
© vichienrat jangsawang, 123RF
Damit Hobby-Youtuber Michael Schilli erfährt, wenn seine Guckerzahlen durch die Decke gehen, analysiert ein Perl-Skript täglich Trends und schlägt Alarm, falls ein Video plötzlich zum Hit wird.
Steht ein Hobby-Handwerker wie ich heute vor einem scheinbar unlösbaren mechanischen Problem, zum Beispiel weil das Gehäuse eines Gadgets sich gegen das Garantie-verachtende Öffnen sträubt, hilft meist ein Youtube-Video weiter. Auch bei nicht ganz einfach zu bedienender Software wie Gimp zeigt meist ein Fachmann in einem Screencast auf Youtube wie man als Hobbyist auch komplizierte Aufgaben löst.
Schiff der Träume
Als es mir vor einiger Zeit gelang, Gimps Scissor-Tool erfolgreich anzuwenden, machte ich gleich einen Screencast daraus. Danach wartete ich vergeblich darauf, dass dieses meisterlich produzierte Video in den Charts aufsteigt. Erst setzte ich mir monatliche Erinnerungstermine in Evernote, um in regelmäßigen Abständen die Anzahl der Views auf Youtube zu inspizieren. Aber das kostet Zeit, die ich nicht habe. Dank des CPAN-Moduls WebService::GData::YouTube geht es nun auch automatisch.
Hierzu listet die Yaml-Datei in Listing 1 die IDs der zu überwachenden Videos auf. Die Hex-Nummern habe ich einfach aus den entsprechenden Youtube-URLs extrahiert. So stammt zum Beispiel der String »_Cxu3-UP0G8« aus der URL-Zeile des Browsers (Abbildung 1).
Listing 1
youtube-watch.yml
01 - 02 name: GIMP - Scissors Select Tool 03 id: _Cxu3-UP0G8 04 - 05 name: How to fix Acura/Honda not starting in hot weather 06 id: ssYpyXjGw9g 07 - 08 name: Flip it: Record Messages and play them Backwards 09 id: LdSTIa2Tx4o 10 - 11 name: Scored a goal at Garfield Square 12 id: bvOvnyJTyss
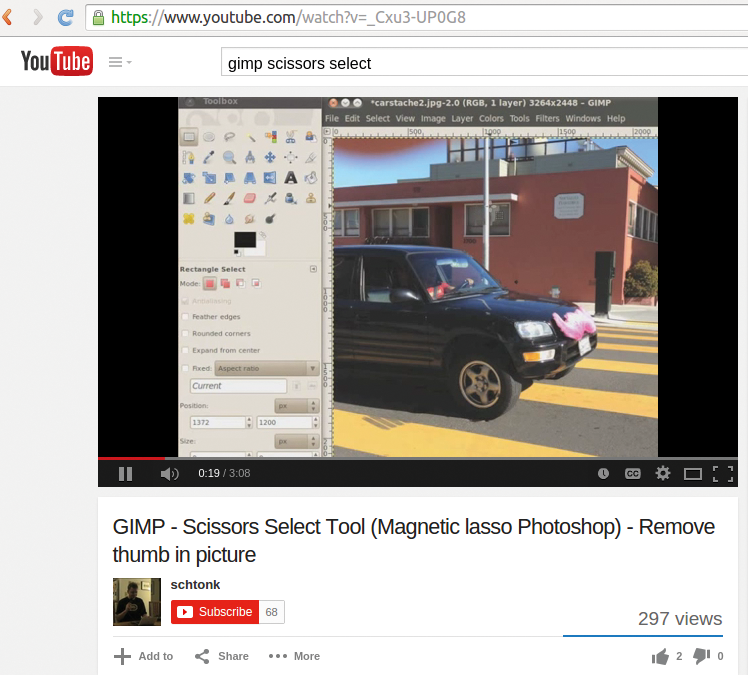
Abbildung 1: Der Hobbyproduzent dieses Youtube-Screencast möchte wissen, wie sich seine Userzahlen entwickeln (297 Views bisher).
