
© keiphotostudio, 123RF
Eigentlich soll mit Solid State Drives automatisch alles einfacher und schneller gehen. Das heißt aber nicht, dass es nicht auch hier noch Optimierungspotenzial gäbe. Dieser Artikel zeigt, worauf beim Zusammenspiel von Linux und SSDs zu achten ist.
Genauso wichtig wie die Hardware, also die Flashchips in der SSD, ist ihre Firmware. Denn auf die physischen Eigenschaften der EEPROM-Zellen sind spezielle Softwaremechanismen wie Wear Leveling und Garbage Collection abgestimmt, ohne die die Haltbarkeit und Performance der SSD im Laufe der Nutzungszeit sinken würde. Damit bildet die Firmware einen wichtigen Teil des Produkts, der auch weiterentwickelt wird. Folglich sind Updates ein Thema.
Firmware updaten
Linux-Anwender schauen da oft neidisch auf Windows, denn eine grafische Oberfläche, über die sich neue Firmwareversionen per Mausklick einspielen ließen, bekommen sie nicht. Intel und Samsung bieten zumindest für die Datacenter-SSDs Linux-Binaries, bei den Consumerprodukten müssen die Anwender eine ISO-Datei booten. Übrigens: Wer viele SSDs hinter einem Raid-Controller in Betrieb nehmen will, der sollte erst deren Firmwareversion prüfen. Sind sie erst Teil des Raid, funktioniert kein Update mehr.
Alignment
Zu Beginn der Verbreitung von SSDs war korrektes Alignment [1] bei den gängigen Werkzeugen für die Partitionierung noch nicht implementiert. Heute achten Kommandozeilen-Programme wie etwa »fdisk« , »gdisk« oder »parted« auf die korrekte Ausrichtung der Partitionen, dass also beispielsweise die erste Partition bei Sektor 2048 beginnt. Wie der Administrator eine neue Partition korrekt anlegt und mit »align-check« prüft, demonstriert das Beispiel in Listing 1.
Listing 1
Korrekt ausgerichtete Partition anlegen
01 $ sudo parted /dev/sdb mklabel gpt 02 $ sudo parted -a optimal -- /dev/sdb mkpart primary 0% 100% 03 $ sudo parted /dev/sdb align-check opt 1 04 1 aligned 05 06 $ sudo gdisk -l /dev/sdb 07 [...] 08 Number Start (sector) End (sector) Size Code Name 09 1 2048 390721535 186.3 GiB 8300 primary
Over Provisioning
Alle SSDs verfügen über eine so genannte Spare Area, also einen reservierten Datenbereich, der für das Betriebssystem nicht direkt sichtbar ist und den die SSD intern für das Wear Leveling, für das Ersetzen defekter Blöcke (Bad Block Replacement) sowie für Read- Modify- und Write-Operationen nutzt.
Besonders bei günstigen Consumer-SSDs ohne Trim-Funktion ist das Vergrößern der Spare Area – das so genannte Over Provisioning – ein gutes Mittel, um Haltbarkeit und Performance zu erhöhen. Enterprise-SSDs werden dagegen bereits mit einer höheren Bruttokapazität ausgeliefert und vertragen mehr Schreiboperationen, weisen also einen größeren Wert für Terrabytes Written (TBW) aus. Die der Abbildung 1 zugrunde liegende SSD vom Typ DC S3500 ist bei 300 GByte standardmäßig mit 336 GByte an Flashchips ausgestattet. Die Grafik zeigt für das 800-GByte-Modell, wie die Schreib-Performance mit einer größeren Spare Area steigt.
