
© Martin Konopka, 123RF.com
Wer seine Daten mit ansehnlichen und informativen Graphen veranschaulichen möchte, braucht meist viel Geduld. Die R-Erweiterung Ggplot2 bringt System in die Grafik, drückt sich in knappem Quellcode aus und bläst frischen Wind in den Alltag der Datenvisualisierung.
Statistiker und Wissenschaftler sehen die Welt gerne als große Datenquelle, die es zu erkunden und verstehen gilt. Doch bedarf es nicht erst des Large Hadron Collider, um interessante Daten zu generieren: Auch Softwareperformance-Messungen oder Zugriffsstatistiken für Webserver werfen viel Material ab, das sich erst mit der richtigen Darstellung von einer trockenen Datenwüste in informative und aussagekräftige Oasen verwandelt. Ggplot2 ist ein leistungsfähiges, aber nicht sehr bekanntes Plotting-Tool, das auf der Statistiksprache GNU R aufbaut.
Strukturfragen
Software zum Erstellen von Charts gibt es mehr als genug: Die üblichen Verdächtigen wie Tabellenkalkulationen, Gnuplot oder das Python-Framework Matplotlib verfolgen einen traditionellen, imperativen Ansatz: Je nach Datensatz wählt der Nutzer aus einer vorgegebenen Auswahl von Charts den besten aus – Barcharts, Punkte, Linien oder Ähnliches – und setzt mehr oder weniger zahlreiche Parameter oder schiebt Kästchen mit der Maus hin und her, um alle Formatierungsdetails einzustellen.
Eine oft mühselige Aufgabe, besonders wenn sich die Daten ständig ändern oder die optimale Darstellung nicht von vornherein klar ist. Schließlich möchte man sich lieber auf die Datenanalyse und nicht auf die technischen Details des Plots konzentrieren. Das Problem ist unter Statistikern und anderen Datenliebhabern nicht neu.
Ein attraktiver Lösungsvorschlag stammt von dem Statistiker Leland Wilkinson [1], der ihn in Jahrzehnten wissenschaftlichen Schaffens erdacht und ausgebaut hat: Die von ihm erfundene “Grammar of Graphics” beschreibt, wie verschiedene Aspekte eines Datensatzes auf die Komponenten eines Graphen abgebildet werden, ohne auf die expliziten Details der Formatierung einzugehen. Mit dem Ggplot2-Paket, das auf der mächtigen Statistiksprache GNU R [2] aufbaut, hat Hadley Wickham eine Implementierung der Grammar of Graphics erstellt, die dieser Artikel vorstellt.
Syntax und Konzepte von Ggplot2 und R scheinen auf den ersten Blick unkonventionell und bleiben es auch auf den zweiten. Zwar ist die Sprache weder unpraktisch noch inkonsistent, ganz im Gegenteil, die Lernkurve ist aber steiler als bei anderen Ansätzen. Belohnt wird der Gewöhnungsaufwand jedoch mit großer Flexibilität und ästhetischen Grafiken in Publikationsqualität, die ohne große Parameterspielereien entstehen.
Das große R
GNU R ist in den meisten Linux-Distributionen als Binärpaket enthalten. Es besitzt eine interaktive Shell, die sich auf der Konsole durch Aufrufen von »R« starten lässt. Daneben gibt es auch diverse Frontends, beispielsweise den ESS-Modus von Emacs. Um Ggplot2 innerhalb einer R-Sitzung verfügbar zu machen, genügt die Eingabe von »library(ggplot2)« . Ist Ggplot2 nicht in der R-Standardinstallation der Distribution enthalten, kann der Anwender es mit dem Kommando »install.packages(“ggplot2”, dependencies=T)« in der R-Shell mit allen benötigten Abhängigkeiten nachinstallieren. Beenden lässt sich eine R-Session durch die Eingabe von »quit()« oder die Tastenkombination [Strg]+[D].
Datenkolonnen
Der Beispieldatensatz in Listing 1 soll dazu dienen, die Prinzipien von Ggplot2 zu demonstrieren. Die Daten liegen in Form einer CSV-Datei vor, einem einfachen, aber universellen Datenformat, das beinahe jede Applikation exportieren kann. Die Daten beschreiben ein Experiment, das die Leistung der Algorithmen »foo« , »bar« und »hyper« misst, die auf Datensätze unterschiedlicher Größe (»Datenumfang« ) angewendet werden. Die Geschwindigkeit, wie viele Daten sie pro Zeit verarbeiten, gibt die Spalte »Durchsatz« an. Zudem unterscheiden die Messdaten zwischen den drei Konfigurationen »A« , »B« und »C« .
