
Für hochverfügbare Linux-Systeme sind Cluster oder Failover-Lösungen die Mittel der Wahl. Mit Linux Heartbeat gelingt das sehr einfach – beispielsweise ein redundanter NFS-Server mit geteilter Platte.
Zwei Maschinen, ein paar Kabel, ein Switch und drei IP-Adressen genügen, um Netzwerkdienste ausfallsicher anzubieten. Im konkreten Fall sind es zwei handelsübliche Desktop-Rechner mit je zwei Netzwerkkarten, einem Fibrechannel-Interface und installiertem Red Hat 8.0. Als gemeinsamer Datenpool dient ein Diskarray, das SCSI über Fibrechannel anbietet und auf diesem Weg an beide Computer angeschlossen ist. Der gerade aktive Rechner stellt den Inhalt des Diskarrays per NFS im Intranet zur Verfügung. Fällt der aktive Server aus, springt sein Double ein und sorgt dafür, dass die Clients nichts von dem Wechsel der NFS-Server bemerken.
Solide Basis dank Linux-HA
Die solide Basis für dieses Vorhaben stammt aus dem Linux-HA-Projekt. Dessen Ziel ist es, Linux-Systeme zur Hochverfügbarkeit aufzurüsten. Ein Teil des Projekts ist Heartbeat[1], das in diesem Artikel beschrieben wird. Um zu verhindern, dass beide Server gleichzei- tig auf die gemeinsame Platte schreiben, kommt zusätzlich Stonith zum Einsatz (Shoot the other node in the head). Damit dreht der Ersatzserver der Maschine, für die er einspringt, rechtzeitig den Strom ab und hindert sie damit zuverlässig am Schreiben.
Zwillingsschwestern
Ein Cluster ist einfacher zu konfigurieren, wenn beide beteiligten Systeme identisch aufgesetzt sind. Für einen NFS-Server genügt es, Red Hat in der Server-Basisvariante zu installieren, das Paket »nfs-utils« ist per Default mit dabei. Notwendig sind zudem Entwicklungstools wie »gcc« und »make« sowie »glib-devel« und »libnet«[2]. Soll das Gerät später auf SNMP-Requests reagieren, benötigt es zusätzlich das Paket »net-snmp-devel«.
In Tabelle 1 ist die Konfiguration der beiden Knoten zu sehen. Die Hostnamen und IP-Adressen sollten entweder im DNS oder in den »/etc/hosts«-Dateien beider Nodes aufgeführt sein. Abbildung 1 zeigt die Vernetzung der Systeme.
Wie Linux auf die gemeinsam genutzten Platten des Diskarrays zugreift, hängt von den verwendeten Fibrechannel-Karten und dem Diskarray ab. Hat der Admin diese Hürde genommen, muss er die Platten nur noch partitionieren und formatieren. Im Beispiel kommt die Ext-3-formatierte Partition »/dev/sdc1« zum Einsatz. Möglich und sinnvoll sind viele Alternativen, etwa mit LVM (Logical Volume Manager) oder Raid. Auf der externen Platte liegen später die Daten selbst sowie die NFS-Lockfiles. Wichtig: Die »/etc/fstab« bleibt unberührt. Das Ein- und Aushängen der Partitionen übernimmt später Heartbeat.
Stonith
Wenn zwei Systeme auf dieselbe Festplatte zugreifen können, ist es zwingend erforderlich, dass sie sich gegen gleichzeitiges Beschreiben einer Partition absichern. Im Normalfall käme das nicht vor: Nur wenn ein Server ausfällt, übernimmt der andere und beginnt erst dann damit, auf die Platte zu schreiben. Hält ein Cluster-Knoten seinen Partner für tot, während dieser in Wahrheit noch munter die Platte füllt, dann schreiben dennoch beide Rechner auf die Platte. Das führt zu zerstörten Dateisystemen und in der Folge zu mühsamen Rettungsaktionen.
