
© zoomteam, 123RF
Der dritte Teil des Open-Stack-Workshops beschäftigt sich mit der Frage, wie Admins Open Stack im Rechenzentrum betreiben, worauf sie bei der Planung achten sollten und welche Probleme auf sie zukommen. Auf die Herausforderung der Installation folgen die nicht minder herausfordernden Mühen der Ebene.
Wer Open Stack – wie im zweiten Workshop-Teil empfohlen – ausprobiert hat, denkt sich vielleicht: Wenn MaaS und Juju Open Stack innerhalb weniger Stunden ausrollen, dann kann die Lösung ja nicht so komplex sein. Das aber ist ein Trugschluss, denn das beschriebene MaaS-Juju-Setup vereinfacht an einigen Stellen Anforderungen radikal und schließt anfangs viele Funktionen aus, die eine produktive Open-Stack-Umgebung später braucht.
Der dritte Teil des Workshops beschäftigt sich deshalb damit, wie die Erkenntnisse aus dem ersten eigenen Mini-Open-Stack auf tatsächliche Setups in Rechenzentren zu übertragen sind. Dieser Teil geht davon aus, dass auch das Deployment einer produktiven Umgebung mit Juju und MaaS erfolgt. Damit einher geht die unangenehme Einschränkung, dass die Lösung ab dem elften Knoten, den MaaS verwalten soll, Kosten verursacht. Freilich wäre es ebenfalls möglich, sich auf andere Deployment-Methoden zu konzentrieren.
So ließe sich alternativ Ansible auf einem nackten Ubuntu nutzen, um Open Stack auszurollen. Dann fiele dem Admin jedoch die Aufgabe zu, den Bare-Metal-Teil selbst zu bauen. Wer diesen Weg beschreitet, kann möglicherweise nicht alle Erkenntnisse aus dem folgenden Artikel auf sein Setup übertragen. Die meisten Ratschläge funktionieren jedoch in allen Open-Stack-Setups, ganz gleich wie diese ausgerollt wurden.
Passende Infrastruktur
Für Open-Stack-Umgebungen gelten dieselben Grundregeln wie für jedes konventionelle Setup: Redundanter Strom und redundantes Netz sind Pflicht. Gerade bei der Netzwerkhardware sollte der Admin von Anfang an eher klotzen statt kleckern: Die Empfehlung ist ganz klar, pro Compute-Knoten mindestens 25-Gigabit-Ethernet vorzusehen – und zwar doppelt. Switches mit 48 25-GBit-Ethernet-Ports sind auf dem Markt mittlerweile problemlos erhältlich (Abbildung 1), und wer es ganz elegant machen möchte, organisiert sich gleich Geräte mit Cumulus [1] und baut ein Layer-3-Routing. Dabei verteilt jeder einzelne Knoten die Routen zu sich per BGP im gesamten Netz. Dieses Fabric-Prinzip nutzen beispielsweise große Anbieter wie Facebook oder auch Google, um ein optimales Netzwerk-Setup zu erreichen.
Abbildung 1: 48-Port-Switches mit 25-GBit-Ethernet pro Port sind mittlerweile marktüblich und für ein neues Open-Stack-Setup unbedingt empfohlen.
Wer eine produktive Open-Stack-Umgebung plant, sollte mindestens zwei Verfügbarkeitszonen (Availability Zones) vorsehen. Das können zwei Räume innerhalb desselben Rechenzentrums sein, die jedoch in verschiedenen Brandschutzzonen liegen. Noch besser ist es, die Verfügbarkeitszonen auf voneinander unabhängige Rechenzentren zu verteilen. Das ist besonders wegen der Service Level Agreements (SLA) von Bedeutung, denn ein attraktives SLA lässt sich mit einer einzelnen Verfügbarkeitszone kaum garantieren.
Passende Hardware
Die schönste Infrastruktur ist nichts wert ohne die in ihr verwendete Hardware. Das ist insofern eine Herausforderung, als Open Stack an Hardware ganz unterschiedliche Anforderungen stellt. Am besten teilen Admins die benötigten Rechner in mehrere Gruppen ein.
Die erste Gruppe umfasst Server, auf denen Controllerdienste laufen. Dazu gehören alle Open-Stack-APIs sowie die Steuerkomponenten der SDN- und SDS-Umgebungen. Solche Server benötigen nicht viele, aber hochwertige Platten, die sich zehnmal am Tag komplett überschreiben lassen sollten (10 Drive Writes per Day, DWPD). Hinzu kommen die Hypervisor-Knoten, auf denen virtuelle Maschinen laufen: Sie brauchen viel CPU und RAM, die Speichermedien sind unwichtig.