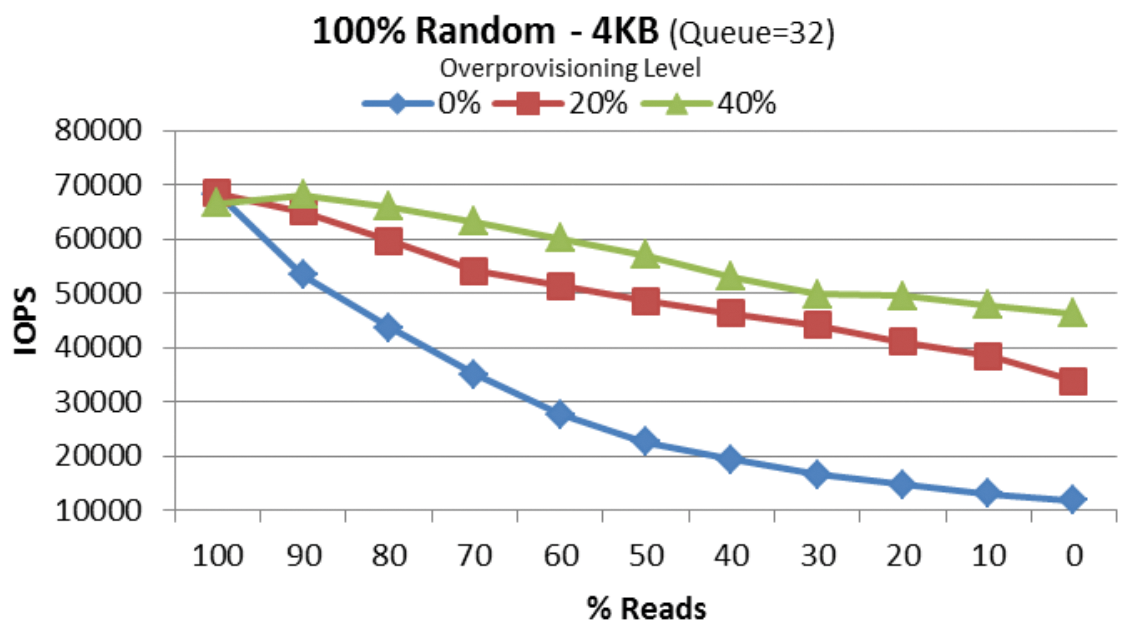
Abbildung 1: 20 Prozent Over Provisioning steigert bei einer Intel DC S3500 mit 800 GByte die Write-IOPS von rund 12000 auf etwa 33000 IOPS, mit 40 Prozent sogar auf über 47000 IOPS. Für reine Lesezugriffe bleibt die Performance unverändert.
Am besten richtet man Over Provisioning ein, bevor eine SSD produktiv in Betrieb geht. Für das Konfigurieren gibt es mehrere Möglichkeiten: Die erste Methode besteht im Einrichten einer Host Protected Area (HPA) mit »hdparm« . Dafür müssen alle Blöcke der SSD gelöscht sein. Nur so kann der SSD-Controller die ausgeblendeten Datenbereiche später tatsächlich für Wear Leveling nutzen. Die Blöcke sind gelöscht, wenn sich die SSD noch im Auslieferungszustand befindet. War sie hingegen schon in Benutzung, ist dieser Zustand durch ein Secure Erase oder manuelles Trim (je nach SSD) wieder erreichbar. Ein
hdparm -Np Anzahl_Sektoren /dev/sdb
richtet anschließend die Host Protected Area ein.
Bei der zweiten Methode lässt der Admin einfach einen Bereich der SSD unpartitioniert und legt zum Beispiel für nur 90 Prozent der Kapazität Partitionen an. Auch hier sollte ein Secure Erase vorangehen, wenn die SSD zuvor bereits in Benutzung war. Der Vorgang löscht alle Flashzellen und gibt sie frei.
Bei der dritten Methode greift der Admin auf SSD-Tools der Hersteller zurück, etwa Intels »isdct« oder Samsungs »magician« .