Listing 1
Beispieldatensatz
01 Algorithmus,Datenumfang,Durchsatz,Konfiguration 02 foo,32,6.67,A 03 foo,64,7.19,A 04 foo,128,7.60,A 05 foo,256,8.03,A 06 foo,512,8.21A 07 foo,32,6.79,B 08 foo,64,6.60,B 09 foo,128,7.45,B 10 [...] 11 foo,512,8.21,C 12 bar,32,4.00,A 13 bar,64,6.92,A 14 bar,128,11.17,A 15 [...] 16 bar,256,16.01,C 17 bar,512,19.97,C 18 hyper,32,6.62,A 19 hyper,64,8.40,A 20 [...]
Das Szenario ähnelt vielen Situationen, die im Alltag von Programmierern oder Administratoren auftreten. In der Praxis müssen sie die Daten zwar meist erst aus Logdateien oder anderen Quellen extrahieren, da dieser Schritt aber nichts mit der Visualisierung zu tun hat, kann er hier entfallen.
Daten sind in Ggplot2 durch Data Frames repräsentiert, einer R-Datenstruktur ähnlich den Listen oder Arrays, die aus anderen Programmiersprachen bekannt sind. Jeder Data Frame besteht aus einer beliebigen Anzahl von Zeilen und Spalten, von denen jede einen Namen tragen kann. Wie im Beispiel reicht es für Ggplot2 aus, wenn die Spalten benannt sind. Listing 2 zeigt, wie das R-Kommando »read.csv« aus der CSV-Datei einen Data Frame erzeugt.
Listing 2
Data Frame erzeugen
01 dat <- read.csv("data.txt", header=T)
02 print(dat)
03 Algorithmus Datenumfang Durchsatz Konfiguration
04 1 foo 32 6.675104 A
05 2 foo 64 7.190872 A
06 3 foo 128 7.684894 A
07 4 foo 256 8.038377 A
08 [...]
Das Argument »header=T« weist R an, die Beschriftungen der Spalten aus der ersten Zeile der Textdatei zu übernehmen. Der R-Zuweisungsoperator »<-« speichert die Daten in der Variablen »dat« . Mit dem abschließenden »print()« -Befehl lässt sich prüfen, ob die Daten korrekt eingelesen wurden.
Der Einfachheit halber steht zunächst lediglich eine Teilmenge, der Algorithmus »foo« , zur Debatte. GNU R stellt dazu das Subset-Kommando bereit, das einen verkleinerten Data Frame erzeugt:
dat.sub <- subset(dat, Algorithmus=="foo")
Zum Umwandeln der Rohdaten in eine Grafik dienen die R-Aufrufe in Listing 3. Das Resultat zeigt Abbildung 1.
Listing 3
Grafik erzeugen
01 g <- ggplot(data=dat.sub, 02 aes(x=Datenumfang, y=Durchsatz, 03 colour=Konfiguration)) + 04 geom_point() + geom_line() 05 print(g)
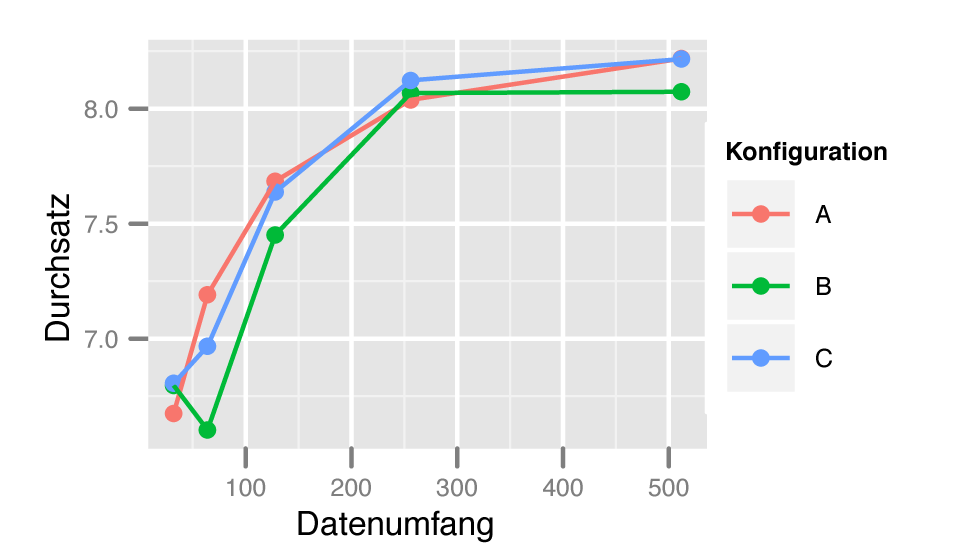
Abbildung 1: Die erste Visualisierung: Leistungsmessung für den Algorithmus »foo« mit drei verschieden eingefärbten Konfigurationen.
