
© crisferra, 123RF
Wer Clouds oder massiv skalierte Setups mit einem konventionellen Monitoringsystem überwachen will, handelt sich Probleme ein. Das von Sound Cloud neu entwickelte Prometheus geht das Thema anders an und ist eine ernst zu nehmende Alternative zu Klassikern wie Nagios & Co.
Wo Monitoring gefragt ist, sind auch Alerting und Trending nicht weit. Alerting spielt bei praktisch allen Monitoring-Umgebungen eine große Rolle, denn schließlich gilt es, die verantwortlichen Techniker auf einen Ausfall aufmerksam zu machen. Kaum weniger wichtig ist das Trending. Gerade in massiv skalierbaren Setups hat der Anbieter großes Interesse daran, mögliche Engpässe in Sachen Performance frühzeitig zu erkennen. Nur so kann er angemessen reagieren und von vornherein kritische Probleme, etwa durch Überlastung, verhindern.
Ein Blick auf die verfügbaren Monitoring-Lösungen erklärt, warum Monitoring samt Alerting und Trending (MAT) besonders in stark ausgebauten Umgebungen nicht selten problematisch ist. Nagios, das den Markt lange dominiert hat, erweist sich vielerorts in Sachen Komplexität als Moloch und besitzt diverse inhärente Schwächen seines Designs.
Nagios-Alternativen wie Icinga haben die Situation zwar erheblich verbessert [1], geraten aber schnell an ihre Grenzen, wenn es etwa um die Skalierbarkeit des Monitoringsystems selbst geht. Die oft zwangsweise mitgeschleppte Kompatibilität zu Nagios und seinen Plugins tut ein Übriges. Ein aktuelles Thema wie Trending war im klassischen Nagios ab Werk kaum vorgesehen. Der Name PNP4Nagios [2] lässt manchen Admin schaudern, nennt aber bis heute eine der wenigen Möglichkeiten für brauchbares Trending mit Nagios (Abbildung 1).
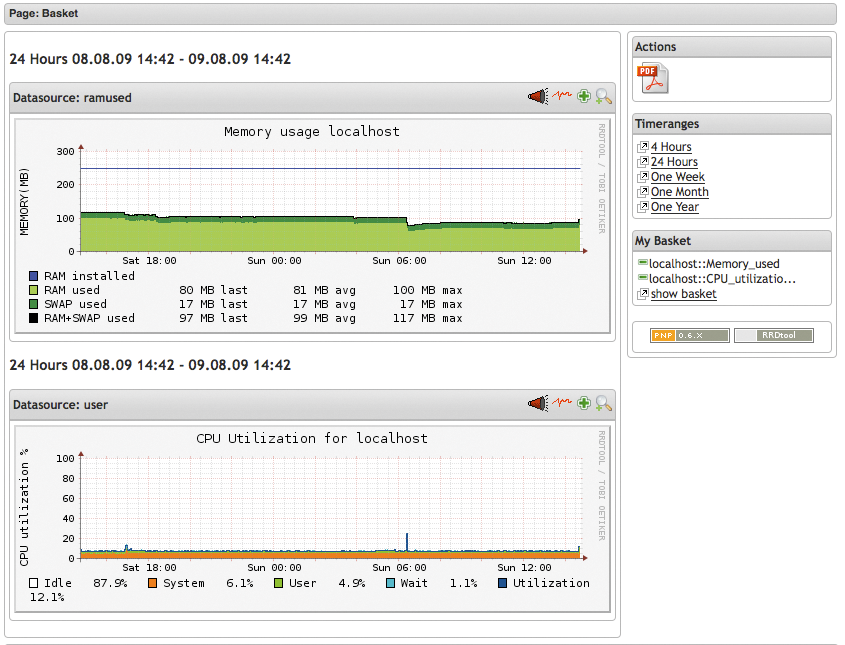
Abbildung 1: Hergebrachte Lösungen wie »pnp4nagios« verursachen beim Generieren von Grafen hohe Last und brauchen trotzdem lange – besonders beim Darstellen größerer Zeiträume.
Sound Cloud als Vorreiter
Vor der Herausforderung, ein Monitoring-Konzept umzusetzen, sah sich auch das britische Unternehmen Sound Cloud. Die Firma betreibt einen Streaming-Dienst nach den Vorbild von Spotify oder Apple Music. Die wirkliche Challenge bestand von Anfang an darin, ein MAT-System so zu bauen, dass es auch bei Tausenden Knoten noch zuverlässig funktioniert. Anstatt vorhandene Komponenten zu einer Besser-als-gar-nichts-Lösung zu kombinieren, ging Sound Cloud neue Wege. Kurzerhand entschloss sich das Unternehmen dazu, ein eigenes Monitoringsystem zu entwickeln. Heraus kam Prometheus [3].
