
© Olga Beregelia, 123RF
Etcd, Zookeeper, Consul und ähnliche Programme werden unter dem Stichwort Konfigurationsmanagement zurzeit heiß diskutiert. Welche Aufgaben wollen sie konkret lösen? Welche Versprechen können sie halten? Das Linux-Magazin geht der Sache auf den Grund.
Der Hype um Docker hat eine Kategorie von Programmen ins Bewusstsein vieler Admins gebracht, die bis dahin fast unbekannt war: die Flotten- und Konfigurationsmanager. Etliche Vertreter dieser Spezies buhlen um die Gunst der Nutzer: Etcd [1], Consul [2] oder Zookeeper [3] sind nur einige.
Doch worum geht es bei den Konfigurationsmanagern eigentlich? Was sind ihre bevorzugten Einsatzgebiete und warum sollen Admins sich an diese Neuerung gewöhnen? Das Linux-Magazin erklärt die Idee hinter den Werkzeugen und lässt dann die oben genannten drei Vertreter gegeneinander antreten.
War früher alles besser?
Nicht selten schwelgen Admins in ihren Erinnerungen, früher sei die Verwaltung von IT-Landschaften leichter gewesen: Jeder Host hatte eine definierte Rolle, die sich im Laufe des Serverlebens nicht mehr änderte. Wenn von Clustern die Rede war, ging es meist um kleine HA-Setups, etwa mit Pacemaker und DRBD zum Synchronisieren von Daten zwischen den Hosts.
De facto kämpften Admins aber schon damals mit einem Problem, das es auch heute gibt: Wenn auf zwei Hosts die Konfiguration von Diensten identisch sein muss, damit beim Ausfall eines Systems das andere nahtlos übernehmen kann, dann ist es nötig, die Konfigurationsdateien irgendwie zu synchronisieren. Oft kamen zu diesem Zweck Krückenkonstruktionen auf Rsync-Basis zum Einsatz. Die waren zwar nicht schön, erfüllten aber ihren Zweck.
Doch in den letzten Jahren sind die IT-Setups kontinuierlich gewachsen – vor allem aber wurden sie dynamischer. Die selbst gebastelten Lösungen, mit denen Admins zwischen den Hosts ihrer Setups die Konfigurationsdateien auf gleichem Stand hielten, gerieten immer komplexer. Als immer schwieriger erwies es sich auch, den Zustand von Diensten über mehrere Hosts hinweg konsistent zu halten. Hinzu kommt: In Scale-out-Setups gilt es, auf die Status aller Instanzen zu achten. Datenbanken geben ein perfektes Beispiel: Ein Schreibvorgang in eine mit Galera geclusterte MySQL-Datenbank zieht Events auf mehreren Hosts des Clusters nach sich – ein komplexes Gesamtgebilde entsteht.
Jeder Dienst mit Unterstützung für das Skalieren in die Breite steht vor der Notwendigkeit, innerhalb des Verbunds jeweils eine unter mehreren Versionen der Daten zum aktuellen und validen Datensatz zu erklären. Wichtig ist, dass sich am Ende alle Komponenten, die an einem Cluster teilnehmen, über den Zustand des Clusters und aller seiner Dienste einig sind.
Die hier vorgestellten Programme wollen dabei helfen und gehen deswegen über die einfache Konfigurationsverwaltung hinaus: Sie wollen in Scale-out-Setups eine verlässliche Quelle sein, die über den Zustand des gesamten Systems Auskunft geben kann. Was einfach klingt, erweist sich in der Praxis aber als technisch anspruchsvoll.
Puppet & Co.
Die steigende Komplexität von IT-Umgebungen war mit ausschlaggebend dafür, dass sich Werkzeuge für das zentrale Management von Konfigurationsdateien durchsetzten: Mit Puppet oder Chef beschränkt sich die Admin-Arbeit auf das Einspielen eines Template und von Konfigurationsparametern, so landen bereits die richtigen Daten in »/etc« . Dennoch löst dieser Ansatz das Problem nur zum Teil. Denn in Scale-out-Setups ist die Konfiguration einzelner Dienste nicht mal annähernd so statisch wie bei konventionellen Setups.
