
© blas, Fotolia
Mikroformate zeichnen HTML-Seiten mit allgemein anerkannten Tags aus, zum Beispiel Verbindungen zu sozialen Netzwerken oder Geokoordinaten. Das erlaubt automatischen Auswertern, sie zu sammeln und grafisch aufzubereiten. Nützlich ist das zum Beispiel bei Geodaten zur Routenplanung.
Herbstzeit, Wanderzeit!Das warme Wetter Ende September bietet ideale Voraussetzungen, um zum Beispiel in die USA zu fliegen, einen der 58 Nationalparks aufzusuchen und Abenteuer zu erleben (Abbildung 1). Die Wikipedia-Seite “List of national parks of the United States” [2] listet die Parks in alphabetischer Reihenfolge auf, beschreibt die Hauptattraktionen und fügt außerdem im HTML-Text die geografische Breite und Länge als Geokoordinaten bei.
Damit nicht nur Websurfer der Wikipedia-Seite an diese Daten herankommen, sondern auch automatisch ablaufende Applikationen, haben sich so genannte Mikroformate eingebürgert [3]. Denn traditionellerweise kodiert HTML-Markup ja nicht semantische Informationen, sondern konzentriert sich hauptsächlich auf die Darstellung. Steht zum Beispiel auf einer Webseite die Adresse einer Firma, sind Name, Straße, Ort und Telefonnummer oft nur durch Zeilenumbrüche getrennt. Suchmaschinen müssen dann erraten, ob es sich überhaupt um eine Adresse handelt, und anschließend die einzelnen Bestandteile herausfieseln.

Abbildung 1: Der Autor mit Büffel auf freier Wildbahn im Yellowstone-Nationalpark.
Ordnung schaffen
Das in Abbildung 2 gezeigte HTML-Snippet des Tabelleneintrags für den Nationalpark Bryce Canyon auf der genannten Wikipedia-Seite definiert ein Tag »span« der Klasse »vcard« , einer so genannten Root-Klasse, die eine Instanz des Mikroformats »hCard« ausweist [4]. Weiter unten, tief verschachtelt in der Vcard-Struktur, findet sich die Klasse »fn org« , die den Namen »name, formatted/full« der beschriebenen Firma oder Organisation angibt. In diesem Fall ist das Bryce Canyon, der Name des Nationalparks. Vier Zeilen weiter oben steht die Klasse »geo« , die die geografische Breite und Länge eines zentralen Punkts im Park mit »37.57« und »-112.18« angibt.
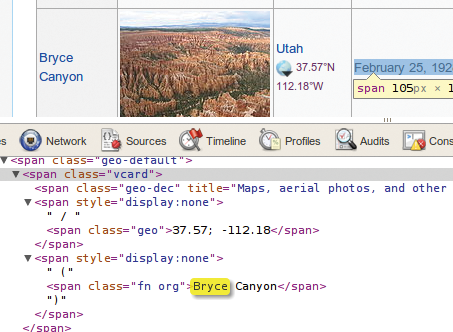
Abbildung 2: Der HTML-Code für die Wikipedia-Seite des Bryce-Canyon enthält auch die geografische Länge und Breite des Standorts. Diese Angaben lassen sich für eigene, automatisch generierte Karten nutzen.
Diese Angaben mit einem HTML-Parser zu extrahieren ist nicht schwer. Kein Wunder, dass bereits Webapplikationen wie Microform.at bereitstehen. Sie nehmen URLs entgegen, holen die entsprechende Seite ein, extrahieren die semantischen Tags und liefern sie als XML zurück (Abbildung 3). Die angezeigte URL zum XML-Ergebnis wiederum kann der geneigte User dann – wie in [5] beschrieben – in das Suchfeld auf Google Maps plumpsen lassen. In Maps sieht er dann eine lange Textliste mit den Namen der Nationalparks. Klickt er auf einen Eintrag, erscheint auf der rechts daneben angezeigten Amerika-Karte eine Sprechblase, und zwar an der Stelle der Geokoordinaten des jeweiligen Parks.
Google versieht wegen der von Microform.at gewählten Style-Definitionen die Landkarte nicht mit digitalen Reißnägeln sämtlicher Parks. Wenn ein Tourist viele Parks in einem Bundesstaat abklappern möchte, wäre das jedoch hilfreich.
