
© .marqs, Photocase.com
Mit Python 3.0 hat Sprachschöpfer Guido van Rossum seine Skriptsprache ausgemistet. Nun bringt Python 3.1 noch die Performance in Ordnung. Was muss ein Programmierer beim Umstieg von Python 2.x wissen? Wie und wann portiert er bestehende Skripte auf die neue Sprachversion?
Die Python-Version 3.0, auch als Python 3000 oder Py3k bekannt, bricht mit einer alten Tradition: Sie ist nicht abwärtskompatibel. Guido von Rossum, der Erfinder von Python, bringt es auf den Punkt: “Python 3 erhebt nicht den Anspruch, dass unmodifizierter Python-2.6-Code darauf läuft.”
Was schon immer störte
Manche Details von Python stören Guido van Rossum bereits seit Anfang des Jahrtausends. Offenbar hat er sich entschlossen die Kompatibilität zu opfern, um diese Stolpersteine auszuräumen. Den Versionssprung nicht so groß werden zu lassen, das ist die Hauptaufgabe von Python 2.6. Viele Features von Python 3.0 wurden nach Python 2.6 rückportiert. Zu der kürzlich erschienenen Python-Release 3.1 wird es entsprechend auch ein Python 2.7 geben. Daneben unterstützt das Kommandozeilentool »2to3« den Programmierer bei der Codemigration von Python 2.x nach 3.x, was dieser Artikel später vorexerziert.
Der offensichtlichste Bruch mit Python 2 ist die syntaktische Veränderung von »print()«. Es mutiert vom Statement zur Funktion und muss daher mit Klammern aufgerufen werden. Der Programmierer ruft Parameter jetzt mit Schlüsselwörtern auf, gemäß dem “The Zen of Python” [1] von Tim Peters: “Explizit ist besser als implizit.”
Die neue Syntax von Print ist allgemein »print(*args, sep=\’ \’, end=\’n\’, file=sys.stdout)«, wobei »args« die Argumente, »sep« den Separator zwischen den Argumenten, »end« das Zeilenendzeichen und »file« das Ausgabemedium bezeichnen. Tabelle 1 stellt die syntaktischen Veränderungen der Print-Funktion inklusive ihrer Defaultwerte gegenüber. Der Vorteil der neuen Version offenbart sich aber erst auf den zweiten Blick, denn die Print-Funktion lässt sich jetzt überladen: Listing 1 zeigt eine Print-Funktion, die sowohl in die Standardausgabe als auch in eine Logdatei schreibt. Dazu instrumentalisiert sie die Built-in-Funktion »__builtins__.print«.
|
Listing 1: Überladen der |
|---|
01 import sys
02 def print(*args,sep='',end="n",file=sys.stdout):
03 __builtins__.print(*args)
04 __builtins__.print(*args,file=open("log.file","a"))
|
Lob der Faulheit
Nur das Nötigste tun, das ist bei Programmiersprachen durchaus eine Tugend. In Python 3 erhält Lazy Evaluation deutlich mehr Gewicht. Listen, Dictionaries oder die funktionalen Bausteine von Python erzeugen jetzt nicht mehr die gesamte Liste, sondern eben nur noch so viel, wie für die Auswertung des Ausdrucks notwendig ist. Diese Bedarfsauswertung spart kostbaren Speicherplatz und Zeit. Das erreicht der Python-Interpreter dadurch, dass er nur noch einen iterierbaren Kontext zurückgibt, der auf Anfrage die Werte erzeugt. Dies war schon in Python 2 der feine Unterschied zwischen den Funktionen »range()« und »xrange()«. Mit Python 3 verhält sich nun »range()« wie »xrange()«, weshalb die zweite Funktion überflüssig wird.
Entsprechend liegt der Fall bei den funktionalen Bausteinen »map()«, »filter()« und »zip()«. Diese Funktionen wurden durch ihre Äquivalente aus der Bibliothek »itertools« ersetzt. Bei Dictionaries heißen die resultierenden iterierbaren Kontexte Views. Benötigt der Programmierer hingegen die voll expandierte Liste, hilft ein einfaches Kapseln des iterierbaren Kontexts durch einen »list()«-Konstruktor, wie das folgende Beispiel zeigt: »list(range(11))« ergibt »[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]«.