Prometheus weist im direkten Vergleich mit etablierten Lösungen wie Nagios eine große Besonderheit auf: Es bringt sein eigenes Speichersystem mit, um die im Rechnerverbund erhobenen Daten zu verwalten. Hier gibt es eine interessante Duplizität der Ereignisse: Auch der Sound-Cloud-Konkurrent Spotify probierte erst diverse etablierte Monitoringsysteme aus, bevor er schließlich auch ein eigenes entwickelte und dabei ebenfalls auf eine selbst geschriebene Time-Series-Datenbank setzte.
Auch die interne Datenbank von Prometheus fußt auf dem Konzept der Time Series Database. Außerdem denkt Prometheus dabei eher in der Dimension einer kompletten Metrik als in einzelnen Alerts. Um zu verstehen, was das bedeutet, ist ein kleiner Ausflug in die Speicherkunde nützlich.
Wie MAT-Systeme ihre Daten verwalten
Klassische Monitoringsysteme wie Nagios oder Icinga verfügen über keine besonders ausgefeilte Datenverwaltung. De facto brauchen sie die auch nicht: Beim Monitoring ist schließlich vor allem die Frage maßgeblich, ob ein Dienst A im Moment gerade ordnungsgemäß funktioniert oder nicht. Kommt das Thema Trending hinzu, wird die Sache aber kniffliger: Trending setzt voraus, dass über die Verfügbarkeit eines Dienstes oder die Auslastung der vorhandenen Infrastruktur langfristige Aufzeichnungen existieren.
PNP4Nagios etwa nutzt im Hintergrund eine Datenbank wie MySQL, um die benötigten Werte darin lange vorzuhalten. Allerdings ist MySQL für diese Art der Nutzung eigentlich nicht ausgelegt, was zu Problemen führt. Zunächst gilt, dass in entsprechend großen Installationen die Menge zu verwaltender Daten rasant wächst. Der persistente Speicher, auf dem alle Trending-Daten liegen, sollte also genauso gut skalieren können wie die gesamte Plattform. Das gilt vorrangig im Hinblick auf den Speicher, betrifft jedoch auch die Art, wie die jeweilige Datenbank mit immer größer werdenden Datenmengen umgeht.
Darüber hinaus stellt auch das Aufbereiten der Daten eine Herausforderung dar: Die Daten trudeln beim MAT-System nämlich sortiert in zeitlicher Reihenfolge ein, müssen auf der anderen Seite aber meistens bezogen auf konkrete Dienste ausgegeben werden. Beispiel: Das MAT-System wird von seinen Zielsystemen regelmäßig Datenpunkte zu verschiedenen Diensten in zeitlicher Abfolge geliefert bekommen, also etwa “9 Uhr: CPU-Nutzung bei 1, RAM-Nutzung bei 30 Prozent und belegter Plattenplatz bei 15 Prozent”. Der Admin hingegen will meist wissen, wie hoch die CPU-Last in einem bestimmten Zeitraum war, also etwa zwischen 9 Uhr und der gleichen Zeit am vorherigen Morgen.
In jedem Fall ist das Speichern der Daten ein Kompromiss, denn die Werte sind entweder beim Ablegen in der Datenbank oder beim Auslesen durch den Administrator zu transponieren. Das allerdings ist eine ausgesprochen Ressourcen-hungrige Angelegenheit und gerade MySQL-Datenbanken sind mit entsprechenden Queries etwa von PNP4Nagios gern lange beschäftigt.
Hier kommt nun das Prinzip der Time Series Database ins Spiel. Denn im Grunde ist eine Time Series Database nichts anderes als eine Datenbank, die auf das Speichern von Daten in zeitlicher Relation ausgelegt ist; dadurch unterscheidet sie sich maßgeblich von klassischen Datenbanken wie MySQL. Das Umrechnen der Daten findet – das ist der Clou – über Algorithmen direkt in der Datenbank statt. Im Grunde bietet eine Time Series Database wie Prometheus bereits über ihr Datenmodell alle Funktionen, die für Trending notwendig sind.
Typisches Monitoring ist dann nicht viel mehr als eine Art Abfallprodukt: Geht für eine spezifische Metrik über einen Zeitraum kein Resultat ein, funktioniert der Dienst vermutlich nicht korrekt und die MAT-Lösung aktiviert das Alerting.
