
© smileus, 123RF
Wer viele Cluster verwaltet, sollte minutiös darauf achten, dass im verteilten Serverzoo geordnete Abläufe herrschen. Linux-Magazin-Autor Konrad Giæver Beiske beschreibt, wie Apache Zookeeper diese Aufgabe in seiner Firma erfüllt und wofür man die Software besser nicht verwendet.
Admins, die Compute-Cluster mit einer bestimmten Anzahl an Knoten und HA-Anforderung verwalten, benötigen irgendwann ein zentrales Managementtool, das sich zum Beispiel um die Namensgebungen, Gruppierungen oder Konfigurationen der Horde kümmert. Dank des Zoowärters Zookeeper [1], der unter der Apache-2.0-Lizenz steht, muss nicht jeder Cluster selbst einen Synchronisierungsdienst mitbringen. Die Software lässt sich in vorhandene Systeme einhängen, zum Beispiel in Hadoop-Cluster.
Server und Clients
Ein Zookeeper-Server behält den Status aller Knoten des Systems im Auge, bei größeren dezentralen Systemen lassen sich mehrere replizierende Server einsetzen (Abbildung 1). Die synchronisieren dann untereinander Informationen zum Status der Knoten und sorgen dafür, dass die Systemtasks in fester Folge ablaufen und keine Inkonsistenzen auftreten.
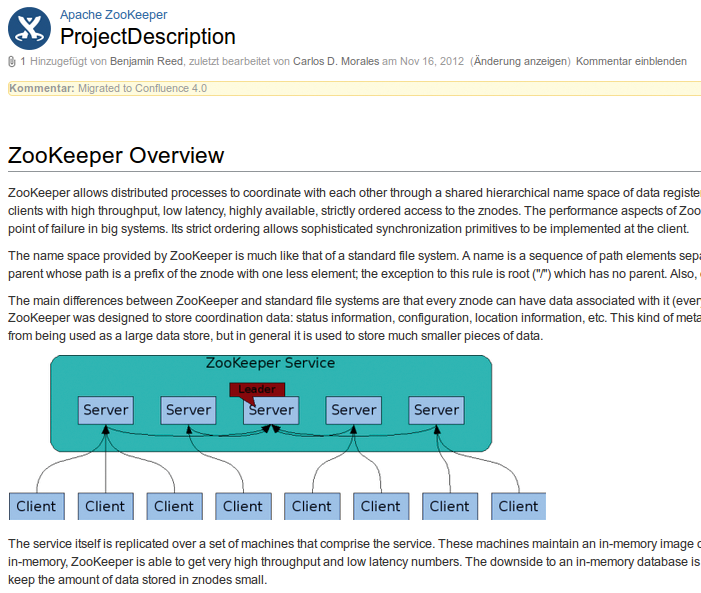
Abbildung 1: Zookeeper ist ein Apache-Projekt und kümmert sich um die Kommunikation der Knoten in einem Cluster.
Man kann sich Zookeeper selbst als ein verteiltes Dateisystem vorstellen, weil es seine Informationen analog zu einem Dateisystem organisiert. An der Spitze steht ein Wurzelverzeichnis, kurz als »/« bezeichnet. Darunter warten die so genannten Z-Nodes, Zookeeper Nodes, der Begriff soll sie von Computer-Nodes unterscheiden.
Ein Z-Node tritt dabei sowohl als Binärdatei als auch als Verzeichnis für weitere Z-Nodes auf, die als Unterknoten dienen. Wie die meisten Dateisysteme bringt auch jeder Z-Node Metadaten mit, die neben Versionsinformationen Lese- und Schreibrechte regeln.
Ordnung im Cluster
Der Admin kann einen Zookeeper-Server im Standalone-Modus oder mit Replikation betreiben, Beispielkonfigurationen dazu liefert das Onlinehandbuch unter [2] und [3]. Der zweite Fall erscheint im Licht verteilter Dateisysteme vorteilhafter, der erste eignet sich eher für Tests und die Entwicklung. Eine Gruppe replizierter Server, die der Admin einer Anwendung zuordnet und die dieselbe Konfiguration verwenden, bilden ein Quorum (siehe Kasten “Quorum”).