True Division
Gerade Python-Einsteiger sind häufig erstaunt, dass »1/2 == 0« gilt. Python 3 beseitigt diesen Zustand und unterscheidet zwischen True Division und Floor Division. Während für die True Division »1/2 == 0.5 « gilt, verhält sich die Floor Division wie die Division in Python 2. Ihre Notation verwendet zwei Schrägstriche: »1//2 == 0«.
Musste der Programmierer in Python 2 Strings noch explizit als Unicode-Strings deklarieren, so sind diese Zeichenketten jetzt implizit Unicode-Strings. Python 3.0 kennt nur noch Text und Daten. Text (»str« [2]) sind Strings und entsprechen dem Unicode-String aus Python 2. Daten (»bytes« [3]) sind 8-Bit-Strings und entsprechen den Python-2-Strings. Daten muss der Python-3-Entwickler deklarieren: »b”8-Bit-String”«. Tabelle 2 zeigt dies in der Übersicht.
Um zwischen den Datentypen zu konvertieren, gibt es die Funktionen »str.encode()« und »bytes.decode()«. Diese Konvertierung benötigt der Entwickler in Python 3.0, wenn er beide Datentypen verwendet, denn es findet keine implizite Typkonvertierung mehr statt. Jetzt muss der Programmierer Farbe bekennen.
Mit Function Annotations bietet Python 3 die Möglichkeit, Metadaten an eine Funktion zu binden. Die Funktion lässt sich im zweiten Schritt auch mit Dekoratoren [4] versehen, die automatisch aus den Metadaten eine Dokumentation erzeugen oder die Typen zur Laufzeit prüfen. Die äquivalenten Funktionen »sumOrig()« und »sumMeta()« (siehe Abbildung 1) zeigen die Funktionsdeklaration mit und ohne Metadaten. Die zweite Funktion ist um Metadaten zur Signatur und zum Rückgabewert der Funktion erweitert. Die Metadaten lassen sich mit dem Funktionsattribut »__annotations__« referenzieren.
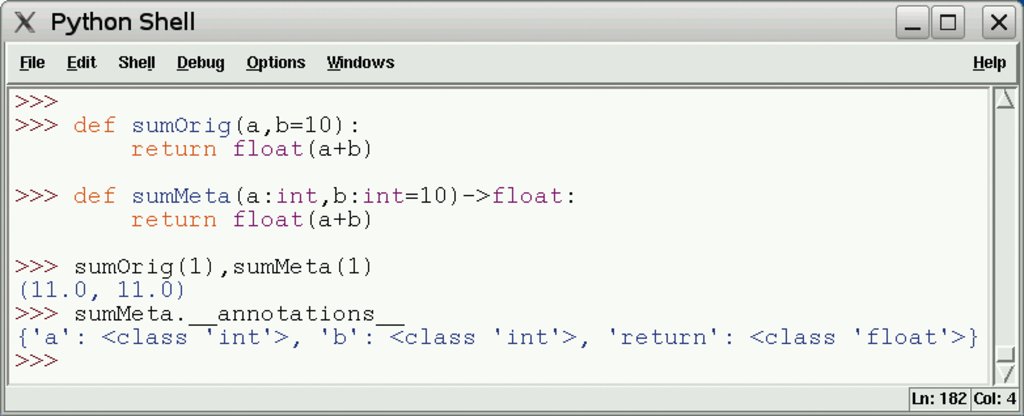
Abbildung 1: Function Annotations binden Metadaten an eine Funktion.
