
© Thomas Sztanek, 123RF
Konventionelle IT-Setups profitieren von überschaubaren Mengen an Hardware und guter Planbarkeit. Wer dagegen massiv skalierbare Setups – etwa Clouds – aufbaut, sieht sich mit ganz anderen Voraussetzungen konfrontiert. Wie behält er dennoch den Überblick?
Zwischen Clouds und konventionellen IT-Setups gibt es mehr Unterschiede als Gemeinsamkeiten. Schon die Dimensionen, die Vertreter beider Gattungen in der Regel erreichen, könnten unterschiedlicher kaum sein: Typische IT-Setups erreichen selten mehr als ein paar Dutzend Server. Drohen sie größer zu werden, ziehen Admins lieber die Reißleine und bauen mehrere kleine Setups statt eines großen. Massiv skalierbare Setups schließen diese Möglichkeit hingegen aus: Um Gewinn aus dem Faktor “Single Point of Administration” zu schlagen, geht es hier ja gerade darum, nur ein einziges Setup zu verwalten.
Ein zweiter zentraler Unterschied ergibt sich aus dem ersten und betrifft das Wachstum des Setups oder genauer gesagt dessen Planbarkeit. Klassische Setups entstehen meist auf Basis eines auf mehrere Jahre angelegten Betriebskonzepts, das auch das erwartete Wachstum mit einbezieht.
Gerade bei Clouds ist es aber oft so, dass die Realität alle Planungen überholt. Ein neuer Kunde etwa, der in der Cloud von heute auf morgen 1200 CPU-Kerne nutzen möchte, erzwingt die Anschaffung und den Aufbau mindestens eines zusätzlichen Rack – und das auch noch in kürzester Zeit.
Wer also eine Cloud oder ein vergleichbares, massiv skalierbares Setup aus dem Boden stampfen möchte, denkt über solche Probleme am besten schon ganz am Anfang nach. Wer später im Falle eines Falles keinen funktionierenden Prozess hat, um 25 neue Server von jetzt auf gleich bereitzustellen, der investiert in diesen Schritt so viel Zeit, dass der Kunde mit hoher Wahrscheinlichkeit abspringt.
Neue Ansätze nötig
Große Setups setzen Überlegungen voraus, die in konventionellen nicht notwendig sind. Das beginnt bei vermeintlichen Standards wie dem Design der Fläche im Rechenzentrum oder der Stromverkabelung. Weiter geht es mit fundamentalen Diensten, etwa DNS oder DHCP. Auch die Hardwareverwaltung spielt eine wichtige Rolle: Automatische Installationsroutinen, die neuen Servern Leben einhauchen, sind zwar wichtig und gut – aber wer Hunderte oder Tausende Server effektiv verwalten will, setzt bereits deutlich früher an. Das Resultat ist echtes Lifecycle-Management, das vom Auspacken des Servers aus dem Karton bis hin zur Entsorgung reicht.
Erst dann ist es überhaupt sinnvoll, über eine Automatisierungslösung nachzudenken oder die Expansion auf anderen Standorten anzugehen. Der folgende Artikel erkundet, wie sich große Setups sinnvoll planen und umsetzen lassen. Er legt besonderes Augenmerk auf die Verwaltung der Hardware.
Die Bedürfnispyramide für Rechenzentren
Abraham Maslow, ein bekannter amerikanischer Psychologe, entwickelte eine Bedürfnishierarchie, die veranschaulicht, welche Bedürfnisse der Mensch hat und in welcher Reihenfolge er sie zu befriedigen versucht. Um die Antwort auf die Frage zu finden, welche Faktoren in massiv skalierbaren Setups von elementarer Bedeutung sind, eignet sich ein ähnlicher Ansatz: die Bedürfnispyramide für Rechenzentren (Abbildung 1).