Quorum
Fallen Teile eines Netzwerks aus, drohen in verteilten Systemen Inkonsistenzen, weil das eine Netzwerksegment nicht mehr weiß, was im anderen vorgeht. Vor solchen Split-Brain-Szenarios schützt sich Zookeeper mit Hilfe von Majority-Quoren. Ein Client erhält nur dann eine Antwort von Zookeeper, wenn mehr als die Hälfte aller Nodes in einem Quorum laufen. Verbindet sich ein Client mit einem Zookeeper-Server, der nicht Teil des Quorums ist, verweigert dieser die Antwort.
Kommen im Zookeeper-Setup drei oder mehr unabhängige Server zum Einsatz, formen diese einen Zookeeper-Cluster und wählen einen Master. Der empfängt jegliche Schreibzugriffe und informiert die anderen Server über die Reihenfolge der Änderungen. Die wiederum erzeugen Redundanz, falls der Master ausfällt, und entlasten ihn von Lese-Anfragen und Benachrichtigungen der Clients.
Es ist wichtig, das Konzept der Ordnung von Zookeeper zu verstehen, auf dem dessen Servicequalität beruht. Zookeeper ordnet alle Operationen so an, wie sie eintreffen. Die Information zu dieser Ordnung verbreitet sich über den Zookeeper-Cluster an die anderen Clients auch dann, wenn der Master-Node ausfällt. Zwei Clients sehen zwar ihre Umwelt womöglich nicht zu jedem Zeitpunkt in exakt synchronem Zustand, aber sie beobachten alle Änderungen in derselben Reihenfolge.
Verfügbare Clients
Das Zookeeper-Projekt betreut zwei Clients, die in Java und C geschrieben sind, hinzu kommen Wrapper in anderen Programmiersprachen. Der Client erwartet, dass Zookeeper auf demselben Server läuft, und stellt automatisch eine Verbindung zu »localhost« auf Port 2181 her. Die Angabe »-server 127.0.0.1:2181« in Listing 1 kann also meist entfallen.
Listing 1
Mit dem Server verbinden
01 beiske-retina:~ beiske$ bin/zkCli -server 127.0.0.1:2181 02 [...] 03 Welcome to ZooKeeper! 04 JLine support is enabled 05 [zk: localhost:2181(CONNECTING) 0] 06 [zk: localhost:2181(CONNECTED) 0]
Knotenkunde
Einmal verbunden sitzt der Admin vor einem Prompt wie am Ende von Listing 1, wobei »ls /« zeigt, ob schon ein Node existiert. Ist das nicht der Fall, kann er nun Z-Nodes anlegen:
$ create /test HelloWorld! Created /test
Der Inhalt, also »HelloWorld!« , lässt sich über einen weiteren Befehl herausfinden, den Listing 2 zeigt und der die Ausgabe weiterer Metadaten bewirkt.
Listing 2
get /test
01 [zk: localhost:2181(CONNECTED) 11] get /test 02 HelloWorld! 03 cZxid = 0xa1f54 04 ctime = Sun Jul 20 15:22:57 CEST 2014 05 mZxid = 0xa1f54 06 mtime = Sun Jul 20 15:22:57 CEST 2014 07 pZxid = 0xa1f54 08 cversion = 0 09 dataVersion = 0 10 aclVersion = 0 11 ephemeralOwner = 0x0 12 dataLength = 11 13 numChildren = 0
Im Unterschied zu einem gewöhnlichen verteilten Dateisystem unterstützt Zookeeper das Konzept von flüchtigen (ephemeral) und sequenziellen (Sequence) Z-Nodes. Ein flüchtiger Z-Node verschwindet, wenn die Sitzung seines Besitzers endet.
Diesen Knoten setzen Admins üblicherweise ein, damit er Hosts im verteilten Dateisystem entdeckt. Jeder Server kündigt dann seine IP-Adresse über einen flüchtigen Knoten an. Verliert der Server den Kontakt mit Zookeeper oder endet die Session, verschwindet die Information mitsamt dem Knoten.
An die Namen neu erzeugter sequenzieller Z-Nodes hängt Zookeeper automatisch einen Suffix aus fortlaufenden Nummern, der permanent hochzählt. Eine Leader Election (siehe Kasten “Leader Election”) lässt sich mit Zookeeper einfach umsetzen, indem die Software dafür sorgt, dass neue Server ihre Informationen in Z-Nodes veröffentlichen, die zugleich sequenzielle und flüchtige Knoten sind.
