
© George Tsartsianidis, 123RF
Das Python-Modul Asyncio bringt neuen Schwung in vernetzte Anwendungen. Als Alternative zu Threads kann ein Entwickler es geschickt mit bestehenden Python-Bibliotheken kombinieren.
Schöpfer von Asyncio [1], das zunächst unter den Namen Tulip entwickelt wurde und seit Python 3.4 in der Standardbibliothek steckt, ist kein Geringerer als Guido van Rossum, der Python-Erfinder höchstselbst. Während seiner Arbeit an der asynchronen Bibliothek führte er ausgiebige Gespräche mit Entwicklern ähnlicher und meist schon fest etablierter Python-Bibliotheken wie Twisted [2], Tornado [3], Gevent [4], Pyzero-MQ ([5], [6]) und Pyftpdlib [7].
Das Ergebnis: Asyncio kann als Grundlage für diese Bibliotheken dienen, denn die Eventloop des Moduls lässt sich in andere Frameworks einbauen. Außerdem bietet Asyncio auf höherem Abstraktionsniveau einen Scheduler auf der Basis von »yield from« an. Van Rossum beschreibt das Modul in dem recht umfangreichen PEP 3156 ([8], Python Enhancement Proposal) sowie in einem auf Youtube verfügbaren Vortrag [9] detailliert. Das API ist vorläufig und Änderungen in Python 3.5 sind noch möglich.
Träge Netzwerke
Computer arbeiten schnell, Netzwerke reagieren im Vergleich dazu träge. Also warten viele Netzwerkanwendungen recht lange, bis eine Anfrage vom Server zurückkehrt. In dieser Wartezeit bleibt die CPU untätig. Es gibt verschiedene Lösungsansätze für das Problem, zu denen etwa Threads, Green Threads oder Callbacks in einer Ereignisschleife (Eventloop) gehören, doch sie alle haben ihre Vor- und Nachteile.
Betriebssystem-Threads brauchen zum Beispiel ein intelligentes Locking, ihre Zahl lässt sich nicht ohne Probleme massiv erhöhen. Alternativ gibt es mit den Microthreads eine Thread-Implementierung im Userspace, auch Green Threads genannt. Sie arbeiten effizienter als ihre OS-Geschwister und können durchaus 10000 Verbindungen in Threads verpacken. Allerdings müssen die Anwendungen zum Teil wissen, dass sie in einem Microthread laufen, um Threadwechsel einzuleiten.
Das neue Modul Asyncio will diese Nachteile vermeiden, indem es möglichst gut mit vorhandenen Frameworks kooperiert. Das klappt, weil die darunterliegenden Eventloops mehrere Nutzungsarten erlauben und trotz unterschiedlicher Ziele auch Gemeinsamkeiten besitzen, etwa das Scheduling und die Callbacks. Das erlaubt es den einzelnen Frameworks, Objekte zu teilen.
Ambitioniertes Konzept
Van Rossums Ziele für das »asyncio« -Modul sind recht ambitioniert. Es läuft auf Unix-, Windows- und OS-X-Systemen, unterstützt IPv4, IPv6, TCP, UDP, eine Implementierung von TLS (SSL) und kann mit Pipes und Subprozessen umgehen. Es soll nicht von weiterer Software abhängen, die Entwickler aber auch möglichst nicht dazu zwingen, eine der beiden wesentlichen Nutzungsarten zu verwenden, die auf Callbacks und »yield from« basieren.
Der Einsatz von Callback-Funktionen lässt sich laut Rossum nicht immer vermeiden, hier ähnelt die Herangehensweise der von Twisted. Callbacks erzwingen eine bestimmte Programmierweise, die sich von der üblichen synchronen deutlich unterscheidet. Der zweite Weg über »yield from« (PEP 380, [10]) steht der synchronen Programmierung schon wesentlich näher.
Letzteres verdeutlichte van Rossum in einem Vortrag mit Hilfe zweier Folien ([9], Abbildung 1). Der asynchrone Programmcode unterscheidet sich vom synchronen lediglich dadurch, dass er an einigen Stellen ein »yield from« sowie den Dekorator »@asyncio.coroutine« vor die Funktionen stellt.

Abbildung 1: Guido van Rossum ließ es sich nicht nehmen, Asyncio persönlich zu präsentieren.