Cluster-Dienste lassen sich beliebig skalieren, indem nach Bedarf immer mehr Instanzen von ihnen starten. Für jede dieser Instanzen Puppet oder Chef anzuwerfen, um sie mit Konfigurationsdaten zu versorgen, wäre unpraktisch. Deshalb sind die typischen Automatisierungstools wie eben Puppet im Inneren von Cloud-VMs praktisch nicht zu finden. Clouds brauchen völlig andere Ansätze, um die Konfiguration von Diensten sinnvoll zu managen. Bis zum Hype rund um Docker und Open Stack waren entsprechende Werkzeuge aber kaum bekannt. Der Cloud-Hype ändert das.
Was ist Konfiguration eigentlich?
Das Fehlen brauchbarer Werkzeuge ist seltsam, gerade weil das Problem eher einfach scheint. Der Umstand, dass auf Linux-Systemen Programme die relevante Konfiguration immer in Form von Dateien im Verzeichnis »/etc« vermuten, ist historisch bedingt. Hier schleppt Linux Altlasten mit sich, die es von seinem Vorgänger Unix geerbt hat.
Konfigurationsdateien folgen in vielen Fällen dem gleichen Prinzip: Einer festgelegten Syntax gehorchend stehen in einer Textdatei Paare aus Parameter und Wert. Eigentlich sind Konfigurationsdateien also nichts anderes als rudimentäre Key-Value-Stores – die sich in Form von Textdateien allerdings über mehrere Maschinen hinweg schlecht verwalten lassen.
Für Key-Value-Stores existieren jedoch mittlerweile mehr als genug sinnvolle Lösungen – erinnert sei an entsprechende Datenbanken. Was läge also näher, als das Datenbankprinzip auch auf das Management von Konfigurationsdateien zu übertragen? Genau hier öffnet sich das Tor zu den Konfigurationsdatenbanken.
Key-Value-Speicher mit Mehrwert
Praktisch allen Konfigurationsdatenbanken ist gemein, dass sie sich selbst als Key-Value-Speicher betiteln. Das gilt etwa für Etcd wie für Consul und auch Zookeeper ist ein typischer Key-Value-Store. Doch belassen es jene Programme nicht dabei. Denn wenn es nur darum ginge, eine Datenbank für die Verwaltung von Einstellungen zu pflegen, wäre ein Ansatz etwa auf der Basis von MySQL vermutlich der einfachere Weg.
Praktisch alle Probanden im Test wollen einen darüber hinausgehenden Mehrwert bieten und preisen deshalb zum Beispiel ihre inhärente Cluster-Fähigkeit an. Etcd und Consul versprechen außerdem besonders effiziente Werkzeuge für das Flottenmanagement von Diensten: Consul etwa kommt mit eingebauter Service-Discovery und wird so flugs zu einem Telefonbuch in skalierten Umgebungen, bei dem sich Services dynamisch an- und abmelden.
Letztlich, so jedenfalls das Versprechen, sollen Etcd & Co. die behäbige Existenz der typischen statischen Konfigurationsdateien in »/etc« beenden und zu einer dynamischen Cluster-Registry werden. Ob das funktioniert, werden die Testkandidaten im Folgenden unter Beweis zu stellen haben.
Etcd von Core OS
Den Auftakt wagt Etcd: Das Programm ist gewissermaßen ein Nebenprodukt von Core OS, also jener Mikrodistribution, die sich auf den Betrieb von Docker-Containern spezialisiert hat. Wie praktisch alle Core-OS-Werkzeuge basiert auch Etcd auf der Programmiersprache Go. Die Selbstbeschreibung klingt unspektakulär: So bezeichnet sich das Programm als “verteilten Key-Value-Store”, der besonders das Handling von Konfigurationsdateien in Mehrmaschinen-Setups vereinfachen und generalisieren soll.
Das Etcd-Frontend ist dabei denkbar simpel konstruiert: Zum Einsatz kommt – ganz Cloud-typisch – eine HTTP-basierte Restful-Schnittstelle, die sich mit jedem handelsüblichen Webbrowser bedienen lässt. Fragt der Admin oder ein an Etcd angebundenes Programm Werte in Etcd ab, kommen diese im Json-Format zurück. Die Datenstruktur in Etcd ist hierarchisch: Ein Key darf verschiedene Unterschlüssel haben, denen dann jeweils ein Wert zugewiesen ist. So können in einem verteilten Setup gleich mehrere Dienste Etcd nutzen, ohne dass sich die verschiedenen Konfigurationseinträge ins Gehege kommen.