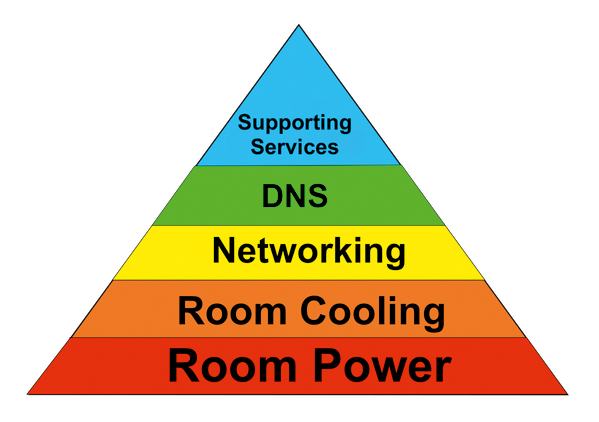
Abbildung 1: Die Bedürfnispyramide von Rechenzentren basiert auf der Maslow-Pyramide. Sie beschreibt nötige Voraussetzungen in RZs.
Sie befasst sich zunächst mit physikalischen Gegebenheiten, also Strom und Kühlung. Logisch: Ohne diese beiden Voraussetzungen lässt sich Hardware im Rechenzentrum nicht betreiben. Eine imaginäre sechste Stufe am Fuß der Pyramide könnte der Faktor Fläche sein.
Das ist bei Scale-out-Setups von deutlich größerer Bedeutung als bei klassischen Setups. Denn wer sich mit der Notwendigkeit konfrontiert sieht, Server gleich Rack-weise und mit wenig Vorlaufzeit anzuschaffen, muss gleich am Anfang entsprechend viel Fläche im Rechenzentrum buchen. Nur so steht sie im Ernstfall bereit. Diverse Anbieter sind mittlerweile dazu übergegangen, mit zwei Racks zu beginnen, aber von Anfang an Fläche für 20 Racks oder mehr zu mieten.
Wachstumsplanung im Netz
Die nächste Stufe der Pyramide thematisiert das Netzwerk. Hier sind gleich mehrere Facetten zu beachten. Massiv skalierbare Setups brauchen ein Netzwerkdesign, das von Anfang an auf späteres Wachstum ausgelegt ist. Die Standardkonfiguration mit Leaf- und Spine-Switches erfüllt diese Forderung: Jedes Rack bekommt einen einzelnen Switch als Top-of-Rack-Switch (ToR), die einzelnen Server sind mit dem ToR-Switch im selben Rack und mit dem Switch im Rack nebenan verbunden.
In der ersten Ausbaustufe des Setups, die meist nur aus zwei kompletten Racks besteht, sind die beiden ToR-Switches zudem direkt miteinander verkabelt – die Spine-Ebene fehlt in Schritt eins. Sobald die Zahl der Racks steigt, kommt sie aber hinzu: Dann sind die ToR-Leaf-Switches über Kreuz mit Spine-Switches verbunden, aber nicht mehr untereinander. Solche Setups verbinden bereits Dutzende Racks miteinander, wenn auf der Spine-Ebene entsprechend potente Hardware zum Einsatz kommt.
Aktuell empfiehlt sich etwa die SN2700-Serie von Mellanox, die 32100-GBit-Ports bei erträglichen Preisen liefert. Obendrein sind diese Switches mit Cumulus erhältlich: Dabei handelt es sich um ein Betriebssystem für Switches auf Debian-Basis, was die Verwaltung der Switches via Automatisierung – etwa Puppet oder Ansible – von Anfang an erlaubt.
Auch die logische Verwaltung des Netzwerks sollten Admins gut überdenken. In vielen Unternehmen finden sich alte Netzwerklayouts, die auf VLANs setzen und in verschiedene VLAN-Segmente aufgeteilt sind. Skalierbare Setups und besonders Clouds erwarten ein völlig flaches Netz: Hier kommen SDN-Lösungen zum Einsatz, die Netzwerkhardware selbst nimmt keine Managementaufgaben mehr wahr. Solange also alle Systeme des Setups zum selben Netzsegment gehören und dieses von den anderen vorhandenen Netzwerksegmenten abgetrennt ist, kommt es in der Regel zu keinen Schwierigkeiten.
