
© Galyna Andrushko, 123RF
Der Start ins Cloud Computing fällt für viele Firmen holpriger aus als erhofft, denn bei Weitem nicht jede ihrer Applikationen ist dafür geeignet. Was zeichnet Cloud-Native-Anwendungen aus und woran scheitern herkömmliche Programme in der Cloud?
Software muss für den Betrieb in einer Cloud vorbereitet sein. Was wie eine Binsenweisheit klingt, ist so manchem Administrator schon böse auf die Füße gefallen. Denn viele Standard-Applikationen lassen sich nur schwer in einer Cloud überhaupt ausrollen.
Das gilt umso mehr, je spezifischer die jeweilige Software auf einen Einsatzzweck ausgerichtet ist: Software, die im eigenen Unternehmen vor Jahren entstanden und an dessen Vorgaben angepasst ist, kann oft nur innerhalb dieser Umgebung laufen. Der Umzug in eine Cloud zeitigt dann unbefriedigende Ergebnisse.
Dieser Artikel beschäftigt sich mit der Frage, was Clouds von herkömmlichen Virtualisierungsumgebungen unterscheidet und inwiefern das von Bedeutung für Software ist, die in einer Cloud laufen soll. Er geht ebenfalls darauf ein, worauf die Autoren von Programmen von Anfang an achten sollten, um eine Applikation für den Betrieb in Cloudumgebungen vorzubereiten.
Genau das unterscheidet die Cloud Native Applications von den herkömmlichen Anwendungen: Sie lassen sich in fast jedem Cloudstack problemlos ausrollen und nutzen automatisch die Dienste, die dort zur Verfügung stehen.
Flexibilität ist Voraussetzung
In der Cloudcommunity kursiert seit Jahren das Bonmot, dass es lediglich um Kätzchen und Rindviecher geht (Cats and Cattle). Kätzchen sind demnach klassische physische oder virtuelle Systeme, die der Admin manuell und mit viel Liebe zum Detail aufsetzt: Wie ein Kätzchen händisch aufgezogen wird, einen Namen bekommt und beim Tierarzt landet, wenn es krank ist, sind auch die entsprechenden VMs Unikate. Sie lassen sich nicht problemlos wiederherstellen, etwa weil sie Bewegungsdaten enthalten. Und sind sie kaputt, steht meist zumindest ein Teil der gesamten Plattform still. Hier kommt die Metapher an ihre Grenzen – denn spezifische VMs dieser Art legen Anbieter meist redundant aus, damit sie auch den Ausfall von kritischer Infrastruktur, etwa von Hardware, überleben.
Cloudumgebungen brauchen mehr Flexibilität. Im Idealfall ist in Clouds jede virtuelle Maschine das Resultat eines definierten und exakt nachvollziehbaren Prozesses, bei dessen Ablauf sie automatisch generiert wird. Es ist zu jedem Zeitpunkt möglich, eine bestehende virtuelle Instanz um eine weitere Instanz desselben Typs mit derselben Konfiguration zu erweitern.
Dieser Anspruch begründet sich damit, dass Anbieter in Clouds üblicherweise nur sehr eingeschränkte Garantien für die Verfügbarkeit einzelner Dienste geben. Wer 1000 oder mehr Rechner als Teile einer Cloud betreibt, kann nicht jede einzelne VM in diesem Setup redundant auslegen, weil das die Anschaffungskosten explodieren ließe. Stattdessen kommt den Admins solcher Plattformen die Verantwortung zu, jede VM so generisch wie möglich zu halten und die Umgebung so zu konstruieren, dass der Ausfall einzelner Instanzen nicht zum Ausfall der gesamten Plattform führt.
In diesem Kontext wird der Vergleich mit Rindviechern verständlich: In einer Herde von Rindern haben die Tiere keine Namen mehr, sondern einen Knopf im Ohr, auf dem eine Nummer steht. Es geht also nicht mehr um das individuelle Tier, sondern lediglich um das Ergebnis, das die Gruppe an Tieren produziert.
