB with p_cluster-ip \ 06 INFINITY 07 pcs -f MariaDB_cfg constraint order start p_cluster-ip then start g_MariaDB
Mittels »pcs -f Maria DB_cfg constraint« lassen sich die hinterlegten Constraints nochmals begutachten. Wenn die Konfiguration passt, übernimmt das Kommando »pcs cluster cib-push Maria DB_cfg« das Setup in den laufenden Betrieb. Der Befehl »crm_mon -1 -rf« (Abbildung 5) sollte nun anzeigen, dass DRBD auf einem Host im Primary-Modus aktiv ist und dass dort Maria DB läuft.
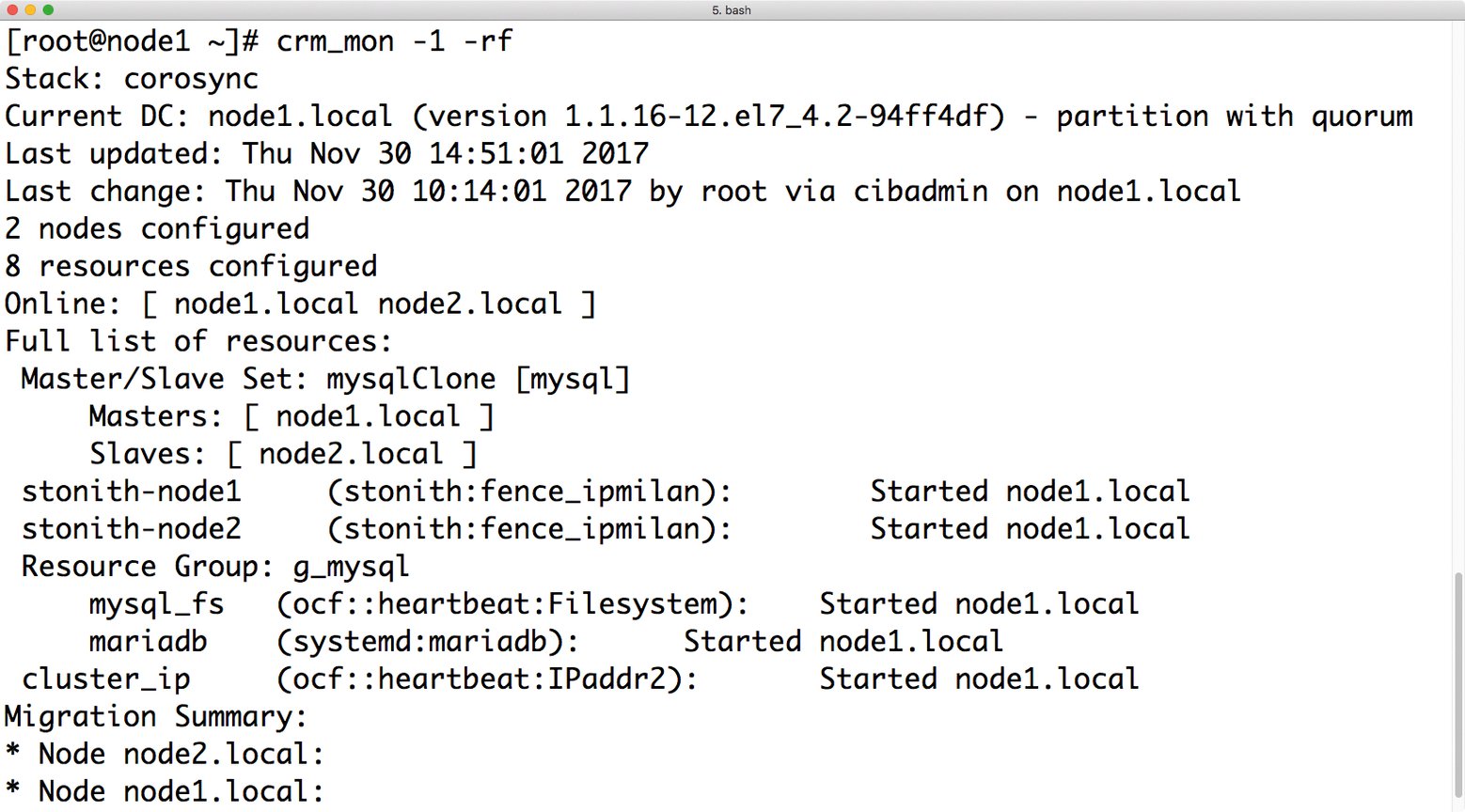
Abbildung 5: Nach der Konfiguration der Ressourcen in Pacemaker lassen sich per »crm_mon -1 -rf« alle Ressourcen anzeigen.
