
© Juri Samsonov, 123RF.com
C++-Programme arbeiten zur Laufzeit, der eingebaute Template-Mechanismus aber zur Compilezeit. Geschickte Entwickler nutzen dies für Metaprogrammierung im funktionalen Stil, die erstaunlich performante und sogar selbstoptimierende Software ermöglicht.
Obwohl durch Zufall entdeckt, erweitert Template Metaprogramming die Sprache C++ mit einer Mächtigkeit, die sich mit klassischem Programmcode nicht erreichen lässt. Der Template-Mechanismus, ursprünglich zum generischen Programmieren (unabhängig vom Datentyp) eingeführt, entpuppte sich als Metasprache in C++, die Typen und Werte zur Compilezeit berechnet. Die resultierenden Programme sind schneller, da sich die Arbeit von der Laufzeit auf die Compilezeit verlagert. Höhere Performance paart sich mit erweiterter Funktionalität.
Wie alles begann
1994 stellte Erwin Unruh von Siemens-Nixdorf dem C++-Standardkomitee sein Primzahlen-Programm vor – das wohl berühmteste C++-Programm, das nicht kompiliert [1]. Die Fehlermeldung als Seiteneffekt des Übersetzungsprozesses war das Revolutionäre seines Programms: Die Primzahlen bis 30 waren in den Fehlerausgaben des Compilers versteckt. Listing 1 zeigt die wesentlichen Zeilen der originalen Ausgabe.
Listing 1
Fehlerausgabe des Primzahlen-Programms
01 | Type `enum{}' can't be converted to txpe `D<2>' ("primes.cpp",L2/C25).
02 | Type `enum{}' can't be converted to txpe `D<3>' ("primes.cpp",L2/C25).
03 | Type `enum{}' can't be converted to txpe `D<5>' ("primes.cpp",L2/C25).
04 | Type `enum{}' can't be converted to txpe `D<7>' ("primes.cpp",L2/C25).
05 | Type `enum{}' can't be converted to txpe `D<11>' ("primes.cpp",L2/C25).
06 | Type `enum{}' can't be converted to txpe `D<13>' ("primes.cpp",L2/C25).
07 | Type `enum{}' can't be converted to txpe `D<17>' ("primes.cpp",L2/C25).
08 | Type `enum{}' can't be converted to txpe `D<19>' ("primes.cpp",L2/C25).
09 | Type `enum{}' can't be converted to txpe `D<23>' ("primes.cpp",L2/C25).
10 | Type `enum{}' can't be converted to txpe `D<29>' ("primes.cpp",L2/C25).
Der Beweis war erbracht: Template-Instanziierung lässt sich dazu verwenden, Werte zur Compilezeit zu berechnen. Das Programm in Listing 2 beispielsweise rechnet die Fakultät von 5 zur Compilezeit aus. Das primäre oder auch allgemeine Template »template <int N> struct Factorial« ruft sich mit »static int const value= N * Factorial<N-1>::value« rekursiv selbst auf, bis die Template-Spezialisierung »template <> struct Factorial<1>« eintritt. In diesem Fall wird die Rekursion mit dem Wert 1 beendet und das Ergebnis berechnet.
Listing 2
Fakultät-Berechnung zur Compilezeit
01 #include <iostream>
02
03 template <int N>
04 struct Factorial{
05 static int const value= N * Factorial<N-1>::value;
06 };
07
08 template <>
09 struct Factorial<1>{
10 static int const value = 1;
11 };
12
13 int main(){
14 std::cout << Factorial<5>::value << std::endl;
15 std::cout << 120 << std::endl;
16 return 0;
17 }
Da die Template-Instanziierung und somit auch die Rekursion zur Compilezeit abläuft, liegt der Wert von »Factorial <5>::value« zur Laufzeit des resultierenden Programms als Konstante vor. Das Übersetzen des Quellcode mit Debug-Informationen per »g++ -g -o fakultaet fakultaet.cpp« und ein anschließender Objektdump mit »objdump -S fakultaet« bringen die Magie in doppelter Hinsicht ans Tageslicht (Abbildung 1).