Drei-Komponenten-Kleber
Asyncio basiert laut Rossum im Wesentlichen auf drei Komponentengruppen: den Coroutinen, Futures und Tasks, dann den Eventloops sowie den Transports und Protocols. Wer auf hohem Abstraktionsniveau programmiert, greift unter anderem zu Coroutinen. Dabei handelt es sich um spezielle Generator-Funktionen, die sich in Python als Iteratoren in For-Schleifen einsetzen lassen.
Coroutinen spielen in Python mitunter eine Doppelrolle: Als Funktionen kennzeichnet sie der vorangestellte Dekorator »@asyncio.coroutine« (Coroutine Function), sie können allerdings auch als Objekte auftreten, die eine aufgerufene Coroutine-Funktion erzeugt (Coroutine Object). Coroutinen können über »yield from« außerdem zeitweise die Kontrolle an andere Coroutinen, Futures oder Tasks abgeben, ohne dabei die Eventloop zu blockieren.
Futures sind an die Klasse »concurrent.futures.Future« angelehnt. Es handelt sich um Objekte (Instanzen einer speziellen Klasse), die ein mögliches Ergebnis oder einen Fehler (Exception) repräsentieren. Ein Entwickler kann Futures mit Callbacks versehen, die eine Coroutine starten, sobald die Futures ein Ergebnis erhalten. Im Nachhinein lassen sich Future-Objekte nicht ändern.
Eine Task wiederum ist eine Subklasse einer Future. Es handelt sich um eine in eine Future-Komponente verpackte Coroutine, die sich bei der Eventloop registriert und dann ein Generator-Objekt zurückliefert. Nimmt der Scheduler dann die Coroutine an die Reihe, in der die Task läuft, gibt diese das Generator-Objekt zurück.
Wie eine Future repräsentiert auch eine Task wahlweise ein durch die Coroutine zu erzeugendes künftiges Ergebnis oder einen Fehler, den ein »try« -Statement auswerten kann. Coroutinen, Futures und Tasks, arbeiten gleichermaßen mit »yield from« , ihre Anwendungsfälle ähneln sich in der Praxis stark. Will ein Entwickler, dass etwas im Hintergrund passiert, während sein Programm im Vordergrund noch andere Aufgaben erledigt, sollte er Tasks einsetzen. Wartet das Programm hingegen auf ein bestimmtes Ergebnis, greift er besser zu Coroutinen.
Die Eventloop kümmert sich schließlich um den Ablauf der Aktionen. Sie beherrscht unmittelbare und verzögerte Callbacks, I/O-Callbacks, die zum Beispiel auf Sockets und Unix-Signale warten, und bringt APIs mit, die Verbindungen und Server erzeugen.
Transports und Protocols gehören stets zusammen und gehen eine symbiotische, wenn auch asymmetrische Partnerschaft ein. Das bedeutet, dass der Code in Client-Server-Konstellationen auf beiden Seiten ähnlich funktioniert.
Transports kümmern sich dabei um den Low-Level-Part, wozu Verbindungen über TCP-Sockets, (Named) Pipes oder das TLS-Protokoll gehören. Sie bringen ein von der Verbindungsart unabhängiges Interface für die Protokolle mit. Mit den Transports kommt der Anwender gewöhnlich nicht in Berührung, sie sind oft Teil des Framework. Unter Protocols versteht van Rossum hingegen Anwendungen, zum Beispiel HTTP-Server. Auf der Basis von Protocols kann ein Entwickler eigene Protokoll-Subklassen anlegen.
Datenharke
Asynchrone Programmierung findet eine sinnvolle Anwendung, wenn Informationen über ein Netzwerk laufen und Rechner länger auf diese warten, als sie brauchen, um die Daten zu verarbeiten. Das ist zum Beispiel beim Webscraping der Fall, das von einer asynchronen Programmierung profitiert. Ein passendes Beispielprogramm soll automatisch Webseiten herunterladen, sie auswerten und basierend auf den Ergebnissen die darin verlinkten Seiten aufrufen.
