
Mit der Move-Semantik und konstanten Ausdrücken besitzt modernes C++ eine kräftige Stellschraube, um die Performance einer C++-Anwendung in die richtige Richtung zu drehen.
Zehn Regeln[1] hat der Autor aufgestellt, die guten C++-Code auszeichnen (Abbildung 1), dieser Artikel widmet sich der dritten.
Während die Move-Semantik es erlaubt, billig zu verschieben statt teuer zu kopieren, führt C++ als »constexpr()« deklarierte Funktionen zur Übersetzungszeit aus. Dieses Optimierungspotenzial gilt es zu nutzen. Dazu genügt es, zwei grundlegende Regeln im Kopf zu behalten:
- Implementiere Algorithmen mit Move-Semantik.
- Erkläre Funktionen als konstante Ausdrücke.
Natürlich gibt es keine Regel ohne Ausnahme. So setzt zum Beispiel die zweite Regel voraus, dass der Entwickler einen C++14-Compiler einsetzt und dass die Funktion kleine syntaktische Einschränkungen aufweist. Die moniert der Compiler allerdings postwendend, sodass der Entwickler stets ein wohldefiniertes Programm erhält. Doch dazu später mehr.

Abbildung 1: “Unterstütze automatische Optimierungen” sollten moderne C++-Programmierer beherzigen.
Move versus Copy
Lang, lang ist es her: Vor fast fünf Jahren hatte der Artikel “Rasch verschoben” [2] bereits die Move- und die Copy-Semantik zum Thema. Daher bringt die Implementierung des »std::swap«-Algorithmus in Listing 1 mit Copy- und Move-Semantik die entscheidenden Fakten für die Anwender nochmals auf den Tisch.
Listing 1
std::swap mit Copy- und Move-Semantik
01 std::vector<int> a, b;
02 swap(a,b);
03
04 template <typename T>
05 void swap(T& a, T& b){
06 T tmp(a);
07 a= b;
08 b= tmp;
09 }
10
11 template <typename T>
12 void swap(T& a, T& b){
13 T tmp(std::move(a));
14 a= std::move(b);
15 b= std::move(tmp);
16 }
Während die erste Implementierung des »std::swap«-Algorithmus die Copy-Semantik (Zeilen 4 bis 9) anwendet, setzt die zweite auf Move (Zeilen 11 bis 16). Konkret fordert die Methode »std::move()« die Move-Semantik in der zweiten Variante explizit vom Compiler an.
Beide Algorithmen sind Funktions-Templates und nehmen somit beliebige Argumente an. Im konkreten Fall sind dies die zwei Vektoren »a« und »b«, die das Codebeispiel vertauscht. Um die Unterschiede zwischen Copy- und Move-Semantik zu verstehen, hilft ein Vergleich der Zeilen 6 (»T tmp(a)«) und 13 (»T tmp(std::move(a)«). Der Ausdruck »T tmp(a)« bewirkt, dass Listing 1
- Speicher für »tmp« und jedes Element von »tmp« alloziert,
- jedes Element von »a« nach »tmp« kopiert,
- Speicher für »tmp« und jedes Element von »tmp« freigibt.
Hingegen bewirkt der Ausdruck »T tmp(std::move(a))« nur, dass »tmp« auf die Daten von »a« verweist und seine Größe richtig initialisiert.
Diese Beobachtungen gelten natürlich auch für die Zeilenpaare 7 und 14 oder 8 und 15. Die Move-Semantik zahlt sich für Datenstrukturen aus, die einen Verweis auf ihre Daten auf dem Heap mitbringen. Das ist für »std::vector<int> a« der Fall, denn der Vektor »a« ist – vereinfachend interpretiert – nur ein dünner Wrapper, der seine Daten auf dem Heap verwaltet. Das ist notwendig, denn ein Vektor muss zur Laufzeit des Programms dynamisch wachsen dürfen.
Diese Eigenschaft zeichnet aber nicht nur »std::vector« aus, sondern alle anderen Container der Standard Template Library inklusive dem String. Lediglich »std::array« legt seine Daten zur Übersetzungszeit des Programms an.
Dass sich die Move-Semantik auszahlt, hat zwei Gründe. Zum einen ist ein einfaches Verbiegen eines Zeigers schneller als das aufwändige Anfordern und Freigeben von Speicher. Zum anderen geht beim Verbiegen eines Zeigers nichts schief, was auf das Anfordern und Freigeben des Speichers nicht so klar zutrifft.
Die Zahlen zu den Performance-Unterschieden beider Semantiken und die weiteren Details kennt der erwähnte Artikel [2]. Bleibt zu klären, in welcher Form die Move-Semantik die automatische Optimierung unterstützt.
I like to move it, move it
Die Copy-Semantik dient als Fallback für die Move-Semantik. Was das heißt, zeigt Listing 2. Obwohl die Klasse »MyData« (Zeilen 13 bis 30) keine Move-Semantik unterstützt und nur einen Copy-Konstruktor (Zeile 19) sowie einen Copy-Zuweisungsoperator (Zeile 24) anbietet, lässt sie sich in dem »swap()«-Algorithmus der Zeilen 6 bis 11 verwenden. Dieser nutzt die Move-Semantik unter der Oberfläche. Die Ausgabe des Programms in Abbildung 2 bringt das Ergebnis ans Tageslicht.
