
© cybernautin, photocase.com
Mit einer chinesischen Guillotine und einem Einzugsscanner bewaffnet geht Perlmeister Michael Schilli diesmal seinen Büchern an den Leim. Die Grundlage seiner bibliophoben Tat liefert Google Drive, das mit 5 GByte genug Speicherplatz für ein Online-PDF-Lager mit eingescannten Büchern bietet.
Noch zieren sich die deutschen Verlage etwas mit der Umstellung auf digitale Bücher, doch die Weichen sind längst gestellt. Wer hat schon Lust, ein paar Kilo Bücher mit in den Urlaub zu schleppen, wenn Übergepäck Unsummen kostet? Warum zu Hause Regale mit staubfangenden Büchern zustellen, die kein Digital Native mehr rauszieht?!
Der Blick zurück ist aber nötig: Ich hatte in meinem früheren, Papier-basierten Leseleben jahrelang Regale mit ungelesenen Papierbüchern gefüllt – und die möchte ich nun nicht alle neu im Digitalformat kaufen. Es geht mir dabei nicht nur ums Geld, sondern auch um die Tatsache, dass die meisten älteren Werke wohl nie digital erscheinen werden.
Zur Vergangenheitsbewältigung habe ich mir deshalb einen 400 Dollar teuren Wunderscanner von Fujitsu angeschafft. Die zweite Digitalisier-Gerätschaft arbeitet rein mechanisch und trägt den jakobinischen Namen “Guillotine”: Ein etwa 20 Kilo schweres Papiermesser (Abbildung 1), erworben für 150 Dollar in einem großen Internet-Auktionshaus), mit dem ich Wälzer bis zu etwa 600 Seiten von Umschlag und Bindung befreie.
Mit einem Teppichmesser trenne ich zunächst Hardcover vom Buchrumpf (Abbildung 2) und halbiere 1000-Seiten-Wälzer, damit sie in die Guillotine aus chinesischer Produktion passen. Das Fallbeil schneidet dann den geklebten oder gebundenen Buchrücken ab und die entstandene Loseblattsammlung zieht anschließend der Fujitsu S1500 ein (Abbildung 3), fährt eine OCR-Zeichenerkennung auf das Digitalformat und speichert das Buch als PDF ab.

Abbildung 1: Eine so genannte Guillotine schneidet ritsch-ratsch den geklebten Buchrücken ab.

Abbildung 2: Mit einem Teppichmesser geht es dem Umschlagdeckel an den Kragen.

Abbildung 3: Der Scanner Fujitsu S1500 zieht die losen Buchseiten ein und führt einen OCR-Lauf aus.
Google Drive vs. Dropbox
Ein dicker Wälzer wie “Algorithmen in C++” schlägt bei mir als PDF mit 200 bis 300 MByte (im Doppelsinn) zu Buche. Damit der User das Nachschlagewerk auf allen Geräten, vom Heim-PC bis zum iPad im Urlaub, parat hat, bieten Firmen wie Dropbox Applikationen an, die einmal gespeicherte Dateien magisch über das Netz verteilen, ohne dass der Anwender dies groß anordnen muss.
Google ist mit “Drive” [2] relativ neu in diesem Onlinestorage-Geschäft. Die für PC, Mac, iPad, Android-Geräte und Webbrowser verfügbaren Applikationen sind noch nicht so ausgereift wie die von Platzhirsch Dropbox, funktionieren aber. Eine native Drive-Applikation für Linux fehlt, Google liefert sie hoffentlich irgendwann nach. Beide Konkurrenten stellen interessierten Bastlern hervorragend dokumentierte APIs zur Verfügung, um nach Herzenslust selbst Applikationen zu zaubern.
PDFs online speichern
Abbildung 4 zeigt die auf Google Drive hochgeladenen PDF-Dateien in einem Chrome-Browser, Google unterstützt aber auch Firefox. Ein Mausklick auf eine Datei löst einen Download aus, einige Zeit später springt der PDF-Reader an und zeigt das gescannte Buch an. Im iPad speichert die Applikation Google Drive (Abbildung 5) die PDF-Daten zwischen, bis zu einer einstellbaren Grenze. Beim Downloaden der App ist darauf zu achten, dass man das Original von Google erwischt, es sind einige minderwertige Klone von Drittfirmen im Umlauf.