Nicht der Erste, aber der Beste
Prometheus ist nicht der erste Versuch, eine Time Series Database für MAT-Zwecke zu etablieren. Graphite [4] gab es lange vor Prometheus, es verfügt aber über ein nicht annähernd so ausgereiftes Datenmodell. Influx DB [5], das meist mit Frontends wie etwa Sensu kombiniert wird, ist sogar jünger als Prometheus, richtet sich aber an einen anderen Anwenderkreis und skaliert nach Meinung mehrerer Tester gerade bei großen Datenmengen nicht so gut wie die Sound-Cloud-Lösung. Dann gibt es noch Open TSDB [6], also die Open Time Series Database, die prinzipiell viel Ähnlichkeit mit Prometheus hat, aber externe Zusatzkomponenten wie Hadoop benötigt. Dass gerade diese externen Constraints bei Prometheus fehlen, rechnen viele Admins dem Produkt hoch an.
Überhaupt hat Prometheus besonders in Cloud-Kreisen gerade so etwas wie einen kleinen Hype ausgelöst. Viele Admins massiv skalierender Systeme und Clouds erhoffen sich von Prometheus nicht weniger als die Lösung aller Monitoring-Sorgen. Passen Wunsch und Realität zusammen? Ein genauerer Blick auf die einzelnen Prometheus-Komponenten soll Klarheit bringen.
Prometheus mit modularer Architektur
Unter der Haube setzt Prometheus auf eine modulare Architektur. Der Kern der Anwendung – eben die Time Series Database – ist wie die meisten zu Prometheus gehörenden Anwendungen in der Programmiersprache Go verfasst. Zur Datenbank gesellen sich ein eigenes Webinterface und ein separates Werkzeug, um Alarme zu verwalten (Alert Manager). Wichtig sind die Exporter auf den Zielhosts, wobei Exporter ein Synonym für Agent ist: Der Node Exporter etwa zeichnet auf dem jeweiligen Host, auf dem er läuft, verschiedene Daten von Metriken wie CPU-Nutzung oder RAM-Verbrauch auf, damit die Prometheus-DB sie im Anschluss per Pull-Prinzip von dort abholen kann. Ist ein Dienst darauf angewiesen, seine Daten per Push-Verfahren an das MAT-System loszuwerden, kommt das Push-Gateway ins Spiel: Es nimmt die Daten der Dienste entgegen und lässt sie von der Datenbank auslesen.
Im Kern des Systems werkelt der Prometheus-Server (Abbildung 2). Ihm kommen viele Aufgaben zu: Die wichtigste ist das Speichern der im Rechnerverbund eingesammelten Messdaten. Obwohl Prometheus aus dem Cloud-Dunstkreis kommt, hinkt dieser Dienst in Sachen Skalierbarkeit noch hinterher. Es ist zwar problemlos möglich, beliebig viele Prometheus-Instanzen innerhalb desselben Setups zu betreiben. Aber anders als viele andere Lösungen setzt Prometheus dabei nicht auf Shared Storage im Backend.
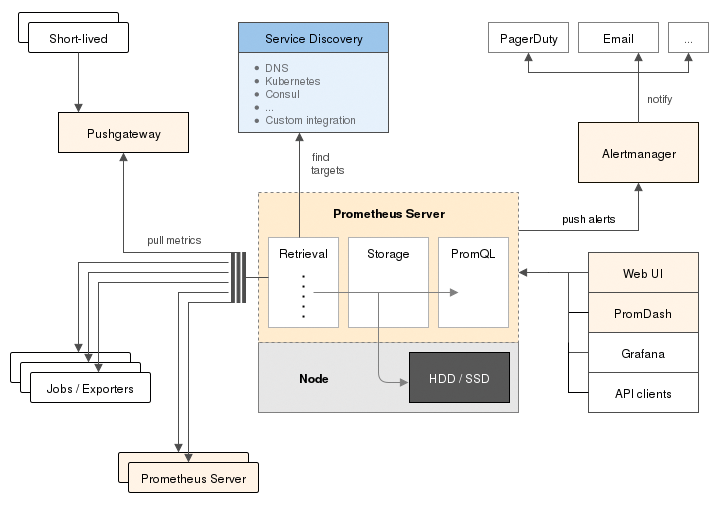
Abbildung 2: Dreh- und Angelpunkt von Prometheus ist der Prometheus-Server, der mit allen anderen Komponenten im Setup kommuniziert.
Die Entwickler begründen das mit der hohen Komplexität, die solch ein Setup mit sich bringe. Sie nennen Open TSDB als negatives Beispiel. Dieses Konkurrenzprodukt zu Prometheus würden viele Admins zwar gerne einsetzen wollen, dann schreckten sie aber doch vor dem enormen Aufwand zurück, den der Betrieb eines vollständigen Hadoop-Clusters verursacht. Einen solchen Cluster benötigt Open TSDB nämlich.
Prometheus setzt stattdessen auf das Sharding-Prinzip. Mehrere Instanzen von Prometheus-Servern konfiguriert der Admin dabei so, dass sie verschiedene, sich nicht überlappende Bereiche der Daten abdecken. Die Datenbank ermittelt dann im Vorfeld einer Suche, in welchem Teilbereich (Shard) die fraglichen Daten liegen müssen, und sucht entsprechend nur noch dort.