Listing 2
Copy-Semantik als Fallback
01 #include <iostream>
02 #include <utility>
03 #include <vector>
04
05
06 template <typename T>
07 void swap(T& a, T& b){
08 T tmp(std::move(a));
09 a = std::move(b);
10 b = std::move(tmp);
11 }
12
13 struct MyData{
14 std::vector<int> myData;
15
16 MyData():myData({1,2,3,4,5}){}
17
18 // copy constructor
19 MyData(const MyData& m):myData(m.myData){
20 std::cout << "copy constructor" << std::endl;
21 }
22
23 // copy assignment operator
24 MyData& operator=(const MyData& m){
25 myData= m.myData;
26 std::cout << "copy assignment operator" << std::endl;
27 return *this;
28 }
29
30 };
31
32 int main(){
33
34 std::cout << std::endl;
35
36 MyData a,b;
37 swap(a,b);
38
39 std::cout << std::endl;
40
41 };
Wie ist das möglich? Die Copy-Semantik ist das Fallback für die Move-Semantik. Steht Letztere nicht zur Verfügung, wendet der Compiler Copy-Semantik an. Das gilt selbst dann, wenn der Code, wie in diesem Beispiel, die Move-Semantik explizit anfordert.
Technisch ist die Argumentation relativ einfach. Der R-Value als Rückgabewert von »std::move«, den der »swap()«-Algorithmus verwendet, lässt sich an eine R-Value-Referenz oder eine konstante L-Value-Referenz binden. Im Zweifelsfall erhält die R-Value-Referenz höhere Priorität. Sowohl der Copy-Konstruktor (Zeile 19) als auch der Copy-Zuweisungsoperator (Zeile 24) erwarten eine konstante L-Value-Referenz.
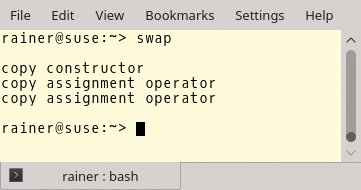
Abbildung 2: Die Move-Semantik mit nur kopierbarem »typename«.
Dass die Copy-Semantik als Fallback für die Move-Semantik dient, hat weitreichende Konsequenzen für die Implementierung von Algorithmen. Ein Algorithmus wie »swap()« lässt sich mit Move-Semantik implementieren, denn wenn die verwendeten Datentypen die Move-Semantik nicht unterstützen, springt die Copy-Semantik als Fallback ein. Passiert dies, besitzt der »swap()«-Algorithmus die Performance des klassischen »swap()« mit Copy-Semantik.
Entwickler sollten beim Implementieren von Algorithmen also die Move-Semantik im Hinterkopf behalten. Unterstützt der Datentyp diese, nutzt der Code sie automatisch. Ist das nicht der Fall, schöpft er ihr Potenzial eben nicht aus. Dennoch bleibt der Algorithmus syntaktisch richtig und zeigt das gleiche Laufzeitverhalten wie die klassische Implementierung mit Copy-Semantik. Dieses Potenzial auf automatische Optimierung lauert übrigens auch in »constexpr()«-Funktionen.
Doppelter Einsatz
Eine kleine Warnung vorweg. Dieser Artikel behandelt die »constexpr()«- Funktionen des C++14-Standards. Die des C++11-Standards besitzen deutlich zu viele Einschränkungen, die für ihre C++14-Gegenstücke nicht gelten.
Im Wesentlichen sollten Entwickler beachten, dass es der modernen Variante nicht erlaubt ist, Thread-lokale und statische Daten zu verwenden. Sie darf zudem keine Ausnahmebehandlung anbieten und konsequenterweise nur Ausdrücke verwenden, die sich bereits zur Compile-Zeit evaluieren lassen.
Natürlich waren konstante Ausdrücke mit »constexpr()« bereits Inhalt der Artikelserie zu modernem C++ und ein Artikel [3] beschäftigte sich ausführlich mit konstanten Ausdrücken in Form von Variablen, benutzerdefinierten Typen und Funktionen. Doch hier geht es um einen besonderen Aspekt von »constexpr()«-Funktionen: Sie lassen sich zur Übersetzungszeit und zur Laufzeit des Programms ausführen (Listing 3). Eine kleine Beobachtung, die jedoch weitreichende Konsequenzen für die Implementierung von Funktionen besitzt.
