
© Marcel Schauer, 123RF.com
Viele Admins lassen PostgreSQL-Installationen im Auslieferungszustand laufen. Das ist oft ein Fehler, denn die Datenbank bringt viele Stellschrauben mit, um dem Server Beine zu machen. Wer die kennt, spart sich den Griff zum Geldbeutel für neue Hardware und erfreut seine Clients, User und Controller.
Weit unter seinen Möglichkeiten bleibt, wer einfach die Vorgaben der Distributoren übernimmt. Die Annahme bewahrheitet sich nicht immer, doch gerade Datenbanken bieten dem Admin zahllose Stellschrauben.
Je nach Anwendungszweck, Datenart und auch Art der Datenbank hat der Admin hier viele Optionen. Welche, das zeigt exemplarisch der folgende Artikel.Anhand der Version 9.2 von PostgreSQL nimmt er sich Stellschrauben für effizientes Tuning vor und legt den Fokus auf Maßnahmen, mit denen ein Administrator die Leistungsfähigkeit seiner Datenbankserver schnell und einfach erheblich steigern kann. Außerdem nennt er die umfangreichen, eingebauten Hilfsmittel, die die beliebte Datenbank mitbringt.
Den Erfolg der Maßnahmen zeigt Abbildung 1. Die Messung fand auf einem Quadcore-Xeon-System mit einem Raid 10 aus SAS-Platten mit 10 000 Umdrehungen statt. Darauf lief in einer virtuellen Maschine (KVM, 12 Gbyte RAM) Gentoo mit Kernel 3.8.4 und der neuesten PostgreSQL-Version 9.2.4 [1].

Abbildung 1: Ohne Write-Ahead-Log gibt’s bis zu sechs Mal schnellere Ergebnisse – aber wer kann sich das leisten? Sinnvoller sind Speicher-, Kernel- und Datenbanktuning, da sie die Leistung einer PostgreSQL-Datenbank mehr als verdoppeln können.
Kritisch: Die Umgebung
Die Leistung eines PostgreSQL-Servers hängt direkt und entscheidend von der Umgebung ab, in der ihn sein Admin betreibt (Hardware, Betriebssystem, die PostgreSQL-Version und wie darüberliegende Anwendungen das RDBMS nutzen). Der Artikel geht in der Reihenfolge vor, in der die einflussnehmenden Komponenten aufeinander aufbauen – von unten nach oben.
Weil relationale Datenbanken gerne umfangreiche Lese- und Schreibprozeduren veranstalten, ist ein schnelles Plattensubsystem essenziell für die Performance. Dabei sind die erzielbaren IO-Operationen pro Sekunde wichtiger als die Werte für das sequenzielle Lesen oder Schreiben. Je nach zu erwartender Größe der Datenbank gibt es mehrere Möglichkeiten: Am performantesten sind derzeit SSD-basierte Systeme. Sie bieten nicht nur sehr hohe Lese- und Schreibraten, sondern glänzen auch durch kurze Zugriffszeiten. Für SSDs wie herkömmliche, mechanische Platten gilt jedoch gleichermaßen das Datenbank-Credo:
- Mehr Platten sind besser.
- Schnellere Platten (10 000 oder 15 000 Umdrehung pro Minute) sind besser.
- Raid 10 oder 50 ist besser als Raid 5.
Bevor der Admin seine Daten nun an den Server übergibt, sollte er die Anwendung, ihr Verhalten und ihre spezielle Arbeitsweise untersuchen. Erst dann kann er über die richtige Verteilung der Daten im Subsystem entscheiden:
- Wie groß wird die Datenbank? (Eine kleine fürs Web oder ein DataWarehouse?)
- Wie schreiblastig arbeitet die Datenbank? (Wie ist das Verhältnis zwischen »SELECT« und »INSERT« oder »UPDATE« ?)
- Muss der Admin die Daten aufwändig analysieren? (Sind komplexe SQL-Queries nötig?)
Idealerweise erhält der Datenbankserver einen eigenen kleinen Storagebereich auf separaten Platten, in dem er die Transaktionslogs der Datenbank speichert. Diesen Transaktionslogs kommt eine zentrale Rolle bei der ACID-Compliance [2] eines RDBMS zu: Die Schreibbestätigung des Subsystems ist Voraussetzung für den gelungenen Abschluss einer Transaktion. Ein schnelles Subsystem (Kasten “Dm-cache”), das ausreichend Platz für das Log – typischerweise zwischen 50 MByte und 4 GByte – bietet, ist deshalb entscheidend für eine performante Datenbank.