Volle Cluster-Kompatibilität
Etcd ist Cluster-fähig: Laufen in einem Setup auf den Hosts eigenständige Instanzen von Etcd, so reden diese im Hintergrund miteinander. Dazu verwenden sie einen Consensus-Algorithmus auf Basis von Raft. Das Prinzip ist simpel: Alle Etcd-Instanzen wählen aus ihrer Mitte einen Master aus, der jeweils die Autorität in allen Cluster-relevanten Fragen ist. Fällt der gewählte Master aus, erfolgt automatisch eine Nachwahl und ein neuer Knoten übernimmt das Regiment. Ein bereits laufender Etcd-Cluster fungiert als Discovery-Dienst für neue Instanzen, die dem Cluster beitreten. Später hinzukommende Instanzen fragen einfach nach, welche Etcd-Instanzen schon vorhanden sind, und verbinden sich mit ihnen.
Einzig beim ersten Start des Clusters, dem Bootstrapping (Abbildung 1), gibt der Admin selbst an, welche Instanz der erste Master sein soll. Solange dann mindestens eine Etcd-Instanz läuft, können ihr andere Etcds beitreten oder sie verlassen, ohne dass ein abermaliges Bootstrapping nötig ist.

Abbildung 1: Etcd benötigt einen Bootstrapping-Prozess, der wahlweise über das Etcd-Verzeichnis des Herstellers oder mittels eines eigenen Etcd erfolgt.
Die Cluster-Fähigkeiten von Etcd schließen auch das Quorum ein: Etcd merkt selbstständig, wenn ein Cluster in mehrere Teile zerbricht, und funktioniert nur in der Cluster-Partition weiter, die die Mehrheit der insgesamt vorhandenen Etcd-Instanzen hinter sich weiß. Lediglich in Sachen Geo-Clustering herrscht Potenzial für Verbesserungen: Mit Multi-Rechenzentrums-Installationen kommt Etcd gerade deshalb nicht klar, weil bei zwei Sites nicht entscheidbar ist, welche Seite das Beschlussrecht hat, nachdem beide ihre Verbindung zueinander verloren haben.
Alte Programme an Bord holen
Etcd hat auch eine Lösung für althergebrachte Software, die eine feststehende Datei in »/etc« mit ihrer Konfiguration erwartet (Abbildung 2). Denn Etcd kennt Templates: Um etwa eine »nginx.conf« aus Etcd heraus zu generieren, platziert der Admin ein entsprechendes Template auf dem Zielhost und legt danach in Etcd die passenden Key-Value-Paare an. Dann kommt ein zweiter Dienst ins Spiel: »confd« . Er generiert aus den Werten in Etcd automatisch die passende »nginx.conf« und legt sie am gewünschten Ort ab. Ein Neustart von Nginx setzt die Konfiguration anschließend in Kraft.
Abbildung 2: Auch wenn Etcd auf einem Host läuft, bedeutet das nicht, dass »/etc« komplett leer ist.
Beeindruckend ist, dass der ganze Ablauf auch Konfigurationsänderungen beachtet. Ändert der Admin die Nginx-Konfiguration in Etcd, triggert Confd von sich aus sowohl das Update der Konfigurationsdatei als auch den Neustart von Nginx.
Alleine nur bedingt nützlich
Zwar ließe sich ein Etcd auch ohne Zusatzkomponenten wie Confd betreiben, aber genau besehen ist Etcd als globales Konfigurationswerkzeug im Rahmen von Core OS gedacht und passt auch am besten in dieses Setup (Abbildung 3). Dabei existiert eine Armada aus Core-OS-Servern und laufenden Etcd-Instanzen, auf denen der Admin nach Belieben Docker-Container startet. Die lesen im Gegenzug ihre nötige Konfiguration aus den Etcd-Instanzen auf dem Host.
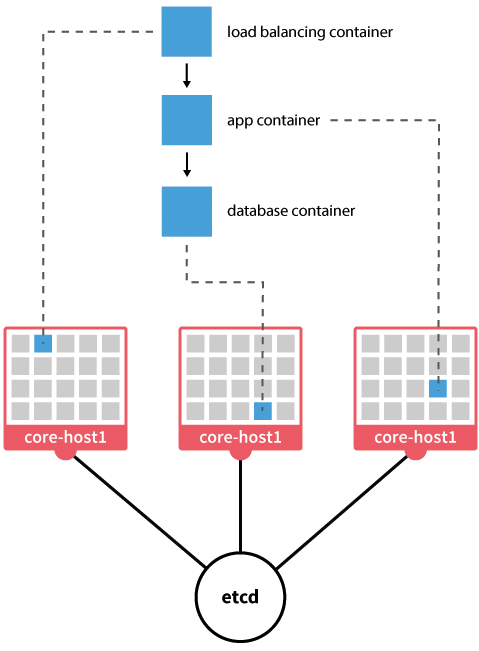
Abbildung 3: Klarer Fall: Etcd fühlt sich am wohlsten, wenn es im Rahmen einer Docker-Installation eingesetzt wird.