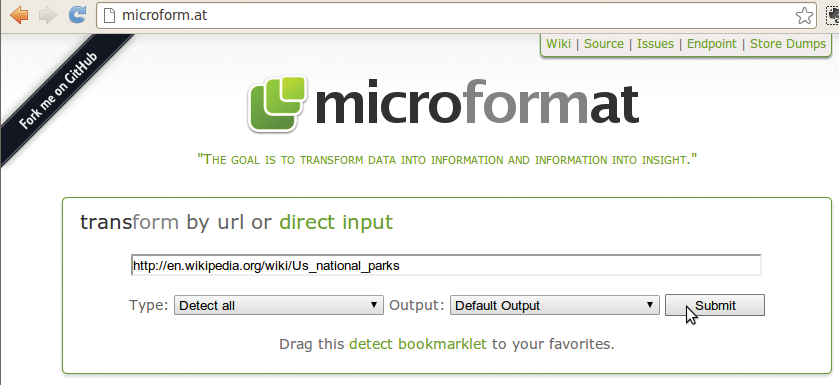
Abbildung 3: Die Webapplikation auf Microform.at nimmt die URL der Wikipedia-Seite entgegen, extrahiert die Microformat-Informationen und formatiert sie als XML.
Modischer Scraper
Zum Glück ist das Auslesen der Vcard-Informationen mit einem in Perl geschriebenen Webscraper nicht weiter schwierig. Wie immer folgt der Perl-Snapshot der neuesten Mode und wählt den modernen »Web::Scraper« vom CPAN. Der von dem Tool Scrapi aus der Ruby-Welt inspirierte Scraper nutzt eine Domain Specific Language (DSL), um in die Tiefen der HTML-Tags vorzudringen und deren Inhalt schön formatiert in Perl-Strukturen zurückzuliefern.
Das CGI-Skript in Listing 1 setzt in Zeile 16 die URL der einzuholenden Wikipedia-Webseite mit den Nationalparks. Der ab Zeile 19 definierte Scraper sucht mit dem Funktionsaufruf »process()« zunächst nach allen »span« -Tags mit dem Attribut »vcard« und legt sie wegen des Parameters »vcard[]« in einem Array innerhalb des Ergebnis-Hash ab.
Wird der Scraper fündig, definiert der erneute, verschachtelte Aufruf ab Zeile 21 einen weiteren Scraper in den Tiefen der Vcard-Struktur. Dieser sucht wegen des Aufrufs »process ‘.geo’« nach den Tags mit dem Attribut »class=geo« aus Abbildung 2 und extrahiert wegen des Parameters »TEXT« deren Textinhalt, also im Beispiel die Geodaten 37,57 und -112,18. Dann legt er den Textinhalt im Array-Eintrag des Nationalparks unter dem Schlüssel »geo« ab.
Listing 1
parks-scraper
01 #!/usr/bin/perl -w
02 use strict;
03 use Web::Scraper;
04 use URI;
05 use Template;
06 use CGI qw( :all );
07
08 print header(
09 -type =>
10 'application/vnd.google-earth.kml+xml',
11 -content_location => 'microformat.kml',
12 -access_control_allow_origin => '*',
13 -expires => '-1d',
14 );
15
16 my $url = "http://en.wikipedia.org/wiki/ .
17 "Us_national_parks";
18
19 my $coords = scraper {
20 process 'span.vcard', 'vcards[]' =>
21 scraper {
22 process '.geo', geo => 'TEXT';
23 process '.org', name => 'TEXT';
24 }
25 };
26
27 my $res = $coords->scrape(
28 URI->new( $url ) );
29
30 my @parks = ();
31
32 for my $vcard ( @{ $res->{ vcards } } ) {
33 next unless exists $vcard->{ geo };
34 my( $lon, $lat ) =
35 split /\s*;\s*/, $vcard->{ geo };
36 push @parks, { name => $vcard->{ name },
37 lat => $lat,
38 lon => $lon };
39 }
40
41 my $tmpl = Template->new();
42 my $data = join( '', <DATA> );
43
44 binmode STDOUT, ":utf8";
45
46 $tmpl->process( \$data, { parks =>
47 \@parks } ) || die $tmpl->error();
48
49 __DATA__
50 <?xml version="1.0" encoding="UTF-8"?>
51 <kml
52 xmlns="http://earth.google.com/kml/2.0">
53 <Folder>
54 <name>US National Parks</name>
55 [% FOR park IN parks %]
56 <Placemark>
57 <name>[% park.name %]</name>
58 <Point>
59 <coordinates>
60 [% park.lat %], [% park.lon %], 0
61 </coordinates>
62 </Point>
63 </Placemark>
64 [% END %]
65 </Folder>
66 </kml>
Daten herausfieseln
Ähnlich verfährt der Scraper mit den Microformat-Einträgen des Formats »fn org« aus Abbildung 2, die den Namen des gewünschten Nationalparks enthalten. Mit der Anweisung »’.org’« findet der Aufruf »process« in Zeile 23 die Tags und fieselt aufgrund des »TEXT« -Parameters den als Klartext im Tag stehenden Parknamen heraus. Dann legt er ihn unter »name« in der Ergebnisstruktur ab.
