
© Andre Helbig, 123RF
Docker ist jung – und schon deshalb bloß ein Hype? Damit aus dem Projekt eine feste Größe innerhalb der Open-Source-Welt wird, braucht es ein umfassendes und zuverlässiges Ökosystem rund um die Containervirtualisierung. Doch reichen die Ansätze von Red Hat und Google aus?
Trends zirkulieren in der IT-Welt regelmäßig. Die Branche giert nach Neuem und stürzt sich begierig auf alles, was zum Spielen und Basteln einlädt. Nach der ersten Phase der Neugier findet üblicherweise die der Konsolidierung statt. In ihr stellt sich für Admins und Unternehmen heraus, welche Technik eine Zukunft hat und was lediglich zur Eintagsfliege taugt.
An diesem Punkt befindet sich auch Docker (siehe Kasten “Docker-Basics”, [1]) zurzeit: Versetzte das Werkzeug die Virtualisierungswelt zunächst in Verzückung, weil es einige der Probleme der Vollvirtualisierung behob, stellt sich nun zunehmend die Frage: Wie lässt sich Docker in den typischen Alltag im Rechenzentrum integrieren und kann es die Probleme bisheriger Ansätze lösen? Der Artikel zeigt, was Unternehmen für Docker entwickeln und in welchen Bereichen sich die Containervirtualisierung in Zukunft womöglich etabliert.
Docker-Basics
Docker bietet auf Basis verschiedener Funktionen im Linux-Kernel Virtualisierung auf Kernelebene an. Im Gegensatz zu KVM und anderen Vollvirtualisierern setzt Docker aber nicht voraus, dass die zu virtualisierende Anwendung in einem eigenen System mit eigenem Kernel läuft. Vielmehr teilen sich die virtuelle Applikation und das Hostsystem die Systemressourcen. Mehr Details darüber, wie Docker arbeitet, liefern zwei jüngere Artikel http://2, http://3 aus dem Linux-Magazin.
Rund um Docker
Oft fällt in Diskussionen über die Zukunft eines Projekts das Schlagwort “Ökosystem”. Die Frage lautet, ob es einer als “hip” geltenden Technik gelingt, ein nachhaltiges Ökosystem um sich herum aufzubauen. Wie wichtig das sein kann, zeigen enge Verwandte von Docker, die Linux Container (LXC, [4]), die an sich sehr einleuchtende Ideen verfolgen. Dennoch ist es LXC nie gelungen, den anfänglichen Hype zu kultivieren, um Kapital daraus zu schlagen (Abbildung 1). Als LXC erstmals in die Öffentlichkeit drängte, berauschte sich die Linux-Welt gerade an den Fähigkeiten von KVM, Xen oder VMware – LXC fand in der öffentlichen Wahrnehmung kaum statt.
