
© HONGQI ZHANG, 123RF.com
Obwohl Entwickler in aller Welt Milliarden von Zeilen an Open-Source-Code geschrieben haben, gab es bislang kaum Untersuchungen darüber, warum, wie viel und mit welchem Ergebis freie Projekte den Quellcode anderer wiederverwenden. Jetzt liegen belastbare Zahlen vor.
Anders als hierarchisch arbeitende Softwarefirmen, die Quellcode nach dem von Eric S. Raymond so bezeichneten Kathedralen-Modell [1] entwickeln und das Urheberrecht nutzen, um Wettbewerbern ihren Code vorzuenthalten, tragen echte Open-Source-Projekte und -Firmen ihre Quellcodes in die Öffentlichkeit – in aller Regel von Anfang an. Sie tun dies in vielen iterativen Schritten unter Beteiligung der Benutzer (RERO: “Release early, release often”).
Raymond sieht in seinem Essay die Open-Source-Entwicklung idealtypisch in der Art eines Basars, auf dem Händler (Programmierer) gleichberechtigt ihre Waren (Code) feilbieten. Andere Entwickler integrieren nach eigenem Ermessen diesen Code in eigene Projekte. Jeder Programmierer darf und soll neue Programmteile hinzufügen oder an einem Stand gefundenen Code verbessern.
Mit dem offenkundigen Erfolg des Basar-Modells in der Praxis wuchs das wissenschaftliche Interesse, genauer zu verstehen, auf welche Weise öffentlich arbeitende Open-Source-Projekte entwickeln und worin sie der klassischen industriellen Software-Entwicklung möglicherweise über- oder unterlegen sind.
Bislang standen hierbei vor allem Fragen hinsichtlich der Qualität (zum Beispiel [2]) und der Sicherheit (zum Beispiel [3]) der entwickelten Software sowie nach der Veröffentlichungsmotivation von Firmen (beispielsweise [4]) oder einzelner Entwickler (wie in [5]) im Vordergrund.
Weiße Flecken auf der Landkarte
Die Code-Wiederverwendung (Reusing) in öffentlich arbeitenden Open-Source-Projekten ist bislang wenig untersucht (etwa [6]), obwohl dieses Thema in der kommerziellen Software-Entwicklung zentral ist, um Software von hoher Qualität wirtschaftlich zu entwickeln. Einerseits könnte man erwarten, dass Entwickler, die aufgrund der Lizenzsituation ihres eigenen Projekts keine Lizenzverletzung beim Wiederverwenden von Code aus anderen Open-Source-Projekten fürchten müssen, sich so viel wie möglich aus dem Baukasten der existierenden Open-Source-Code-Basen bedienen.
Andererseits lässt sich aus den Erfahrungen beim Code-Wiederverwerten in Firmen auch schließen, dass das Thema nicht zum Selbstläufer taugt: So erweist sich für Code wiederverwertende Firmen etwa ein gut gepflegtes Repository als unabdingbar, um den erneut verwendbaren Code einfach identifizieren zu können. Derart ausgerichtete Repositories scheinen jedoch bei Open-Source-Projekten untypisch zu sein.
Nicht technische, sondern organisatorische Voraussetzungen für erfolgreiche Code-Wiederverwendung in Firmen sind explizite Anreizstrukturen, die Entwickler dazu anhalten, leicht wiederverwendbaren Code zu schreiben und ihn entsprechend umfangreich zu dokumentieren. Ein anderes Beispiel sind Budgets, welche die Entwicklung von wiederverwendbaren Komponenten vorfinanzieren. Die lassen sich später über Projekte abzahlen, die sich die entwickelten Komponenten zu Nutze machen.
Da jener firmentypische organisatorische Kontext freien Projekten fehlt, stellt sich die Frage, wie bedeutsam wiederverwendeter Code in diesen Projekten tatsächlich ist und wie die Aneignung geschieht. Dieser Artikel beantwortet diese Fragen mit Daten aus einer im Sommer 2009 durchgeführten Umfrage unter Open-Source-Entwicklern. Als Ausgangspunkt für die Suche nach relevanten Programmierern diente Sourceforge als die vielleicht wichtigste Open-Source-Entwicklungsplattform. Über die Community-Funktionen von Sourceforge wurden Entwickler zufällig ausgewählt und mit der Bitte kontaktiert, an der Umfrage teilzunehmen.
