
© Ariadna De Raadt, 123RF.com
C++0x bringt nicht nur Veränderungen in der Kernsprache. Die Standardbibliothek der C++-Neuausgabe hat Multithreading, asynchrone Funktionsaufrufe, reguläre Ausdrücke und vieles mehr im Angebot .
Der demnächst fertige C++-Standard C++0x hat viel zu bieten – nicht nur auf Ebene der Kernsprache, die Teil 1 dieses Artikel behandelte [1]. Mit Bibliotheken fürs Threading, für reguläre Ausdrücke und zum Template Metaprogramming stößt die Sprache auch in neue Einsatzgebiete vor. Daneben runden Bibliotheken zu Smart Pointern, Containern und Funktions-Wrappern bereits vorhandene Konzepte in C++ ab, sodass sich C++0x im Ganzen deutlich reifer zeigt.
Eine der größten Herausforderungen, denen sich eine moderne Programmiersprache stellen muss, ist die Allgegenwart von Multicore-Prozessoren. Herb Sutter, Vorsitzender des ISO-C++-Standardisierungskomitees, wies bereits 2004 darauf hin, dass Software-Entwickler nicht mehr automatisch von schnelleren CPUs profitieren – sie müssen ihre Arbeitsweise an die Mehrkernprozessoren anpassen. Sutter: “The free lunch is over.” [2]
Multithreading inklusive
C++0x begegnet der Mehrkern-Herausforderung unter anderem mit einem Memory-Modell in der Kernsprache. Ein solches Modell definiert, wie Threads auf Speicher interagieren und sich synchronisieren. Es liefert den Compiler-Bauern die Grundlage für Code-Optimierungen. Die recht anspruchsvollen Details rund um das neue Memory-Modell sowie die neuen atomaren Datentypen und Funktionen sind in der Artikelsammlung von Hans Böhm unter [3] nachzulesen.
Jenseits der Kernsprache, im Umgang mit der Threading-Bibliothek, gibt sich die neue Funktionalität schon vertrauter: C++0x besitzt die Threading-Bausteine, die aus anderen Bibliotheken bekannt sind. Der »std::thread« in Listing 1 wird über das Funktionsobjekt »Work()« parametrisiert und ausgeführt. Ein anschließendes »std::join« synchronisiert den neuen Thread mit dem Vater-Thread. Aber auch für das Lösen der Lebenszeit des neuen Thread vom Vater-Thread bietet C++0x Unterstützung.
|
Listing 1: Starten eines |
|---|
01 class Work{
02 public:
03 void operator()(int i,std::string s,std::vector<double> v){ ... }
04 };
05
06 std::thread t(Work(),42,"hello",std::vector<double>(23,3.141));
07 t.join();
|
Mutexe schaffen Ordnung
Mutexe helfen die Synchronisation gemeinsam genutzter Variablen zwischen Threads zu gewährleisten. Das Mutex in Zeile 5 von Listing 2 versucht das Lock in der Funktion »foo« 3 Millisekunden lang zu erhalten und führt die Funktion »process(data)« abhängig davon aus. Das »std::time_mutex« verwendet die neue Funktion »std::chrono«.
Mutexe sollte der Entwickler nicht direkt, sondern besser über den Wächter »std::unique_lock« einsetzen. Dieser Wächter bindet das Mutex in seinem Konstruktor und gibt es in seinem Destruktor automatisch wieder frei. Bekannt ist dieses C++-Idiom, eine kritische Ressource in einem Objekt zu kapseln, unter dem Namen RAII [4].
Neben einem nicht freigegebenen Lock sind Deadlocks [5] ein häufiges Problem bei Threads. Ein Deadlock kann entstehen, wenn mindestens zwei Threads die gleichen Locks in verschiedener Reihenfolge anfordern. Dagegen demonstriert Listing 3 ein probates Mittel, denn durch den Aufruf von »std::lock« in Zeile 4 erhält der aufrufende Thread entweder beide Locks (»a.m« und »b.m«) oder gar keines. Greifen die Threads auf eine gemeinsam genutzte Variable nur lesend zu, so genügt es, die Variablen beim Initialisieren vor konkurrierenden Zugriffen zu schützen. In Listing 4 stellt »std::once_flag« in Kombination mit »std::call_once« sicher, dass die Methode »createInstance« nur einmal ausgeführt wird, und dies vor allem Thread-sicher.
