
© Ivan Smuk, 123RF
Auf Amazons Lambda-Service laufen selbst geschriebene Python-Skripte in Containerumgebungen – demonstriert im Snapshot am Beispiel eines AI-Programms zur Bewegungsanalyse in Überwachungsvideos.
Nach ersten Gehversuchen im Linux-Magazin 02/16 zum Einrichten eines AWS-Accounts, eines S3-Storage mit statischem Webserver sowie der ersten Lambda-Funktion folgt heute das Setup eines API-Servers auf Amazon zum Aufstöbern von interessanten Szenen in Videos einer Überwachungskamera.
Die per Webaufruf vom Browser oder von einem Kommandozeilentool wie »curl« getriggerte Lambda-Funktion holt dabei ein Video vom Netz, jagt es durch einen mittels Open-CV-Library implementierten AI-Algorithmus (Artificial Intelligence), erzeugt ein Bewegungsprofil und gibt die URL eines als Jpeg generierten Kontaktabzugs mit den wichtigsten Videobewegungen zurück (Abbildungen 1 und 2).
Abbildung 1: Das AI-Programm zur Bewegungsanalyse läuft auf einem Amazon-Server hinter einem REST-API.
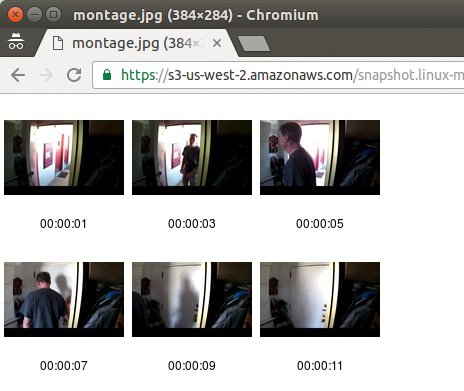
Abbildung 2: Der auf AWS erzeugte Kontaktabzug zeigt die Sekunden im Überwachungsvideo, in denen sich tatsächlich etwas bewegt hat.
Sandkastenspiele
Im Gegensatz zu Amazons EC2-Instanzen mit ihren vollblütigen (wenngleich nur virtuellen) Linux-Servern bietet der Lambda-Service [2] nur eine containerisierte Umgebung. In ihr laufen Node-JS-, Python- oder Java-Programme in einem Sandkasten, den Amazon nach Belieben zwischen echten Servern herumschubst oder bei Inaktivität ganz wegputzt, um ihn beim nächsten Zugriff wieder hervorzuzaubern. Daten auf der virtuellen Platte des Containers liegen zu lassen und zu hoffen, sie beim nächsten Aufruf vorzufinden, ergäbe also eine instabile Applikation. Stattdessen kommunizieren Lambda-Funktionen mit AWS-Angeboten wie dem S3-Storage oder der Dynamo-Datenbank, um Daten zu sichern, und agieren ansonsten “stateless”.
Was eine Applikation nicht in einem Python-Skript beschreiben kann, darf der Entwickler auch als Zip-Datei in den, so munkelt man, auf Centos basierten Container hochladen (Abbildung 3).
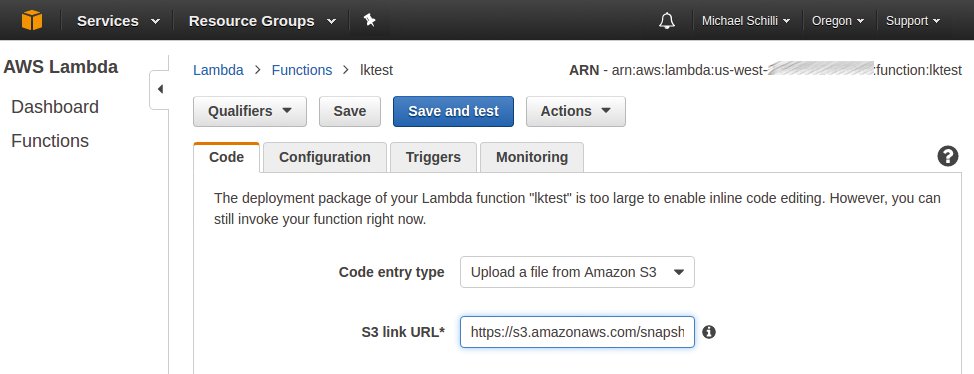
Abbildung 3: Hochladen der Zip-Datei auf den Lambda-Server über einen Amazon-S3-Bucket.