Praktischerweise bietet Wikipedia Beschreibungen aller gängigen Programmiersprachen an. Für die meisten Sprachen stehen wichtige Informationen in einem Kasten, wie Abbildung 2 für Python zeigt. Die Rubriken »Influenced by« und »Influenced« erklären, welche Programmiersprachen entscheidenden Einfluss auf die Entwicklung von Python hatten und welche Sprachen Python seinerseits maßgeblich beeinflusst hat. Meist zeigen die Links auf andere Wikipedia-Seiten mit weiteren Informationen zu den beeinflussenden und beeinflussten Sprachen. Auch diese Seiten verfügen wieder über Infokästen mit den entsprechenden Rubriken, Links und so weiter.
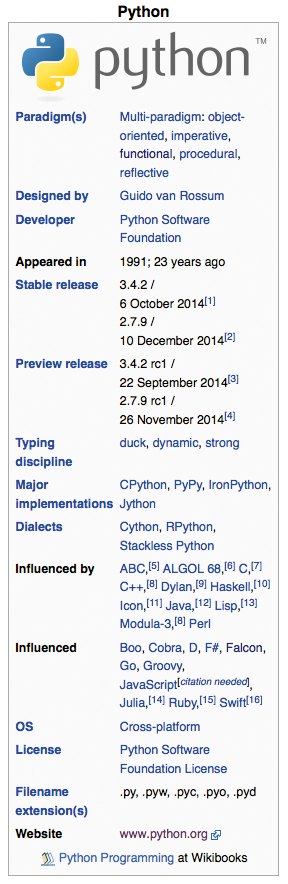
Abbildung 2: Diese in der Wikipedia verwendeten Kästen wertet das Beispielprogramm per Webscraping aus, einmal synchron, einmal asynchron.
Die gesammelten Informationen lassen Aussagen über die Herkunft und Einflüsse von Programmiersprachen zu. Um sie zu extrahieren, macht Python zwei grundlegende Schritte: Im ersten lädt ein Skript eine Seite herunter, im zweiten wertet es deren Inhalt aus. Letzteres bedeutet konkret, dass es die Links zu den Seiten der anderen Programmiersprachen aus dem Infokasten isoliert. Dann beginnt das Spiel wieder von vorn.
HTML auswerten
Bevor Listing 1 die Webseite parsen kann, hilft »urllib.request.urlopen()« dabei, sie herunterzuladen – zumindest im synchronen Ansatz (Listing 2, Zeile 35). Dabei verwendet die Funktion die URL als Argument.
Listing 1
parse_html.py
01 """Parsing a Wikipedia page about a programming language.
02
03 We extract the relationship 'Influenced by' and 'Influenced' to other
04 languages.
05 """
06
07
08 from collections import defaultdict
09
10 import bs4
11 from bs4 import BeautifulSoup
12
13
14 def _find_info_table(html):
15 """Find the table with info box on the right hand side.
16
17 This box contains the information about languages that influenced
18 the target language as well as about languages that got influenced
19 by it.
20 """
21 return html.find('table', attrs={'class': 'infobox vevent'})
22
23
24 def _find_lang_row(info_table, target_header):
25 """Find the row in the table that contains `target_header`.
26
27 Where `target_header` is either 'Influenced by' or 'Influenced'.
28 """
29 res = None
30 for row in info_table:
31 header = getattr(row, 'th', None)
32 if header and header.contents[0] == target_header:
33 res = row
34 break
35 return res
36
37
38 def _make_lang_map(lang_row):
39 """Map the url to the language.
40
41 We use a set to hold the language name just in case there are
42 several spellings for a language, i.e. an entry with the same url.
43 """
44 res = defaultdict(set)
45 tags = (entry for entry in lang_row.find('td')
46 if isinstance(entry, bs4.element.Tag))
47 for tag in tags:
48 href = tag.get('href')
49 name = str(tag.contents[0]) if href else None
50 if name:
51 res[href].add(name)
52 return res
53
54
55 def parse(html_text):
56 """Parse the given HTML.
57 """
58 html = BeautifulSoup(html_text)
59 info_table = _find_info_table(html)
60 res = {}
61 if not info_table:
62 return res
63 for target_header in ['Influenced by', 'Influenced']:
64 lang_row = _find_lang_row(info_table, target_header)
65 if lang_row:
66 mapping = _make_lang_map(lang_row)
67 else:
68 mapping = {}
69 res[target_header] = mapping
70 return res
Python bietet ansonsten einige Werkzeuge, die HTML-Quelltext einlesen und auswerten. Sie stecken im Parser von Listing 1, das einen Ansatz mit Beautiful Soup [11] demonstriert. Die Funktion »_find_info_table()« (Zeile 14) sucht den Anfang des Infokastens, »_find_lang_row()« fahndet nach der Tabellenzeile mit den gesuchten Überschriften, im Beispiel »Influenced by« sowie »Influenced« . Sie enthalten die Namen der Programmiersprachen und die Links zu weiteren Wikipedia-Seiten.