Wichtig ist aber, ob das geplante Setup Storage und Computing im selben Knoten vereinen soll (man spricht von hyperconverged). Wer sich für Ceph entscheidet, sollte separate Storage-Knoten vorsehen, die mit entsprechend vielen Festplatten oder SSDs und einer dicken Anbindung an das lokale Netzwerk ausgestattet sind. CPU und RAM spielen dagegen nur eine untergeordnete Rolle.
Schließlich gibt es kleine Server, die Hilfsaufgaben erledigen, etwa Load Balancer, für die keine großen Kisten nötig sind. Die typischen Pizzaboxen genügen in der Regel, jedoch sollten sie mit schnellen Netzwerkkarten ausgestattet sein.
Baukastenprinzip
Grundsätzlich lautet die Empfehlung, eine Basis-Spezifikation für alle Server festzulegen. In der sollte stehen, welche Gehäuse zum Einsatz kommen, welche CPU- und RAM-Konfiguration gewünscht ist und welche Festplatten sowie SSD-Modelle verwendet werden dürfen. Eine solche Spezifikation ermöglicht es, sich die benötigten Server nach dem Baukastenprinzip zusammenzustellen und entsprechende Angebote einzuholen. Aber Achtung: Eine solche Basis-Spezifikation sollte auch Eventualitäten berücksichtigen und den Händlern in strittigen Punkten klare Vorgaben machen.
Wer sein Setup etwa auf UEFI aufbauen möchte, braucht bei den Netzwerkkarten womöglich eine andere Firmware als die, die der Hersteller standardmäßig installiert. Wer den Händler dazu verpflichtet, die Server gleich mit passender Firmware für alle Geräte zu liefern, spart sich viel Arbeit. Ein gutes Beispiel sind die Connectx-Karten von Mellanox (Abbildung 2): Die können ab Werk nur PXE. Zwar stellt Mellanox auch andere Firmware bereit, doch wer pro Server zwei Karten mit der neuen Firmware versehen muss, sollte dafür mindestens 20 Minuten pro System planen. Bei 50 Servern kommt einiges an Zeit zusammen.

Abbildung 2: Ist auf Karten wie hier bei der Mellanox ConnectX-4 eine spezielle Firmware für spezifische Features nötig, sollte der Hersteller die Karten mit der richtigen Firmware ausliefern.
Besonders wichtig ist das Thema Storage: Wer eine SDS nutzt, will meist keine Raid-Controller, sondern normale HBAs. Es ist sinnvoll, sich ein von Linux gut unterstütztes Modell zu suchen und das in die Spezifikation aufzunehmen. Die sollte auch klarstellen, dass Hacks wie SAS-Expander-Backplanes ausgeschlossen sind. Viele schnelle SAS- oder SATA-Platten oder SSDs helfen in Storage-Knoten nicht weiter, wenn sie über eine schmale Leitung mit ihrem Controller verbunden sind. Für Storage-Knoten ist es ideal, wenn jede Platte direkt an einem Port am Controller hängt, auch wenn das zusätzliche HBAs benötigt.
Vorlaufzeit einplanen
Ein weiterer offensichtlicher Vorteil einer fertigen Hardware-Spezifikation ist die Tatsache, dass sich Aufträge zur Beschaffung neuer Hardware schnell beim Lieferanten eintüten lassen. Das Einplanen von Vorlaufzeit ist hier sehr wichtig: In Clouds kommt es durchaus vor, dass der Anbieter von einem Tag auf den anderen viel mehr Hardware braucht, etwa weil ein großer Kunde sich auf der Plattform einbucht. Selbst wenn der Hardwarelieferant alle Komponenten vorrätig hat, nehmen Auslieferung und Installation einige Zeit in Anspruch. Da ist es umso wichtiger, dass zumindest schnell klar ist, welche Hardware man braucht.
Keine Cloud ohne Netz
Wenn die Themen Hardware und Infrastruktur erfolgreich abgehandelt sind, sieht der Open-Stack-Planer sich mit dem ersten wirklich unappetitlichen Thema konfrontiert: dem Software Defined Networking. In herkömmlichen Setups, wo Virtualisierung im Vordergrund steht, haben Anbieter sich bisher mit eher hässlichen Hacks beholfen: Sie hantierten etwa mit VLANs auf der Hardware-Ebene und schlossen virtuelle Maschinen dann über Bridges an die entsprechenden Interfaces auf der Host-Ebene an.