Immerhin: Auf dieser Ebene lässt sich eine Replikation dadurch erreichen, dass logische Pärchen von Servern Daten derselben Agenten im Netz einsammeln. Ein Datensatz ist in der Folge mehrere Male verfügbar und auch in den Situationen nutzbar, in denen einer der beiden Knoten ausfällt.
Dass die aktuelle Situation ein Problem darstellt, haben die Prometheus-Entwickler selbst erkannt: Aktuell arbeiten sie an einer Lösung, die für einen Verbund von Prometheus-Installationen eine zentrale, übergeordnete Instanz erzeugt, die ihrerseits von den Prometheus-Shards Daten abholt. Somit entstünde eine zentrale Administrationsschnittstelle. Auch für die ferne Zukunft gibt es bereits Pläne: Langfristig soll Prometheus etwa Daten in Open TSDB ablegen können – und so dessen Replikationsfähigkeiten nutzen.
Die Level DB und ein Eigenbau
Die Verwaltung von Daten wickelt Prometheus mittels einer Kombination aus Level DB und einer Sound-Cloud-Erfindung ab. Das Datenmodell nutzt Level DB für die Indizes; das eigentliche Speichern der Datenstrukturen hat Sound Cloud sich im Anschluss selbst ausgedacht. Nicht ganz freiwillig: Im Entwicklerblog von Sound Cloud erklären sie, dass eine vernünftige Storage-Engine zum Speichern von Zeitserien-Einträgen in ihren Augen schlicht nicht existiere.
Der Prometheus-Server ist aber nicht nur das Storage-Backend, das von den Exportern im Cluster Daten abholt. Er ist zugleich auch die Anlaufstelle für Nutzer oder andere Applikationen, die Daten auslesen wollen. Dafür haben die Entwickler sich eine eigene Query-Sprache überlegt: Prom QL (Prometheus Query Language) funktioniert ähnlich wie etwa SQL für Datenbanken, nutzt aber eine eigene Syntax (Abbildung 3).
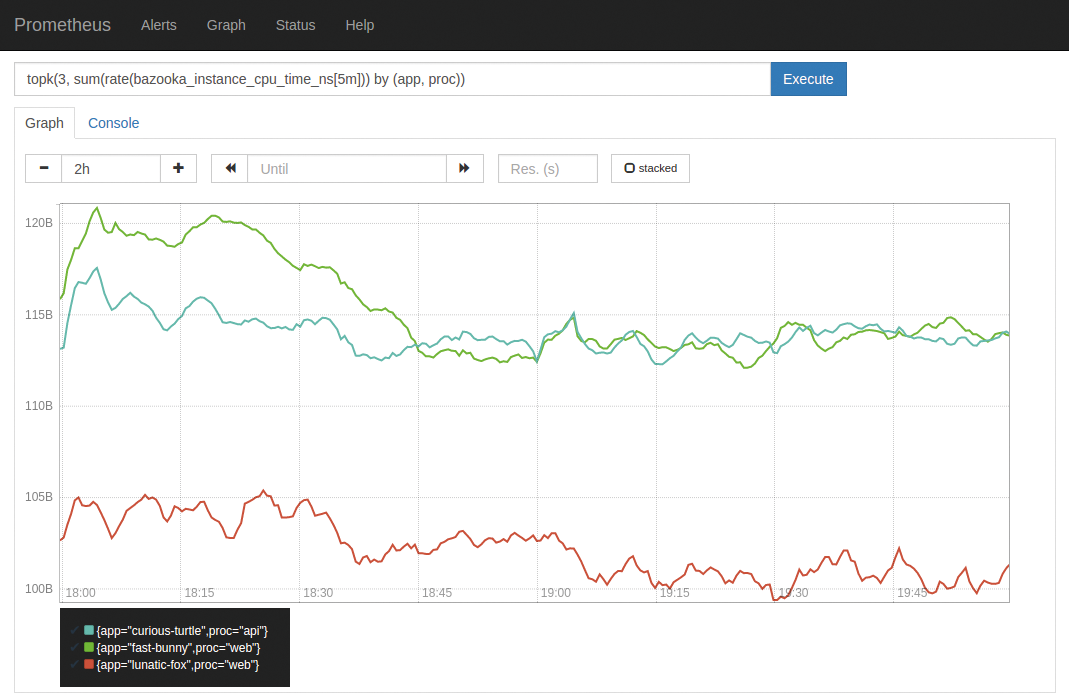
Abbildung 3: Prom QL ist eine eigene Abfragesprache für Prometheus, die auf die Bedürfnisse einer Time Series Database ausgelegt ist.
