
Abbildung 1: Sofa bietet eine intuitive Bedienoberfläche und will damit nicht nur professionelle Statistiker ansprechen, sondern auch Neulingen den Einstieg erleichtern.
Statistik muss kein harter Ritt sein: Sofa kümmert sich um Profis und Einsteiger. Um sprachliche Schwierigkeiten dagegen sorgt sich After the Deadline. Ein Rote-Beete-Salat füllt den Vitaminhaushalt vor dem Winter noch mal richtig auf.
Abbildung 1: Sofa bietet eine intuitive Bedienoberfläche und will damit nicht nur professionelle Statistiker ansprechen, sondern auch Neulingen den Einstieg erleichtern.
Statistik? Da nehmen meist nicht nur Normalsterbliche Reißaus, auch abgebrühte Nerds sind mit diesem Teilgebiet der Mathematik häufig überfordert. Es gilt, gleich mehrere Hürden zu nehmen: Die graue Theorie, die sich oft nur durch stures Auswendiglernen verinnerlichen lässt, und dann noch die Bedienung der Software, die alles in die Praxis umsetzt – der Kopf- oder Taschenrechner ist heute auch in den Reihen der hartgesottenen Statistiker die Ausnahme.
Abhilfe in Sachen Software bietet R ([1], [2]). Seit 1992 empfiehlt sich die freie Umsetzung der Statistik-Programmiersprache S. Wer nicht zu den bedingungslosen Freunden spartanischer Kommandozeilentools gehört, kann allerdings selbst mit statistischem Hintergrundwissen im ersten Moment nicht viel mit R anfangen, denn es gilt, zunächst die Sprache selbst zu lernen.
Eine Alternative ist das kommerzielle Programm SPSS [3], das jedoch selbst von Studenten einen dreistelligen Betrag für die Lizenzierung fordert.
Statistik für alle
Freie Statistiksoftware mit intuitiver Oberfläche verspricht dagegen das Projekt Sofa (Statistics Open For All, [4]). Ziel ist, Statistikern ein leicht bedienbares Tool an die Hand zu geben. Darüber hinaus wollen die Entwickler um den Neuseeländer Grant Paton-Simpson mit Sofa auch Statistikneulinge in dieses schwierige Feld einführen (Abbildung 1).
Die Statistik ist wie andere Felder der Mathematik vor allem eine Hilfswissenschaft und wird in vielen Bereichen zur Interpretation empirischer Schätzungen eingesetzt. Beispielsweise kann man so anhand einer Folge von Ergebnissen berechnen, mit welcher Wahrscheinlichkeit ein Würfel gezinkt ist. Auch eine Voraussage für Sozialwissenschaftler ist möglich, um im Vorfeld zu sehen, ob eine Umfrage aussagekräftig ist oder lediglich Zufallswerte ausspuckt. Es gibt zahlreiche statistische Tests mit unterschiedlichen Stärken und Schwächen, die einzuordnen allerdings der Fachwelt vorbehalten bleibt.
Generell gelten derlei statistische Tests als unverzichtbar, weil die menschliche Intuition oftmals Fehleinschätzungen unterliegt. Ein anschauliches Beispiel hierfür ist der so genannte Monte-Carlo-Fehlschluss. Er führt zur fälschlichen Annahme von Zusammenhängen und daraus resultierenden Wahrscheinlichkeitsverschiebungen zwischen tatsächlich unzusammenhängenden Ereignissen – beispielsweise zwischen dem Ergebnis eines kommenden Würfelwurfs und den vorherigen Resultaten mit demselben Würfel.
Um solchen und komplexeren Problemen zu begegnen, unterstützt Sofa Standards wie Anova (Analysis of Variance, Varianzanalyse), Pearson’s Chi-Square-Test, T-Tests und eine Reihe weiterer Verfahren. Außerdem liefert das Statistiktool grundlegende Werte wie Durchschnitt, Median, Standardabweichung, Summe, Maximum, Minimum und mehr für numerische Datenreihen.