Der Cluster-Teil von Etcd sorgt dafür, dass alle Core-OS-Instanzen stets die ganze Konfiguration kennen. Zwei separate Dienste namens Systemd und Fleetd übernehmen die Steuerung des Clusters auf Basis der Daten aus Etcd. Ohne dieses Framework ist es zwar möglich, Etcd sinnvoll zu nutzen, aber aufwändig.
Einer für alle: Consul
Deutlich umfassender ist der Ansatz, den Consul von Hashicorp verfolgt. Das Werkzeug lässt keinen Zweifel daran, dass es alle Einsatzbereiche bedienen will. Neben Unterschieden zwischen Etcd und Consul gibt es aber auch in vieler Hinsicht Gemeinsamkeiten.
Etwa der Umstand, dass auch Consul einen Key-Value-Store für das Ablegen von Konfigurationsdaten implementiert. Der hat genauso wie bei Etcd eine Restful-Schnittstelle und liefert Json-Ausgaben. Doch gibt das Consul-API deutlich mehr her als das von Etcd: Integriert ist zum Beispiel auch eine Katalogfunktion, bei der Knoten im Netz Dienste wie etwa MySQL registrieren können. Andere Knoten fragen dann das Consul-API ab, um eine Liste aller Knoten im Cluster-Verbund zu bekommen, die den jeweiligen Dienst betreiben (Abbildung 4).
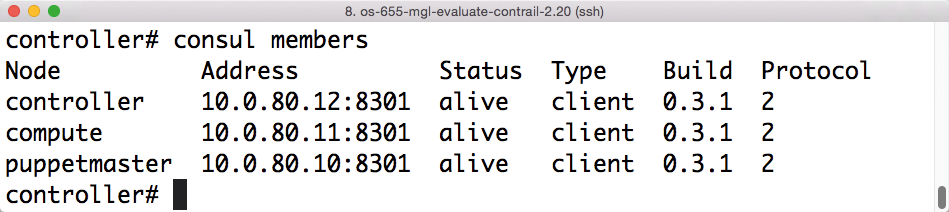
Abbildung 4: Alles in Ordnung: Dieser Consul-Cluster besteht aus drei Knoten, die sich hinsichtlich ihres Zustands einig sind. So soll es sein.
Hinzu kommen eigene API-Module für Health Checks, für ACLs oder für Nutzerevents. Consul spricht von Endpunkten – jeder Endpunkt ist quasi eine eigene Dienstkategorie. Bei Consul steht also das bloße Ersetzen der Konfigurationsdateien in »/etc« eigentlich gar nicht mehr so stark im Vordergrund. Eher will Consul eine umfassende Service-Registry sein, bei der das Konfigurationsmanagement als Nebenprodukt anfällt.
Umfassendes Service-Discovery
Consul folgt einer Server-Agent-Architektur: Es gibt den Cluster von Consul-Knoten und die Rechner, auf denen Anwendungen laufen, also MySQL, Nginx oder ein beliebiges anderes Tool. Auf ihnen arbeitet der zu Consul gehörige Agent. Er meldet die Dienste des Hosts beim Cluster an, sodass sie in der Servicedatenbank in Consul verzeichnet sind.
Will ein anderer Dienst etwa Rabbit MQ nutzen, fragt er bei Consul nach dem entsprechenden Host für Rabbit MQ und erhält die passende Antwort. Damit auch Legacy-Software mit diesem System zurechtkommt, konfiguriert Consul zudem eigene DNS-Einträge: Der Client verbindet sich beispielsweise stets mit dem Host »_rabbitmq._amqp.service.consul« , unter dem Consul die Adresse eines Rabbit-MQ-Hosts definiert.
Es ist nicht leicht, Consul auf den Arm zu nehmen: Behauptet ein Agent, dass auf seinem lokalen Host etwa ein MySQL läuft, kann der Admin dafür in Consul eigene Health Checks definieren. Consul gibt den Host für MySQL nur dann an anfragende Clients weiter, wenn der MySQL-Server auch auf eingehende Monitoring-Anfragen antwortet.