Daten und Ästhetik
Die Transformation erfolgt in zwei Schritten: Das »ggplot« -Basisobjekt legt neben der Datenquelle, dem zuvor angelegten Data Frame »dat.sub« , ein ästhetisches Mapping fest. Das Mapping beschreibt, welche Aspekte der Daten Ggplot2 auf welche Komponenten des resultierenden Graphen abbildet. Listing 3 bestimmt, dass Durchsatz (y-Achse) über Datenumfang (x-Achse) zu plotten ist. Eine weitere Komponente der Daten, die Messkonfiguration, ist mit »colour« farbig kodiert, sprich: Pro Konfiguration verwendet Ggplot2 eine Farbe.
Die Zuordnungen des Basisobjekts beschreiben allerdings noch nicht, welches grafische Objekt für die Datenpunkte zur Verwendung kommt, die durch Datensatz und ästhetisches Mapping beschrieben sind. Grafische Objekte verwaltet Ggplot2 in Ebenen (Layers), die je ein solches Objekt enthalten.
Ein Plot kann aus mehreren übereinandergelegten Ebe-nen bestehen – Ggplot kümmert sich automatisch darum, dass die äußeren Parameter der Grafik, etwa Größe und Achsenbeschriftung, in allen Ebenen übereinstimmen. Das Erzeugen eines Ebenen-Objekts übernimmt eine Funktion nach dem Muster »geom_Typ« , wobei Typ das verwendete grafische Objekt angibt.
Listing 3 verwendet zwei Ebenen mit einfachen grafischen Objekten: Punkten (»geom_point()« ) und Linien (»geom_line()« ). Ggplot2 addiert beide zum Basisobjekt hinzu. Dabei überträgt die Software die Einstellungen des Basisobjekts (Datenquelle und ästhetisches Mapping) in die Ebenen. Durch das Zusammenschalten des Basisobjekts mit den Ebenen-Objekten entsteht ein neues, kombiniertes R-Objekt, das sich mit dem generischen Print-Kommando ausgeben lässt. Das Resultat ist allerdings kein Text auf der Konsole, sondern eine Grafik am Bildschirm.
Natürlich kann man Plots auch permanent speichern. Das Kommando
ggsave("/tmp/graph.pdf", g)
schreibt den in »g« enthaltenen Plot im PDF-Format in die angegebene Datei. Das gewünschte Dateiformat erkennt Ggplot2 automatisch an der Datei-Endung. Neben PDF stehen unter anderem PNG, JPEG, EPS und SVG zur Auswahl. Standardmäßig stellt die Software Abbildungen im Format 9,75 mal 4,6 Zoll bereit, was 24,75 mal 11,7 Zentimetern entspricht. Ändern lässt sich dies über die Parameter »height« und »width« . Rastergrafikformate wie JPG und BMP verwenden gewöhnlich eine Auflösung von 300 dpi, die über den »dpi« -Parameter anpassbar ist.
Um ein rechteckiges PNG mit 5 Zoll Kantenlänge in hoher Auflösung zu zeichnen, ist daher
ggsave("plot.png", g, height=5, width=5, dpi=1200)
der Befehl der Wahl. Selbstverständlich sollte man Vektorformate bevorzugen, um die bekannten Skalierungsprobleme, eckigen Kanten und hässlichen Artefakte bei der Weiterverwendung zu vermeiden.
Ansichtssache
Neben den bislang vorgestellten einfachen Grafikobjekten wie Punkten und Linien bietet Ggplot2 ein umfangreiches Repertoire grafischer Elemente an, die der Anwender praktisch beliebig miteinander kombinieren kann. Abbildung 2 zeigt eine kleine Auswahl davon, eine vollständige Liste findet sich auf der Ggplot2-Homepage [3].
Abbildung 2: Eine kleine Auswahl der Grafikobjekte, die Ggplot2 anbietet.