IaaS ist nur eine Krücke
Wenn Unternehmen bereits existierende Software in die Cloud migrieren, ist das Ziel meist Infrastructure as a Service (IaaS, Abbildung 1). Oder anders ausgedrückt: Die bereits laufende Applikation einer Abteilung oder eines Kunden wandert lediglich aus virtuellen Maschinen in dessen Rechenzentrum in andere virtuelle Maschinen entweder im eigenen Rechenzentrum oder bei einem Public-Cloud-Anbieter. Nach der Migration stehen den Applikationen in der Cloud deren Vorteile zur Verfügung, etwa die Möglichkeit, neue virtuelle Instanzen schnell zu starten. Der gleiche Vorgang hätte zuvor möglicherweise Wochen gedauert, weil erst Hardware anzuschaffen gewesen wäre.
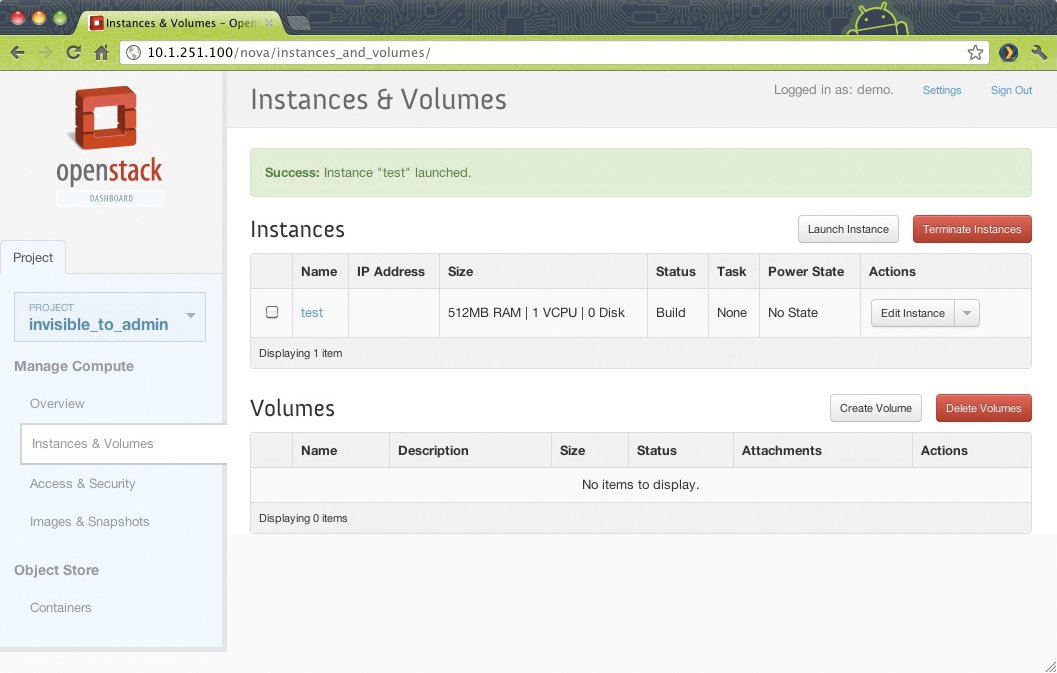
Abbildung 1: Wer das Wort “Cloud” hört, denkt instinktiv an IaaS – doch der Trend geht klar in Richtung nativer Cloud-Apps auf PaaS-Basis.
Bald schon wird dem verantwortlichen Admin aber auffallen, dass praktisch alle gängigen Clouds – ob privat oder öffentlich – zusätzlich zu IaaS diverse Leistungen im Angebot haben. Etwa Datenbanken als Service (DBaaS). Dabei nimmt der Cloudanbieter dem Kunden die Aufgabe ab, eine Datenbank, etwa MySQL, zu betreiben (Abbildung 2). Über ein eigenes Interface oder per Orchestrierungslösung klickt der Kunde sich eine virtuelle Datenbank zurecht und erhält am Ende des Vorgangs eine IP und Login-Daten für sie. Die Credentials nutzt er in seiner Applikation, seine eigene VM mit MySQL fährt er einfach herunter. Dieser Vorgang ist ein typisches Beispiel dafür, wie Anwender generische Services in einer Cloud nutzen.