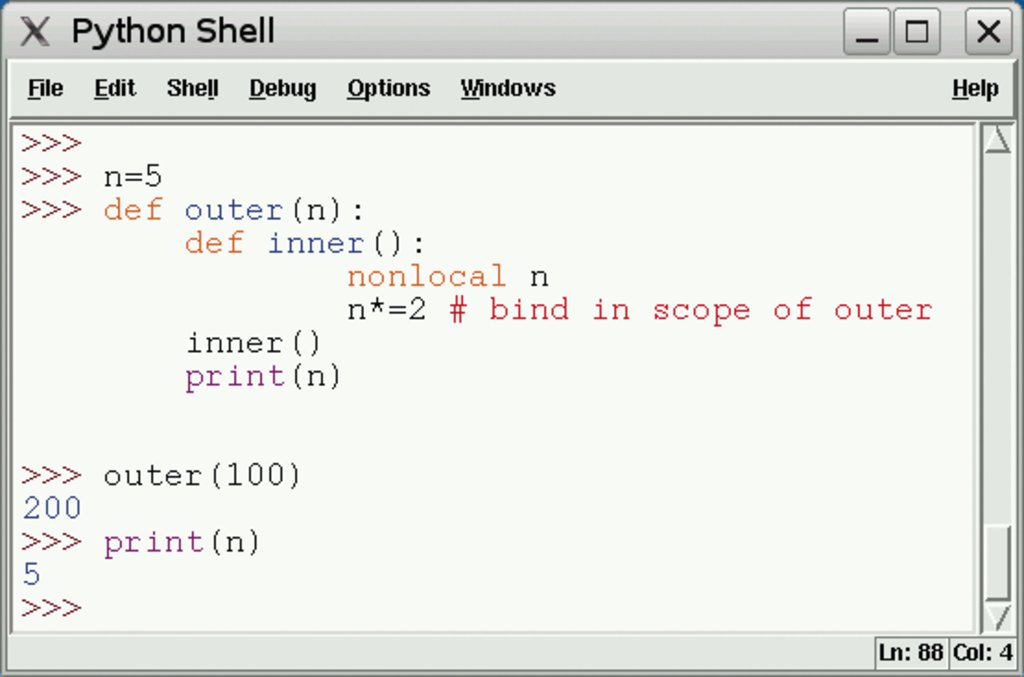
Abbildung 2: Das Statement »nonlocal« ermöglicht es dem Programmierer, auf den nicht-globalen Geltungsbereich außerhalb der Funktion zu schreiben.
Das Statement »nonlocal« erlaubt es dem Programmierer, auf den umgebenden, nicht globalen Scope schreibend zuzugreifen. In Python 2 quittierte der Interpreter dies mit einer schwer zu interpretierenden Exception. Die innere Funktion »inner()« in Abbildung 2 modifiziert die Variable »n« im umgebenden Scope von »outer()«, was den Aufrufparameter 100 von »outer()« verdoppelt.
Backports
Sinn und Zweck von Python 2.6 ist es, den Umstieg auf die Version 3 so einfach wie möglich zu vollziehen. Aus diesem Grund hat das Projekt viele Features von Python 3.0 auf Python 2.6 rückportiert. Das Ressourcen-Management mit »with« ist ein wichtiges neues Feature, das mit Python 2.6 zur Verfügung steht. Eine Ressource (Datei, Socket, Mutex etc.) bindet Python automatisch beim Eintritt in den With-Block und gibt sie beim Austritt wieder frei. C++-Programmierern wird dieses Idiom an “Resource Acquisition Is Initialization” (RAII) erinnern [5].
Das With-Statement verhält sich aus Anwendersicht wie ein »try … finally«, da sowohl der »try«-Block als auch der »finally«-Block immer ausgeführt werden. Dies alles geschieht aber ohne explizite Ausnahmebehandlung.
Wie funktioniert nun das Ganze? In einem With-Block lässt sich jedes Objekt verwenden, das das Context-Management-Protokoll anbietet, das also die internen Methoden »__enter()__« und »__exit()__« besitzt. Beim Eintritt in den With-Block ruft Python die »__enter()__« und beim Austritt die »__exit()__« Methode automatisch auf. Das Datei-Objekt bringt die entsprechenden Methoden von Haus aus mit (Listing 2).
