
Hurd als freies Betriebssystem geht auf eine Idee von Richard Stallman zurück, die viel älter als Linux ist. Von Debian herausgegeben, können erfahrene Anwender heute die hier beschriebenen interessanten Designkonzepte selbst studieren.
Im Jahr 1998 startete Marcus Brinkmann eine Portierung der Debian-Distribution auf Hurd. Auf diese Weise entkam Hurd auch aus Sicht der Anwender dem reinen Experimentalstadium. Seither ist eine Unmenge von Programmen portiert worden und man konnte auch gleich viele Bugs in Hurd korrigieren. Aktuell füllt Debian GNU/Hurd schon vier CDs. Das System ist bislang aber nur für Unix/Linux-erfahrene Anwender betreibbar; und vom produktiven Einsatz sollten auch die tunlichst absehen. Wer in dieses Raster passt, findet am Ende des Beitrags praktische Hinweise, um Hurd auf dem eigenen PC einen Platz zu reservieren.
Was ist so interessant an diesem freien Betriebssystem? Das Ziel des GNU/ Hurd-Projekts ist es von Anfang an, die Software so weit wie möglich frei von künstlichen Einschränkungen zu halten. GNU-Software schneidet zum Beispiel im Gegensatz zu ihren Unix-Pendants die Eingabezeilen nicht nach einer willkürlichen Anzahl Zeichen ab.
Bei Hurd beschränkt sich das Prinzip von Uneingeschränktheit nicht nur auf die Details der Implementierung, sondern ist nach den jeweils aktuellen Erkenntnissen der Entwickler im Design der Software verwurzelt.
Hurd ist mehr als nur ein Redesign von Unix
Im Wesentlichen ist Hurd eine Sammlung von Daemons, die gemeinsam die Funktionalität bereitstellen, die in traditionellen Systemen der Kernel übernimmt. Die Hurd-Entwickler bezeichnen Daemons auch als Server, da sie auch normalen Benutzerprogrammen ihre Dienste anbieten. Beispielsweise gibt es einen Server für das Ext-2-Dateisystem, einen für den IP-Netzwerk-Stack und einen, der für die Posix-Prozessverwaltung zuständig ist.
Nur die Treiber, die direkt die Hardware ansprechen, sowie einige grundlegende Mechanismen befinden sich noch im Hurd-Kernel. Gegenwärtig wird hierbei eine von den Hurd-Entwicklern angepasste Version des Mach-Mikrokernels (siehe[4]) eingesetzt.
Wo Unix-artige Systeme – wie auch Linux – Systemaufrufe einsetzen, senden Hurd-Prozesse eine Nachricht an einen Server, der diese verarbeitet und das Resultat als Nachricht zurücksendet (siehe Abbildung 1). Für das Nachrichten-Handling zeichnet die Standardbibliothek Glibc verantwortlich. Ein Benutzerprozess braucht sich damit um den Unterschied nicht zu kümmern. Untereinander kommunizieren die Hurd-Server auch über Nachrichten – zumeist direkt, aber auch per Glibc.