Dieses Prinzip funktioniert in Clouds nicht mehr. Schmerzhaft offenbart sich das bei Public Clouds. Hier ist es undenkbar, dass die Admins des Anbieters auf Kundenzuruf VLANs anlegen und dann ihr eigenes virtuelles Netz in der Cloud nutzen. Das Zauberwort bei Clouds heißt Decoupling, also Entkopplung. Entkoppelt wird die Netzwerkhardware des Setups von ihrer Software. Das physische Netzwerksetup ist vollständig flach, VLANs und ähnliche Mechanismen sucht man vergeblich. Das oben kurz beschriebene Setup auf Basis von Layer-3-Routing geht in dieselbe Richtung.
An die Stelle der Hardwarefunktionen tritt Software: SDN-Lösungen sind Teil des Setups und konfigurieren im Hintergrund VxLANs oder GRE-Tunnel so, dass VMs unterschiedlicher Kunden auf denselben Servern laufen können, ohne den Traffic des jeweils anderen jemals zu sehen. Die Cloudkunden klicken sich per Webinterface ihre komplette virtuelle Netzwerktopologie so zusammen, wie sie sie brauchen. Für den Anbieter entsteht kein zusätzlicher Aufwand nach dem erstmaligen Aufsetzen des Setups.
Open Vswitch als Standard
In den ersten beiden Artikeln des Open-Stack-Workshops fand das Thema SDN deshalb keine explizite Erwähnung, weil es beim vorgestellten Juju-MaaS-Setup mit aus der Tüte fällt. Open Stack Neutron, das auf der Open-Stack-Seite SDN-Netze verwaltet, setzt in der Standardkonfiguration auf Open Vswitch.
Das Problem dieses Ansatzes ist, dass seine Performance sehr schlecht ist. Weil es im typischen Open-Vswitch-Setup keine zentrale Schaltstelle gibt, fällt viel Overhead-Traffic zwischen den einzelnen Netzwerkknoten an, etwa beim ARP-Protokoll. Für kleine Setups wie das im zweiten Workshop-Teil ist der Ansatz ausreichend, doch für große Umgebungen entsteht daraus ein Problem – oft schon bei mehr als 20 Knoten.
Diverse Anbieter aus dem Open-Stack-Dunstkreis haben das Problem erkannt und bieten Alternativen an. Die vorhandenen Lösungen unterteilen sich grob in zwei Kategorien: Die meisten Ansätze bauen auf Open Vswitch, erweitern es allerdings um zusätzliche Komponenten, um seine Defizite auszugleichen. Dem stehen komplett eigenständige Lösungen gegenüber, allen voran Open Contrail [2] von Juniper.
Viele Fragezeichen
Der technisch eleganteste Ansatz ist dabei zweifellos Open Contrail. Es setzt auf offene, standardisierte Protokolle wie BGP und MPLS und ermöglicht so in der Theorie ein reibungsloses und gut in Open Stack integriertes SDN. In der Praxis scheitert Open Contrail allerdings an seiner enormen Komplexität. Frühere Open-Contrail-Versionen haben sich zudem in Sachen Stabilität nicht mit Ruhm bekleckert. Schließlich lässt sich Contrail längst nicht mit jeder Open-Stack-Cloud nutzen, weil es hohe Anforderungen an das Setup stellt und nötige Pakete längst nicht für alle gängigen Distributionen verfügbar sind.
Wer aktuell eine Open-Stack-Cloud baut, landet also sehr wahrscheinlich bei einer Lösung auf Open-Vswitch-Basis. Die schlechte Nachricht dabei ist, dass eine eindeutige Empfehlung für ein Produkt schlicht unmöglich ist. Die Auswahl ist groß: Midonet ([3], Abbildung 3) von Midokura oder NSX [4] von VMware buhlen neben diversen anderen Produkten um die Gunst der Admins. Am Ende bleibt diesen nur übrig, verschiedene Lösungen zu evaluieren und sich unter Einbeziehung aller Faktoren für eine zu entscheiden.
