
© LEE SERENETHOS, 123RF
Trove bietet DBaaS für Open Stack. Allerdings erreicht der Service sein Optimum nicht vollautomatisch, gründliche Überlegungen für eine zweckgerichtete Konfiguration muss der Anwender beisteuern.
Im Fahrwasser des Cloud Computing und unter Führung von Amazon gehen seit einigen Jahren diverse As-a-Service-Dienste traditionellen IT-Setups an den Kragen. Die Idee dahinter ist simpel: Viele Infrastruktur-Komponenten, etwa Datenbanken, VPNs oder Load Balancer stellen für Unternehmen lediglich ein Mittel zum Zweck dar. Braucht die eigene Webapplikation etwa eine Stelle, an der sie ihre eigenen Metadaten ablegen kann, kommt dafür in der Regel eine Datenbank zum Einsatz.
Das Unternehmen, das die Applikation betreibt, hat aber kein Interesse daran, sich mit Datenbanken tiefgehend zu beschäftigen. Auch eine Datenbank, die nur Mittel zum Zweck ist, verursacht für den Kunden nämlich einigen Aufwand: Ein eigener Server oder zumindest eine eigene VM samt Betriebssystem sind aufzusetzen und zu konfigurieren. Darin ist die Datenbank – in vielen Fällen MySQL – zu installieren. Themen wie Hochverfügbarkeit erhöhen die Komplexität weiter. Dabei würde es genügen, wenn die Datenbank zur Verfügung steht und ein Login sowie eine Adresse bekannt ist, sodass die Applikation sich mit der Datenbank verbinden kann.
Solche Bedürfnisse bedienen die AaS-Dienste, im Beispiel DBaaS. Ihr Vorteil ist, dass sie das Deployment sowie die Wartung der entsprechenden Infrastruktur radikal vereinfachen. Mit DBaaS, so das Versprechen, gehören solche Überlegungen der Vergangenheit an: Der Kunde klickt im Webinterface einfach auf den Knopf für eine neue DB, die kurz darauf fertig konfiguriert verfügbar ist. Redundanz und Monitoring fallen mit aus der Tüte, der Anbieter hat das in entsprechender Vorarbeit sichergestellt.
Für Open Stack existiert eine DBaaS-Komponente bereits seit rund drei Jahren: Sie hört auf den Namen Trove und war im Linux-Magazin bereits ausführlich Thema [1]. Es ist auch gar nicht schwierig, Trove in ein bestehendes Open Stack einzubauen. Der Haken an der Sache: Trove allein macht Admins kaum glücklich. Wer sich ausführlich mit dem Thema Datenbank beschäftigt, merkt schnell, dass Anbieter, Nutzer und DBAs Hand in Hand arbeiten müssen, um aus Trove in Open Stack einen sinnvoll zu nutzenden Dienst zu machen.
Dieser Artikel beschäftigt sich mit den größten Herausforderungen, die der Betrieb und die Nutzung von Trove für alle Beteiligten hervorrufen. Open-Stack-Anbieter erfahren mehr über die großen Stolpersteine im Umgang mit Trove, Cloudanwender bekommen Tipps für den richtigen Umgang mit Trove im Alltag.
Performance
Den Anfang macht ein Thema, das besonders Cloudanbietern regelmäßig Kopfschmerzen bereitet – die Performance bei Datenbanken in der Cloud. Der Grund liegt auf der Hand: Während Datenbanken in konventionellen Setups regelmäßig auf eigener Hardware beheimatet sind, teilen sie sich in der Cloud dieselbe Hardware mit vielen anderen VMs.
Das ist aber noch nicht die größte Herausforderung, denn das Thema Storage spielt hier eine noch größere Rolle. Eine Datenbank, etwa MySQL, die auf echtem Blech läuft, braucht sich meist keine Gedanken über die Performance der Anbindung an ihren lokalen Storage zu machen. Denn meist handelt es sich um eine Festplatte im selben Rechner oder um eine schnelle SSD. Aber virtuelle Maschinen, die in Clouds laufen, haben in der Regel keinen lokalen Storage. Stattdessen nutzen sie Volumes, die im Hintergrund auf einen Netzwerkspeicher zugreifen.