Jetzt sollte es möglich sein, sich mit »mysql« auf der Kommandozeile über die IP-Adresse »192.168.0.3« mit Maria DB zu verbinden (Abbildung 6). Klappt das nicht, ist möglicherweise Firewalld schuld – der Befehl »firewall-cmd –permanent –add-port=3306/tcp« löst auch dieses Problem.
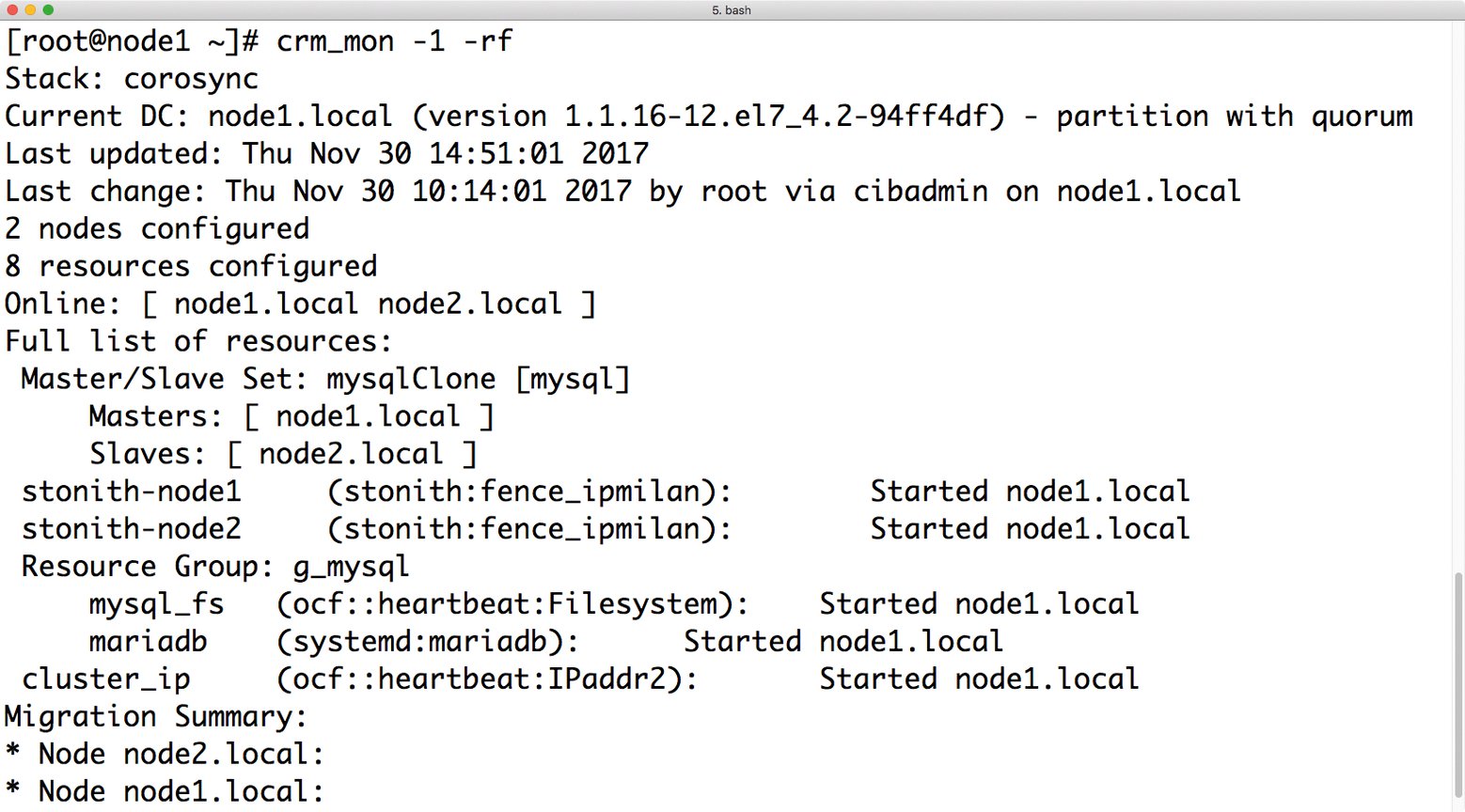
Abbildung 6: Lauscht Maria DB am Ende auf Port 3306, ist die Konfiguration von Pacemaker perfekt.