Die For-Schleife ab Zeile 32 braucht jetzt nur noch alle abgelegten Vcard-Einträge durchzurattern, um zu prüfen, ob sich dort eine »geo« -Klasse findet. Falls ja, splittet Zeile 35 die Geodaten-Information am trennenden Semikolon in die geografische Länge und Breite. Die Länge wandert in die Variable »$lon« , die Breite in »$lat« . Zusammen mit dem Namen des Parks unter dem Schlüssel »name« hängt Zeile 36 die extrahierten Werte als weiteren Eintrag im Array »@parks« an.
XML mit Template gestalten
Zur Formatierung der Daten in XML nutzt Listing 1 die Template-Engine »Template« vom CPAN sowie das ab der »DATA« -Anweisung in Zeile 49 folgende XML-Rohgerüst am Ende des Skripts. Dieses erhält in Zeile 46 mit dem Methodenaufruf »process()« den Array mit den Parkdaten unter dem Schlüssel »parks« in einem Hash. In Zeile 55 definiert das Template mit »[% FOR … %]« eine For-Schleife bis zur Markierung »[% END %]« in Zeile 64, iteriert über die Daten aller Parks und gibt für jeden Park eine XML-Struktur namens »Placemark« aus.
Während der Name eines Parks in die Tags »name« eingeschlossen ist, finden sich die Koordinaten in der Struktur »Point« , die ihrerseits die Tags »coordinates« mit den Geodaten enthalten. Die Koordinaten liegen dort als vorzeichenbehaftete geografische Breite, Länge und Höhe über dem Meeresspiegel vor. Letzterer Wert steht nicht auf der Wikipedia-Seite. Deshalb setzt ihn das Skript auf 0, was bei der später verwendeten zweidimensionalen Google-Maps-Darstellung nicht weiter auffällt.
Alle Placemarks finden in einem Container mit dem Namen »Folder« Platz. Zeile 52 zeigt an, dass es sich um XML-Daten im Google-Earth-Format handelt, die Google Maps später klaglos akzeptieren und anzeigen wird. Wichtig ist noch der »binmode« -Aufruf in Zeile 44, der die Standardausgabe des Skripts auf UTF-8 umstellt. Entsprechend kodiert liegen die Werte der in das Template einzufügenden Variablen schließlich vor. Das ausgespuckte XML sollte ebenfalls in Unicode erscheinen, denn auch die erste Zeile im XML-Template im »DATA« -Bereich legt als Encoding UTF-8 fest.
Arbeit am Header
Da es sich bei dem Park-Scraper aus Listing 1 um ein später auf einem Webserver aufgerufenes CGI-Skript handelt, gibt es vor dem Ergebnis-XML einige HTTP-Header aus. Abbildung 4 zeigt die Reaktion des Skripts, wenn man »parks-scraper« von der Kommandozeile aus startet. Als Typ legen die Zeilen 9 und 10 das Google-Earth-Format fest, gefolgt vom Header »Content-location« mit dem Namen einer Pseudodatei, die Google Maps anscheinend benötigt. Zur späteren Nutzung auf Google Maps ist es ratsam, »Access-control-allow-origin« auf »*« zu setzen, damit der Browser nicht die Kommunikation zwischen XML-Lieferant und Google-Maps wegen der Same-Origin-Policy unterbindet.
Der Expire-Header in Zeile 13 steht mit »-1d« auf dem gestrigen Tag. Das bewirkt, dass Google Maps später jedes Mal frische Ergebnisse vom Geodaten-Lieferanten abholt, statt sie nur zu cachen. Das ist insbesondere in der Debugging-Phase des Skripts wichtig.
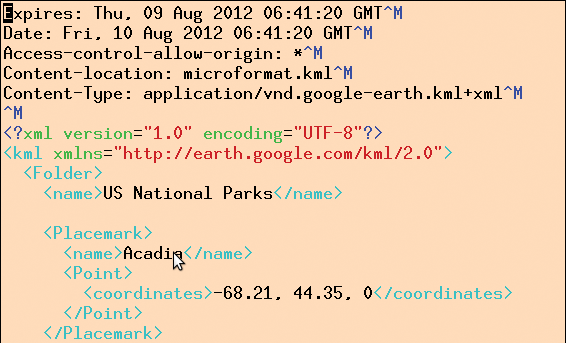
Abbildung 4: Das CGI-Skript extrahiert die Geodaten aus der Wikipedia-Seite und spuckt sie als XML aus.
