
© John Roman, 123RF.com
Der Begriff Cloud umfasst auch das Prinzip, Vorgänge so weit wie möglich zu systematisieren und zu automatisieren. Doch geht es darum, die Cloud dazu zu nutzen, sich selbst zu automatisieren, dann trennt sich die Spreu vom Weizen. Open Stack will das Problem angehen und bringt Triple O.
Der Open-Stack-Hype geht weiter. Manche Szenekenner fürchten bereits um die Vielfalt freier Software, weil sich immer mehr Unternehmen öffentlich zu Open Stack bekennen und andere Cloud-Lösungen ins Hintertreffen geraten.
Kinderschuhe
Zusatzlösungen von Drittherstellern sprießen allerorten aus dem Boden. Verschiedenste Hersteller versprechen, alle möglichen administrativen Aufgaben im Open-Source-Cloud-Management aus den Händen des Administrators zu nehmen und der Automatisierung zu übergeben. Gleichzeitig geht ein Aspekt in der Cloud-Debatte unter: Clouds machen den Kunden zwar das flexible und automatisierte Benutzen von IT-Dienstleistungen möglich, schaffen es aber immer noch nicht oder nur unzureichend, den Betreibern von IT-Plattformen das Einrichten der Cloud selbst zu erleichtern.
Das Cloud-Deployment selbst steckt – abseits teuerer proprietärer Produkte – noch in den Kinderschuhen. Und weil die ersten Open-Stack-Versionen dank undurchsichtiger Abläufe, einer lückenhaften Installation und einer unzureichenden Dokumentation bisweilen schwierig in Betrieb zu nehmen waren, misstrauten viele Admins der Lösung. An dem Image ändert wohl auch nichts, dass Suse (“20 Minuten bis zur Open-Stack-Cloud”) oder Red Hat Setuptools anpreisen, mit denen sich Open Stack schneller installieren lässt als so manches Betriebssystem. Die Insellösungen der großen Distributoren können nicht darüber hinwegtäuschen, dass in der Deploymentkette von Open Stack einiges im Argen lag.
Ist die Cloud aber erstmal installiert, ist der Rest kein Thema mehr: Heat, das in Open Stack Havana Einzug in die Cloud-Umgebung hielt, ist eine vollständige Orchestrierungslösung, die eine VM den gesamten Lebenszyklus lang komfortabel verwaltet: Vom vollautomatisierten Starten über Skalieren in die Breite bis zum Shutdown gibt es nichts, um das sich Heat nicht kümmern könnte.
Heat, Packstack, Kickstack, Razor, Foreman, Crowbar
Aber wie kommen Admins an den Punkt, an dem Heat schlussendlich funktioniert, zusammen mit sämtlichen anderen Open-Stack-Komponenten? Und wie tragen sie dem Umstand Rechnung, dass auch die Cloud-Umgebung selbst dynamisch in die Breite skalieren soll? Dass es also früher oder später notwendig sein dürfte, die vorhandene Open-Stack-Installation um mehrere Gastgeber zu erweitern, komfortabel und automatisiert?
Hier greifen Admins bisher zu sehr unterschiedlichen Lösungen, beispielsweise solche, die auf den Puppet-Modulen aufbauen. Red Hats Packstack fällt in diese Kategorie [1], Kickstack [2] ebenso. Aber damit Puppet laufen und auch Open Stack installieren kann, bedarf es eines installierten Betriebssystems. Das könnte gegebenenfalls Razor [3] leisten, und per Foreman [4] wäre eine solche Installation auch zu warten. Doch sieht sich der Admin dann schon wieder einem ganzen Haufen von Zusatztools gegenüber, die mit Open Stack erstmal nichts zu tun haben. Suse geht seinen eigenen Weg mit dem von Dell entwickelten Crowbar [5] samt Chef, doch ist diese Kombination noch nicht fertig. HP tauchte derweil mit einer eigenen Lösung auf: Triple O [6].
Funktionalität recyclen
Die Grundidee hinter Triple O ist denkbar einfach: Weil es in Open Stack ja sämtliche Werkzeuge schon gibt, die für automatische Installation sowie Orchestrierung notwendig sind, sollte es möglich sein, diese auch auf nacktem Metall zu nutzen. Denn ob ein Rechner, der automatisiert installiert werden soll, eine virtuelle Maschine oder echtes Blech ist, macht in den meisten Fällen keinen Unterschied.
