
© Sherri Camp, Fotolia.de
Vor gut zwei Jahren wirkte der Landstrich OCR-Software auf der Karte der freien Softwarewelt allenfalls dünn besiedelt. Dank zweier Open-Source-Releases ehemals kommerzieller Engines, Tesseract und Cuneiform, hat sich dies geändert.
Vor zweieinviertel Jahren, im Linux-Magazin 12/06, hat schon einmal eine Bitparade freie OCR-Software getestet. Standen damals Fragen wie “Erkennt die Software Umlaute?” im Mittelpunkt und konnte der Anwender froh sein, wenn Scannen und anschließendes Korrekturlesen im Vergleich zum Eintippen überhaupt Zeit sparte, so spielt freie OCR-Software inzwischen in einer anderen Liga: Bei qualitativ guten Vorlagen ist eine praktisch fehlerfreie Erkennung die Messlatte, deutsche Umlaute oder französische Akzente zu erkennen ist selbstverständlich. Auch Text in Spalten ist für freie Software keine Hexerei mehr.
Freigelegt
Die Fortschritte bei der freien OCR-Software gehen zu einem guten Teil aufs Konto der Open-Source-Release einer ehemals kommerziell erfolgreichen Engine, Cuneiform [1]. Doch auch die Entwicklung der von Google gesponserte freie Texterkennungssoftware Tesseract [2], die sich Ende 2006 noch nicht für deutsche Texte eignete, ist ein gutes Stück vorwärts gekommen. Mit Ocropus [3] liegt zudem eine experimentelle Layout-Erkennungs-Software für Tesseract vor. Cuneiform integriert die Layout-Erkennung bereits in die OCR-Engine.
Cuneiform
Cognitive Technologies, ein russischer Software-Hersteller, ehemals direkter Konkurrent der Finereader-Engine von Abbyy, hat seine OCR-Engine nach einiger Zeit des Stillstands bei der Entwicklung als Freeware und schließlich als Open-Source-Software freigegeben. Gegenwärtig steht Cuneiform unter der BSD-Lizenz, eine Release unter der GPL ist geplant.
Seit August 2008 gibt es auf Launchpad-Net [4] einen Linux-Port der freien Engine, inzwischen liegt Version 0.5 vor. Eine Entwicklerfassung spielt die Versionsverwaltung Bazaar mit »bzr branch lp:cuneiform-linux« auf die Festplatte. Im Test auf Ubuntu 8.04 ließ sich die Software ohne Probleme übersetzen, dank des verlässlichen Buildsystems Cmake ist der Erfolg wohl reproduzierbar.
Die Cuneiform-Engine versteht unter anderem die Sprachen Englisch, Deutsch, Französisch, Spanisch, Italienisch, Portugiesisch, Niederländisch, Russisch, Dänisch, Schwedisch und Finnisch. Sie führt außerdem eine Layoutanalyse durch, sodass die Erkennung auch in Spalten angeordneten Text nicht durcheinanderwürfelt. Das Ergebnis einer Layout-Erkennung gibt die Software im Hocr-Format wieder, einem etablierten HTML-ähnlichen Markup-Format, das Firefox fehlerfrei anzeigt.
Tesseract
Auch bei Tesseract kam im Test die SVN-Version zum Einsatz. Merkwürdigkeiten wie das früher eingesetzte Buildsystem Jam gibt es wie bei der stabilen Version 2.03 nicht mehr. Das Übersetzen gelang mit »./configure; make« auf Anhieb.
Anders als Cuneiform, das Buchstaben ohne Training aus festgelegten Formmerkmalen erkennt und daher nicht mit Handschriften, auch nicht handschriftähnliche Truetype-Schriften funktioniert, lässt sich Tesseract prinzipiell für beliebige Zeichensätze und Sprachen trainieren. Fertige Trainingsdaten für Englisch, Deutsch, Niederländisch, Französisch, Spanisch und Italienisch bringt die Software mit. Zuzeit erkennt Tesseract allerdings keine Seitenlayouts. Diese Einschränkung überwindet allerdings die quelloffene Software Ocropus, die eine Forschungsgruppe der Universität Kaiserslautern [5] entwickelt.