Jede Instanz von Prometheus bietet eine rudimentäre Webschnittstelle an, über die sich entsprechende Queries absetzen lassen. Für die aufwändige Virtualisierung von Daten eignet sich diese lokale Schnittstelle jedoch nicht. Für diesen Zweck kommt ein eigens verfasstes Dashboard zum Einsatz. Als erste Auskunftsstelle taugt allerdings auch die einfache Schnittstelle von Prometheus selbst.
Exporter
Die schönste Monitoring-Lösung hilft nicht weiter, wenn sie nicht in der Lage ist, Aussagen über den Zustand einzelner Dienste im Cluster zu treffen. Konkret bedeutet das für Prometheus, dass die zu nutzenden Daten irgendwoher kommen müssen. Das Einsammeln von Daten bezeichnen die Macher der Lösung als Scrapen. Für das Scrapen von Daten gibt es in Prometheus eine eigene Art von Dienst, die Exporter.
Exporter prüfen den Zustand von Prozessen nicht nur anhand der Prozess-ID, wie das einfache Nagios-Plugins tun, sie sind deutlich aufwändiger: Sie legen innerhalb von Prometheus eine Datenstruktur für den jeweiligen Dienst an und lesen je nach Qualität des Exporters Metriken des Dienstes ab. Konkret ruft Prometheus etwa die Information ab, wie viele Instanzen von »haproxy« über einen bestimmten Zeitraum laufen, und schlägt anhand der gemachten Vorgaben Alarm, wenn der Wert dieser Metrik zu gering ist.
Für Administratoren ist das Fluch und Segen zugleich. Denn einerseits ist bei der Entwicklung eines Exporters für einen konkreten Dienst viel mehr Aufwand nötig als für ein minimales Nagios-Plugin. Der von Prometheus selbst angebotene Exporter für HA Proxy macht das deutlich: Neben Kenntnissen in Go ist auch ein profundes Verständnis für die Art und Weise nötig, welche Metriken bei einem jeweiligen Dienst in Frage kommen. Andererseits steht auch das Pauken der Datenstruktur von Prometheus an, weil sich Metriken sonst nicht sinnvoll erstellen lassen.
Auf der Haben-Seite steht dafür eine viel genauere Überwachung, als sie viele einfachere Plugins für Nagios & Co. üblicherweise bieten. Ein gutes Beispiel dafür ist wieder der HA-Proxy-Exporter: Neben der bloßen Aussage, wie viel Traffic durch den Load Balancer geht, erlaubt die vorliegende Version von Prometheus es beispielsweise auch, für einzelne Seiten der in HA Proxy konfigurierten Frontends detaillierte Aussagen zur Verfügbarkeit und zur Performance zu treffen. Die Mühe beim Entwickeln der Exporter zahlt sich letztlich also aus.
Die gute Nachricht ist, dass für viele klassische Dienste schon fertige Exporter existieren. Entweder bietet Prometheus sie selbst an oder die Community hilft, weil andere Admins entsprechende Exporter schreiben und veröffentlichen. Auf der Prometheus-Website für Exporter [7] findet sich eine aktuelle Liste nebst entsprechenden Links zu Exportern, etwa für MySQL, Bind oder Apache.
Einige wenige Dienste fürs Cloud Computing wie zum Beispiel Etcd oder verschiedene Dienste von Googles Kubernetes bieten sogar eine native Unterstützung für Prometheus an. Wenn also Prometheus von diesen Diensten weiß, holt es sich die passenden Metriken von dort automatisch.
Service Discovery
Bemerkenswert ist, dass Prometheus mittlerweile auch zwei Spielarten der automatischen Dienst-Erkennung beherrscht. Dazu kann es entweder DNS-SRV-Record nutzen oder es verwendet eine eventuell ohnehin vorhandene Cluster-Registry in Consul [8]. Die Idee hinter diesem Ansatz ist simpel: Wenn von 200 Hosts grundsätzlich die gleichen Metriken zu holen sind, ist es nicht sinnvoll, eine Datenbank der vorhandenen Maschinen händisch vom Admin pflegen zu lassen. Denn jeder neue Clusterknoten wird für Prometheus auf exakt die gleiche Weise konfiguriert sein. Per Auto Discovery nimmt Prometheus dem Admin diese Aufgabe ab und erspart ihm so Arbeit.
Besonders sticht der Node-Exporter heraus, den Prometheus ebenfalls selbst anbietet. Er stellt Informationen zum jeweiligen System bereit, also etwa den Verlauf der CPU- oder Arbeitsspeicher-Nutzung.
Das Push-Gateway
Nicht alle Dienste lassen sich mit Exportern sinnvoll betreiben. Problematisch sind etwa jene Dienste, die Daten ad hoc generieren und sofort loswerden müssen. Das klassische Beispiel wären Cronjobs, die eine bestimmte Aufgabe erledigen und dabei Output generieren, den anschließend Prometheus nutzen soll. Für diesen Zweck existiert in Prometheus das Push-Gateway.
