
Mit wachsender Verbreitung von Cluster-Systemen steigt auch der Anspruch an die Werkzeuge für ihre Verwaltung. Projekte wie das Scaleable Cluster Environment (SCE) helfen dabei, Aufbau und Management der Rechner-Verbünde zu vereinfachen.
Anfang der 90er Jahre suchten Wissenschaftler an den Hochschulen und Forschungseinrichtungen nach neuen Möglichkeiten, ihren großen Rechenbedarf zu decken. Damals erlebte die verteilte Datenverarbeitung ihre Blüte. Viele Anwender hatten eine leistungsfähige Workstation am Arbeitsplatz. Die Rechner waren über ein lokales Netz miteinander verknüpft und bildeten so eine leistungsfähige Ressource.
Da Wissenschaftler ihre Workstation aber nicht 24 Stunden nutzen, sondern über das gesamte Jahr verteilt nur etwa zu zehn Prozent, lag eine große Rechenkapazität brach. Als die Anwender das erkannten, schlug die Stunde der Cluster of Workstations (COW) – inzwischen Network of Workstations (NOW).
Entwickler an den Instituten schufen die notwendigen Software-Werkzeuge, um den Rechnerpool als ein einziges Parallelrechner-System oder als eine große Zahl einzelner Rechner zu sehen. Dazu musste der Anwender natürlich von der Vorstellung einer eigenen, privaten Workstation Abschied nehmen und sie allen Kollegen zugänglich machen – ein schwieriges psychologisches Problem.
PVM und PVI, die ersten Postboten für Cluster
Schon 1991 lieferten Jack Dongarra und Vaidy Sundaram mit PVM (Parallel Virtual Machine) die erste Implementierung eines Message-Passing-Systems. Per Unterprogrammaufruf konnte der Benutzer Daten an einen anderen oder alle Rechner im lokalen Netz schicken oder von dort abrufen. Das Softwarepaket erlaubte es, durch ein Netzwerk verbundene heterogene Unix- und Windows-/NT-Workstations als einen großen, lose gekoppelten Parallelrechner – eine virtuelle Maschine – zu nutzen.
Etwas später entwickelten die Anwender MPI (Message Passing Interface), einen Standard zum Verteilen von Nachrichten, inzwischen liegt er in der Version 2 vor. Zusätzlich zu den MPI-Bibliotheken der Rechnerhersteller existieren auch offene, frei verfügbare Versionen wie zum Beispiel MPICH.[1]
Daneben entwickelten Unternehmen wie Platform Computing aus Kanada mit LSF (Load Sharing Facility)[2] und das damalige Softwarehaus Genias aus Neutraubling mit Codine schon 1993 Programmsysteme für die Verteilung der Lasten auf die einzelnen oder alle Workstations im Cluster. Inzwischen ist Codine unter dem Namen Grid Engine bei Sun Microsystems gelandet (Grid Engine wird im Schwerpunkt-Artikel “Bitte hinten anstellen” näher behandelt).
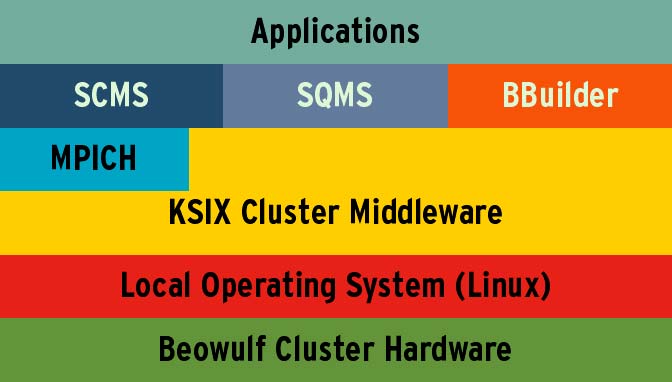
Abbildung 1: Die Grundstruktur von SCE ist einfach und lässt sich gut erweitern.
