
© natulrich, 123RF
Praktisch jede moderne Webanwendung braucht eine Datenbank, doch das Setup von MySQL & Co. ist kompliziert. DBaaS verlagert den Dienst in die Cloud und verspricht Datenbanken per Mausklick.
Die Installation einer Datenbank wie MySQL, PostgreSQL oder auch Mongo DB ist dank Paketverwaltung schnell erledigt, doch das ist nicht einmal die halbe Miete. Denn eine funktionierende Datenbank braucht User-Accounts und diverse Konfigurationsschritte, damit sie besser performt oder besser gegen Angriffe geschützt ist. Diese zusätzlichen Einrichtungsarbeiten machen das Datenbank-Setup zu einer mühseligen und zeitintensiven Aufgabe.
Für die Cloud ungeeignet?
Was in konventionellen Umgebungen nur lästig ist, das wird in Clouds zu einem handfesten Problem. Denn Clouds erweitern die klassische Virtualisierung um den Faktor Automatisierung: Während in hergebrachten Setups der Admin also eine virtuelle Maschine händisch installiert, wollen Cloudanwender eine ganze virtuelle Umgebung aus einem Template generieren. Händisches Eingreifen ist dabei grundsätzlich nicht vorgesehen. Deshalb muss sich zum Schluss automatisch eine fertige Datenbank ergeben.
Mehr noch: Eigentlich soll der Kunde mit dem Setup der Datenbank gar nicht mehr behelligt werden. Stattdessen soll sie als Dienst innerhalb der Cloud per Mausklick verfügbar sein. Was dann im Hintergrund passiert, ob also etwa eine virtuelle Maschine startet und darin MySQL installiert und konfiguriert wird, das ist dem Cloudanwender letztlich egal. Er nutzt allein den Speicherdienst.
DBaaS gewinnt
Solche Produkte gibt es bereits, etwa bei Amazon. Das Konzept hat einen Namen: “Database as a Service” (DBaaS). Es soll den Cloudkunden die Nutzung einer Datenbank so einfach wie möglich machen. Amazon hat in seiner Wolke DBaaS als Funktion bereits seit Jahren, auch Cloudlösungen wie Open Stack kennen mittlerweile entsprechende Features.
Im Gegensatz zur Lösung von Amazon lässt sich anhand von Open Stack aber auch erklären, wie eine DBaaS-Lösung für Clouds unter der Haube aussieht und welche Ziele dem Design zugrunde liegen. Der folgende Artikel stellt die DBaaS-Lösung von Open Stack – Trove – vor und geht auf deren wichtigste Funktionen ein.
Trove [1] existiert bereits seit mehreren Jahren. Anfänglich hatte der Dienst es nicht leicht und seine Entwickler brauchten mehrere Anläufe, um Trove zum offiziellen Teil des Open-Stack-Programmpakets zu machen. Das erklärte Ziel von Trove ist es, den kompletten technischen Unterbau einer Datenbank vor den Augen des Nutzers zu verstecken. Der Kunde fordert bloß noch eine Datenbank an – etwa MySQL – und erhält im nächsten Schritt deren Zugangsdaten. Wie die Datenbank im Hintergrund realisiert ist, bleibt ihm verborgen.
Damit der Kunde den Datensilo effektiv nutzen kann, gibt er ihm Konfigurationsparameter mit auf den Weg – etwa eine Liste der Benutzerzugänge, die in ihm nach dem Start automatisch verfügbar sein sollen. Analog zu virtuellen Maschinen ist die Datenbank ein eigener Servicetyp, für den innerhalb des Open-Stack-GUI auch ein eigenes Menü zur Verfügung steht. Damit all das funktioniert wie gewünscht, müssen im Hintergrund allerdings viele Komponenten zusammenarbeiten.
Die Architektur der Lösung
Das Trove-Design folgt in vielen Aspekten den Vorgaben, mit denen schon andere Open-Stack-Dienste leben: Im Kern besteht die Lösung aus einem API und einer Komponente, die Befehle im Hintergrund ausführt und an das API sendet. Wie alle Open-Stack-APIs folgt auch das von Trove dem Restful-Prinzip und lässt sich per HTTP bedienen. Der Taskmanager – die ausführende Komponente – ist direkt an das API gekoppelt, sodass er eingehende API-Anfragen sieht.