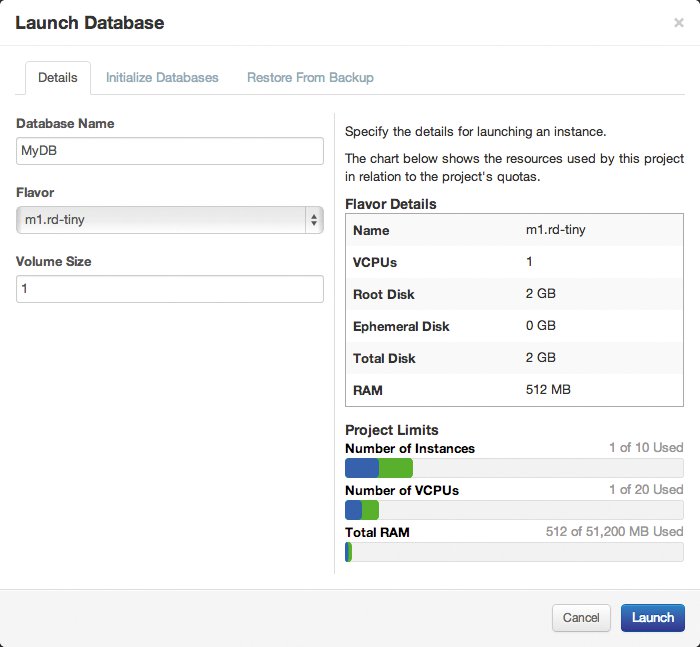
Abbildung 2: Relikt der Vergangenheit? Native Cloudapplikationen erwarten, dass sie sich um die Datenbank selbst nicht mehr kümmern müssen.
Ähnlich verhält es sich bei Platform as a Service: Hier entfällt sogar das Betriebssystem als Komponente, um die sich der Anwender kümmern müsste. Denn bei PaaS nutzt der Kunde eine komplette, fertige Umgebung (Abbildung 3) – etwa eine, in der sich PHP-Webseiten betreiben lassen oder in der C++-Programme funktionieren. Der Kunde spielt bloß noch seine Applikation in diese Umgebung ein – schon ist sie einsatzbereit.
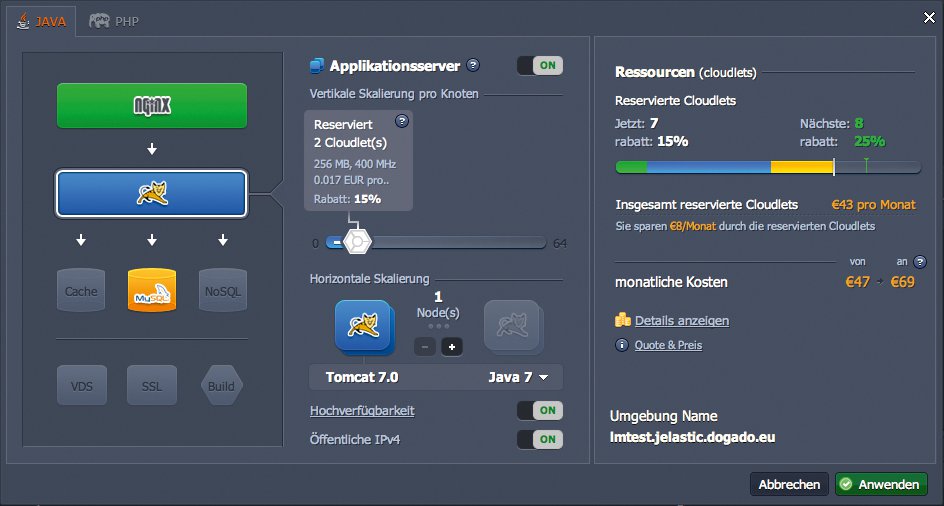
Abbildung 3: Echtes PaaS nimmt dem Nutzer die Aufgabe ab, sich um VMs und die darin laufenden Betriebssysteme zu kümmern.