Das Trim-Kommando
SSDs kennen ein Kommando, das dem Device mitteilt, welche Datenblöcke nicht mehr in Verwendung sind. Denn anders als herkömmliche Festplatten können SSDs Daten nicht einfach überschreiben, sondern müssen alte zuvor explizit löschen. Genau dies erledigt das Trim-Kommando, eine Art interne Garbage Collection, die den Controller auf nicht mehr genutzte Datenbereiche hinweist.
Würde man auf Trim verzichten, dann könnte der Controller Bereiche zunächst nicht wiederverwenden, die auf Dateisystem-Ebene längst als erneut beschreibbar markiert sind [2]. Andererseits würde er weiterhin Teile bereits gelöschter Daten in seine Garbage Collection einbeziehen und so unnötige Arbeit verrichten.
Zu Beginn der SSD-Ära wurde diesem Mehraufwand durch die Mount-Option »discard« entgegengewirkt, was einem automatischen Trim nach Datei-Operationen entspricht. Heute hat sich das so genannte Batched Discard durchgesetzt, das Werkzeuge wie »fstrim« anbieten. Von »discard« als Mount-Option wird inzwischen eher abgeraten.
In der Praxis handelt es sich bei Trim nämlich um keinen trivialen Vorgang, denn wenn die SSD die falschen Datenbereiche verwerfen würde, käme es zu einem Datenverlust. Solche Probleme tauchen auch tatsächlich immer wieder auf. Theodore Ts’o, der Hauptentwickler von Ext 4, rät explizit von »discard« als Mount-Option ab [3]. Unter hohen I/O-Lasten würden viele SSDs dazu neigen, falsche Blöcke zu verwerfen. Nicht so gravierend wie Datenverluste, aber dennoch ärgerlich sind die Performance-Einbußen bei Löschvorgängen mit aktiviertem »discard« .
Jede Ebene des I/O-Stack muss Trim unterstützen – vom Dateisystem über den Block Layer bis hin zum SSD-Device. Das Linux-Software-Raid via »mdraid« zum Beispiel unterstützt ab Kernelversion 3.7 »trim« . Bugs machen den Nutzern aber auch hier das Leben schwer: So mussten etwa Nutzer von Raid 0 mit Kernel 4.0.2 bereits Schlagzeilen lesen wie “Software Raid 0 on SSD’s and discard corrupts data”. [4]
Auf SATA-Ebene war im Zuge der Trim-Weiterentwicklung das Kommando als Queued Trim Command definiert. Das versprach bessere Performance, brachte aber einige prominente SSD-Hersteller unter Linux in die Bredouille. Im »libata« -Quellcode finden sich diese Hersteller auf einer Blacklist wieder, die die Queued-Trim-Kommandos deaktiviert. Summa summarum: Es ist klug, bei Consumer-SSDs lieber auf Trim zu verzichten.
Wer mit seiner SSD auf der sicheren Seite sein möchte, greift besser zu Over Provisioning. Hinter einem Hardware-Raid-Controller scheitert das Ansinnen ohnehin, weil der aktuell kein Trim an angeschlossene SSDs durchreicht. Ansonsten bräuchte es viel Zeit für Recherchen über die SSD-Firmware, den I/O-Stack und die Kernelversion.
Im Server- und Enterprise-Bereich besitzen SSDs von Haus aus eine größere Bruttokapazität und wirken damit dem fehlenden Trim entgegen. Bei Workloads mit hohen Anteilen von Create- und Delete-Operationen bietet sich »fstrim« an. Wer lieber auf Trim verzichten will, der sollte noch bedenken, dass einige Linux-Distributionen – darunter Ubuntu ab Version 14.04 – Cronjobs einrichten, die »fstrim« automatisch ausführen.