Hinzu kommt der Trove-Conductor: Er dient als Anlaufstelle für die Guest Agents, die ebenfalls zu Trove gehören und innerhalb der VM spezifische Aufgaben erledigen. Für die Kommunikation zwischen dem Guest Agent innerhalb der VM und dem Trove-Taskmanager spielt der Conductor quasi den Proxyserver. Die gesamte Kommunikation mit anderen Komponenten von Open Stack erfolgt über API-Aufrufe bei den anderen Diensten (Abbildung 1).
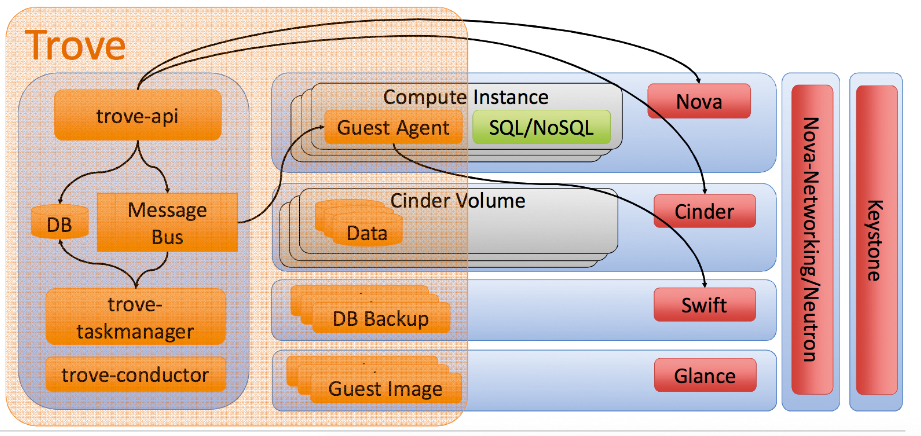
Abbildung 1: Die Trove-Architektur folgt im Wesentlichen der anderer Dienste in Open Stack – das API nimmt Befehle entgegen, der Taskmanager setzt sie um.
Für die Kommunikation mit dem API stehen zwei Möglichkeiten offen: Nutzer haben die Wahl zwischen einem Kommandozeilen-Client (CLI) oder einem Plugin für das Open-Stack-Dashboard Horizon (Abbildung 2). Wie üblich unterstützt der CLI diverse Befehle, die im Webinterface nicht auftauchen. Wer also den vollen Umfang der Trove-Funktionalität will oder braucht, kommt um die Konsole nicht herum.
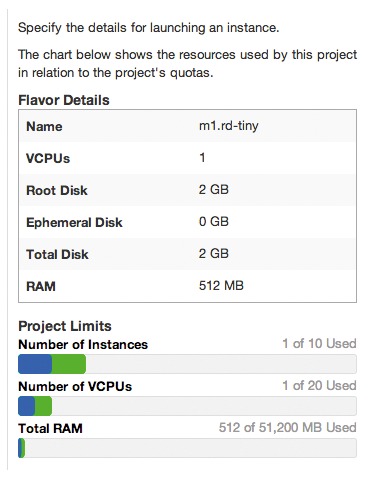
Abbildung 2: Im Open-Stack-Dashboard Horizon lassen sich beim Starten von Datenbanken die gleichen Parameter festlegen wie bei VMs.
Egal, ob Befehle an das Trove-API per GUI oder CLI gesendet werden: Sobald ein Befehl beim API eingeht, kümmert sich der Taskmanager um dessen adäquate Umsetzung. In den meisten Fällen bedeutet das, eine neue VM zu starten und in ihr die notwendige Datenbank zu installieren und zu konfigurieren. Das geht mit dem bereits erwähnten Guest Agent, der innerhalb der VM wie ein verlängerter Arm des Taskmanagers agiert und – anders als die anderen Trove-Komponenten – ein Unikum im Open-Stack-Universum ist.
Eigene Images
Damit steht fest, dass sich die handelsüblichen Distributionsabbilder direkt von Canonical oder Red Hat für die Nutzung von Trove nicht eignen – ihnen fehlt der Guest Agent von Trove (Abbildung 3). Für Admins bedeutet das mehr Arbeit: Damit sich ein Abbild mit Trove nutzen lässt, ist es um die nötige Komponente zu erweitern. Die Trove-Entwickler erklären in einem separaten Dokument, wie das Bauen von Trove-spezifischen Abbildern funktioniert [2] und stellen auch eigene Tools bereit (Abbildung 4).