In einem Block
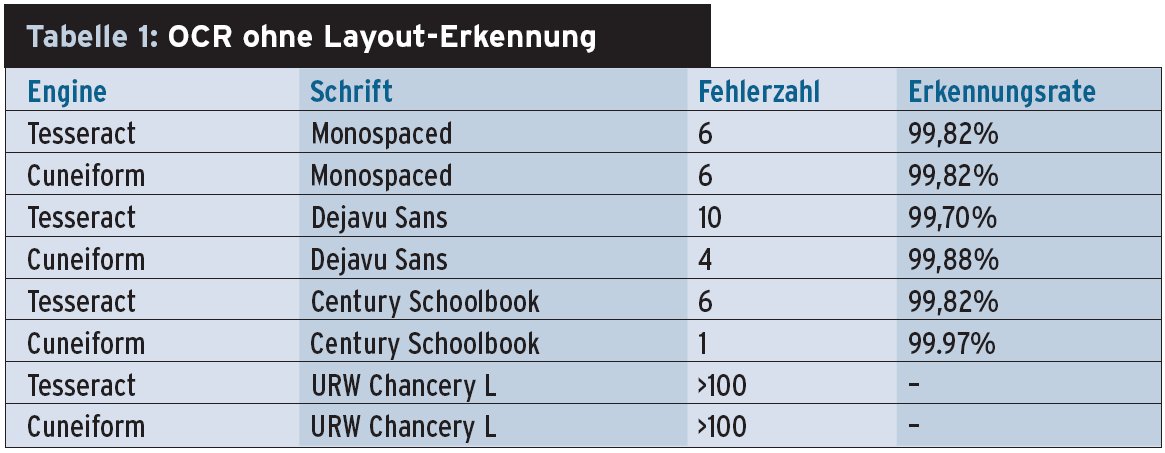
Die erste Aufgabe für die OCR-Software stellt ein qualitativ recht hochwertiger Graufstufen-Scan mit einem ganzseitigen DIN A4 Text ohne Spalten (Abbildung 1). Da es sich um einen Tintenstrahlausdruck handelt, sind die Kanten der Buchstaben zwar nicht völlig glatt, die Buchstabenform ist aber gut erkennbar. Dies bringt die beiden Engines, wie Tabelle 1 zeigt, nicht in Verlegenheit: Im ersten Durchlauf mit der Schriftart Monospaced arbeiten sie solide, wenn auch keineswegs fehlerfrei.

Abbildung 1: Eine einspaltige Textvorlage in vier verschiedenen Schriften testet die Engines ohne Layout-Erkennung. Der vergrößerte Bereich in der Mitte macht die Qualität des Scans sichtbar.
Im 3351 Zeichen langen Testtext, einem Ausschnitt aus einem Linux-Magazin-Artikel, leisten sich beide sechs Erkennungsfehler. Das entspricht einer Erkennungsleistung von 99,82 Prozent, was sich vermutlich hinter dem Komma im Vergleich mit einer kommerziellen Software wie der Abbyy-Finereader-Engine spürbar unterscheidet. Leider war das Abbyy-SDK, das es auch für Linux gibt, trotz mehrmaliger Nachfrage bis Redaktionsschluss nicht eingetroffen.