Das Skript in Listing 2 geht nun mit Hilfe des Yaml-Moduls vom CPAN der Reihe nach durch die Einträge der Yaml-Datei und übergibt jeweils die Video-ID an die Methode »get_video_by_id()« des Pakets WebService::GData::YouTube. Dieses wiederum kontaktiert den API-Server von Youtube und bekommt einen Wust an Metadaten über das Video zurück. Unter dem Schlüssel »_feed« findet das Skript im Eintrag »yt$statistics« den Wert für »ViewCount« , also die Anzahl der Aufrufe des Videos.
Listing 2
youtube-viewcounts
01 #!/usr/local/bin/perl -w
02 use strict;
03 use WebService::GData::YouTube qw();
04 use YAML qw( LoadFile );
05 use Json qw( to_json );
06
07 my @result = ();
08 my $videos =
09 LoadFile( "youtube-watch.yml" );
10 my $yt = WebService::GData::YouTube->new();
11
12 for my $video ( @$videos ) {
13
14 my $meta =
15 $yt->get_video_by_id( $video->{ id } );
16
17 $video->{ count } = $meta->{ _feed }->
18 { 'yt$statistics' }->{ viewCount };
19
20 push @result, $video;
21 }
22
23 print to_json( \@result,
24 { pretty => 1, canonical => 1 } );
Die Zeilen 23 und 24 formen die Ausgabedaten noch schnell mittels des Json-Moduls vom CPAN in das maschinenlesbare Format um, damit nachfolgende Skripte wie Listing 3 sie leicht verarbeiten können. Dabei setzt es die Optionen »pretty« , um die Ausgabe auch für menschliche Konsumenten leicht lesbar darzustellen, und »canonical« , damit die sonst in Perl unsortierten Hashschlüssel sortiert herauskommen. Im Ergebnisarray »@result« führt dann jedes Element die Felder »name« (Titel des Videos), »count« (den in Zeile 17 hineingeschmuggelten Viewcount) und »id« , die eindeutige Youtube-Kennung des Videos.
Listing 3
viewcounts-todb
01 #!/usr/local/bin/perl -w
02 use strict;
03 use DBD::SQLite;
04 use Json qw( from_json );
05 use DBI;
06 my $dbh = DBI->connect(
07 "dbi:SQLite:dbname=viewcounts.db",
08 "", "", { RaiseError => 1} );
09
10 my $data = from_json( join '', <STDIN> );
11
12 for my $video ( @$data ) {
13 my $sth = $dbh->prepare(
14 "INSERT INTO
15 views(video_id,views,queried)
16 VALUES(?,?,CURRENT_TIMESTAMP)" );
17 $sth->execute( $video->{ id },
18 $video->{ count } );
19 }
Abbildung 2 zeigt die Ausgabe des Skripts und offenbart, dass meine bislang wenig öffentlich bekannte Tätigkeit als Automechaniker an 20 Jahre alten Honda-Motoren mit etwa 56000 Aufrufen zu den Highlights meines Oeuvres gehört, während der Gimp-Screencast mit nur 297 Aufrufen noch (!) vor sich hin dümpelt.