Diese Informationen steckt »_make_lang_map()« (Zeile 38) in ein Dictionary mit dem Link als Schlüssel und dem Namen der Sprache als Wert. Vorsichtshalber steht der Name in einem Set, um unterschiedliche Schreibweisen einer Sprache zu berücksichtigen, die aber auf denselben Link verweisen.
Die Funktion »parse()« (Zeile 55) nutzt die drei gerade beschriebenen Funktionen, um die interessanten Teile des HTML-Markup in Python-Datenstrukturen zu verwandeln. Fehlt der Infokasten, bleibt »info_table« leer und die zugehörige Funktion liefert ein leeres Dictionary. Ist der Kasten präsent, kann er beide, nur eine oder gar keine der Kategorien »Influenced by« und »Influenced« enthalten. Deshalb bekommt das Ergebnis-Dictionary als Wert für eine fehlende Kategorie ein leeres Dictionary oder das Ergebnis von »_make_lang_map()« , wenn die Kategorie einen Inhalt hat.
Schön der Reihe nach
Während weiter unten eine asynchrone Variante folgt, zeigt Listing 2 eine rein synchrone Version des Scrapers, sie heißt »get_synchronous.py« und importiert zunächst die benötigten Bibliotheken. Das Modul »shelve« aus der Standardbibliothek errichtet eine einfache Datenbank, die wie ein persistentes Dictionary funktioniert und die Ergebnisse aufnimmt. Die Funktion »urllib.request.urlopen()« lädt wie erwähnt die Webseite herunter. Dann importiert das Skript (Zeile 8) die Funktion »parse()« aus Listing 1.
Die Klasse »LanguageInfluences« enthält die wichtigen Programmbestandteile, die Methode »__init__()« bringt diverse Parameter mit (Zeilen 15 bis 19), etwa die Start-URL und den Datenbanknamen. Die Suche beginnt mit Python (Zeile 15). Der Code begrenzt die Anzahl der untersuchten Programmiersprachen auf 100 (»limit=100« ), damit das Programm nicht endlos läuft.
Die Methode »get_url_content()« (Zeile 27) achtet darauf, dass die verlinkten Zielseiten mit »/wiki« beginnen und es sich damit sowohl um relative Links als auch um Wikipedia-Seiten handelt. Hat das Skript die URL zusammengebaut, holt »urlopen()« die Seite und schiebt sie durch »self.parse« .
Die importierte Funktion »parse()« steckt das Ergebnis in ein Dictionary, das den Namen der jeweiligen Sprache trägt und als Inhalt das Dictionary mit den Einträgen unter »Influenced by« und »Influenced« (Zeile 44). Dann speichert das Skript dieses Dictionary in der »shelve« -Datenbank »self.db« .
Die Methode »work()« startet eine rekursive Reise über die Wikipedia-Seiten. Befindet sich die Start-URL noch nicht in der Datenbank, holt die Methode »get_url_content()« aus Zeile 52 den Inhalt der Wikipedia-Seite über Python. Die Auswertung läuft, solange die Zahl der Datenbankeinträge die Grenze von 100 nicht überschreitet (»len(self.db) <= self.limit« ). Fehlen der Infokasten oder die Kategorie auf einer Seite, geht es einfach weiter zur nächsten Kategorie. Das Programm arbeitet nur, wenn es die passenden Inhalte vorfindet. Steht eine extrahierte URL noch nicht in der Datenbank (»if url not in self.db:« ), läuft der Prozess rekursiv weiter und die damit heruntergeladene Seite wird ihrerseits zur Link-Spenderin.
Natürlich bestehen sehr enge Verbindungen zwischen den Sprachen. Zum Beispiel hatten Algol und C Einfluss auf sehr viele Sprachen. Das Programm muss also kontrollieren, ob es eine bestimmte Wiki-Seite bereits heruntergeladen hat, andernfalls würde dieselbe Seite immer wieder in der Bearbeitungsschleife landen – ein schönes Beispiel für eine Rekursion ohne Ausstiegspunkt.
