
© lakhesis, 123RF
Der Hype um Open Stack führt dazu, dass viele Unternehmen sich reflexartig auf die Software stürzen, um sie zu evaluieren und einzuführen – obwohl andere Ansätze für ihren Anwendungsfall besser geeignet wären. Wann hilft Open Stack, wann nicht?
Auf Konferenzen und Messen ist es zurzeit praktisch unmöglich, dem Thema Open Stack zu entkommen: Ganz gleich wo man ist, die Jünger der Cloudsoftware sind nie weiter als 20 Meter entfernt. Das ist nicht verwunderlich, denn Unternehmen wie Hewlett-Packard, IBM oder Canonical haben in den vergangenen Jahren viel Geld investiert, um auf den Open-Stack-Zug aufzuspringen. HP beispielsweise verspricht seinen Helion-Kunden ein besseres, HP-eigenes Open Stack, das dem Original in vielen Punkten überlegen sein soll.
Für ihr Investment wollen die Hersteller nun Rendite in Form von Supportverträgen einfahren. Konsequent verkaufen viele Anbieter den Kunden Open Stack (Abbildung 1) als eierlegende Wollmilchsau: Vom VMware-Ersatz bis hin zum Software Defined Datacenter soll es sich für praktisch jeden Zweck eignen.
Abbildung 1: Open Stack ist ein mächtiges Werkzeug, aber für viele Szenarien eigentlich viel zu komplex. Im Bild eine Übersicht der aktivierten Komponenten
Dass die Realität eine andere ist, bemerken Unternehmen im Rahmen der ersten Open-Stack-Evaluation. Kleine Proof-of-Concept-Setups gehen ja noch: Im Kontext eines Fünf-Knoten-Clusters lässt sich Open Stack gut meistern. Wenn es im Anschluss darum geht, die Erkenntnisse der Kleininstallation auf ein größeres Setup zu übertragen, setzt schnell Ernüchterung ein, weil sich ein 25-Knoten-Setup in vieler Hinsicht anders verhält als die kleine Testinstallation.
Regelmäßig verzetteln sich Firmen dann im Open-Stack-Klein-Klein statt zu einer funktionierenden Lösung zu kommen. Der Grundfehler: Wegen des großen Marketing-Hype scheint Open Stack vielen Admins die einzige Lösung zu sein, wenn es darum geht, die im Unternehmen etablierte IT-Plattform zu erneuern. Tatsächlich gibt es aber Alternativen, mit denen viele Firmen deutlich besser bedient wären.
Stellt sich die Frage: Welche Workloads sind überhaupt zweckmäßig oder sogar notwendig, um Open Stack sinnvoll produktiv zu nutzen? Welche Voraussetzungen sollten erfüllt sein, damit ein Unternehmen Open Stack sinnvoll betreiben kann? Und welche Gründe sprechen im Zweifelsfalle womöglich sogar gegen die freie Cloudplattform? Wo finden Admins passende Alternativen für ihr Einsatzszenario? Der folgende Artikel gibt Antworten auf diese Fragen.
Was Open Stack kann
IT-Konzepte entstehen eigentlich immer nach dem gleichen Grundmuster: Die Planer gehen vom Bedarf aus, versuchen also die Funktionen zusammenzutragen, die ihre Lösung im besten Fall bieten soll. Dann findet eine grobe Vorsortierung statt, um solche Produkte zu identifizieren, die möglicherweise in Frage kommen. Schließlich folgt ein ausgiebiger Test, in dessen Rahmen man den Produkten auf den Zahn fühlt.
Am Beispiel von Open Stack stehen viele IT-Planer hier schon beim zweiten Schritt vor größeren Problemen: Weil Open Stack aus diversen Komponenten besteht, ist im ersten Augenblick gar nicht ersichtlich, was die Umgebung eigentlich von anderen Ansätzen wie Ovirt oder VMware abhebt. Im Dickicht von Glance, Nova, Neutron, Cinder, Ceilometer und dergleichen Open-Stack-Gewächsen mehr verheddern sich selbst gestandene Sysadmins völlig.