Abbildung 4: Im Webbrowser bringt Google Drive die gespeicherten PDF-Dateien zur Ansicht.
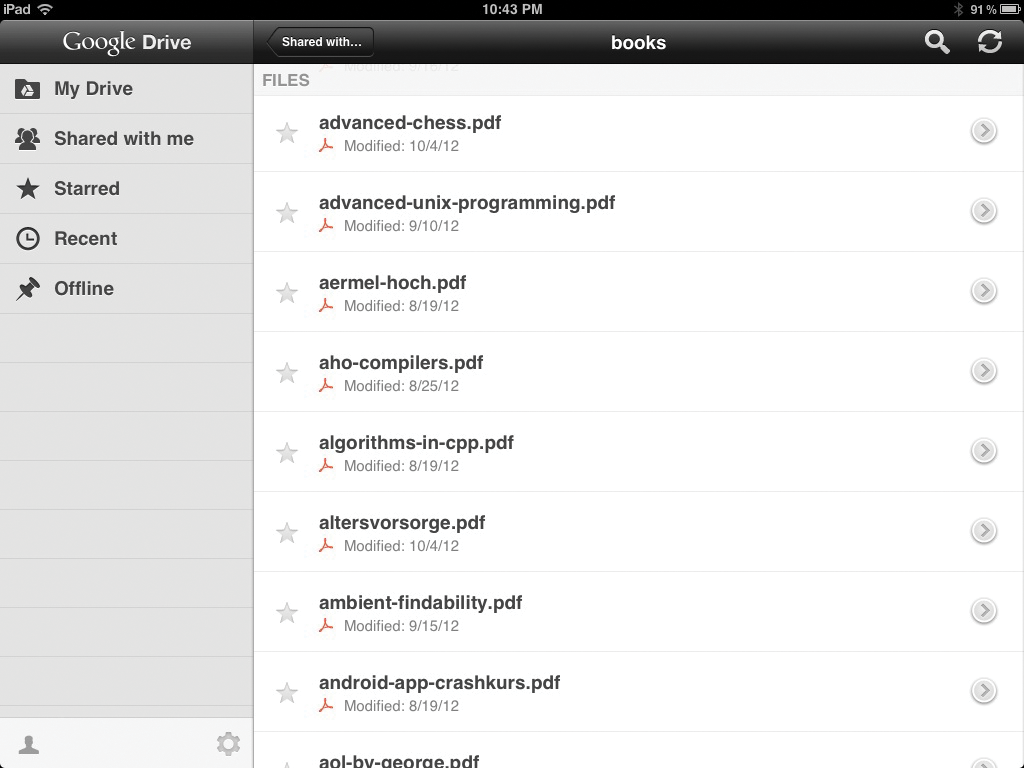
Abbildung 5: Die Drive-App auf dem iPad, die ebenfalls die gescannten Papierbücher als PDFs anzeigt.
Automatisch per API
Als Reader empfiehlt sich bei großen PDF-Dateien nicht das Original von Adobe, da es nicht für schwachbrüstige Mobilgeräte ausgelegt ist. Kostenpflichtige iPad-Apps wie Goodreader [3] oder Ez PDF [4] auf einem Android-Telefon bieten mehr Komfort und Performance. Das Hochladen der gescannten Bücher gestaltet sich im Browser zwar recht einfach, allerdings kann es je nach Netzwerkverbindung eine Weile dauern.
Statt dies jedes Mal manuell durchzuführen, empfiehlt sich unter Linux der Einsatz einer handgeschriebenen Applikation. Es existieren zwar einige Programme, die mittels Fuse ein Dropbox-ähnliches Verhalten vorgaukeln, doch eigene Skripte bieten die kreativeren Möglichkeiten.
Dank des umfangreichen API mit hervorragender Dokumentation [5] ist dies leicht möglich. Leider liefert Google nur SDKs für Java, Ruby, PHP und Python, doch das REST-Web-API lässt sich auch leicht von einem Perl-Skript nutzen.