Leader Election
Im Rahmen einer Leader Election wählen verteilte Systeme mit Hilfe eines Ringalgorithmus einen Prozess aus, der besondere Aufgaben übernimmt und zum Beispiel andere Prozesse koordiniert. Gehen der Leader oder ein beliebiger anderer Server offline, endet die Sitzung und der flüchtige Knoten wird entfernt.
Dank der Sequenznummer lernen andere Server den neuen Leader rasch kennen, denn das Muster, nach dem Zookeeper flüchtige und sequenzielle Z-Nodes erstellt, organisiert zugleich alle Nodes in einer für alle sichtbaren Warteschlange. Das Prinzip lässt sich auch auf verteilte Locks jeder Art mit einer beliebigen Anzahl von Knoten darin anwenden. Diese Locks sorgen dafür, dass nicht mehrere Prozesse zugleich auf eine Ressource zugreifen, die dafür nicht ausgelegt ist.
Listing 3
Flüchtige und sequenzielle Knoten
01 [zk: localhost:2181(CONNECTED) 14] get /myEphemeralAndSequentialNode0000000001 02 ThisIsASequentialAndEphemaralNode 03 cZxid = 0xa1f55 04 [...]
Um solche Doppelknoten anzulegen, verwendet der Admin die Flags »-e« (ephemeral) und »-s« (Sequence):
$ create -e -s /myEphemeralAndSequentialNode ThisIsASequentialAndEphemaralNode Created /myEphemeralAndSequentialNode0000000001
Die Inhalte dieser Knoten lassen sich wieder über »get« auslesen, wie Listing3 demonstriert. Auch hier fallen wieder zusätzliche Informationen an.
Nachrichtendienst
Ein weiteres Schlüsselfeature von Zookeeper besteht darin, dass die Software Watcher für Z-Nodes anbietet, mit deren Hilfe ein Admin ein Benachrichtigungssystem einrichten kann. Dabei registriert er für alle Clients, die eine bestimmte Komponente im Auge behalten möchten, einen Watcher. Die registrierten Clients erhalten so relevante Nachrichten der überwachten Komponente, sobald sich die Z-Node-Inhalte ändern.
Um einen vorhandenen Z-Node in einen Watcher zu verwandeln, greift der Systemverwalter zum »stat« -Befehl und ergänzt ihn um den Parameter »watch« :
$ stat /test watch cZxid = 0xa1f60[...]
Verbindet sich der Admin jetzt von einem anderen Terminal aus mit Zookeeper, darf er den Z-Node verändern:
$ set /test ByeCruelWorld! cZxid = 0xa1f60[...]
Das führt nun dazu, dass der Watcher, den der Admin in der ersten Session eingerichtet hat, eine Nachricht über die Kommandozeile verschickt:
WATCHER:: WatchedEvent state:SyncConnected type:NodeDataChanged path:/test
Ein Nutzer des Systems erfährt so, dass sich der Inhalt des Z-Node verändert hat, und kann den neuen Inhalt ansehen, wenn er das wünscht.
Einen Wermutstropfen gibt es allerdings: Z-Nodes verschießen ihr Pulver beim ersten Mal. Um weitere Updates zu erhalten, muss der Admin den Z-Node erneut registrieren, dazwischen kann ein Update verloren gehen. Das lässt sich allerdings entdecken, wenn der Admin die Versionsnummern der Z-Nodes anschaut. Zählt also jede Versionsnummer, empfiehlt sich der Einsatz sequenzieller Nodes.
Zoo-Ordnung
Zookeeper garantiert für eine Ordnung, indem es jedes Update zum Teil einer festen Reihenfolge macht. Zwar mögen sich nicht alle Clients im selben Zeitrahmen befinden, doch sehen sie sämtliche Updates in derselben Reihenfolge. Das ermöglicht es, Schreibzugriffe von einer bestimmten Z-Node-Version abhängig zu machen: Versuchen zwei Clients denselben Z-Node in derselben Version zu aktualisieren, wird nur eines der Updates Erfolg haben, weil der Z-Node nach dem ersten Update eine andere Versionsnummer erhält. Das macht es einfach, verteilte Counter einzurichten und kleinteilige Aktualisierungen für Node-Daten vorzunehmen.
Zookeeper bietet auch die Möglichkeit, mehrere Update-Operationen in einem Schwung vorzunehmen. Die wendet das System atomar an, das heißt, es führt entweder alle Operationen aus oder keine davon.