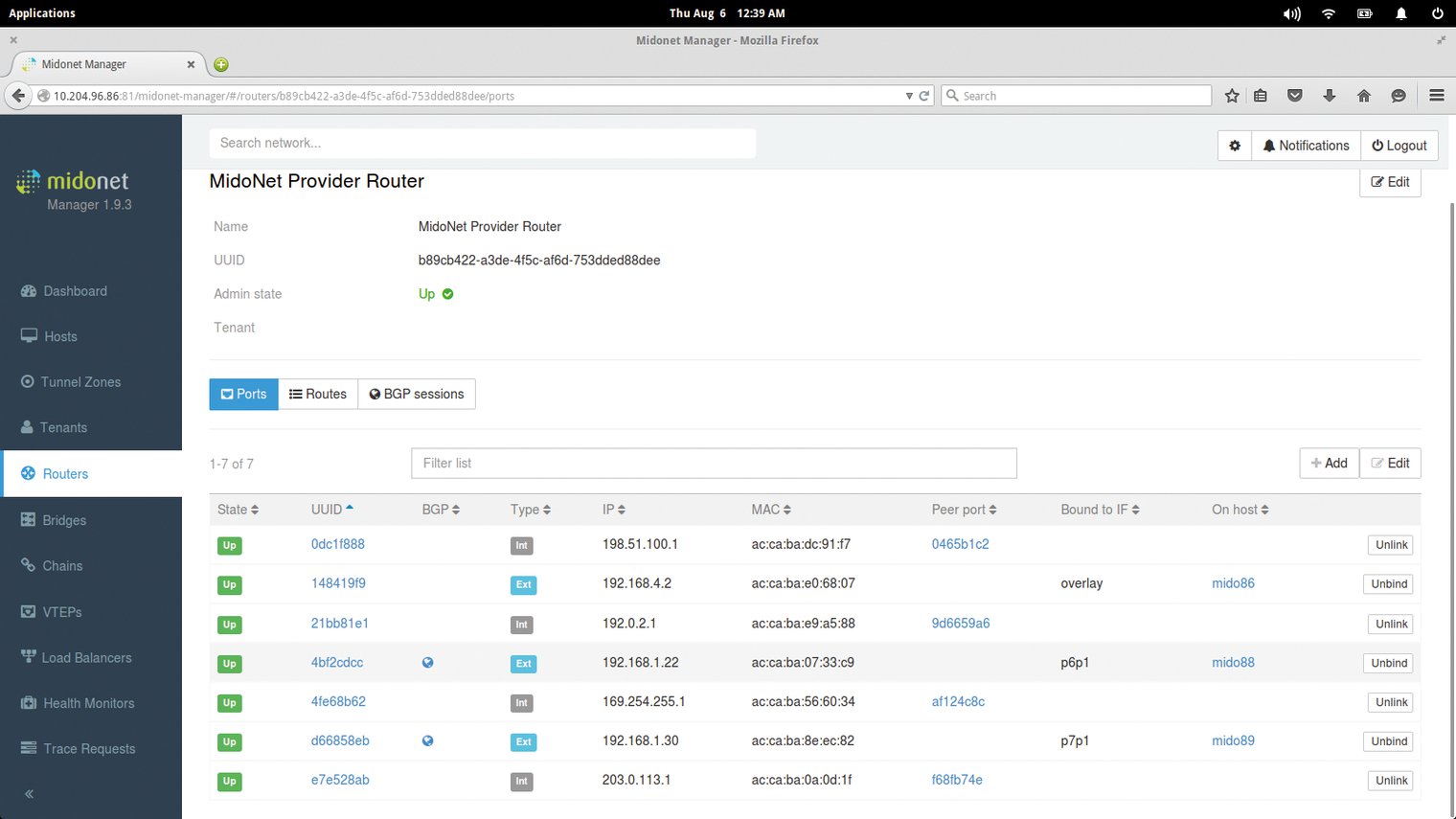
Abbildung 3: Midonet von Midokura ist eine auf Open Vswitch basierende SDN-Lösung, die sich gut in Open Stack integriert.
Wichtig ist etwa die Frage, ob sich eine SDN-Lösung ohne Probleme in das vorgesehene Deployment-Szenario einfügt. Auch die gebotenen Features spielen eine Rolle, hier tun sich zum Teil große Unterschiede auf. Faktoren wie Stabilität und die Möglichkeit, von einer Major-Version der SDN-Lösung auf eine andere zu aktualisieren, tragen ebenfalls ihr Scherflein bei. Last but not least ist auch der Preis wichtig: Fast alle prominenten SDN-Lösungen kosten Geld und belasten das Budget. Zusätzlich zu allen genannten Gründen sollten Admins also auch deshalb genug Zeit für die SDN-Evaluation einplanen, um nicht die sprichwörtliche Katze im Sack zu kaufen.