Dieser ganze Synchronisationsaufwand ist nicht notwendig, wenn jeder Thread seine eigene Kopie der Variablen besitzt. C++0x unterstützt zu diesem Zweck Thread-lokale Daten. Daneben gibt es Bedingungsvariablen, die die einfache Synchronisation von Threads durch Events erlauben. Den einfachen Umgang mit Threads kann man sehr schön in “Simpler Multithreading in C++0x” von Anthony Williams [6] nachlesen.
|
Listing 2: Mutex und |
|---|
01 std::timed_mutex m;
02 my_class data;
03
04 void foo(){
05 std::unique_lock<std::timed_mutex> lk(m,std::chrono::milliseconds(3));
06 if(lk) process(data);
07 }
|
|
Listing 3: Atomares Locken |
|---|
01 void foo(X& a,X& b){
02 std::unique_lock<std::mutex> lock_a(a.m,std::defer_lock);
03 std::unique_lock<std::mutex> lock_b(b.m,std::defer_lock);
04 std::lock(lock_a,lock_b);
05
06 // do the whole work with a and b
07 }
|
Asynchron
Relativ spät fanden die asynchronen Funktionsaufrufe Eingang in C++0x. Sie gestatten es auf elegante Art, einen Job in einem neuen Thread zu starten und das Ergebnis später abzuholen. Das Objekt, das den Wert produziert, wird Promise, das Objekt, das den Wert einfordert, Future genannt. Das Programmschnipsel in Listing 5 verdeutlicht den Zusammenhang.
Die Funktion »asyncFun«, die über »std::promise<int>« parametrisiert wird, setzt das Ergebnis, das auch eine Exception sein kann. Der Thread in Zeile 13 startet die Funktion. Das Future verbindet sich mit dem Promise durch den Aufruf »intPromise.get_future« und holt sich durch »intFuture.get()« das Ergebnis der Funktion. Wenn das Promise seinen Wert noch nicht berechnet hat, blockiert dieser Aufruf.
Mit »std::async« [7] bietet C++0x – aller Voraussicht nach – eine einfache Schnittstelle für den Umgang mit asynchronen Funktionsaufrufen.
|
Listing 4: Einmaliges |
|---|
01 class MyClass{
02 int i;
03 public:
04 MyClass(int i_):i(i_){}
05 };
06 std::once_flag flag;
07
08 void createInstance(){
09 p=new MyClass(17);
10 }
11
12 void bar(){
13 std::call_once(flag,createInstance);
14 }
|
|
Listing 5: Promise und |
|---|
01 void asyncFun(std::promise<int> intPromise){
02 int result;
03 try {
04 // calculate the result
05 intPromise.set_value(result);
06 } catch (MyException e) {
07 intPromise.set_exception(std::copy_exception(e));
08 }
09 }
10
11 std::promise<int> intPromise;
12 std::unique_future<int> intFuture = intPromise.get_future();
13 std::thread t(asyncFun, std::move(intPromise));
14 // do some other stuff
15 int result = intFuture.get(); // may throw MyException
|
Reguläre Ausdrücke
Wie die neue Threading-Funktionalität in C++0x aus anderen Programmiersprachen schon bekannt ist, so auch die regulären Ausdrücke. Sie sind das Mittel der Wahl, um Text effizient zu verarbeiten, und doch waren sie in der Standardbibliothek von C++ bisher nicht verfügbar. Die meisten C++-Entwickler haben sich mit einer String-Toolsammlung beholfen.
Der Umgang mit regulären Ausdrücken in C++0x lässt sich in drei Schritte (Listing 6) zerlegen:
- »std::regex rgx« enthält den regulären
Ausdruck - »std::smatch match« erhält das Ergebnis der
Suche - »std::regex_search« verarbeitet das Suchergebnis
weiter
Der Ausdruck »std::regex rgx(R”d+”)« verwendet die mit C++0x neuen so genannten Raw-String-Literale. »d« steht dabei in regulären Ausdrücken für eine Ziffer. Dementsprechend steht der Ausdruck »d+« für ein Wort, das mindestens eine Ziffer enthält.