Eine Lambda-Funktion, die wie im Beispiel Artificial-Intelligence-Funktionen aus der Open-CV-Library nutzt, muss die nötigen Binaries oder Libraries vorher in einer dem Lambda-Container ähnlichen Unix-Umgebung kompilieren, verpacken, hochladen und später zur Laufzeit aus dem Python-Skript aufrufen. Dabei kommen vorhandene Python-Bindings zu Shared Libraries zum Einsatz oder das Python-Skript ruft vorkompilierte Binaries als externen Prozess auf.
Rank und schlank
Damit das AI-Programm aus [3] nach der Installation in der Amazon-Cloud nicht zu viel Rechenzeit und nach dem Überschreiten des kostenlosen Kontingents “Free Tier” auch Geld verbrät, sucht der Code in der gegenüber der vorigen Ausgabe verbesserten Version in Listing 1 nicht mehr in jedem Frame, also 50-mal pro Sekunde, nach Bewegungen, sondern hüpft in Zeile 99 in Schritten von einer halben Sekunde durch den Film. Nach einem Frame mit Bewegung springt Zeile 96 gar 2 Sekunden vorwärts. Im Gegensatz zu »vid.read()« dekodiert das in Zeile 50 aufgerufene »vid.grab()« nicht mehr aufwändig, sondern wirft ihn weg, um zum nächsten zu gelangen.
Listing 1
max-movement-lk.cpp
001 #include "opencv2/opencv.hpp"
002 #include <stdio.h>
003
004 using namespace std;
005 using namespace cv;
006
007 const int MAX_FEATURES = 500;
008 const int MAX_MOVEMENT = 100;
009
010 int move_test(Mat& oframe, Mat& frame) {
011 // Select features for optical flow
012 vector<Point2f> ofeatures;
013 goodFeaturesToTrack(oframe,
014 ofeatures, MAX_FEATURES, 0.1, 0.2 );
015
016 // Parameters for LK
017 vector<Point2f> new_features;
018 vector<uchar> status;
019 vector<float> err;
020 TermCriteria criteria(TermCriteria::COUNT
021 | TermCriteria::EPS, 20, 0.03);
022 Size window(10,10);
023 int max_level = 3;
024 int flags = 0;
025 double min_eigT = 0.004;
026
027 // Lucas-Kanade method
028 calcOpticalFlowPyrLK(oframe, frame,
029 ofeatures, new_features, status, err,
030 window, max_level, criteria, flags,
031 min_eigT );
032
033 double max_move = 0;
034 double movement = 0;
035 for(int i=0; i<ofeatures.size(); i++) {
036 Point pointA
037 (ofeatures[i].x, ofeatures[i].y);
038 Point pointB
039 (new_features[i].x, new_features[i].y);
040
041 movement = norm(pointA-pointB);
042 if(movement > max_move)
043 max_move = movement;
044 }
045 return max_move > MAX_MOVEMENT;
046 }
047
048 int frames_skip( VideoCapture vid, int n, int *i ) {
049 for( int c = 0; c < n; c++ ) {
050 if (!vid.grab())
051 break;
052 (*i)++;
053 }
054 }
055
056 int main(int argc, char *argv[]) {
057 int i = 0;
058 Mat frame;
059 Mat cframe;
060 Mat oframe;
061
062 if (argc != 2) {
063 cout << "USAGE: <cmd> <file_in>\n";
064 return -1;
065 }
066
067 VideoCapture vid(argv[1]);
068 if (!vid.isOpened()) {
069 cout << "Video corrupt\n";
070 return -1;
071 }
072
073 int fps = (int)vid.get(CV_CAP_PROP_FPS);
074
075 i++;
076 if(!vid.read(oframe)) return 1;
077
078 cvtColor(oframe, oframe, COLOR_BGR2GRAY);
079
080 while (1) {
081 if (!vid.read(frame))
082 break;
083 i++;
084
085 int movie_second = i / fps;
086
087 cframe = frame.clone();
088 cvtColor(frame,frame,COLOR_BGR2GRAY);
089 if(move_test(oframe, frame)) {
090 cout << movie_second << "\n";
091
092 char filename[80];
093 sprintf( filename, "%04d.jpg", i/fps );
094 imwrite( filename, cframe );
095
096 frames_skip( vid, 2*fps, &i );
097 } else {
098 // fast-forward to next 1/2 sec
099 frames_skip( vid, fps/2, &i );
100 }
101
102 oframe = frame;
103 }
104
105 return 0;
106 }
Und während die erste Version in [3] nur die Sekundenwerte im Video in die Ausgabe schrieb, an denen der Algorithmus Bewegungen erkannte, um nachfolgend über Tausendsassa Mplayer die zugehörigen Frames als Jpeg-Dateien zu extrahieren, schreiben die Zeilen 92 bis 94 erkannte Frames gleich mittels der Open CV beiliegenden Bildverarbeitungsfunktionen »imwrite()« im Format »0001.jpg« auf die virtuelle Festplatte. Ein zweiter Durchlauf sowie die Frickelei zur Installation von Mplayer in den Lambda-Container entfallen somit.