Das leidige Thema DNS
Allerdings führt bereits diese strikte Trennung ebenfalls dazu, dass die nächste Stufe der Bedürfnispyramide in Rechenzentren zum Problem wird: DNS. Das spielt in skalierbaren Setups meist schon für die Installation der Systeme eine große Rolle. Verteilte Speicher nutzen zum Beispiel regelmäßig DNS-Einträge, damit Clients den für sie zuständigen Speicherdienst erreichen oder Metadaten mit dem dazu auserkorenen Metadaten-Dienst austauschen können.
Dadurch wird der Betrieb eigener DNS-Server praktisch zur Pflicht – das umfasst sowohl Reverse DNS (rDNS) als auch Asynchronous-capable DNS (aDNS). DNS als Dienst muss also funktionieren, bevor an die Installation der ersten Server überhaupt zu denken ist. Schon deshalb empfiehlt sich der Betrieb von eigenen Servern für alle DNS-Aufgaben.
Unterstützende Dienste
Die letzte Stufe der Pyramide umfasst die Supporting Services, damit sind alle Dienste gemeint, die nötig sind, um die Plattform zu installieren und zu betreiben. Die Details hängen vom konkreten Einzelfall ab. Denkbar wäre etwa, dass die Sicherheitsvorgaben des eigenen Unternehmens den Hypervisorknoten eines Virtualisierungs-Setups den direkten Zugriff aufs Internet verbieten. Dann müssten Jump-Hosts existieren, die jeweils mit einem Bein im lokalen Netz und im Internet stehen und den Zugriff auf die Virtualisierungs-Hosts regeln.
Auch Mirror-Server für das Archiv der eigenen Linux-Distribution sind dann Pflicht; schließlich sollen die Admins auch in der Lage sein, bei fehlender Internetanbindung Paket-Updates einzuspielen. Diskutabel ist schließlich, ob die eigene Virtualisierungslösung ebenfalls in Form eines separaten Dienstes und womöglich auf separatem Blech laufen sollte: Wer etwa zu Puppet mit Puppet-Master greift, braucht schon dafür diverse CPU-Zyklen. Es wäre ungünstig, wenn diese einem anderen System der Plattform im laufenden Betrieb fehlen.
Hardwareplanung
Sind grundlegende Dienste für den Betrieb der skalierbaren Plattform geschaffen und ist die Bedürfnispyramide erfüllt, geht es mit der Hardware für das Setup selbst los. Hier sind diverse Faktoren schon mit Blick auf das Blech zu beachten: Eine klare Spezifikation ist der erste Arbeitsschritt, weil sich mit ihr später Angebote von Hardwarehändlern ohne großen Aufwand einholen lasen.
Voraussetzung dafür ist allerdings, dass aus ihr klar hervorgeht, welche Server mit welcher Hardware gewünscht sind. Wer in seinem Setup unterschiedliche Servertypen braucht, muss das in der Spezifikation von Anfang an berücksichtigen: Controllerknoten für Cloudsysteme etwa brauchen besonders zuverlässige SSDs (für Datenbanken oder ähnliche Programme).
Computingknoten für Virtualisierungsumgebungen sollten die Admins hingegen mit viel CPU-Leistung und Arbeitsspeicher ausrüsten. Es schadet ebenfalls nicht, wenn die Spezifikation gleich mehrere Servertypen auflistet und der Hardwarehändler der Wahl entsprechende Angebote für die einzelnen Typen liefert.
Apropos Lieferung: Wer neue Server gleich Rack-weise anschafft, sollte bei den Verhandlungen mit seinem Händler verschiedene Punkte gleich mitverhandeln. Klar sollte etwa sein, dass Server mit den aktuellen Ständen für das Bios und sämtliche Controller-Firmware ausgestattet sind. Wer eine spezifische Bios-Konfiguration braucht, kann die bei vielen Händlern gleich ab Werk einstellen lassen.
Das klingt zwar banal, erleichtert aber im Regelfall das Deployment neuer Systeme massiv: Wer schon mal an neue Server einen mobilen Monitor samt Tastatur angeschlossen hat, um dort Bios-Schalter umzustellen, der weiß, wie zeitraubend diese Aktion ist.