Dieser Daten-GAU lässt sich mit Stonith verhindern. Dabei handelt es sich im Grunde um ein Stück Hardware zwischen der Steckdose und dem Server (siehe Abbildung 2a). Vermutet die Cluster-Software, dass eine Maschine abgestürzt ist, klemmt sie mit Hilfe von Stonith dem betreffenden Server den Strom ab. Nach einer definierten Zeitspanne lässt das Gerät wieder Strom durch, das Linux-System fährt hoch und löst gegebenenfalls den zweiten Cluster-Knoten wieder ab.
Sollten trotz aller Vorsicht dennoch beide Server kurzzeitig auf die Platte schreiben, stellt die ziemlich unfein anmutende Stonith-Methode sicher, dass der abgeschossene Server kein »umount« und damit keinen »sync« auslöst – er würde dabei Daten aus dem Speicher auf die Platte schreiben. Mit Stonith gehen zwar die Daten im Cache verloren, doch das Dateisystem bleibt heil.
Im Handel sind verschiedene Modelle und Typen von Stonith-Geräten verfügbar, oft unter dem Namen Master Switch oder Power Switch. Das Angebot reicht von preisgünstigen Switches mit zwei Ports und einer Speisung bis zu Geräten mit doppelt ausgelegten Netzteilen und acht oder mehr Ausgangsports.
Das beschriebene Beispiel setzt einen Master Switch von APC mit einem Eingang und acht Ausgängen ein. Diese Architektur hat zwar den Nachteil, dass ein kurzer Zug am falschen Kabel den ganzen Cluster abschaltet, dafür ist das Kosten-Nutzen-Verhältnis aber sehr günstig. Wer mehr Aufwand treiben kann, setzt besser auf eine redundante Anordnung mit je einem Stonith-Gerät pro Server (siehe Abbildung 2b).
Der APC Master Switch lässt sich bequem über ein Webinterface konfigurieren. Wichtig ist, dass die beiden Power-Ausgänge, an denen die Server hängen, den exakten Hostnamen der Server erhalten (»uname -n«). Andernfalls wird Heartbeat keine Möglichkeit haben, die betreffende Maschine abzuschalten. Die Server müssen das Recht haben, SNMP-Kommandos an das APC-Gerät zu senden; APC sieht dafür den Typ »Write+« vor. Wichtig: Der Master Switch ist der wunde Punkt im Cluster. Eine sehr effiziente Denial-of-Service-Attacke ist es, den Servern den Strom abzuklemmen. Darum muss das Stonith-Gerät gut vor Eindringlingen geschützt sein.
|
Tabelle |
||
|---|---|---|
|
Funktion |
Hostname |
IP |
|
Knoten 1 (Master) |
one |
192.168.0.201 |
|
Knoten 2 |
two |
192.168.0.202 |
|
Gemeinsame IP |
cluster |
192.168.0.200 |
|
APC-Master |
apc |
192.168.0.100 |
|
Heartbeat 1 |
– |
172.16.0.1 |
|
Heartbeat 2 |
– |
172.16.0.2 |
Zwei Nabelschnüre
Die beiden Maschinen müssen voneinander wissen, wer gerade aktiv ist und wer nicht. Dazu sind sie mit Heartbeat-Kabeln verbunden. Diese Verbindungen sollten mehrfach vorhanden sein: Am besten über ein serielles Nullmodem-Kabel und zusätzlich über ein gekreuztes Ethernetkabel am »eth1«-Port beider Computer. »eth0« erhält die echte IP sowie die gemeinsame virtuelle IP.