Abbildung 1: Der Objektdump des Fakultät-Programms enthält das Ergebnis der Berechnung.
Zum einen lautet die Fakultät von 5 in hexadezimaler Schreibweise »x78« . Genau dieser Wert steht in der Assembler-Anweisung »mov $0x78,$esi« . Zum anderen resultiert aus dem Sourcecode »std::cout << Factorial<5>::value << std::endl« der gleiche Assembler-Code wie aus dem Sourcecode »std::cout << 120 << std::endl« , in dem der Wert der Fakultät von 5 schon als Konstante vorliegt.
Charakteristiken
Template Metaprogramming ist eine Meta-Technik in C++, in der der Compiler die Templates zur Compilezeit interpretiert und sie in C++-Quelltext transformiert. Diesen temporär erzeugten Code übersetzt er zusammen mit dem restlichen Sourcecode. C++ ist insofern eine Zwei-Level-Sprache, weil der statische Code zur Compilezeit, der resultierende dynamische Code aber zur Laufzeit ausgeführt wird (Abbildung 2).

Abbildung 2: Dank des Template-Mechanismus wird C++ zu einer Zwei-Level-Sprache.
Mit Template Metaprogramming lassen sich aber nicht nur Werte berechnen, das Programm in Listing 3 verändert Datentypen zur Compilezeit. Es entfernt die Konstantheit (Constness) der Typen. Das Programm demonstriert die Charakteristiken des Template Metaprogramming: Der Quelltext besteht aus dem primären Klassentemplate »template <typename T> struct RemoveConst« und dessen Spezialisierung »template <typename T>struct RemoveConst<const T>« , die nur konstante Typen annimmt.
Listing 3
Das Klassentemplate RemoveConst
01 #include <iostream>
02 #include <map>
03
04 template <typename T>
05 struct RemoveConst{
06 typedef T type;
07 };
08
09 template <typename T>
10 struct RemoveConst<const T>{
11 typedef T type;
12 };
13
14 template <typename T>
15 void checkConst(){
16 if (std::is_const<T>::value == true ) {
17 std::cout << "const " << std::endl;
18 }
19 else {
20 std::cout << "not const" << std::endl;
21 }
22 }
23
24 int main(){
25
26 std::cout << "int : "; checkConst<int>();
27 std::cout << "const int: "; checkConst<const int>();
28 std::cout << "RemoveConst<int>::type > "; checkConst< RemoveConst<int>::type >();
29 std::cout << "RemoveConst<const int>::type > : "; checkConst< RemoveConst<const int>::type >();
30 typedef RemoveConst<const int>::type NotConstFromConstInt;
31 std::cout << "NotConstFromConstInt : "; checkConst< NotConstFromConstInt >();
32 NotConstFromConstInt i= 10;
33
34 }
Während das primäre Template den Datentyp unverändert zurückgibt, liefert die Spezialisierung für konstante Datentypen diese nicht-konstant zurück. Das Funktionstemplate »template <typename T> void checkConst()« ist nur eine Hilfsfunktion, die ausgibt, ob der Templateparameter »T« konstant ist. Dies ermittelt die Funktion »std::is_const<T>::value« aus dem kommenden C++0x-Standard [2] zur Compilezeit.
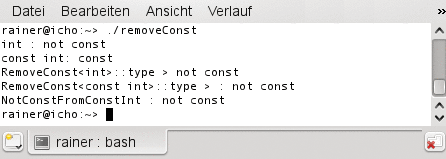
Abbildung 3: Dieses Programm operiert auf Typen: Es nimmt konstante Datentypen entgegen und gibt sie nicht-konstant zurück.
Die letzten vier Zeilen der Main-Funktion sind die interessantesten im ganzen Listing. In Zeile 29 nimmt der Ausdruck »RemoveConst<const int>::type« einen »const int« als Eingabe und gibt einen »int« zurück. Der Ausdruck »typedef RemoveConst<const int>::type NotConstFromConstInt« erklärt ein Alias auf diesen Typ. Dieses Alias ist nichts anderes als ein Integer und lässt sich auch im weiteren Programm (Zeile 32) als solcher verwenden.
