
Zeigt ein C++-Programm undefiniertes Verhalten, sind verlässliche Aussagen gerade zu diesem Verhalten nicht mehr möglich. Oder anders ausgedrückt: Der Computer kann sogar in Rauch aufgehen. Ein heißes Thema also, wobei sich undefiniertes Verhalten mit etwas Geschick auch vermeiden lässt.
Verhaltensforschung spielt auch für C++-Entwickler eine entscheidende Rolle, um möglichst guten Code zu schreiben. Genau darauf geht auch der sechste der zehn Tipps für C++-Programmierer in Abbildung 1 ein: “Vermeide undefiniertes Verhalten.” Er betrifft nicht weniger als die Korrektheit des Programms, denn genau diese zerstört ein Programm mit undefiniertem Verhalten. Doch wie sieht das in der Praxis aus?

Abbildung 1: Der sechste Tipp beschäftigt sich mit Verhaltensforschung.
Ein Programm kann auf alle möglichen Arten fehlschlagen, nicht nur beim Bauen und Ausführen. Es kann beispielsweise ein falsches Ergebnis liefern oder – und das ist die schlimmste aller Ausprägungen undefinierten Verhaltens – zufällig das erwartete Ergebnis. Nichts wiegt einen Entwickler oder Tester in größerer Sicherheit als ein erwartetes Ergebnis. Ein undefiniertes Verhalten, das heute das erwartete Ergebnis liefert, kann morgen mit einem anderen Compiler oder auf alternativer Hardware seine Gestalt vollkommen verändern. Murphys Gesetz [1] folgend ereignen sich solche Worst-Case-Szenarios meist beim Kunden.
Data Race
Den englischen Begriff Data Race übersetzt das deutsche “kritischer Wettlauf” leider nur sehr ungenau. Denn das Wort umschreibt im Deutschen zugleich den englischen Begriff Race Condition. Um dieser Begriffsverwirrung entgegenzuwirken, verwendet der Artikel die englischen Begriffe.
Multithreading ist anspruchsvoll, sehr anspruchsvoll. Daher nimmt es nicht Wunder, dass undefiniertes Verhalten insbesondere in dieser Domäne hinter jeder Codezeile lauert, meist in Gestalt eines Data Race (siehe Kasten “Data Race”). Wie das in der Praxis aussieht, zeigt ein relativ offensichtliches Beispiel. Ein weniger schnell erkennbares zweites Beispiel für undefiniertes Verhalten schließt sich gegen Ende des Artikels an.
Nach Adam Riese
Den Anfang macht ein vermeintlich einfaches Programm, die Idee ist schnell skizziert: Ein Thread startet einen Kinder-Thread. Den ersten füttert der Erzeuger mit der Zahl 1000 und lässt den Kinder-Thread das Produkt von 6 mal 5 hinzuaddieren (Listing 1). Nach Adam Ries [2] macht das 1030.
Listing 1
Starten eines Kinder-Thread
01 #include <chrono>
02 #include <iostream>
03 #include <thread>
04
05 class Sleeper{
06 public:
07 Sleeper(int& i_):i{i_}{};
08 void operator() (int k){
09 for (unsigned int j= 0; j <= 5; ++j){
10 std::this_thread::sleep_for(std::chrono::milliseconds(100));
11 i += k;
12 }
13 std::cout << std::this_thread::get_id();
14 }
15 private:
16 int& i;
17 };
18
19
20 int main(){
21
22 std::cout << std::endl;
23
24 int valSleeper= 1000;
25 std::thread t(Sleeper(valSleeper),5);
26 t.detach();
27 std::cout << "valSleeper = " << valSleeper << std::endl;
28
29 std::cout << std::endl;
30
31 }
Unerwartet falsch
Im Programm steckt aber der Wurm, deshalb folgt eine genauere Erläuterung. Das Ergebnis der Addition stellt die Zeile 27 in der Variablen »valSleeper« bereit. Der Kinder-Thread »t« in Zeile 25 erhält sein Arbeitspensum in Form eines Funktionsobjekts. Das benötigt als Parameter die globale Variable »valSleeper« sowie die Zahl 5. Entscheidend ist, dass das Programm dem Kinder-Thread die Variable »valSleeper« per Referenz übergibt, um den Thread dann mittels »t.detach()« in Zeile 26 von der Lebenszeit seines Erzeugers zu trennen.