Das Rudel der Beo-Wölfe
Die NOW-Cluster bestanden aus vorhandenen, über das LAN vernetzten Workstations. Mit den Beowulf-Clustern[4] entstand eine neue Klasse von Systemen, bei denen die Workstations intern vernetzt waren. Dadurch beschleunigte sich die interne Kommunikation. Im Sommer 1994 bauten Thomas Sterling und Don Becker aus Massenkomponenten den ersten Beowulf-Cluster – COTS (Commodity off the Shelf). Sie vernetzten 16 Intel 80486 (100 MHz, 16 MByte RAM) mit einem dualen 10-MBit/s- Ethernet zu einem Rechner.
Beowulf-Cluster sind Cluster of Workstations und bestehen aus Knoten, die nur zum Cluster gehören. Die Knoten können einen oder mehrere Prozessoren enthalten, die sich einen gemeinsamen Speicher teilen. Die Knoten sind über ein internes Netzwerk verbunden und können daher schneller kommunizieren. Als Software werden offene und Hardware-unabhängige Bausteine verwendet, Linux, GNU-Compiler, Werkzeuge und Bibliotheken wie PVM und MPI. Auf diesem Prinzip beruhen heute viele Cluster mit unterschiedlichen Prozessorarchitekturen. Inzwischen entwickelt und unterstützt das Unternehmen Scyld Computing Corporation Hochleistungslösungen, die auf offenen Systemen wie dem Beowulf-Cluster beruhen.
Bald zeigte sich eine Schwäche: Die Kommunikationsleistung mit Ethernet ist für Programme mit regem Datenaustausch zwischen den Prozessoren zu schwach. Schnelle interne Netze, System Area Networks (SAN), sind wichtig. Sie kennen die Netztopologie und kommen mit geringerem Protokollaufwand aus. Hier bieten Unternehmen standardisierte oder eigene Lösungen an.
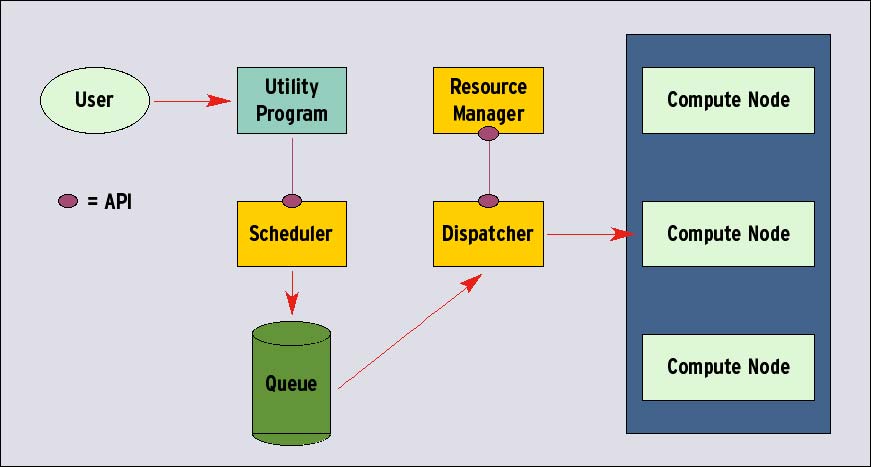
Abbildung 2: Die Prozesssteuerung mit KSIX erspart redundante Daemons auf den Knoten des Clusters.
Schnelle Kommunikation
Aus Kostengründen wählen Anwender oft langsamere Verbindungen (Interconnects) mittels Ethernet. Das Motto lautet dann: Lieber mehr Prozessoren. Bei einigen Anwendungszwecken wird jedoch Interconnect zum Flaschenhals, schnellere Prozessoren und mehr Leistung bringen dann keine Performance-Steigerungen mehr. Die Industrie bietet hierfür schnelle professionelle, aber auch leider recht teure Lösungen an.
Hierzu gehört das wohl am stärksten verbreitete Myrinet von Myricom. Interface-Karten und Treiber sind für PCs, Alpha- und Sun-Workstations verfügbar. Die nominale Bandbreite beträgt 160 MBit/s. Dolphin aus Norwegen unterstützt den IEEE-Standard Scaleable Coherent Interface (SCI) und verbindet bis zu 65536 Knoten in beliebiger Topologie mit einer Bandbreite von 170 MBit/s. Die Firma Scali nutzt die Dolphin-Karten und offeriert fertige Systeme mit SMP-Knoten, Pentium und Sparc.