Genau an dieser Stelle wird meist schmerzhaft offensichtlich, wo der Unterschied zwischen einer nativen Cloudanwendung und einer aus der klassischen Welt liegt: Letztere setzt individuell zugeschnittene Libraries oder Schnittstellen voraus oder ist starr an externe Dienste wie Datenbanken gekoppelt. Die meisten konventionellen Systeme sind zudem Monolithen: Es gibt also ein großes Programm und nicht viele kleine Komponenten wie in einer PaaS-Umgebung.
Zwölf Regeln
Wie sollen Unternehmen also neue Applikationen entwickeln oder bestehende umbauen, damit sie sich in Clouds und in PaaS-Umgebungen problemlos betreiben lassen, nahtlos skalieren und außerdem auch mit den eingeschränkten Verfügbarkeitsgarantien von Clouds zurechtkommen?
Das Zwölf-Faktoren-Manifest [1] liefert in dieser Sache wichtige Hinweise. Der von Adam Wiggins verfasste Text listet zwölf Regeln auf, an die sich App-Entwickler nach Meinung des Verfassers halten sollen. Zunächst stellt sich die Frage, wie die Programmierer mit dem Code ihrer Apps umgehen sollen.
Zentraler Code
Typisch für klassische Setups ist, dass der Admin eine App als Tarball von Server zu Server kopiert, um sie einzeln auszupacken. In Clouds ist das nicht praktikabel: Besser ist es, wenn der gesamte benötigte Code in einem Revisions-Kontrollsystem wie einem Git-Verzeichnis liegt, wo er sich von überall auschecken lässt. Das ist besonders dann hilfreich, wenn man mit demselben Quelltext verschiedene Setups – etwa für mehrere Kunden – in unterschiedlichen Clouds ausrollen will: Denn so ist zugleich sichergestellt, dass überall auch wirklich derselbe Quelltext zum Einsatz kommt.
Damit das funktioniert, muss noch eine weitere Bedingung erfüllt sein: Der Quelltext der Applikation darf weder kundenspezifische Details noch Konfigurationsdateien für ein bestimmtes Setup enthalten. In Clouds ist die grundsätzliche Erwartung, dass die Konfiguration aus der Umgebung kommt.
Das lässt sich auf verschiedenen Wegen erreichen: Entweder läuft im Hintergrund eine Konfigurationsdatenbank wie Etcd, Consul oder Fleetd, die zusammen mit der Applikation ausgerollt und mit den benötigten Daten gefüttert ist. Die Applikation wird sich dann mit diesem Dienst verbinden, um an ihre Daten zu kommen. Oder der ausführende Admin speichert die Konfiguration in den Metadaten der Cloudumgebung.
Alle gängigen Clouds bieten die Option, beim Anlegen virtueller Maschinen für sie Metadaten zu definieren. Die müssen dann alle Daten enthalten, die für den Betrieb der Plattform nötig sind – und die Applikation muss sie entsprechend abfragen. Amazon oder Clouds, die mit Amazon kompatibel sein wollen, lösen das Problem etwa über »cloud-init«: Das Tool verbindet sich beim Bootvorgang einer Cloud-VM mit der Pseudo-Adresse »http://169.254.169.254« und liest die hinterlegten Metadaten aus. Genau so kann eine Applikation aus der VM heraus freilich ebenfalls vorgehen.
Damit die Applikation in möglichst vielen Vanilla-VMs lauffähig ist, muss sie außerdem ihre Abhängigkeiten sauber definieren: Eine PHP-Applikation hat etwa Sorge dafür zu tragen, dass alle benötigten PHP-Module installiert sind, damit sie automatisiert ausrollbar ist. Gleiches gilt für praktisch alle Skript- und Programmiersprachen.