Zugriffe regeln
Nur berechtigte User mit registrierten Applikationen sollen auf die unter Umständen sensiblen Daten auf dem Google Drive zugreifen dürfen. Google regelt die Berechtigung mit dem Oauth-Protokoll, mit dem Webapplikationen von Drittanbietern Userdaten lesen und manipulieren, ohne dass der User dem Drittanbieter sein Passwort mitzuteilen braucht.
Hierzu holt sich eine registrierte Applikation zunächst von Google einen Request-Token ab und leitet den User im Webbrowser auf die Google-Login-Seite weiter. Dort trägt er seinen Usernamen und sein Passwort ein, falls er noch nicht eingeloggt ist, und bekommt daraufhin einen Dialog vorgesetzt, der nachfragt, ob er wirklich gewillt ist, dem Drittanbieter Zugriff auf seine Daten zu gewähren. Nach der Bestätigung leitet Google den Browser des Benutzers wieder zurück zur Applikation des Drittanbieters und schickt einen Access-Token und einen Refresh-Token mit.
Der Access-Token gilt für eine bestimmte Zeitspanne, zum Beispiel eine Stunde, und erlaubt dem Drittanbieter, dem vom User gewählten Berechtigungs-Scope entsprechend auf dessen Daten herumzuorgeln. Manche Scopes gestatten nur das Lesen der E-Mail-Adresse, andere das Lesen aller Dateien auf Google Drive und einer sogar das Lesen und Schreiben aller Daten. Erlischt die Gültigkeit des Access-Token nach der eingestellten Zeitspanne, schickt die Applikation den Refresh-Token zurück an Google und erhält postwendend einen neuen Access-Token, falls der User der Applikation noch nicht den Google-Zugriff entzogen hat.
Auf der API-Console [6] meldet der Programmierer Applikationen an, die nach Zugriff auf die zahlreichen Google-APIs trachten. Für Google Drive ist der Schalter »Google Drive API« umzulegen, der für das darunter stehende Google-Drive-SDK bleibt auf »off« (Abbildung 6). Nach dem Akzeptieren der Nutzungsbedingungen erscheinen zwei Schlüssel als Hex-Strings: die Client-ID und das Client-Secret. Da beide fest im Client verdrahtet sind, handelt es sich bei Letzterem wohl kaum um ein Geheimnis. Skripte mit beiden Werten dürfen von den Google-API-Servern nun Request-Tokens verlangen, um User einzubinden.
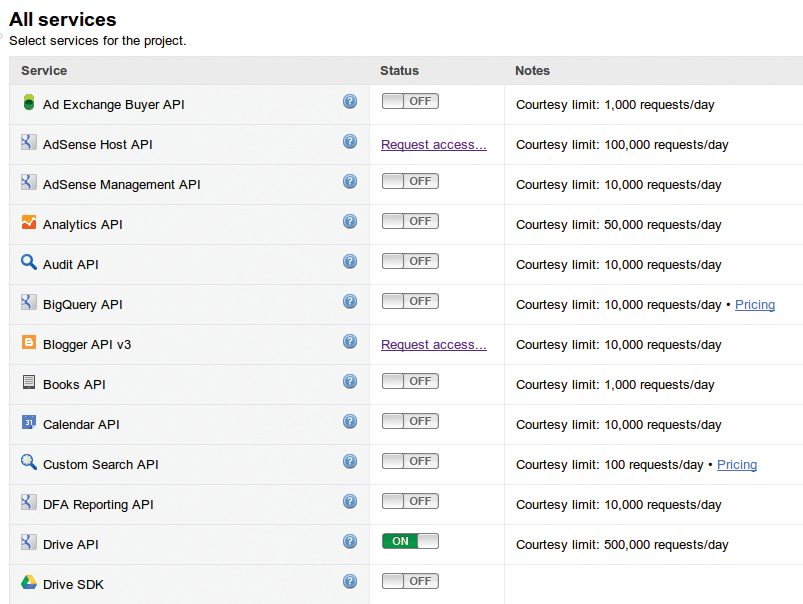
Abbildung 6: In diesem »All services«-Einstelldialog gilt es, für das Perl-Projekt das Google-Drive-API – nicht das SDK – anzuschalten.