Die Virtual Interface Architecture (VIA) unterstützen beispielsweise Intel, Compaq und Microsoft. Ein Einsatzbeispiel ist Server Net von Compaq auf den Tandem-Clustern. Giganet/cLAN basiert auf VIA und ist in Hardware implementiert, die Bandbreite beträgt maximal 106 MBit/s. Die britische Firma Quadrics bietet mit Qs Net eine Fat-Tree-Topologie mit einer maximalen Bandbreite von 340 MBit/s in jede Richtung.
Zu den unterstützten Hardwareplattformen gehören Compaqs Alpha SC, Linux-Cluster für Alpha und Intel sowie Sparc-Systeme. Alle Anbieter stellen auch eigene, schnelle Kommunikationsbibliotheken bereit. Das deutsche Unternehmen Partec, München, entwickelte mit Para Station[5] eine schnelle Kommunikations- und Managementsoftware für Cluster, die sich wie ein einzelner Rechner darstellen – One System Image.
Open-Source-Werkzeuge für Cluster
Beowulf-Cluster haben sich zu einer interessanten Alternative zu den kommerziell verfügbaren Rechnern entwickelt. Sie besitzen ein hervorragendes Preis-Leistungs-Verhältnis, skalieren auf Hunderte von Knoten und schließlich ist für sie eine breite Softwarepalette von Open-Source-Software verfügbar. Damit eignen sie sich für Forschungseinrichtungen und Hochschulen optimal, die eigenes Personal für Anpassungen einsetzen können.
Andererseits zeigte die Praxis aber auch viele Probleme auf. Beowulf-Cluster sind nicht einfach aufzubauen und zu betreiben, insbesondere wenn die Cluster sehr groß sind. Cluster sind auch aufgrund der oft primitiven Betriebsumgebung schwierig zu nutzen. Das Resultat fehlender Werkzeuge: Cluster sind komplex zu nutzen, zu warten und zu konfigurieren, für Anwender ist der effiziente Zugriff schwer zu erlernen. So sucht jeder Betreiber nach eigenen Wegen, die Schwierigkeiten zu beheben.
Diese gesammelten Erfahrungen führten im Projekt SCE zu leicht nutzbaren Software-Werkzeugen. Das Ziel war es, die zwingend notwendigen Funktionalitäten zu entwickeln und auch Nutzung und Implementierung zu erleichtern. Mit den SCE-Software-Tools kann der Benutzer schnell mit seiner Arbeit beginnen, obwohl das System noch nicht unbedingt optimal konfiguriert ist. Der Betreiber kann es später sukzessive verbessern und optimal anpassen.
Das SCE-Projekt wurde von der Parallel Research Group an der Kasetsart-Universität in Bangkok entwickelt und ist jetzt als Open Source bei Sourceforge gehostet. Mit diesen kostenfreien und interoperablen Software-Werkzeugen können Anwender Beowulf-Cluster leicht aufbauen und effizient nutzen. SCE-Tools umfassen alle notwendigen Komponenten auch zum Betrieb des Clusters inklusive Monitoring, Batch-Scheduling und Profiling. Sponsoren des Projekts sind Compaq und AMD.
Portabler Werkzeugkasten
SCE enthält integrierte Software-Werkzeuge und ist ein System mit vielen definierten Schnittstellen. Das System ist portabel, da keine Kernel-Modifikationen vorgenommen wurden. SCE bietet eine einfache, aber erweiterbare Architektur. Es verfügt außerdem noch über APIs (Application Programing Interface) und Dienste für die Entwicklung weiterer Werkzeuge.
Die nächste Generation des SCE-Pakets wird sogar Komponenten enthalten, die das Hinzufügen, Löschen und Modifizieren der Knoten und der Konfiguration ohne großen Aufwand möglich machen. Daneben wird es Kommandos auf Kommandozeile, aber auch grafische Benutzerschnittstellen unterstützen. Zusätzlich sind neben den derzeit plattenlosen auch Knoten mit eigenen lokalen Platten vorgesehen.