|
Tabelle 1: OCR ohne |
|---|
|
|
|
Durchsuchbare PDFs |
|---|
|
Die Open-Source-Toolsammlung Exaktimage [6] sehen ihre Macher als geschwindigkeitsoptimiertes Imagemagick. Unter den Exaktimage-Tools findet sich das Programm »hocr2pdf«, das die Scanvorlage als Bild gemeinsam mit dem erkannten Text in ein PDF verpackt. Das PDF sieht im Betrachter daher genauso aus wie das Original, ist also unabhängig von OCR-Fehlern lesbar. Dennoch kann der Awnender es nach Stichworten durchsuchen oder Text daraus kopieren. Exaktimage ist aus dem SVN-Repository unter [http://svn.exactcode.de/exact-image/trunk] erhältlich. Es ließ sich im Test auf Ubuntu 8.04 problemlos mit »./configure; make« kompilieren. Mit den Hocr-Dateien von Cuneiform entstehen mit »hocr2pdf« passgenaue Sandwich-PDFs (Abbildung 2). 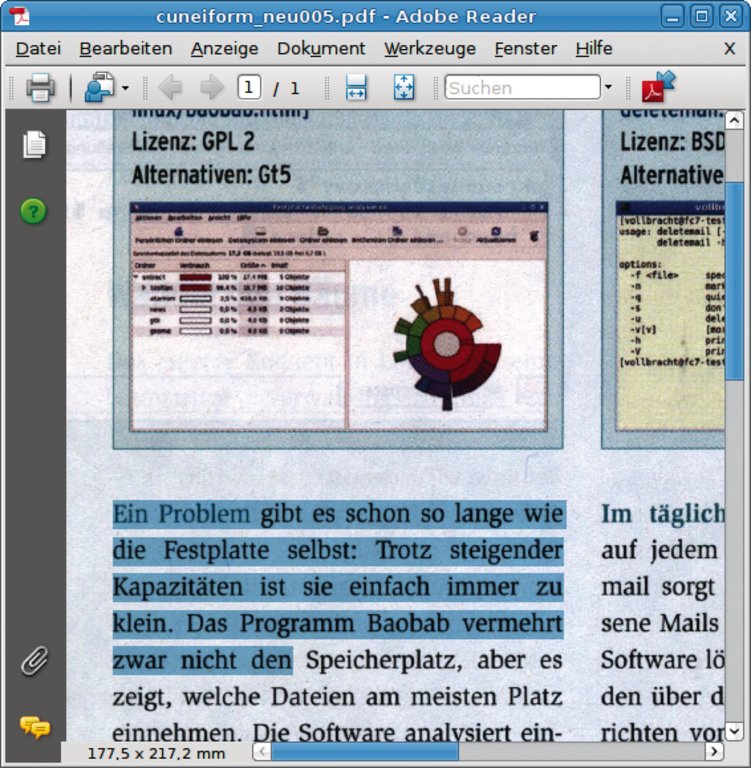 Abbildung 2: Perfektes Archivierungsformat: Bei den mit »hocr2pdf« erzeugten Sandwich-PDFs liegen die Abbildung des Originaldokuments und der erkannte Text exakt übereinander. |
Immer das Gleiche
Bei Erkennungsfehlern handelt es sich oft um die gleichen Buchstaben. Bei jeder Engine sind dies jedoch andere, sodass es sich vermutlich nicht um eine die Erkennung erschwerende Eigenart des benutzten Fonts handelt. Ein Test mit einer serifenlosen Proportionalschrift, also einem Font mit wechselnder Breite bei unterschiedlichen Buchstaben, und einer Serifenschrift, einer Schrift mit kleinen Häkchen an den Buchstabenenden, fördern weitere Stärken und Schwächen der Engines zu Tage (Tabelle 1): Die serifenlose Schrift verschlechter bei Tesseract die Erkennung, eine Serifenschrift führt dagegen zur gleichen Fehlerzahl wie bei der Monospaced-Schrift.
Bei der Serifenschrift Century Schoolbook, die den Lettern in Tageszeitung ähnelt, fällt Cuneiform mit nur einem Fehler angenehm auf und erreicht eine Erkennungsrate, die auch kommerzielle Engines schwer überbieten können. Für die stark kursive, einer Handschrift mit Tuschfeder angenäherten Schriftart URW Chancery liefert mit jeweils weit über 100 Fehlern keine der Engines brauchbare Ergebnisse. Tendenziell schlägt sich Tesseract etwas besser. Mit entsprechendem Aufwand ließe es sich – anders als Cuneiform – auf die Schrift trainieren.
Layouts erfassen
In der Praxis liegt Text häufig in Spalten vor. Ocropus, das Layout-Addon für Tesseract hat die Betaversion 0.3.1 erreicht. Bei ersten Tests nach dem Kompilieren mit »./configure; make« trat auch gleich ein handfestes Problem zu Tage: Ocropus wertete den Parameter »–tesslanguage« für die Spracheinstellung von Tesseract nicht aus, sodass bei deutschen Texten die Umlaute fehlten. Das Setzen der gleichnamigen Umgebungsvariablen »export tesslanguage=deu« brachte dann allerdings den gewünschten Erfolg – ob zufällig, weil die Skriptumgebung für das eingesetzte Lua die Bash-Umgebung importiert oder ob von den Entwicklern so geplant, sei dahingestellt. Auf jeden Fall lässt sich Ocropus damit für deutsche Texte nutzen.