Anschaffung
Sinnvoll strukturierte Hardware-Richtlinien bringen einen sehr wichtigen Vorteil mit sich: Ist einmal klar, welche Hardware anzuschaffen ist, dann ist die Bestellung weiterer Hardware eine reine Formsache. Zumindest dann, wenn in der Hardwarespezifikation exotische Komponenten außen vor bleiben: Meist setzen typische Hardwareshops auf einige Standardkomponenten, die sie entweder auf Dauer am Lager haben oder in kürzester Zeit besorgen können.
Das ist wichtig: Massiv skalierbare Setups zeichnen sich ja auch dadurch aus, dass sie in kurzer Zeit um viele Systeme zu erweitern sind. Public Clouds sind dafür das perfekte Beispiel: Kunden legen sich hier meist per Registrierung einen Zugang an und geben danach ihre Kreditkartendaten an; im Anschluss steht die Dienstleistung zur Verfügung.
In der Praxis führt solch ein Setup regelmäßig zu Situationen, in denen ein neuer Kunde auf einen Schlag viel Computing-Hardware, viel virtuellen RAM oder viel Plattenplatz für sich beansprucht. Einerseits tut der Admin also sehr gut daran, sein Setup nicht auf Kante zu nähen und regelmäßig eine Reserve von mindestens 10 Prozent vorzuhalten. Andererseits muss er aber auch für einen effektiven Beschaffungsprozess sorgen: Wenn das 10-Prozent-Limit angekratzt wird oder ein neuer Kunde mit einem Schlag mehr Ressourcen braucht als selbst mit vorgehaltener Reserve verfügbar sind, steht unweigerlich die Anschaffung zusätzlicher Hardware an. Bei sinnvoll kalkulierten Preisen wird der neue und große Kunde diese letztlich problemlos indirekt refinanzieren.
Aber aus Admin-Sicht besteht die Aufgabe vor allem darin, in kurzer Zeit viel Hardware vom Lieferanten in sein Rack zu bekommen. Wenn zumindest klar ist, welche Hardware im Falle eines Falles Rack-weise zu beschaffen ist, lässt sich der Bestellprozess schnell auslösen. Hier ist aber auch das betreibende Unternehmen gefragt: Durchlaufzeiten von Wochen für die Anschaffung neuer Hardware sind in massiv skalierbaren Setups ein Unding. Wenn die entsprechenden Prozesse also nicht effizient sind, droht der Kunde abzuwandern.
Letztlich ist das Problem also einerseits ein technisches, andererseits muss das Unternehmen auch eigene Abläufe an die neue Situation anpassen. Das alles gilt übrigens nicht nur für Server, sondern auch für alle anderen benötigten Komponenten wie Netzwerkausrüstung oder Rack-Infrastruktur (etwa PDUs).
Hardware effektiv verwalten
Wenn der Beschaffungsvorgang neuer Hardware feinjustiert ist, sieht sich der betreibende Admin regelmäßig größeren Mengen jungfräulicher Server gegenüber. Diese sind zunächst im Rack zu verbauen, dann geht es um die Frage, wie sich Hardware in massiv skalierenden Setups sinnvoll verwalten lässt.
Ein Grundpfeiler ist die ordentliche Inventarisierung: Rack Tables [1] ist für diesen Zweck gut geeignet und erlaubt das Anlegen eines Rack-Plans, in den sich auch neue Hardware integrieren lässt (Abbildung 2). Rack Tables hat Kommentarfelder, über die für spezifische Server auch Zusatzangaben möglich sind. Wenn es sich im Open-Stack-Beispiel etwa um einen Controllerknoten handelt, auf dem die wichtigsten Clouddienste laufen, wäre genau das ein heißer Kandidat für das Kommentarfeld.
