Buffer Overflows, Tricks mit User-IDs, Pfaden und Umgebungsvariablen: An Sicherheitslücken in Software sind immer wieder die gleichen Fehler der Programmierer schuld. Wir sehen uns einige Fallstricke an und erklären, warum sie gefährlich sind.
Sicherheit ist langweilig und hält nur auf, diesen Eindruck haben nicht nur viele Projektverantwortliche, sondern auch zahlreiche Entwickler. Der schöpferische Prozess wird ja behindert, wenn man sich als Softwaredesigner auch noch um solche Randprobleme kümmern muss. Nur – irgendwann kommen die Probleme, und dann muss ein weit fortgeschrittenes Produkt nachträglich sicher gemacht werden.
Das wird dann wirklich langwierig und hat mit Kreativität nur sehr eingeschränkt zu tun. Sich aber von Anfang an Gedanken zur Sicherheit zu machen, kann hingegen wirklich sehr spannend sein. Gerade wenn es um potenzielle Lücken geht, ist nämlich Phantasie gefragt: Wo überall könnte denn ein ebenso kreativer Angreifer ansetzen?
Dabei geht es weniger um Richtlinien und Konventionen, wichtig sind vielmehr etwas Grundwissen zu typischen Sicherheitslücken und außerdem viel Phantasie, um die Lücken zu vermeiden, die im eigenen Projekt auftreten könnten.
Wir picken uns deshalb einige sehr typische Beispiele heraus, aber nicht einfach als Anleitung zum richtigen Programmieren. Ein Blick hinter die Kulissen ist viel interessanter: Warum ist es so gefährlich, wenn ein Buffer Overflow auftritt? Das Programm stürzt halt ab, das kennt man ja. Was ist daran schlimm? Oder: Externe Programme kann man sehr schön mit system() starten, was gefällt den Security-Leuten denn daran nicht? Und wo liegen sonst noch versteckte Fallen?
Sicherheitskritische Software
Bevor wir in die Details einsteigen, stellt sich die Frage, bei welchen Programmen man überhaupt auf Sicherheit achten muss. Die einfache Antwort ist: bei jedem Programm, wenn auch nicht immer im gleichen Umfang. Eine Sicherheitslücke bedeutet vereinfacht gesagt, dass ein Benutzer mehr kann als er darf – etwa Dateien oder Teile von Dateien lesen, für die er nach den vergebenen Zugriffsrechten keine Leseberechtigung hat, oder unter einer anderen User-ID arbeiten. Beliebtes Ziel ist dabei natürlich der Root-Account.
Um diese zusätzlichen Fähigkeiten zu erlangen, kommen – neben übersehenen Fehlern in der Konfiguration – vor allem Programme in Frage, die genau diese Rechte besitzen, sie aber eigentlich nicht an jeden weitergeben. Das können s-Bit-Programme sein, Daemons, CGI-Skripte oder einfach nur Programme, die ein anderer Benutzer gestartet hat.
Solange sich in diesen Programmen nicht sowieso ein trojanisches Pferd befindet (diesen Fall wollen wir im Augenblick noch ausschließen), muss ein Angreifer das Programm in irgendeiner Form beeinflussen. Bei s-Bit-Programmen könnte er mit ungewöhnlichen Parametern spielen oder die Environment-Variablen anders setzen, als der Programmierer es erwartet. Bei Serverprogrammen sind die Eingaben des Clients der typische Weg für einen Angriff.
CGI-Skripte sind im Grunde ebenfalls Server, die vom Webserver gestartet werden und ihre Parameter vom Browser erhalten. Beispielsweise über temporäre Dateien in /tmp können aber sogar sehr gewöhnliche Programme angegriffen werden, die ein anderer User gestartet hat. Die möglichen Wege sind recht vielfältig, sogar Signale können unerwünschte Folgen haben. In jedem Fall führen unerwartete Eingaben zu ungewollten Ergebnissen, zumindest aus der Sicht des betroffenen Programmierers.
Lernen am schlechten Beispiel
Nehmen wir ein kleines Beispiel: Wir könnten zwar beliebige reale Lücken nehmen, der Einfachheit halber (und um nicht ungerecht zu werden) soll es ein kleines selbst geschriebenes s-Bit-Programm sein. Das Beispiel ist etwas weltfremd, so dass hoffentlich niemand auf die Idee kommt, das Programm wirklich einzusetzen: Mehrere Benutzer tragen ihre Änderungen in eine CHANGES-Datei ein, dürfen aber keine alten Einträge ändern oder gar löschen. Bei den üblichen Unix-Zugriffsrechten gibt es aber kein Append-only. Wir sorgen also dafür, dass die Benutzer in die Datei nicht direkt schreiben können, sondern nur unser s-Bit-Programm.