Abbildung 3: Einfacher Einstiegstest für die Layout-Erkennung: Ein zweispaltiger Text mit Überschrift, jedoch ohne Kästen oder Abbildungen.
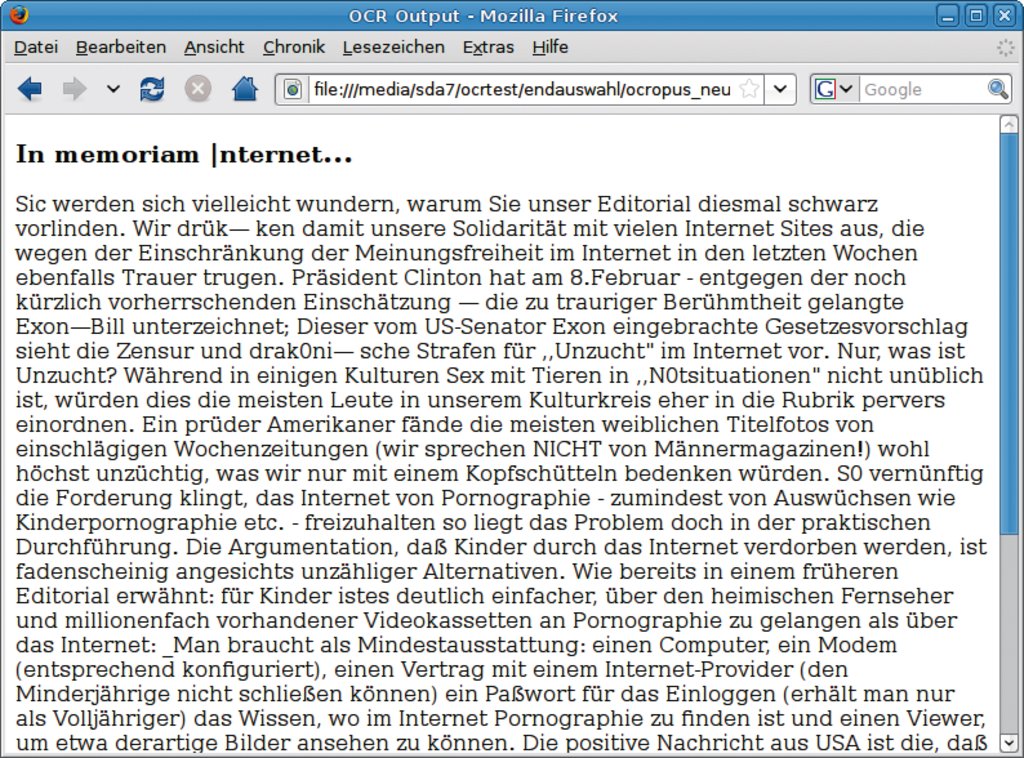
Abbildung 4: Klassenziel erreicht: Ocropus erkennt die Textspalten. Die mittelmäßige Vorlagenqualität schlägt sich aber in vielen Erkennungsfehlern nieder.