|
Listing 2: With-Block mit |
|---|
01 with open('/etc/passwd', 'r') as file:
02 for line in file:
03 print line,
04 # file is closed
|
Das Ressourcen-Management ist aber auch schnell selbst gemacht. Ein klassischer Anwendungsfall besteht darin, einen Codeblock vor gleichzeitigem Zugriff zu schützen. Listing 3 deutet die Verwendung des Codeblocks nur an. Objekte der Klasse »locked« sorgen dafür, dass kein konkurrierender Zugriff auf den With-Block geschieht, indem sie diesen Block mittels »myLock« synchronisieren. Wem dies noch zu viel Arbeit ist, der kann den Dekorator »contextmanager« aus der neuen Bibliothek »contextlib« [6] verwenden, um vom Ressourcen-Management zu profitieren. Weitere Anwendungsfälle sind im Python Enhancement Proposal (PEP) 0343 [7] zu finden.
|
Listing 3: Schutz eines |
|---|
01 with locked(myLock): 02 # Code here executes with myLock held. The lock is 03 # guaranteed to be released when the block is left 04 class locked: 05 def __init__(self, lock): 06 self.lock = lock 07 def __enter__(self): 08 self.lock.acquire() 09 def __exit__(self, type, value, tb): 10 self.lock.release() |
Abstraktes
Die wohl größte syntaktische Erweiterung vollzieht sich in Python 2.6 mit der Einführung von abstrakten Basisklassen. Ob ein Objekt sich in einem Kontext verwenden lässt, hing bisher von den Merkmalen des Objekts ab und nicht von dessen formaler Schnittstellenspezifikation.
Dieses Idiom wird Duck-Typing genannt, frei nach dem Gedicht von James Whitcomb Riley: “When I see a bird that walks like a duck and swims like a duck and quacks like a duck, I call that bird a duck.” (Wenn ich einen Vogel sehe, der wie eine Ente läuft, wie eine Ente schwimmt und wie eine Ente schnattert, dann nenne ich diesen Vogel eine Ente.)
Sobald eine Klasse eine abstrakte Methode besitzt, wird sie zur abstrakten Basisklasse und lässt sich nicht instanzieren. Von ihr abgeleitete Klassen können nur erzeugt werden, wenn sie diese abstrakten Methoden implementieren. Abstrakte Basisklassen in Python verhalten sich ähnlich wie abstrakte Basisklassen in C++, insbesondere dürfen abstrakte Methoden eine Implementierung enthalten.
Neben den abstrakten Methoden kennt Python auch abstrakte Properties. Die Python-Version 3 verwendet abstrakte Basisklassen in den Modulen »numbers« [8] und »collections« [9].
Die entscheidende Frage steht noch aus: Wie wird eine Klasse zur abstrakten Klasse? Die Klasse benötigt die Metaklasse »ABCMeta«. Daraufhin lassen sich die entsprechenden Methoden als »@abstractmethod« oder Properties als »@abstactproperty« mit Hilfe des entsprechenden Dekorators deklarieren. Die Verwendung von abstrakten Basisklassen bedeutet darüber hinaus, dass in die dynamisch typisierende Sprache statische Typisierung Einzug hält.
Das Beispiel in Abbildung 3 kann die Klasse »Cygnus« nicht instanzieren, da es die abstrakte Methode »quack()« nicht implementiert.
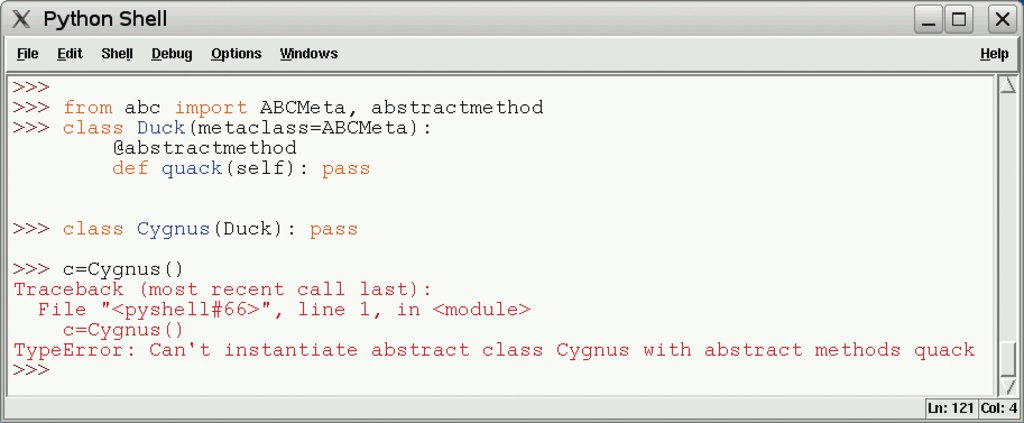
Abbildung 3: Die Klasse »Duck« dient als Beispiel einer abstrakten Klasse. Die Klasse »Cygnus« lässt sich nicht instanzieren, da sie die abstrakte Quack-Methode der Basisklasse nicht umsetzt.
