
© Michael Edward, 123RF.com
Ein großer Vorteil von Virtualisierungen ist die Möglichkeit, Systeme von einem Host auf einen anderen umzuziehen, ohne dass für den Anwender eine längere Downtime entsteht. Damit das reibungslos klappt, müssen sowohl der Hypervisor als auch der verwendete Storage mitspielen.
Effizient und flexibelsei die Cloud, erzählen Experten gebetsmühlenartig. Aber weder Virtualisierung noch die Abrechnung nach Ressourcennutzung sind neu, die Konzepte stammen aus der Urzeit der IT. Mittlerweile gelten die Cloudlösungen als Mainstream. Planer und Consultants gehen in IT-Unternehmen davon aus, dass die Admins eine neue Serverplattform nur mehr virtualisiert betreiben.
Das spart Kosten für Hardware und den laufenden Betrieb und bringt quasi im Vorbeigehen zahlreiche weitere Vorteile. Einer davon ist das Live-Migrieren laufender Systeme. Was bei echter Hardware unmöglich wäre, gelingt mit virtualisierten Systemen ganz leicht. Eine auf einem Host laufende VM “einzufrieren”, sie auf einen der anderen Virtualisierungs-Gastgeber zu verschieben und dort fortzusetzen, ohne dass für die Nutzer des in der VM laufenden Dienstes ein spürbarer Aussetzer entsteht, das ist immer noch die hohe Schule der Virtualisierungskunst, und hier trennt sich Spreu von Weizen.
Spiele ohne Grenzen
In der Tat sind die Ergebnisse beeindruckend. Furore machte vor einigen Jahren ein archetypisches Demo-Setup, bei dem Spieler des 3-D-Egoshooters Quake 3 während des Spiels nichts davon mitbekamen, dass die VM mit ihrem Server gerade von einem auf den anderen Host umgezogen war. Die effektive Downtime beim Client lag bei wenigen Sekunden, sodass problemlos auch ein Schluckauf im Netzwerk die Ursache hätte sein können.
Admins freuen sich freilich auch aus anderen Gründen über eine Livemigration, denn sie erlaubt es, ohne lange Downtime Wartungsarbeiten auf Virtualisierungshosts zu erledigen. Bevor die Arbeit auf einem Computing-Knoten losgeht, migriert der Admin alle VMs auf andere Server und kann dann mit dem Update-Kandidaten tun und lassen, was er will. Dass das allerdings zwischen verschiedenen Produkten, Architekturen oder CPU-Varianten leider immer noch nicht geht, zeigt der Kasten “Gelingt nicht ohne Downtime”.
Gelingt nicht ohne Downtime: Den Hypervisor wechseln
Die wichtigste Komponente bei einer Livemigration ist der Hypervisor. Mit dessen Wahl legt sich der Administrator allerdings fest, denn die Livemigration von einem zu einem anderen Hypervisor ist unter Linux derzeit unmöglich. Wer eine Virtualisierungsumgebung baut, sollte sich also vor Augen halten, dass homogene Setups grundsätzlich leichter zu warten sind als solche, in denen verschiedene Hypervisoren zum Einsatz kommen.
Das Prinzip der Homogenität lässt sich in gleicher Weise übrigens auch auf das Thema Architektur anwenden. Bereits die Migration von einer VM, die auf einem 32-Bit-Host läuft, auf einen 64-Bit-Hypervisor ist eine Herausforderung. 64-Bit-VMs können auf 32-Bit-CPUs gar nicht ordentlich laufen. Wer plant, Architekturen in Virtualisierungs-Setups zu kombinieren, muss sich also mit dem kleinsten gemeinsamen Nenner abfinden, nicht selten also mit 32-Bit-Systemen.
Livemigration zu anderen Hypervisoren?