Zwei kurze Tests garantieren, dass beide Nabelschnüre funktionieren. Nach dem Öffnen des seriellen Interface auf einem Node mit »cat < /dev/ttyS0« kann die andere Seite Daten über diese Verbindung senden: »echo test > /dev/ttyS0«. Wenn jetzt auf dem ersten Rechner der Text »test« erscheint, dann funktioniert die serielle Leitung in dieser Richtung. Es empfiehlt sich, auch die andere Richtung zu testen. Klappt die Übertragung nicht oder erscheint eine Fehlermeldung, dann ist das Serial-Howto[3] eine gute Hilfe.
Die Ethernet-Verbindung lässt sich mit einem einfachen Ping testen. Beide Server müssen dabei eine IP-Adresse im gleichen Subnetz besitzen. Der erste Knoten erhält:
ifconfig eth1 172.16.0.1 up
Der zweite Rechner erhält ebenfalls eine Adresse und sendet ein Ping an die erste Maschine:
ifconfig eth1 172.16.0.2 up ping 172.16.0.1
Ist das Ping erfolgreich, dann ist die Eth1-Konfigurationen in »/etc/sysconfig/network-scripts« für beide Interfaces zu erstellen. Listing 1 zeigt die Konfiguration für Knoten 1. Die zweite Maschine erhält die gleiche Konfiguration, nur mit der IP-Adresse 127.16.0.2. Damit ist gewährleistet, dass beide Schnittstellen beim nächsten Neustart die korrekte IP-Adresse erhalten.
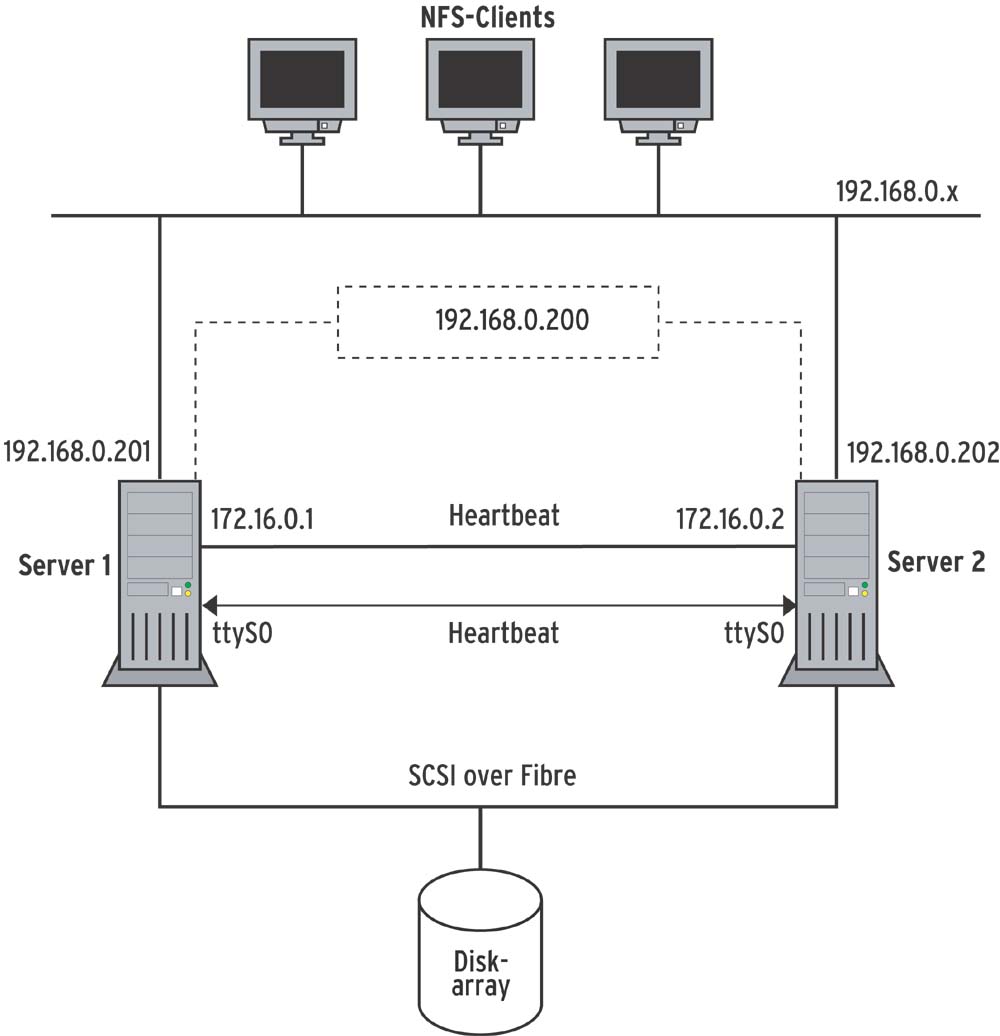
Abbildung 1: Die NFS-Clients sehen nur die IP-Adresse »192.168.0.200«, hinter der sich zwei Server verbergen. Diese greifen auf ein gemeinsames Speichermedium zu und erfahren per Heartbeat-Leitung, ob der Partner noch reagiert.