Dienste im Hintergrund
Die meisten Webanwendungen sind von anderen Dienste abhängig, zum Beispiel von dem vielzitierten MySQL. Weil die Applikation selbst jedoch auf diese Dienste keinen Einfluss hat, geht Andrew Wiggins davon aus, dass sie sich auch nicht selbst darum kümmern sollte. Dem Admin kommt daher die Aufgabe zu, eine funktionierende MySQL-Datenbank so zu betreiben, dass sie für die Applikation verfügbar ist. Die nötige Information, wo sie die Datenbank findet, erhält die App über ihre Konfiguration – wie zuvor beschrieben.
Wiggins geht noch einen Schritt weiter: Native Apps für die Cloud sollen grundsätzlich überhaupt keine Annahmen darüber machen, wie die physische Umgebung, in der sie laufen, gestaltet ist – also auch nicht über die konkrete Realisierung von Diensten wie etwa den persistenten Speicher oder das virtuelle Netzwerk. Das wirkt sich an verschiedenen Stellen auf das Verhalten der Applikation aus, etwa wenn es um Logs geht: Konventionelle Applikationen schreiben ihre Logs meist in Dateien.
Wiggins plädiert dafür, stattdessen alle Log-Ausgaben grundsätzlich nach Stdout zu schreiben und dann die umgebende Plattform entscheiden zu lassen, wohin diese Ausgaben zu leiten sind.
Dynamische Entwicklung
Auch auf die Art und Weise, wie Applikationen entwickelt werden, wirkt sich die Notwendigkeit zur Cloudkompatibilität aus. Das Prinzip ist simpel: Die Entwicklung findet vom Betrieb einer Lösung strikt getrennt statt. Der Betrieb von Entwicklungsversionen im stabilen Einsatz verbietet sich deshalb von selbst.
Es gilt aber auch das Prinzip “Release early, release often”: Das Delta zwischen Produktion und der aktuellen Entwicklerversion soll so klein wie möglich sein. Mehrere Rollouts pro Tag sind demnach einem großen Rollout alle sechs Monate vorzuziehen. In die gleiche Kategorie fällt die Anforderung, dass sich innerhalb einer App jedes System zu jedem Zeitpunkt durch eine frische, neue Version seiner selbst austauschen lassen muss.
Skalierbarkeit als zwingende Voraussetzung
Auf Basis des Prozessmodells definiert Adam Wiggins außerdem, dass sich Cloudapplikationen beliebig in die Breite skalieren lassen müssen. Wenn zu einem bestimmten Zeitpunkt etwa fünf Webserver ihren Dienst in der Plattform verrichten, soll sich diese Anzahl bei Bedarf sofort verdoppeln lassen. Der Punkt baut auf den vorangegangenen auf: Nur wenn diese gegeben sind, ist das Skalierbarkeitskriterium zu erfüllen. Schließlich hat der Admin keinen Einfluss mehr auf die technischen Details des Skalierens bei PaaS – darum kümmert sich der Anbieter.
Der nächste Schritt: Microservices
Konventionelle Applikationen sind meist als monolithische Software designt. Es gibt also ein großes Programm, das alle Funktionen bietet und meist einem Tier-3-Design folgt. Innerhalb der Software steuern viele Einzelmodule die gewünschte Funktionalität bei. Ein Modul lässt sich ohne die Applikation drum herum aber nicht sinnvoll nutzen und ist alleine auch nicht lauffähig.
Unter diesen Bedingungen wird Skalierbarkeit zum Problem: Auch wenn nur einzelne der im Programm verwendeten Funktionen mehr Instanzen benötigen, muss der gesamte Monolith mehrfach ausgeführt werden. Zudem sind solche Anwendungen fehleranfällig: Fällt der Computer aus, auf dem die PaaS-Umgebung jenes Monolithen lag, ist der Dienst schlicht nicht verfügbar.
Auch sind solche Monolithe sehr schwierig im Handling: Ihre Entwicklung lässt sich nur langsam betreiben, weil sie selbst und die anschließenden Tests viel Zeit in Anspruch nehmen. Einige der erwähnten zwölf Regeln verletzen solche Monolithe also implizit. Kurzum: Sie sind ein guter Ansatz für klassische Anwendungen, aber vor dem Hintergrund der nativen Cloudapplikationen sind sie schlicht ein Alptraum, der sich kaum sinnvoll betreiben lässt.