Verwandlungskünstler
Wie erwähnt liegt die Stärke von Sofa nicht in der reinen Funktionalität – alle angeführten Features bieten R & Co. ebenfalls. Vielmehr überzeugt das freie Statistiktool durch seine bequeme Zugänglichkeit sowie seine Im- und Export-Möglichkeiten. Sofa liest Daten aus einer SQL-Datenbank (MySQL, SQLite und PostgreSQL), aus Open-Document-Spreadsheet-Dokumenten (wie sie unter anderem Open Office verwendet) und aus MS Access ein.
Ergebnisse präsentiert das Programm zum Beispiel im HTML-Format und setzt dabei auf Javascript, um gezielt Datenreihen bei Berührung mit der Maus hervorzuheben. So integriert der Anwender seine Statistiken direkt in eine Webseite. Alternativ überträgt er Ergebnisse aus Sofa per Copy & Paste nach Open Office Calc und Microsoft Excel.
Aussehen und Inhalt der Sofa-Berichte definiert der Benutzer mit wenigen Mausklicks (siehe Abbildung 2). Darüber hinaus automatisiert die Software den Output dank Python, sodass beispielsweise zusätzliche Daten direkt zu einem neuen Programm auf dem Weblog führen.
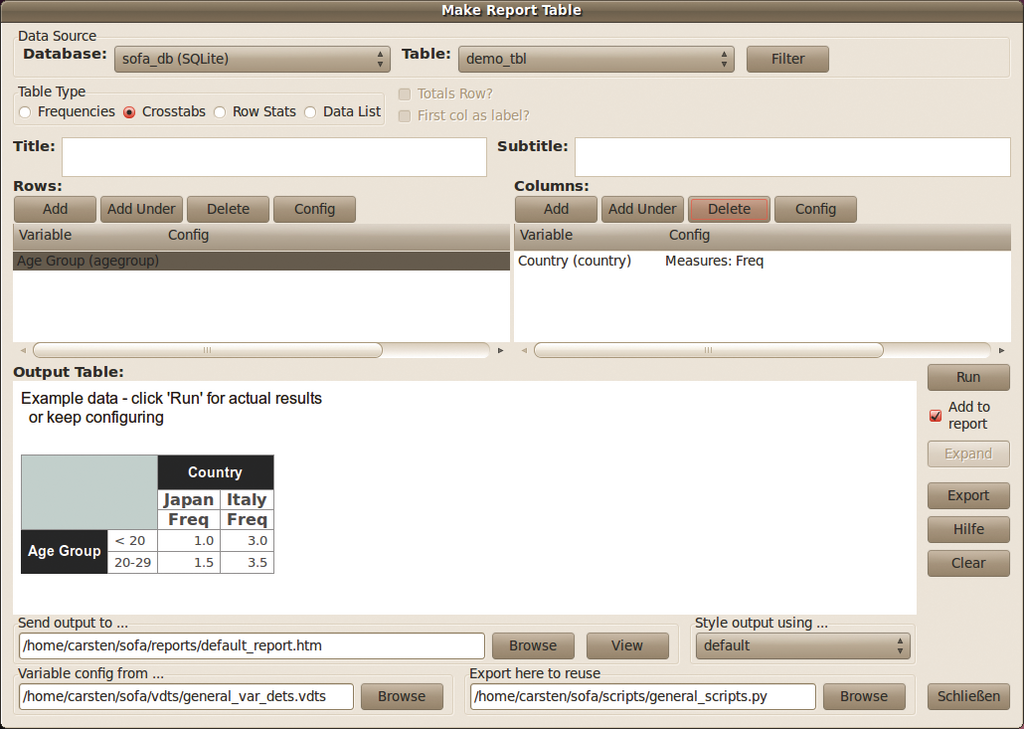
Abbildung 2: Sofa erstellt Berichte in verschiedenen Dateiformaten. Um einen Report zu generieren, wählt der Anwender lediglich die entsprechenden Daten und die Darstellungsform aus.