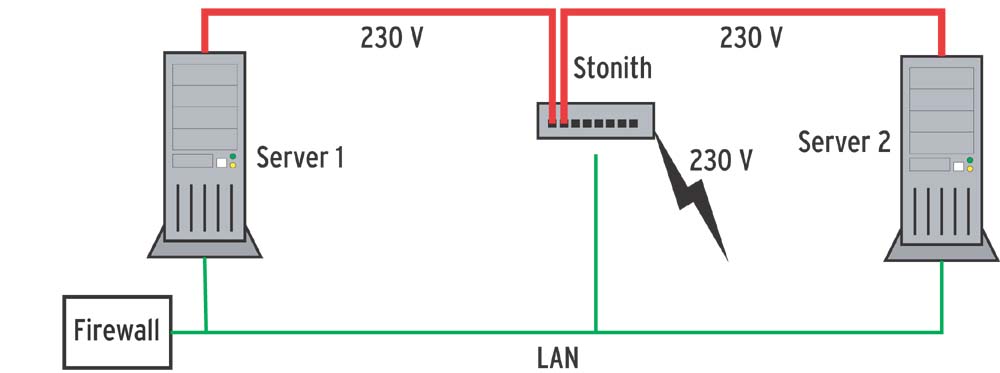
Abbildung 2a: In der klassischen Anordnung beziehen beide Server ihren Strom über ein zentrales Stonith-Gerät, das sie auch fernsteuern.
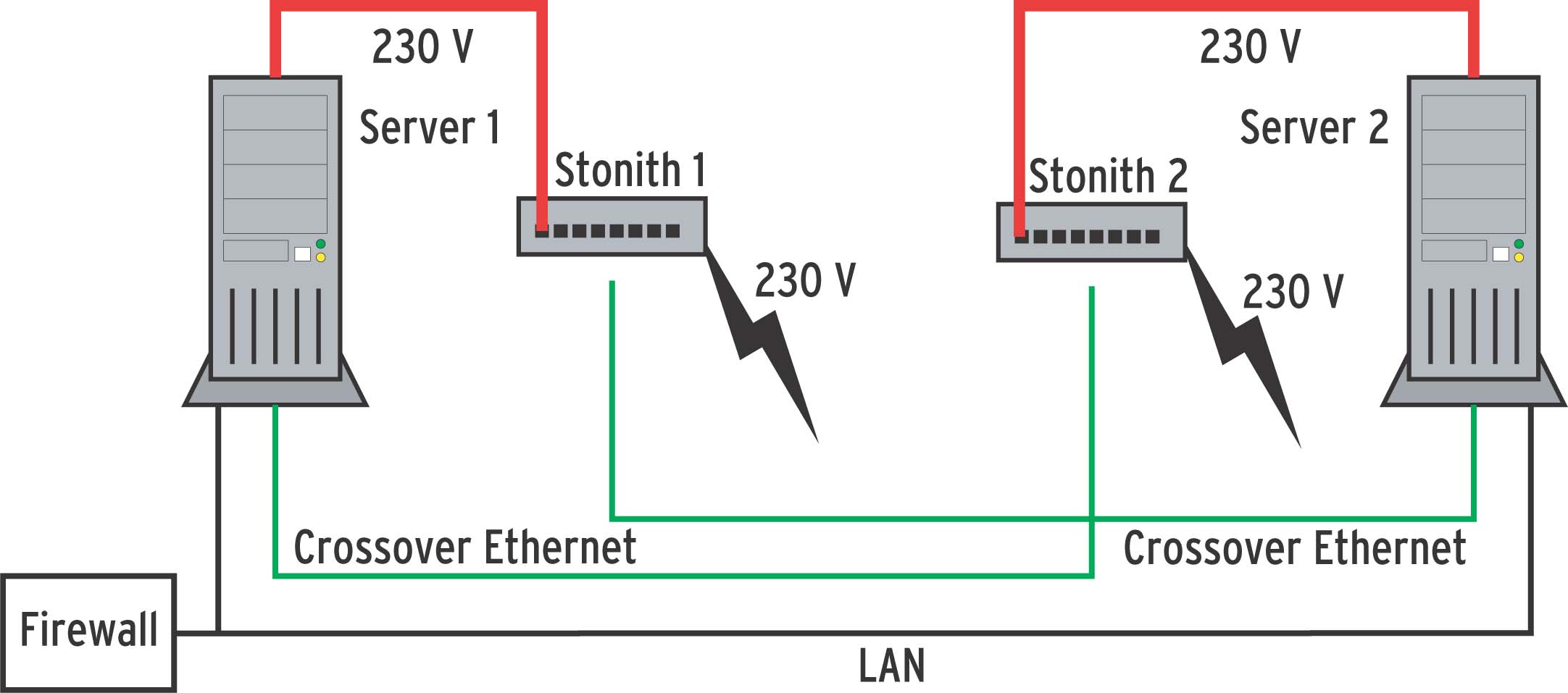
Abbildung 2b: Sicherer ist diese Verkabelung mit Redundanz: Jeder Server kontrolliert das Stonith-Gerät seines Partners über ein Crossover-Ethernetkabel.
Herztöne
Jetzt ist es an der Zeit, Heartbeat zu installieren (siehe Kasten “Herztransplantation”). Damit sind beide Systeme bereit für den Cluster. Als nächste Komponente ist das Stonith-Gerät beim Konfigurieren und Testen an der Reihe. Das Heartbeat-Paket enthält den Befehl »stonith«: ohne Argumente eingetippt gibt er eine lange und ziemlich unübersichtliche Liste der verfügbaren Geräte aus. Jedes dieser Geräte versteht einen eigenen Satz von Kommandos, die teilweise nicht dokumentiert sind.
Das Stonith-Programm benötigt eine Datei »/etc/ha.d/rpc.cfg« mit der IP-Adresse oder dem Hostnamen des Stonith-Geräts sowie Login und Passwort oder SNMP-Community und SNMP-Port. Welche Einträge für welches Gerät erforderlich sind, lässt sich mit »stonith -t Gerätename dummy« herausfinden. Das Kommando zeigt auch, wie die Datei aussehen muss – für den APC-Master- Switch enthält sie auf beiden Cluster-Knoten die folgenden Zeilen:
#IP Port Community 192.168.0.100 161 stw
Die SNMP-Community benötigt die Rechte »Write+«, um einzelnen Ports den Strom abklemmen zu dürfen. Sind die Ports richtig benannt, kann jetzt Knoten 2 dem ersten Knoten den Strom abdrehen:
stonith -t apcmastersnmp one
Das Kontrolllicht geht aus und der Switch kappt die Stromzufuhr. Nach einer definierten Zeitspanne stellt er die Versorgung wieder her und der Linux-Server fährt hoch.