Typisches Beispiel ist Ceph als Storage-Backend für Open Stack. Dabei führt jeder Schreibvorgang in einer VM zu mehreren Netzwerkzugriffen. Einerseits sendet der Ceph-Client auf dem Virtualisierungshost den von der VM zu ihm durchgereichten Write an das primäre Storage-Gerät des Ceph-Clusters, im Ceph-Sprech also zu seinem primären OSD (Object Storage Device, Abbildung 1). Andererseits sendet dieses primäre OSD im zweiten Schritt dieselben Daten an so viele andere OSDs, wie die Policy in Sachen Replikation vorgibt.
Abbildung 1: Ceph repliziert im Hintergrund Daten und liefert erst dann ein Okay für den Schreibvorgang an den Client, wenn genügend Replikate vorhanden sind.
Erst wenn genügend Replikate der Information im Ceph-Cluster angelegt sind, sendet der Ceph-Client der auf ihm laufenden VM die Bestätigung, dass der Schreibzugriff erfolgreich war. Der DB-Client, der ursprünglich nur einen einzelnen Eintrag in MySQL ändern wollte, wartet also mehrere Netzwerk-Roundtrips lang, bis diese Operation erfolgreich beendet ist.
Das ist keineswegs Ceph-spezifisch: Praktisch alle Lösungen für verteiltes Speichern in Clouds haben ein ähnliches Problem. Ceph sticht nur als besonders negatives Beispiel heraus, denn der Crush-Algorithmus (Controlled Replication Under Scalable Hashing), der das primäre OSD und die sekundären OSDs errechnet, ist besonders Latenz-lastig.
Aus Anbietersicht ist das Problem ausgesprochen schwer in den Griff zu kriegen, auch weil eine untere Grenze klar definiert ist. Denn Ethernet hat eine inhärente Latenz, die zu unterbieten nur mit anderen, eher auf Latenz optimierten Transporttechniken möglich ist, zum Beispiel durch den Einsatz von Infiniband. Damit sucht sich der Anbieter jedoch eine andere Netzwerktechnik aus, die ihre eigenen Herausforderungen hat.
(Irr-)Wege
Welche Wege stehen einem Anbieter also offen, um das Thema Latenz für DBaaS in den Griff zu bekommen? Der offensichtliche Ansatz besteht darin, VMs für Datenbanken aus Trove nicht auf Netzwerkspeicher abzulegen, sondern sie mit lokalem Storage zu betreiben. Im Open-Stack-Kontext bedeutet das, dass die VM und deren Festplatte nicht in Ceph oder einem anderen Netzwerkspeicher liegen, sondern direkt auf dem lokalen Speichermedium des Compute-Knotens. Ratsam ist es in einem solchen Szenario freilich, die VM auf einem Knoten mit SSDs zu starten, weil das in Sachen Durchsatz und Latenz nochmals spürbare Performancegewinne bringt.
Der Anbieter müsste sein Open Stack dazu aber entsprechend konfigurieren: Typischerweise würde er eine eigene Availability-Zone mit schnellem lokalen Storage einrichten und Kunden dann die Möglichkeit geben, mit Trove gestartete Datenbanken dort zu beheimaten.
Was auf den ersten Blick wie eine gute Idee wirkt, entpuppt sich jedoch bei genauerem Hinsehen als Schreckensszenario. Denn natürlich gilt, dass eine so gestartete VM ohne jegliche Redundanz auskommt. Fällt der Hypervisor-Knoten mit der VM aus, ist diese schlicht nicht erreichbar. Fällt die Platte aus, auf der die VM mitsamt Datenbank liegt, sind die Daten verloren und der Anwender oder Anbieter holt sein (hoffentlich existierendes) Backup heraus.
Selbst wenn man nicht vom Horrorszenario eines Hardware-Ausfalls ausgeht, birgt diese Art des Setups mehr Gefahren als Nutzen für den Anbieter: Wenn eine VM nur lokal vorhanden ist, lässt sie sich nicht ohne Downtime auf einen anderen Host umziehen. Genau das ist im Alltag einer Cloud mit Hunderten Knoten aber nötig, weil sich die einzelnen Server sonst kaum warten lassen. Wie man es dreht und wendet: Virtuelle Maschinen, die auf lokalem Speicher der einzelnen Hypervisor-Knoten liegen, sind definitiv keine gute Idee.