Aus diesen Jpeg-Bildern macht dann ein weiteres Python-Skript, »mk-montage.py«, unter Zuhilfenahme der Imagemagick-Library einen Kontaktabzug, ebenfalls im Jpeg-Format. Diese Datei legt das Lambda-Programm in Amazons S3-Cloud-Speicher ab und schickt dann einen Link darauf an den aufrufenden Client zurück.
RAM ist Geld
Wie holt ein Python-Programmierer nun ein Dokument vom Web? Ein erster Ansatz wäre die Methode »read()« nach einem »urlopen()«, die alle so eingeholten Bytes gleich wieder mittels »write()« in eine lokale Datei schreibt. Aber das hätte zur Folge, dass eine eventuell große Videodatei komplett in den Arbeitsspeicher gelesen würde, bevor Python sie dann auf die Platte schreibt.
Die damit nötige üppige Versorgung mit RAM kostet aber Geld auf Amazon, also verwendet Listing 2 die Methode »urlretrieve()« aus dem Modul »urllib«, die – hoffentlich mehr oder weniger intelligent – stückweise puffern kann.
Listing 2
vimo.py
01 #!/usr/bin/python
02 import urllib
03 import tempfile
04 import shutil
05 import subprocess
06 import boto3
07 import os
08
09 def lambda_handler(event, context):
10 tmpd = tempfile.mkdtemp()
11
12 # fetch movie
13 movie_url = event['movie_url']
14 movie_file = os.path.join(tmpd,
15 os.path.basename(movie_url))
16 urllib.urlretrieve(movie_url,movie_file)
17
18 # motion analysis
19 print subprocess.check_output([
20 "bin/max-movement-lk.py",
21 movie_file])
22
23 # generate montage
24 print subprocess.check_output([
25 "bin/mk-montage.py",tmpd])
26
27 # store montage in s3
28 s3 = boto3.resource('s3')
29 bucket = "snapshot.linux-magazin.de"
30 data = open(os.path.join(
31 tmpd,'montage.jpg')).read()
32 s3.Bucket(bucket).put_object(
33 Key="montage.jpg",
34 Body=data,ContentType="image/jpeg")
35
36 result = { "montage_url":
37 "https://s3-us-west-2.amazonaws.com" +
38 "/snapshot.linux-magazin.de/" +
39 "montage.jpg"}
40
41 shutil.rmtree(tmpd)
42 return result
Zwiespalt: Python 2 und 3
Die Python-Welt leidet unter den Gegensätzlichkeiten zwischen Python 2.x und 3. Letzteres stellt eine Art paradiesischen Zustand dar, in dem Kinderkrankheiten behoben und Unstimmigkeiten bereinigt sind und coole Neuentwicklungen stattfinden. Nur nutzt kaum jemand Python 3 in Produktionsumgebungen, auch Amazon bietet nur 2.7 an.