Zurück zum vollständigen Demo-Datensatz: Gegenüber der eingeschränkten Variante enthält er mehrere Algorithmentypen. Sie sollen durch die unterschiedliche Form (»shape« ) der Plot-Symbole erkennbar sein. Der Aufruf in Listing 4 erzeugt den Plot in Abbildung 3. Neben der kompletten Datenquelle »dat« anstelle der Teilmenge »dat.sub« und der »shape« -Ästhetik enthält der Code eine weitere Neuerung: Die Größe der mit »geom_point()« erzeugten Punkte ist mittels »size« auf »3« gesetzt und damit gegenüber der Standardeinstellung 2 etwas vergrößert.
Listing 4
Verschiedene Formen
01 g <- ggplot(data=dat, 02 aes(x=Datenumfang, y=Durchsatz, 03 colour=Konfiguration, 04 shape=Algorithmus)) + 05 geom_point(size=3) + geom_line() + 06 scale_x_log10()
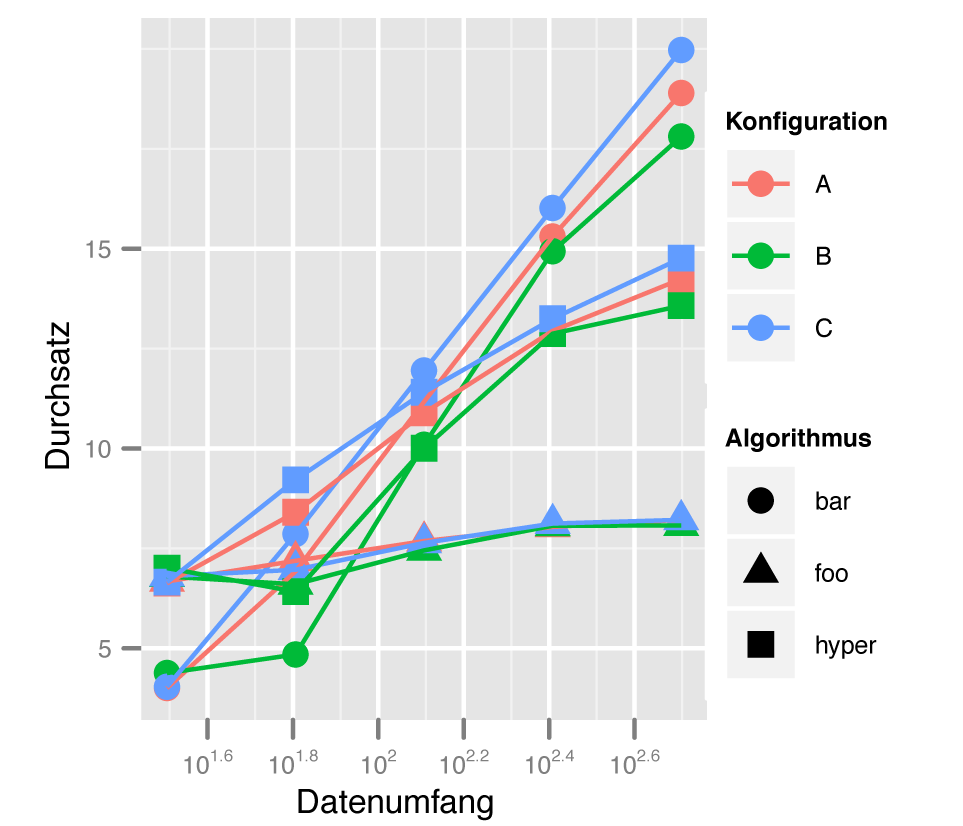
Abbildung 3: Der Plot des vollständigen Beispieldatensatzes mit verschiedenen Formen für die verwendeten Algorithmen.
Zu den direkt im »ggplot« -Objekt eingestellten Ästhetiken gibt es zwei Unterschiede: Erstens ist die Einstellung nicht an die Daten gekoppelt, sondern verwendet einen fixen Wert. Daher ist auch keine Einbindung über den »aes« -Parameter nötig, die Einstellung erfolgt direkt. Zweitens gilt die Vorgabe nur für die Punkt-Ebene, beeinflusst also die ebenfalls eingezeichneten Linien nicht. Nicht alle grafischen Elemente kennen alle ästhetischen Abbildungen: Wie Abbildung 3 zeigt, unterstützen nur Punkte, aber nicht Linien die Angabe »shape« .