Die HP-Entwickler fragten sich folglich, ob man nicht ein “Meta-Open-Stack” bauen könnte, das Hardware verwaltet und komplette Open-Stack-Umgebungen anbietet. Genau darauf zielt Triple O ab: Die Abkürzung steht für “Open Stack On Open Stack”.
Praxischeck
In der Realität ist allerdings nicht alles so einfach, wie es auf den ersten Blick den Anschein hat. Denn Open Stack ist bis dato maßgeblich unter der Vorgabe entwickelt worden, sich hauptsächlich um virtuelle Maschinen zu kümmern, nicht aber um echte Hardware. Während sich bei VMs beispielsweise die Ressourcen voraussagen, sogar notfalls (um)definieren lassen, ist physische Hardware die meiste Zeit eine eher fixe Konfiguration, deren Vor- und Nachteile ein Deployment-Werkzeug im Hinterkopf haben muss. Triple O muss sich folglich mit wechselnden Konventionen im Open Stack-Universum beschäftigen und diese gegebenenfalls anpassen.
Von zentraler Bedeutung ist in diesem Kontext der »baremetal« -Treiber, der in Open Stack Nova für Hardware die gleichen Funktionen bietet wie es üblicherweise die Virtualisierungstreiber tun. Nova ist in dieser Hinsicht sehr modular aufgebaut: Über einen einzelnen Eintrag in der Konfiguration von »nova.conf« lässt sich festlegen, welchen Virtualisierungstreiber Nova einsetzen soll, um virtuelle Maschinen zu starten (Listing 1).
Listing 1
nova.conf
01 [default] 02 compute_driver=nova.virt.baremetal.driver.BareMetalDriver 03 firewall_driver = nova.virt.firewall.NoopFirewallDriver 04 scheduler_host_manager=nova.scheduler.baremetal_host_manager.BaremetalHostManager 05 ram_allocation_ratio=1.0 06 reserved_host_memory_mb=0
Im Triple-O-Kontext verwaltet Nova aber keine virtuellen Maschinen, sondern echte Systeme – der Baremetal-Treiber tritt quasi als Vermittler auf. Auf der einen Seite nimmt er von Nova entsprechende Befehle entgegen, auf der anderen Seite wickelt er die gewünschten Arbeitsschritte auf den Servern ab. Am Ende des Vorgangs ist aus dem zuvor jungfräulichen Server ein Hypervisor-Knoten geworden, der sich sich wiederum durch Nova und den Baremetal-Treiber verwalten lässt.
Ironic
Derzeit arbeiten die Open-Stack-Entwickler übrigens an einem Refactoring des Baremetal-Treibers: Er wird zum eigenen Projekt namens Ironic und soll mehr Aufmerksamkeit bekommen als bisher. Wenn der Baremetal-Server in Nova dafür sorgt, dass Hardware im Sinne des Admins mit einem Betriebssystem ausgestattet wird, dann bedarf es dafür einer zentralen Komponente, die weiß, was für ein Server aus welcher Hardware denn entstehen soll. In Triple O kümmert sich Tuskar um das physische Inventar. De facto erlaubt Tuskar es einem Administrator, Server mit ihrer Hardware-Konfiguration abzuspeichern, ihnen anschließend Open-Stack-Dienste zuzuweisen, die Triple-O-Funktionen installieren und passend konfigurieren.
Tuskar
Der Inventardienst kommt mit einem eigenen Plugin für das Dashboard, also das Open-Stack-Webinterface, und passt sich so nahtlos in das gewohnte Open-Stack-Nutzungskonzept ein. In Tuskar lassen sich überdies Rechnerklassen anlegen, sogar die Einteilung in Racks unterstützt es. Das ist besonders dann praktisch, wenn die Entscheidung über die verwendete Hardware auch auf Grundlage des Standortes eines Systems fallen soll, beispielsweise, um Disaster-Recovery in angemessener Zeit zu ermöglichen.
Unter der Haube funktioniert Tuskar wie praktisch alle anderen Open Stack-Dienste auch: Einem API, das quasi als Schnittstelle zur Außenwelt dient, stehen verschiedene Processing-Engines zur Seite, darunter auch Open Stack Heat. Seine Benutzerauthentifizierung wickelt Tuskar selbstverständlich über die Open-Stack-Komponente Keystone ab.