Der SCE-Ansatz integriert alle Software-Werkzeuge dieses Projekts. Dadurch reduziert sich nicht nur der Zeitaufwand für den Aufbau eines Clusters, sondern auch die Systemgröße. Der Verbrauch von Ressourcen verringert sich und das System wird schneller. Durch die Interaktion der Komponenten kann beispielsweise der Batch-Scheduler die SCE-Middleware für Prozesskontrolle und das Darstellen der Last nutzen, um direkt auf Ressourcen zuzugreifen.
Die aus einzelnen Knoten bestehenden Cluster werden derzeit oft selbst zu Knoten in einem verteiltem Netz, dem Grid. Vorerst noch auf Forschungszwecke beschränkt, deutet sich eine Kommerzialisierung aber schon an (siehe Artikel “Graue Eminenzen”).
SCE und Grid-Computing
Als Standard fürs Grid-Computing, also die weltweite Zusammenarbeit von Rechen-Ressourcen, sind heute die Protokolle und Tools des Globus-Projekts anzusehen. In Grids arbeitet unterschiedliche Hardware – von PCs bis zu Supercomputern und Systemen zur Messdatenerfassung – an einer Aufgabe.
Am Forschungsprojekt Globus nehmen amerikanische Elite-Universitäten und Forschungseinrichtungen teil. Globus untersucht die Basisprobleme wie Ressourcen-Management, Sicherheit, Informationsdienste sowie Datenmanagement und entwickelt Software-Werkzeuge. Das Globus Toolkit löst Probleme in den oben genannten Bereichen. Dazu kommen Bibliotheken beispielsweise für die Kommunikation, Fehlererkennung und Portabilität. Das Toolkit ist Open- Source-Software.
In SCE ist Globus-Unterstützung schon eingebaut. KSIX startet Globus-Jobs mit einem eigenen Skript. Das Schichtenmodell besteht aus folgenden Elementen: Basis ist die Cluster-Hardware, darauf sitzt das lokale Betriebssystem Linux, die nächste Schicht nimmt KSIX als Cluster-Middleware ein, in die auch MPICH als Kommunikationsbibliothek integriert ist. Die Komponenten SCMS und SQMS sowie Beowulf Builder ermöglichen der Applikation den Zugriff auf die Ressourcen.
Die Projektpartner aus der Industrie haben dafür gesorgt, dass SCE für unterschiedliche Prozessorarchitekturen bereitsteht. AMD unterstützte als Sponsor Athlon-Cluster, die mit Myrinet vernetzt sind. Compaq stellte einen Alpha-Cluster für die Portierung auf 64-Bit-Architekturen zur Verfügung. Terra Soft lieferte PowerPC-Systeme für die Portierung auf diese Architektur.

Abbildung 3: Der Support fürs Grid-Computing ist schon eingebaut. Die SCE-Middleware KSIX verwaltet auch Jobs aus dem Grid-Framework Globus.
Die SCE-Version 1.5 kommt spät, aber sie kommt
Detaillierte Informationen über den derzeitigen Entwicklungsstand finden sich auf der SCE-Website. Die Version 1.0 unterstützt Red Hat 7.1 und 6.2. Die SCE-Version 1.2, im Oktober freigegeben, beseitigt einige Fehler und bietet neue Möglichkeiten. Schon für den November letzten Jahres war Version 1.5 angekündigt. Die Fertigstellung hat sich aber verzögert, beim Erscheinen dieses Hefts sollte sie verfügbar sein.