Listing 3
Die constexpr()-Funktionen
01 # größten gemeinsamen Teile zweier Zahlen berechnen
02 #include <iostream>
03
04 constexpr auto gcd(int a, int b){
05 while (b != 0){
06 auto t = b;
07 b = a % b;
08 a = t;
09 }
10 return a;
11 }
12
13 int main(){
14
15 std::cout << std::endl;
16
17 constexpr auto i= gcd(11, 121);
18 std::cout << i << std::endl;
19 std::cout << 11 << std::endl;
20
21 auto fir= 11;
22 auto sec= 121;
23 auto j= gcd(11, 121);
24 std::cout << j << std::endl;
25
26 std::cout << std::endl;
27
28 }
Der Algorithmus »gcd()« (Zeilen 4 bis 11) ermittelt den größten gemeinsamen Teiler der zwei Zahlen »a« und »b«. Entscheidend am Algorithmus ist, dass ihn Zeile 4 als »constexpr()« definiert. Das bedeutet, er lässt sich potenziell zur Übersetzungszeit ausführen. Das nutzt Zeile 17, die das Ergebnis der Berechnung explizit durch »constexpr auto i« zur Übersetzungszeit anfordert. Möglich wird dies, weil die beiden Argumente »11« und »121« des Algorithmus als so genannte Literale bereits zur Übersetzungszeit bereitstehen.
Liegen die Argumente zur Übersetzungszeit noch nicht vor, lässt sich der »gcd()«-Algorithmus dann natürlich nicht anwenden. Genau das zeigt Zeile 23, denn die Funktionsargumente »fir« und »sec« sind keine konstanten Ausdrücke. Verlangt »constexpr auto j« das Ergebnis der Berechnung trotzdem zur Übersetzungszeit, wirft der Compiler sofort das Handtuch und beendet seinen Job.
Um »j« zur Übersetzungszeit anzufordern, muss der Entwickler die Argumente als konstante Ausdrücke definieren: »constexpr auto fir= 11« und »constexpr auto sec= 121«. Abbildung 3 zeigt die bewusst einfach gehaltene Ausgabe des Programms.
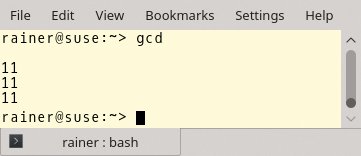
Abbildung 3: Der »gcd«-Algorithmus im Einsatz.
Die meiste Verwirrung in Listing 3 stiftet vermutlich die Zeile 19, die einfach nur die Zahl »11« ausgibt. Nein, es handelt sich in diesem Fall nicht um die Uhrzeit der Artikelproduktion. Vielmehr hilft die Zahl 11, die Zeile 18 besser zu verstehen. Ein Analyse der Assembler-Anweisungen mit Hilfe des Programms »objdump« bringt die internen Abläufe in Abbildung 4 ans Tageslicht.
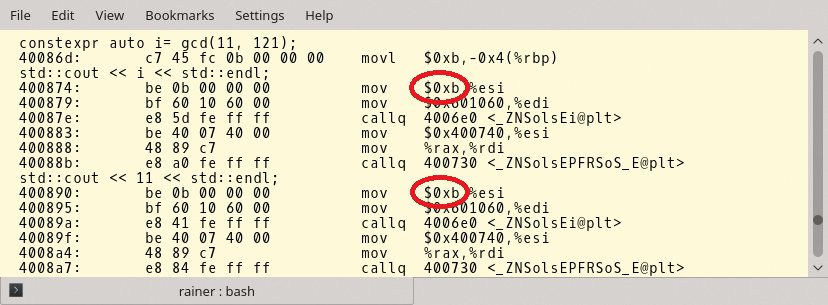
Abbildung 4: Die ausschlaggebenden Assembler-Anweisungen.
Aus der Sicht der C++-Laufzeit ist es vollkommen unerheblich, ob sie den Wert der Variablen »i« mit Hilfe des konstanten Ausdrucks »gcd(11, 121)« zur Übersetzungszeit berechnet oder ob sie den Wert als Konstante »11« verwendet. Die Assembler-Anweisungen verwenden den hexadezimalen Wert »0xb«, der für die dezimale Zahl 11 steht. Das heißt, dass C++ die ganze Berechnung bereits zur Übersetzungszeit ausführt.
Nun aber zurück zum Motto des Artikels: “Unterstütze automatische Optimierungen”. Funktionen oder Methoden, die C++ aufgrund ihrer Definition zur Übersetzungszeit ausführen kann, sollte der Entwickler als »constexpr()«-Funktionen definieren. Diese verwendet C++ zur Laufzeit, kann sie aber auch zur Übersetzungszeit ausführen.
Tatsächlich gab es in der C++-Community Diskussionen, eine Funktion per Default zur »constexpr()«-Funktion zu machen. Dann müsste der Code die Funktion aber explizit auszeichnen, um sie nur zur Laufzeit auszuführen.
Infos
-
Rainer Grimm, “Von der Theorie zur Praxis”: Linux-Magazin 12/16, S. 100, https://www.linux-magazin.de/Ausgaben/2016/12/C
-
Rainer Grimm, “Rasch verschoben”: Linux-Magazin 12/12, S. 96, https://www.linux-magazin.de/Ausgaben/2012/12/C-11
-
Rainer Grimm, “Konstante Magie”: Linux-Magazin 06/15, S. 88, https://www.linux-magazin.de/Ausgaben/2015/06/C-11
Der Autor

Rainer Grimm ist Trainer für C++ und Python. Seine Bücher “C++11 für Programmierer”, “C++”, “C++11-Standardbibliothek” sowie “The C++ Standard Library” sind bei O’Reilly und Leanpub erschienen.