Das Gateway läuft als separater Dienst mit Restful-Schnittstelle und wartet auf das Eintrudeln entsprechender Werte. Soll etwa ein Crobjob-Output auf diese Weise an das Push-Gateway liefern, genügt es, dem jeweiligen Befehl innerhalb der Crontab eine Pipe samt folgendem Curl-Aufruf anzuhängen. Als Zielhost für Curl dient die Rest-Schnittstelle des Push-Gateway.
Natürlich lassen sich diese Gateways horizontal skalieren; es ist also möglich, mehrere davon in der gleichen Installation parallel zu betreiben. Die Prometheus-Server holen sich die abgelegten Daten von den Gateways schließlich auf exakt die gleiche Weise, die auch bei den normalen Exportern zum Einsatz kommt. Einen Haken hat die Sache allerdings: Die Daten, die der Cronjob jeweils ausgibt, müssen in einem Format vorliegen, welches das Push-Gateway auch versteht. Unter Umständen kann es also notwendig sein, die Ausgabe eines Cronjobs entsprechend zu tunen.
Alarme per Alert Manager
Läuft im Cluster etwas schief, erwartet der Admin völlig zu recht, dass ihn das Monitoringsystem darüber in Kenntnis setzt. In Prometheus gibt es gleich zwei mögliche Varianten, das zu tun. Prometheus selbst beherrscht eine grundlegende Alarmfunktion: Bewegt sich der Wert einer Metrik für eine festgelegte Zeit außerhalb eines definierten Bereichs, schickt Prometheus eine Benachrichtigung an eine vorher festgelegte Adresse.
Die Entwickler weisen allerdings ausdrücklich darauf hin, dass es sich bei dieser Funktion nur um eine Basis-Alarmierung handelt. Entsprechend wenige Stellschrauben gibt es, um diese Form des Alerting an lokale Begebenheiten anzupassen.