Abbildung 3: Der Trove-Guest-Agent kümmert sich innerhalb einer VM darum, die Datenbank wie gewünscht auszurollen. Im Innern basiert er auf Templates.
Abbildung 4: Mit dem »disk image create«-Werkzeug legen Admins sich eigene Images für die Nutzung in Trove an. Die sind nötig, weil Standardimages der Guest Agents fehlen.
Das ist aber nur ein schwacher Trost, denn Admins handeln sich bei Trove mit den nötigen Images automatisch neue Komponenten ein, die auch in Updatezyklen und die üblichen Wartungsarbeiten integriert sein wollen. Immerhin genügt es, Trove-Abbilder nur für eine Distribution zu bauen, etwa Ubuntu. Im laufenden Betrieb treten die Trove-VMs nämlich ohnehin nicht wie VMs auf, sondern nur über die in ihnen laufende DB.
Auf den Guest Agent innerhalb der VM kommen diverse Aufgaben zu. Er kümmert sich um die Installation aller benötigten Pakete und startet die Datenbank so, dass sie gemäß den Vorgaben des Nutzers funktioniert. Auch Nutzer richtet der Agent für die Datenbank so ein, wie vom Anwender vorher festgelegt. Je nach gewählter Datenbank sind die Arbeiten, um die sich der Guest Agent kümmern muss, mehr oder weniger aufwändig: Für die Installation einer MySQL-Instanz fallen weniger Arbeitsschritte als für einen Redis-Cluster an.
Den Typ der gewünschten Datenbank gibt der Admin beim Starten einer Trove-Instanz mit an, und je nach Vorgabe ruft der Agent unterschiedliche Templates auf, um zum gewünschten Resultat zu kommen. Das bietet Spielraum für Modifikationen durch den Betreiber der Plattform: Weil der Guest Agent bereits beim Bauen des oben genannten Trove-Abbilds in dasselbe eingebaut wird, lässt sich sein Verhalten während des Image-Baus nach Wunsch verändern.
Zwar nimmt Trove dem Nutzer viel Arbeit ab, wenn es um das Einrichten der Datenbank geht. Die Möglichkeiten, die einem Admin beim händischen Setup in einer virtuellen Maschine zur Verfügung stünden, bietet aber auch Trove: Beim Start der DBaaS-Instanz hat der Nutzer etwa die Wahl, welches Hardwareprofil die Datenbank nutzt. Das macht sich mindestens im Geldbeutel bemerkbar, denn je potenter eine Instanz in Sachen virtueller Hardware ist, desto mehr Geld will der Cloudanbieter für sie üblicherweise sehen.
Natürlich darf der Nutzer sich auch aussuchen, ob die Datenbank auf dem lokalen Speicher eines Hypervisors oder auf einem Volume liegen soll. Hier ist es in den meisten Fällen eine gute Idee, auf Volumes zu setzen – auch wenn das vielleicht zu Einbußen bei der Performance führt. Darüber hinaus bietet eine DBaaS-Instanz die gleichen Möglichkeiten, die auch eine normale Instanz in Open Stack bietet. Per Mausklick kann der Admin die Datenbank also neu starten, löschen oder ihr Hardwareprofil verändern (um etwa ein größeres auszuwählen).
Der Wert einer Lösung wie Trove steht und fällt mit der Zahl der unterstützten Datenbanken. Trove liefert Support für die wichtigsten Vertreter der Gilde: MySQL lässt sich etwa genauso wie PostgreSQL verwenden. Auch Redis und Couch DB bereiten Trove keine Probleme, und Mongo DB war die “Ursuppe” und die erste von Trove offiziell unterstützte Datenbank, die Trove bis heute auch am besten beherrscht.
Ein wichtiger Vertreter aus dem Enterprise-Markt fehlt allerdings: Den Platzhirsch Oracle suchen Admins in Trove vergeblich, wenn sie nicht auf die kommerzielle Variante von Tesora setzen wollen. Auch andere bekannte relationale Datenbanken wir Microsofts SQL Server oder IBM DB2 sind nicht im Angebot.