Evaluation ist alles
Klar ist bei allen Nachteilen lokalen Speichers allerdings auch, dass sich mit Netzwerk-basiertem Speicher die Latenzwerte von lokalem Speicher gerade beim sequenziellen Schreiben niemals erreichen lassen. Wer MySQL auf Fusion-IO (Abbildung 2) gewohnt ist, wird praktisch immer eine unangenehme Überraschung erleben, wenn er auf eine DBaaS-Datenbank in der Cloud umsteigt.

Abbildung 2: Fusion-IO-Speicher ist mit der schnellste Speicher, der sich in Servern verbauen lässt. Wenn MySQL darauf beziehungsweise auf Ceph läuft, sind die Latenzunterschiede dramatisch.
Hier wird ein Spannungsfeld sehr deutlich, in dem Cloudanbieter sich praktisch immer bewegen: Welchen Bedarf soll das Setup eigentlich abdecken? Bevor keine belastbare Antwort auf eben diese Frage existiert, lässt sich nach einer geeigneten Storage-Lösung für Datenbanken in der Cloud kaum fahnden.
Viele – gerade kleine – Setups von Cloudkunden stellen an ihre Datenbank nur minimale Anforderungen, sodass Netzwerk-basierter Speicher völlig ausreicht. Wer große Setups mit Tausenden gleichzeitigen Datenbankzugriffen betreiben möchte, kommt an dieser Stelle womöglich bereits in Bedrängnis. Im ersten Schritt ermittelt der Anbieter deshalb seinen Bedarf, um die Grundlage für die weitere Planung zu schaffen.
Storage-Alternativen
Wer Ceph einsetzt und mit dessen Performance für Datenbanken unzufrieden ist, sollte sich zunächst nach direkten Alternativen umschauen. Viele Lösungen, etwa Quobyte [2] oder Storepool [3], werben mit deutlich geringeren Latenzen, ohne auf Ethernet zu verzichten. Und niemand muss gleich den kompletten, schon existierenden Storage ablösen. Denn die zuvor beschriebene Lösung mit einer eigenen Availability-Zone für die Knoten mit anderem Storage lässt sich in eine existierende Umgebung gut integrieren. Für den Anbieter bedeutet das aber viel Aufwand, weil er evaluieren, testen und entwickeln muss.
Es ist übrigens auch nicht so, als sei den Ceph-Entwicklern das Problem mit hoher Latenz bei Ceph nicht bewusst. Sie arbeiten bereits an einer Lösung: Blue Store soll in Zukunft alles besser machen. Der Ansatz versucht das Problem auf der Ebene der physischen Speichergeräte zu lösen. Hier setzt Ceph bisher auf XFS als Dateisystem, auf dem anschließend die binären Objekte lagern.
Ursprünglich propagierte Inktank, die Firma hinter Ceph, Btr-FS. Weil das aber nicht auf die Beine kommt, begnügte man sich irgendwann mit XFS, das für den typischen Ceph-Usecase allerdings kaum geeignet ist. Denn große Teile der Posix-Spezifikation brauchen OSDs praktisch nie; ihre Einhaltung frisst aber wertvolle Performance.
Blue Store [4] ist entsprechend ein neues Storage Backend oder On-Disk-Format für Daten, das direkt auf den einzelnen Blockspeichergeräten liegt und signifikant besser performen soll als XFS. Die nächste LTS-Version von Ceph soll Blue Store für den produktiven Einsatz unterstützen, bis dahin heißt es jedoch warten.
Wenn alle Stricke reißen
Wer mit einer alternativen Storage-Lösung auf Netzwerkbasis nicht zum Ziel kommt, landet letztlich doch wieder beim Prinzip des lokalen Speichers – sollte dann aber unbedingt dessen schlimmste Nebeneffekte lindern. Denkbar wäre beispielsweise ein Setup, bei dem einzelne Knoten zwar virtuelle Maschinen mit lokalem Speicher betreiben, der im Hintergrund jedoch repliziert wird, sodass das Umschwenken auf einen anderen Host im laufenden Betrieb dann doch problemlos machbar ist.
DRBD 9 mit seiner n-Knoten-Replikation wäre hier grundsätzlich ein guter Kandidat. Allerdings bietet der DRBD-Treiber für Open Stack Cinder aktuell nicht die Möglichkeit, ein Cinder-Volume auf genau dem Host in den Primärmodus zu schalten, auf dem die VM tatsächlich läuft. Das Ergebnis wäre deshalb, dass zwar der Zugriff auf das Storage-Gerät im Zweifelsfall funktioniert, aber die Daten kämen am Ende doch wieder über das Netzwerk.