Metafunktionen
Template Metaprogramming erzeugt den gewünschten C++-Sourcecode zur Compilezeit. Funktionen und Daten, die zur Compilezeit zur Anwendung kommen, nennt man Metafunktionen und Metadaten. Metafunktionen sind Klassentemplates (Zeilen 4 und 9 in Listing 3), der C++-Funktion »myFunction(arg1,arg2)« etwa entspricht die Metafunktion »My Function<Arg1,Arg2>« .
Das Ergebnis der Metafunktion wird per Konvention, falls es ein Typ ist, durch »::type« (Zeile 30), falls es eine integrale Konstante ist, durch »::value« (Zeile 14 in Listing 2) zur Verfügung gestellt. Diese Konvention erleichtert das Programmieren mit Metafunktionen deutlich, da Metafunktionen mehrere Returnwerte zurückgeben können.
Typen und integrale Daten sind die Metadaten, auf denen Metafunktionen wirken. Metadaten werden aber nicht modifiziert, sondern auf Anfrage neu erzeugt. Zur Compilezeit gibt es keine Variablen, sondern nur symbolische Namen. Da C++ weder String- noch Fließkommakonstanten als Templateparameter erlaubt, lassen sich diese beim Template Metaprogramming nicht verwenden. Als Case-Struktur zur Compilezeit dient bei dieser Programmiertechnik Pattern Matching in Form partieller oder vollständiger Templatespezialisierung. Template Metaprogramming setzt Pattern Matching nach dem Best-fit-Prinzip ein, das die am genauesten passende Variante auswählt. Dies steht im Gegensatz zum vertrauteren Pattern Matching nach dem First-fit-Prinzip, das bei Ausnahmebehandlung in C++, Java oder Python gilt.
Die C++-Syntax verlangt, dass der Programmierer das primäre Template (Zeile 4 in Listing 3) als erstes zumindest deklariert, bevor er die Spezialisierungen (Zeile 9) definiert. Pattern Matching und Rekursion als Strukturelemente (Listing 2), die Abwesenheit von Variablen – die Anzeichen häufen sich, dass Template Metaprogramming eine funktionale Sprache ist. Grund genug, sich zu fragen: Lässt sich mit Template Metaprogramming im funktionalen Stil programmieren?
Map macht’s möglich
Neben »filter« und »reduce« ist »map« die klassische Funktion aus der funktionalen Programmierung. Sie nimmt eine Funktion und eine Liste an und gibt eine neue Liste zurück, indem sie die Funktion auf jedes Listenelement anwendet. Was liegt näher, als sie als Metafunktion umzusetzen? Die zwei elementaren Bausteine, um zur Compilezeit Listen zu implementieren, sind Variadic Templates [3] und der Container »std::tuple« [2]. Beide finden sich im kommenden C++0x-Standard und können mit beliebig vielen Argumenten umgehen. Wie die Klassentemplates auf »std::tuple« beziehungsweise wie Metafunktionen auf Metadaten wirken, zeigt Listing 4.
