
© tomwang, 123RF.com
Neben technischer Raffinesse und Verfügbarkeit trägt die in der Praxis erzielbare Geschwindigkeit wesentlich zur Nutzerzufriedenheit gegenüber jedem Storage-Setup bei. Das Linux-Magazin lässt darum NFS 3 und 4, CIFS-SMB 1 und 2 sowie Gluster-FS und Ceph-FS gegeneinander rennen.
Die bisherigen Artikel im Schwerpunkt des Magazins haben die funktionalen Aspekte der neuen Netzwerk-Dateisysteme beleuchtet. Dieser Beitrag dagegen macht sich eine fundierte quantitative Geschwindigkeitsanalyse zur Aufgabe. Denn was nutzen die schönsten Features eines neuen Dateisystems, wenn der Endbenutzer an seinem PC eine halbe Minute warten muss, bevor er ein etwas größeres Fileserver-Directory angezeigt bekommt?!
Um einerseits eine gute Referenz zu haben und andererseits die gängige Praxis in Produktivumgebungen zu würdigen, nehmen die Klassiker NFS und CIFS mittels Samba in den folgenden Tests und im Text anders als in den anderen Schwerpunkt-Artikeln einen großen Raum ein. Gar nicht betrachtet werden verteilte Systeme, die ihren Clients kein Posix-Dateisystem bereitstellen, also nicht als NAS auftreten, sondern ein SAN ersetzen wollen. Folgende Netzwerk-Dateisysteme stellen sich im Labor schließlich den Geschwindigkeitstests:
- NFS 3 – der “Golden Standard” in den meisten Linux-Umgebungen mit dem Ruf schnell und unkompliziert Daten bereitzustellen, er gilt jedoch vielen als unsicher (RFC 1813, [1])
- NFS 4 – Weiterentwicklung mit dem Ziel, bessere Performance und höhere Sicherheit zu bieten (RFC 3010, [2])
- CIFS-SMB – das Original-SMB-Protokoll (Server Message Block), 1996 erweitert und zu CIFS umbenannt [3]
- CIFS-SMB 2 – die Weiterentwicklung von CIFS, ausgeliefert mit Microsoft Windows 7 und 2008R2 sowie ab Samba 3.6 (August 2011) auch für Linux [4]
- Gluster-FS – ursprünglich von Gluster, Inc., seit 2011 von Red Hat entwickeltes, in den Petabyte-Bereich skalierbares Netzwerk-Dateisystem [5]
- Ceph-FS – die Mount-Schnittstelle zu Ceph ist neuester unter den Teilnehmern und noch als experimentell markiert. Es zeigt ähnliche Eigenschaften wie Gluster-FS und eignet sich seit der ersten Long-Term-Support-Version “Argonaut” zum Test [6].
Die ersten vier Teilnehmer des Tests decken den Löwenanteil heutiger Netzwerk-Dateisysteme in Produktivsystemen ab, im letzte Drittel treten die aussichtsreichsten Herausforderer an.
Aufbau und Setup
In ihrem Aufbau unterscheiden sich die Dateisysteme erheblich. Das gilt bereits bei NFS 3 und 4 (Abbildung 1). Wo mit NFS 3 getrennte Daemons mit dem Nfsd als Master und eigenständige Daemons für den Lookup (»rpcbind« ), das Mounten (»rpc.mountd« ) und das Locking (»rpc.statd« mit »rpc.lockd« ) obligatorisch sind, sorgt bei NFS 4 alleine der Nfsd als Master mit »rpc.mountd« als Helfer für die NFS-Exports. Der Admin muss lediglich »/etc/exports« anpassen, und nach Neustart des Daemons steht das Dateisystem zur Verfügung. Im Rahmen dieses Tests kamen zudem die NFS Utilities [7] der Version 1.2.6 zum Einsatz.