Dieses Tatsache wirft freilich das klassische Henne-Ei-Problem auf: Damit Tuskar Open Stack mit Hilfe des Baremetal-Treibers für Nova installieren kann, benötigt es Keystone, doch ist dieses ja selbst eine Open-Stack-Komponente. Ganz ohne händische Installation kann es insofern auch bei Triple O nicht gehen, obgleich die Entwickler im Augenblick einen gelinde gesagt sehr innovativen Weg wählen, um das Problem zu lösen: Sie empfehlen, eine lokale Cloud mittels Devstack [7] zu bootstrappen, um aus dieser heraus dann die für Triple O benötigten Komponenten zu installieren.
Unschön ist das vor allem deshalb, weil die Devstack-Entwickler ausdrücklich vom Einsatz ihrer Software in produktiven Umgebungen abraten. Devstack ist vorrangig gedacht für Entwickler, die an Open Stack arbeiten und regelmäßig frische Umgebungen für Tests brauchen, also Instanzen, denen der dauerhafte Charakter der Unternehmens-IT nicht zukommt.
Wer sich über die Devstack-Hürde traut, kann Triple O immerhin ausgiebig testen. Die Devstack-Cloud benötigt Triple O ja nur ganz kurz – der Admin sollte sie laut Entwickler-Vorstellung nur dazu nutzen, eine echte Open-Stack-Cloud aufs Blech zu bringen. Die bildet dann die Grundlage für alle weitere Arbeiten. Es schadet folglich sicher nicht, diese Initial-Cloud in eine virtuelle Maschine zu verbannen.
Hitziges Helferlein
Grundsätzlich benötigt Triple O sämtliche Dienste, die Open Stack im Moment bereit hält; von besonderer Bedeutung ist das Orchestration-Tool Heat. Bei ihnenbedient sich Triple O, um spezifischen Rechnern eine Rolle zuzuweisen. Erkennt Triple O auf Zuruf des Admins einen in Tuskar bereits angelegten Host, stößt es eine große Welle von Prozessen an, die auf diesem Host sowohl die Installation des Betriebssystems vornimmt als auch die Dienste installiert, die für Open Stack notwendig sind.
Hierzu bedient sich Triple O wiederum einer Vielzahl Zusatzprogramme. Da sind einerseits »os-collect-config« , »os-apply-config« sowie »os-refresh-config« : Am Namen unschwer zu erkennen handelt es sich hier um Tools, die die Konfiguration einzelner Hosts einerseits aus den in Nova vorab hinterlegten Metadaten auslesen, auf den Zielsystemen anwenden und auch Sorge dafür tragen, dass diese aktuell bleiben.
Hinzu kommt der »disk-image-builder« : Dieser fertigt auf Grundlage bestehender Systeme Golden-Master-Images an, die Triple O nutzen kann, um PXE-basiert auf neuen Hosts automatisch ein Betriebssystem abzulegen (Abbildung 1).
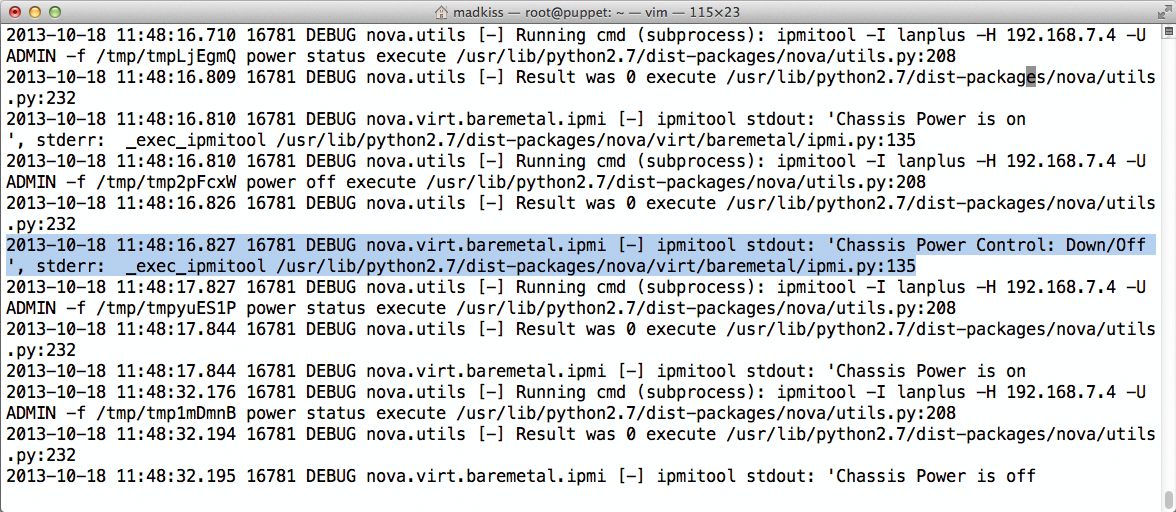
Abbildung 1: Triple O rückt Rechnern sogar mit IPMI zu Leibe, um sie zum Reboot zu zwingen und PXE-Images aufzuspielen.