Mehrere Prozessoren
Pythons Antwort auf Multiprozessor-Architekturen ist die neue Bibliothek »multiprocessing« [10]. Dieses Modul imitiert das bekannte Python-Modul »threading«, nur erzeugt es statt eines Thread einen Prozess, und dies auch noch plattformunabhängig. Das Multiprocessing-Modul war notwendig, da in CPython, der Standardimplementierung von Python, nur ein Thread im Interpreter laufen kann. Geschuldet ist dies Verhalten dem so genannten Global Interpreter Lock, kurz GIL [11].
Klassendekoratoren [12] runden die Dekoratoren in Python ab, denn nun kann der Programmierer neben Funktionen auch Klassen dekorieren. Python 3.0 erhielt eine neue I/O-Bibliothek [13]. Der String-Datentyp gewann eine neue Methode mit »format()« [14] zum verbesserten Formatieren von Strings. Gleichzeitig gilt der bisherige Formatieroperator »%« mit Python 3.1 als “deprecated”.
Aufräumarbeit
Wo es Veränderungen gibt, wollen auch Altlasten bereinigt und entsorgt sein. Dies betrifft Bibliotheken, die entfernt wurden, die nun gemäß dem Python Style Guide [15] klein geschrieben werden, die neu in Pakete verpackt wurden oder in einer C- und einer Python-Implementierung koexistieren.
Das bekannte Python-Idiom, erst die schnelle C-Implementierung eines Moduls zu importieren und im Fehlerfall auf die Python-Implementierung zurückzugreifen, ist nicht mehr notwendig. Python erledigt dies automatisch (siehe Listing 4). Genaueres zu den Änderungen der Standardbibliothek ist unter [16] zu finden. Alle Exceptions müssen nun von »BaseException« abgeleitet sein. Dies impliziert insbesondere, dass Python 3 String-Exceptions nicht mehr unterstützt. Das Exception-Objekt erhält ein neues Attribut »__traceback__«, das den Traceback der Exception enthält.
|
Listing 4: |
|---|
01 try: 02 import cPickle as pickle 03 except ImportError: 04 import pickle |
Sowohl der Aufruf als auch das Fangen von Exceptions mit Argumenten hat sich verändert: Eine Exception mit Argument wirft der Programmierer nun mit dem Ausdruck »raise BaseException(args)«, mit »except BaseException as variable« fängt er sie (Abbildung 4).
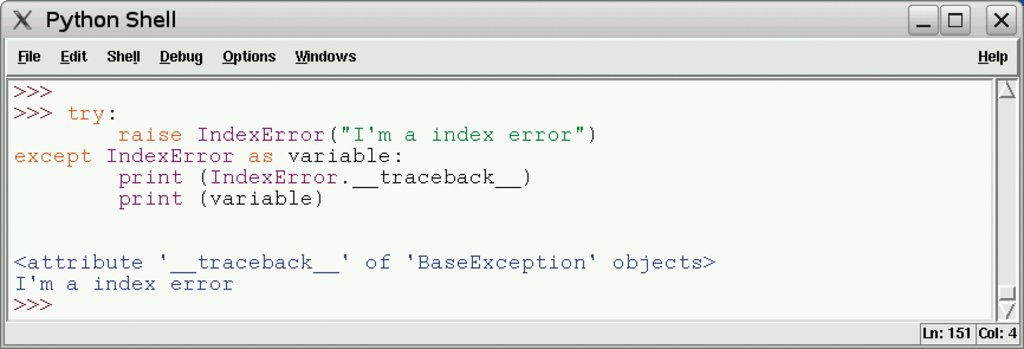
Abbildung 4: Die Exception hat als neues Attribut den Traceback erhalten.