Schließlich ist ein oft anzutreffendes Prozedere der Umstieg von einem Hypervisor auf einen anderen, kombiniert mit dem typischen Wunsch nach so wenig Downtime wie möglich. Wer solch eine Aufgabe zu erledigen hat, muss sich über die entsprechenden Fähigkeiten der künftigen Lösung informieren. KVM und Qemu bringen jede Menge Werkzeuge zum Konvertieren von Images mit, die sich auch ohne langes Studium der Manpages leicht bedienen lassen.
Aber die Idee, eine Qemu-KVM-VM ohne Downtime auf einen Hypervisor-Host mit Windows zu migrieren, schlägt schon deshalb fehl, weil Livemigration mit KVM zum großen Teil direkt in Qemu passiert, Qemu aber zum Beispiel mit Microsofts Hyper-V nicht kommunizieren kann. Eine solche Lösung wäre zwar technisch elegant, fällt im Moment aber leider in die Geht-nicht-Kategorie.
Auch eine Migration von Xen hin zu KVM lässt sich kaum sinnvoll ohne eine – wenn auch kurze – Unterbrechung erledigen. Wer zu einer kommerziellen Virtualisierungssoftware, also zum Beispiel VMware, greift, hat mehr Glück. So bietet VMware eine Migrationsfunktion namens Virtual to Virtual an, die eine beliebige virtuelle Maschine in eine neue VMware-VM umbaut. Ganz ohne Downtime geht das zwar auch nicht, aber die Zeitspanne ist dennoch deutlich kürzer, als es bei einem händischen Umwandeln der Fall wäre.
Der technische Hintergrund
Mittlerweile existieren einige fertige Lösungen zur Livemigration, die das Feature ab Werk mitbringen und oft gar per GUI die Option bieten, Livemigration per Mausklick zu aktivieren. Der technische Hintergrund der meisten Lösungen ist der gleiche. Die im RAM abgelegten Inhalte einer virtuellen Maschine, die auf Host A läuft und im laufenden Betrieb auf einen anderen Host wandern soll, kopiert die verwendete Virtualisierungslösung auf den Zielhost und ruft dort bereits den Virtualisierungsprozess auf, während das System auf Host A noch weiterhin funktioniert.
Erst wenn der RAM-Inhalt vollständig auf dem Zielhost angekommen ist, hält der Virtualisierer die VM am Quellhost kurz an, kopiert das inzwischen entstandene Delta ebenfalls zum Ziel und beendet schließlich den Emulator auf dem Quell-Host. Diese kurze Zeit ist im Idealfall die einzige Downtime, die entsteht.
Damit das Prinzip so funktioniert, sind ein paar Bedingungen zu erfüllen. Die wichtigsten Fragen betreffen den Storage. Denn damit die virtuelle Maschine gleichzeitig auf zwei Hosts laufen kann, ist eine Grundvoraussetzung, dass ihr Storage zum genannten Zeitpunkt auf beiden Rechnern lesend und schreibend zur Verfügung steht. Wie das in der Realität funktioniert, hängt von der genutzten Storage-Technologie und der Architektur der Virtualisierungslösung ab.
Für den Storage: NFS, I-SCSI, DRBD, Ceph
SAN-Storages sind häufig Bestandteil von VM-Setups. Sie bieten ihre Daten meist entweder per NFS oder per I-SCSI an. Mit NFS gelingt der Zugriff auf die Daten von mehreren Seiten problemlos, denn schließlich ist genau das ein Use-Case für NFS. I-SCSI-SANs sind hakeliger und bedingen zusätzliche Funktionen im Hinblick auf die Software, die sich um die Verwaltung der virtuellen Maschinen kümmert. Der I-SCSI-Standard sieht den konkurrierenden Zugriff zweier Server auf dieselbe LUN nämlich gar nicht vor, sodass Hilfskonstruktionen mittels LVM oder Cluster-Dateisystemen wie OCFS2 und GFS2 nötig werden.