Für die Umfrage selbst kam Lime Survey [7] als Onlinefragebogen zum Einsatz, die mehrheitlich geschlossen gestellten Fragen waren über Likert-Skalen [8] implementiert. Innerhalb der gesetzten Frist kamen 632 Entwickler der Bitte nach. Informationen zur Demographie der Umfrageteilnehmer, Details zum Ablauf der Umfrage wie auch der verwendete Fragebogen sind in [9] veröffentlicht.
Beliebter Code
Erstes wichtiges Ergebnis: Code-Wiederverwendung besitzt trotz der dargestellten Hindernisse für die Arbeit der befragten Open-Source-Entwickler eine hohe Bedeutung: Auf einer siebenstufigen Likert-Skala (“Stimme überhaupt nicht zu” bis “Stimme stark zu”) erhalten Statements, die erneut verwerteten Code als sehr wichtig für ihre Arbeit beschreiben – beispielsweise “War für meine Arbeit an diesem Projekt sehr relevant” – im Durchschnitt eine 5, gleichbedeutend mit “Stimme eher zu”.
Dazu passend beruht durchschnittlich 30 Prozent der Funktionalität der Projekte der befragten Entwickler auf wiederverwendetem Code, der Median liegt bei 20 Prozent. Nur 6 Prozent der Entwickler gaben an, dass sie in ihrem Projekt komplett auf wiederverwendeten Code verzichtet haben, während bei knapp 30 Prozent mehr als die Hälfte der Funktionalität ihres Projekts auf wiederverwendetem Code fußt (siehe Abbildung 1).