Orchestrierung und Clustering
Von großer Bedeutung für den Erfolg von Trove ist die Integration in andere Open-Stack-Dienste, allen voran die Orchestrierungslösung Heat. Denn DBaaS ist praktisch nutzlos, wenn sich Datenbank-Instanzen nur händisch starten und verwalten lassen. Die Open-Stack-Entwickler wissen das und haben bereits in der Open-Stack-Version 2014.1 (Icehouse) umfassende Integration von Trove für Heat eingebaut. So steht etwa der Ressourcen-Typ »OS::Trove:Instance« für native Heat-Templates zur Verfügung, der eine DBaaS-Instanz startet und dieser auch gleich die benötigten Credentials mit auf den Weg gibt. Auch für Cluster aus mehreren Datenbank-Knoten liefert die Heat-Integration für Trove alles mit, was für den Alltag nötig ist.
Die Königsdisziplin in Sachen DBaaS bilden Datenbank-Lösungen, die über eigene Clustermechanismen verfügen. Hier multipliziert sich nämlich die Komplexität, mit der die DBaaS-Implementation zurechtkommen muss: Während bei einzelnen DBaaS-Instanzen nur eine VM zu starten ist, müssen im Cluster-Fall mehrere Instanzen starten und so aufeinander abgestimmt sein, dass am Ende ein funktionierender Datenbank-Cluster entsteht.
Die Trove-Entwickler haben in der Open-Stack-Version 2015.1 (Kilo) an mehreren Stellen Clusterfunktionen eingebaut, das Paradebeispiel für DBaaS-Clustering ist zweifellos Mongo DB. Kein Wunder: Mongo DB ist ab Werk darauf ausgelegt, als Clusterverbund zu laufen.
Für die Clusterfunktionalität von Datenbanken haben die Trove-Entwickler extra eine Erweiterung ihres API geschrieben. Diese sieht vor, dass es neben dem Instanzentyp »Instance« – also einer einzelnen Datenbank – auch den Instanzentyp »Cluster« gibt. Startet der Admin eine Clusterinstanz und gibt dabei alle nötigen Parameter an, etwa die Gesamtzahl der notwendigen Instanzen, kümmert sich Trove zuverlässig um den Rest.
Mit einem Umweg über Perconas Xtra DB kommt Trove inzwischen sogar mit Galera zurecht und baut aus mehreren Galera-Instanzen einen funktionalen Cluster. Die Trove-Funktionalität ist dabei strikt auf das Thema Datenbank begrenzt. Wie also etwa der Zugriff auf Galera funktioniert, überlässt Trove dem Nutzer.
Überlegungen zur Performance
Beschäftigen sich Admins zum ersten Mal mit DBaaS, vergessen sie oft ein wichtiges Kriterium: die Performance der Datenbank. Die ist aber keineswegs zu vernachlässigen: Die meisten Webanwendungen sind beispielsweise unbedingt darauf angewiesen, dass die Datenbank im Hintergrund zuverlässig und schnell funktioniert. Wer bei Performance zuerst an Bandbreite und Durchsatz denkt, liegt hier aber falsch: Kritisch für die Verwendung von Datenbanken innerhalb von Clouds ist meist die Latenz.
Die Gründe dafür werden schnell klar, schaut man sich typische Clouds aus der Nähe an: Fast alle Projekte, darunter auch Open Stack, bevorzugen skalierbaren Objektspeicher. Zum Einsatz kommen Lösungen wie Gluster FS oder Ceph. Alle verteilten Speicherlösungen setzen auf klassisches Ethernet, um Daten zwischen den einzelnen Platten der Installation auszutauschen. Das hat aber eine deutlich höhere inhärente Latenz als beim Zugriff auf eine lokale Platte.
Weil alle Datenspeicher auch synchron arbeiten, bekommt die auf ihnen laufende Applikation diese Latenz voll ab. Wenn also eine VM auf einem Ceph-Volume liegt, dauern Schreibvorgänge auf den lokalen VM-Speicher deutlich länger als auf echtem Blech. Wer eine Applikation vom Blech in die Cloud schiebt, sieht sich also mit deutlich höheren Latenzen als zuvor konfrontiert.