Faktor 1: Funktionsumfang
Open Stack bietet mittlerweile einen beachtlichen Funktionsumfang, zumindest auf dem Papier. Er umfasst das Verwalten virtueller Maschinen auf einer großen Zahl an Systemen durch Nova genauso wie Software-defined Networking mit Neutron oder das dynamische Management von verteilten Speichern via Glance. Eben weil so viele Hersteller mittlerweile an der Suppe mitkochen, bietet Open Stack gegenwärtig die größte Geschmacksvielfalt. SDN-Produkte von Juniper oder Cisco lassen sich in Open Stack genauso gut integrieren wie Speicher von EMC oder Netapp.
Und die Familie der Open-Stack-Komponenten wächst stetig: Gerade erst hat das Projekt die Big-Tent-Initiative gestartet, bei der sich im Grunde jede Komponente als Teil von Open Stack bezeichnen darf – solange sie einige wenige essenzielle Regeln einhält. Es ist also damit zu rechnen, dass die Zahl der unterstützten Features in Open Stack weiter steigt.
Die Medaille hat freilich auch eine Kehrseite: Die beachtliche Funktionalität, die viele Komponenten realisieren, führt zwangsläufig zu enormer Komplexität.
Faktor 2: Mandantenfähigkeit
Wer eine öffentliche Cloudinstallation betreiben will, benötigt zwingend eine Software, die durchgehend mandantenfähig ist. Hier punktet Open Stack: Die zentrale Anmelde-Station Keystone ist so tief in Open Stack integriert, dass jede Komponente innerhalb der Cloud mit ihr reden kann. So ist es möglich, die vorhandene Cloudinstallation in einzelne Segmente zu trennen, wobei jedes Segment einem einzelnen Kunden gehört. Die Segmente sind strikt voneinander getrennt: Kunde eins kann nicht sehen, was Kunde zwei gerade tut. Bei Open Stack ist diese Trennung auf allen Ebenen durchgesetzt, echte Mandantenfähigkeit ist damit gegeben.
Faktor 3: Skalieren in die Breite
Anfangs entwickelten die US-amerikanische Weltraumbehörde Nasa und der in den USA beheimatete Webhoster Rackspace Open Stack zusammen. Die Nasa sah in der Software eine Lösung, um vorhandene Computing-Ressourcen sinnvoll auf Nutzer in der Nasa zu verteilen. Mit dem Hinwenden zu Hostern als Kunden hat sich der Fokus von Open Stack leicht verschoben: Mittlerweile geht es darum, Kunden so gut wie möglich mit Rechen- und Speicherleistung zu versorgen.
Das Skalieren in die Breite war bei Open Stack also von Anfang an ein bestimmendes Designelement: Wenn die vorhandene Hardware im Rechenzentrum die anliegende Last nicht mehr bewältigt, soll es ausreichen, einfach mehr Rechner bereitzustellen, die die Last dann unter sich verteilen.
Wer weiß, dass er eine massiv in die Breite skalierende Plattform zu konstruieren hat, kann mit diesem Vorteil arbeiten. Der Umkehrschluss ist aber auch zulässig: Wer vermutlich nicht endlos in die Breite skalieren muss, hat von der Open-Stack-Skalierbarkeit nicht viel.
Faktor 4: Self-Service-Möglichkeiten
Von großer Bedeutung für Open Stack ist das Dashboard, das offiziell Open Stack Horizon heißt. Horizon ist die erste Anlaufstelle für Benutzer, die Dienstleistungen der Cloud in Anspruch nehmen wollen. Hier klicken sie sich etwa neue VMs zusammen oder versorgen vorhandene VMs mit neuem Speicher.
Von Anfang an war Horizon darauf ausgelegt, Nutzern einen möglichst hohen Grad an Selbstbedienung zu bieten. Das führt einerseits dazu, dass Benutzer praktisch keine Wartezeiten mehr in Kauf nehmen müssen, wenn sie neue VMs in der Cloud nutzen wollen. Und andererseits sind Admins nicht dadurch gebunden, dass sie die immer gleichen Aufgaben immer und immer wieder händisch erledigen müssen.
Was Open Stack voraussetzt
Schon aus der Beschreibung der Fähigkeiten, die Open Stack aktuell mitbringt, ist sein primäres Einsatzgebiet erkennbar. Seitens der Entwickler und des Projekts positioniert sich Open Stack deutlich im Enterprise-Bereich für Kunden, die sowohl öffentliche wie private Dienste in der Cloud hosten wollen. Dabei sind mehrere Spielarten denkbar.