Die Parameter sind hier beliebig: Ist etwa die Last auf dem Zielhost zu hoch, kann Consul das ebenfalls merken und Traffic auf andere Hosts umlenken. Im Grunde verhält sich Consul also wie ein gut konfigurierter Load Balancer, der auf Wunsch auch die Konfiguration von Diensten speichern kann.
Cluster-Fähigkeiten: Oho!
Wie Etcd bietet auch Consul einen inhärenten Clustermodus. Anders als der erste Proband im Test ist Consul aber ab Werk mit Support für echte Multi-RZ-Installationen ausgestattet – obwohl es ebenfalls Raft benutzt, um den Konsens im Cluster herzustellen.
Consul kennt drei Konsistenzmodelle: Das Default-Modell ist ein Kompromiss aus erzwungener Konsistenz und der Möglichkeit, dass ein Cluster unter seltenen Umständen Informationen aus der Datenbank liest, die nicht mehr aktuell sind. Demgegenüber steht das Modell mit erzwungener Konsistenz (“consistent”). Variante 3 (“stale”) lässt zu, dass Consul-Instanzen selbst dann Anfragen bearbeiten, wenn sie selbst wissen, dass sie zu einer Cluster-Partition ohne Mehrheit im Quorum gehören (Abbildung 5). Der Admin darf sich im Grunde aussuchen, was ihm lieber ist: funktionslose Consul-Instanzen (weil sie keine Mehrheit im Quorum haben) oder Clients, die womöglich alten Input zurückbekommen.
Abbildung 5: Wie Etcd kennt auch Consul ein initiales Bootstrapping, bei dem sich die Knoten des Systems in einem ersten Schritt einig werden.
So realisiert Consul auch die Multi-RZ-Fähigkeit: Bei solchen Setups hat jedes Rechenzentrum seinen eigenen Consul-Cluster und alle Cluster sind lose miteinander verbunden. Jeder Consul-Instanz in jedem Rechenzentrum steht jede Information des Clusters grundsätzlich zur Verfügung, aber der Ausfall eines Rechenzentrums beeinträchtigt nie die Consul-Cluster der anderen Standorte. Denn alle Consul-Agents in einem RZ reden nur mit den Consul-Instanzen dort – Requests für andere Partitionen des Clusters werden innerhalb der Consul-Server weitergeleitet.
Wie Etcd schlägt auch Consul eine Brücke in die alte Welt. Das Ende 2014 vorgestellte Consul Template gibt Admins die Option, auf Template-Basis Konfigurationsdateien für Dienste zu generieren. Dabei ist Consul Template ein eigener Dienst – ähnlich wie »confd« bei Etcd.
Zookeeper
Quasi der “Opa” unter den Probanden ist Zookeeper. Das Projekt, das unter dem Schirm von Apache steht, blickt auf die längste Vergangenheit der getesteten Werkzeuge zurück. Es verwundert nicht, dass diverse Features bei Etcd wie auch bei Consul offenbar maßgeschneidert sind, um vermeintlich fehlende Zookeeper-Funktionalität zu bieten. Dabei hat Zookeeper durchaus einen mächtigen Kreis von Unterstützern: Das Projekt, das einst zu Hadoop gehörte, kommt bei großen Unternehmen wie Rackspace oder Ebay zum Einsatz.
Auch bei Zookeeper (ZK) findet sich die fast schon typische Aufteilung in mehrere Komponenten. Zuallererst ist auch Zookeeper mit einem Dienst für das Vorhalten von Konfigurationsdaten ausgestattet. Zwar bietet es auch eine Restful-Schnittstelle, doch ist diese zurzeit als experimentell gekennzeichnet. Lieber sehen es die Entwickler, wenn Nutzer auf Zookeeper mit den getesteten Java- oder C-Clients zugreifen.
Der Cluster-Konsens
Damit Zookeeper die Dienste innerhalb einer Cloud und auf den Hosts verwalten kann, braucht es freilich einen inhärenten Cluster-Modus (Abbildung 6). Der gehört zum Lieferumfang: Anders als Etcd oder Consul setzt Zookeeper auf Paxos statt auf Raft als Algorithmus. Aus Admin-Sicht ist das aber ein eher technisches Detail.
Abbildung 6: Zookeeper beherrscht ebenfalls natives Clustering im Hintergrund. Es ist mit Abstand die reifste Komponente im Test.