Welche Tragweite die Entscheidung für eine bestimmte SDN-Umgebung hat, ist daran erkennbar, dass sich in einer laufenden Open-Stack-Umgebung das SDN de facto nicht austauschen lässt. Lösungen wie Midonet, NSX oder Plumgrid legen ihre Konfiguration in einem jeweils eigenen Format meist in einer eigens für diesen Zweck laufenden Datenbank ab, die die anderen Dienste nicht auslesen können. Wer also einmal Midonet ausgerollt hat, muss damit leben – oder die Cloud auf Basis einer anderen SDN-Umgebung neu bauen und in Kauf nehmen, dass die gesamte Netzwerkkonfiguration der Kunden dabei verloren geht.
Weniger problematisch: SDS
Wie das Netzwerk-Thema stellt auch das Speicher-Thema Admins in Clouds vor neue Herausforderungen. In konventionellen Setups ist es ja durchaus üblich, einen zentralen Speicher zu haben, der per NFS, I-SCSI oder Fibre Channel an den Rest der Installation angebunden ist. Gegen diese Vorgehensweise spricht in Clouds eigentlich auch nichts – bis auf die Tatsache, dass solche typischen Netzwerkspeicher meist mehr schlecht als recht skalieren und mit einem großen Preisschild daherkommen.
Hinzu kommt, dass in Clouds zusätzlich zum Speicher für VMs meist ein zweiter Storage-Dienst gewünscht ist, nämlich das Speichern von binären Objekten (Object Storage). Dafür stehen zumindest zwei Protokolle bereit, nämlich Open Stack Swift und diverse Nachbauten von Amazons S3. Aus Admin-Sicht ist es wünschenswert, beide Speicherarten – den für VMs und den für Objekte – aus demselben Speicherdienst heraus zu bedienen. Zumindest den Objektspeicher bieten typische SANs nicht an. Es muss also eine andere Lösung her.
Anders als in Sachen SDN hat sich in den vergangenen Jahren hier allerdings ein De-facto-Standard etabliert: Ceph [5] dominiert die großen Open-Stack-Clouds in praktisch jeder Hinsicht. Red Hat hat in den vergangenen Jahren viel getan, um die Lösung bekannt und beliebt zu machen: Neben zahlreichen neuen Features hat sich auch in Sachen Stabilität einiges getan.
Hinzu kommt, dass Ceph wirklich sehr vielseitig ist: Über die RBD-Schnittstelle fungiert es dank nativer Anbindung an Open Stack als Backend-Speicher für virtuelle Maschinen. Mit Hilfe des Rados-Gateways, das mittlerweile Ceph Object Gateway heißt, liefert es per HTTP(S) binäre Objekte nach dem Amazon-S3- oder Open-Stack-Swift-Protokoll. Und seit Red Hat die Featureliste von Ceph-FS zusammengekürzt hat, steht sogar das Posix-kompatible Dateisystem als Quasi-Ersatz für NFS zur Verfügung.
Nahtlos skalierbar
Seinen größten Vorteil bietet Ceph bis heute in der Möglichkeit, einen Cluster während des laufenden Betriebs praktisch beliebig zu skalieren. Wenn der Platz ausgeht, stellt der Admin einfach eine passende Anzahl zusätzlicher Server dazu, sodass wieder Luft nach oben gegeben ist.
Weil Ceph mittlerweile auch Erasure Coding beherrscht, gilt die alte Regel “Brutto durch drei gleich Netto” auch nicht mehr: Der Overhead, der für Replikation draufgeht, lässt sich mit Erasure Coding erheblich reduzieren. Wer Erasure Coding nutzt, geht aber einen Kompromiss ein: Das Recovery ausgefallener Knoten dauert deutlich länger und belastet deutlich stärker die CPU und den vorhandenen RAM der Storage-Knoten.
Der größte Vorteil von Ceph ist aber zweifellos, dass Red Hat die Software kostenfrei und für verschiedene Distributionen vorbereitet zur Verfügung stellt. Auf üblichen Ubuntu-Systemen lassen sich die Pakete also direkt vom Hersteller installieren und nutzen. Wie schon im zweiten Teil des Workshops erläutert, beherrscht Ubuntus Autopilot auf Basis von MaaS und Juju das Ceph-Deployment sogar ab Werk: Wählt der Admin im Autopilot Ceph aus und weist anschließend den passenden Rechnern die Ceph-Rollen zu, so erhält er am Ende des Setups einen lauffähigen Ceph-Cluster, der direkt passend mit seiner Open-Stack-Installation verbunden ist (Abbildung 4).