Der Erzeuger (der Main-Thread) wartet aber nicht müßig, bis der Kinder-Thread seine Arbeit erledigt hat, er führt seine Anweisungen weiter aus. Der Kinder-Thread hat aber ebenfalls einige Jobs zu erledigen. So muss er im Call Operator (Zeilen 8 bis 14) 6-mal die 5 zur geteilten Variablen »valSleeper« addieren. Das ermüdet, also legt er sich nach jeder Iteration erst einmal für eine Zehntelsekunde (Zeile 10) aufs Ohr.
Ist der Kinder-Thread mit seiner Arbeit fertig, schreibt er seine ID in Zeile 13 auf den Ausgabekanal und der Erzeuger stellt das Ergebnis der Berechnung anschließend dar (Zeile 27). Der Vollständigkeit halber veranschaulicht Abbildung 2 die Ausgabe des Programms, die – oh Schreck! – nicht dem erwarteten Ergebnis entspricht.
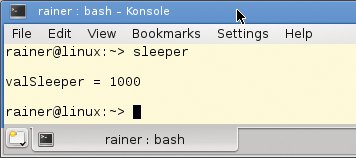
Abbildung 2: Ergebnis der nicht-synchronisierten Addition des Kinder-Thread.
Hat das Programm also ein Problem? Nicht nur eins. Weder enthält »valSleeper« das Ergebnis 1030 der Berechnung, noch stellt es die ID des Kinder-Thread dar. Was aber verursacht diese zwei ernsthaften Probleme?
Erstens teilen sich beide Threads »valSleeper«. Der Erzeuger-Thread liest den Wert zur selben Zeit, in der ihn der Kinder-Thread schreibt. Das führt zu einem klassischen Data Race. Damit landet das Programm mitten in einem undefinierten Verhalten, aber nicht dem einzigen.
Zweitens endet die Lebenszeit des Erzeuger-Thread, bevor der Kinder-Thread seine Arbeit beenden kann. So versucht der Kinder-Thread auf »std::cout« zu schreiben, während der Erzeuger-Thread den Ausgabekanal aufräumt.
Dem sehr aufmerksamen Leser fällt bei dem Programm eventuell noch ein drittes – vermeintliches – Problem auf, das sich dank des C++-Standards aber in Wohlgefallen auflöst. Der Ausgabekanal »std::cout« tritt auch als geteilte Variable auf, die das Programm zeitgleich liest und schreibt. Das ist aber tatsächlich wohldefiniert, da der Standard zusichert, jeden Buchstaben auf »std::cout« atomar zu schreiben.
Listing 2
Das korrigierte main-Programm
01 [...]
02 int main(){
03
04 std::cout << std::endl;
05
06 int valSleeper= 1000;
07 std::thread t(Sleeper(valSleeper),5);
08 t.join();
09 std::cout << "valSleeper = " << valSleeper << std::endl;
10
11 std::cout << std::endl;
12 }
Ein Fix, um das Problem des zweifach undefinierten Programmverhaltens zu lösen, ist recht einfach: Statt »t.detach()« sollte der Entwickler in Zeile 26 »t.join()« verwenden. Listing 2 zeigt die entscheidenden Zeilen des »main()«-Programms. Dank der Korrektur wartet der Erzeuger-Thread, bis sein Kinder-Thread fertig ist, dann sind beide vollständig synchronisiert. In der Folge liefert das Programm das erwartete Ergebnis (Abbildung 3). Natürlich ist das Programm 6-mal 0,1 Sekunden langsamer, doch Korrektheit kommt vor Performance.
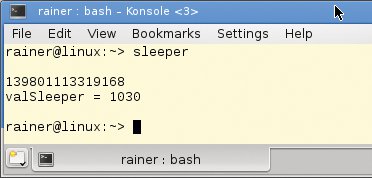
Abbildung 3: Anders sieht es bei einer synchronisierten Addition des Kinder-Thread aus.
Nicht immer lässt sich undefiniertes Verhalten in einem Programm so leicht aufspüren wie in der gerade vorgestellten Beispielanwendung. So bleibt das folgende undefinierte Verhalten in den vom Autor veranstalteten C++-Seminaren meist unentdeckt.
Ich will doch nur lesen
Als Datenstruktur liest C++ ein Telefonbuch typischerweise oft, schreibt aber selten hinein. Da trifft es sich gut, dass C++14 Readers-writer-Locks [3] anbietet. Die erlauben es elegant, wahlweise mehrere Threads zeitgleich zu lesen oder das Telefonbuch mit nur einem Thread zu beschreiben. Das hört sich sehr gut an, denn es entschärft den konkurrierenden Zugriff auf die gemeinsame Variable Telefonbuch deutlich. Listing 3 zeigt das Telefonbuch im Einsatz.
