
© Maria Kovalets, 123RF
Hashfunktionen sind aus der Informatik nicht mehr wegzudenken. Sie spielen nicht nur in Datenbanken oder beim Berechnen von Prüfsummen eine Rolle, sondern sind unverzichtbar, wenn es um das sichere Aufbewahren von Passwörtern gilt.
Linux schreibt die Hashwerte von Passwörtern in die Datei »/etc/shadow« , die nur Root lesen darf. So sollen sie vor Brute Force und Angriffen mit Rainbow Tables geschützt sein. Dieser Artikel wird zeigen, wie ein Angreifer die nicht umkehrbaren Hashfunktionen unter Umständen dennoch knackt.
Ursprünglich waren Hashes dazu gedacht, Daten effizient im Speicher abzulegen. Die Idee ist simpel: Aus dem zu speichernden Wert errechnet sich seine Adresse. Angenommen es sind die vier Benutzernamen »Fritz« , »Laempel« , »Max« und »Moritz« zu speichern. Eine Hashfunktion würde dann aus den Namen einen Zahlenwert berechnen.
Im einfachsten Fall nutzt sie dazu die Buchstaben im Alphabet (»A=1« , »B=2« und so weiter) und bildet aus den Buchstabenwerten des Namens eine Quersumme (Tabelle 1). Da nur eine begrenzte Menge von Speicherstellen zur Verfügung steht, muss der Hashwert in diesen Bereich fallen.
Tabelle 1
Einfache Hashfunktion
|
Wert |
Summe |
Hash |
|---|---|---|
|
Fritz |
79 |
2 |
|
Laempel |
64 |
1 |
|
Max |
38 |
3 |
|
Moritz |
131 |
3 |
Im Beispiel aus Tabelle 1 gibt es insgesamt sieben Speicherstellen, von 0 bis 6. Der Hashwert bestimmt sich somit aus der Summe modulo 7. Wer keine Lust hat die Zahlenwerte für »Fritz« , »Laempel« , »Max« und »Moritz« von Hand zu berechnen, überlässt dies der Bash mit Hilfe von Perl, siehe Listing 1.
Listing 1
Bash-Hash
01 $ for name in "Fritz" "Laempel" "Max" "Moritz"; do echo -n $name": "; echo -n $name | tr "[:lower:]" "[:upper:]" | expr \( `perl -nwle"print join ' - 64 + ', unpack 'C*', $_"` - 64 \) % 7; done 02 Fritz: 2 03 Laempel: 1 04 Max: 3 05 Moritz: 3
Über eine »for« -Schleife landet dort jeder Name einmal in der Variablen »name« , »echo« schickt ihn durch eine Pipe zu »tr« , das alle Klein- durch Großbuchstaben ersetzt und sein Ergebnis an ein Perl-Skript weiterreicht. Das zerlegt die Zeichenkette in einzelne Buchstaben und gibt deren Ascii-Wert getrennt durch die Zeichenfolge »- 64 +« aus. Dadurch bekommt »A« den Wert »1« , »B« die »2« und so weiter. Wer das live sehen möchte, gibt »set -x« ein, »set +x« beendet den Spuk dann wieder (Abbildung 1).
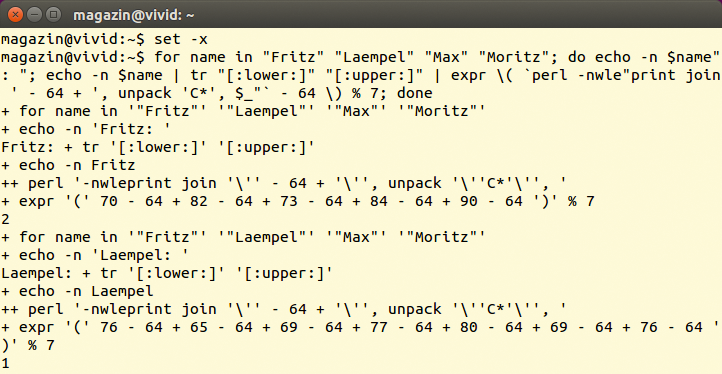
Im Beispiel ergab sich für »Max« und »Moritz« derselbe Hashwert. Wer sich den Speicher als Array vorstellt, der kann an jeder Stelle nur einen Eintrag unterbringen und könnte mit so einer Situation nicht umgehen. Deshalb betrachtet die theoretische Informatik den Hashwert nicht als physische Speicherstelle, sondern als Nummer eines Behälters (Buckets), der mehrere Einträge aufnehmen kann.