Variante eins besteht darin, Kunden direkt Virtualisierung anzubieten, ihnen also die Möglichkeit einzuräumen, über das Open-Stack-Dashboard selbst virtuelle Maschinen einzurichten und zu verwalten – klassisches IaaS also. Ebenfalls häufig zum Einsatz kommt Variante zwei: Open Stack in PaaS- oder SaaS-Umgebungen. Hier ist die Virtualisierung nur das Mittel zum Zweck, verschiedene Dienste zu hosten. Kunden erhalten in solchen Setups meist keinen direkten Zugriff auf die VMs, sondern nur auf die Dienste, die darauf laufen.
Unabhängig davon, welche Art von Service Unternehmen mit Open Stack anbieten wollen, steht aber fest: Open Stack ist hochgradig komplex und lässt sich – besonders in massiv skalierenden Setups – nicht ohne viel Vorarbeit nutzen. Die etablierten Anbieter von Open-Stack-Distributionen versprechen zwar, genau diese Arbeit zu erleichtern, stoßen aber selbst immer wieder an die inhärenten Designprobleme, die so manche Open-Stack-Komponente plagen.
Der Standard-SDN-Stack etwa setzt bisher auf Open Vswitch ohne Zusatzprodukte wie Midonet von Midokura. Wer allerdings eine SDN-Plattform braucht, die nahtlos auch über Dutzende Knoten skaliert, wird sich früher oder später größere Lösungen wie Open Contrail ansehen wollen.
Dadurch erhöht sich der Schul- oder Lernaufwand für das eigene Personal aber nochmals beinahe exponentiell. Mal eben Open Stack – das gibt es also nicht. Schon gar nicht vor dem Hintergrund, dass viele Funktionen in Open Stack zwar eigentlich vorhanden sind, in der Praxis aber nicht gut oder gar nicht funktionieren [1].
Gegenbeispiele aus dem Bilderbuch
In vielen Fällen wird es also sinnvoll sein, sich vor der Evaluation von Open Stack die Frage zu stellen, ob das Produkt überhaupt die Funktionalität liefert, die im eigenen Setup gewollt oder notwendig ist. Vier Beispiele sind symptomatisch für Szenarien, in denen Open Stack eigentlich nicht geeignet ist, aber trotzdem in die engere Auswahl von IT-Planern gelangt: Virtualisierung ohne die Notwendigkeit, Mandantenfähigkeit zu bieten. Virtualisierung mittels Containern (zum Beispiel Docker), ebenfalls ohne die Notwendigkeit, Mandanten zu unterstützen. Der Betrieb einer PaaS-Plattform sowie ein On-Demand-Speicher, der Kunden dynamisch Speicherplatz bietet.
Virtualisierung ohne Mandantenfähigkeit
Virtualisierung ist bekanntlich kein neues Konzept. Lange bevor Open Stack überhaupt am Markt war, haben Unternehmen die verfügbare Hardware durch den Einsatz von Virtualisierung effizienter ausgenutzt. Ganze Unternehmen sind durch ihr Angebot an Virtualisierungsprodukten überhaupt erst so groß geworden, wie sie sich heute präsentieren: VMware etwa.
Wer den Evangelisten aus der Open-Stack-Ecke zuhört, muss glauben, dass all die Jahre viele Dinge fundamental falsch gelaufen sind, weil Virtualisierung ohne Open Stack auskam. Bei genauerem Hinsehen fällt aber auf, dass die Open-Stack-Befürworter häufig bestimmte Einsatzszenarien einfach zugrunde legen. Zweifellos: Open Stack ist ein mächtiges Werkzeug, wenn das Ziel Mandantenfähigkeit ist. Wenn innerhalb der Cloud zwischen Kunden eine strikte Trennung herrscht, die automatisiert umzusetzen ist, kann Open Stack seine Stärken voll ausspielen. In Kombination mit den Self-Service-Fähigkeiten ist es dann unschlagbar.
Der kritische Punkt bei dieser Herangehensweise ist die Annahme, dass jedes Setup tatsächlich umfassende Self-Service-Funktionalität und Mandantenfähigkeit in dem Umfang benötigt, den Open Stack bietet. Das Gegenteil ist der Fall: In vielen Unternehmen leisten Umgebungen wie Ovirt (Abbildung 2) oder VMware seit Jahren sehr gute Dienste, wenn es um den Betrieb virtueller Maschinen geht. Selbst simple Setups auf Basis von Libvirt und KVM reichen unter Umständen bereits aus, um das benötigte Maß an Virtualisierung zu bieten.