Barriers
Viele Webseiten preisen die Mount-Option »nobarrier« als Tuning-Maßnahme. Barriers stellen sicher, dass sich das Dateisystem bei einem Stromausfall in einem konsistenten Zustand befindet. Die Option »nobarrier« kann nun Dateizugriffe beschleunigen, indem sie den Mehraufwand der Synchronisation einspart. Mehrere Tutorials berufen sich darauf, dass »nobarrier« dann gefahrlos sei, wenn die SSD über Power Loss Protection (PLP) verfügt. Hinter PLP verbirgt sich ein Kondensator, der bei Stromausfall das Device einen Moment weiter mit Energie versorgt. Der Write-Cache der SSD wird so noch auf die Flashchips geflusht.
Fest steht: Ohne PLP muss der Nutzer die Option »barriers« auf jeden Fall eingeschaltet lassen, um die Datenkonsistenz nicht zu gefährden. Christoph Hellwig, einer der Hauptentwickler von XFS, rät aber auch bei PLP davon ab, »nobarrier« einzusetzen. Sein Argument: Wenn ein Device keine Cache-Flushes braucht, wird es sie auch nicht anfordern – und dann bewirkt »nobarrier« nichts. Und andersherum: Wenn »nobarrier« einen Unterschied macht, dann ist es nicht sicher wegzulassen.
“relatime”, “lazytime” und “noatime”
Dass die Option »noatime« ein Muss für SSDs ist, gilt mittlerweile als veraltet. Unter Linux aktualisiert jede Datei-Operation die Access Time der Datei (»atime« ). Die Mount-Option »noatime« lässt diesen Schritt aus, was Schreibzugriffe spart. Manche Programme setzen aber eine »atime« -Aktualisierung voraus und funktionieren mit »noatime« nicht mehr.
Zwei neue Mount-Optionen vereinen deshalb Performance mit Funktionalität und machen »noatime« überflüssig: »relatime« ist seit Kernel 2.6.30 die Standardeinstellung. Mit ihr aktualisiert Linux die »atime« nur dann, wenn sich die Datei geändert hat. Eine neue Option in Kernel 4.0 ist »lazytime« . Sie hält Aktualisierungen im Arbeitsspeicher vor, die später zusammen mit anderen Änderungen geflusht werden.
I/O-Scheduler-Performance
Zentrale Komponente im Linux Block Layer sind die I/O-Scheduler Deadline, Noop und CFQ. Sie entscheiden, wie und in welcher Reihenfolge der Kernel I/O-Requests an das Blockdevice übergibt, hier also an die SSD.
Für SSDs eignen sich am besten die Scheduler Deadline oder Noop. Der Deadline-Scheduler versucht für die Requests eine Services-Startzeit zu garantieren, dadurch kann es nicht passieren, dass einzelne Requests gar nicht an die Reihe kommen. Der Noop-Scheduler fungiert als First-in-/First-out-Queue, er reicht die Anfragen einfach an das Device durch. Welcher Scheduler aktuell eingestellt ist, verrät eine Datei im »sys« -Verzeichnis:
$ cat /sys/block/sda/queue/scheduler noop [deadline] cfq
Beim CFQ-Scheduler wird es komplizierter. Er versucht Applikationen in puncto I/O fair zu behandeln. Er ist außerdem der einzige Scheduler mit Prioritätsklassen, die »ionice« vergibt. Das kann in bestimmten Situationen vorteilhaft sein, beispielsweise könnte tagsüber ein Backup mit niedriger Priorität laufen, das andere Applikationen dann nicht mehr behindert.
Auch der CFQ-Scheduler eignet sich prinzipiell für SSDs, kann aber in puncto Performance und Latenz nicht mit Deadline und Noop mithalten (Abbildung 2). Mit Kernel 4.2 erhielt der CFQ-Scheduler allerdings einen speziellen SSD-Modus.
