
© Yaban, Photocase.com
Je moderner die Webapplikationen werden desto mehr gerät die dahinter stehende Infrastruktur unter Druck. Im Kampf gegen Performanceeinbrüche immer weitere Server anzustöpseln, bringt allein nicht den Durchbruch. Intelligent verschaltete Strukturen aber wohl .
Während die Welt twittert, facebookt, xingt und flickrt, müssen sich die Admins und IT-Verantwortlichen auf dem Maschinendeck des Web-2.0-Vergnügungsdampfers Gedanken machen, wie sie einerseits die Reisegeschwindigkeit verbessern können und andererseits nicht auf der Hälfte der Passage mit einem Maschinenschaden liegen bleiben.
Um die Benutzerinteraktionen schneller auswerten zu können verschiebt das moderne Mitmach-Web technisch betrachtet zwar einen Teil der Rechenleistung weg vom Server hin auf den Client (Ajax, Google GWT, Java). Absolut betrachtet verringert sich die Serverlast durchs Web 2.0 nicht, sondern steigt, weil der technische Fortschritt bei den Serverapplikationen und steigende Benutzerzahlen den Ajax-Einsparungseffekt mehr als wettmachen.
Mit performanter Hardware allein lassen sich dynamische Inhalte, Skripte und Animationen nicht in jedem Fall ausliefern – eine intelligent gestaltete Infrastruktur ist genauso wichtig. Der folgende Beitrag geht genau dieser Frage nach.
Das erste Szenario in Abbildung 1 versucht Webangeboten ein stabile Performance zu sichern, indem es einen Webserver mit einem getrennten Webcache, einen getrennten Datenbankserver und die zentrale Storageeinheit über ein VLAN verbindet. Der Admin eines solchen Setups sollte alle Einheiten in Hinblick auf Hard- und Software an ihre jeweiligen Aufgaben angepasst.
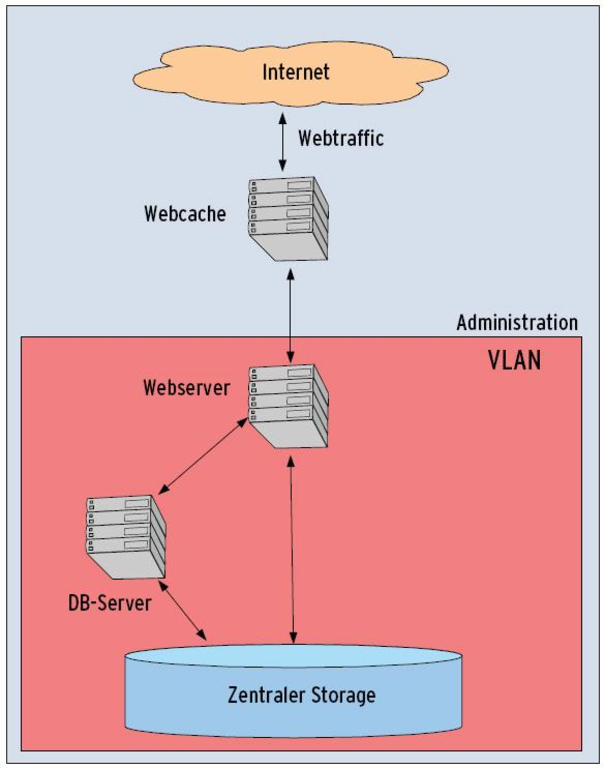
Abbildung 1: Im Szenario 1 beantwortet der Webcache wo möglich Anfragen. Web- und Datenbankserver arbeiten der besseren Performance wegen auf verschiedenen Maschinen.
VLAN als Schutzschirm
Wichtig bei dieser Infrastruktur: Nur der Webcache hängt direkt am Internet, alle anderen Komponenten sind nur über das interne VLAN erreichbar. Zusätzlich lässt sich auf der Maschine mit dem Webcache eine Firewall einrichten, die das VLAN zuverlässig abschirmt (siehe Kasten “VLANs”). Dies hat mehrere Vorteile: Neben einem Sicherheitsgewinn (quasi-physisch getrennte Kommunikation, interne IP-Adressen werden im Internet nicht geroutet) belastet der interne Traffic nicht die Außenanbindung des Webcaches. Die Administration aller Einheiten geschieht ebenfalls über das VLAN, und zwar über einen weiteren Server, der als Gateway dient.