Angenehmer lässt sich ein VM-Setup mit Livemigration auf Grundlage eines DRBD-Clusters konstruieren. DRBD bietet grundsätzlich die Option, eine vorhandene Ressource im Dual-Primary-Modus zu nutzen [2], in dem schreibender Zugriff auf beiden Seiten eines Clusters möglich ist. Zusammen mit einem modernen Clustermanager wie Pacemaker und Libvirt wird aus dem Gespann ein Setup mit echten, Enterprise-tauglichen Livemigrations-Fähigkeiten. Der Pferdefuß an dieser Lösung ist jedoch, dass sie – DRBD-bedingt – auf zwei Knoten beschränkt bleibt, zumindest so lange, wie DRBD 9 noch nicht reif für den Einsatz in einer Produktionsumgebung ist.
Administratoren, die auf der Suche nach zuverlässiger Virtualisierung mit Live-Migration und Scale-out-Funktionalität sind, sollten für neue Setups Ceph ([3], [4]) mit in ihre Planungen einbeziehen. Denn deren Komponenten, die für ein solches Setup notwendig sind, gelten nach Meinung der Autoren der Umgebung mittlerweile als stabil und eignen sich für den Produktiveinsatz.
Ein Object Store
Die Lösung mit dem tierischen Namen (Ceph steht für Krake) gehört zur Kategorie der so genannten Object Storages, was insbesondere darin zum Ausdruck kommt, dass in Ceph abgelegte Dateien in binäre Objekte aufgeteilt und dann auf eine Vielzahl Speicherorte verteilt sind. Object Stores umgehen auf diese Weise ein Designproblem, das entsteht, würde man verteilte Systeme auf Grundlage von Blockspeichern konstruieren: Blöcke sind starr und eng mit dem Dateisystem verbunden, das die Block-basierten Datenträger überhaupt erst für die Anwender nutzbar macht.
Eine “nackte” Festplatte wäre ab Werk nicht sinnvoll zu nutzen; zwar lassen sich Daten auf ihr ablegen, doch wäre es unmöglich, diese zu einem späteren Zeitpunkt geordnet wieder zu lesen. Die Struktur, die den geordneten Zugriff auf Block-basierten Speicher erlaubt, bringen erst Dateisysteme. Weil ein Dateisystem sich aber nicht problemlos in mehrere Streifen aufteilen und dann auf verschiedene Server verteilen lässt, sind Blöcke im Grunde nicht für Scale-out-Lösungen zu gebrauchen.
Object Stores umgehen das Problem, indem sie ihre interne Verwaltung selbst übernehmen und auf Grundlage binärer Objekte konstruieren, die beliebig teilbar und auch wieder zusammensetzbar sind. Sie ziehen zwischen Dateisystem und Benutzer gewissermaßen eine zusätzliche Schicht ein.
Beliebige Frontends? Mit Object Stores kein Problem
Daraus ergibt sich ein großer Vorteil von Object Stores: Sie sind in der Lage, letztlich dem Client jedes beliebige Frontend zur Verfügung zu stellen. Denn wenn der Object Store seine interne Organisation auf Basis der binären Objekte abwickelt, kann er diese in jedem beliebigen Format auch an die Clients ausliefern. Im Falle von Ceph, bei dem der Object Store Rados heißt, machen die Entwickler von dieser Möglichkeit mannigfaltig Gebrauch. Denn neben dem Posix-kompatiblen Dateisystem Ceph-FS und dem Rest-API mit Namen Radosgw exponiert Rados seine Daten auch in Form eines Blockdevice, das RBD heißt – die Abkürzung für Rados Block Device.
Die gute Nachricht ist: Aktuelle Libvirt-Versionen können mit Rados bereits umgehen, auch Qemu kommt in aktuellen Versionen mit einer nativen Anbindung an Rados per RBD (und dem Umweg über die C-Bibliothek Librados).
Der Effekt ist durchaus beeindruckend: Von beliebig vielen Virtualisierungsknoten aus lässt sich der Object Store direkt an Libvirt beziehungsweise Qemu anbinden, und auch der gleichzeitige Zugriff von mehreren Orten auf die gleichen binären Objekte ist möglich, sodass Livemigration kein Problem ist.