Die Funktion »test()« (Zeile 66) bearbeitet die heruntergeladenen Seiten und misst nebenbei, wie lange das dauert. Der Referenzwert auf der Maschine des Autors liegt bei etwa 86 Sekunden. Abhängig von der Netzwerkanbindung wird dieser Wert natürlich signifikant schwanken. Ob das Ganze asynchron schneller geht, verrät der nächste Abschnitt.
Nun asynchron
Listing 3 enthält die asynchrone Variante des Codes, wobei es recht unterschiedliche Möglichkeiten gibt, Asyncio einzusetzen. Das Programm nutzt die wahrscheinlich einfachste, die Unterschiede zu Listing 2 fallen daher eher gering aus. Natürlich muss das Skript »asyncio« zunächst als Modul importieren. Das zugehörige Modul »aiohttp« lehnt sich an »asyncio« an und lässt sich einfach mit »pip install aiohttp« auf den Rechner holen.
Listing 3
Asynchrones Scrapen mit get_asynchronous.py
01 """Asynchronous webscraping.
02 """
03
04 import asyncio
05
06 import aiohttp
07
08 from get_synchronous import LanguageInfluences
09 from parse_html import parse
10
11
12 class AsyncLanguageInfluences(LanguageInfluences):
13 """Asynchronous version.
14 """
15 @asyncio.coroutine
16 def get_url_content(self, url, name):
17 """Get and parse the content of the URL.
18 """
19 if not url.startswith('/wiki/'):
20 print('Skipping URL:', url)
21 return None
22 full_url = self.url_base + url
23 print('fetching', full_url)
24 http_response = yield from aiohttp.request('GET', full_url)
25 html = (yield from http_response.read_and_close())
26 return (yield from self.parse(html, url, name))
27
28 @asyncio.coroutine
29 def parse(self, html, url, name):
30 """Parse and store in DB.
31 """
32 if html:
33 content = parse(html)
34 data = {'name': name, 'content': content}
35 self.db[url] = data
36 return content
37
38 @asyncio.coroutine
39 def work(self, content=None):
40 """Process urls recursively.
41 """
42 if not content and self.start_url not in self.db:
43 content = yield from self.get_url_content(self.start_url,
44 self.start_name)
45 if content and len(self.db) <= self.limit:
46 for category in self.categories:
47 for url, names in content[category].items():
48 if not url or url == 'None':
49 continue
50 name = next(iter(names))
51 if url not in self.db:
52 content = yield from self.get_url_content(url, name)
53 yield from self.work(content)
54
55 if __name__ == '__main__':
56
57 def test():
58 """Run and measure the runtime.
59 """
60 import timeit
61 start = timeit.default_timer()
62 langs = AsyncLanguageInfluences()
63 loop = asyncio.get_event_loop()
64 loop.run_until_complete(langs.work())
65 duration = timeit.default_timer() - start
66 print(duration)
67
68 test()
Es bringt mehrere Funktionen mit, um asynchron mit dem HTTP-Protokoll zu reden. Eine davon heißt »aiohttp.request()« (Zeile 24). Sie löst »urllib.request.urlopen()« ab, kennt 17 Keyword-only-Parameter und ist in etwa 50 Zeilen Code implementiert, die viele – auch fehlerträchtige – Details abfangen.
Die Klasse »AsyncLanguageInfluences« erbt von »LanguageInfluences« und überschreibt die Methoden »get_url_content()« (Zeile 16), »parse()« (Zeile 29) und »work()« (Zeile 39). Dabei fallen grundlegende Unterschiede auf: Der Entwickler stellt vor die Methoden jeweils den Dekorator »@asyncio.coroutine« und ruft die Coroutinen nicht direkt auf, sondern lässt »yield from« dies übernehmen. Auch der Start des Programms in »test()« verläuft anders. Die Funktion »asyncio.get_event_loop()« liefert die Eventloop, die mit »run_until_complete()« die Coroutine »langs.work()« in eine Task einpackt und dann bis zum Ende durchlaufen lässt.
Listing 2
Synchrones Scrapen mit get_synchronous.py
01 """
02 Synchronous webscraping.
03 """
04
05 import shelve
06 from urllib.request import urlopen
07
08 from parse_html import parse
09
10
11 class LanguageInfluences(object):
12 """Find programming languages and the their influnces.