Das muss nicht zwingend ein Problem sein: Wer keine High-End-Datenbank für seine Applikation benötigt, wird auch mit einer typischen DBaaS-Datenbank keine Probleme haben – auf entsprechend konfiguriertem Speicher liefert auch diese 1000 IOPS und mehr. Hier hilft nur konsequentes Messen und bei einer Migration in die Cloud auch das Vergleichen von altem und neuem Setup.
Wer merkt, dass die Anforderungen mit einer DBaaS-basierten Datenbank in einer Cloud-VM nicht zu befriedigen sind, muss jedoch Alternativen suchen: Denkbar wäre zum Beispiel eine eigene Open-Stack-Zone, in der nur Server mit schnellem, lokalem Flash- oder Fusion-IO-Speicher arbeiten. DBaaS-VMs könnten dann wahlweise auf langsamerem, repliziertem Speicher laufen oder auf dem schnellen Speicher, der dafür ohne Replikation arbeitet.
Backups und Snapshots
Weil die virtuelle Maschine bei DBaaS selbst nicht mehr direkt erkennbar ist, gestalten sich auch die anfallenden Wartungsarbeiten anders als bei einem klassischen DB-Setup. Ein gutes Beispiel dafür sind Backups sowie Snapshots: Meist legen Admins Backups von Datenbanken in solchen Setups an, indem sie direkt auf den Hosts passende Programme laufen lassen.
Weil das bei Trove, das die Hosts hinter der Datenbankfunktion versteckt, nicht ohne Weiteres geht, haben dessen Entwickler sich Alternativen ausgedacht: Trove hat eigene Funktionen für Backups und Snapshots – in Trove bezeichnet der Begriff letztlich exakt die gleiche Sache. Anders als vielleicht erwartet, greift dabei aber nicht der Guest Agent ein. Stattdessen speichert Trove über die internen Snapshot-Funktionen des VM-Dienstes Nova und des Volume-Dienstes Cinder einen Snapshot des Volume, das zur DBaaS-Instanz gehört. Dabei sind sowohl vollständige als auch inkrementelle Backups möglich.
Als Ort für die Ablage der Snapshots dient ein Objektspeicher, zum Beispiel Swift. In seiner eigenen Metadaten-Datenbank merkt sich Trove schließlich, wo es den jeweiligen Snapshot abgelegt hat. Später lässt sich auf diese Weise der Zustand sämtlicher Snapshots wiederherstellen. Der Kunde merkt von alledem übrigens nichts: Er ruft lediglich die Backup- und Restore-Funktionen des Trove-API per CLI oder Webinterface auf.
Kommerzielle Lösung von Tesora
Das amerikanische Unternehmen Tesora [2] beteiligt sich massiv daran, Trove in Open Stack weiterzuentwickeln. Allerdings wohl nicht ganz uneigennützig: Die Firma bezeichnet sich selbst als Enterprise-Anbieter von DBaaS mit Open Stack und ist im Markt mit einem eigenen Produkt für diesen Zweck vertreten. Die auf den Namen “Tesora Enterprise” getaufte Software rüstet in Trove viele Features nach, die Admins laut Hersteller schmerzlich vermissen. Dazu gehört besonders der Support für mehr Datenbanken: Zusätzlich zu den Datenbanken, die Trove ab Werk beherrscht, bietet die Tesora-Variante auch Oracle und mehrere Flavors von MySQL, etwa Percona Xtra DB oder Maria DB.
Außerdem enthält Tesora ein eigenes Dashboard-Plugin für DBaaS, über das sich mehr Parameter verändern lassen als mit dem Original aus Open Stack (Abbildung 5). Fertige Gast-Abbilder sollen Admins die Pflege von Trove im laufenden Betrieb erleichtern, weil das Neubauen solcher Abbilder durch den Cloudanbieter nicht mehr nötig ist. Die Enterprise-Version von Tesora enthält sogar für kommerzielle Datenbanken fertige Gast-Abbilder. In Sachen Sicherheit bietet das Produkt verschiedene Methoden fürs Härten der Datenbank, die in Trove fehlen. Clustering – besonders für MySQL – lässt sich in Tesora laut Hersteller besser durchführen als in Trove von Open Stack.