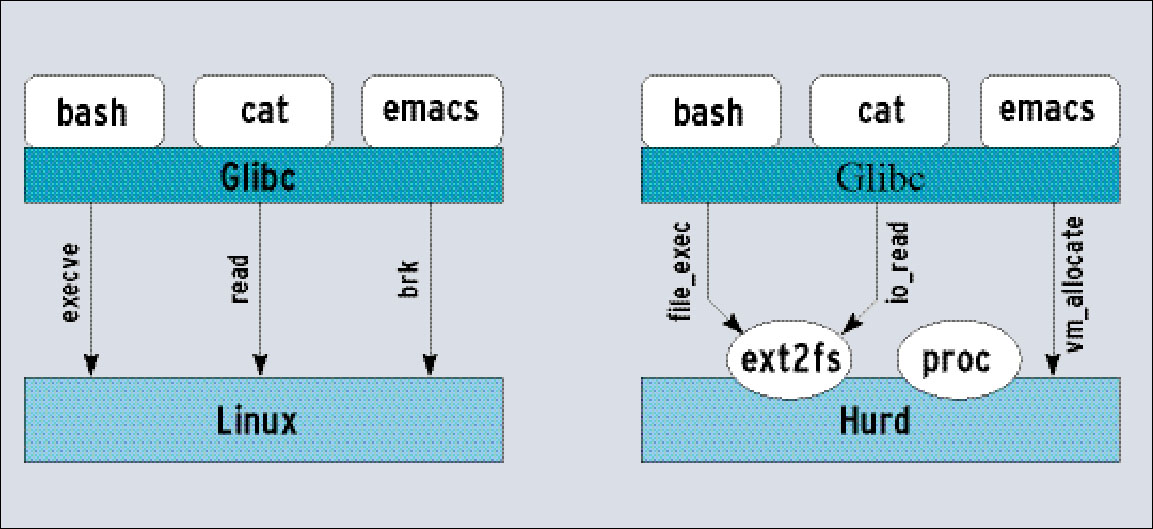
Abbildung 1: Ein Vergleich des grundlegenden Aufbaus von Linux und Hurd. Auf der einen Seite ein monolithischer Kernel, auf der anderen mehrere Server und der Mach-Mikrokernel.
Die Server im Userspace bringen mehr Freiheit
Server sind bei GNU/Hurd gewöhnliche Prozesse: Jeder Benutzer hat das Recht sie zu starten. Das verschafft Usern die Gelegenheit, ihre eigene Umgebung zu bauen ohne dabei die Sicherheit des Gesamtsystems zu gefährden. Diese kleine Welt kann wie eine Posix-Umgebung aussehen oder auch vollkommen anders oder eine Mischung aus eigenen und Posix-Komponenten enthalten. Im Regelfall wird man so weit aber gar nicht gehen, sondern lediglich einige Dinge zur Standardumgebung hinzufügen.
Üblich passiert dies mit dem Dateisystem als Namensraum: Man befestigt einen Server an einem Punkt im Dateisystem, der dort seine Dienste anbietet. (Das ähnelt dem Mounten eines Dateisystems unter Linux.) In diesem speziellen Zusammenhang bezeichnen die Hurd-Entwickler einen solchen Server auch als Übersetzer (Translator). Die Funktionalität der Übersetzer ist nicht auf solche Dateisystem-ähnlichen Gebilde beschränkt, sondern könnte auch auf den gängigen Posix-Systemen undenkbare Features liefern.
Durch diese Kombination aus Flexibilität und Kompatibilität entsteht ein System, das aufregende Neuerungen bietet, ohne dass seine Anwender auf Vorzüge wie die Paketverwaltung von Debian-Linux oder die Auswahl an Software verzichten müssen. Dass das nicht blanke Theorie ist, wird in den folgenden Abschnitten die Funktionalität einiger Hurd-Übersetzer exemplarisch zeigen.
Abbildung 2: Charakteristische GNU/Hurd-Kommandos – gepaart mit dem Beweis, dass X11 mit Hurd läuft.
Settrans: Loopback-Mounts für alle Hurd-Benutzer
Ein Dateisystem-Image mountet man unter Linux per Loopback-Device. Ein Beispiel:
mount -t ext2 -o loop=/dev/loop0 floppy.img /mnt
Ohne expliziten »/etc/fstab«-Eintrag ist das nur dem Administrator gestattet, weil sonst ein bösartige Benutzer durch ein selbst hergestelltes, manipuliertes Dateisystem-Image den Kernel in Verlegenheit bringen könnte.
Da Dateisysteme bei Hurd allerdings normale Programme sind, darf sowieso jeder Benutzer etwa einen »ext2fs«-Server starten. Einen Übersetzer befestigt der User per »settrans«-Kommando – egal ob Loopback oder nicht. (In der Tat kennt Hurd das Konzept des Loopback-Mountens so nicht.) Hier das Beispiel für Hurd:
settrans -c ~/my_floppy /hurd/ext2fs floppy.img
Der Inhalt des Disketten-Image »floppy.img« wird im Verzeichnis »my_floppy« im Homeverzeichnis des Benutzers verfügbar gemacht. Die Option »-c« bewirkt, dass »my_floppy« erzeugt wird, falls es noch nicht existiert.