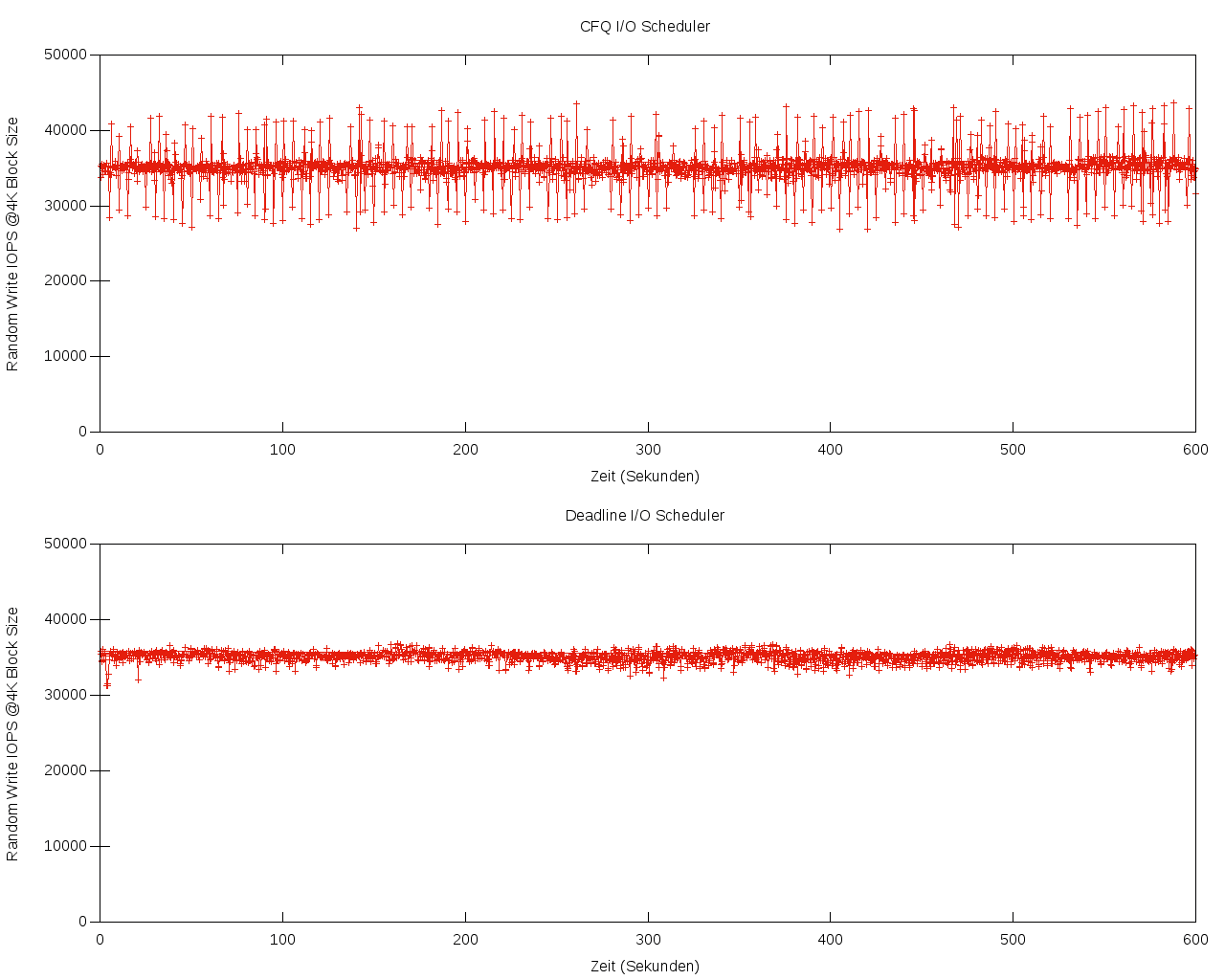
Abbildung 2: Vergleich von Deadline- und CFQ-Scheduler in einem FIO-Performancetest. Der CFQ-Scheduler oben streut deutlich stärker. Der Graph darunter stammt vom Deadline-Scheduler, seine Standard-Abweichung ist deutlich kleiner.