13 """
14
15 def __init__(self, start_name='Python',
16 start_url='/wiki/Python_(programming_language)',
17 limit=100,
18 url_base='http://en.wikipedia.org',
19 db_name='languages'):
20 self.start_name = start_name
21 self.start_url = start_url
22 self.limit = limit
23 self.db = shelve.open(db_name)
24 self.url_base = url_base
25 self.categories = ['Influenced by', 'Influenced']
26
27 def get_url_content(self, url, name):
28 """Get and parse the content of the URL.
29 """
30 if not url.startswith('/wiki/'):
31 print('Skipping URL:', url)
32 return None
33 full_url = self.url_base + url
34 print('fetching', full_url)
35 with urlopen(full_url) as http_response:
36 html = http_response.read()
37 return self.parse(html, url, name)
38
39 def parse(self, html, url, name):
40 """Parse and store in DB.
41 """
42 if html:
43 content = parse(html)
44 data = {'name': name, 'content': content}
45 self.db[url] = data
46 return content
47
48 def work(self, content=None):
49 """Process urls recursively.
50 """
51 if not content and self.start_url not in self.db:
52 content = self.get_url_content(self.start_url, self.start_name)
53 if content and len(self.db) <= self.limit:
54 for category in self.categories:
55 if category not in content:
56 continue
57 for url, names in content[category].items():
58 if not url or url == 'None':
59 continue
60 name = next(iter(names))
61 if url not in self.db:
62 self.work(self.get_url_content(url, name))
63
64 if __name__ == '__main__':
65
66 def test():
67 """Run and measure the runtime.
68 """
69 import timeit
70 start = timeit.default_timer()
71 langs = LanguageInfluences()
72 langs.work()
73 duration = timeit.default_timer() - start
74 print(duration)
75
76 test()
Der Rest des Programms entspricht der synchronen Version. Die Laufzeit auf dem System verringerte sich auf durchschnittlich 48 Sekunden. Damit ist das Programm um den Faktor 1,8 schneller als die synchrone Variante mit 86 Sekunden.
Fazit
Menschen denken normalerweise sequenziell, führen einen Schritt nach dem anderen aus. Asynchrone Abläufe lassen sich häufig nur schwer nachvollziehen, sind aber unter bestimmten Voraussetzungen sinnvoll. Mit »asyncio« bekommt Python 3 einen mächtigen Helfer, um Probleme asynchron zu lösen. Zudem macht es das Modul einfach, etablierte Bibliotheken einzubinden.
Auch Guido van Rossum scheint sich im Video [9] für »yield from« zu begeistern. Trotz der recht komplexen Algorithmen, die darunterliegen, lässt sich Asyncio einfach nutzen. Synchrone Programme benötigen lediglich ein paar zusätzliche Zeilen, um asynchron zu laufen. Nicht zuletzt deshalb könnte Asyncio das noch zögerlich adoptierte Python 3 über das Thema asynchrone Programmierung vorwärtsbringen.
Infos
- Asyncio: https://docs.python.org/3/library/asyncio.html
- Twisted: https://twistedmatrix.com
- Tornado: http://www.tornadoweb.org
- Gevent: http://www.gevent.org
- Zero-MQ: http://zeromq.org
- Pyzero-MQ: http://zeromq.org/bindings:python
- Pyftpdlib: https://code.google.com/p/pyftpdlib/
- Details zu Asyncio in PEP 3156: http://legacy.python.org/dev/peps/pep-3156/
- Guido van Rossum über Asyncio: https://www.youtube.com/watch?v=aurOB4qYuFM
- PEP 380: https://www.python.org/dev/peps/pep-0380/
- Beautiful Soup: http://www.crummy.com/software/BeautifulSoup/bs4/doc/#
Der Autor

Dr.-Ing. Mike Müller ist Geschäftsführer der Python Academy http://www.python-academy.de und ein erfahrener Python-Trainer. Er ist erster Vorstandsvorsitzender des Python Software Verband e.V. und war Chairman der Euro-Python 2014 in Berlin. Auch die Euro-Sci-Py 2008 und 2009 sowie die Pycon DE 2011 und 2012 hat er geleitet.