Will der Tierpfleger Zookeeper mit Daten füttern, die konsistent über mehrere Z-Nodes funktionieren sollen, bietet sich der Einsatz eines Multi-Update-API an. Zu bedenken ist hier jedoch, dass der Umgang mit dem API noch nicht so ausgereift funktioniert wie Acid-Transaktionen in traditionellen SQL-Datenbanken. Ein Admin kann nicht einfach »BEGIN TRANSACTION« eingeben, weil er noch die erwartbaren Versionsnummern der involvierten Z-Nodes festlegen muss.
Bremsklötze
Auch wenn es einem Systemverwalter verlockend erscheint, ein System für alles zu verwenden, könnte er in einige Hindernisse laufen, sollte er versuchen, existierende Dateisysteme durch Zookeeper zu ersetzen. Das erste stellt die »jute.maxbuffer« -Einstellung in den Weg, die einzelne Z-Nodes standardmäßig auf ein Größenlimit von 1 MByte fixiert. Die Entwickler empfehlen, diesen Wert nicht zu ändern, weil Zookeeper nicht als großer Datensilo vorgesehen ist.
Eine Ausnahme von der Regel hat die Firma des Autors entdeckt. Verliert ein Client, der viele Watcher benutzt, die Verbindung zu Zookeeper, versucht die Client-Bibliothek, die im konkreten Szenario Curator [4] heißt, alle Watcher wieder zu rekonstruieren, sobald sich der Client erfolgreich verbindet.
Da das Gleiche auch für alle Nachrichten gilt, die Zookeeper sendet und empfängt, musste der Admin das Limit erhöhen, damit Curator die Clients wieder erfolgreich mit Zookeeper verbandelt. Jetzt stellt sich noch die Frage, was Curator überhaupt ist. Die Software hilft dabei, eine solide Implementierung von Zookeeper zu erzeugen, die alle möglichen Ausnahmen und die Sonderfälle im Netzwerkbereich korrekt handhabt [5].
Mit Einschränkungen im Datendurchsatz muss hingegen rechnen, wer Zookeeper als Nachrichtendienst verwendet: Weil die Software vor allem auf Korrektheit und Konsistenz setzt, stehen Geschwindigkeit beziehungsweise Verfügbarkeit erst an zweiter Stelle (siehe Kästen “Zab versus Paxos” und “Das Cap-Theorem”).
Das Cap-Theorem
Das Cap-Theorem berücksichtigt die drei Eigenschaften Consistency, Availability und Partition Tolerance (Konsistenz, Verfügbarkeit und Aufteilungstoleranz) und besagt, dass ein verteiltes System nur zwei dieser drei Eigenschaften zugleich unterstützen kann. So gesehen ist Zookeeper ein CP-System, weil es Konsistenz wahrt und über Aufteilungstoleranz verfügt, also auch noch dann funktioniert, wenn Teile des Netzwerks ausfallen. Dafür opfert Zookeeper die Verfügbarkeit: Kann es kein korrektes Verhalten garantieren, antwortet es nicht auf Anfragen.
Zab versus Paxos
Auch wenn Zookeeper ähnliche Funktionen wie der Paxos-Algorithmus anbietet, findet die Konsensbildung im Netzwerk nicht über Paxos statt. Der Algorithmus, den Zookeeper verwendet, heißt Zab (für Zookeeper Atomic Broadcast). Wie Paxos setzt er auf ein Quorum, um Dauerhaftigkeit der gespeicherten Daten zu erreichen.
Der Unterschied besteht darin, dass Zab nur einen Proposer verwendet, während Paxos verschiedene Proposer parallel betreibt (Abbildung 2), was aber die Integrität der Reihenfolge verletzen kann, auf die Zab Wert legt. Nicht zuletzt deshalb folgt jeder Wahl eines neuen Leaders eine Synchronisierungsphase, bevor Zab neue Änderungen akzeptiert. Weitere Details verrät ein Paper der Uni Stanford unter [6].

Abbildung 2: Ein Paper der Uni Stanford beschäftigt sich mit den Vor- und Nachteilen von Zab und Paxos.
In freier Wildbahn
Found [7] – die Firma bietet Elasticsearch-Instanzen (ES, [8]) an und ist der Arbeitgeber des Autors – setzt Zookeeper intensiv ein, damit es Dienste entdeckt, Ressourcen alloziert, eine Leader Election vornimmt und Nachrichten mit hoher Priorität verschickt. Der komplette Dienst besteht aus vielen Systemen, die lesend und schreibend auf Zookeeper zugreifen.