Dm-cache
Mit dem Kernel 3.9 hält das neue Device Mapper Target »dm-cache« Einzug. Es erweitert Linux um die Möglichkeit, große Datenspeicher beispielsweise mit Hilfe von SSDs zu beschleunigen, indem es sie als Cache eines anderen Storage-Devices konfiguriert. Was sonst nur teure Lösungen großer Storage-Anbieter boten, ist so erstmals mit Linux-Bordmitteln möglich. Prinzipbedingt verspricht Dm-cache großen Performancegewinn. Wie gut es sich jedoch grundsätzlich und speziell im Datenbankbereich eignet, muss sich in Zukunft noch zeigen.
RAM, CPU, I/O-Scheduler
Genügend Hauptspeicher ist essenziell für eine Datenbank. Gibt es zu wenig, muss sie für manche Operationen auf temporären Festplattenspeicher ausweichen, was das System ausbremst. Viel Hauptspeicher kann als Cache zudem bis zu einem gewissen Grad ein nicht allzu schnelles Storage-Subsystem kompensieren, zumindest lesend. Je mehr gleichzeitige Verbindungen zu der Datenbank bestehen und je mehr komplexe Abfragen an die Datenbank gestellt werden, desto wichtiger wird die CPU-Power. Als Faustformel gilt: Lieber wenige CPU-Kerne mit einer hohen Taktrate als viele Kerne mit niedriger Taktrate, da eine Abfrage immer nur auf einem Core laufen kann.
Die Auswahl des I/O-Schedulers, also die Art, wie der Linux-Kernel Schreiboperationen auf die Festplatte organisiert, spielt ebenfalls eine große Rolle. Wer Schreibzugriffe für ein Datenbanksystem optimieren will, greift am besten zum Deadline-Scheduler. Den gibt der Kernelparameter »elevator=deadline« beim Booten fest für das System vor, zur Laufzeit aktiviert ihn für ein Gerät:
echo deadline > /sys/block/sda/queue/scheduler
Als Dateisysteme kommen derzeit am ehesten XFS oder Ext4 zum Einsatz, Btr-FS eignet sich noch nicht für Datenbanksysteme. Die Parameter »noatime« und »nodiratime« sind sinnvolle Mount-Optionen für Dateisysteme, auf denen PostgreSQL seine Daten und Transaktionslogs ablegt. Verfügt der Server über ein batteriegepuffertes Plattensubsystem, ergeben die Ext4-Optionen »data=writeback« und »nobarrier« zusätzlich Sinn. Sie helfen, das Dateisystem zu beschleunigen, weil es die Plattencaches besser nutzt.
Shared Memory
Genügend Shared Memory ist für PostgreSQL zwingend notwendig. Ohne geeignete Kernelkonfiguration ist die Datenbank nicht in der Lage, Shared-Memory-Segmente in der gewünschten Größe anzufordern. Der Kernelparameter »shmmax« legt die maximale Größe eines solchen Segments fest. Aber die typische Standardgröße von 1 Gbyte reicht nur in den wenigsten Fällen aus. Fordert PostgreSQL ein zu großes Segment an, quittiert es die unzureichende Kernelkonfiguration in seiner Logdatei:
FATAL: could not create shared memory segment: Invalid argument
Die Einstellung »shmall« hingegen legt fest, wie viel Hauptspeicher des Systems als Shared Memory bereit steht, angegeben in Speicherseiten (Pages). Eine Speicherseite hat unter Linux in den allermeisten Fällen eine Größe von 4096 Bytes. Die aktuell gültige Systemeinstellung seines Linux-Servers kann der Admin mit dem Kommando »ipcs -lm« überprüfen (Listing 1)
Listing 1
ipcs -lm
01 ------ Shared Memory Limits -------- 02 max number of segments = 4096 03 max seg size (kbytes) = 1048576 04 max total shared memory (kbytes) = 2097152 05 min seg size (bytes) = 1
Wer der Datenbank das Leben leichter machen will, muss hier Hand anlegen. Hilfe bietet das Log der Datenbank. Ist »shmall« zu klein, schreibt PostgreSQL ins Log:
FATAL: could not create shared memory segment: No space left on device
Im vorliegenden Beispiel lassen sich Segmente mit einer maximalen Größe von 1 GByte anlegen, und insgesamt maximal 2 GByte Shared Memory anfordern. Will der Admin zum Beispiel Segmente von bis zu 5 GByte zulassen, nutzt er das Sysctl-Kommando, um die Werte »kernel.shmmax« und »kernel.shmall« zu ändern (Abbildung 2). Ein Eintrag in »/etc/sysctl.conf« macht sie persistent.