Das Skript »google-drive-init« in Listing 1 startet einen Mojolicious-Server auf Port 8082 des lokalen Rechners, mit dem sich der Browser in Abbildung 7 verbindet. Mit diesem Verfahren hatte sich schon der Perl-Snapshot [7] anhand des Dropbox-API befasst. Es dient dazu, Google den Request-Token zu entlocken, denn beim später beschriebenen Datenabfrage-Skript handelt es sich nicht um eine Webapp. Darum muss es mit eingeweckten Web-Tokens vorlieb nehmen.
Klickt der User auf den dargestellten Link »Login on Google Drive« , springt der Browser zwecks User-Authentifizierung zu Google und fragt, ob er der Applikation »splitsync« , so der frei gewählte Name der Applikation, Zugriff auf sein Drive gewährt (Abbildung 8). Nach der Bestätigung schickt Google den Browser wieder zurück auf die Redirect-URL, in diesem Fall den Mojolicious-Server auf http://localhost:8082. Der speichert die ebenfalls übermittelten Access- und Refresh-Tokens in der Yaml-Datei »~/.google-drive.yml« und meldet den Erfolg mit »Token saved« .
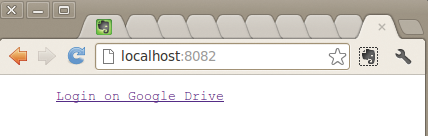
Abbildung 7: Zum Einloggen wendet sich der User an den Mojolicious-Server.
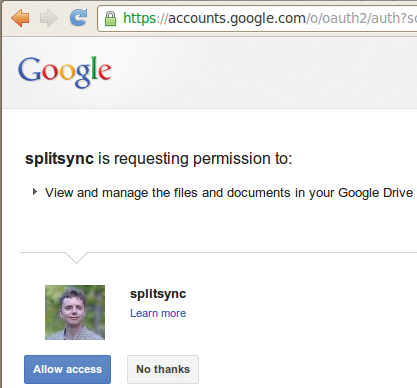
Abbildung 8: Google fragt seinen Benutzer, ob er der Perl-Applikation »splitsync« Zugriff auf seine Drive-Dateien einräumen will.
Skript als Webapp
Die bei der Projekt-Registrierung erhaltene Client-ID und das Client-Secret verdrahtet Listing 1 in den Zeilen 10 und 11. Als Scope gibt es »www.googleapis.com/auth/drive« an und verlangt demnach Schreib-Lese-Zugang zum Drive des Users. Entsprechende Rechte lässt sich Google in Abbildung 8 vom User einräumen.
Im Mojolicious-Testserver eingehende Browseranfragen unter dem Pfad »/« landen im Handler ab Zeile 34, der den Parameter »login_url« für das Template am unteren Rand des Skripts angibt. Später stellt der Browser einen Link darauf dar (Abbildung 7). Die Rücksprungadresse für Google nach getaner Arbeit auf dem Mojolicious-Server liegt wegen Zeile 18 unter dem Pfad »/callback« .
Der zugehörige, ab Zeile 44 definierte Handler schnappt sich den von Google gesendeten Parameter »code« und gibt ihn der Funktion »tokens_get()« ab Zeile 68. Sie schickt einen »POST()« -Request und das Accounts-API, packt die Client-ID und das Client-Secret bei und bekommt von Google einen Request- und einen Refresh-Token im Json-Format zurück. Vorsicht: Der Access-Token darf nicht in fremde Hände gelangen – zusammen mit dem Refresh-Token böte er Übeltätern zeitlich unbeschränkten Zugriff auf die persönliche Drive-Daten des Users!
Beide legt die Funktion zusammen mit deren Verfallsdatum und den Client-ID-Daten in der Yaml-Datei »~/.google-drive.yml« im Homeverzeichnis des Users ab, damit später Skripte wie das in Listing 2 mit den Drive-Daten des Users spielen dürfen. Da das Verfallsdatum des Request-Token als relativ zur aktuellen Uhrzeit verstrichene Sekunden eintrifft, addiert Zeile 59 die aktuelle Zeit in Sekunden seit 1970 und speichert den Zeitstempel unter dem Schlüssel »expires« . Später muss ein Skript nur prüfen, ob die aktuelle Sekundenzeit den Zeitstempel überschritten hat.