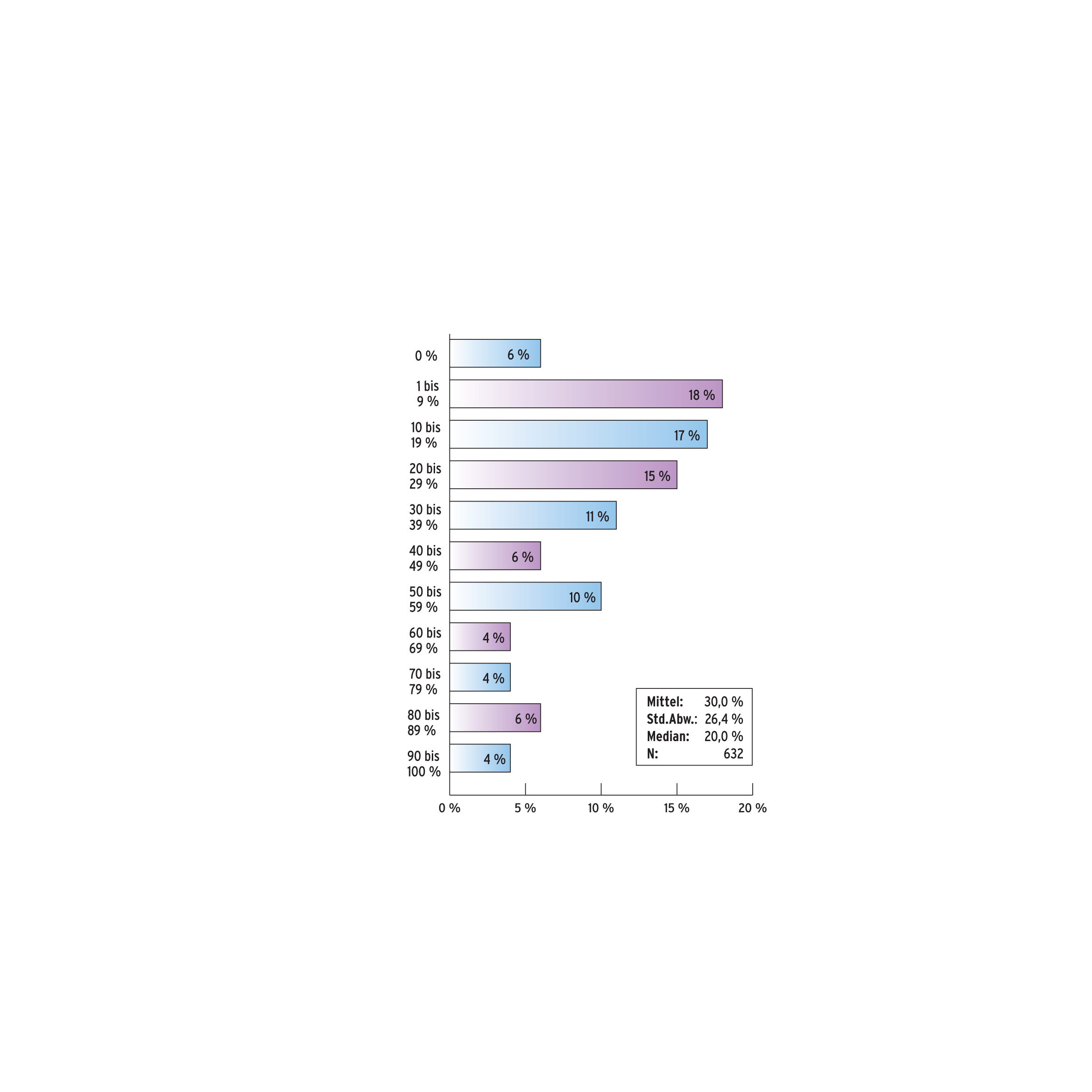
Abbildung 1: Bei welchem Prozentsatz der Entwickler (x-Achse) macht wiederverwendeter Code welchen Anteil an der Projektfunktionalität aus (y-Achse)?
Code-Arten
Code-Reusing findet meist in Form von Komponenten beziehungsweise Snippets statt. Komponenten sind gekapselte Codeblöcke, die jemand in der Regel dediziert für die Wiederverwendung entwickelt hat und die über dokumentierte Schnittstellen ihre Funktionalität bereitstellen – idealtypische Komponenten sind Funktionsbibliotheken.
Im Gegensatz dazu sind Snippets einige Zeilen bis mehrere Hundert Zeilen lange Fragmente bereits existierenden Codes, die der Entwickler in die eigene Software kopiert und falls nötig anpasst. Im Durchschnitt verwenden die befragten Entwickler 5,6 Komponenten in ihren Projekten. Aufgrund der rechtsschiefen Verteilung (siehe Abbildung 2) liegt der Median jedoch bei nur 2 Komponenten. Einer aus fünf Entwicklern verzichtet gänzlich auf wiederverwendete Komponenten, während fast jeder zehnte mehr als 10 Komponenten recycelt.
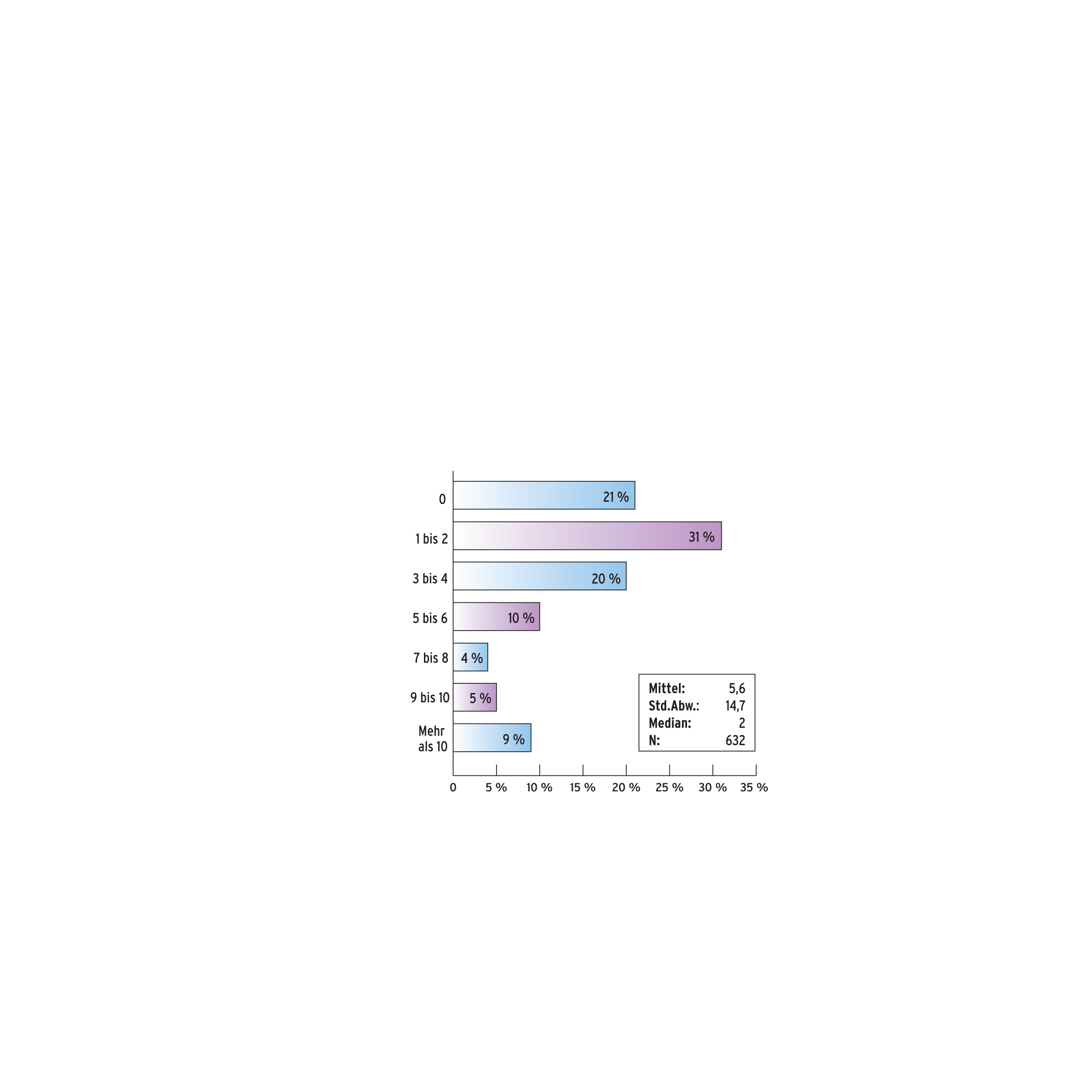
Abbildung 2: Welcher Prozentsatz der Entwickler (x-Achse) verwendet wie viele fremde Komponenten (y-Achse)?