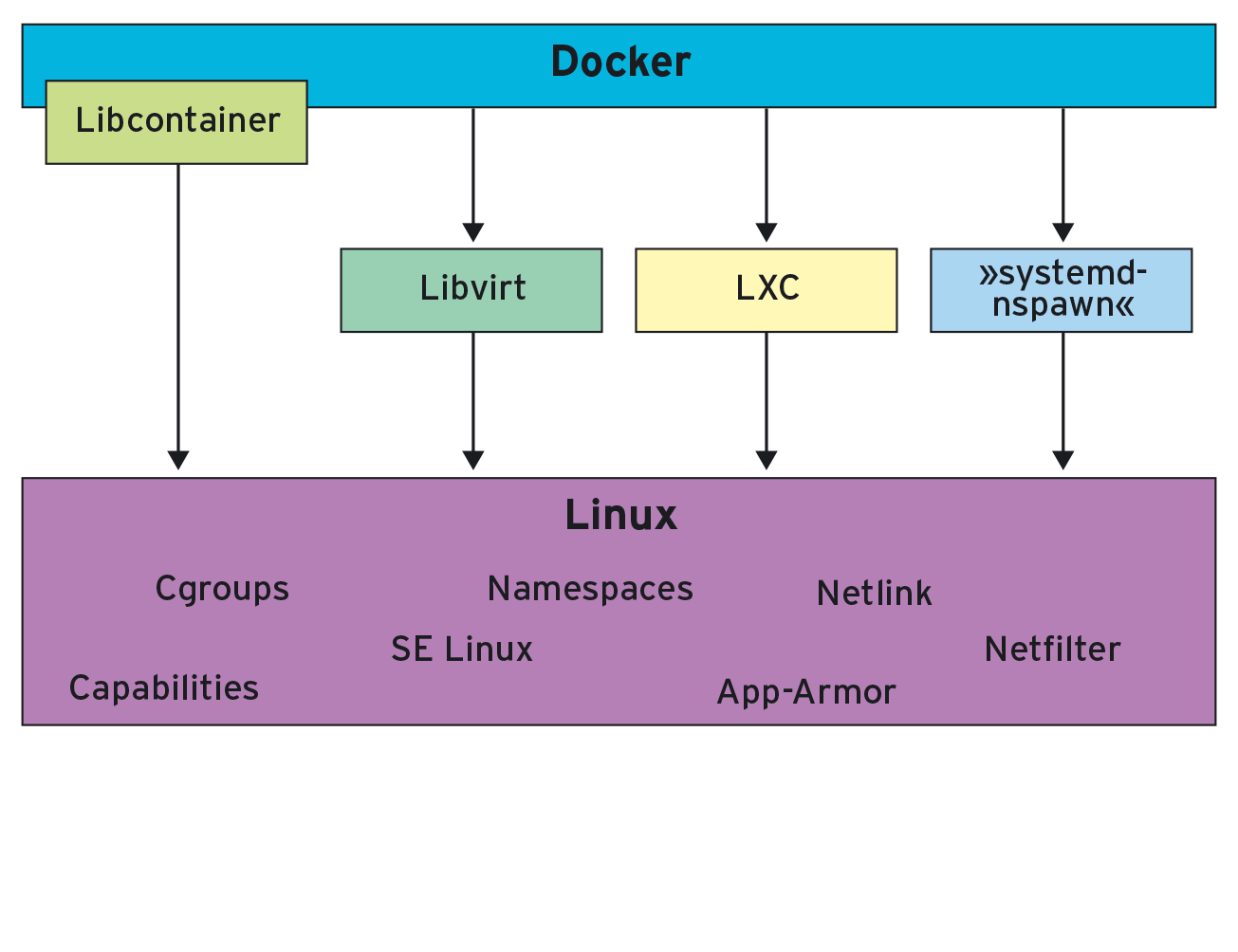
Abbildung 1: Seit Version 0.9 verzichtet auch Docker auf den standardmäßigen Einsatz von LXC.
Neben der Dominanz der Vollvirtualisierer kämpfte LXC aber noch mit einem anderen Problem: Es war recht unkomfortabel. Ein lokal angelegter Container beispielsweise war verhältnismäßig aufwändig zu warten.
Docker-Nutzer dagegen erhalten nicht nur die eigentliche Virtualisierung, sondern auch diverse Werkzeuge, mit denen sie Container sehr schnell erstellen, warten und verteilen. Das erlaubt es ihnen, Docker-Images über entsprechende Portale zu erwerben und zu verschiffen. Dieser Community-Faktor dürfte ein wichtiger Grund dafür sein, dass Docker sehr wenig Zeit brauchte, um eine veritable Fangemeinde aufzubauen.