Images bauen mit dem Builder und Glance
Der gesamte Vorgang funktioniert mit virtuellen Systemen nicht anders, stets kommen die benötigten Images aus Glance. Im Triple-O-Kontext unterscheidet sich lediglich die Art und Weise, wie diese erstellt werden, weil beim Anlegen von Images für echtes Blech andere Faktoren zutreffen als bei virtuellen Maschinen. Echte Server verlangen beispielsweise meist spezifische Hardwaretreiber (Abbildung 2).
Abbildung 2: Triple O erweitert auch den nova-Befehl. baremetal-node-list zeigt alle ausgerollten Hardware-Nodes.
Triple O pflegt eine eigene Sammlung von Heat-Templates, die auf der Grundlage der zuvor beschriebenen Komponenten die Installation neuer Hosts automatisieren. Der Lifecycle-Pfad ist damit klar: Ein Admin hängt einen neuen Host ins Rack, hinterlegt für diesen die vorgesehene Rolle in Tuskar und unter Umständen spezifische Konfigurationsparameter, schaltet das System ein und um den Rest kümmert sich Heat, das im Hintergrund ein Master-Image aus Glance über PXE installiert.
Am Ende steht ein fertig installierter Open-Stack-Knoten, der selbst Teil einer Open-Stack-Cloud ist (der “Bare-Metal-Cloud”), jedoch ansonsten ein ganz normales Mitglied einer Open-Stack-Installation darstellt – mit allen Features und Möglichkeiten, die der Cloud-Manager ansonsten bietet.
Pfiffiger Ansatz, aber noch ein weiter Weg
Triple O unterscheidet sich von den anderen Deploymentsystemen für Open Stack maßgeblich dadurch, dass es selbst die Open-Stack-Funktionen nutzt, um sich auf die Hardware zu bringen. Andere Lösungen erfinden das Rad neu oder bauen um Open Stack mühsam eine Integration für eines der bestehenden Deploymentsysteme wie Puppet oder Chef. Verglichen damit wirkt der Triple-O-Ansatz pfiffig, denn er recyclet vorhandene Funktionen und adaptiert diese nur dort, wo es notwendig ist.
Noch hat Triple O allerdings einen weiten Weg vor sich. Der Rewrite des Baremetal-Treibers für Nova, der am Ende Ironic heißen und ein eigenes Projekt sein soll, ist in vollem Gange, die Entwickler planen, diesen Prozess bis zur “Icehouse”-Release im April 2014 ein gutes Stück voran zu bringen. Zeit sollten sie aber auch investieren, Triple O selbst in ein schöneres Kleid als Devstack zu packen. Denn allein diese Tatsache verleiht dem Projekt derzeit einen gewissen Bastlercharme und wirkt auf Enterprise-Kunden abschreckend.
Langfristig ist mit Triple O aber zu rechnen: HP investiert selbst viel Zeit und Entwicklerkapazität in das Projekt, und auch andere Entwickler begeistern sich offenbar für die Lösung. Wer einen Blick auf aktuelle Triple-O-Vorgänge werfen will, kann das übrigens durch den Triple-O-Incubator in Github tun (Abbildung 3, [8]). Dort finden sich stets die aktuellen Projekte, an denen die Triple O-Developer gerade arbeiten.