|
Archivista-Box |
|---|
|
Die Archivista-Box ist eine Appliance zur Dokumentenarchivierung. Die darauf laufende Software (Abbildung 5) hat der Hersteller [7] als Open-Source-Software freigegeben [8]. Die Software erzeugt mit Hilfe der freien OCR-Engines Tesseract und Cuneiform durchsuchbare PDFs, die sie in einem über ein Webfrontend zugänglichen Archiv speichert. Außer als Archivlösung eignet sich die in Form eines bootbaren ISO bereitgestellte Software auch dazu, die Texterkennung mit Tesseract und Cuneiform ohne Installation auszuprobieren. Mit SANE funktionsfähige Scanner lassen sich auch mit der Live-CD für den Test benutzen. Allerdings enthält die aktuelle Archivista-Version die bereits veraltete Cuneiform-Version 0.3. 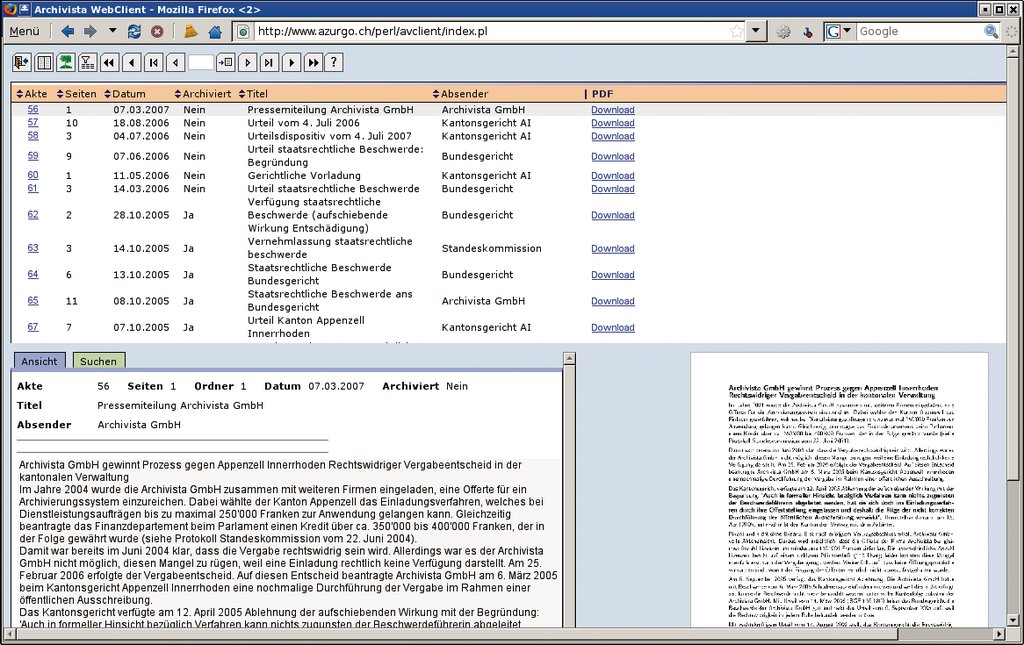 Abbildung 5: Die Archivista-Software erstellt durchsuchbare PDFs mit Tesseract und Cuneiform. Mit der als Live-ISO bereitgestellten Software lassen sich die Engines ohne Installation testen. |
Komplexere Form
Erster Test für die Layout-Erkennung ist eine einfache zweispaltige Textvorlage (Abbildung 3). Die Software muss lediglich sie Spaltenposition erkennen und den Text in der richtigen Reihenfolge einlesen. Tesseract würde die Spalten als eine durchlaufende Textzeile interpretieren. Schaltet man dagegen Ocropus vor, übersetzt die Engine den Spaltensatz richtig (Abbildung 6). Der Aufruf auf der Kommandozeile dafür lautet »ocroscript input.png >output.hocr«, die Umgebungsvariable »tesslanguage« muss dabei den Spachcode für die Tesseract-Engine enthalten, »deu« bei deutschem Text.
Auch Cuneiform erkennt die Spalten richtig und liest die Halbzeilen in der richtigen Reihenfolge ein (Abbildung 6). Auch mit der Vorlage aus Abbildung 7, einer dreispaltigen Tooltipps-Seite, klappt die Layout-Erkennung (Abbildung 8). Wegen des geringen Kontrasts beim farbigen Hintergrund unterlaufen bei der Erkennung allerdings viele Fehler.
Ein ähnliches Bild ergibt sich bei Ocropus (Abbildung 9). Allerdings bereiten Tesseract die farbig hinterlegten Kästen noch mehr Schwierigkeiten als Cuneiform.

Abbildung 6: Cuneiform erkennt die Textspalten und leistet sich im Vergleich zu Tesseract bei der mittelmäßigen Vorlage weniger Erkennungsfehler.

Abbildung 7: Ein typisches Magazinlayout mit dreispaltigem Text, Kästen und Abbildungen stellt die Praxistauglichkeit der Layout-Erkennung auf die Probe.