Listing 1
google-drive-init
001 #!/usr/local/bin/perl -w
002 use strict;
003 use Mojolicious::Lite;
004 use YAML qw( DumpFile );
005 use Log::Log4perl qw(:easy);
006 use HTTP::Request::Common;
007 use JSON qw( from_json );
008 use URI;
009
010 my $client_id = "XXX";
011 my $client_secret = "YYY";
012 my $scope =
013 "https://www.googleapis.com/auth/drive";
014 my $listen = "http://localhost:8082";
015 my($home) = glob '~';
016 my $CFG_FILE =
017 "$home/.google-drive.yml";
018 my $redir_uri = "$listen/callback";
019
020 my $login_uri = URI->new(
021 "https://accounts.google.com" .
022 "/o/oauth2/auth" );
023
024 $login_uri->query_form (
025 response_type => "code",
026 client_id => $client_id,
027 redirect_uri => $redir_uri,
028 scope => $scope,
029 );
030
031 @ARGV = (qw(daemon --listen), $listen);
032
033 ###########################################
034 get '/' => sub {
035 ###########################################
036 my ( $self ) = @_;
037
038 $self->stash->{login_url} =
039 $login_uri->as_string();
040
041 } => 'index';
042
043 ###########################################
044 get '/callback' => sub {
045 ###########################################
046 my ( $self ) = @_;
047
048 my $code = $self->param( "code" );
049
050 my( $access_token, $refresh_token,
051 $expires_in ) =
052 tokens_get( $self->param( "code" ) );
053
054 DumpFile $CFG_FILE, {
055 access_token => $access_token,
056 refresh_token => $refresh_token,
057 client_id => $client_id,
058 client_secret => $client_secret,
059 expires => time() + $expires_in,
060 code => $code
061 };
062
063 $self->render_text( "Tokens saved.",
064 layout => 'default' );
065 };
066
067 ###########################################
068 sub tokens_get {
069 ###########################################
070 my( $code ) = @_;
071
072 my $req = &HTTP::Request::Common::POST(
073 'https://accounts.google.com/o/' .
074 'oauth2/token',
075 [
076 code => $code,
077 client_id => $client_id,
078 client_secret => $client_secret,
079 redirect_uri => $redir_uri,
080 grant_type => 'authorization_code',
081 ]
082 );
083
084 my $ua = LWP::UserAgent->new();
085 my $resp = $ua->request($req);
086
087 if( $resp->is_success() ) {
088 my $data =
089 from_json( $resp->content() );
090
091 return ( $data->{ access_token },
092 $data->{ refresh_token },
093 $data->{ expires_in } );
094 }
095
096 warn $resp->status_line();
097 return undef;
098 }
099
100 app->start;
101
102 __DATA__
103 ###########################################
104 @@ index.html.ep
105 % layout 'default';
106 <a href="http://<%=%20$login_url%20%>"
107 >Login on Google Drive</a>
108
109 @@ layouts/default.html.ep
110 <!doctype html><html>
111 <head><title>Token Fetcher</title></head>
112 <body>
113 <pre>
114 <%== content %>
115 </pre>
116 </body>
117 </html>
Auf Daten orgeln
Listing 2 implementiert eine Applikation, die schaut, ob alle in einem lokalen Verzeichnis gespeicherten Dateien bereits auf Google Drive hochgespielt sind. Mit Hilfe des API schickt sie eine Anfrage an den Drive-API-Server unter dem URL-Pfad »/files« , der ein Listing aller unter dem Account des authentisierten Users liegenden Dateien anfordert. Das voreingestellte Maximum an Treffern liegt bei 100, der Parameter »MaxResults« in Zeile 27 setzt es auf 3000.
Liegt ein gültiger Request-Token vor, kommt von Google auf den »GET« -Request in Zeile 26 ein Json-String nach Art der Abbildung 9 zurück. Er zeigt alle auf dem Drive liegenden Dateien an, und zwar unabhängig davon, in welchem Verzeichnis sie gespeichert sind.