Zudem stellt das Programm sicher, dass jeder Eintrag mit der korrekten User-Kennung sowie mit Datum und Uhrzeit versehen ist. Weil der Admin die Datei auch nicht ständig überprüfen will, schickt ihm das Programm nach jedem Eintrag eine kurze Mail.
Unser Versuch ist als Listing abgedruckt. Der erste Fehler wird bereits beim Öffnen der Datei gemacht: Sie ist ohne Pfad angegeben.
Listing |
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define BUFLEN 1024
void addChanges(FILE *f)
{
char buffer[BUFLEN];
time_t t;
printf("Your changes: ");
gets(buffer);
time(&t);
fprintf(f, "%s: %st%snn",
getenv("USER"),
asctime(localtime(&t)),
buffer);
}
int main()
{
FILE *ch;
if(ch=fopen("CHANGES", "a"))
{
addChanges(ch);
fclose(ch);
system("echo CHANGES | mail admin");
return 0;
}
fprintf(stderr,
"Could not open CHANGESn");
return 1;
}
|
Vorsichtig öffnen
Durch den fehlenden Pfad kann jede Datei mit Namen CHANGES, auf die das s-Bit-Programm ein Schreibrecht hat, beschrieben werden. Was auf den ersten Blick als wünschenswerte Flexibilität erscheint, ist auf den zweiten Blick durchaus gefährlich: Statt einer echten CHANGES-Datei könnten wir einen Link (Symlink oder Hardlink) auf eine andere Datei anlegen, die dann entsprechend geändert würde. Da symbolische Links auch ins Leere zeigen können, eignet sich das sogar zum Anlegen neuer Dateien. Also lieber den absoluten Pfad angeben und sicherstellen, dass normale Benutzer kein Schreibrecht auf die Verzeichnisse haben.
Eine verbreitete Vorsichtsmaßnahme könnte uns vor negativen Folgen dieses Bugs bewahren: das Programm nicht unter einer auch anderweitig genutzten User-Kennung laufen lassen (und schon gar nicht als Root), sondern einen eigenen Benutzer einrichten. Dieser Account sollte außer dem Schreibrecht auf die CHANGES-Datei keinerlei Rechte haben.
s-Bit-Programme |
| Jeder Prozess in einem Unix-System läuft unter einer bestimmten Benutzerkennung. Sie entspricht in der Regel dem Benutzer, der ihn gestartet hat. Aus der Kennung leiten sich die Zugriffsrechte ab, die das Programm hat.
Wenn ein Programm zusätzliche Rechte haben soll, kann man es mit einem s-Bit ausstatten. Dieses Bit wird wie alle anderen Dateirechte mit chmod gesetzt. Es steht für set-ID und führt dazu, dass das Programm zusätzlich zu den Rechten desjenigen, der es ausführt, auch noch die Rechte des Besitzers der Programmdatei erhält. Da die Rechte eines Benutzers sich aus seiner UID und seiner GID (Gruppe) ableiten, gibt es auch zwei s-Bits, eines für den Benutzer und eines für die Gruppe. Das Programm kann, während es ausgeführt wird, entscheiden, unter welcher UID (oder GID) es seine Befehle ausführt. Im Normalfall wird es seine zusätzlichen Rechte nur für die geplante Bestimmung nutzen, ein Angreifer wird aber versuchen diese Grenzen zu überschreiten. Um den Wechsel zu ermöglichen, unterscheidet Unix zwischen der real, der effective und der saved UID, entsprechende Unterscheidungen gelten für die GID. Die real UID bezeichnet den tatsächlichen User, der das Programm gestartet hat, die effective UID bestimmt die Zugriffsrechte (nur sie wird vom s-Bit geändert). Die saved UID schließlich sorgt dafür, dass ein Programm seine Privilegien zwischendurch abgeben und sie sich später wieder zurückholen kann. Die saved UID wird nicht an Kindprozesse weitergegeben. Mehr zu den Details der UIDs und zu den Regeln, wann ein Programm welche UID oder GID annehmen kann, finden Sie beispielsweise in [1]. Häufig werden s-Bit-Programme auch als SUID-Programme bezeichnet; leider wird die Abkürzung SUID aber auch für die saved UID verwendet. Genaueres zu s-Bits und die genauen Regeln, wann ein Programm welche Rechte annehmen kann, sind in [5] nachzulesen. |
Wer bin ich?