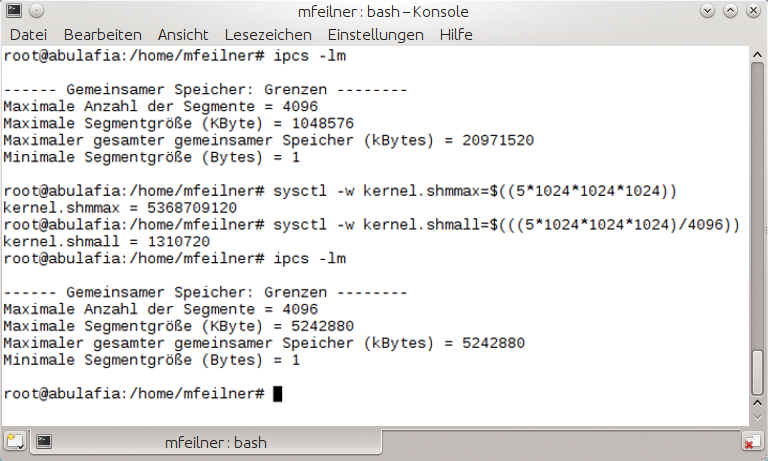
Abbildung 2: Sysctl legt die Menge und Verteilung des für Datenbanken relevanten Shared Memory fest. Die Standardwerte der Distributoren sind nur für die wenigsten Setups optimal.
Was PostgreSQL selbst angeht, so finden sich alle im Folgenden konfigurierten Einstellungen in der Datei »postgresql.conf« . Sie beziehen sich auf einen mit 12 GByte RAM ausgestatteten Server. Für Version 9.2 liegt diese Datei bei Debian unter »/etc/postgresql/9.2/main/« , Gentoo verwendet dafür »/etc/postgresql-9.2/« .
PostgreSQL selbst: <C>shared_buffers<C>
Hat der Administrator das System wie weiter oben beschrieben vorbereitet, konfiguriert dieser Parameter die Größe des Shared-Memory-Segments, welches PostgreSQL benutzen wird, um Daten im Hauptspeicher zu puffern. Es wird dabei versuchen, diesen Speicher direkt beim Start von PostgreSQL zu allozieren. Als guter Startwert gilt dabei, ein Viertel des gesamten Hauptspeichers für dedizierte Datenbankserver zu nutzen, die über mehr als ein GByte an RAM verfügen. Nur selten wird der Wert jedoch 40 Prozent des Hauptspeichers übersteigen:
shared_buffers = 3GB
Weil auch Einstellungen der Datenbank, zum Beispiel »max_connections« , den Bedarf an Shared Memory beeinflussen, benötigt PostgreSQL immer etwas mehr als den in »shared_buffers« angegebenen Wert. Genauere Angaben finden sich in den Kernelressourcen von PostgreSQL unter [3].
<C>effective_cache_size<C>
Anders als der Name nahelegt, hat »effective_cache_size« keinen direkten Einfluss auf den von PostgreSQL belegten Hauptspeicher. Vielmehr dient der Wert dazu, abschätzen zu können, wie viel Hauptspeicher das System insgesamt für Festplattencaching und in der Datenbank direkt nutzt. Diese Information hilft dem Query Planner zu entscheiden, ob es sinnvoller ist, für bestimmte Abfragen einen Index zu benutzen oder nicht. Ist dieser Wert zu gering, kann es sein, dass PostgreSQL einen großen Index nicht verwendet, da es davon ausgehen muss, dass dieser nicht in den Hauptspeicher passt und somit auch keine Vorteile brächte. Normale Werte bewegen sich zwischen 50 und 75 Prozent des Hauptspeichers – bei 12 GByte RAM etwa 7 GByte:
effective_cache_size = 7GB
Im laufenden Betrieb ist es mit einem simplen »free« -Kommando möglich, bessere Werte zu ermitteln (Listing 2). Wichtig ist dabei, dass alle Applikationen, die auch normalerweise auf einem System laufen, zu diesem Zeitpunkt gestartet sind und den für sie normalen Speicherbedarf in Anspruch nehmen. Addiert der Admin dann zum Wert von »shared_buffers« die Werte »free« und »cached« hinzu, so erhält er einen recht guten Wert für die »effective_cache_size« .