Libvirt kümmert sich dabei darum, dass nichts schiefgeht, verhindert also feindlichen, schlimmstenfalls konkurrierenden Schreibzugriff beim eigentlichen Migrieren der VM.
Der Weg zum Virtualisierungscluster
Für ein sinnvolles Ceph-Setup sind drei einzelne Server Grundvoraussetzung – drei Server deshalb, damit das Quorum-Handling in Ceph sinnvoll funktioniert. Ceph behandelt jede einzelne Festplatte als ein eigenes Speichergerät, sodass die Zahl der Platten (OSD, Object Storage Daemon, Abbildung 1) pro Host letztlich eine untergeordnete Rolle spielt. Es empfiehlt sich anfangs trotzdem, drei Rechner mit identischer Hardwarekonfiguration für das Setup zu nutzen.
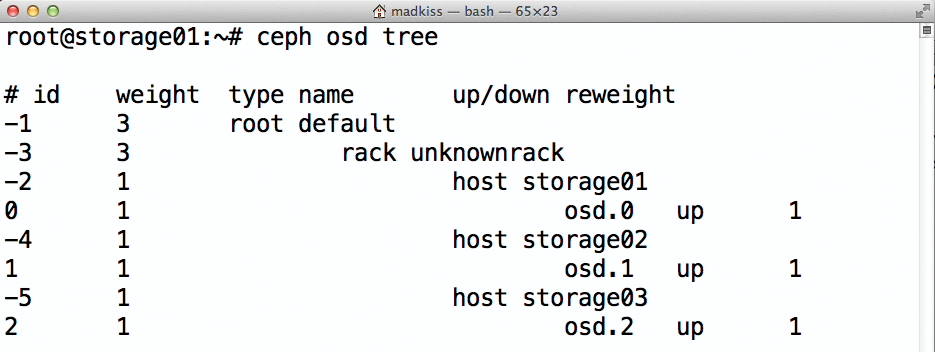
Abbildung 1: Ceph verwaltetet seine OSDs zentral, zieht zwischen Benutzern und Blockdevice aber noch eine Zwischenschicht ein und ist so sehr flexibel.
In Sachen Hardware sollten Admins nicht sparen, denn neben der Rolle des Object Store übernehmen die Rechner zugleich auch die Rolle der Virtualisierungshosts. Jeder ist also zugleich Teil des Object Store und virtualisiert auch.
In Kombination mit Pacemaker und einer Konfiguration ähnlich wie der beschriebenen für DRBD wird dann aus den einzelnen Clusterknoten ein sich selbst verwaltender VM-Cluster, bei dem jede virtuelle Maschine auf jedem Host laufen kann und bei dem auch die Livemigration zwischen den Rechnern – dank des Gespanns aus Qemu und RBD – problemlos funktioniert. Weitere Informationen zum Thema Ceph finden sich in weiteren Artikeln des Autors unter [5], [6] und [7].
DRBD, Libvirt und Pacemaker
Die VM-Migrationskonzepte diverser Drittanbieter sind ebenso unterschiedlich wie komplex. Allerdings gibt es auf Linux-Systemen auch schon mit Bordmitteln die Möglichkeit, eine VM-Migration per Libvirt und Pacemaker einzurichten. Das folgende Beispiel orientiert sich zunächst an einem simplen Zwei-Knoten-Cluster, der seine Daten per DRBD zwischen den Hosts synchron hält. Diese Art von Setup ist nicht besonders komplex und erlaubt einen guten Einblick in seine Funktionsweise.
Damit Livemigration mit Libvirt und Pacemaker auf Grundlage von DRBD wie gewünscht funktioniert, muss DRBD zunächst lernen im Dual-Primary-Modus zu funktionieren; diese Option ist ab Werk aus Sicherheitsgründen deaktiviert.