Der letzte Zusatz, »scale_x_log10()« , führt eine Skalentransformation durch: Anstelle der linearen kommt für die x-Achse nun eine logarithmische Skala zur Verwendung. Dass Ggplot2 auch in diesem Fall die Achsen so anpasst, dass alle Ebenen passend untergebracht sind, versteht sich von selbst.
Facetting
Eine aussagekräftige Abbildung soll möglichst viele Informationen enthalten, um alle Facetten der Daten wiederzugeben. Natürlich birgt dies die Gefahr, überfrachtete und ohne langes Meditieren unverständliche Plots zu erzeugen. (Die Grenze ist fließend: Während es dem Leser wissenschaftlicher Monografien durchaus zuzumuten ist, zehn Minuten über eine Abbildung nachzudenken, wird die Freude in der Redaktion von Boulevardzeitungen tendenziell geringer ausfallen.) Eine mögliche Lösung besteht darin, die Facetten der Daten nicht implizit über Farben und Symbole, sondern explizit über Untergraphen darzustellen.Ggplot2 setzt dies über das Facetten-Konzept um, das mittels »facet_grid()« verfügbar ist.
Um die Daten wie in Abbildung 4 auf mehrere Untergraphen zu verteilen, ist die Befehlssequenz aus Listing 5 notwendig. Der Ausdruck »facet_grid(~Konfiguration)« legt fest, dass Ggplot2 für alle möglichen Konfigurationen (also A, B und C) einen eigenen Unterplot anlegt. Jeder Unterplot zeigt eine eigene Teilmenge der Gesamtdaten, verwendet aber identische Ebenen und ästhetische Mappings.
Listing 5
Facetten
01 g <- ggplot(data=dat, 02 aes(x=Datenumfang, y=Durchsatz, 03 colour=Algorithmus)) + 04 geom_point(aes(colour=Algorithmus)) + 05 facet_grid(~Konfiguration)
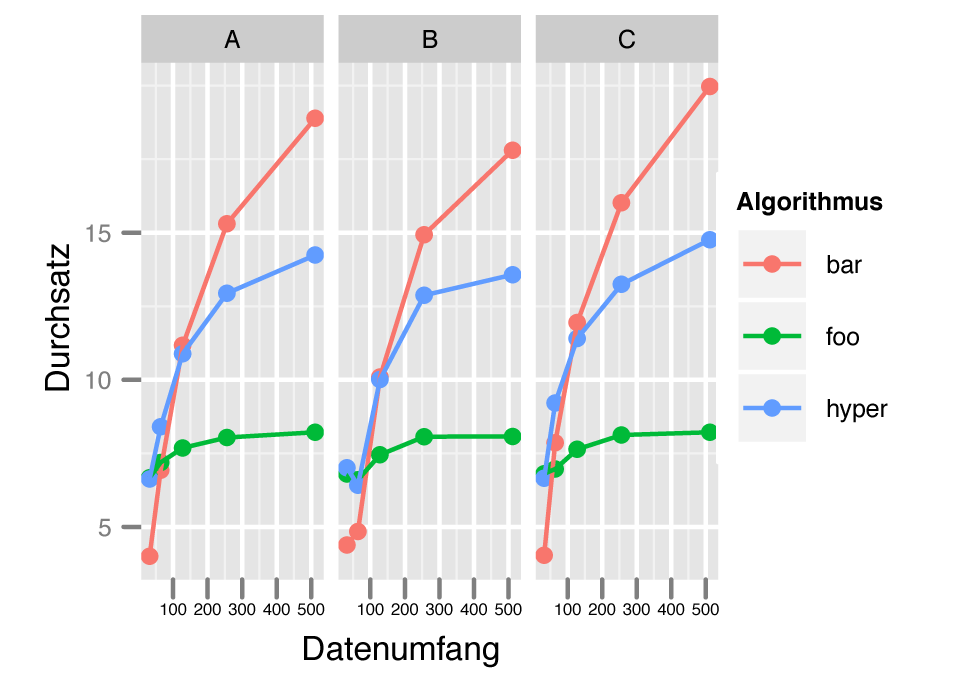
Abbildung 4: Eindimensionale Facettierung: Für jede Konfiguration erzeugt die Software einen eigenen Untergraphen.
