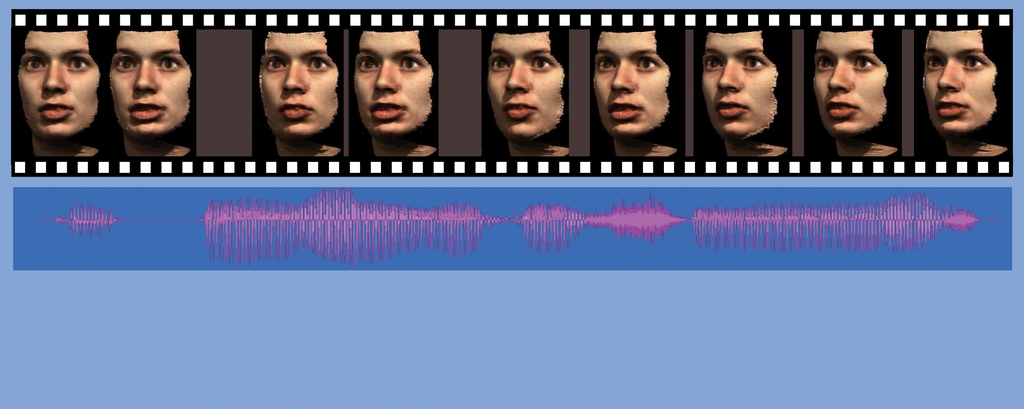
Abbildung 1: Eine Audio-Aufnahme und ein vorbereitetes 3D-Modell: Die lernbasierte Gesichtsanimation macht daraus einen Kurzfilm, in dem ein Sprecher die Lippen zum Text bewegt. Die mühevolle Kleinarbeit der Character-Animation entfällt. So entstehen in Echtzeit qualitativ hochwertige 3D-Avatare.
Sprechende Bilder: Diesen Ausdruck nimmt Robert Bargmann recht wörtlich. Sein Forschungsprojekt "Lernbasierte Gesichtsanimation" sorgt auf der Basis von Audiodaten bei 3D-Modellen unter Linux automatisch für die entsprechende Mundbewegung.
Abbildung 1: Eine Audio-Aufnahme und ein vorbereitetes 3D-Modell: Die lernbasierte Gesichtsanimation macht daraus einen Kurzfilm, in dem ein Sprecher die Lippen zum Text bewegt. Die mühevolle Kleinarbeit der Character-Animation entfällt. So entstehen in Echtzeit qualitativ hochwertige 3D-Avatare.
Animierte 3D-Characters, deren Mundbewegungen zum gesprochenen Text passen, gibt es schon recht lange. Wie bei handgefertigten Zeichtrickfiguren ist es bisher jedoch dem Geschick der Animateure zu verdanken, wenn die Lippenbewegungen der Computer-generierten Figuren natürlich wirken. Der finanzielle Aufwand für eine hochwertige Character-Animation erreicht dabei schnell Hollywood-Dimensionen.
Das Verfahren zur lernbasierten Gesichtsanimation [1], an dem Robert Bargmann am Max Planck Institut für Visual Computing und Communication in Saarbrücken arbeitet, soll den Animationskünstlern einen Teil ihrer Arbeit abnehmen (Abbildung 1). “Stellen Sie sich vor, Sie rufen ihren Freund mit Skype an. Das Programm zeigt dabei ein 3D-Modell seines Gesichts an, das die Lippen passend zu dem, was er sagt, bewegt”, umreißt Bargmann eine mögliche Anwendung seines Forschungsprojekts.
Die Grundlage für die Mundbewegungen bilden die Aufnahmen eines dynamischen 3D-Scanners, der das Gesicht eines sprechenden Menschen 40-mal pro Sekunde vermisst. Derartig schnelle 3D-Scanner gibt es noch nicht sehr lange: “Früher benötigten statische Scanner über zehn Sekunden, um ein räumliches Objekt zu erfassen. Da konnte man nur nachgestellte Mundpositionen scannen, die oft übertrieben wirkten. Unsere Technik filmt einen Sprecher, der in normaler Geschwindigkeit redet, mit 40 Frames pro Sekunde.”
Optik und Akustik
Linguisten unterteilen den Lautbestand einer Sprache in Phoneme, also unterschiedliche Laute, aus deren Kombination sich die Wörter ergeben. Die zugehörigen Mundstellungen nennt Bergmann Viseme: Für ein helles i formt ein Sprecher seine Lippen anders als für ein dunkles a. Um die Korrespondenz zwischen Visemen und Phonemen genauer zu ermitteln, schneidet Bargmann den Klang und die Mundbewegungen von zehn Sätzen mit. Als Rohdaten ergeben sich 2000 dreidimensionale Gesichtsscans (Abbildung 2).

Abbildung 2: Lippenlesen: Ein 3D-Scan analysiert die Mundbewegungen eines Sprechers und gibt sie als 3D-Mesh-Reihe wieder.