Microservices sind extrem modular
Auf all diesen Annahmen fußt die Idee der Microservices. Hier bauen die Entwickler nicht mehr eine große Applikation. Salopp formuliert wird aus jeder Funktion, die bei monolithischer Software ein Modul wäre, ein eigener Dienst. Das führt an manchen Stellen zwar zu Mehraufwand, so müssen Dienste einer Microservice-Architektur über ein festgelegtes Protokoll miteinander kommunizieren, etwa über APIs. Im Gegenzug sorgt das Design aber auch für größtmögliche Flexibilität. Wenn einzelne Dienste des Setups etwa mehr Last bewältigen müssen, lässt es die Microservice-Architektur zu, nur genau jene Dienste mehrfach zu starten, die mehrfach benötigt werden – und nicht das ganze Programm.
Auch die Anforderungen im Hinblick auf die interne Redundanz lassen sich mit Microservices besser erfüllen. Denn wenn ein einzelner Teildienst ausfällt und die Applikation entsprechend programmiert ist, springt einfach eine andere Instanz desselben Dienstes ein und übernimmt dessen Aufgaben.
Mehraufwand durch viele Standards
Zwar ist sich die Fachwelt aktuell weitgehend einig, worin sich native Cloudapplikationen von konventionellen Programmen unterscheiden. Doch das Beispiel von PaaS auf der einen Seite und Docker, Kubernetes & Co. auf der anderen macht auch deutlich: Den Goldstandard für den Betrieb nativer Cloudapplikationen gibt es bisher nicht.
Das zeigt sich besonders bei der Frage, wie der konkrete Betrieb und wie das Setup solcher Applikationen aussehen sollen. Der Vertrieb der Applikation in fertigen Containern ist aus Autorensicht ein bequemer Weg, setzt beim Kunden aber voraus, dass er sich eine passende Plattform sucht, in der sich die entsprechenden Container starten lassen – aber das ist bei keinem der großen Public-Cloud-Anbieter zurzeit möglich.
Denn dort hat man ganz eigene Vorstellungen davon, wie sich native Apps in die eigene Plattform integrieren. Amazon bietet als Paradebeispiel so viele Funktionen in seiner AWS-Cloud, dass Neulinge schnell den Überblick verlieren. Von echtem PaaS über das semi-automatische Ausrollen von Plattformen per Cloud Formation – Amazons eigenem Cloud-Orchestrierungsdienst – sind fast alle Varianten denkbar. Ähnlich verhält es sich mit Microsofts Azure. Wer stattdessen lieber eine öffentliche Cloud mit Open Stack wählt, findet auch dort spezifische Voraussetzungen vor, an die er sein Deployment anpassen muss.
Das Beispiel MySQL macht deutlich: Die meisten gängigen Applikationen gehen davon aus, dass ihnen der Zugriff auf eine wie auch immer geartete Datenbank zur Verfügung steht. Der konventionelle Ansatz besteht darin, auf IaaS-Basis ein eigenes MySQL in einer separaten VM zu starten. Deutlich mehr im Sinne der PaaS-Idee wäre es allerdings, die Datenbank als von der Cloud eigens angebotenen Dienst zu nutzen, also DBaaS.
Wer solch ein Setup allerdings auf Azure, AWS oder Open Stack ausrollen möchte, sieht sich mit drei unterschiedlichen Orchestrierungswerkzeugen konfrontiert (Abbildung 4). Während also die jeweilige Applikation möglicherweise durchaus der Idee einer nativen App folgt, gestaltet sich das Deployment der Software kompliziert und hängt stark von der gewählten Zielplattform ab.

Abbildung 4: Gemeinsames Ziel ist eine MySQL-Datenbank, doch Amazon, Azure und auch Open Stack nehmen unterschiedliche Wege dorthin.