Die nächste Nachlässigkeit ist in getenv(“USER”) verborgen: Diese Variable enthält zwar normalerweise die Login-Kennung des Anwenders, nur kann er die Variable beliebig ändern. Damit könnte er beispielsweise Einträge unter einem anderen Namen vornehmen. Da der Wert dieser Variablen inklusive der Zeilenumbrüche direkt übernommen wird, könnte er sogar ganze Einträge (mit Namen und Datum) fälschen – dagegen hilft auch die Vorsichtsmaßnahme mit dem speziellen Account nicht. Besser ist der Weg über getpwuid(getuid()). Weil getuid() die real UID abfragt, das s-Bit aber die effective UID setzt, erhalten wir den richtigen Benutzer.
Diese Lücken waren ja noch ziemlich offensichtlich. Komplizierter wird es beim Einlesen der Änderungen per gets(). Diese Funktion liest einfach so lange, bis ein Zeilenende ( NEWLINE) kommt oder das Dateiende ( CTRL-D) erreicht wird. Sie kann aber nicht wissen, wie viel Platz im Array buffer wirklich zur Verfügung steht. Gibt ein Benutzer mehr als 1023 Zeichen ein (das abschließende 0-Byte nicht vergessen), wird der Speicher hinter dem Array überschrieben und in der Folge stürzt das Programm meist mit SIGSEGV ab.
Überlaufende Puffer
So ein Absturz ist zwar ärgerlich, stellt an sich aber noch keine Sicherheitslücke dar. Es trifft ja nur den Anwender selbst, der mit der überlangen Eingabe selbst schuld ist. Nun sind solche Buffer Overflows aber einer der häufigsten Ansatzpunkte für Exploits. Um das zu verstehen, untersuchen wir erst einmal genauer, wie der Speicher in unserem Programm organisiert ist – und wo die überzähligen Zeichen nach der Eingabe überhaupt landen.
Im Prinzip gilt das Problem der Buffer Overflows für jeden Speicherbereich, in den ein Prozess schreiben kann. Dabei könnte es sich um dynamisch alloziierten Speicher handeln (malloc) oder um statische Variablen. In unserem Beispiel handelt es sich aber um automatische Variablen, das heißt: Das Array existiert (im Gegensatz zu static-Variablen) nur während der Ausführung der Funktion addChanges. Diese Variablen liegen auf dem Stack.
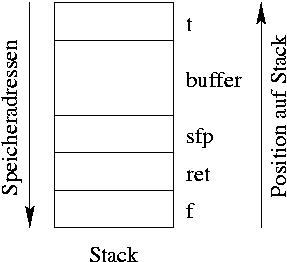
Abbildung 1: Die Belegung des Stacks nach dem Aufruf der Funktion addChanges().
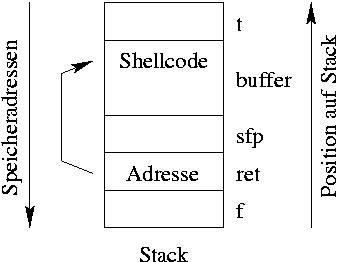
Abbildung 2: Gezieltes Überschreiben des Stacks mit einem AssemblerProgramm und der passenden Adresse.
Stapelweise Daten
Das Konzept eines Stacks muss ein C-Programmierer heute gar nicht mehr unbedingt kennen, jeder Assembler-Entwickler ist damit aber sehr vertraut. Ein Stack, auch LIFO (Last In, First Out) genannt, dient gewissermaßen zum Stapeln von Daten. Die zuletzt auf den Stapel gelegten Daten werden als zuerst wieder heruntergenommen.
Diese Eigenschaft ist fürs Speichern von Rücksprungadressen bei Unterprogrammen ideal: Vor dem Sprung wird die aktuelle Programmadresse auf den Stack gelegt. Egal welche Funktionen wie oft und in welcher Reihenfolge aufgerufen wurde, den Weg zurück findet man durch Abtragen der Adressen vom Stack.
Der Stack ist aber auch ideal dafür geeignet, die Parameter und die dynamischen lokalen Variablen einer Funktion zu speichern. Würde man diese Daten an einer festen Adresse ablegen, wären rekursive Funktionen kaum mehr möglich. So aber wird bei jedem Aufruf ein neuer Block (stack frame) angelegt, in dem diese Daten liegen. In einem solchen Block liegt auch unser Array, wie Sie in Abbildung 1 sehen.