Listing 4
Die Map-Funktion zur Compilezeit
01 #include <iostream>
02 #include <tuple>
03
04 // Int2Type
05
06 template <int v>
07 struct Int2Type {
08 const static int value= v;
09 };
10
11 // a few class templates
12
13 struct ApplyId{
14 template<typename T>
15 struct apply{
16 typedef Int2Type<T::value> type;
17 };
18 };
19
20 struct MakeTen{
21 template<typename T>
22 struct apply{
23 typedef Int2Type<10> type;
24 };
25 };
26
27 struct DoubleMe{
28 template<typename T>
29 struct apply{
30 typedef Int2Type<2*(T::value)> type;
31 };
32 };
33
34 struct AbsMe{
35 template<typename T>
36 struct apply{
37 typedef Int2Type< (T::value > 0)? T::value : -(T::value) > type;
38 };
39 };
40
41 // helper function for output
42
43 template< typename head >
44 void showMe( std::tuple< head> ){
45 std::cout << head::value << "\n";
46 };
47
48 template< typename head, typename ... tail>
49 void showMe( std::tuple< head, tail ... > ){
50 std::cout << head::value << " ," ;
51 showMe( std::tuple< tail ...>() );
52 }
53
54 // map function
55
56 template<typename F, typename ... Elements> struct map;
57
58 template< typename F, typename ... Elements>
59 struct map<F,std::tuple<Elements ...> >{
60 typedef std::tuple<typename F::template apply<Elements>::type ... > type;
61 };
62
63 int main(){
64
65 std::cout << "original tupel: " << std::endl;
66 typedef std::tuple<Int2Type<-5>,Int2Type<-4>,Int2Type<-3>,Int2Type<-2>,Int2Type<-1>,Int2Type<0>,
67 Int2Type<1>,Int2Type<2>,Int2Type<3>,Int2Type<4>,Int2Type<5> >constNumbers;
68 showMe( constNumbers() );
69
70 std::cout << "\napply identity: " << std::endl;
71 typedef map<ApplyId, constNumbers >::type idConstNumbers;
72 showMe( idConstNumbers() );
73
74 std::cout << "\nset each value to 10" << std::e ndl;
75 typedef map<MakeTen, constNumbers >::type makeTenConstNumbers;
76 showMe( makeTenConstNumbers() );
77
78 std::cout << "\ndouble each value" << std::endl;
79 typedef map<DoubleMe, constNumbers >::type doubleMeConstNumbers;
80 showMe( doubleMeConstNumbers() );
81
82 std::cout << "\nabsolute value" << std::endl;
83 typedef map<AbsMe, constNumbers >::type absMeConstNumbers;
84 showMe( absMeConstNumbers() );
85
86 };
Vor der Theorie kommt die Praxis. Kompiliert und ausgeführt, ergibt der Quelltext die Ausgabe in Abbildung 4. Das Programm besteht aus der »map« -Metafunktion (Zeile 56), die beliebig viele Argumente annimmt, sie in ein »std::tuple« verpackt und die Metafunktionen »ApplyId« , »MakeTen« , »DoubleMe« und »AbsMe« auf ihre einzelnen Argumente (Zeile 60) anwendet. Das einfache Funktionstemplate »showMe« gibt den Container zu Laufzeit aus.

Abbildung 4: Ganz funktionale Schule: Die in der Templatesprache umgesetzte Map-Funktion wendet eine Funktion auf jedes Element einer Liste an.
Eindeutig funktional
Es zeigt sich: Das Programm hat alles zu bieten, was die funktionale Programmierung auszeichnet (siehe den Artikel “Funktionale Grundzüge” auf Linux-Magazin Online [4].)
Metafunktionen sind:
- Funktionen erster Ordnung, denn als Klassentemplates können Aliase (Zeile 71) auf sie erzeugt und im weiteren Programmverlauf verwendet werden.
- Funktionen höherer Ordnung, denn sie lassen sich als Argument (Zeile 56) oder Returnwert einer Metafunktion verwenden.
- Reine Funktionen, denn es gibt zur Compilezeit keinen veränderlichen Zustand.
Die Kontrollstruktur der funktionalen Programmierung ist die Rekursion über eine Liste. Dabei wird das erste Element verarbeitet und über den Rest weiter iteriert. In der funktionalen Programmierwelt haben sich »head« für den Beginn der Liste und »tail« für deren kompletten Rest etabliert. Diesem Muster folgt »showMe« ab Zeile 49.
Die Struktur »struct Int2Type« in Zeile 7 nimmt eine natürliche Zahl an und verpackt diese in einem Typ. Über »const static int value= v« in Zeile 8 stellt der Typ seinen Wert wieder als integrale Konstante zur Verfügung. Was wie obfuscated C++-Code wirkt, hat einen einfachen Grund: Um das Alias »constNumbers« in Zeile 67 zu definieren, werden Typen benötigt. Der Kunstgriff, eine natürliche Zahl in einem Typ zu verpacken, geht auf Andrei Alexandrescu [5] zurück.