Listing 3
Gleichzeitig aus dem Telefonbuch lesen
01 #include <iostream>
02 #include <map>
03 #include <shared_mutex>
04 #include <string>
05 #include <thread>
06
07 std::map<std::string,int> teleBook{{"Dijkstra", 1972}, {"Scott", 1976},
08 {"Ritchie", 1983}};
09
10 std::shared_timed_mutex teleBookMutex;
11
12 void addToTeleBook(const std::string& na, int tele){
13 std::lock_guard<std::shared_timed_mutex> writerLock(teleBookMutex);
14 std::cout << "\nSTARTING UPDATE " << na;
15 std::this_thread::sleep_for(std::chrono::milliseconds(500));
16 teleBook[na]= tele;
17 std::cout << " ... ENDING UPDATE " << na << std::endl;
18 }
19
20 void printNumber(const std::string& na){
21 std::shared_lock<std::shared_timed_mutex> readerLock(teleBookMutex);
22 std::cout << na << ": " << teleBook[na];
23 }
24
25 int main(){
26
27 std::cout << std::endl;
28
29 std::thread reader1([]{ printNumber("Scott"); });
30 std::thread reader2([]{ printNumber("Ritchie"); });
31 std::thread w1([]{ addToTeleBook("Scott",1968); });
32 std::thread reader3([]{ printNumber("Dijkstra"); });
33 std::thread reader4([]{ printNumber("Scott"); });
34 std::thread w2([]{ addToTeleBook("Bjarne",1965); });
35 std::thread reader5([]{ printNumber("Scott"); });
36 std::thread reader6([]{ printNumber("Ritchie"); });
37 std::thread reader7([]{ printNumber("Scott"); });
38 std::thread reader8([]{ printNumber("Bjarne"); });
39
40 reader1.join();
41 reader2.join();
42 reader3.join();
43 reader4.join();
44 reader5.join();
45 reader6.join();
46 reader7.join();
47 reader8.join();
48 w1.join();
49 w2.join();
50
51 std::cout << std::endl;
52
53 std::cout << "\nThe new telephone book" << std::endl;
54 for (auto teleIt: teleBook){
55 std::cout << teleIt.first << ": " << teleIt.second << std::endl;
56 }
57
58 std::cout << std::endl;
59
60 }
Das Telefonbuch in Zeile 7 tritt als gemeinsame Variable auf, die es zu schützen gilt. Acht Threads wollen das Telefonbuch lesen und zwei wollen es aktualisieren. Um das Telefonbuch gleichzeitig zu lesen, verwenden die lesenden Threads einen »std::shared_lock<std::shared_ timed_mutex>« in Zeile 21. Verpackt der Entwickler den »std::shared_timed_mutex« in Zeile 13 hingegen in einen »std::lock_guard«, kann ihn nur maximal ein Thread zu einem Zeitpunkt verwenden. Zum Schluss gibt das Programm das aktualisierte Telefonbuch (Zeilen 54 und 55) aus.
Der Screenshot in Abbildung 4 zeigt schön, wie sich die Ausgaben der lesenden Threads überlappen, während die Ausgaben der schreibenden Threads einer nach dem anderen erscheinen. Das bedeutet, dass das Programm die lesenden Threads zeitgleich ausführt.
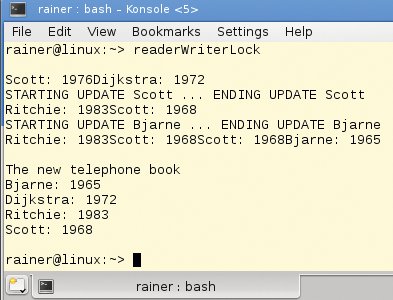
Abbildung 4: Hier lässt sich ein Readers-writer-Lock im praktischen Gebrauch bewundern.
Das war einfach, fast schon zu einfach. Denn tatsächlich zeigt das Programm undefiniertes Verhalten. Um noch etwas genauer zu sein: In ihm lauert eine Race Condition, die sich zum Data Race auswachsen kann. Dabei ist das gleichzeitige Schreiben auf »std::cout« gar nicht das Problem.
Bjarne fehlt
Die Charakteristik eines Data Race besteht darin, dass zumindest zwei Threads auf eine gemeinsame Variable zugreifen, wobei wenigstens einer der beiden Threads versucht diese zu ändern. Genau dies ermöglicht die Programmausführung.