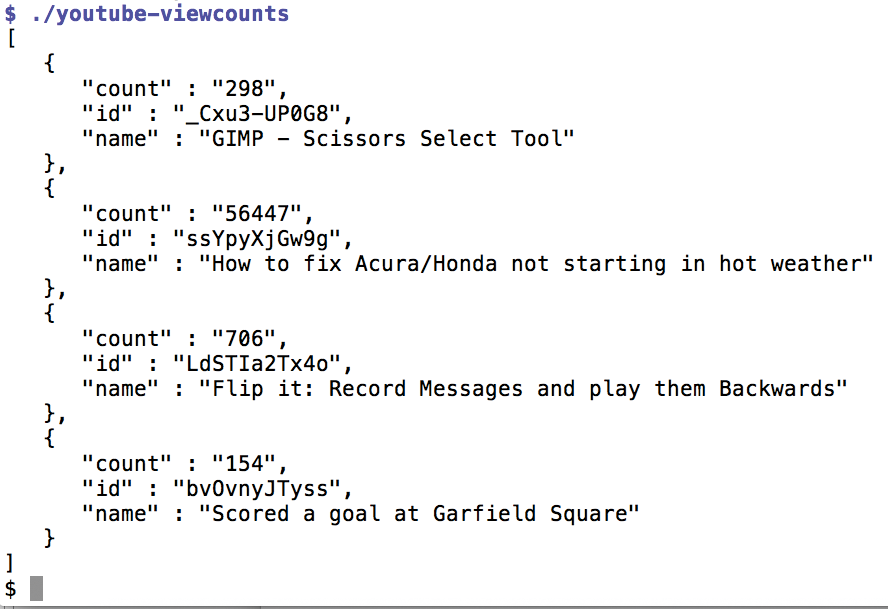
Listing 2 mit den von Youtube eingeholten Guckerzahlen pro Video.” width=”300″ height=”206″ />
Abbildung 2: Die Json-Ausgabe von Listing 2 mit den von Youtube eingeholten Guckerzahlen pro Video.Tägliche Tests
Läuft Listing 1 täglich mittels eines Cronjobs einmal ab, steht danach die Archivierung und spätere Auswertung der Daten an. Dazu dient in Listing 3 die Minidatenbank SQlite, die ihre Daten in einer einzigen Datei ablegt, aber SQL-Abfragen erlaubt.
Das in Listing 4 gezeigte Datenbankschema enthält Felder für die Youtube-ID des Videos (»video_id« ), die Anzahl der Views (»views« ) und den Datumstempel der Abfrage (»queried« ). Mit dem Befehl
Listing 4
viewcounts.sql
1 CREATE TABLE views ( 2 video_id TEXT, 3 views INTEGER, 4 queried DATE 5 );
sqlite3 viewcounts.db <viewcounts.sql
erzeugt SQlite dann die Datenbank in der frischen Datei »viewcounts.db« . Damit kann dann Listing 3 als zweite Brennstufe mit Hilfe von
youtube-viewcounts | viewcounts-todb
die von Listing 2 erzeugten Json-Daten entgegennehmen und für jeden Array-Eintrag einen Datenbankrecord anlegen.
Das Datumsfeld jedes neuen Eintrags füllt es in Zeile 16 mit »CURRENT_TIMESTAMP« , was SQlite in der Datenbank durch das aktuelle Datum mit Uhrzeit ersetzt. So entsteht für jedes überwachte Video pro Tag ein Datenbankeintrag mit Zeitstempel, der sich hinterher – zeitlich sortiert – leicht wieder herausholen lässt.
Anhand der in Abbildung 3 gezeigten Datenbankeinträge versucht nun Listing 5 herauszufinden, ob die Zuschauerzahlen nur stetig ansteigen oder sich explosionsartig erhöhen. In diesem Fall soll das Skript später den interessierten Beobachter alarmieren.