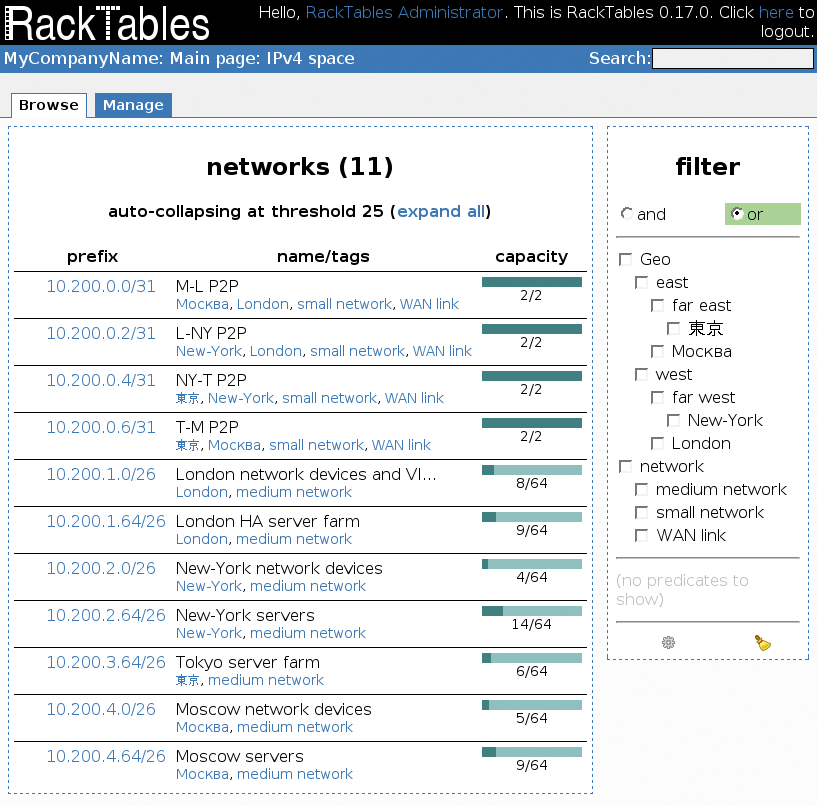
Abbildung 2: Rack Tables ist ein ausgezeichnetes Werkzeug, um eigene Ressourcen im RZ zu verwalten.
Doch Rack Tables allein reicht nicht: Wer 40 neue Server in kurzer Zeit installieren und ihrer Bestimmung übergeben möchte, braucht umfassende Management-Funktionalität. Das Ziel muss darin bestehen, den neuen Server nur noch im Rack festzuschrauben und einmal anzuschalten. Alle weiteren Schritte, etwa die Zuweisung einer IP-Adresse oder die Installation von Betriebssystem und nötiger Software, müssen danach automatisch erfolgen. Das aber bedingt ein System mit zentraler Registratur, die alle neuen Server verzeichnet und etwa per Remote-Management-Funktionen entsprechend vorbereitet.
Sisyphusarbeit
“Entsprechend vorbereiten” sagt sich dabei allerdings leichter, als es in der Realität ist. Im ersten Schritt muss eine solche Maschinenverwaltung die von neuen Servern eingehenden DHCP- und TFTP-Requests abfangen und dem Server automatisch IP-Adressen zuweisen. Weil starr auf den Servern konfigurierte IPs nicht funktionieren (Server können jederzeit verschwinden, etwa weil sie nicht mehr benötigt oder durch neuere ersetzt werden), muss das per DHCP-Protokoll geschehen.
Zwar macht das den Betrieb eines eigenen DHCP-Servers im Netzwerksegment zur Pflicht. Doch das ist die kleinere Aufgabe. Die größere besteht darin, aus der Maschinenverwaltung heraus den DHCP-Server dynamisch zu konfigurieren, sodass er für ein und denselben Server über dessen gesamte Lebensdauer dieselben IP-Adressen sowohl für die Remote-Management-Schnittstellen als auch für die System-NICs vergibt.
Ist diese Klippe umschifft, steht das lästige Thema Firmware an: Selbst in Fällen, in denen der Lieferant alle Firmware- und Bios-Versionen auf den aktuellen Stand gebracht hat, können diese bei der Lieferung schon wieder veraltet sein. Maschinen-Management muss außerdem, will es effektiv sein, auch im späteren Verlauf des Server-Lebens diesen jederzeit neu starten und Firmwares auf ihm aktualisieren können.