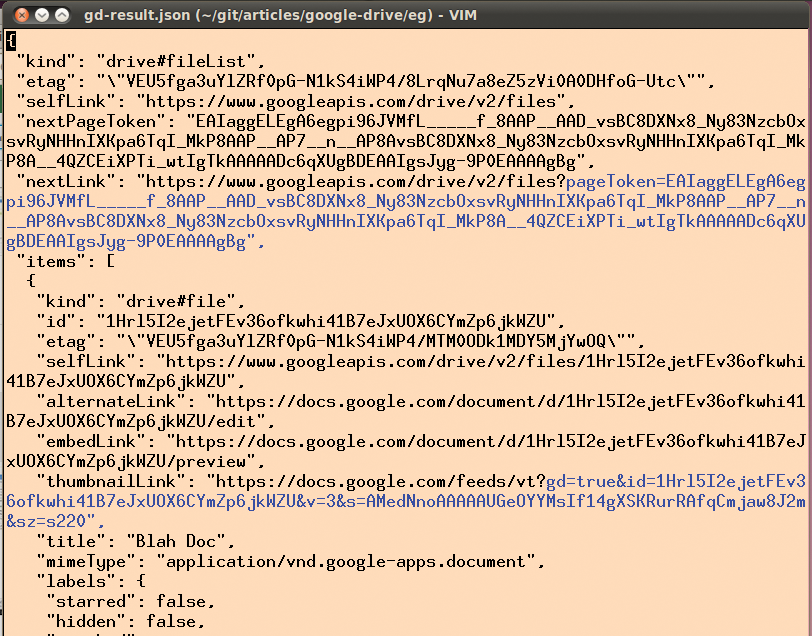
Abbildung 9: Die Json-Daten mit auf Google Drive gespeicherten Dokumenten, die das Google-API auf eine Datei-Listing-Anfrage zurückschickt.
Zeile 44 prüft, ob der Parameter »kind« auf »drive#file« gesetzt ist, und Zeile 45 extrahiert den Wert von »originalFilename« , den Namen der hochgeladenen Datei. Jeden Treffer speichert der Hash »%books_remote« , damit die For-Schleife ab Zeile 51, die über alle lokal im vorgegebenen Verzeichnis »~/books« gefundenen Bücher läuft, blitzschnell feststellen kann, welche Bücher noch nicht gesichert sind.
Ist der in der Yaml-Datei gesicherte Access-Token abgelaufen, weil seit dem Lauf von »google-drive-init« mehr als eine Stunde vergangen ist, holt die Funktion »token_refresh()« ab Zeile 58 einen frischen Access-Token vom Server. Sie benötigt außer dem Refresh-Token nur noch die Clientdaten, verlangt also dem Benutzer keine weiteren Eingaben ab. Dieser könnte weitere Token-Auffrischer eigentlich nur verhindern, indem er auf Google der Applikation »splitsync« die Rechte hierzu entzieht.
Listing 2
google-drive-check
01 #!/usr/local/bin/perl -w
02 use strict;
03 use LWP::UserAgent;
04 use HTTP::Request;
05 use HTTP::Headers;
06 use HTTP::Request::Common;
07 use File::Basename;
08 use YAML qw( LoadFile DumpFile );
09 use JSON qw( from_json );
10
11 my( $home ) = glob "~";
12 my $cfg_file = "$home/.google-drive.yml";
13 my $syncdir = "$home/books";
14 my @books_local =
15 map { basename $_ } <$syncdir/*.pdf>;
16
17 my $cfg = LoadFile $cfg_file;
18
19 if( $cfg->{ expires } - 60 < time() ) {
20 warn "Token needs to be refreshed.";
21 token_refresh( $cfg );
22 DumpFile( $cfg_file, $cfg );
23 }
24
25 my $req = HTTP::Request->new(
26 GET => 'https://www.googleapis.com/' .
27 'drive/v2/files?maxResults=3000',
28 HTTP::Headers->new( Authorization =>
29 "Bearer " . $cfg->{ access_token })
30 )
31
32 my $ua = LWP::UserAgent->new();
33 my $resp = $ua->request( $req );
34
35 if( ! $resp->is_success() ) {
36 die $resp->message();
37 }
38
39 my $data = from_json( $resp->content() );
40
41 my %books_remote = ();
42
43 for my $item ( @{ $data->{ items } } ) {
44 if( $item->{ kind } eq "drive#file" ) {
45 my $file = $item->{ originalFilename };
46 next if !defined $file;
47 $books_remote{ $file } = 1;
48 }
49 }
50
51 for my $book ( @books_local ) {
52 if( !exists $books_remote{ $book } ) {
53 print "Book not saved yet: [$book]\n";
54 }
55 }
56
57 ###########################################
58 sub token_refresh {
59 ###########################################
60 my( $cfg ) = @_;
61
62 my $req = &HTTP::Request::Common::POST(
63 'https://accounts.google.com/o' .