Andere Varianten bestehen in lokal angeschlossenen Fibre-Channel-Geräten. Die können die Replikation selbst abwickeln. Ein maßgeschneidertes Setup für den Einzelfall ist jedenfalls unbedingt notwendig.
Replikation und Multi-Master-Modus
Grundsätzlich ist die Replikation in MySQL natürlich ein geeignetes Mittel, um Last auf mehrere Knoten zu verteilen und Redundanz herzustellen. Wenn allerdings die Replikation auf Datenbank-Ebene zwischen drei MySQL-Instanzen stattfindet, die im Hintergrund alle auf Ceph-Volumes schreiben, multipliziert sich der schon beschriebene Latenz-Effekt sogar noch – dieses Konstrukt ist also kein guter Ansatz.
Denkbar wäre dagegen eine Replikation auf der MySQL-Ebene, wenn sie zwischen drei VMs stattfindet, die über lokalen Speicher verfügen. Denn dann wäre die maximale Latenz fast identisch mit der Ethernet-Latenz zwischen den physischen Hosts und auf jeden Fall deutlich geringer als beim Zugriff auf verteilten Netzwerkspeicher.
Eine tatsächliche Relevanz haben Multi-Knoten-Setups in MySQL im Kontext der Lastverteilung. Das typische Master-Slave-Setup, wie es auch bei Datenbanken auf echtem Blech zum Einsatz kommt, lässt sich freilich auch in einer DBaaS-Umgebung nutzen. Und das beste ist: Trove bringt für diese Art des Setups ab Werk sogar Unterstützung mit.
Als Cluster gestartet
Ganz konkret bedeutet das, dass ein Admin beim Starten einer Datenbank mit Trove bereits festlegen kann, ob die Datenbank auf einer einzelnen VM oder in einem Clusterverbund laufen soll. Das funktioniert für sämtliche DB-Treiber in Trove, die Support für die Replikation der jeweiligen Datenbank haben, aktuell also mit Mongo DB, MySQL, Redis, Cassandra sowie einigen weiteren, nicht jedoch mit PostgreSQL.
Die Herangehensweise aus Admin-Sicht ist simpel: Im Beispiel MySQL startet der Nutzer zunächst eine einzelne MySQL-Datenbank, der er anschließend eine Slave-Datenbank zur Seite stellt. Der Trove-Agent, der in der von Trove gestarteten VM läuft, konfiguriert die Datenbank sodann automatisch um. Der Clusterverbund entsteht auf diese Weise ohne weiteres Zutun des Nutzers. Der Befehl
trove create lm-slave 1 --size 2 --slave_of ae427c76-eee3-11e6-802a-00215acd73e2
würde der Datenbank mit der ID »ae427c76-eee3-11e6-802a-00215acd73e2« einen Slave-Knoten namens »lm-slave« auf Basis des Flavor »1« hinzufügen (siehe Abbildung 3).
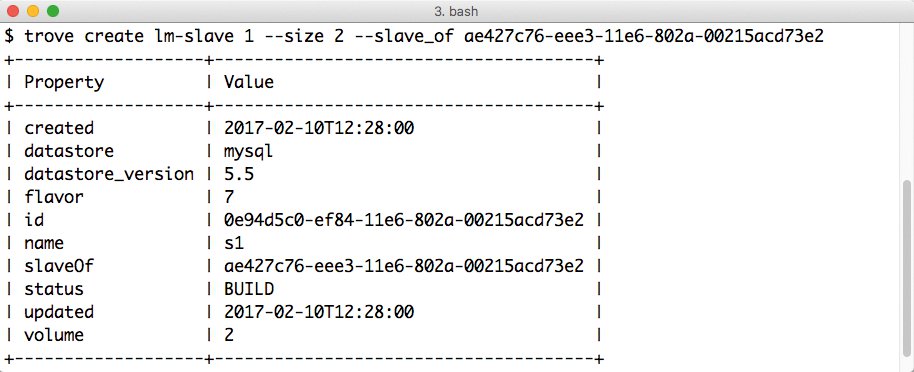
Abbildung 3: Trove kann die Clustermodi etlicher verschiedener Datenbanksysteme nutzen, darunter wie im Beispiel auch den Modus von MySQL.