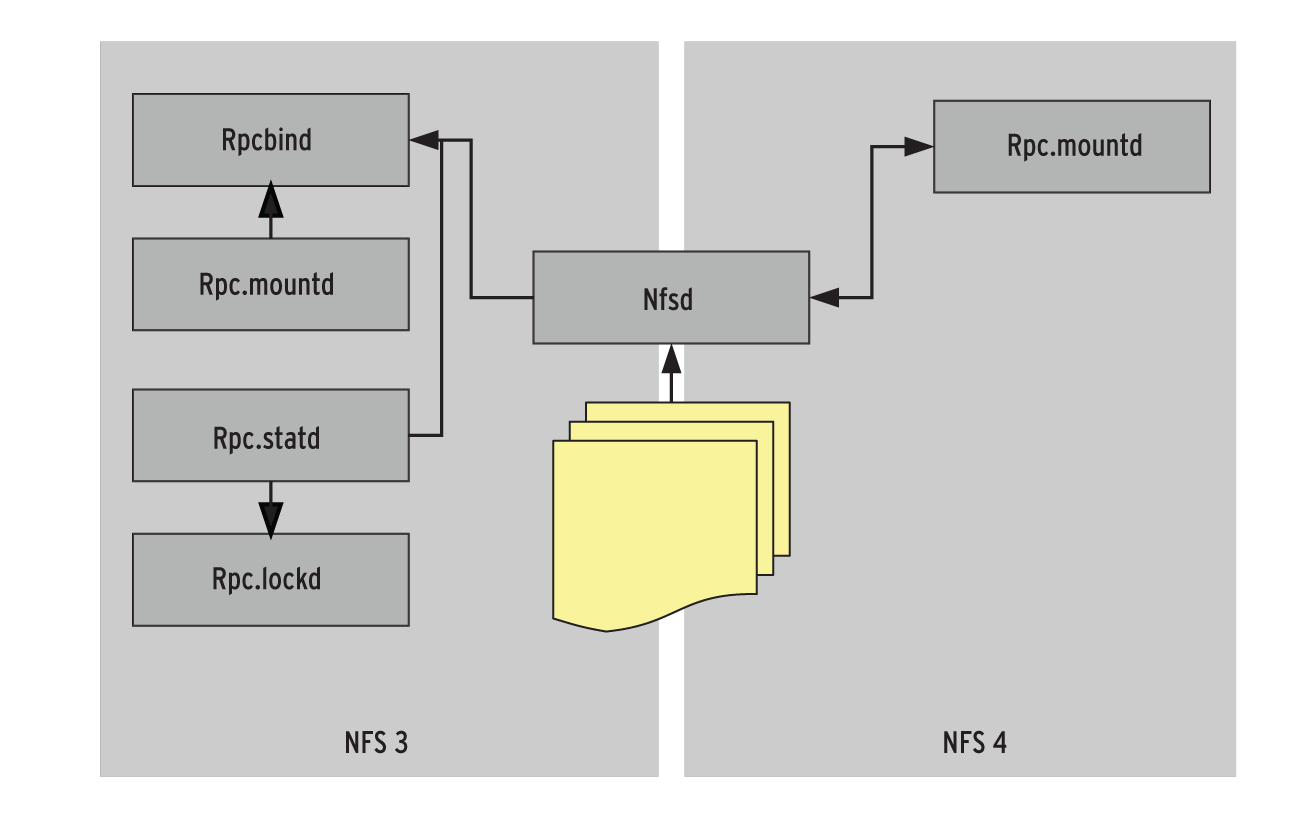
Abbildung 1: Die Architektur von NFS 4 ist deutlich simpler als die von NFS 3.
CIFS-Architekturen mit ihrem sehr modularen und konditionalen Aufbau lassen sich nicht in ein paar Sätzen schlüssig erklären. Wer sich verständlicherweise dafür interessiert, kann in [8] die Grundlagen nachlesen und dort insbesondere die Abbildung B.17 zu Rate ziehen. Die vorliegende Testumgebung war mit Samba 3.6.7 bestückt und das Konfigurieren über die bekannte »/etc/samba/smb.conf« -Datei schnell erledigt.