Der Übersetzer startet allerdings erst, wenn auf das Verzeichnis zugegriffen wird. Auch bleibt er beim Neustart des Systems erhalten. Die »my_floppy«-Node speichert also, welcher Übersetzer (hier »/hurd/ext2fs«) mit welchen Argumenten (hier »floppy.img«) dort zu finden ist. Es ist möglich, einen Übersetzer auf einer Node explizit direkt zu starten, ohne dass das Dateisystem, auf dem sie liegt, modifiziert wird. Dazu übergibt man dem »settrans«-Kommando die Option »-a«. Ein solch aktiver Übersetzer ist aber nicht dauerhaft.
Gelegentlich könnte der Wunsch aufkommen, die Optionen eines Übersetzers anzupassen, und zwar nachdem er gestartet ist, um etwa ein Dateisystem in den Read-only-Modus zu schalten. Unter Linux verwendet man für diesen Zweck ein Kommando wie:
mount -o remount,ro /home
Hurd kennt hingegen das Kommando »fsysopts«, mit dem sich die Optionen sowohl ansehen als auch setzen lassen, wie folgendes Beispiel zeigt:
hurd:~# fsysopts /home /hurd/ext2fs --writable hurd:~# fsysopts /home --readonly hurd:~# fsysopts /home /hurd/ext2fs --readonly
Das »fsysopts«-Programm dient ganz allgemein dem Anpassen von Übersetzer-Optionen. Wie einzelne Übersetzer die Optionen interpretieren, ist aber allein deren Sache.
Bequemer FTP-Zugriff
In der Unix-Welt sind mehrere Ansätze dafür bekannt, den Zugriff auf die unterschiedlichen Datenquellen als Dateisystem zu vereinheitlichen. Ein Beispiel ist das VFS von Gnome, das unter anderem den Zugriff auf FTP-Server regelt. Eine Eigenschaft haben aber alle Ansätze gemeinsam: Sie funktionieren nur für jene Anwendungen, die die korrespondierende Bibliothek nutzen.
In Hurd wird die entsprechende Funktionalität transparent allen Anwendungen angeboten, ohne dass Anpassungen notwendig wären. Den »ftpfs«-Übersetzer nutzt man dann so:
settrans -c debian /hurd/ftpfs ftp.de.debian.org head -n 1 debian/welcome.msg
Aber es geht noch einfacher! Durch die Kombination von »ftpfs« mit dem »hostmux«-Übersetzer entfällt die Notwendigkeit, pro FTP-Server einen Übersetzer zu befestigen. Stattdessen startet man lediglich einen »hostmux«-Übersetzer. Als Argument wird ihm jener Übersetzer übergeben, den er dann für jedes Unterverzeichnis starten soll:
settrans -c /ftp /hurd/hostmux /hurd/ftpfs head -n 1 /ftp/ftp.de.debian.org/welcome.msg
Hierbei ist »hostmux« insbesondere dafür verantwortlich, dass im Falle eines Zugriffs über die IP-Adresse des Servers kein weiterer Übersetzer gestartet werden muss, das heißt, der gleiche Host wird auch unter verschiedenen Namen durch die gleiche Node repräsentiert.
Abbildung 3: Eine typische Prozessliste bei Hurd. Neben diversen Servern ist hier auch Mach selbst zu finden.
Tummelplatz für viele Übersetzer
Aber Übersetzer sind keinesfalls nur für Dateisystem-artige Strukturen da. Es gibt auch Übersetzer, die nur für eine einzelne Node zuständig sind. Diese findet man oftmals im Verzeichnis »/dev«. Ein typisches Beispiel ist der »null«-Übersetzer, der eine Node mit dem Erscheinungsbild von »/dev/null« bereitstellt. In die gleiche Kerbe hauen zum Beispiel der »mouse« und der »random«-Übersetzer und einige weitere.