Es gibt weitere Punkte, die das Leben des Python-Programmierers erleichtern. So muss er bei kooperativen »super«-Aufrufen nicht mehr die Instanz der Klasse und den Klassennamen nennen. Die Old-Style-Klassen, bereits “deprecated”, existieren mit Python 3.0 nicht mehr, sodass das lästige Ableiten von »object« nicht mehr notwendig ist, um die neueren Features von Python anzusprechen.
Das unmittelbare Evaluieren der Eingabe mit Hilfe des Kommandos »input()« ist nicht mehr möglich, da die Eingabe als Eingabestring zur Verfügung steht. Damit hat sich ein extremes Sicherheitsloch geschlossen (Abbildung 5). Konsequenterweise wurde die Funktion »raw_input()« in »input()« umbenannt sowie »raw_input()« entfernt.
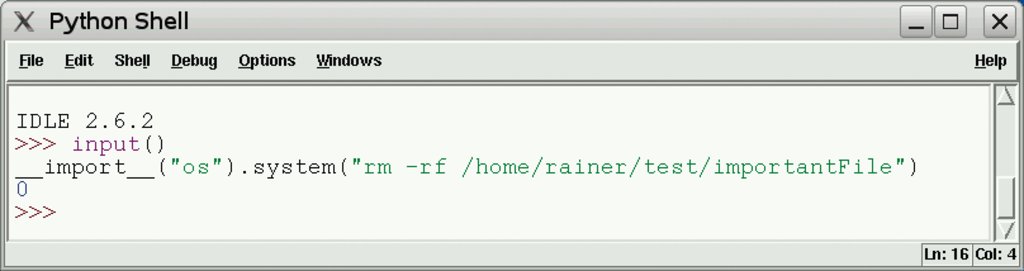
Abbildung 5: Das Evaluieren der Eingabe mittels Input-Kommando ist in Python 3 nicht mehr möglich.
Die Darstellung all dieser neuen Features kann natürlich nur unvollständig sein. Wer es genauer wissen will, sollte das Referenzdokument von Guido von Rossum “What\’s New In Python 3.0” unter [17] nachlesen.
Auf dem Weg zu 3.0
Zum Portieren von Python-2-Code nach Python 3 zeichnet sich ein klar definierter Pfad (Abbildung 6) ab, wobei der Entwickler nach jedem Schritt den Code testen und Probleme beseitigen muss. Die vier Codezeilen in Listing 5 sollen als Beispiel für die Migration von Python 2 nach 3.0 dienen. Alle vier Zeilen des Beispiels verwenden funktionale Komponenten von Python, da sich bei diesen Built-in-Funktionen einige Veränderungen vollzogen haben.
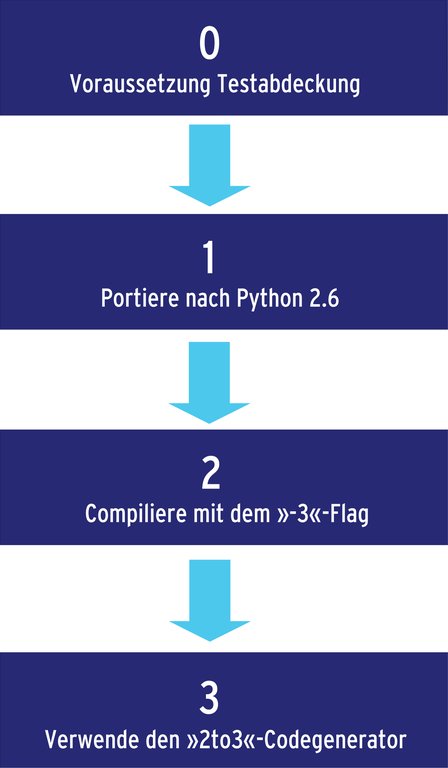
Abbildung 6: Für die Portierung von Python-2.6-Code auf Version 3 gibt es einen empfohlenen Weg.