In Python 2.x schlägt sich der Programmierer mit hanebüchenem Wildwuchs an Libraries herum und muss sich etwa beim Holen von Webdaten zwischen den inkompatiblen Erzeugnissen »urllib« und – kein Scherz – »urllib2« entscheiden. Wer externe Programme starten möchte, nutzt in 2.x »check_output()« des Moduls »subprocess«, während in Python 3.x die Methode »run()« andere Parameter verwendet und »check_output()« nicht mal mehr existiert.
Lambda Go
Die Lambda-Funktion in Listing 2 bekommt die URL der zu analysierenden Videodatei im Parameter-Dictionary »event« unter dem Schlüssel »movie_url« zugespielt. In einer echten Produktionsumgebung darf kein Python-Skript in einem festen Verzeichnis wie »data« operieren und hoffen, dass niemand dazwischenfunkt. Da Amazon-Lambda-Funktionen parallel aufgerufen werden, müssen sie für solche Zwecke mit Pythons »tempfile«-Modul zunächst ein Instanz-eigenes temporäres Verzeichnis anlegen und nach Abschluss der Tätigkeit wieder abräumen.
Damit dies auch passiert, falls eine der Funktionen nach einem Fehler eine Exception auswirft, sollte die letzte Zeile im Produktionsbetrieb in einem Exception-Handler stehen, das unterblieb in der Testversion. Listing 2 ruft in Zeile 10 die Methode »mkdtemp()« auf und nutzt das neue Verzeichnis, um in Zwischenschritten ermittelte Daten für die nächsten Stufen des Skripts abzulegen.
So legt Zeile 16 die per Webrequest eingeholte Videodatei unter dem in der Variablen »movie_file« abgelegten Namen ab, der aus dem letzten Teil des Pfads der URL stammt. Als nächste Stufe ruft Zeile 19 das Skript »max-movement-lk.py« aus dem Listing 3 auf, einen Python-Wrapper um das C++-Programm in Listing 1, und übergibt ihm den Pfad zur Videodatei im temporären Verzeichnis.
Listing 3
max-movement-lk.py
01 #!/usr/bin/python 02 import sys 03 import os 04 import subprocess 05 06 top_dir = os.getcwd() 07 movie_path = sys.argv[1] 08 09 os.chdir(os.path.dirname(movie_path)) 10 11 os.environ["LD_LIBRARY_PATH"] = os.path.join(top_dir,"lib") 12 13 print subprocess.check_output( 14 [ os.path.join(top_dir, "bin/max-movement-lk") ] + 15 [ os.path.basename(movie_path) ] )
Auf Montage
Hinterlässt die Analyse eine Reihe von Jpegs im Format »0001.jpg«, »0002.jpg«, …, kommt in der nächsten Stufe ab Zeile 24 in Listing 2 das Wrapperskript »mk-montage.py« in Listing 4 zum Zuge, das in die Dateinamen eingebettete Sekundenwerte ins Format »SS::MM:ss« umwandelt und die alten Dateinamen sowie die formatierten Labels Imagemagicks »montage« zu fressen gibt:
Listing 4
mk-montage.py
01 #!/usr/bin/python
02 import glob
03 import subprocess
04 import re
05 import time
06 import os
07 import sys
08
09 dir = sys.argv[1]
10 files = glob.glob(
11 os.path.join(dir,'*.jpg'))
12 cmds = ["bin/montage.py"]
13
14 r = re.compile('.*?(\d+)')
15
16 for file in sorted(files):
17 match = r.match(file)
18 if match:
19 label = time.strftime("%H:%M:%S",
20 time.gmtime(int(match.group(1))))
21 cmds.append("-label")
22 cmds.append(label)
23 cmds.append(file)
24 else:
25 print "no match: " + file
26
27 cmds.append(os.path.join(
28 dir,'montage.jpg'))
29
30 print subprocess.check_output(cmds)
montage.py -label 00:00:01 tmp/001.jpg [...]
Das Programm baut daraus einen Kontaktabzug in der Datei »montage.jpg«, die später in Amazons S3 landet, damit User sie per Link auf den Client holen können.
Abbildung 4: Gesammelte Shared Libs.
Das Python-Skript in Listing 5 fungiert als Wrapper um das Binary »montage«, dem im Verzeichnis »lib« eine Reihe von Shared Libraries beiliegt, damit das dynamisch gelinkte Binary im Container läuft. Die Umgebungsvariable »LD_LIBRARY_PATH« setzt den Suchpfad für Shared Libs auf dieses nicht standardisierte Verzeichnis, damit das Binary diese zur Laufzeit auch findet.