Wichtig: Bevor der Admin einen solchen Cluster in Betrieb nimmt, sollte er das Fail-over auf Herz und Nieren prüfen, etwa durch das Ausschalten eines Servers. Geht beim Setup der Ressourcen oder beim Testen etwas schief, hilft »pcs resource cleanup Name« dabei, eine fehlgeschlagene Aktion aufzuräumen – andernfalls führt der Cluster die Aktion möglicherweise nicht mehr aus.
Stonith einrichten
Die Abkürzung Stonith steht für “Shoot The Other Node In The Head”. Was im alltäglichen Sprachgebrauch etwas archaisch klingt, hat im Cluster-Kontext eine durchaus aktuelle Daseinsberechtigung: Im Rahmen des Fencing, also des Einzäumens, schickt ein Rechner einen anderen willentlich in einen Reboot, wenn er diesen verdächtigt, sich falsch zu verhalten. Falsch etwa deshalb, weil er Daten auf einem geteilten Speicher zu korrumpieren droht, wie das bei DRBD durchaus möglich ist.
Verlieren etwa beide Knoten den Sichtkontakt zueinander, könnten beide auf die Idee kommen, die bei ihnen bekannten DRBD-Ressourcen in den primären Betriebsmodus zu schalten. Das führt zwangsläufig zu einer Situation, in der die Datensätze der Server divergieren, was aber unter keinen Umständen vorkommen darf. Fencing ist die Notbremse: Egal welcher Knoten überlebt – die Gefahr für die Integrität der Daten wäre damit gebannt.
Hier kommt der Zugriff auf die BMC-Schnittstelle des Servers ins Spiel, die der Artikel zuvor bereits erwähnt hat. Das folgende Beispiel geht von IPMI over LAN aus. Zunächst installiert der Admin für funktionierendes Stonith in Pacemaker die Fencing-Agenten von Pacemaker mittels »yum install fence-agents«. Anschließend fügt er dem Cluster zwei Fencing-Ressourcen hinzu, die den Zugriff auf beide BMC-Schnittstellen erlauben (Listing 5).
Listing 5
Fencing
01 pcs stonith create stonith-knoten1 fence_ipmilan pcmk_host_list="knoten1.domain" action=reboot ipaddr="192.168.0.1" login="root" passwd="PASSWORT" op monitor interval=15s 02 03 pcs stonith create stonith-knoten2 fence_ipmilan pcmk_host_list="knoten2.domain" action=reboot ipaddr="192.168.0.2" login="root" passwd="PASSWORT" op monitor interval=15s
Anschließend definiert er noch zwei Location-Constraints, die in Kombination dafür sorgen, dass die Knoten sich nur gegenseitig neu starten können – andernfalls könnte es passieren, dass ein defekter Knoten in die Verlegenheit käme, sich selbst neu zu starten:
pcs constraint location stonith-knoten1 avoids knoten1.domain=INFINITY pcs constraint location stonith-knoten2 avoids knoten2.domain=INFINITY
Der Vollständigkeit halber sei abschließend erwähnt, dass Stonith per IPMI over LAN und grundsätzlich per BMC-Schnittstelle nur eine Variante von vielen ist. Andere Ansätze sehen vor, den Rechner per fernsteuerbarer PDU neu zu starten, indem Pacemaker ihm im Falle eines Stonith-Events einfach kurz den Strom abstellt.
Abschlussarbeiten
Ein letzter Schritt ist noch nötig: Getreu der Red-Hat-Standards sorgt die Installation der Pakete für Pacemaker, Corosync und Pcsd nicht dafür, dass die auch tatsächlich beim Systemstart loslaufen. Drei Befehle lösen das Problem:
systemctl enable pcsd systemctl enable corosync systemctl enable pacemaker
Danach darf der Admin annehmen, dass die Clusterdienste nach dem Reboot eines Systems automatisch gestartet werden. Für die weitere Arbeit mit dem Clustermanager und DRBD empfiehlt sich übrigens die gute Dokumentation, die Linbit und das Pacemaker-Projekt gemeinsam interessierten Admins zur Verfügung stellen ([1], [2]).
Infos
- Pacemaker-Dokumentation: http://clusterlabs.org/doc/
- DRBD-Dokumentation: https://docs.Linbit.com/docs/users-guide-8.4/
Der Autor

Martin Gerhard Loschwitz ist Telekom Public Cloud Architect bei T-Systems und beschäftigt sich beruflich vorrangig mit Themen wie Open Stack, Ceph und Kubernetes.