Funktionalität und Usability
Bei der Umsetzung der durch Javascript bereicherten HTML-Ausgabe erhält Sofa Unterstützung vom ebenfalls freien Dojo-Toolkit [5]. Sofa selbst ist in Python implementiert und läuft daher nicht nur unter Linux, sondern auch auf anderen Plattformen. Auf der Homepage stehen fertige Pakete für Ubuntu, Windows und Mac OS X sowie der Quellcode des Programms zum Download bereit.
Für künftige Programmversionen sind der Export ins Oracle-Datenbankformat und zusätzliche Diagrammtypen geplant. Zudem soll eine Plugin-Architektur die Integration weiterer Statistikfunktionen erleichtern. Die Sofa-Entwickler verfolgen außerdem konsequent ihr ursprüngliches Ziel, nämlich Einsteigern die statistischen Methoden nahezubringen. Für diese Zwecke soll das Tool in Zukunft Tipps zu typischen Anwendungsfällen und grafische Beispiele liefern.
Auch die Internationalisierung soll weiter fortschreiten: Während Sofa bisher nur auf Englisch und Galizisch zur Verfügung steht, sollen weitere Sprachen bald folgen. Wer an der Übersetzung mitwirken oder die Sofa-Entwicklung auf andere Weise fördern möchte, kann mit dem Entwickler über die Projekt-Homepage Kontakt aufnehmen. Grant Paton-Simpson ermutigt Anwender ausdrücklich dazu, auch Probleme zu melden und an den Abstimmungen auf den Open-Source-Portalen Freshmeat und Sourceforge teilzunehmen.
Lippenbekenntnis
Einen praktischen Anwendungsfall ausgefeilter statistischer Methoden bietet die automatische Verarbeitung natürlicher Sprachen. Nachdem erste Anwendungen in diesem Feld, zum Beispiel die automatische Übersetzung, Textzusammenfassung und Korrektur, schnell an ihre Grenzen stießen, dominiert seit einiger Zeit ein neuer Ansatz die Forschung: statistische Modelle. Schrieb man bisher die in jeder Sprache unfassbar komplizierten Regeln von Hand auf, nur um immer wieder auf neue Ausnahmen und Zuätze zu stoßen, sollen Programme nun mit statistischen Methoden anhand existierender Texte lernen.
Der Vorteil solcher statistischer Sprachmodelle besteht darin, dass sie praktisch keine manuelle Vorarbeit benötigen. Eine möglichst große Textmenge zum Lernen genügt. Der damit eingehergehende Nachteil liegt auf der Hand: Eine obere Grenze für die Textmenge gibt es nicht, aber wenigstens ein paar Hundert MByte Text sollten es schon sein. Daher benötigt ein solches System relativ viel Platz – sowohl auf der Festplatte, als auch im Arbeitsspeicher -, was insbesondere mobile Geräte vor Probleme stellt.
Somit eignen sich auf Statistik basierende Programme zur Grammatik- und Rechtschreibkontrolle eher weniger als Korrekturfunktion für den Desktop. Wer möchte schon auf einem schlanken Client den Ressourcenbedarf seiner Textverarbeitung nur für diese eine Funktion vervielfachen?
Die Alternative ist eine reine Rechtschreibprüfung, die mit einem Wörterbuch abgleicht und meldet, wenn sie auf Unbekanntes stößt. Die so gefundenen Missgriffe sind eher von einfacher Natur. Fehler im Satzbau, stilistische Unzulänglichkeiten, Grammatikfehler und der falsche Gebrauch existierender Wörter bleiben unentdeckt.
Als Abhilfe liefern manche kommerzielle Textverarbeitungsprogramme regelbasierte Grammatik-Checker mit, aber wie bereits erwähnt, solche manuellen Definitionen können niemals alle Regeln der natürlichen Sprachen erfassen.