Listing 5
montage.py
1 #!/usr/bin/python 2 import sys 3 import os 4 import subprocess 5 6 os.environ["LD_LIBRARY_PATH"] = "lib" 7 8 print subprocess.check_output( 9 [ "bin/montage" ] + sys.argv[1:])
Abbildung 4 zeigt die mit Listing 6 gesammelten Shared Libs. Offensichtlich zieht das mit Open-CV gelinkte AI-Programm zur Bewegungsanalyse einen Rattenschwanz an Bibliotheken mit sich. Hinter einem Video steckt eben geballte Kompressionstechnik, die es zu dekodieren gilt, will man an die rohen Frame-Daten heran.
Listing 6
ldd-ls.py
01 #!/usr/bin/python
02 import subprocess;
03 import sys;
04
05 if len(sys.argv) != 2:
06 print("usage: {} file".format(sys.argv[0]))
07 sys.exit(1)
08
09 file = sys.argv[1]
10
11 output = subprocess.check_output(['ldd',file])
12 for line in output.split("\n"):
13 words = line.split()
14 if len(words) > 3:
15 print words[2]
Sicher abgelegt
Ist der Kontaktabzug »montage.jpg« erstellt, kopiert der Code ab Zeile 28 in Listing 2 die Datei aus dem temporären Verzeichnis in einen vorher angelegten S3-Bucket auf Amazons Cloud-Storage-System. Das Python-Modul »boto3« steht auf Lambda-Servern standardmäßig zur Verfügung und bietet allerlei Tools zur Kommunikation mit verwandten Service-Angeboten.
Die Methode »put_object()« in Zeile 32 legt die von der virtuellen Festplatte gelesene Ausgabedatei als Objekt vom Typ »image/jpeg« im Cloudspeicher ab. Von dort liefert sie der in der vorigen Ausgabe besprochene S3-Webserver an den interessierten User aus, dem der API-Aufruf nach Abschluss die zugehörige URL gesteckt hat. Damit dieser sie findet, stellt Zeile 36 eine Json-Antwort zusammen, die dem Webclient die zur Montage-Datei gehörige S3-URL mitteilt. In Zeile 41 bleibt nur noch, das temporär angelegte Verzeichnis zu löschen.
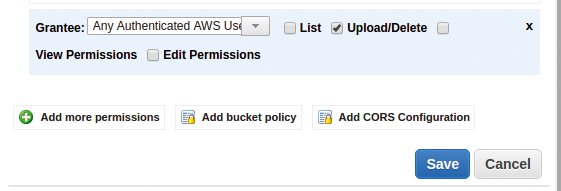
Abbildung 5: Der Lambda-Server benötigt Zugriffsrechte am S3-Bucket.
Damit das Lambda-Skript Schreibrechte an dem als »snapshot.linux-magazin.de« konfigurierten S3-Bucket erhält, muss der User Letzterem entsprechende Rechte verleihen. Abbildung 5 zeigt, dass der S3-Bucket jedem ausgewiesenen AWS-User Zugriff gewährt. Auf der anderen Seite müssen vom Lambda-Server im S3-Bucket erzeugte Dateien auch weltweit für interessierte User lesbar sein. Dies erfolgt über eine so genannte Bucket-Policy, deren Inhalt Listing 7 zeigt. Jede dort neu eingelegte Datei ist demnach für alle lesbar, also kann der am S3-Bucket hängende Webserver sie auch an anfragende Webclients ausliefern.
Listing 7
bucket-policy.json
01 {
02 "Version": "2012-10-17",
03 "Statement": [
04 {
05 "Sid": "",
06 "Effect": "Allow",
07 "Principal": "*",
08 "Action": "s3:GetObject",
09 "Resource": "arn:aws:s3:::snapshot.linux-magazin.de/*"
10 }
11 ]
12 }
Tor zur Welt
Amazon hilft beim Testen von Lambda-Funktionen, der Entwickler kann hochgeladene Skripte entweder durch das Kommandozeilen-Utilty »aws« oder auch den Test-Button der Konsole im Browser ausführen. Aber schließlich sollen User die Funktion aus dem Internet ausführen können, und dazu bietet sich Amazons API-Gateway an. Dieser ebenfalls auf der Konsole anklickbare Service legt einen Cloud-Webserver mit einem REST-API an, dessen Methoden (wie im gezeigten Beispiel »/vimo«) es neben anderen Optionen auf User-definierte Lambda-Funktionen umleitet.