Zentrale Neuerung in dieser Version ist eine einfache Datenbank namens CIB (Cluster Information Base). Sie basiert auf XML und ist von allen Knoten nutzbar. Die Cluster-Betreiber können dort die dynamischen Informationen über den aktuellen Status des Clusters ablegen, aber auch statische Daten zur Systemkonfiguration. (uwo)
SCE-Komponenten |
|
Beowulf Builder: Ein Werkzeug zum Aufbau des Clusters und zur Wartung der Cluster-Konfiguration. Automatisch erstellt der Builder alle notwendigen Konfigurationen, mit denen die Knoten remote von einem Masterknoten gebootet werden können. Ist die Konfiguration abgeschlossen, steuert und überwacht die Middleware-Komponente KSIX den normalen Betrieb des Clusters. Sie läuft im Hintergrund und stellt den darüber liegenden Tool-Schichten Dienste zur Verfügung. Auf KSIX setzen SCMS (das Cluster Management System) und SQMS (das Batch Scheduling System) auf. SCE unterstützt auch MPICH, eine weit verbreitete MPI-Implementierung (Message Passing Interface). Somit kann der Anwender unverzüglich seine parallelen Jobs starten. KSIX (Cluster Middleware): Die KSI-Middleware stellt viele Dienste bereit. Dazu gehören beispielsweise der globale Prozess, die Verwaltung der Clusterzugehörigkeit, verteilte Ereignis- und Namensdienste. Zusätzlich besitzt KSIX 30 APIs. Es muss zuerst gebootet werden, dann können die anderen Werkzeuge folgen. Es beschleunigt parallele Unix-Kommandos, erzeugt die Prozesse sehr schnell und bietet Prozessverwaltung für den Batch Scheduler SQMS. Daneben ermöglicht es das Debuggen von MPI-Programmen. SCMS (Scaleable Cluster Management System): SCMS ist ein interaktives und erweiterbares Cluster-Management-Werkzeug. Mit Hilfe leistungsfähiger grafischer Schnittstellen führt es die administrativen Aufgaben durch. Eine Vielzahl von Kommandos, ein Monitoring-System in Echtzeit und eine Web-Schnittstelle kommen noch hinzu. CMA: Der CMA (Control and Monitoring Agent) läuft auf allen Knoten und schickt periodisch die Daten zum SMA (System Management Agent). Dazu kommt noch der RMA (Resource Management Agent). Sie werden sämtlich über Red Hat Linux gestartet. Mit Hilfe von Selector kann der Administrator bis zu 10000 Knoten betrachten und die Kommunikationsverzögerung messen. Bis zu 40 Knoten sind auf einen Blick auf dem Bildschirm zu sehen. Außerdem kann man sich die CPU-Auslastung und die aktuellen Benutzer des Systems auflisten lassen. SQMS (Batch Scheduling): Dieses System zur Verwaltung der Warteschlangen vereinfacht das Task-Management im Beowulf-Cluster. Der Anwender kann Jobs abschicken, ihren aktuellen Status prüfen und Jobs in den Rechenknoten löschen. Es unterstützt sequenzielle und parallele MPI- und PVM-Tasks sowie Web-Portale, erlaubt eine eingeschränkte Lastverteilung, verwendet eine variable Scheduling- und Resource-Allocation-Strategie und nutzt Globus-Komponenten. KCAP (Web-basiertes Cluster Management System): Auch dieses Werkzeug hilft dabei, den Cluster interaktiv zu überwachen und zu verwalten. Es ist ein Zusatz zu SCMS und präsentiert nützliche Informationen vom einzelnen oder allen Knoten im Cluster. Hierzu gehören Kernel Messages, die Liste der aktiven Kerne, die Netzwerkkonfiguration, Routing-Informationen und solche über freien Plattenplatz und Hauptspeicher sowie Benutzer im Knoten. Auch detaillierte Angaben über den Benutzer sind möglich: Benutzer- und System-CPU, die Temperatur der CPU oder auch die Computer-Last in definierbaren Minutenabständen. AMATA (Automatic Fault Detection and Recover System): AMATA entdeckt Fehler im Cluster, besonders bei größeren Clustern eine wichtige Aufgabe. Es sendet die Meldungen an den Administrator und erlaubt es ihm, eine einfache Fehlerentdeckungs- und Wiederaufsetzungs-Logik hinzuzufügen. |
Infos |
|
[1] MPICH: [www-unix.mcs.anl.gov/mpi/mpich/] [2] LSF-Erfinder Platform Computing: [http://www.platform.com/] [3] Grid Engine, vormals Gridware und Codine: [http://www.sun.com/software/gridware/] [4] Beowulf-Projekt: [www.beowulf.org/] [5] Partec: [www.par-tec.com] [6] Das SCE-Projekt: [http://www.opensce.org] [7] Globus-Grid-Projekt: [http://www.globus.org] |
Der Autor |
|
Uwe Harms ist Consultant im Bereich Supercomputing, Buchautor und freier Journalist. |