Bei Found kommt Zookeeper konkret in Kombination mit der Kundenkonsole zum Einsatz: Die Webanwendung öffnet den Kunden ein Fenster in die Welt von Zookeeper, indem sie es ermöglicht, die von Found gehosteten ES-Cluster zu verwalten. Erzeugt ein Kunde einen neuen Cluster oder ändert er etwas an einem bestehenden, landet dieser Schritt als geplanter Änderungsauftrag in Zookeeper.
Letzte Instanz
Ein Konstruktor hält in Zookeeper Ausschau nach neuen Aufträgen. Er setzt diese um, indem er kalkuliert, wie viele ES-Instanzen er benötigt und ob er die vorhandenen Instanzen wiederverwenden kann. Basierend darauf aktualisiert er die Instanzenliste für jeden ES-Server und wartet darauf, dass die neuen Instanzen starten.
Auf jedem Server, auf dem solche Elasticsearch-Instanzen laufen, beobachtet eine kleine, von Zookeeper verwaltete Anwendung die Instanzenliste. Sie startet und stoppt bedarfsabhängig LXC-Container mit ES-Instanzen. Beim Start einer Suchinstanz liefert ein kleines ES-Plugin die IP-Adresse und den Port an Zookeeper und entdeckt zudem weitere ES-Instanzen, um einen Cluster zu formen.
Der Konstruktor wartet bereits auf die von Zookeeper gelieferten Adresseninformationen, um sich mit den Instanzen zu verbinden und zu überprüfen, ob der Cluster steht. Kommt innerhalb einer bestimmten Frist keine Rückmeldung, nimmt der Konstruktor die Änderungen zurück. Ein typisches Problem, das den Start neuer Knoten verhindert, sind falsch konfigurierte oder zu speicherhungrig konzipierte ES-Plugins.
HA und Backup
Um den Kunden auf Wunsch auch Hochverfügbarkeit und Ausfallsicherheit zu gewährleisten, stellt das Unternehmen einen Proxy vor seine Such-Cluster. Der leitet den Traffic an die passenden Server weiter, egal ob Auftragsänderungen anstehen oder nicht. Zugleich liest der Proxy die Informationen mit, welche die ES-Instanzen an Zookeeper schicken. Auf Basis dieses Wissens entscheidet er, ob er Traffic an andere Instanzen weiterleiten kann oder ob er Anfragen komplett blockieren muss, damit sich der Gesundheitszustand eines angeschlagenen Clusters nicht verschlechtert.
Im Backup-Bereich kümmert sich Zookeeper um die Leader Election. Für das Sichern selbst verwenden die Admins das Backup- und Restore-API von Elasticsearch, das keine Instanzen, sondern nur Indizes und Cluster-Settings speichert. Daher konserviert Found auch lediglich die Inhalte von Clustern, nicht aber die von Servern und Instanzen.
Weil das API keine periodischen Schnappschüsse unterstützt, hat die Firma einen eigenen Scheduler implementiert. Um diesen so zuverlässig zu machen wie den ES-Cluster, für den er verantwortlich ist, läuft ein Scheduler auf jedem Server mit ES-Instanzen. Das entfernt einen Single Point of Failure für die HA-Kunden von Found. Auf unabhängigen Servern sollen die Scheduler nicht laufen, weil das zusätzliche Fehlerquellen einschleppt. Da die Backups pro Cluster stattfinden und nicht pro Instanz, besteht ein Bedarf, die Backup-Scheduler entsprechend zu koordinieren. Indem diese über Zookeeper für jeden Cluster einen Leader auswählen, löst nur ein Scheduler allein die Schnappschüsse aus.
Da viele Systeme auf Zookeeper vertrauen, benötigt Found zudem eine möglichst verzögerungsfreie Verbindung. Daher kommt pro Region ein Zookeeper-Cluster zum Einsatz. Befinden sich Client und Server in derselben Region, steigert das die Zuverlässigkeit des Netzwerks. Dennoch muss der Admin Störungen berücksichtigen, die besonders bei Wartungsarbeiten am Cluster auftreten.
Die Erfahrungen von Found zeigen auch, dass es extrem wichtig ist, sich im Vorfeld Gedanken darüber zu machen, welche Informationen ein Client im lokalen Cache vorhalten sollte und welche Aktionen er ausführen kann, falls die Verbindung zu Zookeeper abreißt.