64 '/oauth2/token',
65 [
66 refresh_token =>
67 $cfg->{ refresh_token },
68 client_id =>
69 $cfg->{ client_id },
70 client_secret =>
71 $cfg->{ client_secret },
72 grant_type => 'refresh_token',
73 ]
74 );
75
76 my $ua = LWP::UserAgent->new();
77 my $resp = $ua->request($req);
78
79 if ( $resp->is_success() ) {
80 my $data =
81 from_json( $resp->content() );
82 $cfg->{ access_token } =
83 $data->{ access_token };
84 $cfg->{ expires } =
85 time() + $data->{ expires_in };
86 return 1;
87 }
88
89 warn $resp->status_line();
90 return undef;
91 }
Eine Extrawurst für dicke Dateien
Ein schöner Nebeneffekt der Datenspeicherung auf Google Drive ist, dass Google den Inhalt der Dateien indiziert und eine Volltextsuche darauf erlaubt. Mit 200-MByte-Monsterdateien geht dies allerdings schief. Als weiteres Testprojekt habe ich deshalb ein Skript geschrieben, das die PDF-Dateien an Seitengrenzen in Einzelstücke von etwa 10 MByte Größe aufteilt. Das unter [1] ebenso wie die Listings 1 und 2 zum Download bereitstehende Skript beschleunigt nicht nur das Herunterladen bestimmter Buchteile, sondern wirft auch Googles Indizierungsmechanismus an, sodass nun, wie in Abbildung 10 ersichtlich, eine Suche nach “Heuschnupfen” tatsächlich Treffer im ebenfalls eingescannten “Medizinischen Hausbuch” liefert.
Das Drive-API erlaubt es Experimentierfreudigen, sehr funktionale Applikationen zu entwickeln, denn auch Uploads und Downloads von Dateien oder das Verschieben in Ordner sind möglich. Vielleicht legt ja eine Linux-Programmiererin oder ein -Programmierer einen richtigen Google-Drive-Client vor – noch bevor der Konzern in die Hufe kommt? (jk)
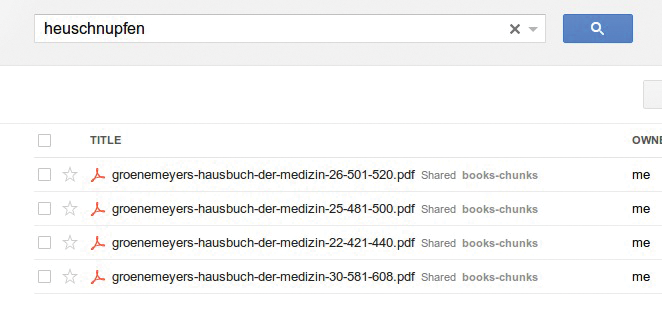
Abbildung 10: Volltextsuche auf den PDF-Dateien im Google-Drive.
Online PLUS
In einem Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/plus/2012/12
Infos
- Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2012/12/Perl
- Google Drive: http://drive.google.com
- Goodreader: http://www.goodiware.com/goodreader.html
- Ez PDF: https://play.google.com/store/apps/details?id=udk.android.reader&hl=de
- “Integrate your app with Google Drive”: https://developers.google.com/drive/
- API-Console: https://code.google.com/apis/console#access
- Michael Schilli, “Ab in die Kiste”: Linux-Magazin 07/11, S. 102, https://www.linux-magazin.de/Heft-Abo/Ausgaben/2011/07/Perl-Snapshot
Der Autor

Michael Schilli arbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. In seinen seit 1997 erscheinenden Snapshots forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