Gluster-FS teilt seine effektiv verwendeten Storage in so genannten Bricks auf, die Glusterd bereitstellt. Die Komponentenstruktur ist sehr einfach gehalten. Der Admin kommt sowohl auf dem Server als auch auf dem Client beim Einrichten lediglich mit dem Haupttool »gluster« in Kontakt. Für die Benchmark-Umgebung entschieden sich die Tester für Gluster-FS in der Mainline-Version 3.2.4, die Open Suse ausliefert.
Ceph-FS ist nur ein Bestandteil des gesamten Ceph-Rados-Gesamtpakets und trägt, anders als die anderen Komponenten Rados, Librados, Radosgw und RBD (Rados Block Device), den Experimentell-Status (siehe Abbildung 2). Das Setup von Ceph-FS erwies sich im Test als ein wenig komplexer, gelang schließlich mit Hilfe der Dokumentation Ceph Quickstart [9] aber auch in wenigen Minuten. Bei der Installation zuvor war dies leider nicht der Fall, offenbar sind die Deb-Pakete von Ceph besser erprobt als die RPMs. Als funktionsfähig erwies sich ein Suse-Paket [10], das ein Ceph-Poweruser in der aktuellen Long-Term-Support-Version 0.48.2 per Open Suse Build Service bereitstellt.
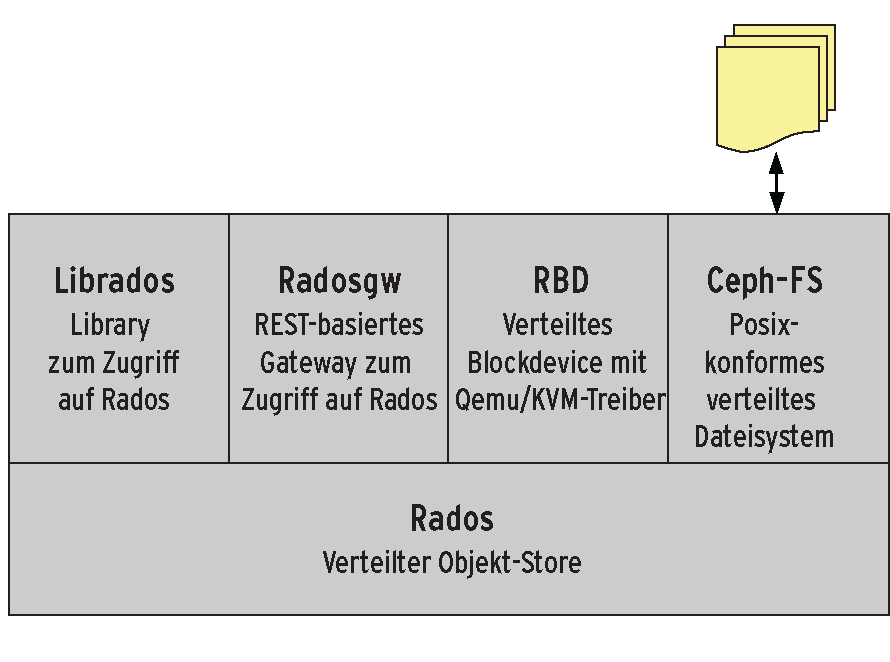
Abbildung 2: Ceph-FS stellt die Filesystem-Schnittstelle des Rados-Storage-Frameworks nach außen dar.
Gezielt: Die Auswahl der Performance-Tests
Die verwendeten Benchmark-Tools und die selbst geschriebenen Skripte schöpfen aus dem Pool jahrelanger Erfahrungen und sinnvoller Empfehlungen diverser Experten. Analog zum Linux-Magazin-Artikel [11], der lokale Dateisysteme untersuchte, kam auch hier ein Benchmark-Mix zur Anwendung, der einerseits ein Set einfacher Dateisystem-Operationen skriptgesteuert abarbeitet und andererseits ausgewählte Durchsatztests des Standardtools Iozone ansolviert (siehe Tabelle 1).