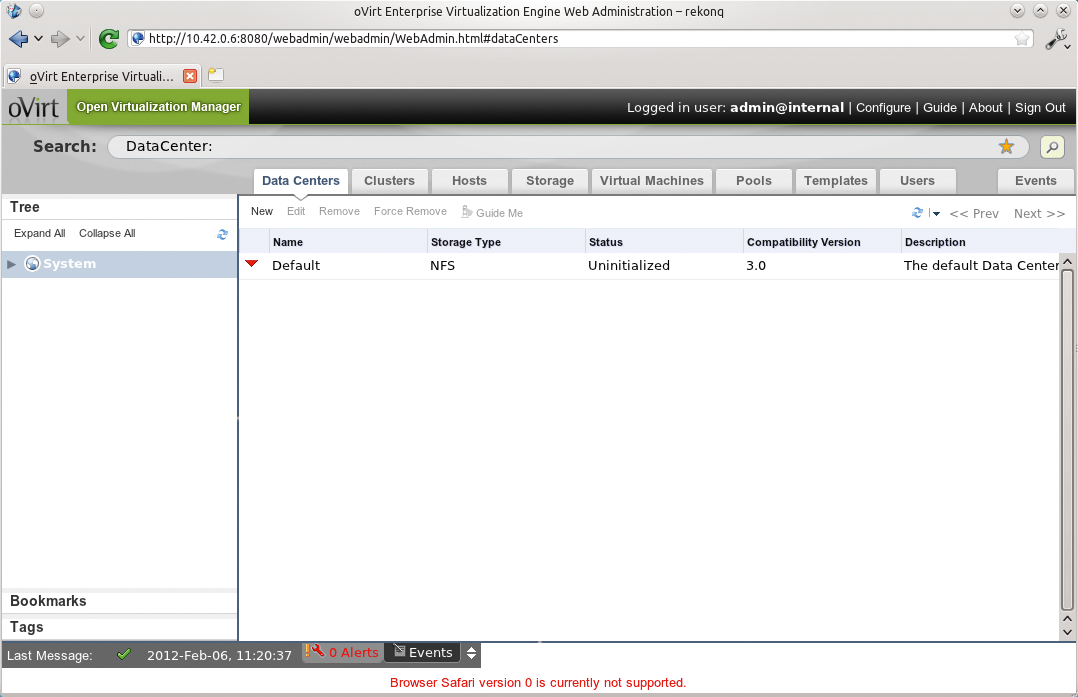
Abbildung 2: Ovirt von Red Hat ist eine freie Alternative zu VMware und sehr viel weniger komplex als Open Stack. Für kleine Setups reicht es aber oft schon aus.
In Kombination mit Diensten wie Pacemaker lässt sich hier sogar Hochverfügbarkeit sinnvoll nachrüsten; bei dynamischen Open-Stack-Setups ist HA auf der Ebene der VMs dagegen bisweilen eine knifflige Angelegenheit. Wer Virtualisierung braucht, Mandantenfähigkeit und Self-Service-Mechanismen aber nicht, ist mit Setups dieser Art meist sehr viel besser bedient (Abbildung 3) – und arbeitet mit Technik, die sich seit vielen Jahren und in etlichen Firmen produktiv bewährt hat.