Der Parameter f wird als zuerst auf den Stack gelegt, da er ja noch von der aufrufenden Funktion stammt. Diese benutzt dann den Assembler-Befehl call, der sich die Rücksprungadresse auch mit Hilfe des Stacks merkt. Folglich liegt ret danach auf dem Stapel. Der Eintrag sfp ist der gespeicherte Frame-Pointer, er zeigt auf die Variablen im Stack-Frame. Bevor dieser Zeiger (FP) auf den aktuellen Frame verbogen wird, legen die Compiler seinen (alten) Wert auch auf den Stack.
Ab ins Nirwana?
Schließlich liegen noch unser Array buffer und die Struktur t auf dem Stapel. Das Array wird dann aber innerhalb addChanges() ohne Überwachung der Grenzen aufgefüllt. Wenn es voll ist, schreibt gets() jedoch weiter Daten in den Speicher: Woher soll es denn auch wissen, dass der Speicherbereich für buffer eigentlich schon voll ist?
Ein Array wird mit wachsenden Adressen beschrieben, der Stapel wächst zumindest bei Intel-x86-Prozessoren aber in Richtung kleinerer Adressen. Folglich fallen sfp, ret und so weiter dem Schreiben zum Opfer. Zuerst wirkt sich davon die Rücksprungadresse aus: Der Wert des Frame- Pointers wird zwar vorher aus dem sfp restauriert, aber erst nach dem Rücksprung wirklich genutzt.
Da wir die RET-Adresse aber soeben überschrieben haben, landet dieser Sprung im Nirwana: Die Adresse wird in der Regel außerhalb des Adressraums liegen, der unserem Prozess zur Verfügung steht, und dafür gibt’s die Segmentation Violation ( SIGSEGV) als Strafe.
Oder doch nicht?
Der Trick der Angreifer ist, nicht irgendwelche zufälligen Werte zu schreiben, sondern an den Anfang des Buffers ein kleines Assembler-Programm zu setzen. Der Rest wird mit beliebigen Werten gefüllt, auch sfp wird überschrieben. An die Stelle der Rücksprungadresse ret schreiben sie aber die Anfangsadresse des Buffers (siehe Abbildung 2) – diese Adresse lässt sich mit gdb ermitteln. Wenn die Funktion nun zurückkehren will, springt sie in Wirklichkeit zum Assembler-Code in buffer.
Üblicherweise nimmt man als Assembler-Programm einen übersetzten execve(“/bin/sh”)-Aufruf, daher stammt auch der Name Shellcode. Der Cracker erhält schließlich eine interaktive Shell, die mit den Rechten des aufgerufenen Programms ausgestattet ist.
Das Schreiben des Shellcode ist dabei nicht immer ganz einfach. Ein Angreifer kann in den wenigsten Fällen wirklich beliebige Bytes schreiben, speziell ein Null-Byte ist kaum möglich und auch die Anfangsadresse des Buffers will erst ermittelt werden. Doch sind all diese Probleme längst gelöst, dabei kommen auch Techniken wie beispielsweise selbst modifizierender Code zum Einsatz. Der einmal entwickelte Shellcode kann sogar in vielen unterschiedlichen Exploits genutzt werden. Diese Exploit-Programme übergeben dann nur noch den Shellcode an das Programm, das sie knacken wollen.
Es gibt einige Ansätze, wie das Problem der Buffer Overflows umgangen werden könnte. Sie reichen von der automatischen Überprüfungen der Array-Grenzen bis zur Überprüfung der Rücksprungadresse, oder man sorgt dafür, dass Code auf dem Stack nicht ausgeführt werden kann. All diese Tricks haben allerdings auch ihre Probleme (so legt der gcc etwa in manchen Fällen selbst Code auf dem Stack ab, so genannte Trampolines) und können ihrerseits auch wieder umgangen werden.
Am Ende macht es mehr Sinn, die Lücken in den Programmen zu schließen. In unserem Fall würde ein fgets(buffer, BUFLEN, stdin) anstelle von gets(buffer) helfen. Beim Aufspüren der Lücken im Quelltext können spezielle Source Code Security Analyzer wie Slint oder ITS4 hilfreich sein. Allerdings werden diese Tools immer nur einen Teil der Buffer Overflows finden können, so dass sie den Programmierer auch in trügerischer Sicherheit wiegen können. Am Ende muss er doch die Quellen von Hand überprüfen.
Gefährliches Echo
Nach diesen Ausflügen zu den Interna von C und Stack ist unser nächster Kandidat wieder einfacher zu verstehen. Das Absenden der Mail geschieht im Beispielprogramm über einen Aufruf von system(). Dessen Argument wird an eine Shell übergeben, die den Code ausführt und in der Folge unsere kleine Mail sendet. Oder zumindest senden soll – die Shell sucht ja die Programme, die sie ausführt, in den Verzeichnissen aus der Umgebungsvariablen $PATH.