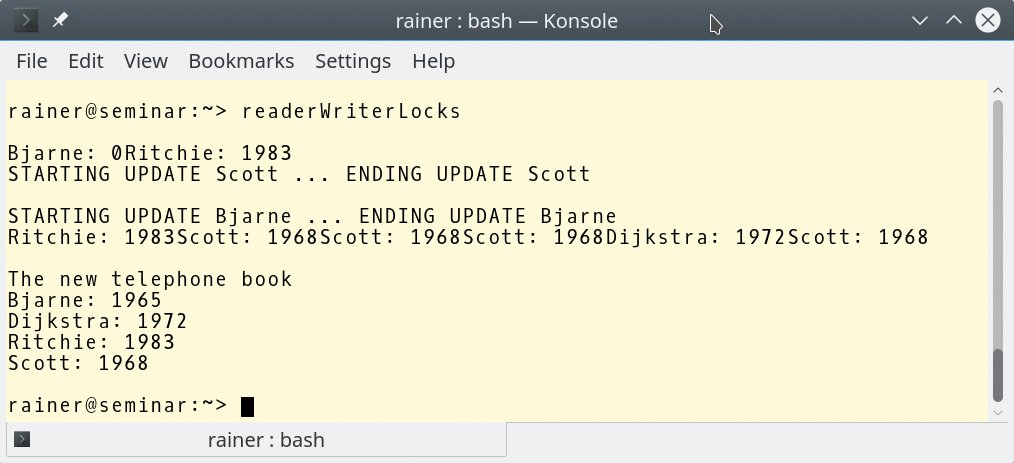
Abbildung 5: Das Programm liest »Bjarne« zu früh, ein Data Race folgt.
Eines der Features assoziativer Container wie »std::map« besteht darin, mit dem Lesen eines Wertes die »std::map« zu verändern. Das passiert immer dann, wenn der Schlüssel noch nicht im Container existiert. Findet das Programm also »Bjarne« noch nicht im Telefonbuch vor, legt es das Paar (»Bjarne«, »0«) darin an. Dieser Vorgang lässt sich auch auf einfache Weise erzwingen, wenn das Lesen des Schlüssels »Bjarne« in Zeile 38 vor allen anderen Threads (in den Zeilen 29 bis 38) stattfindet. Und genau darin besteht dieses Data Race. Abbildung 5 zeigt das Verhalten recht deutlich, »Bjarne« besitzt hier den Wert »0«.

Abbildung 6: Nach der Reparatur zeigt das veränderte Programm eine Meldung an, falls der Schlüssel nicht existiert.
Die naheliegende Lösung, um so ein Data Race zu verhindern, besteht darin, nur eine lesende Operation in der Funktion »printNumber()« in den Zeilen 20 bis 23 zu verwenden. Diese Idee setzt Listing 4 in die Praxis um. Findet es jetzt den Schlüssel nicht im Telefonbuch, schreibt das veränderte Programm lediglich den String »not found« auf die Konsole (Abbildung 6).
Listing 4
printNumber(), nur lesend
01 [...]
02 void printNumber(const std::string& na){
03 std::shared_lock<std::shared_timed_mutex> readerLock(teleBookMutex);
04 auto searchEntry = teleBook.find(na);
05 if(searchEntry != teleBook.end()){
06 std::cout << searchEntry->first << ": " << searchEntry->second << std::endl;
07 }
08 else {
09 std::cout << na << " not found!" << std::endl;
10 }
11 }
12 [...]
Das runderneuerte Programm zeigt zudem im zweiten Lauf die Ausgabe »Bjarne not found!« an. Dies gilt nicht für die erste Programmausführung, denn während dieser ruft es zuerst die Funktion »addToTeleBook()« auf. Daher befindet sich »Bjarne« an diesem Punkt bereits im Telefonbuch.
Wie geht’s weiter?
Entwickler lesen Sourcecode mindestens zehnmal so oft wie sie ihn schreiben. Die Lesbarkeit des Codes ist daher eine sehr wichtige Anforderung. Genau um die geht es im nächsten Artikel, denn viele Wege führen nach Rom. Das heißt aber nicht, dass sich alle Wege gleich einfach meistern lassen.
Infos
- Murphys Gesetz: https://de.wikipedia.org/wiki/Murphys_Gesetz
- Adam Ries: https://de.wikipedia.org/wiki/Adam_Ries
- Readers-writer-Locks: https://en.wikipedia.org/wiki/Readers%E2%80%93writer_lock
Der Autor

Rainer Grimm ist Trainer für C++ und Python. Seine zahlreichen C++-Bücher, zuletzt “The C++ Standard Library” und “Concurrency with modern C++”, sind bei O’Reilly und Leanpub erschienen.