Die gängige Methode, um die Form räumlicher Körper Computer-tauglich zu beschreiben, sind 3D-Gitternetze, so genannte Meshes. Die räumlichen Positionen der Netzmaschen definieren die Form eines Objekts. Auch 3D-Scanner liefern solche Meshes. Problematisch an den Rohdaten vom Scanner ist allerdings, dass die Lage der Netzmaschen zwischen den Scans variiert, selbst wenn sie das gleiche räumliche Objekt wiedergeben. Erst ein Optical-Flow-Verfahren [2] vereinheitlicht die Meshes, sodass sie die gleiche Anzahl von Gitterpunkten aufweisen und damit eine geeignete Basis für das Herausarbeiten der Mundbewegung abgeben.
Jedes Gitternetz besteht aus mehreren hunderttausend Gitterpunkten. Eine Hauptkomponenten-Analyse [3] fahndet systematisch nach den größten Formveränderungen unter den Modellen. Etwa die ersten 50 Bewegungskomponenten sind für die Analyse der Mundbewegung relevant, der Rest besteht zum größten Teil aus Rauschen.
Am liebsten unter Linux
Auf die optische Analyse folgt die akustische: Die Open-Source-Anwendung CMU-Sphinx [4] zerlegt das gleichzeitig mit den 3D-Modellen aufgenommene Audio-File in eine Phonemfolge. “Jetzt wissen wir, welchen Laut die Figur in einem bestimmten Frame des 3D-Films ausspricht. Eine weitere Herausforderung besteht nun darin, fließende Übergänge zwischen den Mundbewegungen zu erzeugen.” Dazu ordnet Bargmann das Ergebnis der Hauptkomponenten-Analyse in einem 50-dimensionalen Raum an. Jede Achse dieses Raums entspricht einer bestimmten Verformung des Mundes. Jede Lippenstellung lässt sich als ein Punkt im Komponentenraum beschreiben. Der fließende Übergang ergibt sich aus einer Geraden durch zwei Punkte, die den gewünschten Lippenstellungen entsprechen.
Mit Ausnahme von CMU-Sphinx programmiert Robert Bargmann die Software für sein Projekt selbst. Er verwendet dabei Xemacs und den GNU-Compiler »g++« auf einem Debian-System. “Ich bevorzuge zum Programmieren Linux, weil ich es gewohnt bin, auf der Konsole zu arbeiten, freie Software zu benutzen und Skripte zur Arbeitserleichterung einzusetzen.”
Nach der optischen und akustischen Analyse fehlt nur noch die Übertragung der Lippenbewegungen auf andere räumliche Modelle. “Dazu benutze ich ein Verfahren meines Doktorvaters Professor Blanz, der inzwischen an der Universität Siegen unterrichtet.” Diese Technik unterzieht die 3D-Scans von 200 Gesichtern einem Optical-Flow-Verfahren. Dies vereinheitlicht auch hier die Meshes, sodass sie die gleiche Zahl an Netzmaschen aufweisen.
Gleitende Übergänge
Eine Hauptkomponenten-Analyse bildet Unterschiede zwischen den Gesichtern ebenfalls in einem multidimensionalen Raum ab. Wie bei den Mundpositionen sind so stufenlosen Übergänge zwischen den verschiedenen Gesichtern möglich. Die gleitende Überblendung heißt Morphing. Integriert eine weitere Optical-Flow-Analyse das Gesichtsmodell aus dem Scan der Lippenbewegungen in das multidimensionale Gesichtskontinuum, dann lassen sich die Mundbewegungen auf alle darin enthaltenen Gesichter anwenden. “Das Erlernen der Mundbewegungen kostet einiges an Rechenzeit. Die Synthese der Mundbewegungen kann jedoch in Echtzeit erfolgen. Die Phonemanalyse einer Audiodatei nimmt wenige Zehntelsekunden in Anspruch.”
Außer realistischen 3D-Avataren kann sich Bargmann vorstellen, dass sein Forschungsprojekt vielleicht einmal dazu beiträgt, das Synchronisieren von Kinofilmen zu revolutionieren. Bisher legen Synchronsprecher mehr schlecht als recht den übersetzten Text über die Lippenbewegungen des Films. Sowohl bei der Übersetzung als auch bei der Übereinstimmung von Sprache und Lippenbewegung sind dabei Kompromisse unvermeidlich. “Unser Morphable-Model-Verfahren ermöglicht es, aus 2D-Bildern 3D-Modelle abzuleiten. Auf dieser Basis lassen sich vielleicht in Zukunft – umgekehrt als bisher – die Mundbewegungen der Schauspieler im fertigen Film an den übersetzten Text anpassen.”
|
Infos |
|---|
|
[1] Projektseite Gesichtsanimation: [http://www.mpi-inf.mpg.de/~bargmann/research_facialanimation.html] [2] Optischer Fluss: [http://de.wikipedia.org/wiki/Optischer_Fluss] [3] Hauptkomponentenanalyse: [http://de.wikipedia.org/wiki/Hauptkomponentenanalyse] [4] CMU-Sphinx: [http://cmusphinx.sourceforge.net/html/cmusphinx.php] |