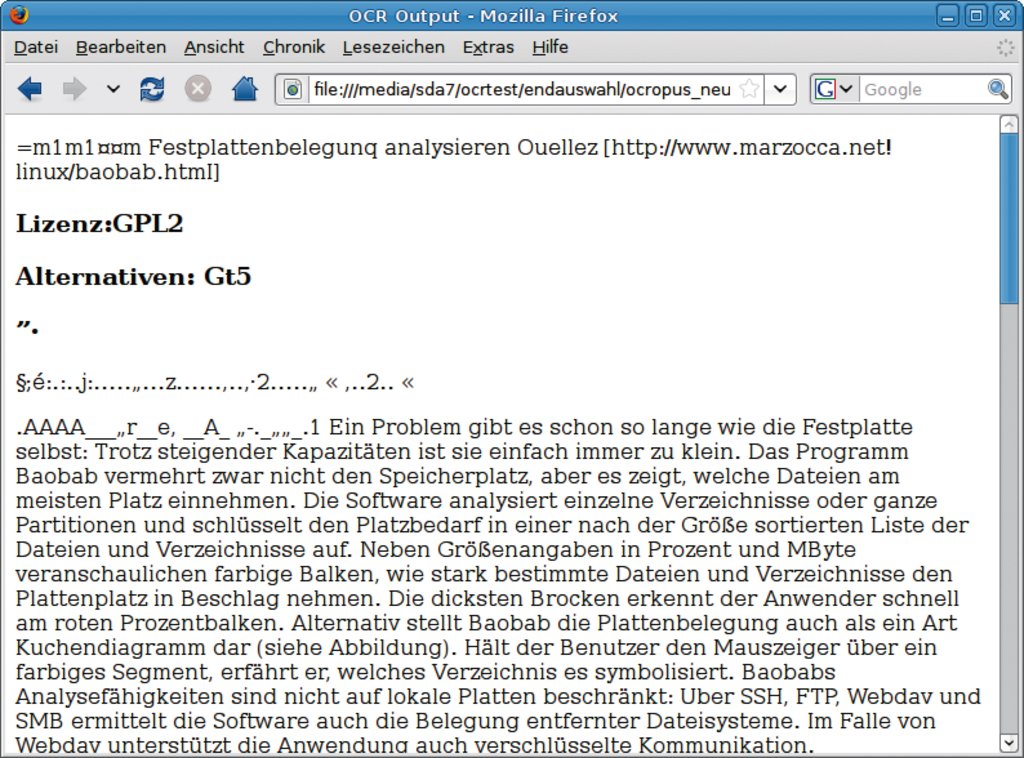
Abbildung 8: Die dreispaltige Magazinseite erkennt Cuneiform richtig – mit Einschränkungen bei der Erkennungsgenauigkeit wegen des farbigen Hintergrunds.

Abbildung 9: Auch Ocropus erkennt das Layout der Linux-Magazin-Seite richtig, leistet sich aber bei der Texterkennung noch mehr Fehler als Cuneiform.
Formatsache
Sowohl Ocropus als auch Cuneiform erzeugen Dateien im Hocr-Format. Dabei handelt es sich um HTML-Dateien, die mit Hilfe von absolut positionierten »Span«-Tags das Layout des Originaldokuments nachzubilden versuchen. Diese Dateien lassen sich im Browser betrachten. Ein Blick in den Quellcode zeigt, dass Cuneiform jeden einzelnen Buchstaben platziert (Abbildung 10), Ocropus dagegen nur einzelne Zeilen. Zwar wachsen die Dateigrößen bei Cuneiform auf ein Vielfaches der Textlänge, in der Praxis spielt dies jedoch kaum eine Rolle.