Die von den befragten Entwicklern am häufigsten verwendeten Komponenten implementieren sehr generische, grundlegende Funktionen, die sie nur mit hohem Aufwand in vergleichbarer Qualität hätten selbst entwickeln können (zum Beispiel Apache Commons, Apache Log4j, Qt).
Zirka die Hälfte der Entwickler, die fremde Komponenten übernehmen, integrieren diese unmodifiziert und sichern sich damit die Möglichkeit, von zukünftigen Aktualisierungen der Komponenten leicht zu profitieren. Besonders häufig verfolgen jene Entwickler diese Strategie, die mit objektorientierten Sprachen wie C++ oder Java programmieren.
Wie bei den Komponenten erweist sich auch die Verteilung wiederverwendeter Snippets als rechtsschief (siehe Abbildung 3): Im Durchschnitt bestanden knapp 10 Prozent der Codezeilen, die ein Entwickler bei seinem Projekt verantwortet, aus wiederverwendeten Snippets. Der Median liegt allerdings nur bei 5 Prozent und fast ein Viertel der befragten Entwickler verzichtet gänzlich auf fremde Codestücke. Wie zu erwarten, mussten die Befragten Snippets fast immer modifizieren, während sie diese mit eigenem Code verschmolzen. Zirka ein Drittel der Entwickler beschränkt sich hierbei auf kleinere Modifikationen, etwa das Umbenennen von Variablen, während die restlichen die nachgenutzten Snippets umfangreich abändern.