Horizontal und vertikal
Facetten lassen sich nicht nur in horizontaler Richtung einsetzen. Auch eine vertikale Aufspaltung des Plots ist möglich – mit »facet_grid(Variable~.)« . Dabei darf man den abschließenden Punkt nicht vergessen, der aus formalen Gründen notwendig ist. Selbstverständlich kann der Anwender auch beide Varianten kombinieren: Die Facettierungsangabe
facet_grid(Algorithmus~Konfiguration)
produziert das in Abbildung 5 gezeigte Ergebnis. Die überflüssig gewordene »colour« -Ästhetik ist dabei entfallen: Bei gedruckten Publikationen kann eine reine Schwarz-Weiß-Darstellung manchmal vorteilhaft sein, um teuren Farbdruck zu vermeiden. Alternativ könnte man weitere Variablen auf die nun nicht mehr verwendete Farbe legen, um den Plot mit mehr Informationen anzureichern.
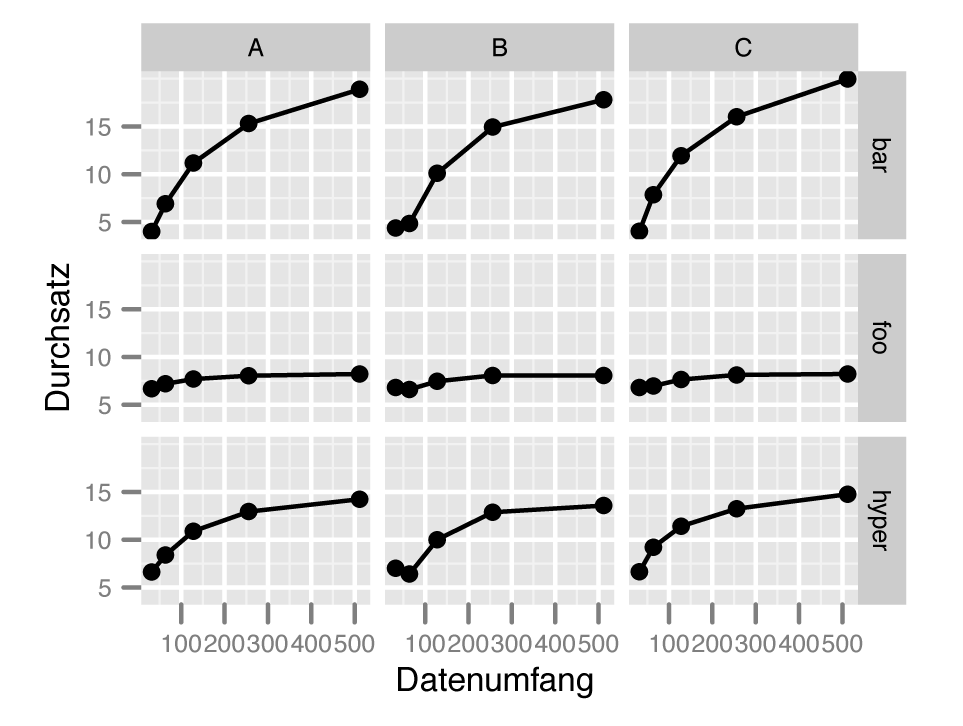
Abbildung 5: Zweidimensionale Facettierung ohne Farbe.
Facetting funktioniert dann gut, wenn die aufgespaltete Variable nur wenige unterschiedliche Werte besitzt – drei im Artikel-Beispiel. Bis zu einer gewissen Grenze an Variationsmöglichkeiten kann der Anwender auf Farben ausweichen, bei mehr Variabilität empfiehlt es sich, unterschiedliche Symbolgrößen (»size« -Ästhetik) zu verwenden. Alternativ ließen sich hochkategorielle Rohdaten auch durch entsprechendes Preprocessing (was sehr gut mit R möglich ist) zu einer übersichtlicheren Anzahl von Kategorien zusammenfassen.
Während Abbildung 3 vom oben erwähnten Untertauchen in zu vielen Details bedroht ist, zeigen sich die Alternativen in den Abbildungen 4 und 5 übersichtlicher. Welche Darstellungsform besser geeignet ist, entscheidet der Anwender von Fall zu Fall, am besten mit Hilfe kompetenter Literatur wie [5].
Wichtig aus Anwendersicht ist vor allem, dass der Aufwand zwischen den Varianten sich nicht ändert: Ggplot2 übernimmt automatisch alle lästigen Details wie die Positionierung der Subgraphen oder das Achsenlayout – wer sich an gekachelten Plots mit anderen Programmen versucht hat, kann ein Lied von nervtötenden Detailarbeiten singen, die nötig sind, um ein zufriedenstellendes Resultat zu erreichen. Ganz ohne manuelle Nacharbeit geht es aber auch bei Ggplot2 in der Praxis leider nicht. Der Aufwand fällt jedoch glücklicherweise meist gering aus.