Neben Alexandrescu, der die Mächtigkeit der Template-Metaprogrammierung auf einzigartige Weise in seinem Werk “Modern C++ Design” [6] angewendet hat, sind insbesondere Krzysztof Czarnecki und Ulrich W. Eisenecker zu nennen, die wegen ihrer Veröffentlichung “Generative Programming” [7] als Pioniere dieser neuen Programmiertechnik gelten.
Ungewohnt und neu sind auch die oft verwendeten drei Punkte (Ellipse), die sowohl in »showMe« als auch in »map« auftauchen. Dies sind die so genannten Variadic Templates [3]. Sie bezeichnen Templates, die beliebig viele Argumente annehmen dürfen. Stehen die drei Punkte links vom Bezeichner, werden die Argumente gepackt, rechts entpackt.
Der wohl befremdlichste Ausdruck ist »std::tuple<typename F::template apply <Elements>::type … > type« in Zeile 60. Durch das Entfernen der Schlüsselwörter, die dem C++-Parser bei der Evaluierung des Ausdrucks helfen, wird dieser schon deutlich lesbarer: »std::tuple <F::apply<Elements>::type … > type« . Die Metafunktion »F« und besonders deren Klassentemplate »apply« werden auf jeden Typ von »std::tuple« angewandt. Das Ergebnis ist, dass für jeden Typ »Int2Type« ein neuer Typ erklärt wird.
Im Falle der Metafunktion »DoubleMe« besitzt dieser neue Typ die Eigenschaft, dass seine integrale Konstante verdoppelt ist »typedef Int2Type<2*(T::value)>« . Um das Ergebnis mit »showMe( doubleMeConstNumbers() )« auszugeben, muss der neue Typ instanziiert werden. Dies geschieht zur Laufzeit.
Dieser Ausflug in die Tiefen der C++-Syntax zeigt, dass Template Metaprogramming eine eingebettete, rein funktionale Subsprache in der imperativen Sprache C++ ist.
Gedächtnis inklusive
Der Vergleich einer Laufzeit- und einer Compilezeit-Funktion bringt überraschende Eigenschaften der Template-Instanziierung ans Tageslicht. Als Beispiel dient im Folgenden der klassische Fibonacci-Algorithmus, als Funktion und als Metafunktion implementiert. Der Algorithmus lässt sich in wenigen Zeilen Code ausdrücken (Listing 5). Zudem lässt er sich fast eins zu eins als Compilezeit-Algorithmus implementieren. Lediglich die Bedingungen »if (n==0)« und »if (n==1)« muss der funktionale Programmierer durch die Templatespezialisierung »template<> struct fib<0>« und »template<> struct fib<1>« abbilden (Listing 6).
Listing 5
Fibonacci-Algorithmus zur Laufzeit
01 long int fib(int n){
02 if (n==0) return 0;
03 if (n==1) return 1;
04 return fib(n-1)+fib(n-2);
05 }
Listing 6
Fibonacci-Algorithmus zur Compilezeit
01 template <int n>
02 struct fib{
03 const static long int value= fib<n-1>::value + fib<n-2>::value;
04 };
05
06 template <>
07 struct fib<0>{
08 const static long int value= 0;
09 };
10
11 template <>
12 struct fib<1>{
13 const static long int value= 1;
14 };
Dann ein kleines Hauptprogramm um die beiden Funktionen geschrieben – und es zeigen sich bei Ausführung die Ergebnisse in Abbildung 5 für die zwei Variationen des Fibonacci-Algorithmus. Während die Laufzeit von »FibonacciDynamic« bei höheren Werten von »n« exponentiell wächst, scheint das Verhalten von »FibonacciStatic« konstant zu sein. Das verwundert nicht, muss doch die statische Version ihre Berechnungen zur Compilezeit ausführen, während die dynamische dies zur Laufzeit erledigt.