Heartbeat braucht noch die drei Dateien »/etc/ha.d/ha.cf«, »/etc/ha.d/haresources« und »/etc/ha.d/authkeys«. Beispiele für diese Files sind in »/usr/share/doc/heartbeat-1.0.1/« zu finden. Sie sind ausführlich dokumentiert und selbsterklärend.
|
Listing 1: |
|---|
01 DEVICE=eth1 02 BOOTPROTO=static 03 IPADDR=172.16.0.1 04 NETMASK=255.255.255.0 05 ONBOOT=yes |
|
Listing 2: |
|---|
01 # /etc/ha.d/ha.cf 02 debugfile /var/log/ha-debug 03 logfile /var/log/ha-log 04 logfacility local0 05 deadtime 20 06 initdead 120 07 serial /dev/ttyS0 08 baud 19200 09 udpport 694 10 bcast eth1 11 stonith apcmastersnmp /etc/ha.d/rpc.cfg 12 node one 13 node two |
Startvorbereitung
Aus der längeren Datei »ha.cf« liest der Heartbeat-Daemon beim Start seine Standardwerte. Sie müssen nicht auf beiden Maschinen gleich sein, beispielsweise kann der eine Node ohne weiteres auf einem anderen seriellen Port auf Herztöne lauschen oder seine Logging-Ausgaben an eine andere Stelle schreiben. Listing 2 zeigt eine Standardkonfiguration ohne Kommentare.
Die Datei »haresources« muss auf beiden Seiten des Clusters identisch sein. Sie definiert die zu übertragenden Dienste, den Hauptknoten und die Cluster-IP-Adresse. Die Vorlage in »/usr/share/doc/heartbeat-1.0.1/« ist sehr gut dokumentiert und enthält viele praktische Beispiele. Für einen NFS-Cluster ist nur folgende Zeile nötig:
one 192.168.0.200 Filesystem::/dev/sda1::/data::ext3 nfslock nfs
Das erste Wort in der Zeile beschreibt den Hostnamen (»uname -a«) des Master-Servers, darauf folgt die Cluster-IP-Adresse. Dahinter stehen die Dienste, die von Heartbeat gestartet beziehungsweise beendet werden sollen: Beim Start sucht Heartbeat in »/etc/init.d/« und in »/etc/ha.d/resource.d/« nach den Skripten, die in »haresources« aufgelistet sind. Für obiges Beispiel könnte der volle Name des Skripts also »/etc/ha.d/resource.d/Filesystem« lauten.
Heartbeat übergibt den Parameter »start« an das Skript. Weitere Parameter kann der Admin durch doppelte Doppelpunkte getrennt angeben – Heartbeat stellt diese noch vor das »start«-Argument. Der Filesystem-Eintrag führt so zu folgendem Kommando:
/etc/ha.d/resource.d/Filesystem /dev/sda1 /data ext3 start
Analog hält Heartbeat die Dienste in umgekehrter Reihenfolge mit dem »stop«-Parameter an.
Das Verzeichnis »/etc/ha.d/resource.d/« enthält Skripte für spezielle Dienste. Das Modul »Filesystem« beispielsweise hängt Partitionen ein und wieder aus. Die Quellen der Skripte sind gut dokumentiert und zeigen deren Verwendung anhand von Beispielen.
Die dritte Datei, »authkeys«, ist für das Authentifizieren der Herztöne über die Ethernet-Schnittstelle erforderlich. Bei einer direkten Verbindung per Crossover-Kabel ist das kaum nötig; läuft Heartbeat jedoch über ein unsicheres Netz, schützt diese Option die Server vor Denial-of-Service-Angriffen. Im vorliegenden Fall genügt eine Pseudo-Authentifizierung per CRC:
auth 1 1 crc
Heartbeat verlangt aus Sicherheitsgründen recht strenge Zugriffsrechte: »chmod 600 /etc/ha.d/authkeys«.