Mit DRBD 8.3
Es hängt von der genutzten DRBD-Version ab, wie sich dieser Modus für DRBD aktivieren lässt. Kommt, wie bei der Mehrzahl der Enterprise-Systeme üblich, DRBD 8.3 zum Einsatz, aktiviert der folgende Eintrag in der Konfiguration einer Ressource den Dual-Primary-Modus:
net {
allow-two-primaries;
}
Kommt hingegen DRBD 8.4 ins Spiel, ist die Konfiguration einer Ressource um den folgenden Eintrag zu erweitern:
net {
protocol C;
allow-two-primaries yes;
}
Die Änderungen lassen sich auch im laufenden Betrieb durchführen, wenn im Anschluss ein »drbdadm adjust Resource« erfolgt. Vorsicht: Mit Pacemaker empfiehlt es sich, den Cluster wenigstens in den Wartungsmodus zu versetzen, bevor irgendwelche Änderungen an DRBD oder Libvirt stattfinden. Das geht mit »crm configure property maintenance-mode=true« direkt auf der Kommandozeile einer der Knoten, die zum Cluster gehören, und gilt danach Cluster-weit.
Pacemaker mit mehr als zwei Knoten?
Apropos Pacemaker: Wer einen Zwei-Knoten-Cluster für Virtualisierung nutzt, wird in diesem üblicherweise auch DRBD von Pacemaker verwalten lassen. Die im Netz kursierenden Anleitungen konfigurieren DRBD-Ressourcen dabei so, dass nur einer der beiden Knoten im Primary-Modus läuft (Abbildung 2). Um das zu ändern, ist eine Konfigurationsänderung in Pacemaker notwendig. Meist sehen DRBD-Ressourcen in Pacemaker so aus:
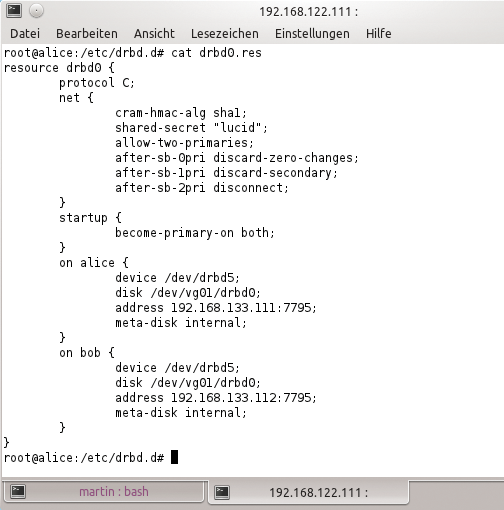
Abbildung 2: DRBD lässt sich mit der Dual-Primary-Funktion nutzen, um virtuelle Maschinen in Zwei-Knoten-Clustern live zu migrieren.
ms ms_drbd-vm1 p_drbd-vm1 \ meta notify="true" master-max="1" clone-max="2"
Um für eine solche DRBD-Ressource den Dual-Primary-Modus zu aktivieren, genügt es, den Wert hinter »master-max« auf »2« zu setzen. Danach konfiguriert Pacemaker die DRBD-Ressource automatisch so, dass sie auf den beiden Clusterknoten im Primary-Modus läuft.
Gestatten? Die Libvirt-Instanzen
Die nächste Hürde für Livemigration besteht darin, die Instanzen von Libvirt auf den Knoten miteinander bekannt zu machen. Denn damit eine Livemigration zwischen den Knoten A und B funktionieren kann, müssen die Libvirt-Instanzen miteinander kooperieren. Konkret heißt das, dass jede Libvirt-Instanz einen TCP/IP-Socket öffnen. Dafür reichen die folgenden Einträge in »/etc/libvirt/libvirtd.conf« :
listen_tls = 0 listen_tcp = 1 auth_tcp = "none"
Aber Achtung: Die gezeigte Konfiguration verzichtet auf jede Form von Authentifizierung zwischen den Clusterknoten. Anstelle von TCP ließe sich auch SSL-Kommunikation mit entsprechenden Zertifikaten bauen. Diese Konfiguration wäre aber deutlich umständlicher, so dass diese Anleitung darauf verzichtet, sie zu dokumentieren.