Die Grenzen von Zookeeper
Auch wenn Found Zookeeper sehr intensiv einsetzt und davon abhängt, achtet die Firma darauf, gewisse Grenzen nicht zu überschreiten. Nur weil A und B Zookeeper einsetzten, senden die Admins Nachrichten nicht ausschließlich über Zookeeper. Vielmehr müssen der Wert und die Dringlichkeit der Information hoch genug sein, um damit die Kosten einer Sendung zu rechtfertigen, die sich aus der Größe und der Updatefrequenz zusammensetzen.
- Anwendungs-Logs: So ärgerlich es beim Debuggen auch sein mag, wenn die Logs fehlen, sind sie dennoch gewöhnlich die erste Sache, die ein Admin opfert, wenn das System an sein Limit gelangt. Admins sollten hier eine Lösung mit weniger Konsistenzansprüchen wählen.
- Binärdateien: Sie sind schlicht zu groß. Sie würden es erfordern, Zookeeper bis zu einem Punkt zu optimieren, an dem womöglich Ausnahmeprobleme auftreten, die nie zuvor jemand getestet hat. Binärdateien legt Found deshalb in Amazon S3 ab und verwaltet nur die URLs mit Zookeeper.
- Metriken: Am Anfang mag das gehen, auf längere Sicht ergeben sich Skalierungsprobleme. Metriken über Zookeeper zu schicken wäre schlicht zu teuer, weil der Admin einen Puffer für die angestrebte und verfügbare Kapazität vorhalten müsste. Das gilt für Metriken generell – mit der Ausnahme von zwei kritischen Metriken für die Anwendungslogik: die aktuelle Festplattenauslastung und die Speichernutzung jedes Knotens. Letztere verwenden die Proxys, um das Indizieren einzustellen, wenn ein Kunde seine Plattenkapazität sprengt. Erstere wird künftig wichtig, wenn es darum geht, Kundenverträge zu aktualisieren.
Erste Hilfe
Zookeeper ist inzwischen ein recht großes Open-Source-Projekt geworden mit zahlreichen Entwicklern, die ziemlich fortgeschrittene Features implementieren mit starkem Fokus auf Korrektheit. Natürlich bedeutet es etwas Aufwand, sich damit vertraut zu machen, aber das sollte Admins nicht abhalten. Die Anstrengung lohnt sich vor allem für Verwalter von verteilten Systemen. Drei Handbücher helfen beim Einstieg.
Es gibt den “Getting Started Guide” [9], der zeigt, wie ein Systemverwalter einen einzelnen Zookeeper-Server aufsetzt, sich per Shell mit ihm verbindet und einige grundlegende Operationen umsetzt. Der ausführlichere “The Programmers Guide” [10] versammelt eine Reihe von wichtigen Hinweisen, die Admins vor dem Aufsetzen von Zookeeper beachten sollten. Der “Administrators Guide” [11] beschreibt die Optionen, die relevant für einen Produktionscluster sind.
Einige Admins bezweifeln zwar, dass es etwas bringt, mehr als ein System für Deployments und Upgrades zu verwenden. Wer es dennoch tut, sollte darauf achten, jedes dieser Systeme so klein und unabhängig wie möglich zu gestalten. Für Found ist Zookeeper ein wichtiger Schritt zu diesem Designziel.
Infos
- Zookeeper: http://zookeeper.apache.org
- Zookeeper Standalone: http://zookeeper.apache.org/doc/r3.4.6/zookeeperStarted.html
- Zookeeper-Server mit Replikation: http://zookeeper.apache.org/doc/r3.4.6/zookeeperStarted.html#sc_RunningReplicatedZooKeeper
- Zookeeper-Helfer Curator: https://github.com/netflix/curator
- Netflix kündigt Curator an: http://techblog.netflix.com/2011/11/intro-ducing-curator-netflix-zookeeper.html
- Zab versus Paxos: http://web.stanford.edu/class/cs347/reading/zab.pdf
- Found: https://www.found.no
- Elasticsearch: http://www.elasticsearch.org
- Getting Started: http://zookeeper.apache.org/doc/r3.4.6/zookeeperStarted.html
- Programmers Guide: http://zookeeper.apache.org/doc/r3.4.6/zookeeperProgrammers.html
- Administrators Guide: https://zookeeper.apache.org/doc/r3.4.6/zookeeperAdmin.html