Wer auf einer halbwegs aktuellen Cloud mit Open Stack Mitaka unterwegs ist, hat in Sachen Clustering bei MySQL sogar die Möglichkeit, Galera zu nutzen (siehe dazu auch den Artikel über die Replikation bei MySQL). Trove startet dann mehrere MySQL-Instanzen und bereitet sie so vor, dass in ihnen Galera eine Multi-Master-Datenbank anlegt.
Ein solches Setup lässt sich gut mit lokalem Speicher in Hypervisorknoten kombinieren: Weil die Daten dann mehrmals auf unterschiedlichen Hosts existieren, schmerzt es nicht weiter, wenn ein einzelner Host ausfällt oder zu Wartungszwecken temporär aus dem Cluster verschwindet. Allerdings repliziert Galera synchron, sodass zumindest eine einfache Netzwerklatenz entsteht, die der Client abbekommt. Die ist jedoch deutlich geringer als bei zu Ceph.
Der Umgang mit eigenen Images
Damit Trove funktionieren kann, benötigt es ein spezielles Abbild für seine virtuellen Systeme [5]. Um zu verstehen, warum das notwendig ist, ist ein kleiner Ausflug in die Trove-Architektur nötig. Im Grunde unterscheidet sich eine von Trove gestartete VM mit Datenbank nur durch einen Umstand von einer normalen VM von der Stange. Damit Trove innerhalb der VM arbeiten kann, schleust es in diese einen Helfer ein, den so genannten Trove Guest Agent. Der bekommt von außen Anweisungen und führt dann in der VM die notwendigen Schritte aus – im Beispiel zuvor etwa die MySQL-Konfiguration für den Betrieb als Cluster.
Blöd nur: Ein Standard-Ubuntu-Abbild enthält den Trove Guest Agent schlicht nicht. Admin oder Nutzer kommt deshalb die Aufgabe zu, ein entsprechend vorbereitetes Image mit Guest Agent zu bauen. Wichtig ist dabei nicht nur, dass das Abbild den Guest Agent als Programm enthält, sondern dass der auch eine passende Konfiguration hat. Dazu muss der Inhalt der Datei »/etc/trove/trove-guest-agent.conf« zu den Anforderungen des jeweiligen Setups passen, konkret etwa zur Keystone-Konfiguration.
Die gute Nachricht ist, dass das Open-Stack-eigene Standardwerkzeug für das Bauen von Nova-Images bereits für Trove angepasst ist. Auf Befehl erstellt es also ein Image, das sich in der jeweiligen Cloud des Anbieters unmittelbar nutzen lässt. Die Trove-Dokumentation enthält ein Beispiel für Ubuntu. Admins sollten das Tool allerdings auf einem Host aufrufen, auf dem für Trove bereits die erforderlichen Konfigurationsdateien so liegen, wie sie für die Cloud benötigt werden, denn nur dann landen diese korrekt im Image.
Das Trove-Projekt bietet auf Basis von Ubuntu übrigens auch fertige Images für verschiedene Datenbanken an. Sie unterscheiden sich von den offiziellen Ubuntu-Images lediglich dadurch, dass die entsprechenden Trove-Komponenten bereits integriert sind. Ganz komfortabel ist diese Lösung für die Nutzer jedoch nicht. Denn die in den fertigen Images enthaltenen Konfigurationsdateien sind natürlich zuerst einmal generisch und noch nicht an die jeweilige spezielle Cloud angepasst.
Kunden kommt daher die Aufgabe zu, beim Starten einer virtuellen Maschine mit Trove über Nova-Metadaten die zum vorliegenden Anwendungsfall passenden Konfigurationsdateien an das Abbild zu übergeben. Dazu sollte der DBaaS-Anbieter eine vollständige und ausführliche Dokumentation bereitstellen.
Wer als Anbieter seinen Kunden diese Arbeit ersparen möchte oder wer als Kunde aus speziellen Gründen auf handgeschnitzte Abbilder angewiesen ist, nutzt besser den zuvor beschriebenen Workflow und baut sich seine Images für Trove selbst.