Beim offenen Hashing (Abbildung 2) dürften Max und Moritz in einem Bucket hausen, denn hier darf jeder Bucket beliebig viele Einträge aufnehmen. Beim geschlossenen Hashing ist die Zahl der Einträge dagegen begrenzt.
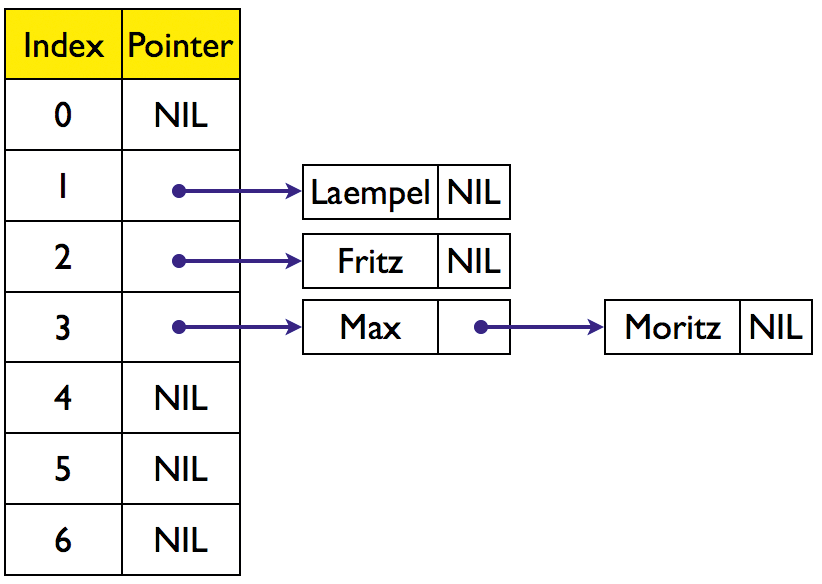
Eine geeignete Datenstruktur für offenes Hashing ist ein Array of Pointers, das im Prinzip unbegrenzt viele Elemente aufnehmen kann. Dargestellt wird es durch eine verkettete Liste. Offenes Hashing ist immer dann sinnvoll, wenn die Größe des Array vergleichbar mit der Anzahl n aller zu speichernden Werte ist. Der Programmierer sollte sein Array in diesem Fall passend dimensionieren.
Die Hashfunktion benötigt eine konstante Zeit zur Berechnung des Wertes »O(1)« . Der Zeitaufwand zum Durchwandern der Liste in jedem Bucket wächst jedoch linear mit der Anzahl der Elemente. Im schlimmsten Fall landen alle n Elemente in einem Bucket und die benötigte Zugriffszeit liegt nun in »O(n)« . Dann ist – verglichen mit einer einfach verketteten Liste – nichts gewonnen.
Im Idealfall verteilt die Hashfunktion die Anzahl der zu speichernden Werte gleichmäßig über alle m Indizes (»O(n/m)« ), was das Auffinden von Elementen schneller als bei einer einfach verketteten Liste macht. So eine Konstruktion lohnt sich vor allem dann, wenn ein bestimmter Wert in einer großen Datenmenge gesucht wird. Geschlossenes Hashing begrenzt die Zahl von Einträgen in einem Bucket und verhindert dadurch lange Ketten.
Deckel drauf
Viele reale Implementierungen ziehen die Grenze für die maximale Anzahl Einträge pro Bucket bei 1; es sind theoretisch aber auch andere Werte möglich. Die einfachste Implementierung wäre ein zweidimensionales Array mit »n« Zeilen (=Buckets) und »m« Spalten für die maximale Zahl von Elementen pro Bucket. Allerdings ist diese Lösung im Hinblick auf die Speichernutzung nicht optimal. Jetzt sind Kollisionen nicht mehr egal – denn jetzt braucht es ein Bucket, in dem noch Platz ist.
Ergibt sich das nicht auf Anhieb, sieht der Algorithmus als Lösung ein neues Hashing – Rehashing genannt – mit einer anderen Hashfunktion vor. Das wird so oft wiederholt, bis keine Kollision mehr auftritt. Im schlimmsten Fall ist eine sehr große Anzahl immer neuer Hashfunktionen erforderlich, die zu unterschiedlichen Ergebnissen führen, um irgendwann einen freien Platz zu finden.