Listing 2
free -m
01 total used free shared buffers cached 02 Mem: 11990 10109 1880 0 5143 2306 03 -/+ buffers/cache: 2660 9330 04 Swap: 4095 201 3894
Checkpoints
PostgreSQL führt für seine Transaktionen ein Log, das die Datenbank zum Beispiel bei einem Servercrash vor Datenkorruption und -verlust schützt. Das Log zieht die Datenbank beim Neustart des Servers heran, um in einen konsistenten Zustand zu gelangen. Das TA-Log landet in Dateien, die WAL-Segmente (Write-Ahead-Log) genannt werden. Jedes WAL-Segment ist 16 MByte groß, in der Standardkonfiguration schreibt PostgreSQL maximal drei davon.
Sind alle WAL-Segmente gefüllt, muss das System einen so genannten Checkpoint generieren. Der stellt sicher, dass alle Transaktionen, die in den WAL-Segmenten enthalten sind, auch tatsächlich in die Datenbank gelangen. Danach recycelt es die WAL-Segmente und beschreibt sie bei Bedarf neu.
Dieser Prozess kann recht ressourcenintensiv sein. Ihn muss der Admin sorgfältig und mit Blick auf die Größe des Datenbankservers und die Schreiblast der Datenbank einrichten. Wird viel in die Datenbank geschrieben, dann bewirkt das Hochsetzen von »checkpoint_segments« , dass PostgreSQL mehr WAL-Segmente anlegt, bevor der Server zum nächsten Checkpoint gezwungen ist. Sinnvolle Werte fangen bei 10 an, können aber auch höher sein. Im Benchmark aus Abbildung 1 bringt die richtige Wahl 50 Prozent mehr Transaktionen pro Sekunde (zweiter Balken von links).
Der niedrige Standardwert von »3« hat eher historische Gründe. Höhere Werte benötigen jedoch mehr Plattenplatz für WAL-Dateien und die Datenbank braucht im Falle eines Crashs länger für das Recovery. Von daher sollte der Admin die Werte nicht unnötig hoch setzen. Ein guter Anfangswert ist 16, was einen Speicherbedarf auf der Festplatte von 256 MByte ergibt. Je nach Datenbank sind aber auch Werte von 32 (512 MByte) bis hin zu 256 (4 GByte) nicht unüblich.
checkpoint_segments = 16 checkpoint_completion_target = 0.9
Ist dieser Wert deutlich zu klein und muss PostgreSQL zu oft Checkpoints generieren, kann der Admin auch das wieder der Logdatei entnehmen. Bevor er einen Datenbank-Restore startet – also sehr viele Daten auf einmal in die Datenbank schreiben lässt – empfiehlt es sich, den Wert deutlich zu erhöhen und ihn danach wieder zurück zu stellen.
PostgreSQL bemüht sich darum, die für einen Checkpoint nötigen Schreiboperationen möglichst schon vor dem eigentlichen Checkpoint zu erledigen, damit der schneller vonstatten gehen kann. Der Parameter »checkpoint_completion_target« definiert dabei die zeitliche Distanz bis zum nächsten Checkpoint. Bei einem Standardwert von »0.5« versucht PostgreSQL, alle Operationen in der ersten Halbzeit vor dem nächsten Checkpoint zu erledigen. Wer »checkpoint_segments« auf einen sinnvollen Wert erhöht hat (größer als 10), sollte diesen Wert auf »0.9« stellen, um so die Schreiboperationen gleichmäßiger zu verteilen.