Daneben gibt es einen zweiten Weg: Statt das Alerting selbst in die Hand zu nehmen, hat Prometheus deshalb auch einen Schalter, der Alerts direkt an den Alert Manager weitergibt. Der Alert Manager ist eine eigene Komponente im Prometheus-Universeum (Abbildung 4), er ist aktuell wohl auch eine der größten Baustellen in Prometheus. Auf seiner Github-Seite [9] fand sich bei Redaktionsschluss der Hinweis, dass die Version im Master-Branch eine völlige Neuentwicklung ist, die mit der aktuellen stabilen Version nicht mehr kompatibel ist. Wer sich Prometheus anschauen und testen möchte, sollte trotzdem zu dieser Version greifen, denn die alte wird in absehbarer Zeit verschwinden.
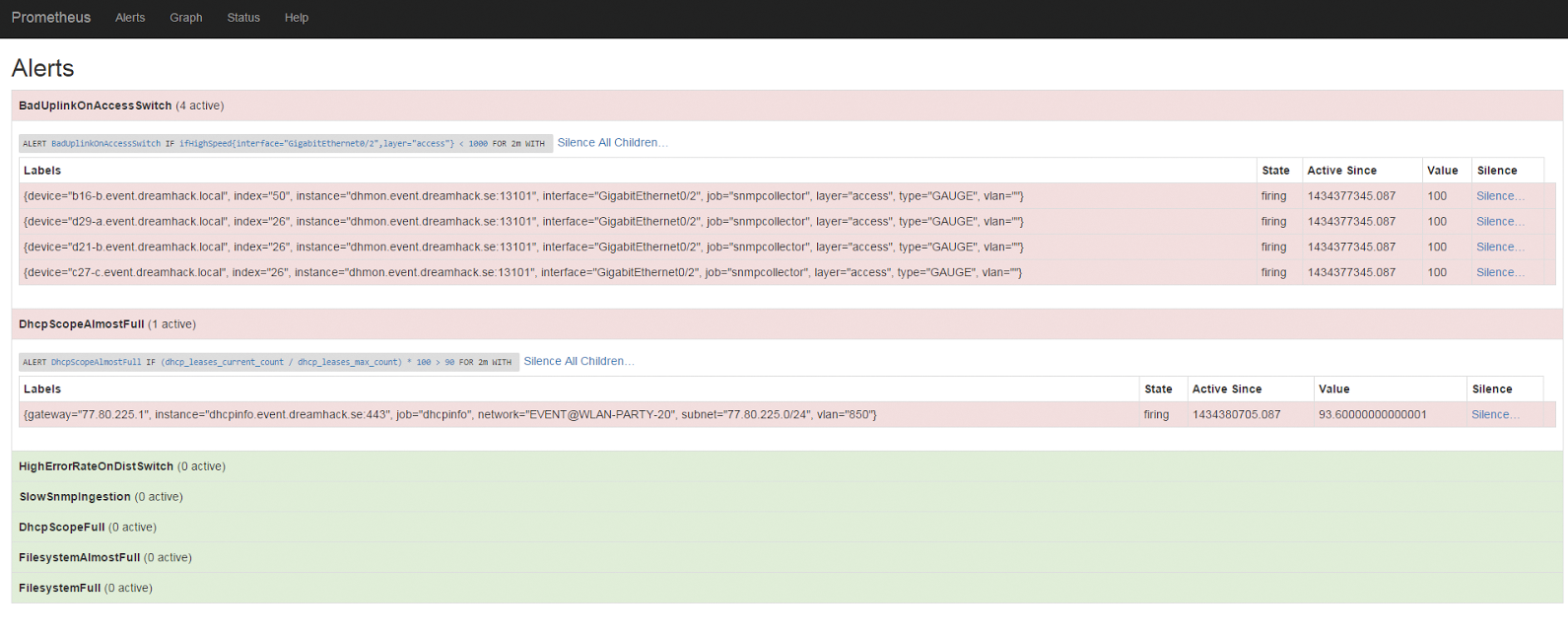
Abbildung 4: Mit den richtigen Metriken und den passenden Parametern lässt sich für jeden Zustand “gut” oder “schlecht” feststellen.
Als Schnittstelle zu Prometheus bietet der Alert Manager ein eigenes API. Kommt von Prometheus ein Alarm rein, lässt sich dieser im Manager auf verschiedenen Wegen verarbeiten: Den Versand einer Warnung per E-Mail kennt der Manager, ebenso die Weiterleitung an das Pager-Duty-API. Das wiederum ist mittels diverser Module aufbohrbar: Ab Werk liegen Pager-Duty-Module für Slack, Hipchat und diverse andere Chatprotokolle bei. Mit einem Modul für einen SMS-Dienst ließe sich Pager Duty aber auch an diesen ankoppeln.
Schließlich darf in der Vorstellung der Komponenten Prom Dash (Abbildung 5) nicht fehlen. Denn Prom Dash ist mit Abstand das mächtigste Werkzeug, um die in Prometheus abgelegten Metriken übersichtlich und hilfreich darzustellen. Die Entwickler des Werkzeugs beschreiben Prom Dash ausdrücklich als einen Dashboard-Builder und nicht etwa als gewöhnliches Dashboard. Denn Prom Dash will keine fertigen Vorlagen für Graphen liefern, sondern dient Admins als Werkzeug, um sich die passenden Vorlagen selbst zu erstellen. De facto ließe sich Prom Dash damit auch als grafische Hilfe bezeichnen, die die Nutzung der Sprache Prom QL erleichtert.
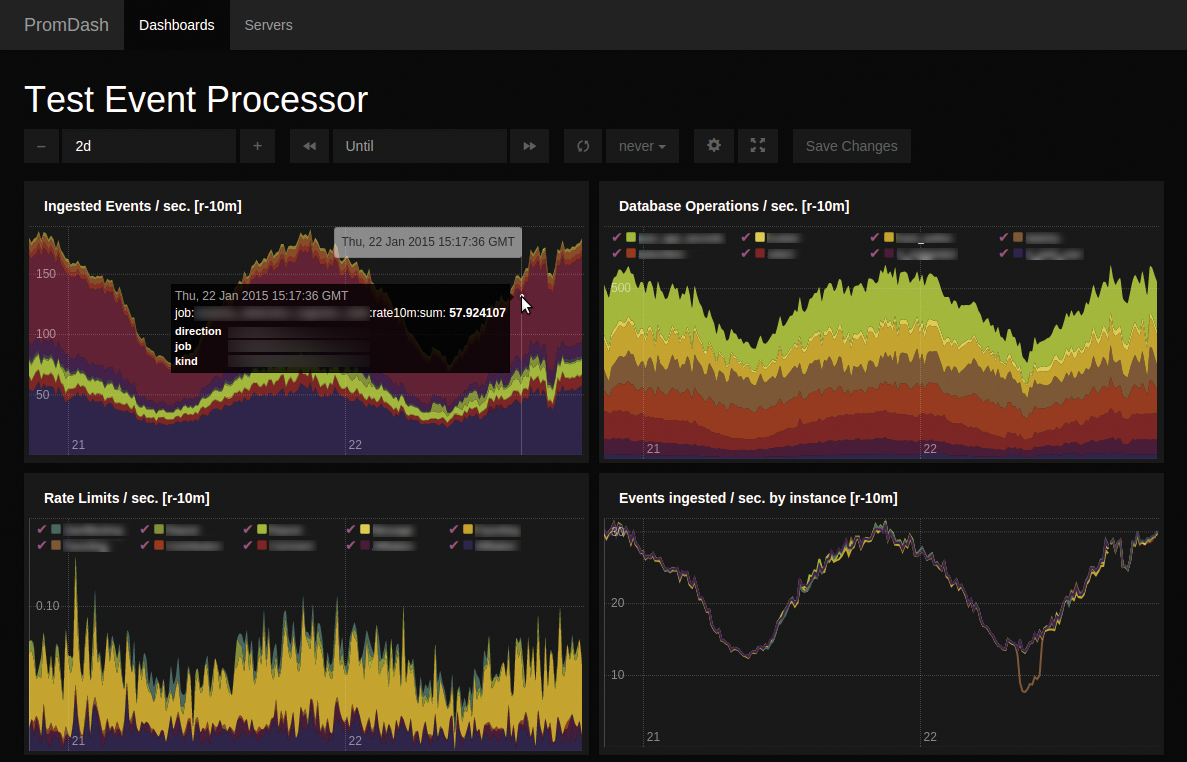
Abbildung 5: Prom Dash ist ein Hilfswerkzeug, um auf Basis vorhandener Daten aus Prometheus passende Graphen zu erstellen.