Die einfachsten Hashfunktionen addieren immer 1 zum vorherigen Hashwert hinzu; »h0« ist die ursprüngliche Funktion, »n« die Anzahl der Buckets und »i« der i-te Versuch zu rehashen:
hi = (h0 + i) mod n
Das Verfahren heißt lineares Sondieren und ähnelt einem Besuch im Wiesn-Festzelt: Jemand geht von Tisch zu Tisch, bis er einen freien Platz gefunden hat. Das führt zu Blockbildungen. Wo schon alles besetzt ist, wird der Nachbartisch mit höherer Wahrscheinlichkeit belegt.
Daher gibt es Verfeinerungen, die abwechselnd ober- und unterhalb suchen. Eine Alternative ist die quadratische Sondierung, die »i2« anstelle von »i« verwendet. Kollisionen beim ersten Hash sind gleich wahrscheinlich, beim Rehashing nimmt ihre Wahrscheinlichkeit ab.
Das Rehashing führt zu einem weiteren Problem: Wer später einen Eintrag im Speicher sucht – also zum Beispiel »Max« –, wendet auf den Namen die Hashfunktion an und erhält die Speicheradresse. Ist unter dieser Adresse aber nichts gespeichert, muss er so lange rehashen, bis »Max« oder ein leerer oder nicht vollständig gefüllter Bucket gefunden ist. In letzterem Fall wurde »Max« nicht gespeichert.
Wurde ein Eintrag gelöscht, dann muss – damit die Suche nicht zu früh terminiert – an dieser Stelle ein Marker gesetzt werden. Um die Wahrscheinlichkeit für Kollisionen niedrig zu halten, sollte der Speicher zu weniger als 80 Prozent ausgelastet sein.
Mit Sicherheit
Die Kryptographie stellt höhere Anforderungen an Hashfunktionen. Sie gelten dann als sicher, wenn es keine Möglichkeit gibt, vom Hashwert auf den Ausgangswert zu schließen – zumindest nicht in akzeptabler Zeit. Die Funktion darf also nicht umkehrbar sein. Die Wahrscheinlichkeit, zu einem gegebenen Hashwert einen zweiten Ausgangswert mit demselben Hashwert zu finden sowie die Wahrscheinlichkeit, dass zwei beliebige Ausgangswerte zum selben Hashwert führen, sollte sehr gering sein.
Die letzten beiden Forderungen klingen ähnlich, unterscheiden sich aber, wie das Geburtstagsparadoxon belegt: Angenommen Max befindet sich auf einer Party und fragt die anderen Gäste, ob jemand am selben Tag wie er Geburtstag hat. Das ist aber relativ unwahrscheinlich.
Deutlich wahrscheinlicher ist, dass zwei beliebige Partybesucher am selben Tag Geburtstag haben: Schon bei 23 Gruppenmitgliedern liegt die Wahrscheinlichkeit bei über 50 Prozent. Für das erste Szenario wären 183 Personen nötig, um auf einen solchen Wert zu kommen. Der Geburtstag ist aus kryptographischer Sicht also ein schlechter Hashwert. Das liegt unter anderem daran, dass er eine sehr große Menge (7 Milliarden Menschen) auf einen sehr kleinen Wertebereich (365 Tage) abbildet.
Daher ist bei kryptographisch sicheren Hashfunktionen der Wertebereich sehr groß gewählt. MD5 beispielsweise nutzt 128 Bit (2128, also zirka 3×1038 verschiedene Werte). SHA-1 verwendet 160 Bit (1048 verschiedene Werte), SHA-256 sogar 256 Bit (1077). Eine Funktion gilt als kollisionsresistent, wenn bei einem Hashwert von n Bit die Wahrscheinlichkeit für eine Kollision unter 2n/2 liegt. Der Beweis ist in der Praxis nicht immer einfach zu führen. Das ist etwa daran zu erkennen, dass es recht lange dauert, den Algorithmus MD5 anzugreifen und die Kollisions-Wahrscheinlichkeit anzuheben.
Wie alle Hashverfahren bringt der MD5-Algorithmus eine Nachricht zunächst auf die geeignete Länge. Gewünscht ist ein ganzzahliges Vielfaches von 512 Bit. Das Padding funktioniert dabei so, dass als erstes Bit eine 1 an die Nachricht angehängt wird, dann folgen Nullen, bis am Ende noch 64 Bit frei bleiben. In diesen ist binär kodiert, wie lang die Nachricht war [1]. Die Nachrichtenlänge ist somit durch 512 teilbar.