Gruß aus der Containerwelt
Ein sicheres Anzeichen dafür, dass die Idee der Microservices sich trotzdem durchsetzt, liefert ein Blick in die Welt der Container. Hier prescht besonders Docker seit Jahren in die gleiche Richtung vor, auf die sich auch native Cloudapplikationen stürzen: Entwickler haben bei Docker die Möglichkeit, ihre Applikation so zu paketieren, dass andere Nutzer sich einfach nur den fertigen Container herunterladen und ihn anschließend einsetzen können.
Viele Beispiele in der Praxis zeigen, wie man das aus Admin-Sicht besser nicht machen sollte: Ein riesiger Docker-Container mit einem LAMP-Stack, in dem der Admin nicht nachvollziehbare, händische Änderungen vorgenommen hat, ist nicht hilfreich, sonder eine Katastrophe in Sachen Betrieb und Wartung. Gerade der Umstand, dass Apache, MySQL & Co. eben keine nativen Cloud-Apps sind, macht an vielen Stellen allerdings Kompromisse nötig.
Native Cloudapplikationen nutzen die Vorteile von Containern besser: Ein entsprechend optimierter Workflow ermöglicht es Programmautoren, einzelne Microservices einer Cloudapplikation in saubere Standardcontainer zu verpacken. Das automatische Bauen von passenden Container-Abbildern gehört im besten Falle zum Teil des Release-Prozesses: Wo ein Prozess üblicherweise einen Tarball als fertige Release einer Software produziert, könnte bei nativen Cloudapplikationen genauso gut ein standardisierter Docker-Container Ergebnis des Release-Vorgangs sein.
Auf Plattformen wie Kubernetes oder Docker Swarm ist das Ausrollen der entsprechenden Applikation dann ein Kinderspiel: Gerade Kubernetes mit seinem Prinzip von Pods und einzelnen Containern darin ist wie gemacht für native Cloudapplikationen (Abbildung 5). Anders als bei PaaS müssten sich die Entwickler hier zwar teilweise um das eingesetzte Betriebssystem kümmern. Im Gegenzug gibt es aber eine Garantie dafür, dass die gesamte Umgebung sich auf jeder mit Kubernetes oder Docker kompatiblen Plattform ohne Mehraufwand ausrollen lässt.
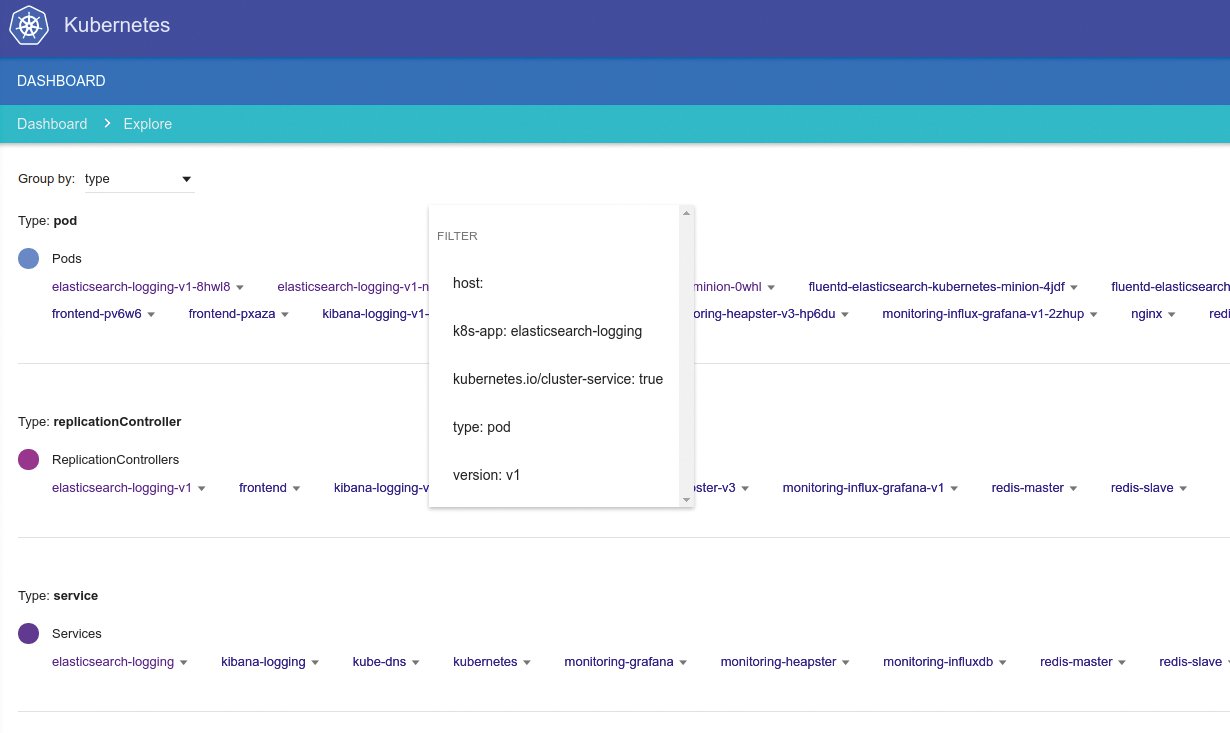
Abbildung 5: Kubernetes bietet zwar das perfekte Umfeld für native Cloudapplikationen, ist aber mit anderen Lösungen nicht sinnvoll kompatibel.
Fazit