Zusätzlich zu den Änderungen in »libvirtd.conf« müssen Admins auch sicherstellen, dass Libvirt mit dem Parameter »-l« startet; auf Ubuntu genügt es, den Eintrag »libvirtd_opts« in »/etc/default/libvirt-bin« um den entsprechenden Parameter zu erweitern. Im Anschluss ist ein Libvirt-Neustart fällig, danach gelingt bereits die Livemigration zumindest auf Libvirt-Ebene (Abbildung 3).
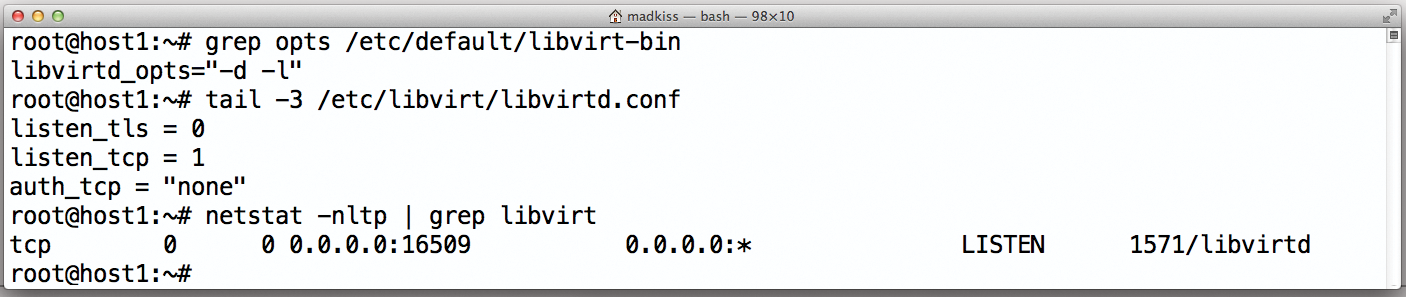
Abbildung 3: Mit den richtigen Konfigurationsparametern lauscht Libvirt auf einem Port für eingehende Verbindungen von anderen Libvirt-Instanzen im Netz.
Livemigration mit Pacemaker
Damit Pacemaker Livemigration tatsächlich kontrollieren kann, ist noch eine kleine Änderung der Konfiguration notwendig im Hinblick auf die in Pacemaker abgelegten Definitionen der virtuellen Maschinen. Der Agent in Pacemaker, der sich um virtuelle Maschinen kümmert, würde ab Werk auch dann, wenn der Admin eine VM per »migrate« -Befehl verschiebt, diese stoppen und auf dem Ziel-Host wieder starten.
Damit er das nicht tut, muss er lernen, dass Livemigration erlaubt ist. Dazu ein konkretes Beispiel, dessen ursprüngliche Konfiguration so aussieht:
primitive p_vm-vm1 ocf:heartbeat:VirtualDomain \ params config="/etc/libvirt/qemu/vm1.cfg"\ op start interval="0" timeout="60" \ op stop interval="0" timeout="300" \ op monitor interval="60" timeout="60" start-delay="0"
Um die Livemigration zu aktivieren, wäre die Konfiguration wie folgt zu ändern. Wichtig sind insbesondere die zusätzlichen Parameter sowie das neue »meta« -Attribut in der letzten Zeile:
primitive p_vm-vm1 ocf:heartbeat:VirtualDomain \ params config="/etc/libvirt/qemu/vm1.cfg"migration_transport="tcp" \op start interval="0" timeout="60" \ op stop interval="0" timeout="300" \ op monitor interval="60" timeout="60" start-delay="0" \meta allow-migrate="true" target-role="Started"
Mit dieser Konfiguration migriert »crm resource move p_vm-vm1« die virtuelle Maschine im laufenden Betrieb.