Stolpersteine im Hafen
Die einfache Bedienung und die gute Community-Anbindung sollten nicht darüber hinwegtäuschen, dass Docker allein nicht glücklich macht. Möchte ein Admin die Software im Rechenzentrum einsetzen, tut er das selten auf der grünen Wiese, sondern fügt sie in vorhandene Strukturen ein. Überdies fehlen Docker einige Optionen, die größere Setups dringend von Virtualisierern verlangen: Admins möchten den verfügbaren Speicher und die Rechenleistung zentral verwalten und setzen oft Frameworks ein, die auch in die Breite skalieren – das sind nur drei von vielen Beispielen.
Docker muss sich in vorhandene Management-Frameworks integrieren oder eigene Alternativen bieten, sonst hat es keine Chance. Für Docker spricht, dass Branchengrößen wie Google und Red Hat bereits angekündigt haben, Zeit und Mühe in die Software zu investieren.
Kubernetes
Gespitzte Ohren waren garantiert, als Google im Juni mit einer für Docker konzipierten Software aufwartete und Kubernetes [5] vorstellte. Das soll werden, was für andere Virtualisierungen bereits existiert: ein zentrales Management-Framework (Abbildung 2).
Abbildung 2: Kubernetes besteht aus mehreren Komponenten, die zusammenspielen, um die Docker-Hosts sinnvoll zu orchestrieren.
Die Kubernetes-Funktionen sollen es erleichtern, Docker-VMs zu steuern und zu verwalten [6]. Das umfasst gleich mehrere Ebenen. So soll sich Kubernetes wie ein Clustermanager in einem Rechnerverbund benehmen. Wer eine große Plattform auf Docker-Basis baut, benötigt nicht nur viele Rechner, sondern meist auch eine Möglichkeit, in die Breite zu skalieren. Ab Werk unterstützt Docker keines der beiden Szenarien, denn im Grunde ist es nichts anderes als ein Stück Software, das Funktionen des Linux-Kernels verwendet.
Als eine Art Orchestrierungssystem für Docker weiß Kubernetes, auf welchen Hosts gerade welche Docker-Container laufen. Das Prinzip ist über eine Server-Agent-Struktur implementiert. Nicht nur darin ähnelt Kubernetes in frappierender Weise den Cloudumgebungen im Stile von Open Stack, denn es kommt auch mit einem ausgefeilten, zentralen API daher, das es ermöglicht, den Dienst von außen zu steuern. Alle Requests landen also stets beim gleichen API, das im Hintergrund dann entsprechende Instruktionen an die Agents (Kubelets) auf den Docker-Systemen leitet.
Neues und Bewährtes
Google kredenzt bei Kubernetes einen Strauß hochaktueller Softwareprinzipien. So fehlen zum Beispiel allen Diensten von Kubernetes die Konfigurationsdateien in »/etc« , stattdessen kommt der Dienst »etcd« zum Einsatz. Wer sich mit Core OS (Abbildung 3) beschäftigt hat, kennt ihn: Als klassischer Key-Value-Store bietet er in einem Cluster allen Knoten die Möglichkeit, schnell an spezifische Konfigurationsparameter zu kommen.
Abbildung 3: Core OS ist ein Fork von Chrome OS und als solcher ein minimales Betriebssystem, das den Betrieb von Apps im Rahmen von Docker-Containern ermöglicht.
Zugleich setzt Kubernetes auf erprobte Konzepte: Alles, was das Starten, Stoppen und Terminieren von VMs betrifft, ahmt Libvirt nach. Daneben enthält Kubernetes Komponenten von Pacemaker. Wer Pacemaker nicht leiden kann, braucht nicht in Panik auszubrechen: Der Dienst gehört nicht direkt zu Kubernetes, das Projekt verwendet allerdings einige der Ideen und Designansätze hinter dem Clustermanager. Der Mühe Lohn ist, dass Kubernetes einen Container auf einem anderen Host automatisch neu startet, falls der ursprüngliche Gastgeber des Containers ausfällt.