Arbeitsteilung zwischen Cache und Webserver
Beim Aufruf eines in dem beschriebenen Setup gehosteten Onlineshops als Beispiel pendelt sich folgende Situation ein: Die Shop-Startseite würde vollständig gecacht, ebenso solche Seiten wie Impressum, Geschäftsbedingungen und anderer statischer Content, aber auch die Seiten besonders beliebter Produkte. Andere tiefer liegende Seiten erzeugt der Webserver weiterhin dynamisch und reicht sie an den Client durch, während Navigationselemente wiederum aus dem Cache kommen.
Ruft ein Client eine Seite auf, landet die komplette Anfrage im Webcache. Auf der Seite enthaltene dynamische Elemente fragt das Setup beim Webserver ab, der sie entweder direkt aus dem Storage holt (zum Beispiel Bilder) oder vom Datenbankserver zusammenstellen lässt. Diese Daten übergibt der Webserver an den Cache, der sie gemeinsam mit dem statischen Content ausgibt. In der Seite eingebette Web-2.0-Elemente (Ajax) sind tun dem Ablauf keinen Abbruch.
|
VLANs |
|---|
|
Ein Virtual Local Area Network trennt physikalische Netze trotz gemeinsamer Switches in statische oder dynamische Teilnetze auf, indem es das Routing der Datenframes auf das richtige Teilnetz beschränkt. [1] Moderne VLANs arbeiten zumeist mit getaggeten Paketen, also solchen, die eine zusätzliche VLAN-Markierungen tragen. Zu dieser Gattung gehören die VLANs nach IEEE 802.1q [2], Ciscos Inter-Switch Link Protocol (ISL) und 3Coms Virtual LAN Trunk (VLT). |
Das Zusammenspiel von Webserver und -cache ist dabei die große Herausforderung. Welche Elemente kann der Cache ausliefern, welche muss die Datenbank jedes Mal dynamisch erzeugen? Das Ensemble au den der einzelnen Maschinen profitiert hier von der VLAN-Architektur, die neben guten Bandbreiten auch kurze Zugriffszeiten aufgrund der physikalischen Nähe bereitstellt.
Horizontale Skalierung
Um die Performance zu steigern, lässt sich das Setup horizontal skalieren: Je nach Lastplanung repliziert der Admin zunächst die Webcaches über das VLAN. Allerdings muss er in diesem Setup auch einen Loadbalancer einplanen, der die Anfragen auf die Caches gerecht verteilt. Die Praxis zeigt, dass sich die Replikation der Caches jedoch nur dann anbietet, wenn das System nicht allzu viele dynamische Elemente ausliefern muss.
Die nächste logische Ausbaustufe wäre demnach, auch Web- und Datenbankserver zu replizieren, wie Abbildung 2 es zeigt. Dann lohnt sich die zentrale Datenhaltung im Storage besonders, denn das Duplizieren der Daten auf die Maschinen entfällt. Zudem bietet ein zentrales Storage eine deutlich höhere Verfügbarkeit der Daten und höhere Datensicherheit als die lokalen Festplatten der Server.