Damit die HA-Software nach einem Reboot automatisch startet, müssen die Links in den entsprechenden Runlevels stimmen (Listing 3). Zu beachten ist, dass das Netzwerk vor Heartbeat starten muss, da sonst der Rechner den anderen Knoten für inaktiv hält und ihm per Stonith den Strom abdreht.
Doppelter NFS
Bislang kam NFS nur am Rande zur Sprache. NFS ist einer der Dienste, die sich mit Heartbeat redundant auslegen lassen. Ziel in dem hier behandelten Beispiel ist es, die Partition »/dev/sda1« in »/data« einzuhängen und über NFS freizugeben. Beide Maschinen haben Zugriff auf diese Partition. Wichtig ist dabei Folgendes: Es darf keinen Eintrag in »/etc/fstab« geben, sonst entsteht die Gefahr, dass beide Systeme gleichzeitig schreiben. Die »mount«- und »umount«-Aktionen erledigt das Heartbeat-Skript »Filesystem«.
NFS verwaltet seine Filelocking-Dateien normalerweise im Verzeichnis »/var/lib/nfs«. Wenn allerdings »/data« im Fall eines Fehlers von Knoten 1 zu Knoten 2 migriert, bleiben die Lockfiles auf dem bisher zuständigen Server. Damit hat NFS ein Problem: Die Clients melden Fehler und können nicht mehr auf Dateien zugreifen.
Um dies zu vermeiden, müssen die Lockfiles ebenfalls auf den neuen Server migrieren. Das gelingt am einfachsten, wenn sie auf der gemeinsamen Partition liegen. Nach einem manuell ausgeführten »mount /dev/sda1 /data« kann man das Verzeichnis verschieben: »mv /var /lib/nfs /data/varlibnfs«. Ein Symlink gibt dem NFS-Daemon sein Verzeichnis zurück: »ln -sf /data/varlibnfs /var /lib/nfs«. Danach muss man die Platte noch aushängen, Heartbeat mountet sie später wieder.
Der »rpc.statd«-Prozess, der im Startskript »/etc/init.d/nfslock« initialisiert wird, identifiziert sich mit seinem Hostnamen. Normalerweise nutzt er dazu die Libc-Funktion »gethostname()« – doch liefert diese statt des Clusternamens den Namen des aktuellen Node. Um das Problem zu beheben, bietet »statd« den Schalter »-n«. Das Startskript muss ihn nur passend setzen:
start() {
...
echo -n "Starting NFS statd: "
daemon rpc.statd -n cluster
RETVAL=$?
...
}
NFS gibt die in »/etc/exports« eingetragenen Verzeichnisse frei. Die Benutzer sollen nichts von den Lockfiles wissen, der Admin exportiert daher nur Unterverzeichnisse von »/data/«. Für erste Tests genügt folgender Eintrag:
/data/userdata *(rw)
|
Herztransplantation |
|---|
|
Die Quellen von Heartbeat sind bei[4] verfügbar. Dort ist auch ein kurzes Howto für den Einstieg zu finden. Um Heartbeat zu kompilieren, ist zunächst Libnet notwendig: wget http://www.packetfactory.net/ libnet/dist/libnet.tar.gz tar zxvf libnet.tar.gz cd Libnet-latest ./configure make make install-strip Ist Libnet erfolgreich installiert, lässt sich Heartbeat mit minimalem Aufwand konfigurieren und kompilieren: wget http://www.linux-ha.org/ download/heartbeat-1.0.1.tar.gz tar zxvf heartbeat-1.0.1.tar.gz cd heartbeat-1.0.1 ./ConfigureMe make make install-strip |
Endspurt
Nun ist alles vorbereitet. Die beiden Nodes im Cluster wissen, was wann zu tun ist, und das Stonith-Gerät klemmt im Zweifelsfall den Strom ab. Auf beiden Knoten lässt sich Heartbeat jetzt starten: »/etc/init.d/heartbeat start«. Ein Blick in »/var/log/messages« und »/var/log/ ha-*« zeigt das saubere Hochkommen der Dienste auf Node 1. Die gemeinsame IP-Adresse ist bereits pingbar und liegt auf »eth0:0« von Knoten 1.