Die Verbindung zwischen Webserver und Applikation auf dem Lambda-Service erledigt AWS hinter den Kulissen, wenn der User für die Option »Integration Type« beim Anlegen der REST-Methode (zum Beispiel »GET« oder »POST«) die Option »Lambda Function« angibt und weiter unten die Region des Datencenters und den Namen der Lambda-Funktion (etwa »vimo«) nennt (Abbildung 6).
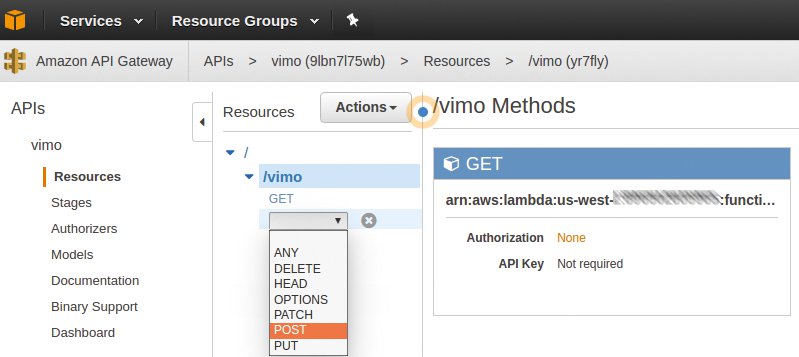
Abbildung 6: Das Anlegen der REST-Methode mit GET.
In unserem Fall soll der Pfad »/vimo« die »POST«-Methode verwenden und im Body des Request einen Json-Blob mit benamten Parametern (etwa »movie_url«) führen. Setzt der Webclient wie in Abbildung 1 sichtbar den Header »Content-Type« auf »application/json«, dann fängt bereits das API-Gateway den Json-Blob ab und analysiert ihn.
Die später aufgerufene Lambda-Funktion erhält dann bereits die dekodierten Wertepaare aus den Json-Daten in einem Python-Dictionary als Funktionsparameter »event«. Im vorliegenden Fall legt der Client in Abbildung 1 die URL zum Überwachungsvideo im Json-Blob im Parameter »movie_url« ab, während die Lambda-Funktion in Listing 2 mit »event[‘movie_url’]« darauf zugreift.
Live schaltet das REST-API erst, nachdem der User im Kontextmenü unter »API Actions« die Funktion »Deploy-API« angeklickt (Abbildung 7) und eine Produktionsumgebung (Stage) ausgewählt hat (etwa »Beta«). Im Browser zeigt AWS dann die URL an, unter der der neue Webservice erreichbar ist.