Einsendeschluss für Vertipper
After the Deadline [6] bietet eine innovative Lösung für Anwender mit (schnellem) Internetanschluss. Der freie Webdienst nimmt Texte entgegen und liefert Korrekturvorschläge zurück. Namengeber für das Programm ist übrigens die gleichnamige Kolumne der “New York Times”, die sich mit stilistischen Unzulänglichkeiten im Alltags-Englisch befasst.
Ein 1 GByte großes statistisches Sprachmodell residiert im Arbeitsspeicher der Serverkomponente, so bleiben die Ansprüche an den Client minimal. Auf Benutzerseite ist lediglich ein Programm erforderlich, das auf den Onlinedienst zugreift. Diesen Job erledigen Plugins für die Textverarbeitung Open Office, für die Browser Firefox und Google Chrome sowie für die Blogging-Software WordPress. Zusätzlich stehen Erweiterungen für Jquery und Tiny MCE bereit, mit deren Hilfe Anwender den Spellchecker in Website-Formulare einbinden. Dank offener Standards und Quelltexte steht der Entwicklung weiterer Schnittstellen nichts im Weg.
Abbildung 3 zeigt die Einrichtungsmöglichkeiten für die Open-Office-Erweiterung. After the Deadline stellt eine lange Liste optionaler stilistischer Prüfungen bereit, welche die Kernfunktionen ergänzen. Diese Tests warnen beispielsweise vor übermäßig komplizierten Schachtelsätzen, Nominalisierungen (Hidden Verbs) und Passivsätzen.
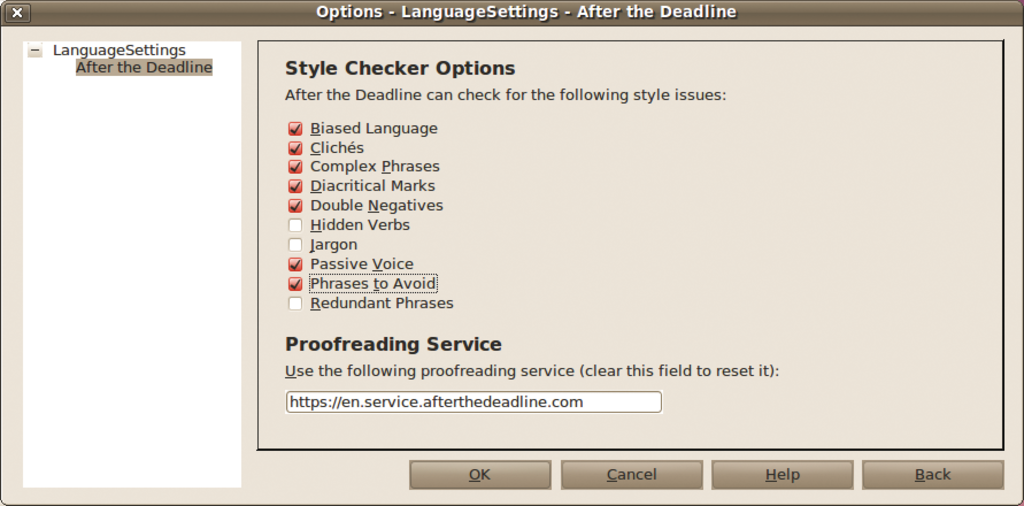
Abbildung 3: Das Open-Office-Plugin für After the Deadline erlaubt neben der Suche nach Schreibfehlern auch stilistische Korrekturen.