I-SCSI-SANs
Wer darauf angewiesen ist, Livemigration auf Grundlage eines SAN mit I-SCSI-Anbindung zu realisieren, hat ein ungleich schwereres Los. Das liegt im Wesentlichen an der Tatsache, dass SAN-Storages eigentlich nicht darauf ausgelegt sind, von mehreren Seiten konkurrierenden Zugriff auf bestimmte LUNs zu verstehen. Es ist deshalb notwendig, eine Zwischenebene einzuziehen, die diese Funktion nachrüstet.
Die meisten Admins erledigen das mit der Clusterversion von LVM (»cLVM« ) oder einem der typischen Cluster-Dateisysteme (GFS2 oder OCFS2). Konkret sieht das Setup so aus wie in Abbildung 4: Auf jedem Knoten des Clusters ist die I-SCSI-LUN als lokales Device angemeldet, eine Instanz von CLVM oder OCFS/GFS2 kümmert sich um den koordinierten Zugriff. Zudem setzt die Konstruktion zwingend voraus, dass Libvirt sich selbst zuverlässig um das Locking kümmert.
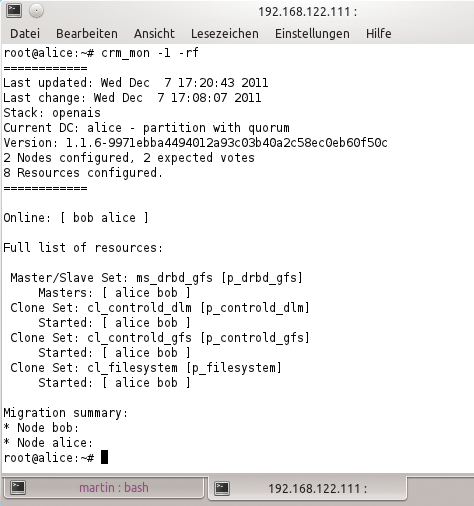
Abbildung 4: Ein typisches Pacemaker-Setup.
Setups wie das erwähnte sind deshalb nur sinnvoll, wenn Libvirt gleichzeitig das kleine Tool Sanlock [8] nutzt. Denn nur dies verhindert, dass dieselbe VM auf mehr als einem Server gleichzeitig gestartet ist, was ebenfalls tödlich für die Konsistenz der Dateisysteme innerhalb der VM selbst wäre.
LVM als schwächstes Glied
Was in der Theorie einleuchtend klingt, kann im Alltag des Sysadmin schnell nervig werden. Das schwächste Glied in der Kombination aus Libvirt, einem SAN, Pacemaker sowie GFS2/OCFS2/CLVM ist zweifellos CLVM. Das liegt einerseits daran, dass der DLM-Stack auf Linux (DLM steht für Distributed Locking Manager) in den letzten Jahren immer wieder umgebaut worden ist, sodass auf SLES, RHEL, Debian sowie Ubuntu heute jeweils unterschiedliche Dinge zu erledigen sind, wenn solch ein Setup überhaupt entstehen soll.
Andererseits kommen die DLM-basierten Komponenten mit viel Komplexität einher. Das betrifft sowohl die Ebene der Dienste selbst wie auch ihre ordnungsgemäße Verwaltung mittels eines Clustermanagers, der für solche Setups zum Pflichtprogramm gehört.
Bastian Blank, der maßgeblich an der Pflege des Linux-Kernels für Debian beteiligt ist, hat den CLVM-Dienst im Debian-Kernel kürzlich sogar mit dem Kommentar deaktiviert, dieser habe ohnehin nie zuverlässig funktioniert. Wer ein SAN zur Verfügung hat, das NFS kann, tut sehr gut daran, lieber dieses zu nutzen, statt zu einem Cluster-Dateisystem oder verteiltem LVM zu greifen.
Basteln oder kaufen?