Wenn wir nun einfach an erster Stelle in $PATH unser Home-Verzeichnis angeben und dort ein Programm mit dem Namen mail ablegen, wird genau dieses benutzt. Was das Programm dann macht, liegt natürlich wieder in unserer Hand.
Eine alte Empfehlung ist es, innerhalb von system() Programme nur mit absoluten Pfadangaben zu starten. Aber auch das hilft nicht wirklich: Die Shell ist einfach zu vielseitig, um sich von solchen Dingen ernsthaft beeindrucken zu lassen. Sie bietet uns etwa die Variable $IFS an: Alle Zeichen, die diese Variable enthält, dienen als Trennzeichen zwischen einzelnen Anweisungen.
Üblicherweise enthält sie Leerzeichen, Tabulator und Zeilenende. Niemand hindert uns aber daran, zusätzlich den Slash als Trennzeichen zu nehmen. Aus einem /bin/echo werden so die zwei Kommandos bin und echo. Wieder setzen wir an den Anfang von $PATH unser Home-Verzeichnis und legen dort ein Programm ab, diesmal mit Namen bin. Bingo.
Oder doch nicht? Um sich vor solchen Gemeinheiten zu schützen, nutzt die Bash $IFS etwas vorsichtiger als andere Shells: Lediglich die Ergebnisse von Expandierungen werden mit Hilfe von $IFS zerteilt, nicht die Kommandos. Unser Angriff funktioniert daher nicht, wenn /bin/sh in Wirklichkeit eine Bash ist. Andere Shells verhalten sich aber anders (etwa die originale Bournce Shell) und man kann mit $IFS und anderen Variablen auch in der Bash immer noch Unfug treiben.
Was kann man dagegen tun? Eine bessere Alternative zu system() wäre execve(), nur wird damit aus der einen Zeile ein deutlich aufwändigeres Stück Code. Andererseits braucht aber unser s-Bit-Programm seine besonderen Rechte schon nicht mehr, wenn es die Mail senden soll. Warum sollte es diese Rechte dann aber an ein potenziell nicht vertrauenswürdiges Programm weitergeben? Besser geben wir diese Rechte wieder ab, bevor wir externe Programme starten: setuid(getuid()). Das Aufgeben der zusätzlichen Rechte sollte so bald wie möglich geschehen; je weniger Code mit unnötigen Privilegien läuft, desto geringer wird die Gefahr.
Allerdings ist der Schutz durch die Besonderheiten der saved UID etwas eingeschränkt: Die eben aufgegebenen Rechte kann sich unser Programm selbst erneut holen – nur an Kindprozesse wird die saved UID nicht vererbt, so dass von denen keine weitere Gefahr mehr ausgeht. Der Shellcode eines Buffer Overflows wird aber als Teil des angegriffenen Programms ausgeführt, so dass dort durchaus auch die saved UID genutzt werden kann.
Noch nicht am Ende
Offenbar lauert die Gefahr an allen Ecken. Vom einfachen Öffnen einer Datei über das Verarbeiten von Benutzereingaben bis zum Starten von Hilfsprogrammen, überall können sich schnell kleine Fehler einschleichen, deren Folgen möglicherweise fatal sind.
Neben den hier genannten Fallen gibt es natürlich noch eine Vielzahl weiterer typischer Fehler, die häufig zu Sicherheitslücken führen. Verbreitet sind zum Beispiel die Format-Bugs, bei denen der Format-String von printf zweckentfremdet werden kann, oder Race conditions bei temporären Dateien in /tmp. Wir werden deshalb in lockerer Folge weitere verbreitete Fallen vorstellen, die man als Programmierer kennen und berücksichtigen sollte. ( fjl)
Infos |
| [1] Secure Unix Programming FAQ: http://www.whitefang.com/sup/secure-faq.html
[2] A Lab engineers check list for writing secure Unix code: ftp://ftp.auscert.org.au/pub/auscert/papers/secure_programming_checklist [3] Secure Programming for Linux and Unix HOWTO: http://dwheeler.com/secure-programs [4] Aleph One: Smashing The Stack For Fun And Profit. Phrack Vol. 7, Issue 49, File 14; beispielsweise auf: http://www.securityfocus.com/data/library/P49-14.txt [5] W. Richard Stevens: Advanced Programming in the Unix Environment, Addison-Wesley 1992 |