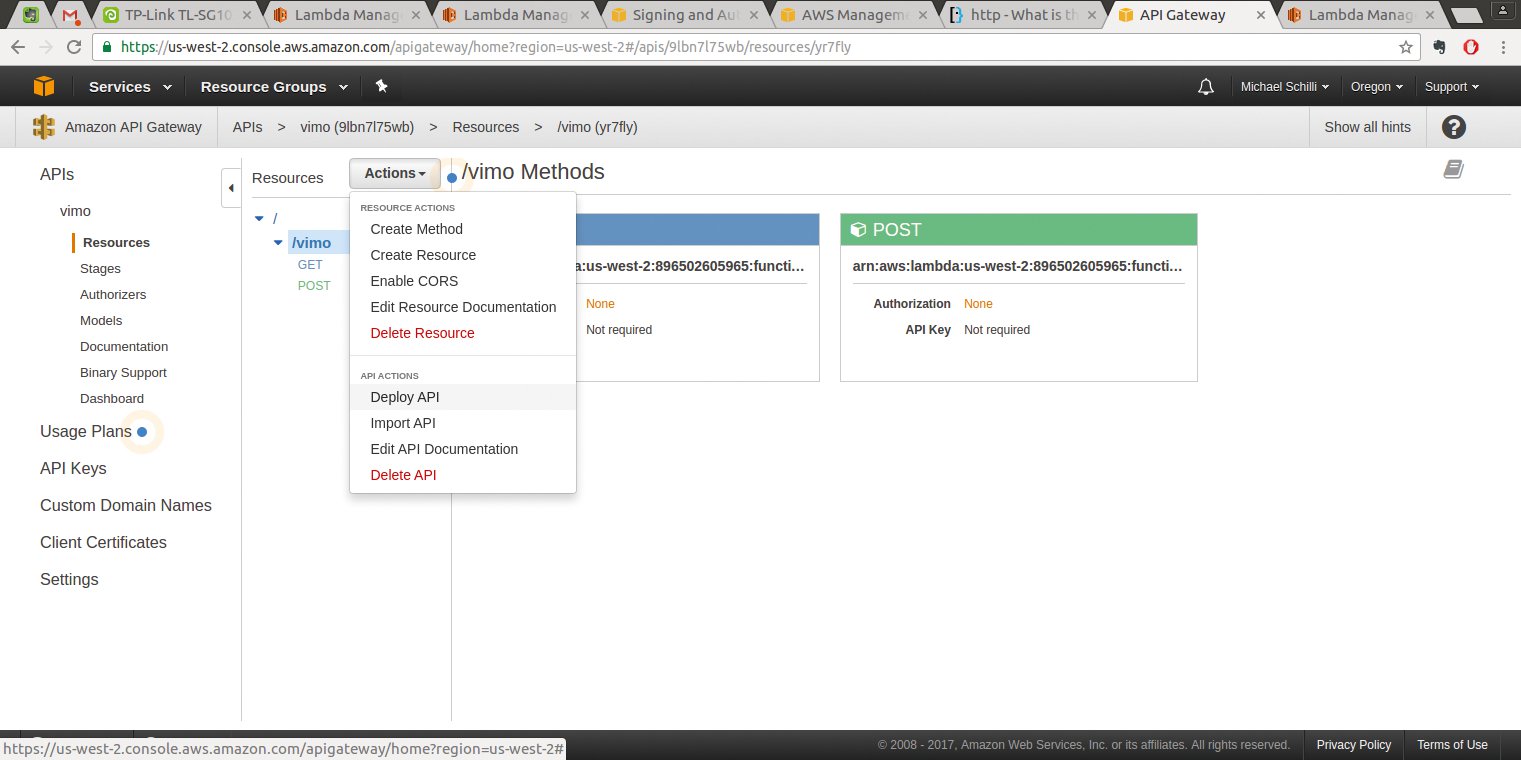
Abbildung 7: Das Live-Schalten erfolgt über die Funktion »Deploy-API«.
Als Produktionsumgebung installiert ist der Einsatz von API-Tokens zu empfehlen, die den Zugang zum API regeln. Auch ein Drosseln des Ansturms (etwa auf 1000 Requests/Sekunde) ist hiermit möglich, um einer überraschenden Kostenexplosion vorzubeugen, falls der Link sich lauffeuerartig verbreitet.
Bei der Arbeit an diesem Artikel hatte ich immer ein wachsames Auge auf anfallende Kosten, doch die hielten sich im “Free Tier”-Rahmen, es fielen nur 0,01 US-Dollar an, um die während vieler Testdurchgänge aufgebrauchte Bandbreite zum Hochladen der ständig aktualisierten und verbesserten Zip-Datei mit Testcode und Libs zu decken.
Online PLUS
Im Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/Ausgaben/2017/03/plus
Infos
- Listings zu diesem Artikel: https://www.linux-magazin.de/static/listings/magazin/2017/03/snapshot/
- Danilo Poccia, “AWS Lambda in Action”: Manning 2017
- Michael Schilli, “Schaut auf diese Stadt”: Linux-Magazin 12/16, S. 104, https://www.linux-magazin.de/Ausgaben/2016/12/Perl-Snapshot
Der Autor

Michael Schilli arbeitet als Software Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne widmet er sich Kurzprojekten in Perl und wechselnden Sprachen. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