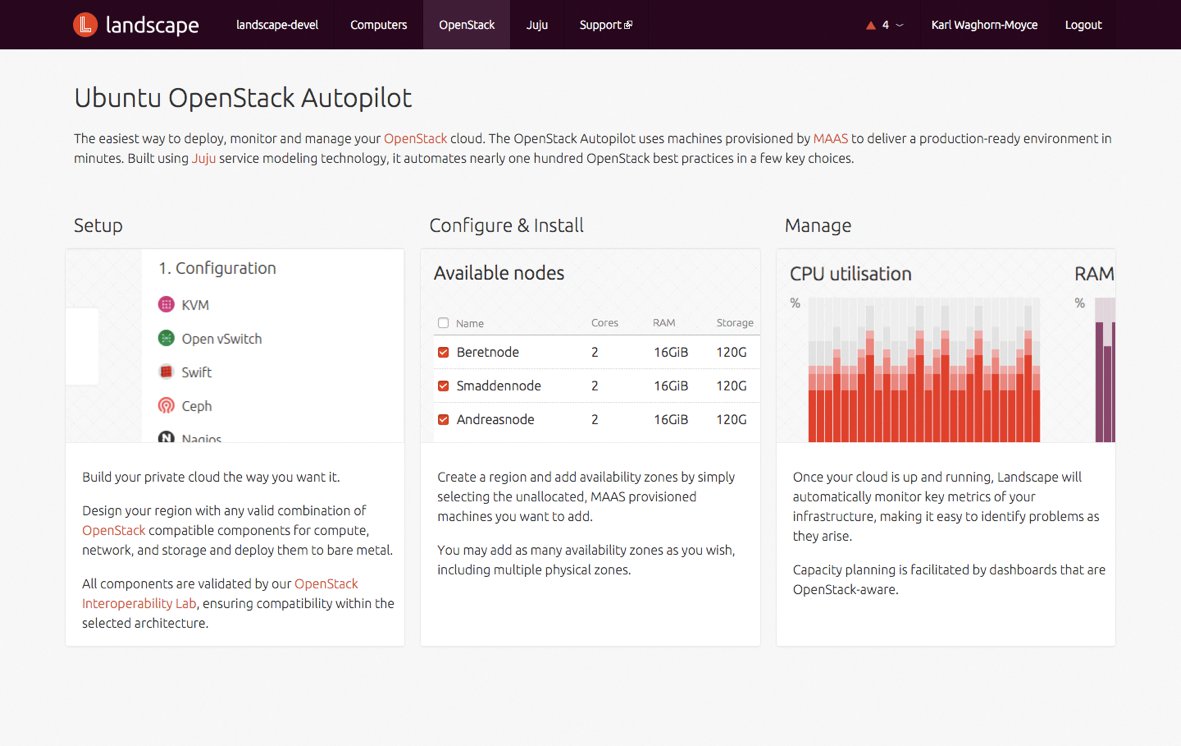
Abbildung 4: Ubuntus Autopilot ist auf Ceph ausgelegt und installiert einen kompletten Ceph-Cluster auf Mausklick. Extra Installationsarbeiten für den Speicher sind unnötig.
Tipps & Tricks für Ceph
Wer ein Open Stack aufbauen will, tut also gut daran, sich zunächst mit Ceph zufriedenzugeben. Denn die Lösung deckt den größten Teil der alltäglichen Bedürfnisse ab. Zumal sich durch richtige Handhabung durchaus noch einiges an Ceph optimieren lässt: Der Klassiker besteht etwa darin, die Journale der einzelnen Festplatten in Ceph – im Ceph-Sprech OSD genannt, das steht für Object Storage Device – auf schnelle SSDs zu legen. Das bringt bei Schreibvorgängen auf den Cluster einiges an Performance und verringert die für den Schreibvorgang benötigte Zeit – also die Latenz – beträchtlich.
Auch auf die bereits im Hardware-Abschnitt erwähnten Faktoren sei nochmals hingewiesen: Ceph eignet sich kaum für den Betrieb in einem Hyperconverged-System, denn die Storage-Knoten sollten eigenständig sein. Und sie sollten über potente Netzwerkpfade mit den Open-Stack-Knoten sprechen können, sodass der Ausfall eines Knotens und der daraus resultierende Netzwerktraffic das Netz nicht verstopfen.
Viele Admins nutzen für ihre Ceph-Cluster eigene Server für die MONs, also die Monitoring-Server – jene Wachhunde, die den Cluster überwachen und dessen Quorum erzwingen. Das ist nicht unbedingt nötig: Die MONs beanspruchen fast keine Ressourcen, sodass sie auf den OSD-Knoten mitlaufen können. Hier ist es also durchaus möglich, ein bisschen Geld zu sparen.