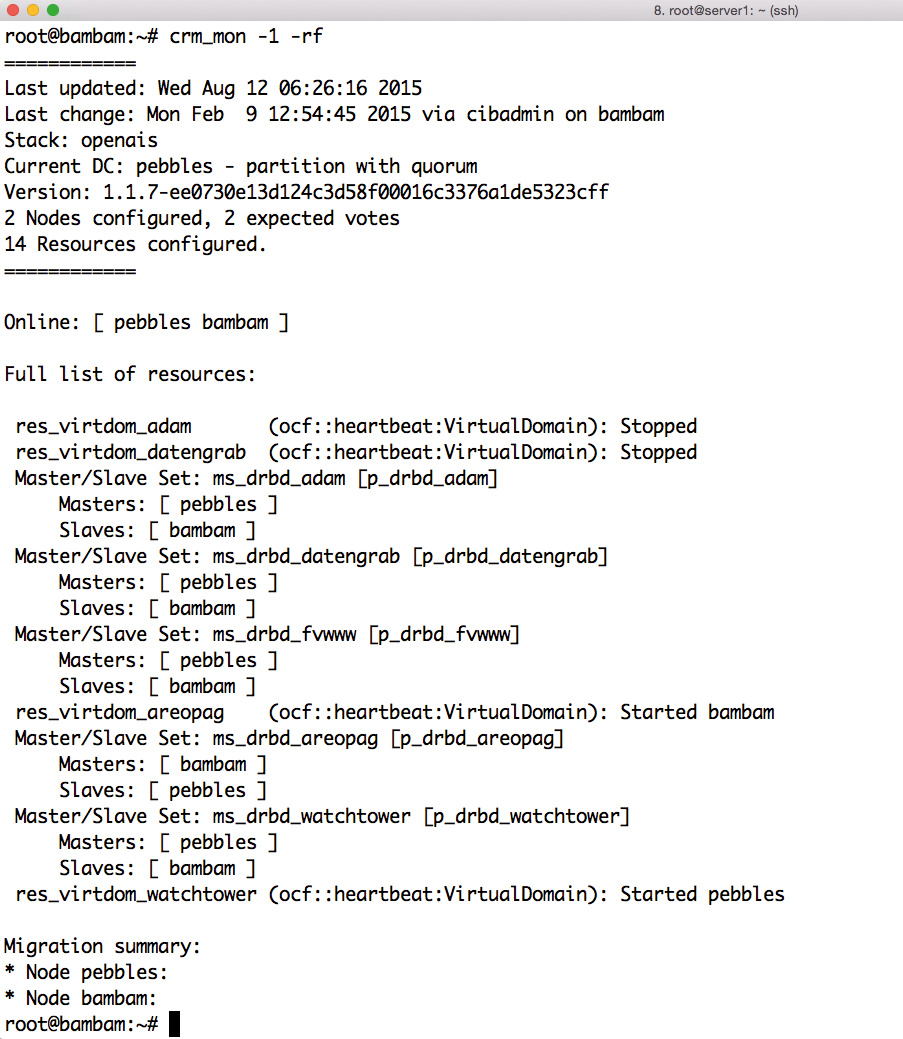
Abbildung 3: Wer nur ein paar hochverfügbare VMs benötigt, ist mit klassischer Virtualisierung und Tools wie Pacemaker vielleicht besser dran.
Virtualisierung mit Containern
Anders als bei der klassischen Vollvirtualisierung gibt es bei Containern nur wenige Erfahrungswerte, auf die Admins sich berufen können. LXC gibt es zwar seit einigen Jahren, einen flächendeckenden Durchbruch konnte die Software bis vor Kurzem aber nicht verbuchen. Der kam erst mit Docker: Seit die Entwickler des einstigen Start-ups LXC mit einer eigenen Verwaltung für die Abbilder von Festplatten versahen, strömen die Nutzer in Massen zu dieser Lösung.
Weil Docker die eine echte Hype-Technologie ist und Open Stack die andere, scheint es auf den ersten Blick völlig logisch, die beiden Teile miteinander zu verbinden. In der Praxis stellt sich das jedoch schnell als problematisch heraus. Denn Docker und Open Stack verfolgen in vielerlei Hinsicht konträre Design-ziele. Und doppelte Funktionalität gibt es auch: Docker etwa verwaltet Festplatten-Abbildern auf Host-Basis, Open Stack setzt auf einen Cluster-weiten Image-Speicher (Glance).
Auch im Netzwerk sind sich Open Stack und Docker nur bedingt grün. Das Docker-Plugin für Nova, das selbst bislang kein offizieller Teil von Open Stack ist, hat zwar inzwischen eine generische Netzwerkschnittstelle. Passende Treiber gibt es aber längst nicht für jedes SDN-Plugin, das Neutron unterstützt.
Wer Docker in einem verteilten Setup betreiben möchte, ist mit Open Stack in vielen Fällen also vermutlich nicht gut bedient. Andere Lösungen scheinen auf den ersten Blick deutlich besser zu passen: Kubernetes (Abbildung 4) von Google legt sich um Docker-Container auf den einzelnen Hosts und erlaubt es Admins, diese von einer zentralen Stelle aus zu steuern.
Abbildung 4: Kubernetes kann viele Dinge sogar besser als Open Stack, allerdings fehlt die umfassende Mandantenfähigkeit. Wer Docker will, sollte sich Kubernetes trotzdem genauer anschauen.