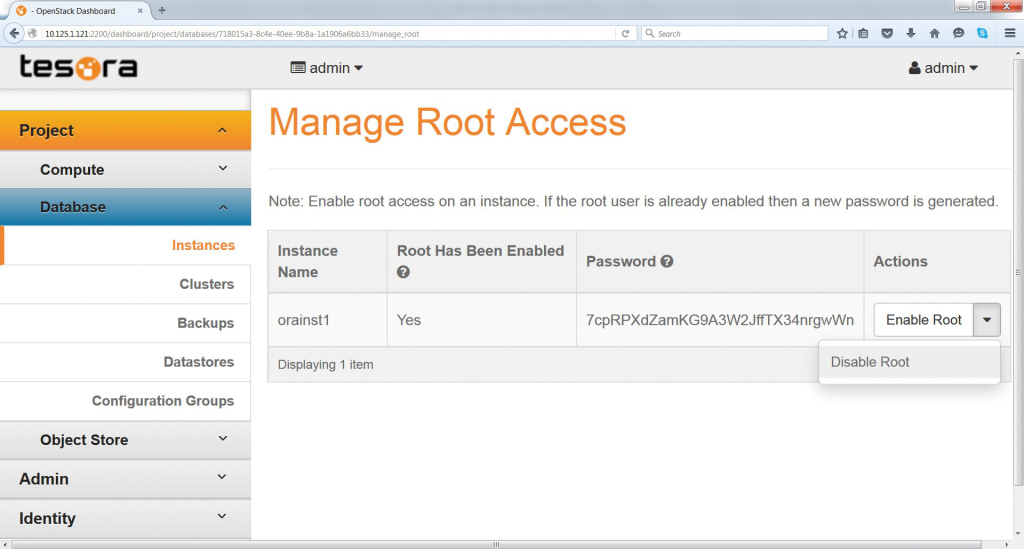
Abbildung 5: Tesora hat das GUI für seine Open-Stack-Lösung aufgemotzt und bietet obendrein Support für mehr Datenbanken, auf Wunsch auch rund um die Uhr.
Schließlich offeriert Tesora für sein Trove-Produkt auch Support bis hin zu einem 24/7-Modell. Für Firmen, die kritische Applikationen mit DBaaS-Datenbanken betreiben, dürfte dieses Supportangebot wohl das wichtigste Argument sein, denn die Open-Stack-Anbieter selbst bieten Support für Trove nur im Rahmen des normalen Supports, der bei praktisch allen fertigen Open-Stack-Distributionen Teil des Pakets ist.
Über den Preis der Tesora-Enterprise-Edition schweigt sich die Website des Unternehmens zwar aus; Interessierte haben aber die Möglichkeit, das Produkt als Trial-Version auf [3] zu erhalten und 60 Tage zu testen. Die sprichwörtliche Katze im Sack kauft man also nicht. Wer gar kein Geld bei Tesora lassen möchte, hat immerhin noch Zugriff auf die Community-Edition des Produkts – bei der sind allerdings keine kommerziellen Komponenten mit berücksichtigt und auch Support fehlt vollständig.
Zwar hat sich der Artikel bis hierhin vornehmlich mit der Open-Stack-Lösung für DBaaS beschäftigt, doch lässt sich ein vergleichbares Prinzip auch ohne Cloudinfrastruktur und mithin außerhalb von Open Stack & Co. realisieren. Der Admin nimmt dabei allerdings Abstriche in Kauf: Wenn DBaaS nicht direkt in die Managementfunktionen der Virtualisierung eingebaut ist, lässt eine DB sich auch nicht als eigene Ressource verwalten. In den Augen von Puristen ist dieser Ansatz also kein echtes Database as a Service – dafür lässt er sich auch in konventionellen Virtualisierungsumgebungen nutzen.
Alternative mit Ansible
Der Hebelpunkt ist die virtuelle Maschine selbst: Wer DBaaS ohne die erwähnte Integration in die Managementfunktionen der Umgebung baut, setzt auf eine automatisierte VM auf, in der zusätzlich auch die Datenbank automatisch aufgesetzt wird. Die konkrete Umsetzung bleibt den Vorlieben des jeweiligen Admin überlassen: Praktisch jede Automatisierung bringt das Rüstzeug mit, um verschiedene Datenbanken zu bearbeiten. Damit ist es zweitrangig, ob Puppet, Chef, Ansible oder andere Lösungen dies erledigen. Das folgende Beispiel setzt auf Ansible und geht den Prozess anhand von MySQL durch.