Ein Lauf der beiden Benchmarks dauerte etwa drei Stunden, jedes Dateisystem musste etwa 15 Läufe hinter sich bringen. Alle Ergebnisse wurden zum Schluss gemittelt und in Relation zueinander gebracht. Das Vorgehen stellt eine gute Basis der Vergleichbarkeit her. Die Testteile liefen sequenziell ab, denn die Tester verzichteten auf parallel Dateisystem-Zugriffe, da einerseits erste Experimente instabile Ergebnisse zu Tage förderten und andererseits Iozone im hier verwendeten Auto-Modus multiple Threads nicht zulässt.
Tabelle 1
Verwendete Benchmarks
|
Name |
Beschreibung |
|---|---|
|
Mkdir |
16 Top- mit je 1024 Unterverzeichnissen anlegen |
|
Touch |
16*1024 leeren Dateien anlegen |
|
Echo |
63 Bytes langes Echo in erstellte leere Dateien |
|
Cat |
63-Byte-Dateien nach »/dev/null« ausgeben |
|
DD-Write |
Sequenzielles Schreiben von 16*128 1-MByte- und 10-MByte-Dateien mit einer Blockgröße von 512 Byte |
|
DD-Read |
Sequenzielles Lesen von 16*128 10-MByte-Dateien mit Ausgabe nach »/dev/null« |
|
Rmfile |
Löschen von 16*1024 63-Byte-Dateien und 16*128 10-MByte-Dateien |
|
Rmdir |
Löschen von 16*1024 Verzeichnissen |
|
Iozone |
Iozone-Benchmark (Read, Write, Random Read, Random Write) mit 32-MByte-Dateien ohne Prozessor-Caching |
Testaufbau und -kandidaten
Als Testhardware arbeiteten zwei Dell Poweredge 1950 (siehe Kasten “Die Testumgebung”), ein System diente als Server, das andere als Client. Das Netzwerk mit Cisco SG200 stand während des gesamten Testablaufs, der etliche Tage in Anspruch nahm, exklusiv und damit ungestört zur Verfügung. Für beide Systeme erstellten die Tester eine LACP-Gruppe, jeder Rechner war mittels einem 802.3ad-Bonding konfiguriert. Als Betriebssystem auf Server und Client lief Open Suse 12.2 mit aktiviertem Tumbleweed und dem zum Redaktionsschluss aktuellen Stable-Kernel 3.6.9.
Als lokales Dateisystem kam überall Ext 4 zu Ehren, das alle großen Distributionen anbieten, viele sogar als Default. Um praxisnahe und sachgerechte Leistungsergebnisse zu erhalten, experimentierten und maßen die Tester mit diversen Setups. So betrieben sie die Systeme wechselweise mit SSDs und HDDs.
Die Testumgebung
Geräte: Zwei Stück Dell PowerEdge 1950
Ausstattung: Zwei Quadcore-CPUs Intel Xeon L5430 (2,66 GHz), 16 GByte ECC-RAM, zwei Ethernetcontroller Broadcom Netxtreme II BCM 5708
Speichermedien: Zwei Stück SATA-II Intel SSD 710 Series (100 GByte), zwei Stück Western Digital WD7500BPVT (750 GByte)
Switch-Infrastruktur: Cisco SG200-26P, 802.3ad-Bonding mit LACP-Group
Betriebssystem: Open Suse 12.2 mit Tumbleweed
Filesysteme: NFS 3, NFS 4, Samba 3.6.7 (SMB 2), Ceph 0.48.2 (Argonaut), Gluster-FS 3.2.4.
Wichtig: Caching-Effekte minimieren
Vor jedem Benchmark-Lauf löschen »sync« und ein doppeltes »echo 3 > /proc/sys/vm/drop_caches« Pagecache, Dentries und Inodes. Das stellt sicher, dass der Linux-Kernel keine Gelegenheit erhält, Optimierungen durchzuführen und IO-Operationen über Buffers oder Caches zu serialisieren. Eine weitere Herausforderung für sauberes Benchmarking ist, dass die Testprogramme selbst keine Buffers und Caches in Anspruch nehmen. Um solchen Effekten zu begegnen gibt es drei Möglichkeiten:
- Das Gehäuse aufschrauben und einen Teil des Arbeitsspeichers ausbauen,
- per Grub-Kernelparameter »mem=« den Speicher limitieren, den Linux verwenden soll, (was übrigens auf den Testsystemen auch unter Beachtung der »uppermem« -Direktive nicht funktionierte) oder
- Direct-IO benutzen, welches dafür sorgt, dass das jeweilige Dateisystem unter Umgehung vom Buffercache des Linux-Kernels sofort auf die Festplatte schreibt.