Schreibzugriffe verringern
Um die Flashchips der SSD zu schonen, lassen sich die Schreibvorgänge auf die SSD auf verschiedene Weise verringern. Generell besitzen heutige Consumer-SSDs eine hohe Haltbarkeit, das Thema “Verringern von Schreibzugriffen” ist daher vor allem für schreibintensive Workloads interessant.
Viele Distributionen gehen in der Standardeinstellung relativ schnell zum Swappen über, sie lagern also virtuelle Memory Pages aus dem Arbeitsspeicher (RAM) in den Swapspace auf der Festplatte oder eben der SSD aus. Über den Parameter Swappiness lässt sich steuern, ab welchem Schwellenwert der Linux-Kernel auszulagern beginnt, was seinerseits wiederum Einfluss auf die Gesamtmenge der Schreiboperationen hat:
$ cat /proc/sys/vm/swappiness 60
Ein hoher Wert (maximal 100) führt dazu, dass Linux frühzeitiger die Pages inaktiver Prozesse ausgelagert, was wiederum zu erhöhter I/O-Aktivität beiträgt. Ein niedrigerer Wert hält Pages länger im RAM und lagert sie erst aus, wenn das System unter Speichermangel leidet, weil andere Prozesse den restlichen RAM belegen. Red Hat empfiehlt einen Wert von 10 für Latenz-empfindliche Datenbanksysteme, deren Pages möglichst im RAM verbleiben sollen [5]. In einer »sysconf« -Datei lässt sich der Wert permanent anpassen:
$ sudo vi /etc/sysctl.d/60-swapiness.conf vm.swappiness=10
Eine weitere Methode, um Schreibzugriffe einzusparen, bedient sich eines temporären Filesystems. Ein Merkmal von »tmpfs« ist, dass es seine Daten im Arbeitsspeicher ablegt und eben nicht auf Platte oder SSD schreibt.
Ein gutes Beispiel für den sinnvollen Einsatz ist das Speichern von Crashdumps. Sie entstehen wegen fehlerhafter Programme, oft im Zusammenhang mit Segmentation Faults. Der Admin kann die Dateien später fürs Debugging verwenden, daher reicht es, wenn er sie temporär aufbewahrt. Die SSD wird dann nicht durch die Schreiboperationen beim Erzeugen der Dumps belastet. Die Befehle
$ mkdir /mnt/crashdumps$ mount -t tmpfs -o size=1g tmpfs /mnt/crashdumps
richten das erforderliche Umleiten des Tmp-FS ein.
SSD-Monitoring und Smart-Attribute
Beim Betrieb von SSDs ist die Haltbarkeit der Flashzellen mindestens so wichtig wie deren Performance – immerhin nutzen sich Floating Gates von Flashzellen beim Beschreiben ab. Eine Zelle hat daher nur eine begrenzte Lebenszeit, die sich in der Anzahl möglicher Program/Erase-Zyklen (P/E-Zyklen) ausdrückt. Zwei Haltbarkeits-Indikatoren beziffern den Grad der Abnutzung:
- Der Media Wearout Indicator – er steht für die Abnutzung von Flashzellen.
- Die Anzahl an übrigen Spare Blocks – Available Reserved Space.
Optimal ist, wenn der Hersteller die oben genannten Werte über Smart-Attribute an den Nutzer weitergibt. Unglücklicherweise ist die Spezifikation der Attribute wegen fehlender Standardisierung bei jedem Hersteller verschieden. Tabelle 1 verdeutlicht die Unterschiede.