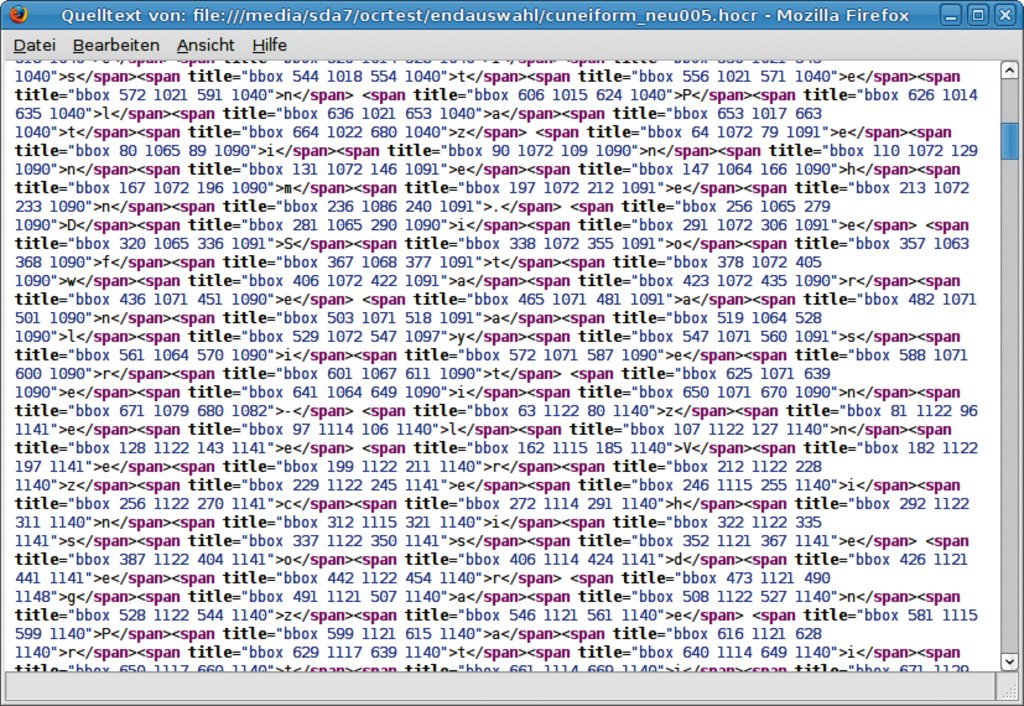
Abbildung 10: Cuneiform umgibt in den Hocr-Dateien jeden Buchstaben einzeln mit »span«-Tags. Die Akribie zahlt sich beim Umwandeln in ein PDF aus.
Sandwich-Technik
Die freie Software Exaktimage (siehe Kasten “Durchsuchbare PDFs”) erstellt aus Hocr-Dateien durchsuchbare PDFs, also PDF-Dokumente, bei denen sandwichartig ein Bild des Originaldokuments und transparent der mit OCR erkannte Text übereinander liegen. Dies ist die optimale Kombination für die Datenarchivierung. Die Abbyy-Engine erstellt solche PDFs seit Jahren so präzise, dass der Anwender, wenn er den Auswahl-Cursor über das Bild bewegt, stets den gewünschten Teil des unsichtbaren Textees markiert. Nur aus den Hocr-Dateien von Cuneiform lassen sich solche PDFs erzeugen.
Sieg nach Punkten
Bei den Formaten der zu verarbeitenden Dateien zeigten sich sowohl Cuneiform als auch Tesseract wählerisch: Tesseract erkennt nur Tiff-Dateien, die zudem noch die in der Windows-Welt übliche Drei-Buchstaben-Endung ».tif« tragen müssen. Cuneiform scheiterte dagegen an Graustufen-Bitmaps und lieferte nur mit dem RGB-Format, das den dreifachen Speicherplatz belegt, zufriedenstellende Testergebnisse.
Insgesamt geht Cuneiform aus dem Vergleich als Sieger hervor. Außer bei in der Praxis häufigen Serifenschriften fällt der Vorsprung bei der reinen Zeichenerkennung nicht allzu deutlich aus.
Text in Spalten setzt Tesseract mit der vorgeschalteten Layout-Engine Ocropus zwar korrekt in Fließtext um. Nur Cuneiform positioniert allerdings die Buchstaben in einer Hocr-Datei exakt genug für Sandwich-PDFs aus Bilddatei und erkanntem Text.
|
Infos |
|---|
|
[1] Cuneiform: [http://www.cuneiform.ru/eng/] [2] Tesseract: [http://code.google.com/p/tesseract-ocr/] [3] Ocropus: [code.google.com/p/ocropus/] [4] Cuneiform für Linux: [http://launchpad.net/cuneiform-linux] [5] IUPRR-Forschungsgruppe: [http://www.iupr.com] [6] Exaktimage: [http://www.exactcode.de/site/open_source/exactimage/] [7] Archivista: [http://www.archivista.ch/de/] [8] Archivista-Software: [http://sourceforge.net/projects/archivista] |