Es ist schließlich nicht praktikabel, 200 oder mehr Server einzeln in Rettungssysteme zu booten und dort händisch Programme der Hersteller aufzurufen, die die Firmware erneuern. Die Verwaltung der Maschinen eines massiv skalierenden Setups muss diesen kompletten Prozess per entsprechender PXE- und TFTP-Konfiguration (oder per EFI-Netboot) automatisch abwickeln können.
Anschließend folgt die Konfiguration der Hardware: Für das Remote-Management – etwa mit HPs ILO oder Dells DRAC – ist in der Regel eine Konfiguration nötig. Dazu gehört zum Beispiel auch das Setzen eines Admin-Passworts. Praktisch alle BMC-Controller bieten entsprechende Interfaces an, über die Administratoren solche Änderungen vornehmen. Die Qualität der Maschinenverwaltung trägt letztlich die Verantwortung dafür, dass dies auch tatsächlich passiert.
Die Installation des Betriebssystems
Ist der Rechner so weit wie nötig vorbereitet, steht als letzter Schritt die Installation des eigentlichen Betriebssystems an. Erst hier kommen typische Bare-Metal-Deployment-Ansätze ins Spiel: Ob mit Foreman, FAI oder einer anderen Lösung ist letztlich irrelevant. Am Ende steht im Idealfall eine Installation, deren weitere Konfiguration die gewählte Automatisierungslösung abwickelt – etwa indem der Agent von Puppet startet oder Ansible (Abbildung 3) zum Zuge kommt.
Abbildung 3: Automatisierungslösungen sind ein fester Bestandteil von Deployment-Automatismen; der gedankliche Ansatz muss allerdings viel früher bei der Verwaltung der Hardware beginnen.
Selbst danach spielt die Maschinenverwaltung noch mit: Zentral verwaltete SSH-Zertifikate etwa sind in Installationen aus Hunderten Servern sinnvoll. Diese muss die verwaltende Software für neue Server automatisch generieren und schließlich mit der Automatisierung auf die Rechner bringen.
Rack HD als Fertiglösung
Viele Unternehmen haben für ihre massiv skalierbaren Setups und die damit verbundenen Aufgaben selbst entwickelte Lösungen eingeführt. Doch die schlechte Nachricht lautet, dass sich die meisten von ihnen nicht dazu durchringen konnten, ihre Software auch unter eine freie Lizenz zu stellen und zu veröffentlichen. Der wahrscheinlichste Grund dafür ist, dass umfassende Managementlösungen immer auch Details über die Struktur eines Setups verraten, wenn sie nicht generisch gehalten sind. Je generischer sie aber sind, desto schlechter passen sie zu einem konkreten Setup.
Eine löbliche Ausnahme macht ausgerechnet der Storage-Dino EMC: In Form von Rack HD [2] bietet das Unternehmen eine Lösung an, die zumindest einige der beschriebenen Faktoren abdeckt (Abbildung 4). Rack HD kombiniert viele der erwähnten Protokolle: Neue Maschinen registriert die Lösung automatisch auf Grundlage ausgesandter DHCP-Anfragen. Per PXE und TFTP erhalten die Server dann ein bootbares Image, mit dem Rack HD Wartungsaufgaben erledigt.