Der String folgt standardmäßig der ECMA-Skriptgrammatik, es lassen sich aber auch andere Grammatiken verwenden. »std::smatch match« erhält das Ergebnis der Suche und bietet ein reiches Interface an: Es lässt sich unter anderem nach dem Gesamttreffer, dessen Position, seinem Suffix oder Präfix, seiner Länge oder auch Teiltreffern in dem zu analysierenden String fragen. Neben »std::regex_search«, das den ersten Treffer »std::string(“123A43”)« sucht, verlangt »std::regex_match« einen genauen Treffer und gibt ein Boolean zurück. »std::regex_replace« hingegen ersetzt den Treffer mit einem neuen String.
Die neue Bibliotheksfunktionalität erlaubt außerdem das wiederholte Suchen mit Hilfe von regulären Ausdrücken (Listing 7). Der Code »std::sregex_iterator it1(str1.begin(),str1.end(),reg1)« erzeugt einen Iterator, der über alle Zeichen aus »std::string str1=”1,2,3,4,5,6,7,8,9,10,11,12″« iteriert und nur die Zeichen zurückgibt, die nicht in dem regulären Ausdruck »std::regex reg1(“[^13579,]”« enthalten sind. Dies sind genau die geraden Zahlen.
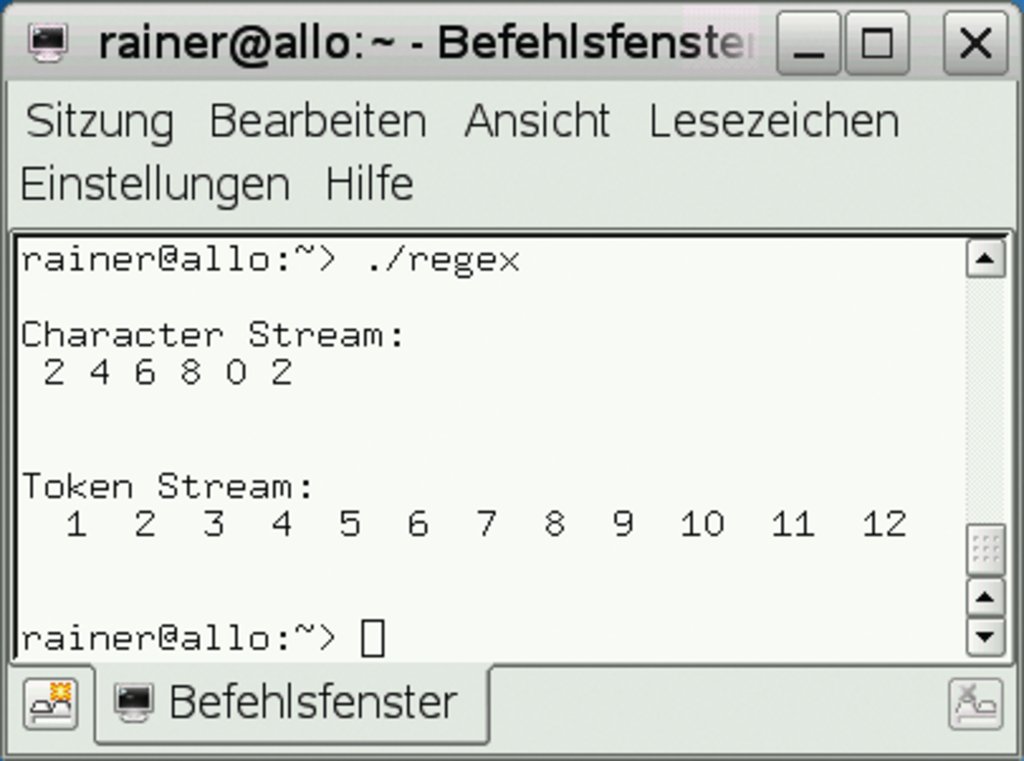
Abbildung 1: Wiederholtes Suchen in einem String, zuerst über die Zeichen, danach über die Wörter.