Der schnelle Überblick mittels Prom Dash
Nach dem Setup der Lösung trägt der Admin in Prom Dash die Prometheus-Server ein, die als Datenquelle dienen – und schon geht die Party los. Eine Funktion von Prom Dash ist neben den schon erwähnten Templates die Möglichkeit, einzelne Graphen mit Notizen zu versehen oder direkt in andere Seiten zu integrieren. So ließe sich etwa auch ein Status-Dashboard für die gesamte Plattform sehr leicht realisieren. Der Admin gewänne damit eine zentrale Übersicht über alle überwachten Systeme.
Ziemlich clever gelöst ist auch die Konfiguration von Prom Dash selbst: Die eingestellten Dashboards legt das Modul nämlich in einer MySQL-Datenbank im Hintergrund ab. Damit sind Konfiguration und Programm voneinander getrennt. Auf diese Weise lassen sich beliebig viele Prom-Dash-Instanzen auf denselben Hosts betreiben, ohne dass der Admin die Konfiguration der einzelnen Instanzen händisch synchron halten müsste.
Fazit
Prometheus läutet in Sachen Monitoring zusammen mit den anderen Time-Series-Datenbanken eine neue Ära ein. Statische Konstrukte wie Nagios oder Zabbix werden zwar auf absehbare Zeit nicht verschwinden und haben in kleinen und mittleren Umgebungen auch ihre unbestrittene Daseinsberechtigung. Im Hinblick auf massiv skalierbare Setups oder Clouds haben sie aber ihren neuen Mitbewerbern nicht gerade viel entgegenzusetzen.
Obgleich Prometheus in Monitoring-Dimensionen ein noch sehr junges Produkt ist, erscheint sein Funktionsumfang schon heute recht beachtlich. Das von Sound Cloud erfundene Datenmodell erlaubt es der Anwendung, riesige Datenmengen nicht nur effizient zu verwalten, sondern sie auch schnell durchsuchbar zu machen. Der Alert Manager ist zwar ebenfalls noch in einem sehr frühen Stadium seiner Entwicklung, aber trotzdem schon jetzt äußerst flexibel und vielversprechend.
Die Möglichkeit, vorhandene Daten mittels Prom Dash in ansprechende Grafiken zu verwandeln und dann in übersichtlichen Dashboards zu präsentieren, ist im Alltag sehr hilfreich. Clevere Funktionen wie die automatische Erkennung neuer Dienste im Netz oder auch das detaillierte Erfassen von diversen Messwerten bei Diensten runden das Angebot weiter ab. Dieser Test hat deutlich gezeigt: Prometheus wird noch von sich reden machen. (jcb)
Infos
- “Monitoring-Exit”: Linux-Magazin-Schwerpunkt 06/15, S. 23 ff.
- Prometheus: http://prometheus.io
- PNP4Nagios: http://sourceforge.net/projects/pnp4nagios
- Graphite: http://graphite.wikidot.com
- Influx DB: https://influxdata.com
- Open TSDB: http://opentsdb.net
- Fertige Exporter: http://prometheus.io/docs/instrumenting/exporters/
- Consul: http://consul.io
- Alert Manager: https://github.com/prometheus/alertmanager
Der Autor

Martin Gerhard Loschwitz arbeitet als Cloud Architect bei Sys Eleven. Er beschäftigt sich dort intensiv mit den Themen Open Stack, Distributed Storage und Puppet. Außerdem pflegt er in seiner Freizeit Pacemaker für Debian.