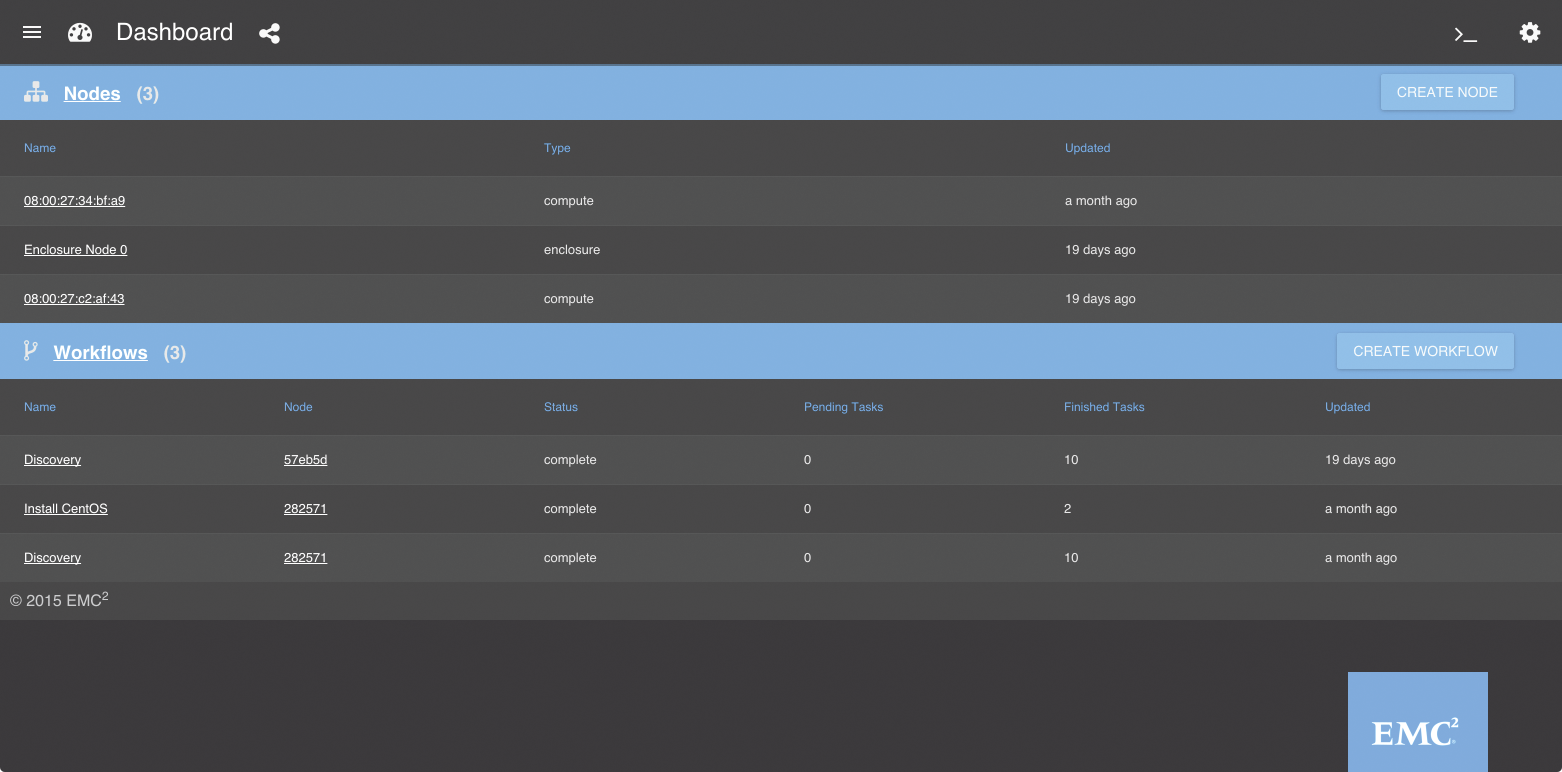
Abbildung 4: Rack HD bietet ein eigenes Webfrontend und ist bisher der beste verfügbare Ansatz für umfassendes Maschinen-Management.
Admins definieren auf Wunsch so genannte Flows: Das sind Abläufe, die genau festlegen, welche Schritte ein Server vom ersten Start bis zum installierten System durchlaufen soll. Zugleich legt Rack HD für den neu erkannten Server einen Eintrag in seiner Datenbank an. Per IPMI spricht die Lösung zudem mit den Remote-Management-Schnittstellen der Systeme und startet diese über die BMC-Schnittstelle bei Bedarf neu – etwa um das Betriebssystem (nochmals) neu zu installieren.