|
Listing 5: Zu portierender |
|---|
01 print "sum of the integers: " , apply(lambda a,b,c: a+b+c , (2,3,4)) 02 print "factorial of 10 :", reduce(lambda x,y: x*y, range(1,11) ) 03 print "titles in text: ", filter( lambda word: word.istitle(),"This is a long Test".split()) 04 print "titles in text: ", [ word for word in "This is a long Test".split() if word.istitle()] |
Die erste Funktion berechnet die Summe der drei Zahlen 2, 3 und 4, indem sie diese Argumente auf die Lambda-Funktion anwendet. Das Built-in »reduce()« reduziert sukzessive die Liste aller Zahlen von 1 einschließlich der 10, indem sie das Ergebnis der letzten Multiplikation mit der nächsten Zahl aus der Sequenz multipliziert. Die letzten zwei Funktionen filtern aus dem String alle Wörter heraus, die mit einem Großbuchstaben beginnen. Der Code funktioniert bereits unter Python 2.6, sodass nur noch die Schritte 3 und 4 für die Portierung zu vollziehen sind. Der Quelltext ist in diesem Beispiel in einer Datei mit dem Namen »port.py« gespeichert.
Ein Aufruf des Python-2.6-Interpreters mit der Option »-3« (Abbildung 7) zeigt die Inkompatibilitäten zur Version 3: Sowohl die Funktion »apply()« als auch die Funktion »reduce()« sind in Python 3.0 keine Built-ins mehr. Der Code ist schnell repariert (Listing 6) und die Deprecation-Warnungen unterbleiben.
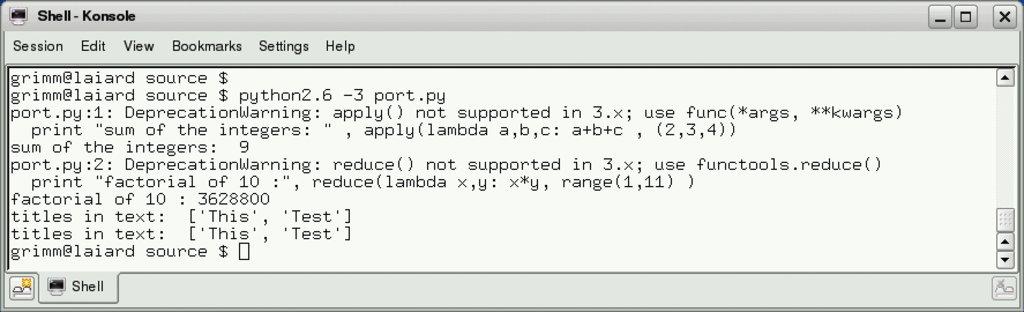
Abbildung 7: Die Python-3-Option von Python 2.6 zeigt Probleme für die Portierung auf.
|
Listing 6: Behebung der |
|---|
01 print "sum of the integers: " , (lambda a,b,c: a+b+c)(*(2,3,4)) 02 import functools 03 print "factorial of 10 :", functools.reduce(lambda x,y: x*y, range(1,11) ) 04 print "titles in text: ", filter( lambda word: word.istitle(),"This is a long Test".split()) 05 print "titles in text: ", [ word for word in "This is a long Test".split() if word.istitle()] |
Der Codegenerator »2to3« erweist sich bei der Korrektur des Python-2-Code als sehr hilfreich, denn er erzeugt im letzten Schritt automatisch Code für die Versionen 3.0 und 3.1. Dazu bietet das Tool mehrere Optionen an (Abbildung 8). Der direkte Weg besteht darin, die Ursprungsdatei zu überschreiben: »2to3 port.py -w«. Das Ergebnis ist der nach Python 3.0 portierte Quelltext (Listing 7). Interessanterweise hat der Codegenerator den »filter()«-Ausdruck durch eine äquivalente List-Comprehension ersetzt.