Hingegen erzeugt »std::sregex_token_iterator it2(str2.begin(),str2.end(),reg2,-1)« einen Iterator über alle Wörter aus dem gleichen String, die mit dem regulären Ausdruck »std::regex reg2(“,”)« gebildet wurden. Abbildung 1 zeigt den Unterschied zwischen dem Iterator über die Zeichen und dem über die Wörter. Für das Studium der Details bietet sich die Dokumentation der Reguläre-Ausdrücke-Bibliothek von Boost [8] an, die die Grundlage für die C++0x-Implementierung darstellt.
|
Listing 6: Suche mit einem |
|---|
01 std::regex rgx(R"d+");
02 std::smatch match;
03 if (std::regex_search(std::string("123A43"), match, rgx))
04 std::cout << "match found after " << match.prefix() << 'n';
|
|
Listing 7: Wiederholtes Suchen |
|---|
01 std::regex reg1("[^13579,]");
02 std::string str1="1,2,3,4,5,6,7,8,9,10,11,12";
03 std::sregex_iterator it1(str1.begin(),str1.end(),reg1);
04 std::sregex_iterator end1;
05 std::cout << "Character Stream: " << std::endl;
06 while (it1 != end1) std::cout << " " << *it1++;
07 std::cout << "nn";
08
09 std::regex reg2(",");
10 std::string str2="1,2,3,4,5,6,7,8,9,10,11,12";
11 std::sregex_token_iterator it2(str2.begin(),str2.end(),reg2,-1);
12 std::sregex_token_iterator end2;
13 std::cout << "Token Stream: " << std::endl;
14 while (it2 != end2) std::cout << " " << *it2++;
15 std::cout << "n";
|
Type Traits
Sind reguläre Ausdrücke für den Anwendungsprogrammierer ein hilfreiches Werkzeug, so ist es die Type-Traits-Bibliothek für den Designer von generischen Bibliotheken in C++0x. Mit »type_traits« erhält C++0x eine Bibliothek, die das Template Metaprogramming in C++ hoffähig macht. Diese Metasprache der Templates hilft C++-Code zur Compilezeit zu erzeugen, der zur Laufzeit ausführbereit vorliegt. Das bedeutet einen deutlichen Performancegewinn für das Programm, denn die Metasprache erlaubt mächtige Optimierungen des resultierenden C++-Code.
Die »type_traits«-Bibliothek stellt die Bausteine für das Template Metaprogramming bereit: die Abfrage von Typen, deren Vergleich und auch Modifikation. Danny Kalev, ehemaliges Mitglied der C++-Standard-Komitees, stellt diese ebenso anspruchsvolle wie innovative Technik in seinem Artikel vor [9]. Der Autor entwickelt einen Kopieralgorithmus für Container, der seine Elemente performant mit der C-Funktion »memcpy()« kopiert, sofern die Container und deren Elemente die notwendigen Bedingungen erfüllen.
Bewährtes verbessert
Nach den vorgestellten Neuerungen bieten die folgenden Bibliotheken bereits aus C++ bekannte Konzepte in überarbeiteter und generischer Form an. Den Anfang machen die Smart Pointer, die in C++-Kreisen als eine wichtige, wenn nicht gar die wichtigste Erweiterung gelten, die die C++0x-Bibliothek mit sich bringt. Smart Pointer sind spezielle intelligente Zeiger, die als Wrapper Aufrufe vollkommen transparent an die eingepackte Ressource weiterreichen und diese außerdem mit zusätzlicher Funktionalität ausstatten. C++0x bietet sie in drei Formen an, als »shared_ptr«, »weak_ptr« und »unique_ptr«:
- Der »shared_ptr« verwendet einen
Referenzzähler auf eine gemeinsam genutzte Ressource. Jeder
neue Shared Pointer auf die geteilte Ressource inkrementiert, jeder
gelöschte dekrementiert den Referenzzähler. Sobald dieser
0 erreicht, wird die Ressource automatisch freigegeben. - Der »weak_ptr« hilft zyklische Referenzen beim
Einsatz von Shared Pointers aufzulösen. Ein Weak Pointer
verändert den Referenzzähler auf die geteilte Ressource
nicht. - Der »unique_ptr« besitzt eine Ressource exklusiv.