Etwas ungewöhnlicher ist da schon Run: Auch er stellt nur eine einzelne Node mit einer I/O-Schnittstelle zur Verfügung, doch man übergibt ihm als Argument ein Unix-Kommando:
settrans -c glückskekse /hurd/run /usr/games/fortune -s
Jedes Mal, wenn nun »glückskekse« geöffnet wird, führt »run« das angegebene Kommando aus. Wer daraufhin aus der Datei liest, erhält die Ausgabe des Kommandos, hier also einen Fortune-Cookie. Damit schlägt der »run«-Übersetzer eine Brücke zwischen der Hurd- und der Unix-Welt.
Ähnlich ungewöhnlich ist der Firmlink-Übersetzer, eine Mischung aus symbolischem und hartem Link. Wie ein symbolischer Link orientiert er sich am Dateinamen und funktioniert damit über die Grenzen von Dateisystemen hinweg. Der angestrebten Ambivalenz folgend verhält sich ein Firmlink jedoch auch wie ein Hardlink: Innerhalb eines Chroots verweist er auf dasselbe File wie ohne den Chroot, da er beispielsweise ungeachtet eines Chroots auf dieselbe Datei verweist. Ein Firmlink auf ein Verzeichnis verhält sich bei »cd ..« ebenso wie ein harter Link auf ein Verzeichnis.
Hier zeigt sich die Flexibilität der Übersetzer in Hurd, die für andere Unix-artige Systeme unmögliche Verhaltensweisen möglich macht. Hurd-Übersetzer sind auch keineswegs auf die altbekannten Arten von Schnittstellen festgelegt, auch neue Interfaces sind damit beliebig implementierbar. Beispiele hierfür finden sich im Verzeichnis »/servers«, etwa der Password-Server »/servers/password«, der für die initiale Benutzer-Authentifizierung zuständig ist.
Weitere Schnittstellen sind denk- und ohne besondere Privilegien im System umsetzbar. So spräche nichts dagegen, den Widget-Baum von Gtk+-Anwendungen in Form eines Verzeichnisbaums darzustellen und durch passende Schnittstellen für die verschiedenen Widget-Typen alle Gtk+-Anwendungen skriptbar zu machen – zugegeben eine etwas ausgefallene Idee.

Abbildung 4: Die Login-Shell ist ein Prozess ohne User-ID. Wer lieber einen normalen Login-Prompt verwenden möchte, darf natürlich auch das tun.
Hurd – mehr als nur Daemons
Neben Kernel und Servern besteht Hurd aus diversen Bibliotheken, die das Entwickeln von Servern vereinfachen. Für gängige Dateisysteme wie Ext2fs und UFS steht beispielsweise die Bibliothek Libdiskfs bereit, die einen Großteil der Arbeit übernimmt.
Zwar ist die Zeilenanzahl im Quellcode zur Aufwandsabschätzung nicht ideal, vermittelt aber einen guten Eindruck: Kommentare, leere Zeilen und solche mit nur einer geschweiften Klammer nicht mitgezählt, kommt die Libdiskfs-Bibliothek auf knapp 5000 und der Ext2fs-Server auf 3000 Zeilen. Natürlich verwendet ein Dateisystem-Server noch andere Bibliotheken. Libstore etwa stellt die verschiedenen Backend-Stores für Software-RAID-0 sowie komprimierte und künftig auch verschlüsselte Dateisysteme zur Verfügung.
Hurd erscheint mit einer Reihe spezifischer Benutzerprogramme, »settrans« und »fsysopts« wurden schon vorgestellt. Ein weiteres ist »rpctrace«, das mit »strace« unter Linux vergleichbar ist, im Gegensatz zu ihm aber Kernel-seitig keine spezielle Unterstützung erfordert. Es beobachtet eigenständig, welche Remote Procedure Calls (RPCs) ein Prozess verwendet, also welche Nachrichten er an andere Prozesse sendet und welche Antworten er darauf erhält.
»showtrans« ist ein weiteres Programm, das mit den Übersetzern arbeitet: Es zeigt nämlich an, welche passiven Übersetzer auf bestimmten Nodes vorhanden sind. Aber auch für eine andere Hurd-spezifische Funktionalität steht eine Reihe von Programmen zur Verfügung: Ein Prozess kann beliebig viele (aber auch gar keine) User-IDs zur gleichen Zeit haben. Für das Anzeigen, Hinzufügen und Entfernen dieser IDs stehen die Programme »ids«, »addauth« sowie »rmauth« bereit.