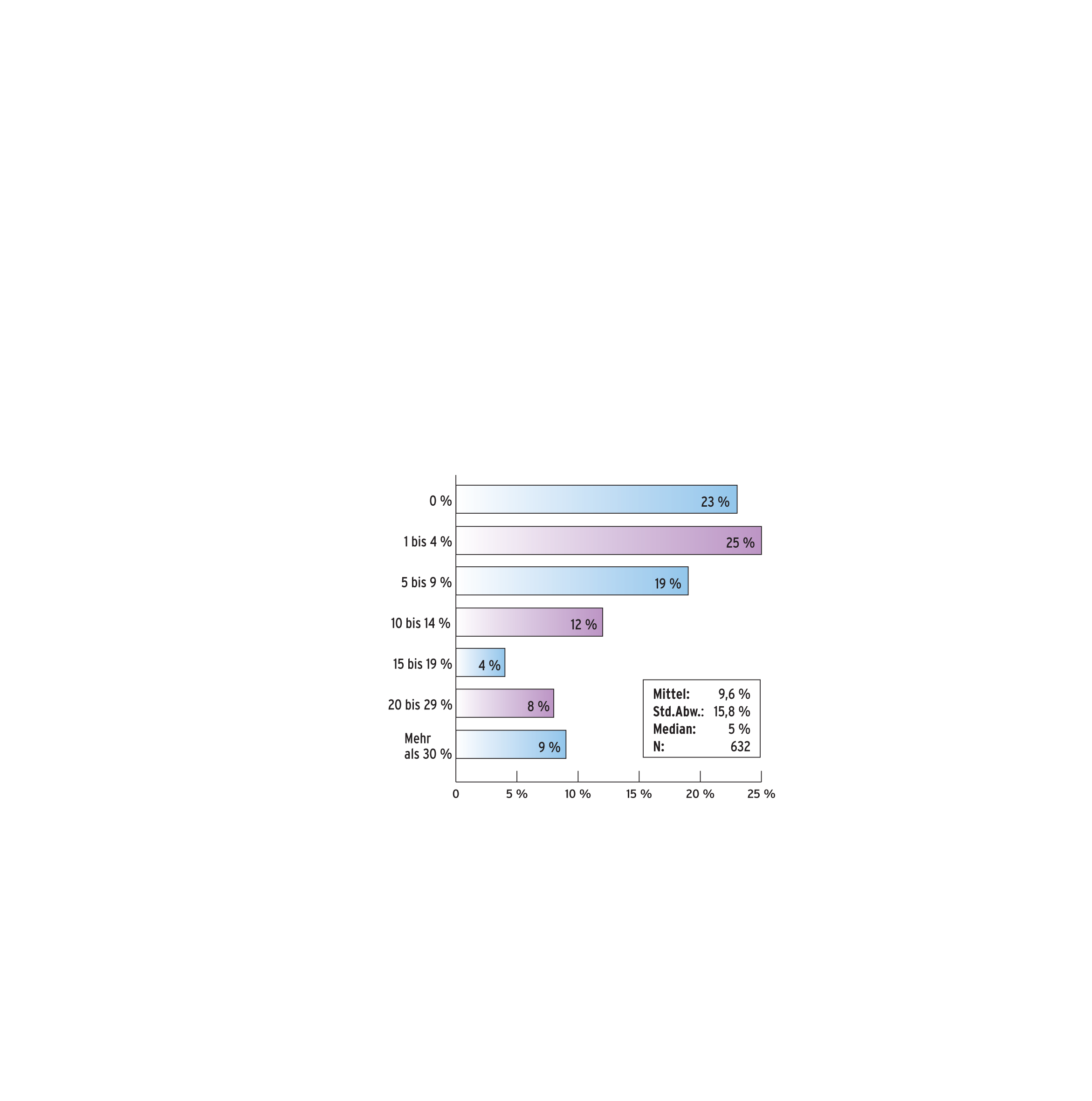
Abbildung 3: Bei welchem Prozentsatz der Entwickler (x-Achse) machen Snippets welchen Prozentsatz der Codezeilen des Gesamtprojekts aus (y-Achse)?
Entwickler arbeiten ähnlich
Die Ergebnisse sind über verschiedene Projektkategorien und Entwicklertypen relativ stabil. So verwenden Entwickler, die beruflich an ihren Projekten arbeiten, nur geringfügig mehr fremden Code als reine Hobbyentwickler. Auch zwischen Projekten, die sich gängigen, aber unterschiedlichen Open-Source-Lizenzen unterworfen haben, bleiben die Unterschiede gering. Bei der Differenzierung nach Programmiersprachen praktizieren objektorientiert arbeitende Entwickler geringfügig mehr Code-Wiederverwendung als andere. Dabei offenbart sich, dass diese Gruppe Komponenten besonders intensiv erneut nutzt, während sie Snippets eher verschmäht.