Anschließend zerlegt der Algorithmus die Nachricht in 512-Bit-Blöcke und diese wiederum in 32-Bit-Blöcke. Auf diesen Blöcken, auch Wörter genannt, erfolgen dann die eigentlichen Berechnungen des Hashwerts. Dabei werden immer vier Wörter je viermal auf unterschiedliche Art und Weise miteinander logisch verknüpft, bitweise verschoben oder addiert. Daraus entstehen vier 32-Bit-Wörter: A, B, C und D. Diese addiert der Algorithmus jeweils zu den vorher berechneten Werten A, B, C und D. Diese Kombination aus A, B, C und D nach jeder Runde heißt Statusvektor.
Das passiert so lange, bis die gesamte Nachricht abgearbeitet ist. Der MD5-Wert ist dann A, B, C und D hintereinander geschrieben. Vor der Berechnung erhalten A, B, C und D einen festen Ausgangswert, den so genannten Initialisierungsvektor.
Geknackt
MD5 gilt als geknackt: Wang und Yu haben 2005 ein Verfahren vorgestellt, bei dem nur zwei entsprechend konstruierte 128-Bit-Blöcke irgendwo in der Mitte einer Nachricht ausreichen, damit der Statusvektor nach diesen zwei Blöcken wieder gleich ist ([2], [3]). Zwei so erzeugte Dateien unterscheiden sich dann zwar in diesen 128 Bit, haben aber denselben MD5-Hash.
128 Bit klingt nach wenig, sie reichen aber aus, um einen Angriff vorzubereiten. Weiß der Angreifer, welches Programm sein Opfer verwenden möchte, kann er dort ein Codestück einbauen, das prüft, welcher 128-Bit-Block in dessen Mitte steht. Theoretisch sieht die Abfrage so aus:
if (128-Bit-Block == guteVersion) then mache_was_gutes() else mache_was_boeses();
Jetzt fehlt nur noch die korrekte Berechnung des 128-Bit-Blocks. Dabei helfen Tools wie Evilize [4]. Wer sich das Beispielprogramm »hello_erase.c« von der Projektseite anschaut, erkennt die Konstruktion aus dem letzten Listing sofort wieder. In »goodevil.c« ist die Auswahl der gewünschten Funktion definiert. Wenn der Speicherblock den Inhalt für den Ablauf »good« hat, dann soll die “gute” Programmvariante starten, sonst die “böse”. Den Speicherbereich definiert »crib.h« durch eine Zeichenfolge, die das Programm »evilize« später durch zwei geeignete 128-Bit-Blöcke ersetzt, die zum selben MD5-Hash führen.
Wer das selbst ausprobieren möchte, entpackt das Evilize-Archiv und kompiliert die Quelldatei »hello_erase.c« :
gcc hello-erase.c goodevil.o -o hello-erase
Anschließend erzeugt der folgende Aufruf die beiden Programme »good« und »evil« mit demselben MD5-Hash:
./evilize hello-erase -g good -e evil
Eine Kontrolle mit »diff« und »md5sum« zeigt, dass die beiden Dateien sich voneinander unterscheiden, die Hashwerte jedoch gleich sind (Abbildung 3).
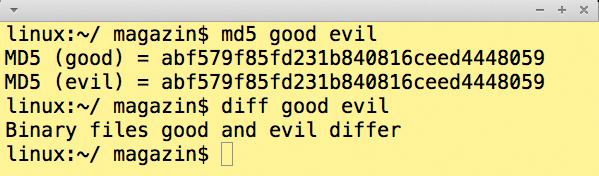
Abbildung 3: Durch geschicktes Manipulieren von 128 Bit entstehen zwei verschiedene Dateien mit demselben MD5-Hashwert.
Passwörter
Ein entsprechendes Angriffsmuster ist auch für andere Dateitypen denkbar, die eine solche Fallunterscheidung möglich machen. Dazu gehören Postscript-, PDF- und Word-Dokumente sowie Tiff-Bilder oder Flash-Filme [5]. Auf dem Chaos Communication Congress 2008 demonstrierten einige Teilnehmer, wie leicht das Fälschen von Zertifikaten und Signaturen mit dieser Technik gelingt [6].
Wenn es also so einfach ist, für zwei unterschiedliche Dateien denselben MD5-Hash zu setzen, sind die Passwörter eines Linux-Rechners dann noch sicher? Das hängt davon ab, wie leicht es gelingt, ein zweites Passwort zu finden, das denselben Hash wie ein anderes hat. Das ist zum Glück nicht sehr wahrscheinlich, weil die meisten Kennwörter weniger als 16 Zeichen (128 Bit) haben dürften, die für den Angriff auf die Programmdateien mindestens erforderlich sind.