Die Testcrew für diesen Artikel benutzte die letzte Variante. Außerdem deaktivierte sie sowohl Raid-Controller-RAM als auch alle Festplatten-Caches, um auch diesen Komponenten keine Gelegenheit für Optimierungen zu verschaffen.
Ein berechnetes Mittel mehrerer Varianten
Um stochastisch auftretenden Fehlern keine Bedeutung zu verleihen und um praxisrelevant zu bleiben, liefen wie erwähnt alle Tests mehrfach. Dabei kamen einerseits konventionelle Festplatten und andererseits schnelle SSDs zum Einsatz. Um netzwerkseitig den klassischen Fileserver genauso wie eine SAN-Umgebung zu vertreten, liefen zudem ein Teil der Messungen mit der sehr gängigen MTU von 1500 ab und ein anderer Teil mit der MTU 9000 ab, also mit Jumbo Frames wie sie in geschlossenen SAN-Netzwerkumgebungen üblich sind.
Jedes Netzwerk-Dateisystem bietet beinahe unzählige Möglichkeiten zur Optimierung. Um eine klare Vergleichbarkeit herzustellen, lief ein Teil der Tests Out-of-the-Box ohne Optimierung und ein anderer Teil mit einem für das jeweilige Dateisystem passenden bekannten Optimierungspattern.
Die Ergebnisse des umfangreichen Bündels an Messungen haben die Tester gemittelt, da dies nicht nur der Übersichtlichkeit dient, sondern auch einen seriösen Vergleich ermöglicht. Im Umkehrschluss heißt dies, dass alle Zahlen der Analyse nicht als absolute Werte zu verstehen sind, sondern nur die Relation zwischen Dateisystemen abbilden – das dafür besonders gut.
Prozessorauslastung
Im Verlaufe der Benchmarks als die mit Abstand CPU-hungrigsten Daemons erwiesen sich Gluster-FS (durchschnittlich 35 Prozent Last) und Ceph-FS (40 Prozent). Das ist für Storage-Planer durchaus von Bedeutung, bei den hier verwendeten Rechnern kam es über den ganzen Testzeitraum aber nie zur CPU-Vollauslastung. CIFS machte den Eindruck, bei allen Operationen gleichmäßig rund 20 Prozent der CPU-Leitung zu konsumieren. Dabei war unerheblich, ob SMB 2 aktiviert war oder nicht. NFS 3 gab sich mit etwa 15 Prozent am genügsamsten im Testfeld, NFS 4 lag stets mit rund 2 bis 3 Prozent Aufschlag knapp darüber.
Werte und Wertung
Die Balkendiagramme in Abbildung 3, 4 und 5 zeigen die gemittelten Einzelergebnisse. Wer einzelne Performance-Anforderungen an Netzwerk-Dateisysteme hat, kann hier eine Vorauswahl treffen. Um den Ausgang des Wettrennens klarer zu machen, zeigen die drei ersten Spalten von Tabelle 2 die Rankings der Testkandidaten für drei die Hauptdisziplinen atomare Dateiaktionen, DD-Write und -Read sowie Iozone.
Erstaunlich an den Ergebnissen ist, dass die beiden CIFS-Samba-Implementierungen bei den atomaren Operationen, also Verzeichnisse und Dateien anlegen und so weiter, alle anderen Teilnehmer bei Weitem übertrumpfen. Bei den Durchsatztests dagegen trübt sich das sonnige Bild merklich ein. Einzig CIFS-SMB 2 erklettert beim Iozone-Benchmark noch den dritten Rang, was eindeutig die verbesserte Performance von SMB 2 gegenüber SMB 1 darlegt.