Strukturen und Prozesse
Interessanterweise besitzen trotz der beschriebenen hohen Bedeutung von Code-Wiederverwendung in den meisten Projekten die befragten Entwickler keine formalen Strukturen passend zum Thema: Zirka ein Drittel der Entwickler gibt sogar an, innerhalb des Projektteams noch nie über Code-Reusing diskutiert zu haben. Von den anderen zwei Dritteln ist nur eine sehr kleine Minderheit in Projekten aktiv, die dafür über formale Richtlinien verfügen.
Für eine Mehrheit der Befragten existiert lediglich ein gemeinsames Verständnis zur Basar-Praxis, das sich im Laufe der Projektarbeit herauskristallisiert hat. Typischerweise spiegelt dieses Verständnis eine positive Haltung gegenüber der Code-Wiederverwendung wider. Nur einige wenige Entwickler sind in Projekten aktiv, deren Mitglieder explizit darauf achten, möglichst wenig fremden Code zu benutzen.
Obwohl dieser Konsens nur lose formuliert ist und in den meisten öffentlichen Open-Source-Projekten keine Autoritätsstrukturen wie in Firmen existieren, scheinen sich die Entwickler an die selbst gegebenen Regeln in Bezug auf den Code Dritter zu halten. So macht der Anteil wiederverwendeten Codes an der Gesamtfunktionalität bei Projekten, die versuchen Wiederverwendung zu vermeiden, zirka 20 Prozent aus, während er bei solchen, die sie forcieren möchten, 40 Prozent beträgt.
Die erwarteten Hindernisse in öffentlichen Projekten scheinen praktisch kaum eine Rolle zu spielen: Obwohl keine strukturierten Wiederverwendungs-Repositories existieren, geben nur zirka 40 Prozent der Befragten an, dass sie in der Vergangenheit aufgrund mangelnder Verfügbarkeit von Code weniger wiederverwenden konnten, als sie eigentlich wollten. Lizenz-, Architektur- und Programmiersprachen-Inkompatibilitäten sind sogar von noch geringerer Bedeutung.
Obwohl nicht alle Open-Source-Lizenzen miteinander kompatibel sind – beispielsweise kann ein BSD-Projekt GPL-Code nicht ohne Weiteres integrieren –, fühlt sich dadurch nur knapp ein Viertel der Befragten in der Wiederverwendung eingeschränkt. Weniger als 20 Prozent sehen sich durch die Architektur ihres Projekts und weniger als 10 Prozent durch die Programmiersprache behindert.
Vor- und Nachteile
Hauptsächlich schätzen die Entwickler den Effizienzgewinn, den sie aus der Wiederverwendung ziehen. Jeweils mehr als 90 Prozent stimmten Aussagen zu, dass sie deshalb ihre Aufgaben schneller erledigen und ihre Ressourcen für projektzentrale Arbeiten aufwänden können. Neben der Effizienz sehen mehr als 80 Prozent der Programmierer eine höhere Effektivität; mit dem aufgegriffenen Code konnten sie Probleme lösen, für die sie selbst keine ausreichende Expertise besitzen.
Etwas nachrangig, aber zu immerhin über 70 Prozent, berichten Entwickler von positiven Qualitätseffekten, die sie aus der Code-Wiederverwendung zogen. Namentlich funktionierte die eigene Software verlässlicher und stabiler, außerdem wies sie eine höhere Kompatibilität mit bestehenden Standards auf. Den Effekt, dass die eigene Software sicherer wird, schätzen 57 Prozent der Befragten. Als letzte Vorteilsgruppe schließlich beschrieben zirka 60 Prozent die Code-Wiederverwendung als Möglichkeit, bestimmte Entwicklungsaufgaben wie die Codepflege auszulagern, um sich auf als interessanter eingeschätzte Themen zu konzentrieren.
Als überwiegend nachteilig empfindet die untersuchte Gruppe entstehende Abhängigkeiten: Rund 80 Prozent sehen ein Problem darin, auf Bugfixes anderer Projekte angewiesen zu sein. Aber auch technische Abhängigkeiten, die die Installation und Nutzung ihrer Software schwieriger machen, sehen zwischen 60 und 70 Prozent der Befragten kritisch. Mit 50 Prozent messen die Entwickler möglicherweise importierten Sicherheits- und Stabilitätsproblemen eine etwas geringere Bedeutung zu.