Auch in Sachen Netzwerk und persistentem Speicher stellt sich Kubernetes deutlich intelligenter gegenüber Docker-Containern an, als es Neutron und Cinder bei Open Stack tun. Auch wenn Anbieter wie Mirantis nicht müde werden, das Power-Duo Open Stack und Docker zu propagieren (siehe Artikel “Magnum” in dieser Rubrik), sind auf Container-Virtualisierung ausgerichtete Tools wie Kubernetes Open Stack hier klar überlegen.
Zwar ist Kubernetes selbst nicht alt, hat sich in den vergangenen Monaten aber schon einige Male Meriten verdient. Und obwohl auch Kubernetes aus mehreren Teilen besteht, ist es deutlich weniger komplex als Open Stack.
Einen Nachteil hat die Sache: Kubernetes oder vergleichbare Lösungen wie Core OS und Project Atomic verzichten auf die Mandantenfähigkeit. Hier wäre es also nötig, Kunden über den Umweg eigener Hardware voneinander zu trennen – falls diese Trennung überhaupt nötig ist. Wer innerhalb eines Unternehmens mit Containern virtualisieren will, dürfte mit Kubernetes & Co. jedenfalls besser bedient sein als mit Open Stack.
Eine Plattform für den PaaS-Betrieb
Infrastructure-as-a-Service und Platform-as-a-Service sind nach außen hin zwar zwei unterschiedliche Dienste, unter der Haube werkelt hüben wie drüben jedoch häufig eine ähnliche Mechanik: Während bei IaaS die Kunden aber direkt Zugriff auf ihre VMs bekommen, schaltet der Anbieter in PaaS-Setups noch die Anwendungsschicht dazwischen. Für den Anbieter der Plattform ändert sich aus technischer Sicht nicht viel: Auch in den meisten PaaS-Umgebungen startet eine eigene VM, wenn ein Kunde den Aufruf eines bestimmten Dienstes im Webinterface beauftragt.
Damit PaaS sinnvoll funktioniert, sind Voraussetzungen zu schaffen: Einerseits muss der Admin einen Pool von Festplatten-Abbildern anlegen, auf die er zurückgreift. Denn die komplette Umgebung auf Zuruf jedes Mal neu zu installieren wäre zu aufwändig. Darüber hinaus muss seitens des Anbieters Virtualisierung grundsätzlich möglich sein. Für PaaS ist es dabei aber nicht von Bedeutung, ob die Virtualisierung in Form einer Qemu-VM oder in Form von Containern stattfindet. Docker-Container reichen in der Mehrzahl der Fälle völlig aus.
Mit diesem Wissen ausgestattet geht es ans Werk: Open Stack wäre der Wunschlos-glücklich-Ansatz mit Mandantenfähigkeit und der Option auf Self-Service durch die Kunden. Wer jedoch kein Anbieter öffentlicher PaaS-Dienste sein will, sondern IaaS lieber im Rahmen des eigenen Unternehmens anbietet, benötigt diese Funktionalität aber vielleicht gar nicht. Dann ergeben sich mehrere Alternativen.
Einerseits könnte das schon erwähnte Kubernetes auf Basis von Docker eine gute Wahl anstelle von Open Stack sein. Denn das Anlegen eigener Container für Docker ist nicht kompliziert und im Netz an verschiedenen Stellen sehr gut dokumentiert [2]. Der Image-Teil des Problems wäre damit bereits gelöst. Auch die Virtualisierung ist keines mehr. Das Gespann aus Docker und Kubernetes kann im Falle eines Falles fast den gesamten Umfang der Open-Stack-Funktionalität bieten, lediglich die Mandantenfähigkeit fällt weg, ebenfalls die Self-Service-Funktionalität.
On-Demand-Speicher: Owncloud & Co.
Im vierten Fall geht es um einen weiteren klassischen Anwendungsbereich: On-Demand-Speicher nach dem Prinzip von Google Drive oder Dropbox. Open Stack hält auch hierfür eine Lösung parat: Swift. Swift verträgt sich gut mit Keystone für die Authentifizierung. Wer dieses Gespann fährt, braucht die anderen Open-Stack-Dienste wie Nova und Glance im Grunde nicht.
Es gibt trotzdem gewichtige Gründe gegen Swift. Wie Ceph ist Swift nach dem Prinzip eines Object Store aufgebaut, im Handling ist die Software aber sehr viel komplizierter. Mit Swift holt der Admin sich zwar einen vielseitigen und skalierbaren Speicher ins Setup, aber auch sehr viel Komplexität.