Wenn Admins auf eine der diversen fertigen Virtualisierungslösungen wie VMware oder Red Hats O-Virt setzen, müssen sie sich mit dem Thema Migration und Livemigration in der Regel gar nicht mehr befassen. Denn alle fertigen Lösungen dieser Art beherrschen Livemigration. Wenn ein kleines Virtualisierungs-Setup auf Grundlage von DRBD gewünscht ist, so reicht die Kombination aus DRBD, Libvirt und Pacemaker für Livemigration völlig aus. Wer sich hingegen mit einem SAN-Storage konfrontiert sieht, hofft auf die NFS-Fähigkeiten des Geräts oder greift notgedrungen zu Werkzeugen, die aus einem SAN einen verteilten Storage machen.
Als Alternative bietet sich jedenfalls Ceph an, bei dem Livemigration mittels Libvirt von Anfang an serienmäßig war (Abbildung 5). Nachdem der Hersteller Inktank die dafür benötigten Komponenten von Ceph, also Rados, Librados und DRBD, mittlerweile auch offiziell als stabil betrachtet, sollte Ceph jedenfalls mit in die Überlegungen einfließen, in deren Rahmen ein Setup wie das hier erläuterte entsteht.
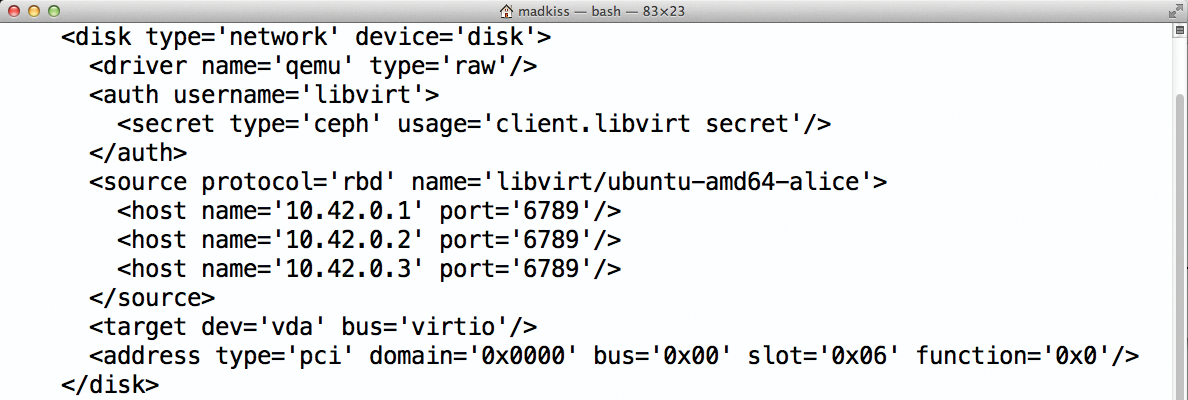
Abbildung 5: Libvirt enthält in aktuellen Versionen bereits eine native Anbindung an Ceph. Livemigrationen sind in solchen Setups kein Problem mehr.
Infos
- Studie der NSDI (2005): http://static.usenix.org/event/nsdi05/tech/full_papers/clark/clark.pdf
- Dual-Primary in DRBD: http://www.drbd.org/users-guide/s-dual-primary-mode.html
- Ceph: http://ceph.com
- Udo Seidel, “Speicher satt”: Linux-Magazin 02/13, S. 30
- Martin Gerhard Loschwitz, “Der RADOS-Objectstore und Ceph”, Teil 1: Admin-Magazin 06/12
- Martin Gerhard Loschwitz, “Der RADOS-Objectstore und Ceph”, Teil 2: Admin-Magazin 01/13
- Martin Gerhard Loschwitz, “Der RADOS-Objectstore und Ceph”, Teil 3: Admin-Magazin 02/13
- Sanlock: https://fedorahosted.org/sanlock/
Der Autor

Martin Gerhard Loschwitz arbeitet als Principal Consultant bei Hastexo. Er beschäftigt sich dort intensiv mit Hochverfügbarkeitslösungen und pflegt in seiner Freizeit den Linux-Cluster-Stack für Debian..