Backups und Snapshots
Ein alltäglicher Vorgang bei der Arbeit mit Datenbanken ist das Anlegen von Snapshots oder Backups. Denn eine laufende Datenbank ist zwar nett, aber der Grat zwischen Glück und Unglück ist schmal: Daten fallen allzu oft umfassenden Löschkommandos zum Opfer. Und manchmal zerlegt sich der Inhalt der Datenbank ganz ohne das berüchtigte Fat-Fingering: Etwa bei einem Software-Update, das auch das Schema der Datenbank aktualisieren soll, was jedoch leider schiefgeht und in der Datenbank nur Müll zurücklässt. In solchen Fällen ist guter Rat teuer und ein Backup überlebenswichtig.
Die Zahl an Werkzeugen, mit denen sich verschiedene Datenbanken sichern und wiederherstellen lassen, ist fast unüberschaubar. Weil beim Einsatz von Trove der Nutzer an die virtuelle Maschine mit der Datenbank aber gar nicht rankommt, fallen einige der üblichen Verdächtigen hier schon wieder weg. Damit Anwender nicht ständig ein Damoklesschwert über sich spüren, haben die Trove-Entwickler ihrer Software deshalb eine eigene Backup-Funktion spendiert.
Der Clou dabei: Backups lassen sich von außerhalb der VM direkt über das API von Open Stack anstoßen und zentralisiert ablegen. Auch das Restore geschieht auf diesem Wege. Das folgende Beispiel demonstriert das Vorgehen auf der Basis von MySQL.
Die Backup-Datenbank
Zunächst benötigt der Nutzer die ID der Trove-Instanz, von der ein Backup anzulegen ist. Auf der Kommandozeile zeigt der Befehl »trove list« alle laufenden Trove-Instanzen des jeweiligen Nutzers. Die Einträge beim Feld »id« sind von Bedeutung. Sobald die ID der Datenbank bekannt ist, von der ein Backup anzulegen ist, führt der Befehl »trove backup-create ID backup-1« zum gewünschten Resultat (Abbildung 4). »trove backup-list« zeigt danach das angelegte Backup. Steht der Eintrag im Feld »status« auf »COMPLETED« hat alles funktioniert.
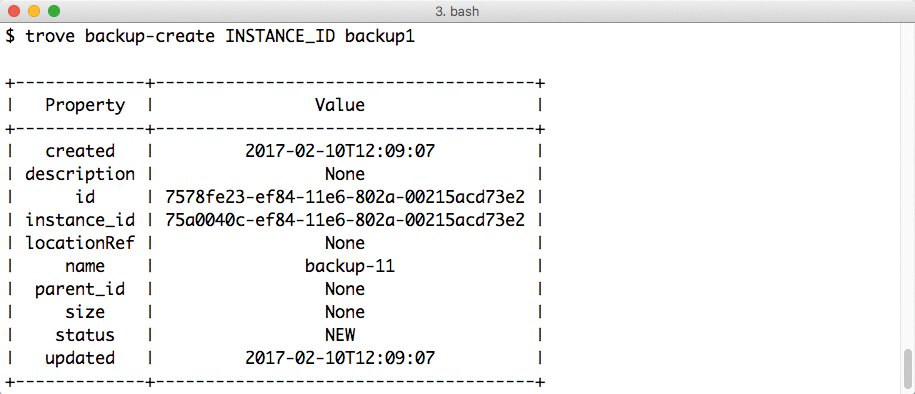
Abbildung 4: Sowohl das Anlegen eines Backups …
Für erfolgreiche Backups muss der Trove Guest Agent in der VM ordnungsgemäß konfiguriert sein. Insbesondere muss in »/etc/trove/trove-guestagent.conf« stehen, wo der Guest Agent die Backups ablegen soll. Ab Werk ist der Standard die Ablage in Open Stack Swift, dem Objektspeicher der Cloudumgebung.
Wer die Backups stattdessen an einer anderen Stelle abgelegt haben möchte, jubelt als Kunde seiner VM entweder eine modifizierte Guest-Agent-Konfiguration über die Nova-Metadaten unter oder bittet den Anbieter, ein Trove-Abbild bereitzustellen. Der Anbieter sollte hier ohnehin tätig werden und ein Trove-Abbild in Glance anbieten, das der jeweiligen Umgebung angepasst ist.