Als Beispiel aus dem Arbeitsalltag zeigt dieser Artikel abschließend das Ergebnis von Latenzmessungen, die auf einem Dualcore-System zwischen einer Echtzeit- (RT-) und einer Nicht-Echtzeit-Variante (Non-RT) von Linux durchgeführt wurden. Jeder Messpunkt speichert eine Verzögerung (Latenz) zusammen mit der Information, auf welcher CPU und in welchem Modus (Echtzeit oder nicht) die Messung stattfand.
Daten zusammenfassen
Im Unterschied zum bisherigen Beispiel liegt hier eine hohe Anzahl von Messwerten vor (mehrere Tausend, die Rohdaten sind online unter [6] verfügbar), weshalb sich als grafisches Objekt ein zusammenfassendes Histogramm empfiehlt. Listing 6 zeigt den Code, der den Plot in Abbildung 6 erzeugt. Die manuellen Korrekturen beziehen sich vor allem auf die Achsen: Neue Schlüsselwörter schränken die Daten in x-Richtung auf den Wertebereich 1 bis 500 ein (»xlim()« ) und verschönern die Beschriftung der logarithmischen y-Achse (Argumente für »scale_y_log10()« ). Das Kommando »theme_bw()« wählt eine alternative Stilvorgabe aus, die den Plot für die Darstellung in Schwarz-Weiß optimiert.
Listing 6
Feinschliff
01 g <- ggplot(data=latency,
02 aes(x=total_observed_delay)) +
03 geom_histogram(binwidth=1) +
04 scale_y_log10(breaks=c(1, 10, 100, 1000),
05 labels=c("1", "10", "100", "1000")) +
06 xlim(1,500) + facet_grid(type~CPU) +
07 xlab(expression(paste("Delay [", mu, "s]"))) +
08 ylab(" # samples [a.u.]") + theme_bw()
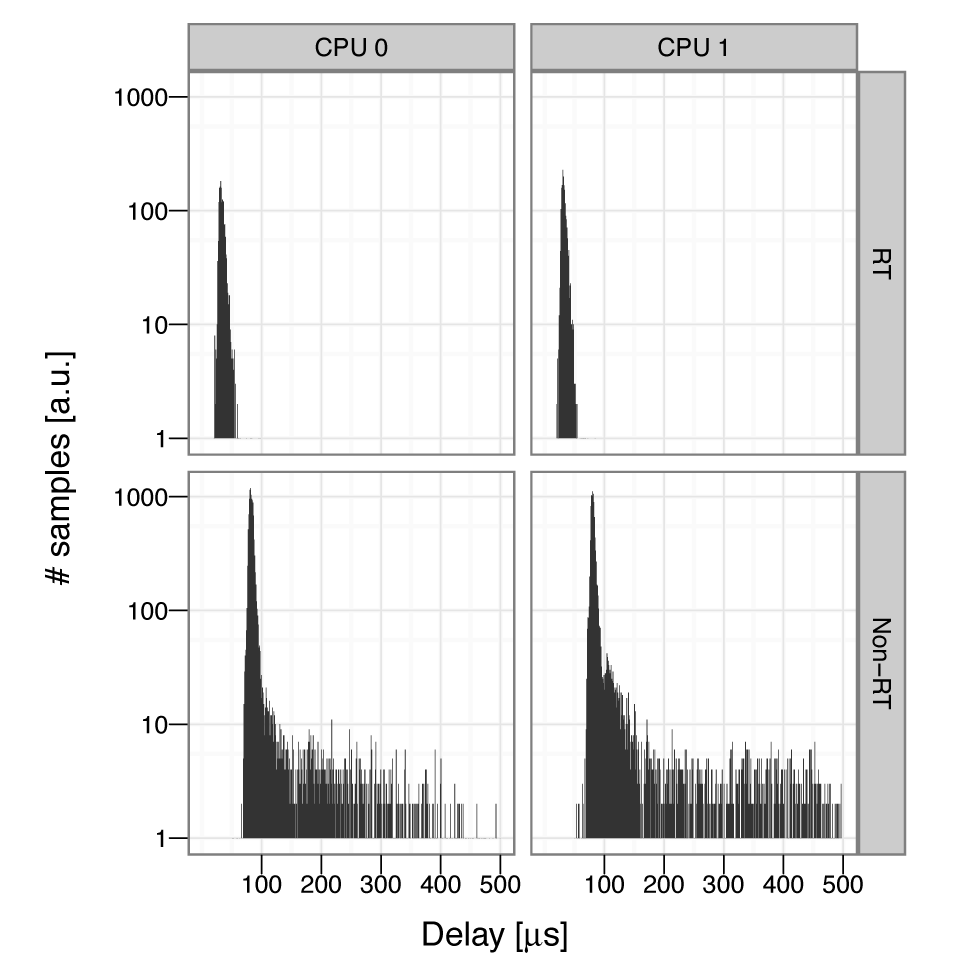
Abbildung 6: Histogramm-Beispiel: Latenzmessungen am Linux-Kernel.