Erreichtes und Erstrebenswertes
Der Kasten “Wie alles begann” fasst knapp den bisherigen Verlauf des Projekts zusammen. Da die Entwickler auf die Einhaltung von Standards viel Wert legen, kann Hurd inzwischen eine bemerkenswerte Anzahl an Applikationen vorweisen, auch freie, die unportablen Code enthalten, werden laufend angepasst. Im Zuge der normalen Hurd-Entwicklung wird zwar ständig seine Funktionalität erweitert, doch gibt es hier noch einiges zu tun.
Ein großes Defizit hat Hurd hingegen bei der Geschwindigkeit; verglichen mit Linux ist das System ziemlich schwerfällig. Doch haben die Verbesserungen in diesem Punkt gegenwärtig keine hohe Priorität. Es wird vor allem daran gearbeitet, die Robustheit der Software zu erhöhen. Für ihre Benutzbarkeit ist dies von größerer Bedeutung. Als Beispiele seien zwei bedeutende Aspekte beschrieben, die in der Entwicklung gegenwärtig eine große Rolle spielen.
Kommunikation und Konsolen-Client mit Unicode
Während innerhalb des Mach-Kernels 1.3 eine eigene Konsole implementiert ist, steht bei der unter dem Namen OSKit-Mach bekannten Entwicklungsversion keine zur Verfügung. Das macht es erforderlich, eine Konsole außerhalb des Kernels zu entwickeln. Die neue Konsole läuft teilweise schon.
Zur Verwendung kommt hierbei eine clevere Client-Server-Architektur, wie sie in Abbildung 5 zu sehen ist: Ein Konsolen-Server ist für die Verwaltung der virtuellen Konsolen verantwortlich. Er interpretiert die Kontrollsequenzen, die die Verwendung von Farben, die Positionierung des Cursors und Ähnliches ermöglichen. Die Clients füttern ihn mit einem Zeichenstrom und lesen eine Zeichenmatrix aus – inklusive Benachrichtigung bei Änderungen.
Selbstverständlich können beliebig viele Clients einen Konsolen-Server nutzen. Beispiel: Ein User am Hurd-Rechner A hat dort virtuelle Terminals in Betrieb. Wenn er zum Hurd-Rechner B geht und sich auf Rechner A per Telnet oder SSH einloggt, kann er die virtuellen Terminals von dort weiter verwenden.
Dass die Kommunikation zwischen Konsolen-Client und -Server mit Unicode abläuft, liegt nahe. Interessant ist aber, dass selbst der Konsolen-Client, der den VGA-Textmodus als Backend verwendet, in der Lage ist, Unicode darzustellen. Aufgrund der Beschränkungen des Textmodus kann dabei nur eine begrenzte Anzahl an verschiedenen Zeichen zugleich angezeigt werden, was in der Praxis aber unerheblich ist.

Abbildung 5: Die Client-Server-Architektur der Konsole. Der Client stellt ein Terminal am Bildschirm dar und sendet Benutzereingaben an den Server.
L4 statt Mach
Zwar ist Mach ein Kernel mit sauberem Design und innovativen Konzepten, doch er enthält eine reichlich große Menge an Abstraktionen, die Hurd nicht benötigt und die das System nur langsam machen. Auch erledigt Mach zu viele Dinge selbst, was Hurds angestrebter Dezentralität in einzelnen Bereichen widerspricht.
Langfristig plant die Hurd-Community darum eine sehr einschneidende Änderung: die Umstellung vom Mach- auf den L4-Mikrokernel (siehe[4] und[5]). L4 ist ein zumindest im Vergleich zu Mach relativ neuer Mikrokernel, der eine andere Strategie verfolgt: Er bietet nur Mechanismen an, während diverse Server die Regeln bestimmen und umsetzen. Das Konzept führt dazu, dass die von L4 angebotenen primitiven Operationen sehr schnell sind und man auf ihnen exakt die benötigte Funktionalität aufbauen kann.