Er lässt sich nicht kopieren.
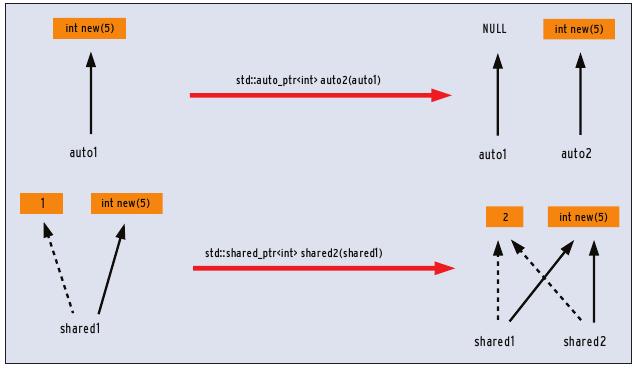
Abbildung 2: Während der alte Auto Pointer in C++ seine Ressource an den erzeugten Pointer übergibt, hält der neue Shared Pointer eine Referenz auf seine Ressource und eine auf den Referenzzähler.
Kluge Pointer
Smart Pointer überwachen den Lebenszyklus der Ressource nach dem RAII-Idiom [4]. Ihr C++-Ahne ist der »auto_ptr«, der aber eine große konzeptionelle Schwäche hat: Wird ein »auto_ptr« kopiert, geht seine Ressource in den Besitz des neuen Objekts über. Im Gegensatz hierzu hält der »shared_ptr« eine Referenz auf die Ressource und eine auf den Referenzzähler. Abbildung 2 stellt das Kopieren des »auto_ptr« und des »shared_ptr« gegenüber.
Dieses Verhalten führt einerseits dazu, dass sich »auto_ptr« nicht in Standard-Containern verwenden lässt, und andererseits, dass der Code in Listing 8 undefiniertes Verhalten aufweist, da »auto1« die Ressource »new int(5)« nicht mehr besitzt. Das C++-Standard-Komitee entschloss sich daher, »auto_ptr« als »deprecated« zu kennzeichnen und dafür den neuen Smart Pointer »unique_ptr« zu definieren. Listing 9 zeigt die neuen Smart Pointer im Einsatz, Abbildung 3 die entsprechende Ausgabe dazu.
Zeile 1 definiert einen Vektor über »shared_ptr«. Der »sharedPtr« aus Zeile 2 wird in der nächsten Zeile auf den Vektor geschoben. »shared_ptr« lassen sich im Gegensatz zu den »auto_ptr« von C++ in Standardcontainern verwenden, da sie kopierkonstruierbar und zuweisbar sind. Die Zuweisung »*sharedPtr=”modified”« modifiziert auch den Shared Pointer in dem Vektor, wie die Ausgabe zeigt.
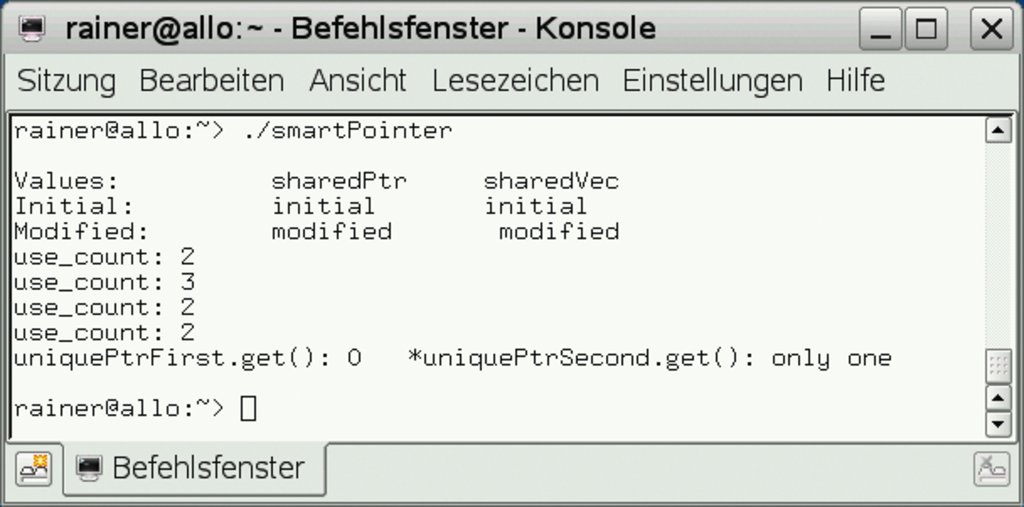
Abbildung 3: Die Ausgabe von Listing 9 zeigt die Entwicklung des Referenzzählers beim Einsatz verschiedener Pointer-Typen.