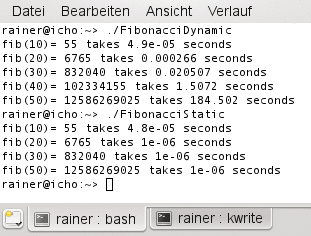
Abbildung 5: Vergleich der Laufzeit- und der Compilezeit-Umsetzung des Fibonacci-Algorithmus.
Ein Blick auf den Zeitbedarf beim Übersetzen verblüfft aber doch: Die statische Variante benötigt eine ähnlich kurze Compilezeit wie die dynamische (Abbildung 6). Das Rätsel ist schnell gelöst: Während die dynamische Variante in jeder Rekursion beide Werte nochmals berechnet, verwendet die statische einmal berechnete Werte wieder. Sie baut ein Gedächtnis auf. Dadurch besitzt sie ein lineares Compilezeit-Verhalten.
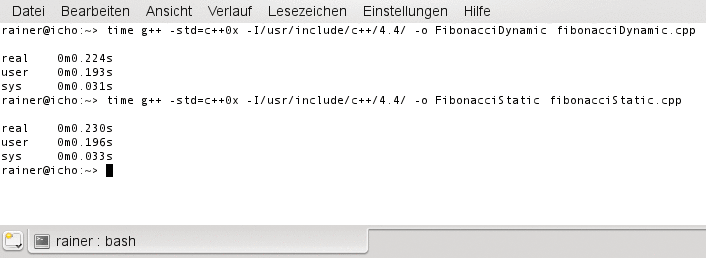
Abbildung 6: Das Übersetzen von Template-Programmen benötigt nicht zwangsläufig mehr Zeit: Compilezeit-Vergleich der verschiedenen Fibonacci-Implementierungen.
Der wichtigste Anwendungsbereich der Template-Metaprogrammierung besteht aber nicht darin, numerische Werte zur Compilezeit zu ermitteln, sondern Programme zu schreiben, die sich selbst optimieren.
Reflexion
Reflexion bezeichnet die Fähigkeit eines Programms, seine Struktur zu kennen (Introspection) und gegebenenfalls anzupassen (Intercession). Sie ist die Grundlage für selbstadaptive Systeme. Hier spielt Template Metaprogramming seine wahre Stärke aus – insbesondere mit der neuen Bibliothek »type_traits« [8] des kommenden C++0x-Standards, die von neueren GCC-Versionen angeboten wird. Sie erlaubt es, Typ-Eigenschaften abzufragen, sie zu vergleichen und zu modifizieren, was die Grundlage für automatische Code-Anpassungen zur Compilezeit bildet. Der Kopieralgorithmus in Listing 7 stellt dies exemplarisch dar.
Listing 7
Kopieralgorithmus für Container
01 #include <string.h>
02 #include <chrono>
03 #include <iostream>
04 #include <type_traits>
05
06 namespace my{
07 template<typename I1, typename I2, bool b>
08 I2 copy_imp(I1 first, I1 last, I2 out, const std::integral_constant<bool, b>&){
09 while(first != last){
10 *out = *first;
11 ++out;
12 ++first;
13 }
14 return out;
15 }
16
17 template<typename T>
18 T* copy_imp(const T* first, const T* last, T* out, const std::true_type&){
19 memcpy(out, first, (last-first)*sizeof(T));
20 return out+(last-first);
21 }
22
23 template<typename I1, typename I2>
24 I2 copy(I1 first, I1 last, I2 out){
25 typedef typename std::iterator_traits<I1>::value_type value_type;
26 return copy_imp(first, last, out, std::has_trivial_assign<value_type>());
27 }
28 }
29
30 const int arraySize = 1000;
31 const int counter=100000;
32
33 int intArray[arraySize] = {0,};
34 int intArray2[arraySize]={0,};
35 int* pArray = intArray;
36 const int* pArray2 = intArray2;
37
38 int main(){
39
40 auto begin= std::chrono::monotonic_clock::now();
41 for(int i = 0; i < counter; ++i){
42 my::copy(pArray2, pArray2 + arraySize, pArray);
43 }
44 auto last= std::chrono::monotonic_clock::now() - begin;
45 std::cout << " takes " << std::chrono::duration<double>(last).count() << " seconds" << std::endl;
46
47 begin= std::chrono::monotonic_clock::now();
48 for(int i = 0; i < counter; ++i){
49 my::copy(intArray2, intArray2 + arraySize, intArray);
50 }
51 last= std::chrono::monotonic_clock::now() - begin;
52 std::cout << " takes " << std::chrono::duration<double>(last).count() << " seconds" << std::endl;
53
54 }