An dieser Infrastruktur wird derzeit gearbeitet. Das soll aber keinesfalls bedeuten, dass es noch nicht interessant ist, sich mit Mach näher zu beschäftigen. Wie hier gezeigt, ist GNU/Hurd bereits mit dem aktuellen Mach als Basis ein System mit interessanten Konzepten.
GNU/Hurd ausprobieren
Nach dieser Rundreise durch GNU/Hurd ein paar praktische Hinweise: Es gibt zwar noch keine offizielle Release von Debian GNU/Hurd, doch in unregelmäßigen Abständen erscheinen neue CD-Images, von denen sich das System einigermaßen komfortabel installieren lässt. Für die Installation wird derzeit GNU/Linux eingesetzt. Entsprechend bestehen die Versionsnummern für die CDs aus zwei Komponenten: Ein Buchstabe (gegenwärtig “J”) kennzeichnet die Version der Linux-Komponente, während die angehängte Zahl die Änderungen an den Paketen widerspiegelt.
Empfehlenswert ist es, sich vor jeder Hurd-Installation auf den Webseiten von Hurd[3] ausgiebig zu informieren, denn Schwierigkeiten sollte man einkalkulieren. Die Lösungen für einige häufig auftretende Probleme erläutert der Kasten “Typische Probleme”.
Upgrades sind normalerweise mittels APT bequem möglich. Eine Ausnahme machen die J1-CDs, die Unterstützung für große Dateien ermöglichen. Die damit verbundenen inkompatiblen Änderungen erzwingen eine besondere Upgrade-Prozedur[2]. (jk)
|
Wie alles begann |
|
Anfang der 80er Jahre begann Richard M. Stallman (RMS) mit der Entwicklung des GNU-Betriebssystems, das anderen Betriebssystemen nicht nur technisch, sondern vor allem auch “sozial und ethisch” überlegen sein sollte. Er meinte damit, dass Benutzer nicht durch tyrannische Lizenzbestimmungen davon abgehalten werden sollen, miteinander zu kooperieren und jene Freiheit zu nutzen, die Software bieten kann. Stallman war sich bewusst, dass die Entwicklung eines vollständigen Systems lange dauern würde und dass nicht vorhersagbar ist, welche Hardware in Jahren verbreitet sein wird. Darum verschob er die Entwicklung der hardwarenahen Komponente, des Kernels, an den Schluss. Da das Debuggen von Code, der im Kernel-Modus läuft, kompliziert ist, entschied man sich für das moderne Design einer Mikrokernel-Architektur. Es dauerte allerdings mehrere Jahre, bis der Mach-Mikrokernel [4], eine Entwicklung der University of Rochester aus den 70ern, die alsbald an die Carnegie Mellon University überging, unter einer Lizenz bereitgestellt wurde, die für die GNU-Gemeinde akzeptabel war. Daher begann die Entwicklung von Hurd erst 1991. Ebenfalls ziemlich lange dauerte die Entwicklung von Schnittstellen, die einerseits mächtiger und sauberer als ihre Äquivalente aus der Unix-Welt sein sollten und andererseits dennoch der Unix-Semantik folgen. Da Linux, eine Kombination aus dem Rest des GNU-Systems und dem monolithischen Linux-Kernel, sehr beliebt und zuverlässig ist, hatte Hurd im GNU-Projekt kaum Priorität – das damalige Fehlen eines freien Desktops war wichtiger. Zwischenzeitlich kam die Entwicklung von Hurd sogar ganz zum Erliegen. Politik ist bei GNU wichtig Um den Erfolg von freier Software langfristig zu sichern, wird Hurd nach Ansicht mancher GNU-Akteure wieder interessanter. Sie meinen, dass einige der Linux-Hauptentwickler den Status des Linux-Kernels als freie Software durch ihre unpolitischen Ansichten und Handlungen gefährden würden. |
|
Typische Probleme |
|