<C>work_mem<C>
Der »work_mem« -Parameter beziffert den Speicher, den das System einer Datenbankverbindung beim Bearbeiten einer Abfrage für Sortiervorgänge bereit stellt. Wer also über genügend Speicher verfügt und oft komplexe Abfragen mit Sortier-Operationen verwendet, sollte diesen Parameter vergrößern. Aber Achtung: Dieser Wert gilt pro Sortiervorgang. Wer den wahren Speicherverbrauch abschätzen will, den der Parameter verursachen kann, muss ihn mit der Anzahl offener Verbindungen und der Anzahl von Sortiervorgängen innerhalb einer Abfrage multiplizieren: Ist der Wert beispielsweise auf 32 MByte gesetzt, können 25 Benutzer im Hauptspeicher schon weit über 2 GByte belegen, indem sie komplexe Abfragen stellen, welche jeweils zwei Mal den »work_mem« benutzen.
Reicht der hier gesetzte Speicher (der Standard ist 8 MByte) nicht, wird PostgreSQL eine temporäre Datei auf der Festplatte anlegen, um seine Aufgabe zu bewältigen. Dies sollte der Admin aus Performancegründen vermeiden. Um herauszufinden, ob PostgreSQL von temporären Dateien Gebrauch machen muss, kann er über die Einstellung »log_temp_files = 0« den Server anweisen, sämtliche Vorkommnisse dieser Art in die Logdatei zu schreiben.
Vorsicht vor <C>synchronous_commit = off<C>
Achtung: Diese Option auf »off« zu stellen, bringt mehr Performance (dritter Balken in Abbildung 1), kann aber zum Verlust der zuletzt geschriebenen Daten führen! Normalerweise benutzt PostgreSQL synchrones Schreiben für seine WAL-Segmente, um die maximale Zuverlässigkeit bei einem Servercrash oder Stromausfall bieten zu können.
Dies ist vor allem dann nötig, wenn das Platten-Subsystem, also der Server, nicht über eine unabhängige Stromversorgung (USV) verfügt. Synchrones Schreiben bewirkt, dass PostgreSQL den Erfolg über das Schreiben von Daten auf die Festplatte erst dann zurückmeldet, wenn diese es tatsächlich auf die Festplatte geschrieben hat.
Das Warten limitiert aber die maximal mögliche Anzahl von Transaktionen pro Sekunde. So waren beim Testsystem mit einem Client kaum mehr als 100 TA/s pro Client oder insgesamt kaum mehr als 1500 TA/s möglich. Mit einer USV kann der Admin das Risiko eines Datenverlusts erheblich reduzieren, aber dennoch nicht ganz ausschließen.
In einer Datenbank mit besonders wichtigen Daten, wie zum Beispiel bei einer Bank, bei der garantiert kein Datensatz verloren gehen darf, muss diese Option eingeschaltet bleiben. Aber für viele Applikationen ist die gesteigerte Performance wichtiger als der im seltenen Falle eines Servercrashs mögliche Verlust von wenigen Daten, die zuletzt hätten geschrieben werden sollen. Das Ausschalten dieser Option (mit »synchronous_commit = off« ) kann die Performance erheblich steigern, vor allem für Datenbanken, die viele kleine Transaktionen erledigen. Im Beispiel aus Abbildung 1 sorgt es für einen fast 2,5-fachen Datendurchsatz gegenüber den Standardeinstellungen.
Auch wenn der Admin diese Option ausschaltet, ist die Datenbank weiterhin vor Datenkorruption geschützt, da sie beim erneuten Start bis zum letzten vollständigen Checkpoint wiederhergestellt wird. Mehr dazu bietet die PostgreSQL-Dokumentation unter [4].
Das richtige Datenbank-schema verwenden
Auch das Design des Datenbankschemas gibt vielerlei Ansatzpunkte für Performance-Optimierungen. So lässt sich der Speicherbedarf der Datenbank schon durch die sorgfältige Auswahl geeigneter Datentypen reduzieren. Das verringert direkt die Anzahl schreibender und lesender Vorgänge und wird somit die I/O-Performance steigert. Die PostgreSQL-Dokumentation auf der Webseite erklärt unter [5] zu jedem Datentyp, wie viele Byte das Speichern eines Wertes in Anspruch nimmt.
Um CPU-Ressourcen zu schonen, kann der Programmierer auf nicht benötigte implizite Constraints verzichten. Muss er zum Beispiel die Länge eines Textfeldes nicht zwingend in der Datenbank begrenzen, so ist es performanter, statt des Typs »VARCHAR« den Typ »TEXT« zu verwenden, der eine unbegrenzte Länge zulässt. Das Feld beglegt dann den gleichen Speicherplatz wie ein Feld des Typs »VARCHAR« , aber das Prüfen der Länge vor dem Speichern entfällt.