Dazu kommt, dass schon der recht einfache MD5-Algorithmus einige Rechenzeit in Anspruch nimmt. Selbst wenn ein Angreifer von allen denkbaren Passwörtern den MD5-Hash im Vorfeld berechnet, um diese abzugleichen, wäre das wenig praktikabel. Bei achtstelligen Kennwörtern, die aus Groß- und Kleinbuchstaben sowie Ziffern (ohne Satz- und Sonderzeichen) bestehen (die also 8 Byte lang sind), gibt es bereits 628 (2 × 1014) mögliche Kombinationen, das heißt, dass eine solche Liste rund 5 Petabyte Speicherplatz benötigt.
Ein solcher Ansatz ist demnach wenig praktikabel und lohnt sich nur dann, wenn mehrere Passwörter zu knacken sind. Für einmalige Aktionen sind Brute-Force-Angriffe effizienter.
Hinter dem Regenbogen
Eine Möglichkeit, den Speicherbedarf einer reinen MD5-Liste zu reduzieren und gleichzeitig die Rechenzeit zu verkürzen, bieten Rainbow Tables. Eine Reduktionsfunktion generiert aus einem Hash ein neues Passwort. Listing 2 zeigt ein in Perl implementiertes Beispiel. Die Funktion »reduce« konzentriert sich auf die druckbaren Ascii-Zeichen aus dem Bereich zwischen 32 und 127. Vom dadurch gewonnenen Passwort berechnet »md5_hex« einen Hashwert, danach generiert die Reduktionsfunktion ein neues Passwort und so weiter. Je nach Implementierung entsteht so eine Kette von Kennwörtern und deren Hashes, und es ist jederzeit möglich, das ursprüngliche Passwort wiederherzustellen. Abbildung 4 zeigt den Output des Perl-Skripts mit dem Startpasswort »Linux« .
Listing 2
Perl-Skript hashing.pl
01 #!/usr/bin/perl -w
02 use Digest::MD5 qw(md5 md5_hex md5_base64);
03 sub reduce
04 { my $what = shift;
05 for ($res='', $i=0; $i<8; $i++)
06 { $res.=chr(hex(substr($what,$i*2,2)) % 96 + 32)
07 }
08 return $res;
09 }
10
11 $passwort = "Linux";
12
13 for ($count=0; $count < 10; $count++)
14 {
15 print $passwort." -> ";
16 $hash = md5_hex($passwort);
17 $passwort = reduce($hash);
18 print $hash." -> ";
19 }
20 print "\n";
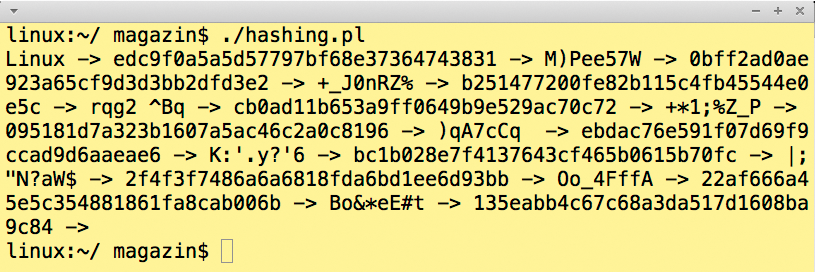
Diese Kette kann zwar beliebig lang sein; zu lang ist jedoch ungünstig, weil Suchzeit und Speicherbedarf mitwachsen. Den Speicherhunger reduzieren gängige Implementierungen, indem sie nur das erste und das letzte Passwort einer Kette speichern. Andernfalls wäre der Speicherbedarf genauso groß wie bei einer vollständigen Liste von Passwörtern und ihren Hashes.
Das Verfahren hat zwei Haken: Erstens ist nicht garantiert, dass es wirklich alle denkbaren Passwörter erwischt, und zweitens könnte es zu Kollisionen kommen und in mehreren Listen irgendwann dasselbe Passwort auftauchen – von diesem Punkt ab wären zwei Tabellen identisch, was die Effizienz massiv mindert und Speicher verschwendet. In einem 2009 auf der DFRWS-Konferenz in Montreal veröffentlichten Paper stellten Thing und Ying daher eine Modifikation des Rainbow-Tables-Angriffs vor, die das Kollisionsrisiko vermindert und die Geschwindigkeit verbessert [7].