Quellen für wiederverwendbaren Code
Um abschließend zu untersuchen, über welche Kanäle Open-Source-Entwickler nach dem Code anderer suchen, sollten die befragten Entwickler auf einer fünfstufigen Skala (“nie” bis “immer”) angeben, in welcher Intensität sie verschiedene Quellen nutzen (Abbildung 4). Sowohl für Komponenten als auch für Snippets fielen interessanterweise am häufigsten die Namen allgemeiner Suchmaschinen, obwohl Google & Co. nicht für die Suche nach Code ausgelegt sind, beispielsweise keine speziellen Suchkriterien wie die Programmiersprache bereitstellen. Code-Suchmaschinen wie Koders.com hingegen rangieren unter ferner liefen.
Für Komponenten nannten die Entwickler als weitere wichtige Quellen Projekt-Repositories wie Sourceforge, ihre anderen Projekte, andere Entwickler, die sie mit Fragen ansprechen können, thematisch verwandte Open-Source-Projekte und auch Linux-Distributionen. Als Grabungsorte nach Snippets dienen ihnen neben den allgemeinen Suchmaschinen häufig Internetseiten mit Codebeispielen, die auch Erklärungen zu deren Verwendung liefern. Immer wieder nannten sie auch andere eigene Projekte, Kollegen, thematisch verwandte Open-Source-Projekte und -Repositories.
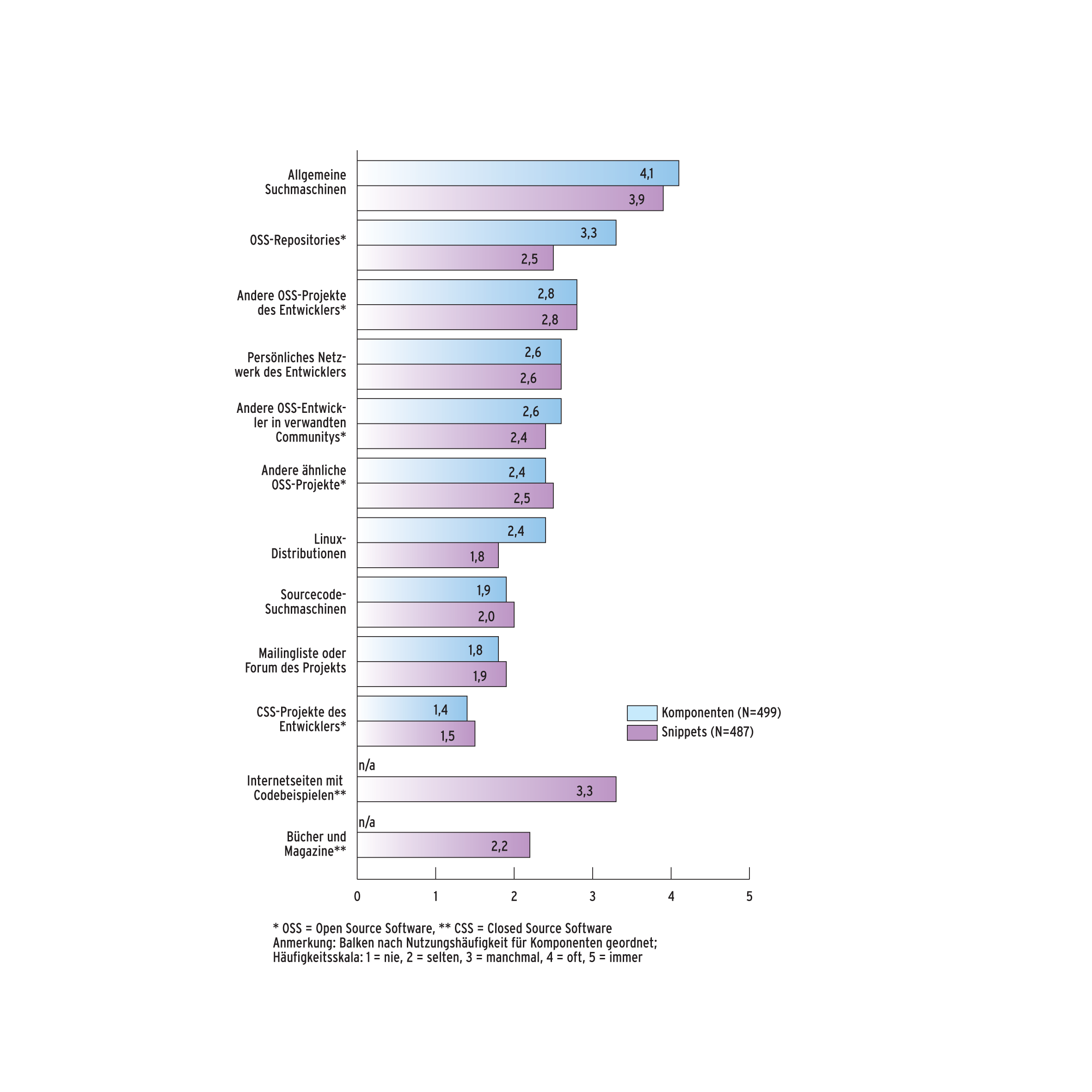
Abbildung 4: Die durchschnittliche Nutzungshäufigkeit einzelner Quellen für wiederverwendbaren Code.