Alternativen gibt es jedoch gleich mehrere: Ceph ist zwar letztlich nur unwesentlich weniger komplex, dafür aber besser automatisiert und deutlich weiter verbreitet. Obendrein lässt sich das Rados-Gateway, das quasi die Restful-Schnittstelle (S3-Kompatibilität) für Ceph herstellt, sogar mit Keystone koppeln, falls das gewünscht ist.
Wer Objektspeichern partout nichts abgewinnen kann, greift alternativ zu lokalem Speicher und setzt auf Lösungen wie Owncloud (Abbildung 5). Insbesondere für diesen Dienst gibt es viele Clients für verschiedene Betriebssysteme. Selbst wenn sich der Admin dann um Themen wie HA selbst kümmern muss, gerät ein solches Setup immer noch weniger komplex als eine ausgewachsene Installation von Open Stack Swift.
Abbildung 5: Owncloud mit lokalem Speicher ersetzt bei Bedarf Open Stack Swift und bietet über Clients für diverse Plattformen umfassende Kompatibilität.
Cloud – auch ganz ohne Open Stack?
Zwar dominiert Open Stack aktuell die Nachrichten, doch gibt es auch fernab von Open Stack durchaus beachtenswerte Ansätze für die Cloud. Die Frage ist im Grunde immer die gleiche: Auf wie viel Open-Stack-Funktionalität kann der Admin verzichten? Wer auf Mandantenfähigkeit oder Self-Service nicht völlig verzichten möchte, aber nicht die volle Open-Stack-Dröhnung braucht, wird bei Open Nebula fündig: Hier ist bereits ab Werk an Konzepte wie HA gedacht – und manch fehlendes Feature erstattet Open Nebula dem Admin in der Währung geringerer Komplexität.
Fazit
Die hier diskutierten Szenarien beweisen, dass Open Stack längst nicht für jeden Einsatzzweck das geeignete Werkzeug ist. Gegen seinen flächendeckenden Einsatz sprechen vor allem die hohe Komplexität, die der Lösung schon ab Werk innewohnt, und der damit verbundene, enorme Lern- und Evaluationsaufwand. Von den ersten Open Stack-Gehversuchen bis hin zu einer Plattform, mit der Kunden tatsächlich produktiv arbeiten können, vergeht bei Open Stack nicht selten ein Jahr. Zu groß ist die Zahl der Komponenten, die es unter einen Hut zu bringen gilt.
Admins tun im Zweifel also gut daran, sich ihre Anforderungen ein zweites Mal genau anzusehen und sich die Frage zu stellen, ob es tatsächlich Open Stack sein muss. Zwei Faktoren stechen als wesentlich heraus: Open Stack und seine APIs sowie das Webinterface Horizon zeichnen sich einerseits durch die durchweg implementierte Mandantenfähigkeit und andererseits durch die Self-Service-Fähigkeiten aus.
Beide Faktoren spielen in nicht-öffentlichen Computing-Umgebungen für IaaS oder PaaS allerdings nur selten eine Rolle. Wer der Entwicklungsabteilung per PaaS eine Spielwiese zur Verfügung stellen will, braucht dazu weder die eine noch die andere Funktion. Zwar sind beide Features “nice to have” und Open Stack bietet sie. Im Gegenzug steigt jedoch andererseits auch die Komplexität des Setup ganz erheblich.
Wer keine öffentliche Cloud mit massivem Skalierbarkeitsbedarf plant, stellt bald fest: Regelmäßig erledigen besser etablierte und viel weniger komplexe Komponenten den Job mindestens so zuverlässig. Obendrein ist bei den etablierten Lösungen der Hype-Faktor nicht annähernd so hoch: Libvirt & Co. sind nicht darauf angewiesen, durch vermeintlich wichtige Features bei jeder neuen Version im Gespräch zu bleiben, sondern verrichten im Hintergrund ruhig und gelassen ihre Arbeit. Für Admins, die auf Stabilität aus sind, ist das von nicht zu unterschätzender Wichtigkeit.
Infos
- Martin Loschwitz, “Open Stack im Reality-Check”: Linux-Magazin 07/15, S. 74
- Michael Unke, Mattias Giese: “Docker-Container am Beispiel von Owncloud”: Linux-Magazin 09/14, S. 32