Fehlervielfalt
Das von After the Deadline verwendete Sprachmodell basiert auf Bigrammen, also Sequenzen aus jeweils zwei Wörtern. Ihre relative Häufigkeit im Trainings-Corpus repräsentiert die Wahrscheinlichkeit ihres Auftretens in einem neuen Text. Dazu haben die Entwickler Texte von Wikipedia, des Gutenberg-Projekts und zahlreicher Weblogs automatisch ausgewertet. Hinzu kommt ein Trigramm-basiertes Sprachmodell, das bei der Suche nach leicht zu verwechselnden – beispielsweise gleich klingenden – Wörtern zum Einsatz kommt (Abbildung 4).
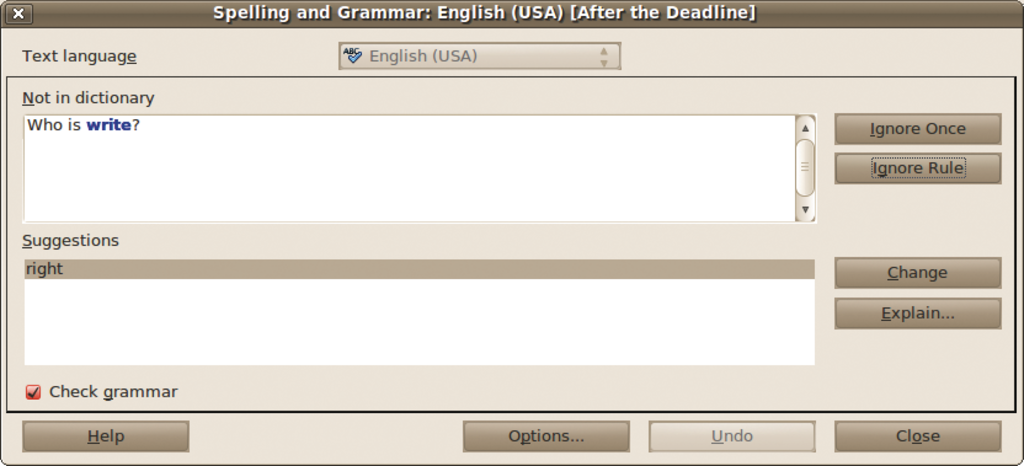
Abbildung 4: Auch ein bekanntes Wort kann je nach Kontext falsch sein: After the Deadline erkennt Verwechslungen, die auf gleich klingender Aussprache verschiedener Wörter beruhen.
Die gewonnenen Wahrscheinlichkeitswerte dienen zunächst dazu, bei unbekannten Wörtern den besten Korrekturvorschlag zu liefern. Neben der Wahrscheinlichkeit für ein Wort im jeweiligen Kontext, also unter Berücksichtigung des vorhergehenden und des nachfolgenden Begriffs, bezieht After the Deadline weitere Faktoren in die Berechnung mit ein, beispielsweise die Anzahl der Änderungen, um aus dem falsch geschriebenen ein anderes Wort zu erzeugen, die Übereinstimmung der ersten Buchstaben und die kontextunabhängige Häufigkeit eines Worts. Ein neuronales Netz hilft dann bei der Einschätzung für die Verbesserungsvorschläge.
Für weitergehende Prüfungen greift allerdings auch After the Deadline auf manuell erstellte Regeln zurück und hat zu diesem Zweck das bereits seit 2003 entwickelte Language Tool [7] integriert, das auch als unabhängige Open-Office-Erweiterung zur Verfügung steht. Darüber hinaus kann After the Deadline Texte sinnvoll unterteilen und daraus etwa Vorschläge für Absatzgrenzen ableiten.
Unbegrenzte Möglichkeiten
Wer die Fähigkeiten des Programms unter die Lupe nehmen möchte, kann After the Deadline unter [8] erst einmal online in einem Webformular testen. Auch die erwähnten Plugins arbeiten auf Wunsch mit einem Server des Projekts zusammen, sind damit allerdings auf Englisch und die rein private Nutzung beschränkt. Anwender, die den Stil- und Sprachprüfer kommerziell und mehrsprachig einsetzen möchten, finden auf der Projektwebseite Anleitungen zur Installation der Serverkomponente.