Sparen sollte man hingegen nicht bei der Bestückung des Clusters mit Platten. Viele Admins erliegen der Versuchung, statt Carrier-Grade-SATA- oder SAS-Platten die günstigeren Consumer-Geräte zu nutzen. Das kann sich im Alltag als Stolperstein entpuppen, denn die Consumer-Platten unterscheiden sich von ihren Enterprise-Kollegen gerade durch ihr Fehlerverhalten.
Eine sterbende Consumer-Platte versucht so lange wie möglich zu funktionieren, während sich eine Enterprise-Platte bei erheblicher Fehlfunktion selbst für tot erklärt und den Dienst gleich komplett verweigert. In einem Ceph-Cluster wünscht der Admin sich letzteres Verhalten: Nur wenn eine Platte hart ausfällt, merkt Ceph den Defekt und setzt die vielen Redundanz-Maßnahmen in Kraft. Eine Platte, die hingegen nur ein bisschen kaputt ist, sorgt im schlimmsten Fall für hängende Schreibvorgänge und erschwert auch die Fehlersuche beträchtlich.
In Sachen Ceph und Open Stack ist schließlich durchaus nicht alles Gold, was glänzt. Denn die Kombination hat auch technische Probleme: Wer etwa eine Datenbank in einer VM auf Ceph laufen lässt, kann mit der Performance des Konstrukts kaum zufrieden sein. Der Ceph zugrunde liegende Crush-Algorithmus ist ausgesprochen latenzlastig und kleine Datenbank-Writes machen das leider überdeutlich.
Umgehen lässt sich das Problem nur, indem der Admin für Datenbanken Alternativen zu Ceph anbietet, etwa lokalen Speicher oder per FC angebundenen lokalen Speicher. Ein solches Setup würde allerdings einen eigenen Artikel rechtfertigen, sodass hier nur der Verweis auf entsprechende Ansätze möglich ist.
Hochverfügbarkeit ist auch bei Open Stack wichtig
Am Schluss des Open-Stack-Workshops steht ein Thema, das den meisten Admins aus der Vergangenheit bestens bekannt sein dürfte. Denn Hochverfügbarkeit spielt in praktisch jedem IT-Setup eine bedeutende Rolle. Redundanz kam in den drei Workshop-Teilen bereits mehrfach zur Sprache – kein Wunder: Viele Komponenten einer klassischen Open-Stack-Umgebung sind implizit hochverfügbar. Ceph etwa kümmert sich um das HA-Thema selbst. Hier müssen tatsächlich mehrere Komponenten gleichzeitig ausfallen, damit es zur Beeinträchtigung des Dienstes kommt.
Nicht ganz so eindeutig ist das Thema SDN: Ob und wie gut der SDN-Layer das Thema HA beherrscht, hängt maßgeblich von der gewählten Lösung ab. Praktisch alle SDN-Stacks beherrschen aber zumindest grundsätzliche HA-Features und fangen etwa den Ausfall eines Gateway-Knotens ab. Sie verschieben dann die dem ausgefallenen Knoten zugewiesenen Netzwerke auf andere Knoten.
Also alles super in Sachen HA? Leider nicht ganz. Denn auch die Dienste, die Open Stack selbst ausmachen, brauchen natürlich eine hohe Verfügbarkeit. Mittlerweile sind die meisten Open-Stack-Dienste so gebaut, dass es von ihnen mehrere Instanzen im Cluster geben kann. Bei einer zentralen Komponente funktioniert dies aber nicht: Die API-Dienste sind zwar mehrmals startbar, aber aus Client-Sicht ist es schlicht unmöglich, mit vielen IP-Adressen zu hantieren. Hier ist der übliche Ansatz, vor die API-Dienste einen Load Balancer zu klemmen, der eingehende Anfragen auf seine verschiedenen Backends verteilt. Freilich muss auch der hochverfügbar sein: Wenn es sich um normale Linux-Rechner handelt, bietet ein Clustermanager wie Pacemaker einen validen Ansatz. Bei kommerziellen Produkten verraten deren Handbücher, wie Hochverfügbarkeit funktionieren kann.
MySQL & Rabbit MQ
Nicht zu vergessen sind in Sachen Hochverfügbarkeit auch MySQL und Rabbit MQ. Die sind zwar nicht direkt Teil von Open Stack, aber trotzdem wichtige Teile praktisch jeder Open-Stack-Installation. Bei MySQL lässt sich HA entweder per Clustersetup und einem speziellen Load Balancer wie Max Scale (Abbildung 5), per MySQL Group Replication (neues Feature ab Version 5.5) oder mittels Galera und dem in diese Lösung integrierten Clustering erreichen.