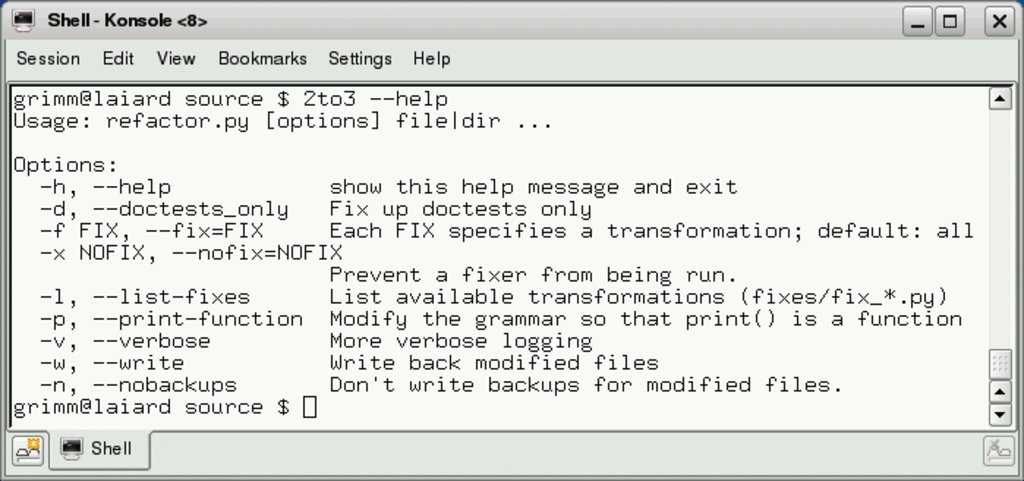
Abbildung 8: Der Codegenerator »2to3« kennt zahlreiche Optionen.
|
Listing 7: Nach Python 3.0 |
|---|
01 print("sum of the integers: " , (lambda a,b,c: a+b+c)(*(2,3,4)))
02 print("factorial of 10 :", reduce(lambda x,y: x*y, list(range(1,11)) ))
03 print("titles in text: ", [word for word in "This is a long Test".split() if word.istitle()])
04 print("titles in text: ", [ word for word in "This is a long Test".split() if word.istitle()])
|
Python 3.0 legt hauptsächlich Wert auf die Funktionalität, daher läuft es um etwa 10 Prozent langsamer als Python 2. Die notwendigen Optimierungen sind in Python 3.1 erfolgt [18]. Dies betrifft die Spezialbehandlung kleiner Integers. Darüber hinaus ist in Python 3.1 die I/O-Bibliothek in C implementiert, sodass sie um den Faktor 2 bis 20 schneller ist. Auch das Dekodieren der Zeichensätze UTF-8, UTF-16 und Latin-1 geschieht doppelt bis viermal so schnell.
Wann umsteigen?
Wann also sollten Python-Programmierer bestehenden Code auf Python 3 portieren? Das ist relativ einfach zu beantworten: Bevor nicht die benötigten Bibliotheken der Drittanbieter auf Python 3 portiert sind, ergibt es keinen Sinn, den Anwendungscode auf den neuen Python-Zweig zu aktualisieren. Guido von Rossum selbst empfiehlt außerdem, keinen Code zu schreiben, der sowohl auf Python 2.6 als auch auf Python 3 unmodifiziert läuft [19]. Besser sei es vielmehr, die Quelltexte als Python-2.6-Code zu pflegen und sie erst bei Bedarf mit den automatischen Tools nach Python 3.0 oder 3.1 zu portieren.
Das Schlusswort stammt von Christopher Neugebauer, der in einem Videovortrag zu Python 3000 sagt: “Lernt 2.6. Aber behaltet 3k im Hinterkopf.” (mhu)
|
Der Autor |
|---|
|
Rainer Grimm arbeitet seit 1999 als Software-Entwickler bei der Science + Computing AG in Tübingen. Insbesondere hält er Schulungen für das hauseigene Produkt SC Venus. |