Containerumschlag
Letztlich soll Kubernetes offenbar zu einem Managementwerkzeug reifen, das es dem Admin erlaubt, Docker-Container wie VMs in großen Cloudumgebungen zu warten und zu kontrollieren. Dazu wollen Googles Entwickler es ihm auch gestatten, alternative Scheduler, Storagesysteme und Distributionsmechanismen zu verwenden. Kubernetes soll auf physikalischer Hardware ebenso laufen wie in Cloudumgebungen. Ein Cluster umspannt aber nicht verschiedene Availability Zones, vielmehr bleibt es dem Admin überlassen, Cluster in HA-Deployments auf Zonen zu verteilen.
Gegen die Hype-Theorie spricht nicht nur, dass Zugpferd Google sich offenbar ernsthaft mit Dockers Integration in den Admin-Alltag beschäftigt. Auch Branchenriese Microsoft, der zunehmend seine Scheu vor Open-Source-Software verliert, will Kubernetes in seine Azure-Cloud integrieren. Die Entwickler arbeiten bereits an einem Kubernetes Visualizer [7], der die Pods, Minions und Container (Tabelle 1) in einem Cluster visualisiert, damit Admins nicht den Überblick verlieren. Nicht zuletzt hat auch VMware eine Partnerschaft mit den Dockern geschlossen und ist zugleich der Kubernetes-Community beigetreten.
Tabelle 1
Kubernetes-Komponenten
|
Komponente |
Funktionalität |
|---|---|
|
Master |
Die Hauptkomponente kontrolliert über ein zentrales API die Minions, beherbergt den Scheduler, die Replikationskontrolle und kommuniziert mit den Kubelets. |
|
Minions |
Begriff für die VM, auf der Docker mit den Containern läuft. Gruppen von Containern versammeln sich dabei jeweils in einem Pod. |
|
Pods |
Eine Docker-Instanz kann mehrere Pods enthalten, die jeweils mehrere Container beherbergen. Hauptzweck ist die Skalierbarkeit: Pods erleichtern das Teilen und Terminieren von Ressourcen. |
|
Kubelets |
Agents, die auf Basis von Manifesten überwachen, ob alle notwendigen Container in einem Pod starten und laufen. |
|
Labels |
Labels organisieren lose verbundene Pods über Key-Value-Einträge. |
Jenseits von Docker
Obwohl Kubernetes ein sehr aktives Projekt ist, sollte man das Engagement von Google keinesfalls als exklusiv für Docker verstehen. Mit Lmctfy (Let me container that for you, [8]) hat Google ein zweites Eisen im Feuer, das als Alternative zum Docker-Projekt gelten darf, auch wenn die Entwickler es eher als Alternative zu LXC betrachten [9].
Im Gegensatz zu LXC will Lmctfy das komplexe Cgroup-API nicht einfach weiterreichen, sondern den Zugang dazu vereinfachen. Auch Overcommitment – eine Methode, um gezielt die CPU- und Speicherressourcen des Hostsystems zu überziehen – und Ressourcen-Sharing sind geplant. Als kleinste Einheit in Googles Cloud wollen es die Entwickler zudem als Fundament für Toolchains tauglich machen.
Laut Roadmap [10] wird Lmctfy aus zwei Komponenten, CL1 und CL2, bestehen. CL1 interagiert direkt mit dem Kernel, um eine Containerpolicy umzusetzen, die der Admin über die CL2-Komponente definiert. Legt CL2 etwa fest, dass Container nicht mehr CPU beanspruchen dürfen, als die Gastmaschine anbietet, setzt CL1 diese Regel um, indem die Komponente die summierten CPU-Werte der Container beobachtet. Zurzeit arbeiten die Entwickler vor allem an der robusten Isolation von Ressourcen wie Speicher, Netzwerk, Disk-I/O und CPU für CL1. Einmal fertig soll es Abbilder der Root-Dateisysteme von Containern ex- und importieren, Checkpoints anlegen und Container auf andere Rechner verfrachten.