Neal Walfields Installationsanleitung[1] beschreibt die Installation von Hand. Wenn man von den Debian-GNU/Hurd-CDs installiert – was sinnvoll ist -, werden einige der dort beschriebenen Punkte bereits automatisch ausgeführt. Dennoch ist die Anleitung außerordentlich hilfreich. Da zudem die Installation nicht übermäßig schwierig ist, seien hier nur häufig auftretende Probleme mit passenden Lösungen beschrieben. Problem: Bei der Installation wird kein Bootmanager eingerichtet Lösung: Der Bootmanager muss derzeit manuell eingerichtet werden. Prinzipiell eignet dazu jeder Bootloader, der den Multiboot-Standard implementiert. Das ist derzeit allerdings nur GNU Grub. Der bekannte Lilo dagegen funktioniert nicht. Disketten-Images, auf denen sich Grub befindet, liegen auf den Installations-CDs bereit. Problem: Der Mach-Kernel bootet nicht Lösung: Es gibt für dieses Verhalten zwei typische Ursachen. Erstens: Mach hat Probleme mit großen Arbeitsspeichern. Bei Rechnern mit mehr als 700 MByte muss das »uppermem«-Kommando in Grub die für Mach sichtbare Menge einschränken. Zweitens: Mach unterstützt kein IRQ-Sharing, das also deaktiviert werden sollte. Problem: Der »ext2fs.static«-Server stürzt beim Booten ab Lösung: Hurd unterstützt derzeit nur Dateisysteme bis etwa 1,9 GByte, da »libdiskfs« das Dateisystem in den virtuellen Adressraum des Übersetzers einblendet (mappt). Für Ext 2 und UFS gilt diese Einschränkung, über NFS sind jedoch größere Dateisysteme nutzbar. Problem: »native-install« schlägt fehl Lösung: Beim Erzeugen des Root-Dateisystems muss als Besitzer »hurd« angegeben werden (»mkfs.ext2 -o hurd«), da sonst das Verwenden von Übersetzern nicht möglich ist. Problem: »native-install« bleibt hängen Lösung: Der »ext2fs«-Server hat Probleme mit dem Schreibzugriff bei manchen Blockgrößen. Die Option »-b 4096« beim Erzeugen des Dateisystems soll dieses Problem lösen. Problem: Das Installieren von Paketen schlägt wegen nicht erfüllbarer Abhängigkeiten fehl Lösung: Einige wichtige Pakete befinden sich nicht auf den Debian-Servern, sondern auf [alpha.gnu.org] und dessen Mirrors. Es ist daher in der Datei »/etc/apt/sources.list« folgende Zeile erforderlich: deb ftp://alpha.gnu.org/gnu/hurd/debian unstable main Problem: X11 funktioniert nur als Root Lösung: GNU/Hurd kennt keinen Library-Mechanismus mit »/etc/ld.so.conf« oder Ähnlichem. Der Loader sucht nach Bibliotheken nur in »/lib« und den Pfaden, die in »LD_LIBRARY_PATH« stehen. Da SUID- und SGID-Binaries wie Xterm diese Umgebungsvariable ignorieren, geht der XFree-Aufruf vielfach ins Leere. Es bleibt hier nur, die X11-Bibliotheken aus »/X11R6/lib« entweder nach »/lib« zu kopieren oder symbolische Links anzulegen. |
|
Infos |
|
[1] Neal Walfields’s Installationsanleitung: [http://web.walfield.org/papers/hurd-installation-guide/english/hurd-install-guide.html] [2] Upgrade-Anleitung: [http://www. debian.org/ports/hurd/extra-files/hurd-upgrade.txt] [3] Hurd-Homepage: [http://www.gnu.org/software/hurd/] [4] Mach-Kernel: [http://www-2.cs.cmu.edu/afs/cs.cmu.edu/project/mach/public/www/mach.html] [5] L4-Mikrokernel: [http://www.l4ka.org] |
|
Der Autor |
|
Wolfgang Jährling ist einer der wenigen Hacker, die gerne an einer Dokumentation schreiben. Er versucht daher in der Hauptsache, Hurd in dieser Hinsicht zu verbessern, steuert aber auch gelegentlich Code bei. |