Fazit und Folgerung
Öffentliche Open-Source-Projekte unterscheiden sich in ihren Prozessen, Tools und Anreizstrukturen von der klassischen Softwareproduktion in Firmen. Trotz der oft fehlenden Infrastruktur nutzen freie Entwickler in substanziellem Maße existierenden Code für ihre Arbeit, um damit in kürzerer Zeit Software von höherer Qualität zu schaffen. Ihre Motive sind dabei identisch zu denen im kommerziellen Kontext, allerdings logischerweise weniger ökonomischer Art, sondern folgen intrinsischen Zielen oder dem Zweck des Aufbaus einer Reputation innerhalb der Open-Source-Gemeinschaft.
Entwickler in öffentlichen Projekten verwenden sowohl Komponenten als auch Snippets anderer und machen sich die Code-Reusing-freundliche Struktur der Open-Source-Lizenzen zu Nutze. Als primäre Quelle dienen interessanterweise nicht spezialisierte Code-Suchmaschinen, sondern die allgemeinen, die offenbar einen guten Ersatz für die in Softwarefirmen gängigen Wiederverwendungs-Repositories darstellen.
Angesichts der hohen Recyclingquote von Open-Source-Code in öffentlichen Projekten sollten auch Firmen versuchen, bei ihren Entwicklungsaktivitäten die Wiederverwendung von Open-Source-Code zu maximieren. So können sie ihre Entwicklungskosten und -dauer senken und gleichzeitig die Codequalität erhöhen. Der Schlüssel dafür liegt in der lizenzgerechten Verwendung des technisch geeigneten Open-Source-Codes [10]. (jk)
Infos
- E. S. Raymond, “The Cathedral and the Bazaar”: O’Reilly & Associates, Sebastopol, CA, 2nd Edition, http://www.catb.org/~esr/writings/cathedral-bazaar/cathedral-bazaar, deutsche Übersetzung: http://gnuwin.epfl.ch/articles/de/Kathedrale/
- I. Stamelos, L. Angelis, A. Oikonomou, G. L. Bleris, “Code Quality Analysis in Open Source Software Development” (2002): Information Systems Journal 12(1), S. 43-60
- G. Schryen, “Is Open Source Security a Myth?” (2011): Communications of the ACM 54(5), S. 130-140
- J. Henkel, “Selective Revealing in Open Innovation Processes: The Case of Embedded Linux” (2006): Research Policy 35(7), S. 953-969
- K. R. Lakhani, R. G. Wolf, “Why Hackers Do What They Do: Understanding Motivation and Effort in Free/Open Source Software Projects” (2005): J. Feller, B. Fitzgerald, S. Hissam, K. R. Lakhani (Ed.), Perspectives on Free and Open Source Software. MIT Press, Cambridge, MA, S. 3-22
- S. Haefliger, G. von Krogh, S. Spaeth, “Code Reuse in Open Source Software” (2008): Management Science 54(1), S. 180-193
- Lime Survey: http://www.limesurvey.org/de
- Likert-Skala: http://www.wirtschaftslexikon24.net/d/likert-skala/likert-skala.htm und http://de.statista.com/statistik/lexikon/definition/82/likert-skala/
- M. Sojer, “Reusing Open Source Code” (2010): Gabler Verlag, Wiesbaden
- M. Sojer, J. Henkel, “License Risks from Ad-Hoc Reuse of Code from the Internet: An Empirical Investigation” (2011): Communications of the ACM 54(12), S. 74-81