|
Listing 8: Kopieren eines |
|---|
01 std::auto_ptr<int> auto1(new int(5)); 02 std::auto_ptr<int> auto2(auto1); 03 int a= *auto1; |
|
Listing 9: |
|---|
01 std::vector< std::tr1::shared_ptr<std::string> > sharedVec;
02 std::tr1::shared_ptr<std::string> sharedPtr( new std::string("initial"));
03 sharedVec.push_back(std::tr1::shared_ptr<std::string>( sharedPtr));
04 std::cout << "Values: sharedPtr sharedVec" << std::endl;
05 std::cout << "Initial: " << " " << *sharedPtr << " " << *sharedVec[0] << std::endl;
06 *sharedPtr="modified";
07 std::cout << "Modified: " << " " << *sharedPtr << " " << *sharedVec[0] << std::endl;
08 std::cout << "use_count: " << sharedPtr.use_count() << std::endl;
09 {
10 std::shared_ptr<std::string> localSharedPtr( sharedPtr );
11 std::cout << "use_count: " << sharedPtr.use_count() << std::endl;
12 }
13 std::cout << "use_count: " << sharedPtr.use_count() << std::endl;
14 std::weak_ptr<std::string> weakPtr( sharedPtr );
15 std::cout << "use_count: " << sharedPtr.use_count() << std::endl;
16 std::unique_ptr<std::string> uniquePtrFirst( new std::string("only one") );
17 // std::unique_ptr<std::string> uniquePtrSecond( uniquePtrFirst); will not compile
18 std::unique_ptr<std::string> uniquePtrSecond( std::move(uniquePtrFirst));
19 std::cout << "uniquePtrFirst.get(): " << uniquePtrFirst.get() << " *uniquePtrSecond.get(): " << *uniquePtrSecond.get() << std::endl;
|
Mitgezählt
Die Aufrufe »sharedPtr.use_count()« geben den Referenzzähler der gemeinsam genutzten Ressource aus. Schön ist zu sehen, wie der Referenzzähler nach der Destruktion von »localSharedPtr« am Ende des Blocks in Zeile 13 wieder den Wert 2 annimmt. Der »weak_ptr« in Zeile 14 erhöht den Referenzzähler auf die geteilte Ressource nicht.
Der »uniquePtrFirst« in Zeile 16 besitzt die Ressource exklusiv, sie kann nur durch eine explizite Verwendung von »std::move« an »uniquePtrSecond« in Zeile 18 übertragen werden. Dies ist der Grund, warum »uniquePtrFirst.get()« in Zeile 19 ein Nullpointer ist, »*uniquePtrSecond.get()« hingegen die Ressource besitzt und ausgeben kann.
Die neuen Smart Pointer geben dem C++-Programmierer die notwendigen Hilfsmittel an die Hand, um eine automatische deterministische Speicherbereinigung umzusetzen. Deterministisch, weil der Speicher sofort im Destruktor wieder freigegeben und nicht – wie bei der Garbage-Collector-Implementierung in Java oder Python üblich – lediglich dem Garbage Collector zur künftigen Freigabe überlassen wird.