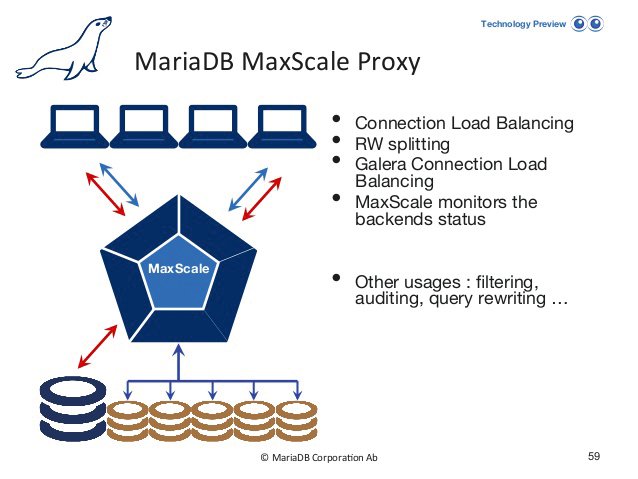
Abbildung 5: HA für MySQL lässt sich mit einem Load Balancer wie Max Scale und einer Cluster-Lösung wie Galera erreichen.
Bei Rabbit MQ sieht die Sache weniger rosig aus: Der Dienst hat zwar einen Clustermodus, doch der hat sich bei verschiedenen Gelegenheiten als unzuverlässig erwiesen. Als Alternative zu Rabbit MQ käme Qpid in Frage, der selbst jedoch auch keine überzeugendere HA-Story bietet. In Sachen AMQP ist es zumindest eingangs sinnvoller, den jeweiligen Dienst – meist also Rabbit MQ – zu überwachen und auf Basis eines entsprechenden Monitoring-Alarms den Admin ausrücken zu lassen.
Alternativ lässt sich ein entsprechendes HA-Setup auch über eine Service-IP und Pacemaker realisieren – auch wenn der Admin sich dabei in Form von Pacemaker zusätzliche Komplexität einhandelt.
HA für VMs
Einer der großen Kritikpunkte, die in Bezug auf Open Stack immer wieder aufs Tapet kommen, ist die fehlende Möglichkeit, auf Open-Stack-Ebene VMs hochverfügbar auszulegen. Anders formuliert: Der Ausfall eines Hypervisor-Knotens veranlasst Open Stack nicht automatisch dazu, die VM auf einem anderen Host neu zu starten.
Das liegt aber nicht daran, dass die Open-Stack-Entwickler nicht in der Lage wären, entsprechende Funktionalität zu implementieren. Sie verfolgen in diesem Fall aber einen anderen Ansatz und verweisen darauf, dass eine virtuelle Umgebung in Open Stack so konstruiert sein muss, dass sie den Ausfall einzelner VMs verkraftet, ohne selbst kaputtzugehen. Letztlich ist die Diskussion also eher eine ideologische und keine technische. Trotzdem sollten Nutzer das aber im Hinterkopf behalten.
Fazit
Am Ende des Open-Stack-Workshops ist klar: Es ist nicht sonderlich schwer, sich einen ersten Überblick über die Open-Stack-Komponenten zu verschaffen. Es ist auch nicht kompliziert, eine kleine Open-Stack-Umgebung auf Basis von MaaS und Juju oder anderen Hilfswerkzeugen aufzusetzen. Eine wirkliche Herausforderung ist es aber, Open Stack im Rechenzentrum so zu konfigurieren und zu betreiben, dass sich für Anbieter und Kunden ein nachweislicher Mehrwert ergibt.
Zentrale Fragen bezüglich des Deployments, der genutzten Open-Stack-Distribution, der SDN- und SDS-Tools und alltäglicher Wartungsaufgaben sind schon während der Planung der Plattform zu stellen und zu beantworten. Im laufenden Betrieb ist das später nur noch eingeschränkt oder gar nicht mehr möglich. Die anfangs investierte Mühe zahlt sich jedoch später aus: Ein Open Stack, das einmal läuft, ermöglicht die Betreuung vieler Kunden ohne den Aufwand, den dies außerhalb einer Cloud hervorrufen würde. Der Weg ist also zwar lang und steinig, am Ende lockt aber ein echter Mehrwert.
Infos
- Konstantin Agouros, “Onie und Cumulus Linux auf dem Switch”: Linux-Magazin 04/15, S. 70
- Open Contrail: http://www.opencontrail.org
- Midonet: http://www.midokura.com/midonet/
- NSX: http://www.vmware.com/products/nsx.html
- Ceph: http://www.ceph.com