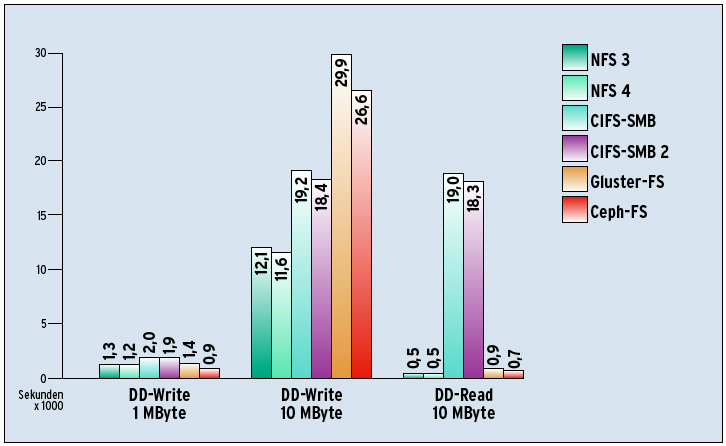
Abbildung 3: Blocktransfers im Real-World-Szenario: Gluster-FS und Ceph-FS liegt das Schreiben großer Blöcke offensichtlich nicht besonders. Beim Lesen großer Datenmengen zeigen die CIFS-Geschwister Hemmungen.
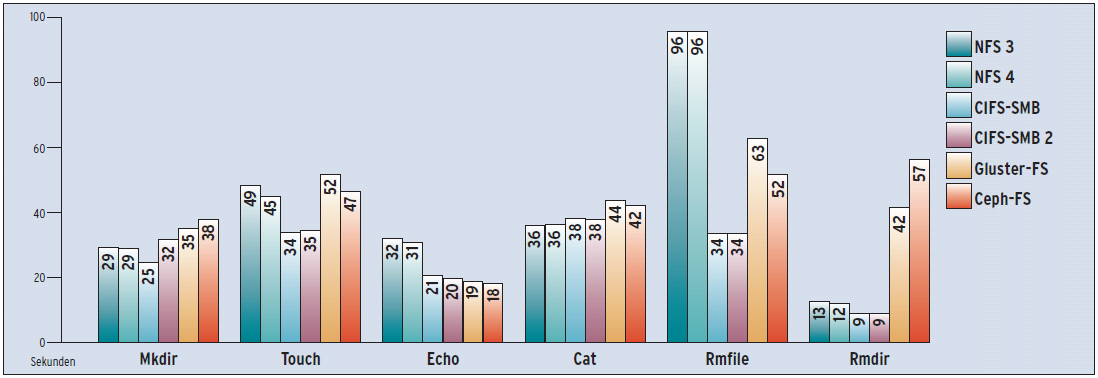
Abbildung 4: Zum Absolvieren atomarer Dateioperationen brauchen die einzelnen Testkandidaten meist ähnlich lange. Echte Ausreißer ins Negative gibt es allein beim Löschen von Dateien (NFS) und Verzeichnissen (Gluster-FS und Ceph-FS).
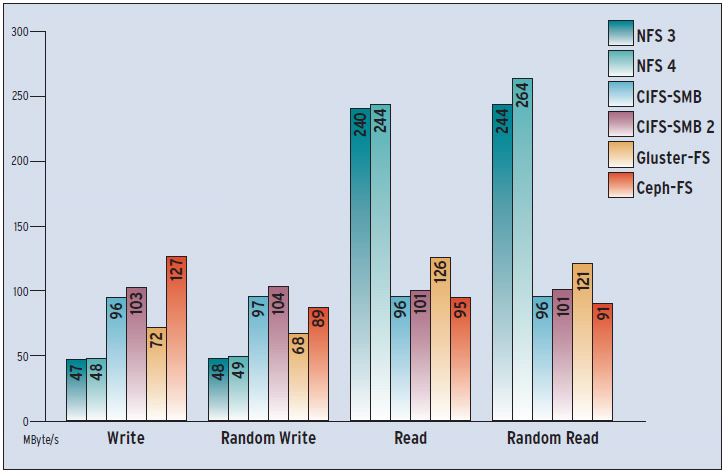
Abbildung 5: Durchschnittliche Datendurchsätze beim synthetischen Iozone: Die beiden NFS-Varianten zeigen sich hier als wahre Schnell-Leser, beim Schreiben machen CIFS und der Newcomer Ceph die beste Figur.