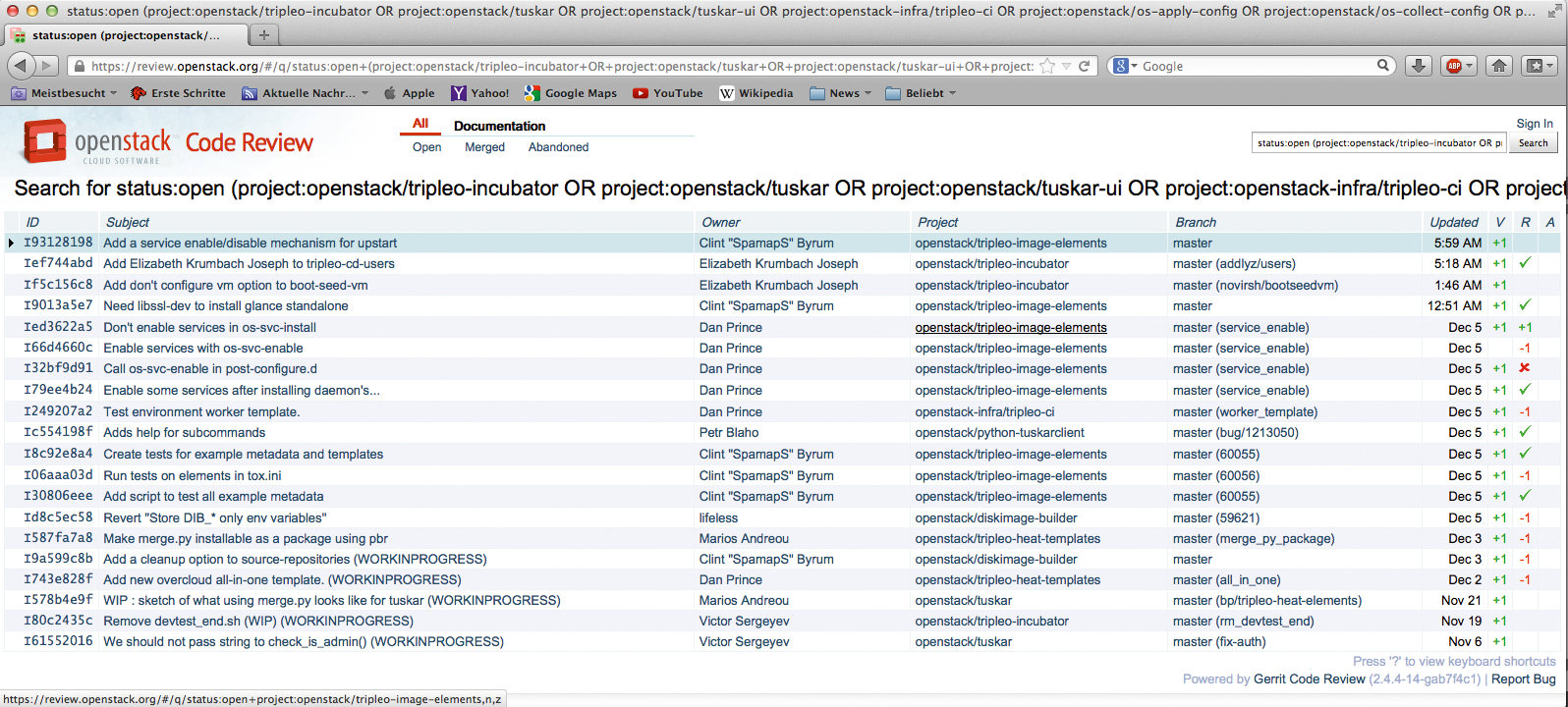
Abbildung 3: Viel zu tun – und viele Entwickler, die mit großem Aufwand daran arbeiten: Triple O ist derzeit eines der aktivsten Open-Stack-Projekte, und im System für Code-Review (“Gerrit”) finden sich etliche Einträge für Triple O. Das liegt auch am Engagement von HP.
Infos
- Packstack: https://wiki.openstack.org/wiki/Packstack
- Kickstack: https://github.com/hastexo/kickstack/
- Razor: http://github.com/puppetlabs/Razor
- Foreman: http://theforeman.org
- Crowbar: https://github.com/crowbar/crowbar
- Triple O: https://wiki.openstack.org/wiki/TripleO
- Devstack: http://www.devstack.org
- Triple-O-Incubator auf Github: https://github.com/openstack/tripleo-incubator
Der Autor

Martin Gerhard Loschwitz arbeitet als Principal Consultant bei Hastexo.
Er beschäftigt sich dort intensiv mit Open-Source-Hochverfügbarkeitslösungen und pflegt in seiner Freizeit den Linux-Cluster-Stack für Debian GNU/Linux.