Stoppt der Administrator die Heartbeat-Software auf dem Master manuell mit »/etc/init.d/heartbeat stop«, übernimmt Knoten 2 die Platte und die Arbeit. Er meldet im Syslog »/var/log/messages« unter anderem die in Listing 4 zu sehenden Zeilen. Sobald Heartbeat vom ersten Node wieder die entsprechenden Signale liefert, lässt Node 2 die Services, die Platte und die IP-Adresse fallen und übergibt wieder an den Master.
Stonith ist bislang noch nicht in Aktion getreten. Heartbeat wurde jeweils sauber heruntergefahren und hat dementsprechend den Takeover angekündigt. Wird Node 1 derart überbelastet, dass er die Dienste nicht mehr geordnet übergeben kann, dann dreht ihm Heartbeat den Strom ab. Ein kleines, als Root gestartetes Bash-Skript, simuliert diesen Zustand:
#!/bin/bash
:(){ :|:&};:
Es gibt bestimmt nettere und auch effizientere Methoden, beispielsweise CPUburn, doch hat das Skript eine gewisse morbide Eleganz. Nach dem unsauberen Reboot kommt die Maschine wieder hoch und übernimmt ihre Arbeit. Die NFS-Clients bemerken von der Übernahme nichts.
Ausblick
Mit Heartbeat lassen sich auch deutlich aufwändigere Szenarien umsetzen. Beispielsweise ist eine Aktiv-Aktiv-Konfiguration, bei der beide Nodes parallel arbeiten und sich die Last teilen, durchaus realisierbar. Ein Blick in »/etc/ha.d/ resource.d/« bietet einen Überblick über weitere Dienste, die man ohne großen Aufwand in die »haresources« aufnehmen kann.
Treten Probleme auf, ist die Mailingliste[5] außerordentlich hilfsbereit. Die Entwickler von Heartbeat und einige sehr erfahrene Administratoren lesen mit und helfen gerne. (fjl)
|
Listing 3: |
|---|
01 cd /etc/rc0.d ; ln -s ../init.d/heartbeat K03heartbeat 02 cd /etc/rc3.d ; ln -s ../init.d/heartbeat S80heartbeat 03 cd /etc/rc5.d ; ln -s ../init.d/heartbeat S80heartbeat 04 cd /etc/rc6.d ; ln -s ../init.d/heartbeat K03heartbeat |
|
Listing 4: Knoten 2 |
|---|
01 info: Taking over resource group 192.168.0.200 02 info: /sbin/ifconfig eth0:0 192.168.0.200 ... 03 info: Running /etc/ha.d/resource.d/Filesystem ... 04 info: Running /etc/init.d/nfslock start 05 info: Running /etc/init.d/nfs start 06 info: mach_down takeover complete for node one. |
|
Infos |
|---|
|
[1] Heartbeat-Homepage: [http://www.linux-ha.org/heartbeat/] [2] Libnet: [http://www.packetfactory.net/libnet/dist/] [3] Serial-Howto: [http://www.ibiblio.org/pub/Linux/docs/HOWTO/Serial-HOWTO] [4] Heartbeat-Download: [http://www.linux-ha.org/download/] [5] Kontakt und Mailinglisten: [http://www.linux-ha.org/contact/] |
|
Der |
|---|
|
André Bonhôte arbeitet als IP-Engineer bei COLT Telecom Zürich. Er war maßgeblich am Aufbau einer Internet-Plattform beteiligt, die auf einem NFS-Cluster basiert. |