Will ein Angreifer nun ein Passwort aus einem Hash ermitteln, wendet er die Reduktionsfunktion auf den Hashwert an. Er erhält eine Kette von Hashes und Passwörtern, die er mit den Rainbow Tables vergleicht. Endet eine Zeile auf ein so erzeugtes Passwort, ist klar, dass in der Zeile auch der gesuchte Hash vorkommt. Nun baut er die Zeile ausgehend vom Startkennwort neu auf und vergleicht jeden Hash mit dem gesuchten. Sobald die Werte übereinstimmen, steht links vom Hash das Passwort – und damit ist es geknackt.
Der Einsatz von Rainbow Tables lohnt sich allerdings nur dann, wenn ein Angreifer immer mal wieder Passwörter knacken will. Für eine einmalige Attacke ist der Brute-Force-Angriff effizienter. Im Netz gibt es etliche fertige Rainbow-Tabellen ([8], [9]), die sich potenzielle Eindringlinge zunutze machen können. Die Frage ist, wie weit sie damit kommen. Taucht das gesuchte Kennwort nicht in der Liste auf, findet ein Rainbow-Table-Angriff es auch nicht. Das funktioniert insbesondere bei recht langen Passwörtern schlecht, da die meisten Tabellen von einer Kennwortlänge zwischen sechs und zehn Zeichen ausgehen.
Um solche Angriffe zu erschweren, nutzen moderne Linux-Systeme einen so genannten Salt, der an das Passwort angehängt wird. Der Salt steht zwar in der Datei »/etc/shadow« und ist damit kein Geheimnis, dennoch versagt die Rainbow-Tables-Technik, da für jeden denkbaren Salt eine eigene Tabelle nötig wäre. Bei einem Salt von 8 Bit Länge sind 256 Tabellen statt einer einzigen erforderlich. Linux nutzt einen 12-Bit-Salt; damit wächst die Anzahl der nötigen Tabellen um den Faktor 4096.
Linux nutzt für jedes Passwort einen eigenen Salt. Daher muss ein Angreifer für jede Passwort-Salt-Kombination eine eigene Rainbow Table konstruieren. Ob nun ein individueller Salt oder ein gemeinsamer für alle zum Einsatz kommt, der dann Pepper heißt, ist diskussionswürdig.
Der Pepper ist dann vorteilhaft, wenn beispielsweise ein PHP-Skript Passworthashes in eine Datenbank schreibt. Dann kann der Pepper im Skript stehen und die Hashes in der Datenbank. Ein Angreifer, der sie per SQL-Injection ausliest, kennt den Pepper noch nicht, wodurch sein Aufwand für das Erstellen von Rainbow Tables deutlich wächst.
Fazit
Hashing kann effizient Daten im Speicher organisieren, weil im Idealfall eine Zugriffszeit von »O(1)« möglich ist. Sobald kryptographisch sichere Hashverfahren mit einer hohen Kollisionsresistenz zum Einsatz kommen, eignen sich Hashfunktionen dazu, Passwörter zu schützen. Allerdings kann ein Angreifer mit Rainbow Tables versuchen aus einem Hashwert das ursprüngliche Kennwort zu ermitteln. Erst mit einem Salt wird der Aufwand unrealistisch hoch.
Infos
- RFC zu MD5: https://tools.ietf.org/html/rfc1321
- How to break MD5 and other Hash Functions: http://merlot.usc.edu/csac-f06/papers/Wang05a.pdf
- Collisions for Hash Functions: http://eprint.iacr.org/2004/199.pdf
- Evilize: http://www.mathstat.dal.ca/~selinger/md5collision/downloads/evilize-0.2.tar.gz
- A Note on the Practical Value of Single Hash Collisions for Special File Formats: http://csrc.nist.gov/groups/ST/hash/documents/Illies_NIST_05.pdf
- Creating a rogue CA certificate: http://www.win.tue.nl/hashclash/rogue-ca
- A novel time-memory trade-off method for password recovery: http://dfrws.org/2009/proceedings/p114-thing.pdf
- Free Rainbow Tables: https://www.freerainbowtables.com/en/tables2
- Free XP Rainbow Tables: http://ophcrack.sourceforge.net/tables.php
Der Autor

Tobias Eggendorfer ist Professor für IT-Sicherheit in Weingarten (Baden-Württemberg) und hält außerdem Grundlagen-Vorlesungen zur theoretischen Informatik. Zudem ist er noch freiberuflicher IT-Berater und externer Datenschutzbeauftragter: http://www.eggendorfer.info