Das Programm kopiert zwei Arrays der Länge 1000, und dies genau 100000-mal. Es initialisiert beide Arrays mit 0, auf das erste Array greift es direkt, auf das zweite jedoch mit einem Pointer zu. Der indirekte Zugriff bewirkt, dass für das erste Array ein optimierter Kopieralgorithmus Anwendung findet (Zeile 18), für das zweite Array (Zeile 7) aber nur der Default-Kopieralgorithmus. Dieser Algorithmus kopiert jedes Element (Zeilen 9 bis 13) einzeln, während der optimierte ganze Datenblöcke (Zeile 19) mit der C-Funktion »memcpy()« [9] dupliziert. Dazu verwenden beide Implementierungen die C++-Iteratoren »first« , »last« und »out« , um mit den Containern der Standard Template Library (STL) kompatibel zu sein. Das Ergebnis kann sich sehen lassen (Abbildung 7): Der optimierte Algorithmus ist nahezu um den Faktor 20 schneller.

Abbildung 7: Die Laufzeiten der Kopieralgorithmen unterscheiden sich beträchtlich.
Der Hintergrund: Der Compiler wertet in dem Ausdruck »copy_imp(first, last, out, std::has_trivial_assign<value_type>())« (Zeile 26) die Eigenschaften des Quell- und Zieltyps aus, um abhängig von dessen Eigenschaften die passende Implementierung für »my::copy_imp« (Zeilen 8 und 18) zu verwenden. Entscheidungskriterien für den Compiler, den optimierten Kopieralgorithmus zu verwenden, sind:
- Die Iteratoren müssen Pointer sein: »const T* first, const T* last, T* out« (Zeile 18).
- Die Iteratoren müssen auf die gleichen Typen verweisen: »const T* first, const T* last, T* out« (Zeile 18) enthält nur einen Typ »T« , im Gegensatz zu den zwei Typen »I1« und »I2« in »I1 first, I1 last, I2 out« (Zeile 8).
- Die Elemente des Containers müssen einen trivialen, vom Compiler automatisch erzeugten Zuweisungsoperator besitzen »const std::true_type&« (Zeile 18).
Entrollt
Die Auflösung von Schleifen, besser bekannt unter dem Namen Loop Unwinding oder Loop Unrolling [10], ist eine beliebte Technik, um an der Performance-Schraube des Executable zu drehen. Auch hierfür lässt sich Template Metaprogramming einsetzen. Darüber hinaus zeigt das Listing 8 schön, wie sich Compile- und Laufzeit-Berechnung in einem Algorithmus elegant kombinieren lassen.
Listing 8
Die Power-Funktion
01 #include <iostream>
02
03 inline int power(const int& m, int n){
04 int r = 1;
05 for(int k=1; k<=n; ++k) r*= m;
06 return r;
07 }
08
09 template<int m, int n>
10 struct Power{
11 enum { value = Power<m,n-1>::value * m };
12 };
13
14 template<int m>
15 struct Power<m,0>{
16 enum { value = 1 };
17 };
18
19 template<int n>
20 inline int power(const int& m){
21 return power<n-1>(m) * m;
22 }
23
24 template<>
25 inline int power<1>(const int& m){
26 return m;
27 }
28
29 template<>
30 inline int power<0>(const int& m){
31 return 1;
32 }
33
34 int main(){
35 std::cout << "power(2,10): " << power(2,10) << std::endl;
36 std::cout << "power<10>(2): " << power<10>(2) << std::endl;
37 std::cout << "Power<2,10>::value: " << Power<2,10>::value << std::endl;
38 }
Die drei verschiedenen Aufrufe »power (2,10)« , »power<10>(2)« und »Power <2,10>::value« führen zum gleichen Ergebnis (Abbildung 8). Trotzdem gibt es feine Unterschiede. Während »power (2,10)« zur Laufzeit berechnet wird, erfolgt die Evaluierung von »Power <2,10>::value« zur Compilezeit.