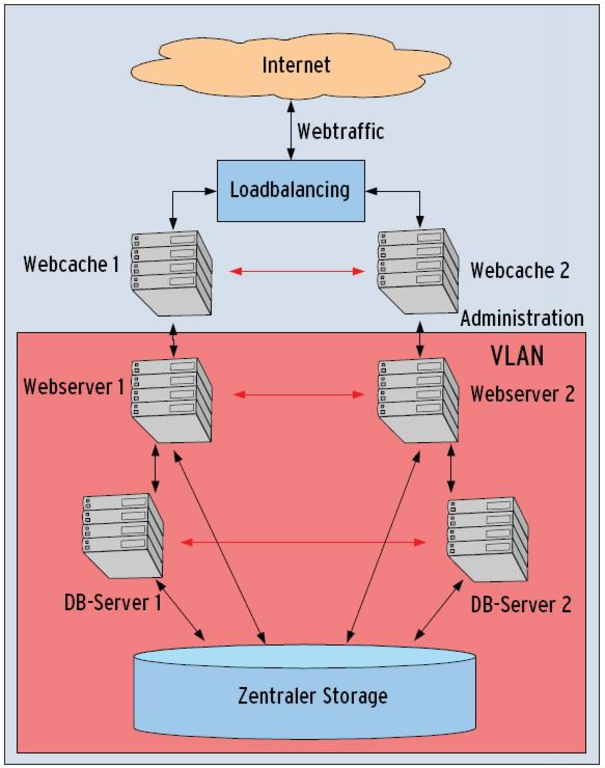
Abbildung 2: Rein aus Performancegründen sieht Szenario 2 alle Komponenten doppelt vor. Das Verteilen der Last übernimmt ein Load Balancer, den man dafür auch anschaffen muss.
Mehr Server, weniger Verfügbarkeit
Allerdings addieren sich nun, wenn ein Webangebot auf mehreren Servern aufgebaut ist, deren Ausfallwahrscheinlichkeiten: Sind zwei Server, die aufeinander angewiesen sind, statistisch zu 99 Prozent verfügbar, sinkt die Verfügbarkeit des Gesamtsystems auf rund 98 Prozent. Je mehr Systeme beteiligt sind, desto stärker wirkt sich dieser Effekt aus – bei fünf Systemen mit je 99 Prozent fällt die Gesamtverfügbarkeit auf rund 95 Prozent, was einer Downtime von 36 Stunden pro Monat oder 18 Tagen pro Jahr entspricht. Deshalb sollte der Verantwortliche eines verteilten Systems eine Failover-Strategie von Beginn an mit eingeplanen.
Ein reines Failover-Szenario ergäbe sich zwar ebenfalls aus horizontaler Replikation von Webserver, Cache und Datenbankserver. Jedoch wäre dazu – abgesehen vom Storage – die doppelte Zahl an Servern nötig, und das ohne die Performance zu steigern. Denn die Replikationen der einzelnen Server laufen ja im Idle-Mode unproduktiv und warten nur auf einen Ausfall des Produktivrechners. Tritt der ein, schaltet der Router einfach die IP-Adresse des Caches um und die gesamte Last gelangt auf die Failover-Servergruppe.
Das Beste beider Welten vereinen
Eine Mischung aus Loadbalancing und Failover erscheint nun als der Königsweg, der die Vorteile anderer Szenarien kombiniert ohne ihre Nachteile zu erben. Abbildung 3 zeigt ihn: Wenn alle Server funktionieren, verteilt sich die Last auf beide Stränge. Fällt ein einzelnes System oder ein ganzer Strang aus, verteilt sich automatisch die Last um.
Beispielsweise ließen sich die Webserver so konfigurieren, dass sie bei Ausfall der Caches die komplette Seite inklusive der statischen Elemente selbst ausliefern könnten. Oder so, dass ein Datenbank-Server die Last zweier Webserver trägt. Dazu muss der Admin allerdings innerhalb des VLANs die einzelnen Server vermaschen, sodass jeder über einen Heartbeat feststellen kann, wenn ein benachbarten System ausgefallen ist.
Im Fehlerfall muss das Setup eine neue Route setzen – effizient gelingt das, wenn der Admin im Router eine zusätzliche IP-Adresse anlegt, die wiederum den Traffic auf die konkreten IPs der Server umleitet. Die Alternativlösung über DNS wäre zu langsam, da es im DNS seine Zeit dauert, bis eine neue Adresse proklamiert ist. Die Lösung über eine zusätzliche IP lässt sich dagegen in wenigen Augenblicken in Gang setzen.
Testen, testen, testen
Wer eines der vorgestellten Szenarien nachbaut, sollte es nach der ersten Inbetriebnahme ausgiebig testen. Zum Simulieren der HA-Fehlerfälle genügt meist, den einen oder anderen Stecker zu ziehen und die Erreichbarkeit des Webangebots zu testen. Performance-Benchmarking ist nicht so einfach.