Ein Projekt namens C-Advisor (Container Advisor, [11]) legt hingegen die Grundlagen für CL2 und versorgt die Nutzer mit Informationen zu Performance und Ressourcennutzung ihrer Container. Dazu werkelt C-Advisor als Daemon im Hintergrund, sammelt, sortiert, bewertet und exportiert Informationen maschinenweit. Die Software läuft auch in den Docker-Instanzen, die Kubernetes verwaltet, sie unterstützt zurzeit sowohl Docker als auch Lmctfy.
Nach der Einführung von Kubernetes hat Google die Arbeit an Lmctfy keineswegs eingestellt. Allerdings scheint es nicht sehr wahrscheinlich, dass beide Projekte dauerhaft existieren. Google wird vermutlich eine Entscheidung fällen, sobald klar ist, welches Tool auf Dauer eine größere Nutzerbasis erreicht und mehr Funktionalität bietet.
Project Atomic
Auf der gleichen Abstraktionsebene wie Kubernetes buhlt auch Project Atomic [12] um die Gunst seiner Nutzer. Und wie Kubernetes (und übrigens auch Core OS, [13]) handelt es sich um einen Umbau für Docker, der die vorhandene Docker-Funktionalität um ein Management-Framework und Cluster-Fähigkeit erweitert.
Dem Projekt zugrunde liegt der Project Atomic Host, ein auf die absolute Basisfunktionalität zurückgestutztes Linux, dessen einzige Aufgabe im Betrieb von Docker-Containern besteht. Hinzu kommt – wie bei Kubernetes oder Core OS – eine Reihe von Daemons, die sich um verschiedene Faktoren des Systems kümmern. Project Atomic setzt massiv auf Docker, Systemd [14], Geard [15], das sich um die Integration von Systemd und Docker kümmert, sowie RPM-OS-Tree [16]. SE Linux schottet die Container gegeneinander ab.
Analog zu Kubernetes hat auch Project Atomic einen prominenten Unterstützer: Geld für die Entwicklung kommt direkt von den roten Hüten aus Raleigh. Insofern darf Project Atomic als Produkt gelten, das Red Hat gegen Kubernetes und Core OS ins Feld führt. Offenbar will man sich den vermeintlich lukrativen Containermarkt nicht einfach so von Wettbewerbern abluchsen lassen.
So überrascht es kaum, dass der Project-Atomic-Host auf RHEL, Fedora oder (künftig) Centos beruht (Abbildung 4). Systemd kümmert sich um die Containerabhängigkeiten und reagiert auf Fehler, Journald sammelt und ordnet Containerlogs. RPM-OS-Tree dient als Upgradesystem, das bootbare Dateisystembäume verteilt und so atomare Upgrades ermöglicht. Weil es dabei auch die vorherigen Versionen einer Software aufbewahrt, erlaubt es im Fehlerfall Rollbacks.
Abbildung 4: So einfach kann es gehen: RHEL erweckt einen Docker-Container in wenigen Zeilen zum Leben.
Technisch unterscheidet sich Project Atomic sonst nicht allzu stark von Core OS oder Kubernetes – es ist ja gut, dass es mehr als einen Weg gibt, um Docker in größeren Szenarien einzusetzen.
Open Stack und Docker
Wenige Themen waren in den einschlägigen Foren und Zeitschriften so lange so präsent wie Open Stack [17]. Das ehemals kleine Projekt zieht nun Geld und Entwickler von praktisch allen namhaften Unternehmen an, darunter IBM, Intel, HP, Dell und VMware. Open Stack ist ein klassisches Beispiel für eine Anwendung, die sich ihr eigenes Ökosystem aufgebaut hat. Was läge näher, als die eine Hipster-Technik mit der anderen zu kombinieren – zumal Open Stack ein Framework für Virtualisierung ist und Docker ein Virtualisierer.