Umwälzungen in der IT sind meist langwierige Prozesse. Die Cloud selbst ist dafür das beste Beispiel, denn obwohl diverse Cloudangebote seit Jahren existieren, beschäftigen sich Unternehmen erst nach und nach mit dem Umstieg auf das neue System. Zwar ist aktuell an vielen Stellen von nativen Cloudapplikationen die Rede, doch schon jetzt ist absehbar, dass es viele Jahre dauern wird, bis sich das Konzept flächendeckend durchgesetzt hat.
Applikationen, die extra für Cloudumgebungen gebaut worden sind, sind in vielerlei Hinsicht anders als ihre konventionellen Vorgänger. Sie nutzen die in Clouds typischerweise feilgebotenen Dienste und Services optimal aus. Die Karten zwischen Cloudanbietern und den Unternehmen, die in der Cloud eine Lösung betreiben, werden dabei neu gemischt: Aus Sicht des Unternehmens spielt die einzelne virtuelle Instanz praktisch keine Rolle mehr. Die Erwartung an den Cloudanbieter ist viel eher, dass er im Sinne einer Platform as a Service die nötigen Dienste so anbietet, dass die Kunden sie schnell und problemlos nutzen können.
Beide Seiten gewinnen: Der Anbieter selbst kann sich auf entsprechende Standards berufen und vereinfacht den Aufbau und die Wartung seines Systems merklich. Kunden werden im Gegenzug deutlich flexibler: Eine Applikation, die in einer Cloud läuft, läuft auch in einer anderen – wobei hier noch Nachbesserungsbedarf besteht: Der Idealzustand für den Autor einer Software wäre freilich, dass ein einzelnes Container-Image oder eine einzelne Version seiner Software sich in beliebigen Umgebungen ausrollen und nutzen lässt. Doch dazu mangelt es bisher an Standardisierung innerhalb aktueller Angebote.
Noch steht das Prinzip der Cloud Native Applications also ganz am Anfang seiner Karriere. Doch mit zunehmender Verbreitung der Cloud und mit immer mächtiger werdenden Diensten der öffentlichen Cloudanbieter wird das Prinzip in Zukunft zusehends Fahrt gewinnen. Anbieter wie Kunden haben ein starkes Interesse daran, den Prozess zu beschleunigen.
Infos
-
Andrew Wiggins’ 12 Faktoren: https://12factor.net/
Der Autor

Martin Gerhard Loschwitz arbeitet als Teamlead Open Stack bei Sys Eleven in Berlin. In seiner Freizeit segelt er bevorzugt auf der Ostsee.