Zuerst sollte sich der Admin über die Eckdaten klar werden: Geht es um Antwortzeiten oder um Stabilität des Systems? Welche Maximallast ist zu erwarten und welche Antwortzeiten empfinden die Benutzer als “wünschenswert” und welche als “akzeptabel”? Soll der Test lediglich eine Applikation oder die gesamte Infrastruktur erfassen? Welche Fehlerrate ist zu Stoßzeiten für bestimmte Applikationen hinnehmbar, welche Applikation fordert durchgehend null Fehler?
Anhand dieser Kriterien sucht der Systemverantwortliche nun einen Benchmark von der Stange aus oder muss selbst einen schreiben. Damit erhobene Messwerte vergleicht er mit den Vorgaben und kann das System produktiv schalten und sich entweder zufrieden zurücklehnen. Oder er muss weitere Tuningmaßnahmen ergreifen – eventuell in Zusammenarbeit mit den Programmierern seiner Webapplikationen.
Fazit
Ein System wie in Abbildung 3 ist natürlich für eine einfache Website überdimensioniert. Andererseits kann ein Admin auch mit weniger Hardware ähnliche Szenarien verwirklichen, beispielsweise wenn er Webserver und Cache auf derselben Maschine betreibt und nur den Datenbankserver auslagert. Einzig das Problem der verschlechterten Verfügbarkeit bleibt hier ungelöst. Abgesehen von den Details zeigt dieser Artikel allen Admins auf dem Maschinendeck der “Web 2.0”: Sehr gute Performance mit akzeptabler Verfügbarkeit erreichen sie nicht mit Hardware allein – das intelligente Setup entscheidet. (jk)
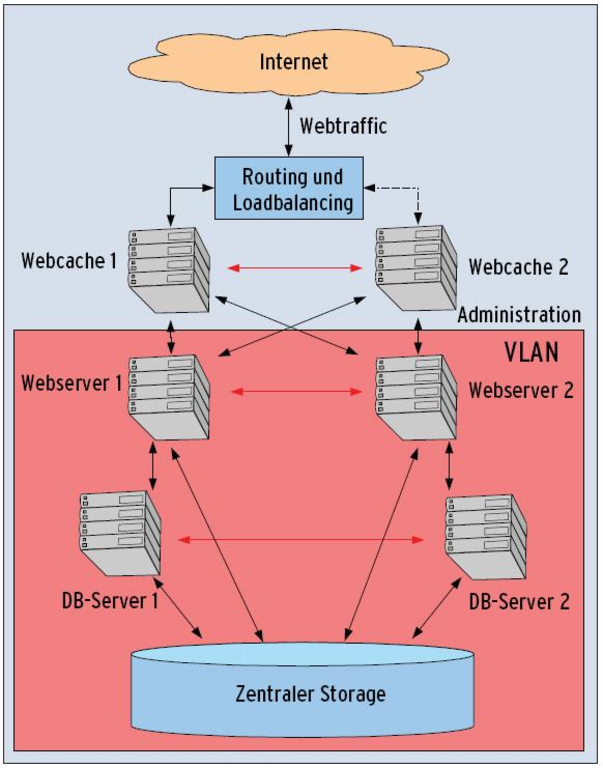
Abbildung 3: Das Szenario 3 vereint durch das geschicke Verschalten aller Komponenten die beiden Funktionalitäten Lastverteilung und Hochverfügbarkeit in sich.
|
Infos |
|---|
|
[1] Chris Hübsch, “Virtuelle LANs unter Linux nutzen”, Linux-Magazin 11/06, S. 56 [2] Virtual Bridged Local Area Networks – IEEE Std 802.1Q-2005/Cor 1-2008: [http://standards.ieee.org/getieee802/download/802.1Q-2005_Cor1-2008.pdf] |
|
Der Autor |
|---|
|
Julien Ardisson, Jahrgang 1968, ist studierter Informatiker und sitzt seit 2003 im Vorstand der Strato Rechenzentrum AG. Dort verantwortet er unter anderem die Bereiche Dedicated Hosting und Data Center Facility. |