Listing 5
hit-detect
01 #!/usr/local/bin/perl -w
02 use strict;
03 use DBI;
04 use DBD::SQLite;
05 use Statistics::LineFit;
06 use YAML qw( LoadFile );
07 use Json qw( to_json );
08
09 my $dbh = DBI->connect(
10 "dbi:SQLite:dbname=viewcounts.db",
11 "", "", { RaiseError => 1} );
12
13 my $videos =
14 LoadFile( "youtube-watch.yml" );
15
16 for my $video ( @$videos ) {
17 my $sth = $dbh->prepare(
18 "SELECT views from views
19 WHERE video_id = ? ORDER BY
20 queried ASC" );
21 $sth->execute( $video->{ id } );
22
23 my @xvalues = ();
24 my @yvalues = ();
25
26 my $x = 1;
27 while ( my @row =
28 $sth->fetchrow_array ) {
29 push @xvalues, $x;
30 push @yvalues, $row[0];
31 $x++;
32 }
33
34 my $last_x = pop @xvalues;
35 my $last_y = pop @yvalues;
36
37 my $fit = Statistics::LineFit->new();
38 $fit->setData (\@xvalues, \@yvalues) or
39 die "Invalid data";
40
41 my ($intercept, $slope) =
42 $fit->coefficients();
43
44 my $y_predicted = $intercept +
45 $last_x * $slope;
46
47 if( abs( $last_y - $y_predicted ) >
48 3 * $slope ) {
49 print
50 "Hooray, $video->{ name } is a hit!\n";
51 }
52 }
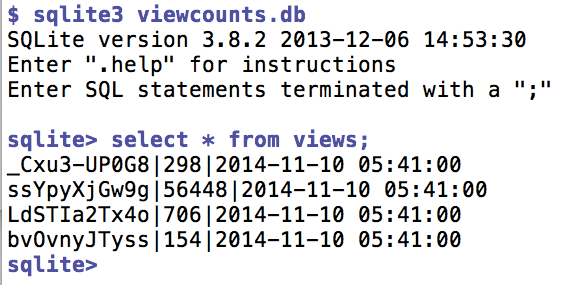
Abbildung 3: In der SQlite-Datenbank speichert das Skript täglich die aktuellen View-Zahlen ab.
Hitverdächtig?
Was macht aber einen hitverdächtigen Sprung aus? Bei einem Video mit 30000 Aufrufen, das im Schnitt zehn Views pro Tag zulegt, bedeuten diese zehn Hits mehr nicht viel. Bei einem weniger erfolgreichen, das lange unentdeckt blieb und plötzlich zehn Views zulegt, wäre vielleicht eine Notiz angebracht.
Weil ich kürzlich das ausgezeichnete Buch “Machine Learning with R” [2] studiert habe, das allerhand statistische Methoden erläutert, kam mir die Idee, ungewöhnliche Sprünge in den Viewerzahlen mittels linearer Regression [3] zu ermitteln. Dabei versucht das CPAN-Modul Statistics::LineFit in Listing 5 durch flache oder stetig ansteigende historische Zuschauerzahlen eine Gerade zu legen (Abbildung 4). Auf der x-Achse läuft die Zeit von links nach rechts, die y-Achse gibt die Anzahl der zum Messzeitpunkt vorliegenden Views an.
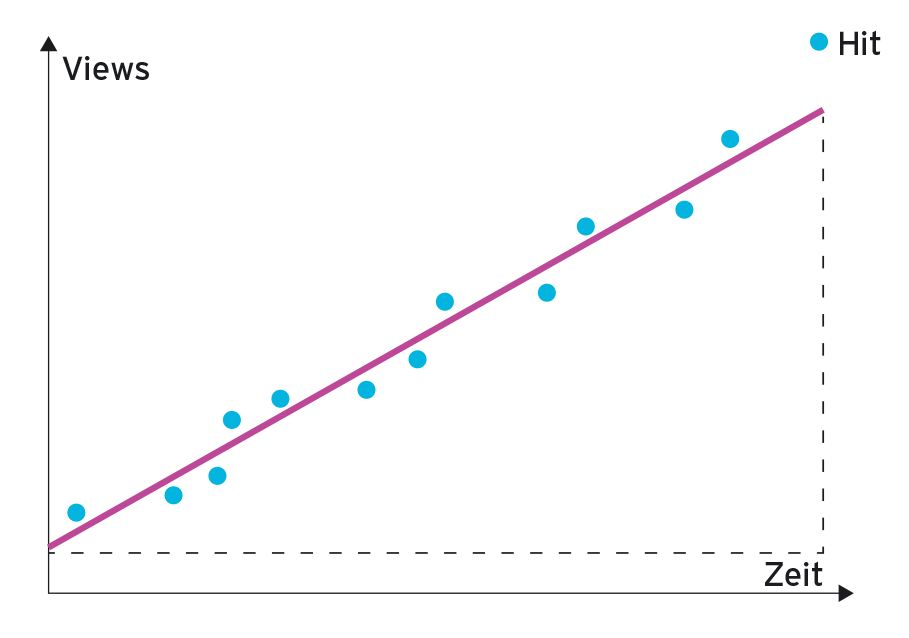
Listing 5, wenn der neueste Wert (blauer Punkt ganz rechts) den geschätzten Wert weit übersteigt.” width=”300″ height=”211″ />
