Listing 1
»oo-dumper«
01 #!/usr/local/bin/perl -w 02 use strict; 03 use OpenOffice::OODoc; 04 05 (my $file) = @ARGV; 06 07 die "usage: $0 file" unless defined $file; 08 09 my $doc = ooDocument( 10 file => $file, 11 member => "content", 12 ); 13 14 (my $element) = $doc->selectElements( 15 '//office:body'); 16 17 print $element->_dump();
XML erforschen
Die Methode »selectElements()« setzt einen Xpath-Query ab, der alle XML-Elemente unterhalb des Tag »office:body«, also des eigentlichen Textdokuments, zutage fördert. Dokumente enthalten nur einen einzigen Body, allerdings besteht OpenOffice::OODoc darauf, dass die linke Seite der Zuweisung in Zeile 14 einen List-Kontext suggeriert, deshalb die einschließenden Klammern um »$element«. Zurück kommt eine Referenz auf ein Objekt vom Typ OpenOffice::OODoc::Element, das aber aufgrund von Vererbung auch die Methoden des ausführenden XML-Parsers XML::Twig versteht.
Dieses schon einmal in einem früheren Snapshot vorgestellte [3], etwas eigenwillige XML-Modul stellt die Methode »_dump()« bereit, die eine textuelle Aufbereitung eines XML-Unterbaums generiert und als String zurückliefert.
So zeigt sich in Abbildung 5, dass im Dokument unter dem Tag »office:body« ein Tag namens »office:text« hängt, das nach einigen Sequence-Deklarationen wiederum einen Textabsatz vom Typ »text:p« (Paragraph) enthält. Dieser stellt sich als eine Tabellenzeile mit drei Spalten heraus, für deren Rahmen jeweils Elemente vom Typ »draw:frame« verantwortlich zeichnen, die wiederum ein »draw:text-box«-Element mit einem »text:p«-Element mitbringen, in denen sich endlich die eingegebenen Test-Texte (»test1«, …) wiederfinden.
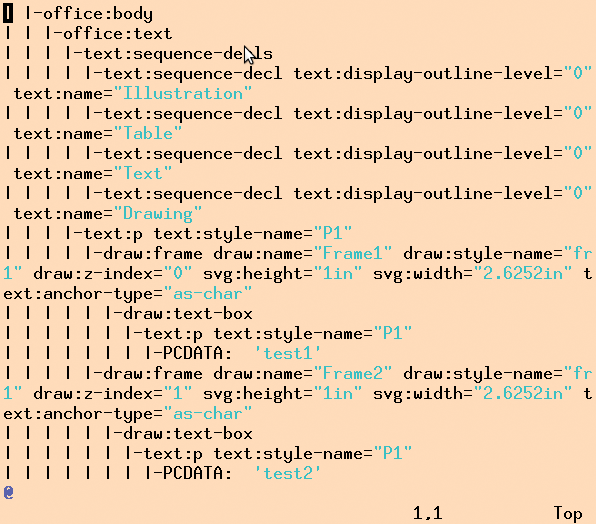
Abbildung 5: Die »_dump()«-Methode zeigt die interne Verschachtelung des XML-Dokuments.
Somit fördert ein Xpath-Query vom Format
//office:body/office:text/text:p
alle Tabellenzeilen zutage (die ihrerseits wieder Spaltenrahmen enthalten), während sich die Tabellenelemente (drei in jeder Zeile) relativ dazu unter »…/draw:frame/drawtext-box/text:p« finden. Das Skript in Listing 2 bedient sich des ersten Xpath-Query, um zunächst das Dokument um so viele Tabellenzeilen zu erweitern, wie nötig sind, damit alle auszudruckenden Adressdaten darin Platz finden. Mit dem zweiten Query stöbert es durch alle Labels und stopft jeweils die dafür bestimmten Textdaten hinein.
Listing 2
»label-writer«
01 #!/usr/local/bin/perl -w
02 use strict;
03 use OpenOffice::OODoc;
04 use Sysadm::Install qw( :all );
05 use Text::CSV_XS;
06 use POSIX qw(ceil);
07
08 my $template = "template.odt";
09 my $file = "ready.odt";
10 my $addr_book = "address-book.csv";
11 my $labels_per_page = 30;
12
13 my @addresses =
14 addresses_scan( $addr_book);
15
16 my $addtl_pages =
17 ceil( scalar @addresses /
18 $labels_per_page ) - 1;
19
20 # Put template in place
21 cp $template, $file;
22
23 my $doc = ooDocument(
24 file => $file,
25 type => "content",
26 local_encoding => "",
27 );
28
29 # Extend document as necessary
30 my @rows = $doc->selectElements(
31 '//office:body/office:text/text:p'
32 );
33
34 for ( 1 .. $addtl_pages ) {
35 for my $row ( @rows ) {
36 $doc->replicateElement( $row, "body" );
37 }
38 }
39
40 # All labels, including new ones
41 my @labels = $doc->selectElements(
42 '//office:body/office:text/text:p/' .
43 'draw:frame/draw:text-box/text:p'
44 );
45
46 my $addr_idx = 0;
47
48 for my $label ( @labels ) {
49 $doc->setStyle( $label, "P1" );
50 $doc->setText( $label,
51 $addresses[ $addr_idx ] );
52 $addr_idx++;
53 $addr_idx = 0 if
54 $addr_idx > $#addresses;
55 }
56
57 $doc->save();
58
59 ###########################################
60 sub addresses_scan {
61 ###########################################
62 my( $addr_book ) = @_;
63
64 my @addresses = ();
65
66 open( my $fh, "<:encoding(utf8)",
67 $addr_book ) or die "$addr_book: $!";
68
69 my $csv = Text::CSV_XS->new (
70 { binary => 1 } ) or die
71 "Cannot use CSV: " .
72 Text::CSV->error_diag ();
73
74 while( my $row = $csv->getline( $fh ) ) {
75 unshift @$row, "";
76
77 for ( @$row ) {
78 s/^/ /;
79 }
80
81 push @addresses,
82 join( "\n", @$row );
83 }
84 close $fh;
85
86 return @addresses;
87 }
Zum Öffnen der ODT-Datei bedient es sich wieder des Konstruktors »ooDocument()«, der auf die Datei »ready.odt« zugreift, die ihrerseits zuvor die Funktion »cp« aus dem Modul Sysadm::Install in Zeile 21 aus dem Template »template.odt« erzeugt hat.
Die gegenwärtige Version von OpenOffice::OODoc weist einen Bug auf, der sie UTF-8-kodierte Daten inkorrekt verarbeiten lässt, falls diese Umlaute enthalten. Die gewählte Einstellung »local_encoding =>»”””« behebt das Problem vorläufig, sollte aber eigentlich auf den Wert »utf8« gesetzt sein.
Adressbuch einpflegen
Die Rohdaten legt der User in der Datei »address-book.csv« (Abbildung 6) ab, von wo sie das Skript aus Listing 2 mit dem CPAN-Modul Text::CSV_XS zeilenweise mit »getline()« ausliest. Die ab Zeile 60 definierte Funktion »addresses_scan« öffnet dazu die Datei mit dem Pragma »:encoding(utf8)«, damit Perl dort stehende und in UTF-8 kodierte Umlaute auch korrekt einliest und gleichzeitig intern in den dafür vorgesehenen Datenstrukturen das UTF-8-Flag setzt.