Beliebiger Code per Json
Über Code-Snippets im Json-Format lassen sich diese Workflows definieren. Die Freiheit des Admin reicht bis zu direkten Shellbefehlen, die sich auf dem laufenden System ausführen lassen. So ist auch ein Prozess implementierbar, der die beschriebenen Firmware-Updates einspielt. Klar ist aber auch: Rack HD in der von EMC gelieferten Standard-Variante ist vorrangig ein Werkzeugkasten, aus dem Admins sich bedienen können und müssen. Die konkrete Konfiguration von Rack HD sowie das Anlegen eigener Workflows kosten viel Zeit und setzen tiefgreifendes Verständnis der Abläufe in Rack HD voraus (Abbildung 5). Wer Rack HD für sein eigenes Setup nutzen möchte, sollte also entsprechend Zeit einplanen.
Abbildung 5: Spotify hat sich ein eigenes Deployment-System gebaut, dessen Komponenten allerdings nicht öffentlich verfügbar sind.
Gebranntes Kind: Spotify
Dass die Verwaltung großer Mengen physischer Hardware eine Herausforderung ist, haben auch große Unternehmen wie Spotify schmerzhaft gelernt: Die Firma erklärt im eigenen Blog, wie sie Systeme in der Vergangenheit verwaltet hat und wie sich diese Prozesse im Laufe der Zeit geändert haben [3]. Anfangs setzte Spotify etwa auf den Fully Automated Installer (FAI) für Debian und kombinierte diesen mit Puppet. Später ersetzte sie FAI durch den Debian-Installer und diesen schließlich durch Duck, einen von Spotify selbst geschriebenen Installationsmechanismus.
Hinzu kam ein ebenfalls selbst programmiertes Werkzeug namens Server DB, das als zentrale Registratur für die Aufzeichnung vorhandener Ressourcen verantwortlich war. Alle Komponenten waren seit 2011 jedoch immer wieder großen Veränderungen unterworfen: Aus der Server DB wurde ein auf PostgreSQL basierender Restful-Dienst, der irgendwann auch die DNS-Verwaltung der Spotify-Domäne übernahm. Doch das ganze Konstrukt war langsam und störanfällig.
Mittlerweile setzt Spotify auf Sid, was auch ein REST-API ist, und leitet im Hintergrund Befehle an Neep weiter, das seinerseits an die Messaging-Queue RQ gekoppelt ist. Auf Lingon-Basis ist für Sid ein Webinterface entstanden (Abbildung 5), über das sich Anfragen in Sid eintragen lassen. Noch immer werkelt im Hintergrund Server DB und führt Buch über physische Server.
Der Haken an der Sache: Sid, Neep oder Server DB stellt Spotify nicht auf dem eigenen Github-Account bereit [4]. Die Erläuterungen des Unternehmens lassen sich für das eigene Setup also nicht sofort umsetzen; als interessante Beschreibung dienen sie aber allemal.
Was sonst noch anfällt
Bis hierhin hat sich der Artikel im Allgemeinen mit Fragen beschäftigt, die das Layout und die Konzeptionierung von skalierbaren Setups betreffen. Für den konkreten Einzelfall greifen eventuell noch zusätzliche Bedingungen: Open Stack etwa kommt üblicherweise mit einem Netzwerkdesign daher, das eigene Gateways auf der Open-Stack-Seite voraussetzt. Diese wollen bei der Planung natürlich so beachtet sein, dass sie bei Bedarf um zusätzliche Exemplare erweiterbar sind.
Auch die genutzte Speicherlösung stellt eventuell zusätzliche Bedingungen für den reibungslosen Betrieb, die hier nicht diskutiert werden konnten.
Infos
- Rack Tables: http://racktables.org
- Rack HD: http://rackhd.readthedocs.io/en/latest/
- Spotify-Blog zum Machines-Management: https://labs.spotify.com/2016/03/25/managing-machines-at-spotify/
- Spotify bei Github: https://github.com/spotify
Der Autor

Martin Gerhard Loschwitz arbeitet als Cloud Architect bei Sys Eleven. Er beschäftigt sich dort intensiv mit den Themen Open Stack, Distributed Storage und Puppet. Außerdem pflegt er in seiner Freizeit Pacemaker für Debian.