Die neue Standardbibliothek hat noch mehr zu bieten: Die neuen Container zu Tupeln, Arrays und Hashtabellen runden C++0x weiter ab. C++ besitzt Paare, C++0x bekommt Tupel. Tupel sind eine Verallgemeinerung von Paaren – sie können mindestens zehn verschiedene Elemente binden. Ihre Elemente (Zeilen 1 und 2) in Listing 10 lassen sich in Standardcontainern (Zeile 4) verwenden, miteinander vergleichen (Zeile 5) und besitzen eine feste Dimension. Mit Hilfsfunktionen wie »std::make_tuple« (Zeile 2) lässt sich ein Tupel schnell erzeugen und mit »std::get« lesen (Zeile 6) und schreiben (Zeile 7).
|
Listing 10: Tupel |
|---|
01 std::tuple<std::string,int,float> tup1("first tuple",3,4.17);
02 std::tuple<std::string,int,double> tup2= std::make_tuple("second tuple",4,1.1);
03 std::vector < std::tuple<std::string,int,float > > tupVec;
04 tupVec.push_back(tup1);
05 bool a= tup1 < tup2;
06 std::string str= std::get<0>(tup1);
07 std::get<0>(tup2)= "Second Tuple";
|
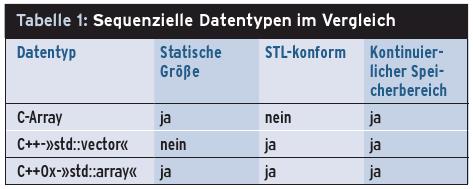
Der ebenfalls neue sequenzielle Container »std::array« ist ein Container-Wrapper für Arrays fester Länge, der mit der Standard Template Library (STL) konform geht. Er verbindet das Laufzeitverhalten des C-Array mit den Schnittstellen des C++-Vektors. Die Tabelle 1 stellt die feinen Unterschiede der drei sequenziellen Datentypen dar.
Einer der im C++98-Standard am häufigsten vermissten Container ist die Hashtabelle, auch bekannt als Dictionary oder assoziatives Array. Hashtabellen erlauben den performanten Zugriff auf die Werte in Containern mit dem assoziierten Schlüssel, sie sind aus dem Programmiererleben nicht wegzudenken [10].
C++0x füllt nun endlich diese Lücke: Die Hashtabellen sind unter ihren Namen »unordered_map«, »unordered_set«, »unordered_multimap« und »unordered_multiset« Bestandteil des neuen C++0x-Standards. Die vier Hashtabellen lassen sich gut mit Hilfe dieser beiden Fragen unterscheiden: Kommen die Schlüssel einfach vor? Ist den Schlüsseln ein Wert zugeordnet?
Die sperrigen Namen der Hashtabellen sind zum einen der Tatsache geschuldet, dass die intuitiveren Namen schon für verschiedene C++-Erweiterungen vergeben sind. Zum anderen entsprechen die neuen Container den bekannten C++-Containern »map«, »set«, »multimap« und »multimap«. Die bekannten Container und die neuen wie »unordered_map« bieten zwar ein sehr ähnliches Interface, unterscheiden sich aber in der Performance: Nur die Schlüssel der C++-Container sind geordnet. Dadurch reduziert sich die Zugriffszeit im Idealfall von einem logarithmischen auf ein konstantes Laufzeitverhalten.
Programmieren höherer Ordnung
Der generische Adapter »std::bind« ermöglicht in Kombination mit der neuen Funktion »std::function« das Programmieren höherer Ordnung [11] in C++0x. Mit »std::bind«, das die C++-Funktionsadapter »std::bind1st« und »std::bind2nd« auf generische Stufe stellt, kann der Entwickler Argumente an beliebige Positionen einer Funktion, einer Methode oder eines Funktionsobjekts binden. Das resultierende Funktionsobjekt kann er direkt aufrufen oder in einem Funktionsobjekt (»std::function«) speichern. Darüber hinaus lassen sich für Argumente ohne Wert Platzhalter verwenden. Die Funktionsobjekte, die »std::function« bindet, sind First Class Functions [11].
Die Umwandlung einer Funktion mit mehreren Argumenten in mehrere Funktionen mit je einem Argument, in der funktionalen Programmierung unter dem Namen Currying [12] bekannt, ist nun auch in C++0x möglich.