Ausschlaggebend ist: Zookeeper garantiert Programmen einen konsistenten Cluster-Status und implementiert ein Quorum. Verbindet sich also ein Client mit einer Zookeeper-Instanz, kann er sicher sein, stets die vom Cluster als gültig anerkannten, neuesten Daten zu bekommen. Fällt der Cluster temporär auseinander, dann verweigern die Cluster-Partitionen ohne Quorum-Mehrheit den Dienst.
Ähnlich wie bei Etcd fehlt auch bei Zookeeper das Framework für Service Discovery. Will ein Admin die Software entsprechend nutzen, muss er sich selbst darum kümmern, dass verfügbare Dienste sich durch einen Eintrag in Zookeeper an- und abmelden.
Ausgeschlossen ist es also nicht, Zookeeper etwa als Service Registry zu nutzen. Allerdings hat beispielsweise Netflix damit so schlechte Erfahrungen gemacht, dass man in Form von Eureka [4] kurzerhand einen eigenen Discovery-Dienst schrieb, der ohne Zookeeper auskommt. Letztlich darf die Software als ein mit Etcd vergleichbares Produkt gelten, das allerdings nicht so stark ins Cloudkorsett gepresst ist.
In Sachen Features unterliegt Zookeeper aber Consul klar und deutlich. Neben der schon genannten Registry-Funktion fehlt bei Zookeeper etwa auch ein Mechanismus, um aus den abgelegten Konfigurationsparametern fertige Dateien zu erzeugen, die müsste der Admin selbst fabrizieren. Wegen des genutzten Paxos-Algorithmus sind zudem Multi-RZ-Setups schwieriger. Zwar kommt Zookeeper ab Werk mit so genannten Observern, die so ähnlich funktionieren wie die Inter-RZ-Kommunikation bei Consul. Die Zahl an Setups in der echten Welt, die Observer tatsächlich produktiv nutzen, dürfte allerdings äußerst gering sein.
Fazit
Tatsächlich machen Programme wie Etcd und Consul das Lebens von Admins leichter, wenn sie im angestammten Terrain des Werkzeugs zum Einsatz kommen. Sind etwa alle Komponenten eines Setups mit Support für das jeweilige Tool ausgestattet, kann der Admin Sorgen wegen der Synchronisierung von Dateien in »/etc« ad acta legen. Allerdings, und das ist der Pferdefuß, handelt es sich dann mit hoher Wahrscheinlichkeit tatsächlich um eine hippe Cloudanwendung, die auf den Einsatz im Rahmen von Core OS oder einer der vielen anderen Mikrodistributionen ausgelegt ist. Nur wenn alle Programme der Installation direkt mit dem jeweiligen Konfigurationsmanager reden können, reizt der Manager sein Potenzial voll aus.
Deutlich weniger attraktiv wirken die Werkzeuge, wenn es ausschließlich um konventionelle Programme geht. Die haben keine direkte Anbindung an irgendeins der vorgestellten Programme. Hier fängt der Admin also an, sich aus der Template-Funktion des jeweiligen Werkzeugs – soweit vorhanden – eine Konfigurationsdatei in »/etc« selbst zu basteln. Allein dafür sind die Probanden des Tests aber zu komplex – ein solches Setup bringt gegenüber klassischer Automatisierung mit Puppet & Co. kaum Vorteile. Auch von der inhärenten Cluster-Fähigkeit der einzelnen Tools profitieren altmodische Programme praktisch überhaupt nicht.
Als Fazit darf gelten: Wer sich mit Docker oder einer der Mikrodistributionen für den Cloudeinsatz beschäftigt, wird mit Etcd, mit Consul oder mit Zookeeper vermutlich seine Freude haben. Wer nur eine zentrale Pflege altertümlicher Konfigurationsdateien benötigt, greift besser wie bisher zu Puppet, Chef oder einer der vielen am Markt vorhandenen Alternativen.
Das muss aber nicht immer so bleiben. Wegen ihrer REST-APIs ist es für die Autoren anderer Programme sehr leicht, ihre Software so anzupassen, dass sie direkt mit den Testkandidaten redet. Gelänge es beispielsweise in Zukunft, den allseits beliebten IMAP-Server Dovecot zur Zusammenarbeit mit einem der vorgestellten Werkzeuge zu überreden, dann wäre das eine ausgesprochen attraktive Kombination. Es gilt wie so oft: Die Zukunft bleibt spannend.
Infos
- Etcd: https://coreos.com/etcd
- Consul: https://consul.io
- Zookeeper: https://zookeeper.apache.org
- Eureka: https://github.com/Netflix/eureka