Tabelle 1
Smart-Spezifikation
|
Intel |
Samsung |
Crucial |
|
|---|---|---|---|
|
Smart-Attribut-ID |
233 |
180 |
180 |
|
Attribut-Name |
Available Reserved Space |
Unused Reserved Block Count |
Unused Reserve (Spare) NAND-Blocks |
|
Attribut-Wert |
Value (in Prozent) |
Value (in Prozent) |
Raw Value, absolute Anzahl an übrigen Spare-Blocks |
Während bei Intel und Samsung zum Beispiel der Normalized Value die Anzahl an Spare-Blocks in Prozent angibt, verwendet Crucial den Raw Value. Erst mit einer Smart-Spezifikation des jeweiligen Herstellers lassen sich die Werte der Attribute richtig deuten.
Unter Linux bieten sich die »smartmontools« zum Abfragen der Werte einer SSD an. Hersteller wie Intel und Samsung entwickelten zusätzlich eigene Tools (»isdct« , »magician« ), mit denen der Nutzer auch an die Smart-Attribute gelangt. Auf der Kommandozeile ruft der Befehl »smartctl« wie in Listing 2 diese SSD-Statistiken ab (falls sie die SSD bereitstellt): Im professionellen Umfeld sollte die SSD-Überwachung in eine Monitoringlösung wie Icinga integriert sein (Abbildung 3).
Listing 2
sudo smartctl -a /dev/sdb |egrep -i ‘space|wear’
01 232 Available_Reservd_Space 0x0033 100 100 010 Pre-fail Always - 0 02 233 Media_Wearout_Indicator 0x0032 100 100 000 Old_age Always - 0
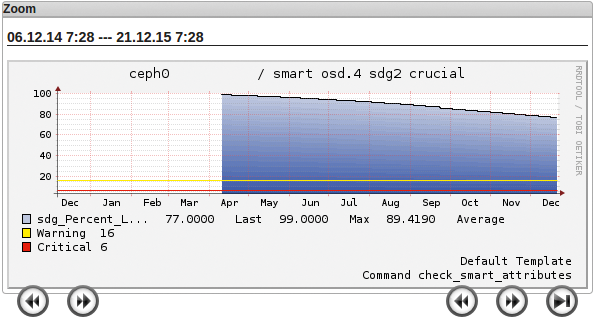
Abbildung 3: Eingebunden in ein Monitoringsystem bleibt die voraussichtliche Lebensdauer der SSD stets im Blick.
Fazit
Grundsätzlich bringt ein aktueller Linux-Kernel schon alles für den optimalen SSD-Betrieb Erforderliche mit. Der Deadline-Scheduler arbeitet außerdem gut mit SSDs zusammen. Beim Trim-Kommando steckt der Teufel im Detail, hier sollte jeder sein Setup genau prüfen, bevor er dieses Kommando regelmäßig einsetzt. Mit Blick auf die Hardware ist die Dokumentation der Smart-Attribute der eigenen SSD interessant. Für den Unternehmenseinsatz ist außerdem Power Loss Protection unerlässlich, neben dem Cache-Schutz bietet sie zudem einen Performancevorteil.
Das alles zusammen führt zu der folgenden To-do-Liste:
- Firmware der SSDs möglichst aktuell halten.
- Over Provisioning einrichten.
- Den Einsatz von Trim gründlich prüfen und im Zweifelsfall darauf verzichten.
- Wenn möglich Power Loss Protection nutzen.
- Deadline-I/O-Scheduler verwenden, beim CFQ-Scheduler den SSD-Mode einsetzen.
- Dokumentation der Smart-Attribute der eigenen SSDs besorgen und die Werte überwachen.
Infos
- Partition Alignment: https://www.thomas-krenn.com/de/wiki/Partition_Alignment
- Braucht man Trim?: http://arstechnica.com/gadgets/2015/04/ask-ars-my-ssd-does-garbage-collection-so-i-dont-need-trim-right/
- Theodore T’so zu Mountoptionen: https://lkml.org/lkml/2015/5/21/102
- Berichte über Filesystem-Korruption: https://lkml.org/lkml/2015/5/21/102
- Memory-Parameter tunen: https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Performance_Tuning_Guide/s-memory-tunables.html