Abbildung 8: Lauf- und Compilezeit-Varianten der Power-Funktion.
Zu welchem Zeitpunkt findet aber die Auswertung von »power<10>(2)« statt? Zur Lauf- und zur Compilezeit: Das Template-Argument »10« wird zur Compilezeit ausgewertet, das Funktionsargument »2« zur Laufzeit. Das Evaluieren des Template-Arguments bewirkt, dass zur Laufzeit lediglich das Funktionsargument in die aufgelöste Schleife »m*m*m*m*m*m*m*m*m*m« eingesetzt werden muss.
Mächtige DSEL
Ziel dieses Artikels war es zum einen, die Techniken hinter Template Metaprogramming zu vermitteln, zum anderen, deren Innovationskraft für C++ aufzuzeigen. Die wahre Stärke von Template Metaprogramming liegt in seinen Eigenschaften einer Domain Specific Embedded Language (DSEL). Das bezeichnet eine Sprache, die auf eine spezielle Domäne ausgerichtet und zudem in die Gastgebersprache eingebettet ist. Anders ausgedrückt: Es ist mit Template Metaprogramming möglich, in der Universalsprache C++ eine mächtige, spezielle Subsprache für besondere Anwendungsbereiche zu definieren. Das Schöne daran ist, dass sowohl die Gast- als auch die Gastgebersprache der C++-Syntax genügen.
Bekannte Beispiele sind die hochperformante Bibliothek Blitz++ [11] für Array-Berechnungen und der Parser-Generator Spirit [12]. Blitz++ bricht durch Template Metaprogramming in die Performance-Domäne von Fortran-Bibliotheken ein [13]. Die Boost-Bibliothek Spirit ermöglicht es, die Grammatik des Parsers vollständig in C++-Syntax zu formulieren. Beide wenden die auf Template Metaprogramming beruhenden Expression Templates [14] an.
Infos
- Erwin Unruh, “Primzahlen”: http://www.erwin-unruh.de/primorig.html
- Rainer Grimm, “Reichhaltiges Angebot”: Linux-Magazin 05/10, S. 110
- Rainer Grimm, “Erfrischend neu”: Linux-Magazin 04/10, S. 116
- Rainer Grimm, “Funktionale Grundzüge”: https://www.linux-magazin.de/Online-Artikel/Funktionale-Programmierung-1-Grundzuege
- Andrei Alexandrescu, “On mappings between types and values”: C/C++ Users Journal, 08/2000
- Andrei Alexandrescu, “Modern C++ Design”: http://www.moderncppdesign.com
- Krzysztof Czarnecki und Ulrich W. Eisenecker, “Generative Programming”: http://www.generative-programming.org
- Bibliothek »type_traits« : http://publib.boulder.ibm.com/infocenter/comphelp/v9v111/index.jsp?topic=/com.ibm.xlcpp9.aix.doc/standlib/header_type_traits.htm
- Memcpy: http://www.cplusplus.com/reference/clibrary/cstring/memcpy/
- Loop Unwinding: http://en.wikipedia.org/wiki/Loop_unwinding
- Bibliothek Blitz++: http://www.oonumerics.org/blitz/
- Bibliothek Spirit: http://boost-spirit.com/home/
- Benchmarks Blitz++: http://www.oonumerics.org/blitz/benchmarks/
- Expression Templates: http://www.angelikalanger.com/Articles/Cuj/ExpressionTemplates/ExpressionTemplates.htm