Einpflanzen in Google Maps
Läuft das Skript dann endlich auf einem öffentlich zugänglichen Webserver – oder auch auf dem im letzten Perl-Snapshot vorgestellten Service auf Heroku.com [6] – pflanzt der Wanderfreund die URL ins Suchfeld von Google Maps ein. So erhält er auf der Landkarte für jeden Park einen digitalen Reißnagel (Abbildung 5).
Hinter den Kulissen springt Google Maps auf das in diesem Beispiel auf Perlmeister.com hinterlegte CGI-Skript an. Es holt die Wikipedia-Seite mit den Nationalparks, wirft den Scraper an, extrahiert die Geodaten und gibt sie als XML zurück. Google Maps wiederum analysiert das XML-Format, holt die Geodaten hervor, ermittelt die Positionen der Reißnägel auf der Landkarte und stellt sie dar.
Wanderlustige rücken den Daten im nächsten Schritt auf Wunsch mit künstlicher Intelligenz zu Leibe [7]. So ließe sich zum Beispiel herausfinden, in welcher Gegend der USA die meisten Nationalparks liegen. Oder vielleicht lassen sich ja mit fünf Inlandsflügen 70 Prozent aller Nationalparks abdecken, wenn man den Aktionsradius richtig wählt und die Parks in Cluster zusammenfasst? Vielleicht wird das Gegenstand eines künftigen Snapshots. (ake)
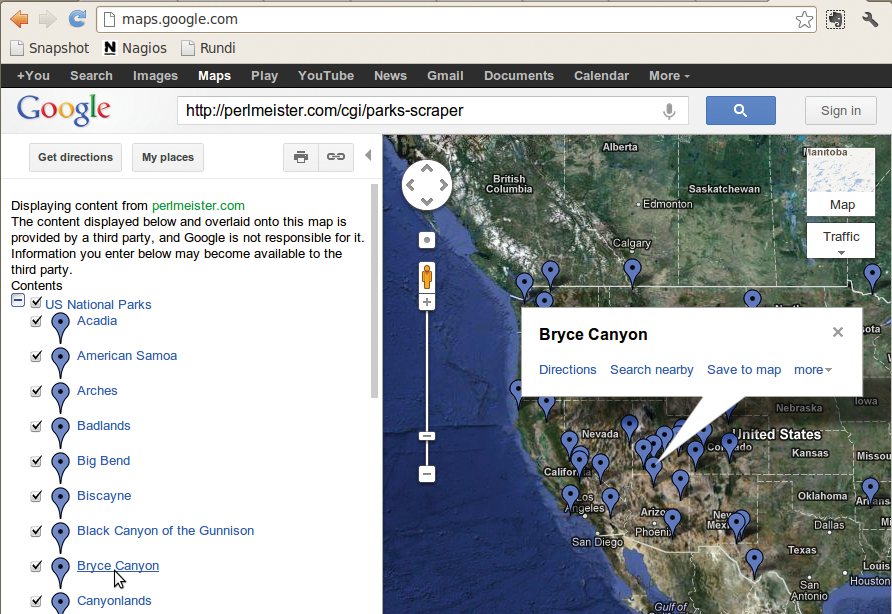
Abbildung 5: Ergebnis: Der Park-Scraper beliefert Google Maps mit Koordinaten für die Nationalparks.
Infos
- Listings zu diesem Artikel:ftp://www.linux-magazin.de/pub/listings/magazin/2012/10/Perl
- Wikipedia-Eintrag zu den US-Nationalparks: http://en.wikipedia.org/wiki/Us_national_parks
- Andreas Möller, “Datenhäppchen”: Linux-Magazin 03/12, S. 82
- Mikroformat “hCard 1.0”:http://microformats.org/wiki/hcard
- Matthew A. Russell, “Mining the Social Web”: O’Reilly 2011
- Michael Schilli, “Einfach abheben”: Linux-Magazin 09/12, S. 96
- Drew Conway, John Myles White, “Machine Learning for Hackers”: O’Reilly 2012
Der Autor

Michael Schilli arbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. In seinen seit 1997 erscheinenden Snapshots forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