Abbildung 4: Einen Hit erkennt Listing 5, wenn der neueste Wert (blauer Punkt ganz rechts) den geschätzten Wert weit übersteigt.Dabei ist es nicht so wichtig, dass die Gerade jeden Messpunkt genau trifft (was auch gar nicht möglich ist), solange das Verfahren die zwangsläufig auftretenden Fehler minimal hält. Das Problem ist wissenschaftlich seit Urzeiten gelöst, und das CPAN-Modul implementiert nur den Algorithmus, um die Parameter »a« und »b« aus der Geraden-Formel y = b + a*x zu berechnen. Der Parameter »b« gibt dabei den y-Wert am Nulldurchgang der Geraden an (Intercept), während »a« die Steigung (Slope) der Geraden darstellt.
Machine Learning Lite
Listing 5 iteriert in Zeile 16 durch alle zu überwachenden Videos und setzt für jedes einen SQL-Query ab, um die historischen View-Zahlen aufsteigend sortiert nach dem Messzeitpunkt hervorzuholen. Diese y-Werte stopft es in den Array »@yvalues« , während es die zugehörigen x-Werte bei 1 anfangen lässt und dann an jedem Messtag um jeweils 1 erhöht. In »$row[0]« , dem ersten Element einer jeden Zeile des SQL-Ergebnisses, steht der View-Count des gerade bearbeiteten Videos zum Messzeitpunkt.
Die Zeilen 34 und 35 entfernen dann den letzten (tagesaktuellen) Messwert, damit das Skript die Regressionsgerade nur durch die mehr als einen Tag zurückliegenden Messpunkte legt. Die Methode »coefficients()« in Zeile 42 liefert schließlich den errechneten Nulldurchgang in »$intercept« und die Steigung der Geraden in der Variablen »$slope« . Mit diesen interpoliert Zeile 44 den Wert für die letzte Messung »$y_predicted« , ermittelt also, welcher Wert zu erwarten wäre, falls die Zuschauerzahlen wie bisher weiter gestiegen wären.
Ist die Differenz zum wirklich gemessenen Wert dreimal so groß wie die Geradensteigung, liegt offensichtlich ein virales Video vor, und der User erfährt davon durch die ausgegebene Nachricht. Mit dem Faktor sollte man experimentieren, manch einer möchte vielleicht schon bei kleineren Erfolgen Bescheid bekommen. Statt der »print« -Anweisung empfiehlt sich das Absenden einer HTML-E-Mail, zum Beispiel mit dem CPAN-Modul Mail::DWIM, das dazu nur ein paar Zeilen benötigt, sodass der Empfänger gleich auf sein frischgebackenes Hitvideo klicken kann.
Online PLUS
In einem Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/2015/1/plus
Infos
- Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2015/01/Perl
- Brett Lantz, “Machine Learning with R”: Packt Publishing, 2013
- Lineare Regression: http://de.wikipedia.org/wiki/Lineare_Regression
Der Autor

Michael Schilli arbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. In seiner seit 1997 erscheinenden Kolumne forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