Weiterhin lassen sich Spalten, in denen immer die gleichen Zeichenketten mit bis zu 63 Zeichen vorkommen, als »TEXT« anstatt als »ENUM« speichern. Dazu legt man zunächst mit »CREATE TYPE Name AS ENUM …« einen neuen Typ an und teilt ihm die möglichen Werte explizit mit. Ein Feld vom Typ »ENUM« belegt dann für jeden Wert nur noch exakt 4 Byte und ist auch noch sehr gut indizierbar.
Flaschenhälse finden und vermeiden
Bei der gezielten Suche nach dem Bottleneck einer Installation gilt es zunächst herauszufinden, in welchem Teil des Systems ein Engpass besteht und ob eine Tuning-Aktion erfolgreich war. Das entscheidende Maß dabei ist in der Regel, wie viel Zeit die Verarbeitung einer Datenbankabfrage benötigt. PostgreSQL kennt Möglichkeiten, Abfragen an die Datenbank zu protokollieren. Fürs Performance-Tuning eignen sich wiederum die Logs, die zu jeder Abfrage auch die Zeit notieren, welche die Datenbank dafür benötigt hat.
Wer einzelne Abfragen interaktiv über den Commandline-Client »psql« testet, schaltet per »\timing on« die Messung der Abfragen ein. Zu jeder Abfrage dieser Session zeigt der Client nun jeweils die Dauer in Millisekunden an. Noch besser geht es, wenn der Admin dafür sorgt, dass PostgreSQL global entweder alle Abfragen, oder zumindest alle Abfragen, die eine bestimmte Zeit dauern, protokolliert. Dies erreicht er über den Parameter »log_min_duration_statement« .
Ein Wert von 100 protokolliert alle Abfragen, die mindestens 100 Millisekunden gedauert haben. Der Wert 0 protokolliert sämtliche Abfragen. Eine detaillierte Analyse der so angefertigten Protokolle lässt sich mit dem Tool Pgfouine [6] aus der PostgreSQL-Foundry erstellen.
I/O- und CPU-Analyse
Um herauszufinden, ob die I/O-Last des Systems einen Engpass darstellt, eignen sich Standardtools wie »top« oder »htop« . Sie stellen die »IO-Wait« -Werte der CPU-Last dar, die zeigen, ob die CPUs oft auf die Festplatten des Systems warten. I/O-Wait-Werte über 20 Prozent weisen recht deutlich auf ein mögliches Problem hin. Mit beiden Tools misst der Admin zudem die CPU-Auslastung des Systems.
Tauchen in der nach CPU-Last sortierten Liste oft oder ständig Prozesse der Art
postgres: exampledb pguser01 127.0.0.1 (36140) SELECT
ganz oben auf oder sind sogar alle CPU-Cores mit derlei beschäftigt, dann deutet dies sehr klar darauf hin, dass der Server über zu wenige oder aber zu viele Cores verfügt. Alternativ kann die Ausgabe aber auch bedeuten, dass der Server schlicht zu umständlich formulierte Anfragen verwendet. Auch das Fehlen von wichtigen Indizes kann ein Grund für eine derart hohe CPU-Last sein.
Swap und Locking
Kluge Admins behalten die Belegung des Hauptspeichers mittels »free« ständig im Auge. Dass der Kernel ein wenig Swapspeicher benutzt, ist normal. Wenn er allerdings sehr viel Swap im Vergleich zum vorhandenen Haupspeicher verwendet und dabei der »cached« -Wert sehr gering ist (Listing 2), deutet das auf zu wenig RAM oder aber zu hoch eingestellte Speicherparameter in der Konfigurationsdatei »postgresql.conf« hin.
Abseits der genannten Szenarien kann es auch passieren, dass alle Systemparameter normal aussehen, die Datenbank aber trotzdem nicht aus den Puschen kommt und überaus langsam arbeitet, obwohl sich Speicher, CPU und Festplatten scheinbar langweilen. Manchmal ist dann Locking das Problem: Bestimmte Transaktionen in der Datenbank können verlangen, dass andere Transaktionen so lange warten, bis sie ihre eigenen Transaktionen beendet haben.