Die Funktionalität von »std::bind« lässt sich oft durch Lambdafunktionen ausdrücken, jene von »std::function« durch die Type-Inference von »auto«. Beides steht bereits mit der C++0x-Kernsprachen-Erweiterung zur Verfügung [1]. Welche Variante der Entwickler wählt, bleibt im Grunde seinem Geschmack überlassen (Listing 11).
|
Listing 11: »bind« |
|---|
01 template <typename T>
02 T addMe(T a, T b){
03 return a+b;
04 };
05
06 std::function<std::string(std::string)> addString =std::bind(addMe<std::string>,"first",_1);
07 std::cout << addString("second") << std::endl;
08
09 auto addString2= std::bind(addMe<std::string>, "first",_1);
10 std::cout << addString2("second") << std::endl;
11
12 std::vector<int> myVec{1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20};
13
14 std::copy_if( myVec.begin(), myVec.end(),
15 std::ostream_iterator<int>( std::cout, ", " ),
16 std::bind( std::logical_and<bool>(),
17 std::bind( std::greater <int>(),_1,9 ),
18 std::bind( std::less <int>(),_1,16 )));
19
20 std::copy_if( myVec.begin(), myVec.end(),
21 std::ostream_iterator<int>( std::cout, ", " ),
22 [](int a){ return (a>9)&&(a<16);});
|
Zeile 6 erzeugt ein Funktionsobjekt, das »first« an das erste Argument bindet. Für das zweite Argument kommt der Platzhalter »_1« zum Einsatz. Der Funktionsadapter »std::bind« erzeugt aus dem generischen Template, das zwei Argumente gleichen Typs erwartet, ein Funktionsobjekt, das einen »std::string« erwartet und einen »std::string« zurückgibt. Das entspricht genau der Deklaration von »std::function<std::string(std::string)>«. Das automatische Ableiten des Funktionsobjekt-Typs durch »auto addString2« aus dem Funktionsadapter ist in diesem Falle jedoch deutlich einfacher. Beide Funktionsobjekte geben »firstsecond« auf der Kommandozeile aus.
Im Gegensatz hierzu ist »std::copy_if« wesentlich ungewohnter zu lesen. Beide Kopieralgorithmen in Listing 11 geben jene Elemente von »myVec« (Zeilen 14 und 20) kommasepariert aus (Zeile 15 und Zeile 21), die sowohl größer als 9 als auch kleiner als 16 sind (Zeilen 16 bis 18 und 22). Das Ergebnis der beiden Algorithmen ist »10, 11, 12, 13, 14, 15«.
Abbildung 4: Der Technical Report 1 und damit die C++0x-Bibliotheken fußen auf Boost.
Aus- und Fernblick
Dieser Artikel bleibt zwangsläufig unvollständig, denn die neue C++0x-Standardbibliothek ist sehr umfangreich. Drei praktische Werkzeuge seien aber unbedingt noch genannt. Das erste ist die Bibliothek zur Erzeugung von Zufallszahlen [13], die aus zwei Teilen besteht: einem Generator, der Sequenzen von Zufallszahlen erzeugt, und einer Verteilung, die die Zufallszahlen in einem vorgegebenem Bereich verteilt. Zweitens: Aktionen, die von anderen zeitlich abhängen, etwa »std::time_mutex«, benötigen Zeit-Tools. Auch diese hat C++0x im Repertoire [13]. In die dritte Kategorie der nützlichen Werkzeuge fallen jene Wrapper [14], die Referenzen umhüllen, sodass sich diese in Standardcontainern verwenden lassen.
Zwar ist der neue C++0x Standard noch nicht verabschiedet, doch es lässt sich bereits ein sehr detailliertes Bild von C++0x und seinen Bibliotheken zeichnen. Viele der neuen Features, insbesondere der neuen Bibliotheken, stehen mit einem aktuellen Compiler wie GCC 4.5 schon zur Verfügung. Da stellt sich die Frage, was auf C++0x noch folgen soll: Nach dem Technical Report 1 [15], der auf den Boost-Bibliotheken (Abbildung 4) aufbaut, folgt Technical Report 2 [16]. Er soll sich vor allem mit Unicode, XML/HTML, Netzwerkprogrammierung und der Usability der Standardbibliothek für C++-Novizen befassen. (mhu)
|
Der Autor |
|---|
|
Rainer Grimm arbeitet seit 1999 als Software-Entwickler bei der Science + Computing AG in Tübingen. Insbesondere hält er Schulungen für das hauseigene Produkt SC Venus. |