Backup wiederherstellen
“Keiner braucht Backups, alle brauchen Restore” lautet ein Bonmot, das etwas überspitzt auf Offensichtliches hinweist: Das schönste Backup ist wertlos, wenn es sich nicht richtig wiederherstellen lässt. Zum Glück haben die Trove-Entwickler das Thema Restore bedacht und bieten die Option, direkt über das Trove-API eine Datenbank wiederherzustellen (Abbildung 5). Das funktioniert aber anders, als Nutzer es aus klassischen Setups möglicherweise gewohnt sind.
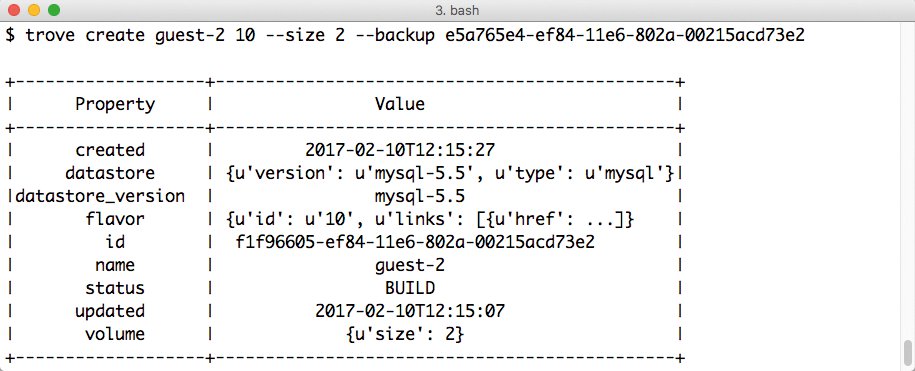
Abbildung 5: … als auch das Wiederherstellen einer Datenbank aus einem Backup sind für Trove, ist es erst einmal erfolgreich installiert und konfiguriert, leichte Übungen.
Im ersten Schritt startet der Nutzer eine komplette neue Datenbank und weist Trove an, in dieser das Backup wiederherzustellen. Im zweiten Schritt schwenkt er die (öffentliche) IP-Adresse, welche die alte Datenbank zuvor hatte, direkt auf die neue Datenbank um. Im letzten Schritt löscht der Admin die alte DB, sodass sie aus Trove komplett verschwindet. Clients bekommen dann wieder eine Verbindung zu einer Datenbank mit validen Daten, ohne dass der Nutzer an der Konfiguration seiner Komponenten irgendwas ändern müsste.
Der Befehl, um aus einem bestehenden Backup eine Datenbank zu starten, lautet zum Beispiel:
trove create guest-2 10 --size 5 --backup ID
Mittels »trove delete ID« lässt sich die alte Datenbank löschen, wenn die Migration abgeschlossen ist.
Während Backups in Trove ordentlich umgesetzt sind, sieht es bei Snapshots nicht annähernd so rosig aus: Support für sie fehlt in Trove bisher komplett. Immerhin können Admins sich mit der Snapshot-Funktion von Nova behelfen. Die erzeugt aber einen Snapshot der gesamten VM, nicht nur der Datenbank.
Fazit
Zwar lassen sich die einzelnen Trove-Komponenten in eine existierende Open-Stack-Plattform relativ simpel integrieren. Doch auf den Admin wartet auch noch ein ganzer Haufen Arbeit: Schon das Anlegen der für Trove zwingend benötigten Images ist nicht so leicht, wie man es sich als Betreiber der Plattform wünscht. Von besonderer Tragweite ist das Thema Storage: Hier tut der Betreiber gut daran, sehr genau den eigenen Bedarf zu definieren. Aus Nutzersicht macht Trove jedoch Spaß, wenn der Plattformbetreiber seine Arbeit gut macht. Das Verwalten eigener VMs für Datenbanken erleichtert Trove merklich.
Infos
-
Martin Loschwitz, “Lagerservice”: Linux-Magazin 7/2016, S. 62
-
Quobyte: https://www.quobyte.com
-
Storepool: https://StorPool.com
-
Blue Store: http://events.linuxfoundation.org/sites/events/files/slides/LinuxCon%20NA%20BlueStore.pdf
-
Guest Images für Trove: http://docs.openstack.org/developer/trove/dev/building_guest_images.html
Der Autor

Martin Gerhard Loschwitz ist Head of Cloud bei der Firma iNNOVO Cloud. Er beschäftigt sich dort bevorzugt mit den Themen Distributed Storage, Software Defined Networking und Open Stack.