Erstellt der Admin zum Beispiel mit »REINDEX« und ohne die Angabe »CONCURRENTLY« einen Index auf einer Tabelle neu, so blockiert das alle schreibenden Anfragen auf der Tabelle, bis der neue Index fertiggestellt ist. Hat eine Anfrage zu viel Zeit benötigt, weil sie auf eine andere warten musste, sollte der Admin zwei Optionen setzen, damit PostgreSQL eine Logdatei anlegt:
log_lock_waits = on deadlock_timeout = 0
Dies wird alle Anfragen protokollieren, die sich aufgrund von Locks verzögern. Der Standardwert von »deadlock_timeout« beträgt 1 Sekunde, was nur Verzögerungen von mehr als einer Sekunde loggt. Locking-Probleme fangen aber schon bei viel geringeren Wartezeiten an.
PostgreSQL sammelt in der Standardeinstellung viele nützliche Informationen, die beim Aufspüren von Performance-Engpässen behilflich sind. Im Commandline-Client kann der Admin recht einfach sehen, welche Indizes nützlich sind, welche oft benutzt werden und welche die Datenbank vielleicht niemals heranzieht. Die wären folglich pure Ressourcenverschwendung. Mit der Zieldatenbank verbunden, schaut sich der Admin den View »pg_stat_user_indexes« an (Listing 3 zeigt das am Beispiel einer Bacula-Datenbank).
Listing 3
Reine Ressourcenverschwendung
01 SELECT relname,indexrelname,idx_scan,idx_tup_read,idx_tup_fetch FROM pg_stat_user_indexes; 02 relname | indexrelname | idx_scan | idx_tup_read | idx_tup_fetch 03 ----------------+-------------------------------+----------+--------------+--------------- 04 file | file_jobid_idx | 6825 | 145477550 | 4114986 05 file | file_jpfid_idx | 0 | 0 | 0 06 file | file_pathid_idx | 0 | 0 | 0 07 jobmedia | job_media_job_id_media_id_idx | 1526 | 23049 | 9046 08 filename | filename_name_idx | 1477899 | 1388829 | 1388829 09 job | job_name_idx | 624 | 199263 | 0
Der Statistics Collector
Indizes, für die in keiner der drei Spalten »idx_scan« , »idx_tup_read« oder »idx_tup_fetch« etwas gezählt wurde (Werte gleich Null), hat die Datenbank nie benutzt. Bestehen solche Indizes für sehr schreibintensive Tabellen, wirkt sich das fast zwangsläufig negativ auf die Performance aus. PostgreSQL zeichnet auch für jede Tabelle die Anzahl der sequenziellen Lesevorgänge auf. Weist die Spalte »seq_scan« des Views »pg_stat_user_tables« (Listing 4) einen hohen Wert auf, dann kann das darauf hindeuten, dass sich mit dem Anlegen geeigneter Indizes die Performance merklich erhöhen lässt. Was dabei ein “hoher Wert” ist, muss der Admin allerdings selbst aus Erfahrung mit seiner Datenbank und seinen Anwendungen feststellen.
Listing 4
Zu viele Full-Table-Scans
01 SELECT relname,n_live_tup,seq_scan,idx_scan FROM pg_stat_user_tables; 02 relname | n_live_tup | seq_scan | idx_scan 03 ----------------+------------+----------+---------- 04 path | 7731 | 366 | 3094707 05 media | 181 | 921 | 6952 06 jobmedia | 2987 | 121 | 1526 07 log | 62971 | 55 | 280 08 pathvisibility | 295566 | 55 | 280 09 filename | 89070 | 327 | 8732226 10 file | 17772210 | 62 | 6825 11 job | 1418 | 2780 | 9540
Infos
- PostgreSQL: http://www.postgres.org
- Atomicity, Consistency, Isolation, Durability: http://en.wikipedia.org/wiki/ACID
- Shared-Memory-Parameter: http://www.postgresql.org/docs/current/static/kernel-resources.html#SHARED-MEMORY-PARAMETERS
- PG-Server-Tuning: http://wiki.postgresql.org/wiki/Tuning_Your_PostgreSQL_Server
- Datentypen: http://www.postgresql.org/docs/current/static/datatype.html
- Pgfoundry: http://pgfouine.projects.pgfoundry.org