Die unter der GPL stehende Software setzt außer Suns Java in Version 1.6.0 noch 1,5 GByte RAM für die Low-Memory-Variante beziehungsweise 4 GByte RAM für die Vollversion voraus. Erstere eignet sich vor allem für kurze Dokumente und eine beschränkte Anzahl von Clientzugriffen. Außer der Software selbst sind auch einige Sprachmodelle frei verfügbar. After the Deadline spricht nicht nur Englisch, sondern auch Niederländisch, Französisch, Deutsch, Indonesisch, Italienisch, Polnisch, Portugiesisch, Spanisch und Russisch.
Kommende Versionen der Software sollen in der Lage sein, versehentlich weggelassene Wörter zu finden. Außerdem ist geplant, dass der Server seine Sprachmodelle automatisch regelmäßig erweitert, um deren Qualität stetig zu steigern. Darüber hinaus ist eine Verbesserung der Plugins vorgesehen sowie eine Funktion, welche die Texte schon während der Eingabe auf Fehler hin prüft. Wer dabei mithelfen oder eigene Ideen beisteuern möchte, findet auf der Projekt-Homepage eine Anlaufstelle.
Rote-Beete-Salat
Sie enthalten Vitamin B, Kalium, Eisen und Folsäure und sind ein wichtiger Bestandteil von Labskaus und Borschtsch – Rote Beete, auch rote Rüben genannt. Als leckerer Salat passen sie gut zu Grillgerichten oder Fisch. Für dieses Rezept werden sie gekocht, man kann sie aber auch als Rohkost essen.
Zutaten: 3 mittelgroße Knollen Rote Beete, 1 großer Apfel, 1 große Zwiebel, Öl, Essig, Senf, Salz, Pfeffer und Zucker. Das Grün der Rüben nicht zu dicht an der Knolle abmachen, sondern ein paar Zentimeter stehen lassen. Außerdem empfiehlt es sich, die Blätter nicht abzuschneiden, sondern abzudrehen, damit die Knolle nicht ausblutet. Das Gemüse abbürsten und ungeschält in einen Topf geben, mit Wasser bedecken und mit Deckel zirka 20 bis 30 Minuten kochen.
Mit einem scharfen Messer testen, ob das Gemüse weich und somit gar ist. Danach das Wasser abschütten und die Knollen noch im heißen Zustand schälen – so geht die Schale leichter ab. Wer Angst vor roten Fingern hat, sollte Einmal-Handschuhe tragen. Nicht umsonst wurden Rote Beete früher als Färbemittel verwendet.
Den Apfel schälen und in dünne Streifen schneiden, Zwiebel schälen und fein würfeln, die erkalteten Rote-Beete-Knollen ebenfalls in dünne Streifen schnippeln und alles mischen.
Für das Dressing 3 Esslöffel Öl mit 2 Esslöffel Essig und 1 Teelöffel Senf cremig rühren, mit Salz, Pfeffer und Zucker abschmecken. Danach über den Salat geben und unterheben. Der Rote-Beete-Salat sollte 24 Stunden ziehen; in dieser Zeit immer mal wieder durchrühren – und natürlich probieren, auch auf die Gefahr hin, dass die Schüssel beim Servieren nur noch halb so voll ist. (hej)
|
Infos |
|---|
|
[1] Statistiksoftware R: [http://www.r-project.org] [2] Gerrit Eichner, Volker Schmitt, “R wie Rechenriese”: Linux-Magazin 09/08, S. 40 [3] SPSS: [http://www.spss.com] [4] Sofa-Projekt: [http://www.sofastatistics.com] [5] Dojo-Toolkit: [http://www.dojotoolkit.org] [6] After the Deadline: [http://afterthedeadline.com] [7] Language Tool: [http://www.languagetool.org] [8] After the Deadline, Online-Spellchecker: [http://www.polishmywriting.com] |