Die größte Neuigkeit versteckt sich im grafischen Objekt. Der Plot zeigt keine direkte Abbildung der Originaldaten, sondern führt eine (implizite) statistische Transformation durch: Das Histogramm (»geom_histogram()« ) fasst alle Latenzen zusammen, die in einen Bereich mit einer bestimmten zeitlichen Breite fallen. Jeden Bereich repräsentiert ein Balken, dessen Höhe proportional zur Anzahl der darin enthaltenen Messpunkte ist. Anders als Linien und Punkte basieren solche komplizierteren grafischen Objekte nicht immer auf direkten Abbildungen der Originaldaten.
Auf die ebenfalls vorhandene Möglichkeit, explizite statistische Transformationen in den Plot-Prozess einzubinden, kann dieser Artikel nicht im Detail eingehen. Ein guter Einstiegspunkt hierfür ist jedoch die erschöpfende Sammlung der Schlüsselwörter (Geoms, statistische Transformationen, Skalen, Layout-Parameter und so weiter), die sich auf der Ggplot2-Homepage [3] findet.
Ein unverzichtbarer Begleiter für die tägliche Arbeit mit der Software ist das Buch des Ggplot2-Autors Wickham [4]. Leider ist noch keine wirklich umfassende Einführung zu Ggplot2 im Web frei verfügbar, aber die Investition ins Buch lohnt sich in jedem Fall – und wird vermutlich auch die Weiterentwicklung und Pflege des Pakets unterstützen.
Neben den genannten Ressourcen gibt es (knapp gehaltene) Hilfeseiten für alle Befehle, die allerdings nicht über den klassischen Manpage-Mechanismus, sondern direkt in R durch Eingabe von »?Stichwort« verfügbar sind, beispielsweise »?geom_line« .
Ausblick
Abschließend sei noch auf die zwei charmanten Möglichkeiten hingewiesen, Ggplot2 nicht-interaktiv zu verwenden, was bei der automatisierten Datenauswertung praktisch unverzichtbar ist. Zum einen genügt es bereits, alle benötigten Kommandos einschließlich »ggsave()« und Laden der Ggplot2-Bibliothek in einer Textdatei zu speichern, die sich auf der Unix-Shell mit »R CMD BATCH Datei.r« ausführen lässt. Die generierten Grafiken könnte man beispielsweise auf einem Webserver zur Verfügung stellen. Noch raffinierter, allerdings auch etwas anspruchsvoller, ist das System Sweave: Es vereinigt R und Ggplot2 mit dem Textsatzsystem Latex zu einer dynamischen Kombination, die druckreif gesetzte Dokumente mit eleganter Grafik kombiniert – generiert aus einer Quelltext-Mischung von R- und Latex-Code. Wagemutige Anwender finden alle Details im Sweave-Handbuch [7].
Infos
- L. Wilkinson et al., “The Grammar of Graphics”: 2ed, Springer, 2005
- Gerrit Eichner, Volker Schmitt, “R wie Rechenriese”: Linux-Magazin 099/08, S. 40
- Ggplot2: http://had.co.nz/ggplot2
- H. Wickham, “Ggplot2: Elegant Graphics for Data Analysis”: Springer, 2009
- E. Tufte, “Visual Display of Quantitative Information”: Graphics Press, 2ed, 2001
- Listings und Daten zum Artikel: https://www.linux-magazin.de/static/listings/magazin/2012/03/ggplot2/
- F. Leisch, “Sweave User Manual”: http://www.statistik.lmu.de/~leisch/Sweave/