Genau das dürften sich auch die Open-Stack-Entwickler gedacht haben, die an einer Docker-Integration arbeiten (Abbildung 5). Während Kubernetes und das Project Atomic noch relativ jung sind, wird die Docker-Integration in Open Stack bereits seit einigen Monaten diskutiert, entsprechend weit ist die Integration. Nova, das in Open Stack virtuelle Systeme verwaltet, kommt mit Containern weitgehend zurecht. Der Imagedienst Glance kann mit Docker ebenfalls etwas anfangen, auch wenn er lediglich fertige Container aus Docker holt – direkt mit Docker spricht er bislang leider nicht. Wann diese Funktion kommt, ist nicht absehbar, weil Entwickler zwar schon länger an ihr arbeiten, vorzeigbarer Code allerdings noch aussteht.
Abbildung 5: Docker lässt sich mittlerweile auch direkt an Open Stack anbinden, allerdings ist die Integration Design-bedingt noch etwas holprig.
Insgesamt lässt auch die Docker-Integration von Open Stack für Admins noch einiges zu wünschen übrig, doch ließen sich im Verlauf der letzten Releases von Open Stack deutliche Verbesserungen ausmachen. Gelingt es Docker, dauerhaft einen Fuß in die Open-Stack-Türe zu setzen, dürfte kaum noch jemand am Stehvermögen zweifeln.
Ausblick
Alles in allem befindet sich Docker gerade in einer kritischen Phase seines Wachstums. Vor allem das Ökosystem dürfte entscheiden, ob sich Docker, wie sein direkter Vorgänger LXC, als Strohfeuer entpuppt oder gekommen ist, um zu bleiben. Die vorgestellten Managementwerkzeuge von Google und Red Hat und die Liebe, die Docker gerade seitens VMware und Microsoft erfährt, deuten auf ein längeres Abenteuer hin.
Ein paar Fragen bleiben offen, besonders die, wie Admins mit der neuen Art der Virtualisierung sinnvoll umgehen. Kristian Köhntopp führt in einem Artikel [18] aus, dass die “Works for me”-Mentalität, die er bei den Entwicklern von Docker-Containern anzutreffen meint, im Alltag eines Rechenzentrums und für normale Sysadmins nur selten funktioniere. Bekommt Docker solche Probleme in den Griff, ist mit seinem Verschwinden vorerst nicht zu rechnen.
Infos
- Docker: https://www.docker.com
- M. Feilner, M. Unke, M. Giese, “Hafenarbeiter”: Linux-Magazin 09/14, S. 32
- M. Feilner, M. Unke, M. Giese, “Intelligenter stapeln”: Linux-Magazin 09/14, S. 56
- LXC: https://linuxcontainers.org
- Kubernetes: https://github.com/GoogleCloudPlatform/kubernetes
- Design von Kubernetes: https://github.com/GoogleCloudPlatform/kubernetes/blob/master/DESIGN.md
- Microsoft macht in Kubernetes: http://msopentech.com/blog/2014/08/28/docker-containers-on-microsoft-azure-with-kubernetes-visualizer/
- Lmctfy: https://github.com/google/lmctfy
- Lmctfy versus LXC: http://stackoverflow.com/questions/19196495/what-is-the-difference-between-lmctfy-and-lxc
- Roadmap für Lmctfy: https://github.com/google/lmctfy/blob/master/README.md#roadmap
- C-Advisor: https://github.com/google/cadvisor/
- Projekt Atomic: http://www.projectatomic.io
- Core OS: https://coreos.com
- Systemd: http://www.freedesktop.org/wiki/Software/systemd/
- Geard: http://openshift.github.io/geard/
- RPM-OS-Tree: https://github.com/projectatomic/rpm-ostree
- Open Stack: http://www.openstack.org
- Text von Kristian Köhntopp: https://docs.google.com/document/d/1LlPWnzTHH6spRrvOXOXa2P5GIqsBA-cS5Mw_V7RM8tI/edit#heading=h.2t6eqym2zh08