Ähnlich dem Prinzip, das auch Trove in Open Stack nutzt, ist das Deployment gut in mehrere Schritte einzuteilen. Im ersten geht es nur darum, die Datenbank tatsächlich zu installieren. Schritt zwei versorgt die installierte Datenbank mit der gewünschten Konfiguration und startet sie schließlich neu. Im dritten und letzten Schritt erfolgt das Anlegen benötigter Nutzer, damit eine fiktive Anwendung MySQL tatsächlich auch nutzen kann.
Installation und Konfiguration
Im Netz finden sich gleich mehrere fertige Ansible-Rollen, sie erlauben die Installation und Konfiguration des Pakets. Beispiele sind [4] sowie [5]. Beide funktionieren grundsätzlich gleich und unterscheiden sich nur darin, wie der Admin zu konfigurierende Parameter festlegt. Um mit einer der beiden Rollen zu einer funktionierenden Datenbank zu kommen, legt er für Ansible eine entsprechende Inventardatei an und vermerkt den Host, auf dem MySQL landen soll, etwa als eigene Host-Gruppe.
Den Rest erledigt ein eigenes Playbook, das die MySQL-Rolle dieser Hostgruppe zuweist. Im Playbook legt der Admin auch die Parameter fest, die die Rolle für die Konfiguration von MySQL nutzen soll. Das Ausführen des Playbooks führt dann bereits zu einem lauffähigen MySQL auf dem Zielsystem.
Ansible bietet über so genannte Module Zusatzfunktionen. Das Modul mit dem Namen »mysql_user« eignet sich perfekt, um Nutzer in MySQL anzulegen. Weil es »mysql« im Hintergrund aufruft, muss der Benutzer, als der Ansible auf dem Zielsystem Befehle aufruft, eine passende Konfigurationsdatei für »mysql« haben. Diese befindet sich im persönlichen Verzeichnis und heißt ».my.cnf« . Die in ihr abgespeicherten Zugangsdaten sollten jedenfalls zu einem MySQL-Nutzer gehören, der neue Zugänge anlegen und Berechtigungen vergeben darf. Falls das der Fall ist, lässt sich ein geeigneter Benutzer einfach per Task mit »mysql_user« kreieren.
Die Dokumentation des Moduls [6] verrät alle nötigen Details. Auf die gleiche Weise lassen sich mit dem Modul »mysql_db« auch Datenbanken anlegen [7].
Fazit
DBaaS in Clouds macht das Thema Datenbank fit für die Zukunft. Es bietet eine Abstraktionsebene, die es auch unerfahrenen Anwendern erlaubt, sich den nötigen Datentresor innerhalb einer Cloudumgebung anzulegen. Trove in Open Stack zeichnet sich obendrein durch seine perfekte Integration in die Orchestrierung von Open Stack aus. Durch sie lassen sich Datenbanken sogar automatisiert aus Templates heraus anlegen.
Der mühsame Umweg über ein virtuelles System samt händischer Konfiguration entfällt, weil bei DBaaS die nötigen Arbeitsschritte durch die Cloud selbst erledigt werden. Wer nicht in einer Cloud unterwegs ist, kann mittels einer Automatisierungslösung wie Chef oder Ansible zumindest einen großen Teil der Automatisierung auch ohne DBaaS- Komponente erledigen.
Infos
- Trove: https://wiki.openstack.org/wiki/Trove
- Guest-Images bauen: http://docs.openstack.org/developer/trove/dev/building_guest_images.html
- Tesora: http://www.tesora.com/database-as-a-service/
- MySQL für Ansible, Nr. 1: https://github.com/geerlingguy/ansible-role-mysql
- MySQL für Ansible, Nr. 2: https://github.com/bennojoy/mysql
- MySQL-Nutzer in Ansible anlegen: http://docs.ansible.com/ansible/mysql_user_module.html
- MySQL-Tabellen in Ansible anlegen: http://docs.ansible.com/ansible/mysql_db_module.html