Obwohl es ein Newcomer und zudem ein im Userspace beheimatetes Filesystem ist, das beim Verarbeiten ständig Systemschranken passieren muss, schafft es Ceph-FS in allen Hauptdisziplinen auf mittlere Plätze. Gerade die Datentransferrate zeigt eindeutig, dass Ceph-FS schon heute eine gute Alternative zu den Etablierten bildet. Der andere Newcomer, Gluster-FS, lief durch die Tests zwar durchwegs stabil und erfreut mit einer Leseperformance, die sogar vor CIFS-SMB 2 liegt, fällt als Userspace-Filesystem beim Schreiben aber mit immens schlechten Werten auf.
Bei Ceph-FS und Gluster-FS wird eine Tendenz zur Optimierung auf große Dateien erkennbar, was mit dem propagierten Einsatzzweck in der Cloud und der seit Geburt integrierten Replikation mit VM-Images übereinstimmt.
NFS 4 erweist sich bei Datenübertragungen als klarer Sieger. Atomare Dateisystemoperationen sind dagegen nicht so des Kandidaten Ding – hier ist sogar der Vorgänger NFS 3 besser.
Tabelle 2
Platzierung
|
Atomare Dateiaktionen |
DD-Write und -Read |
Iozone |
Gesamt |
|---|---|---|---|
|
1. CIFS-SMB |
1. NFS 4 |
1. NFS 4 |
1. NFS 4 (16 Punkte) |
|
2. CIFS-SMB 2 |
2. NFS 3 |
2. NFS 3 |
2. CIFS-SMB 2 (11 Punkte) |
|
3. NFS 4 |
3. Ceph-FS |
3. CIFS-SMB 2 |
2. NFS 3 (11 Punkte) |
|
4. Ceph-FS |
4. Gluster-FS |
4. Ceph-FS |
4. Ceph-FS (10 Punkte) |
|
5. Gluster-FS |
5. CIFS-SMB 2 |
5. Gluster-FS |
5. CIFS-SMB (8 Punkte) |
|
6. NFS 3 |
6. CIFS-SMB |
6. CIFS-SMB |
6. Gluster-FS (7 Punkte) |
The Winner is …
Um einen Gesamsieger zu küren, macht dieser Artikel eine einfache Rechnung auf: Für die drei Hauptdisziplinen in Tabelle 2 vergibt sie an jedes Dateisystem für dessen erreichte Platzierung Punkte: Der Erstplazierte bekommt 6 Punkte, der Zweitplazierte 5 Punkte und so weiter. Aus der Summe der Punkte aus den drei Kategorien lässt sich dann leicht das Gesamtranking bestimmen – die vierte Spalte von Tabelle 2 zeigt es. Die Arme in Siegerpose hochreißen wie im Aufmacherfoto zu diesem Artikel darf: NFS 4! Den zweiten Platz teilen sich salomonisch CIFS-SMB 2 und NFS 3.
Fazit
Die erhobenen Benchmark-Ergebnisse rücken ein paar Dinge gerade: Die vielen Betreiber von NFS-3-Fileservern machen im Kern nichts falsch: Der betagte Klassiker hält auch im Jahr 2013 unterm Strich gut mit. NFS 4 als Gesamtsieger des Performance-Wettbewerbs erweist sich zudem als ein mehr als würdiger Nachfolger und weist der NFS-3-Gemeinde einen guten Migrationspfad.
In Netzen mit Windows-Teilnehmer ist Samba nicht nur funktional die richtige Wahl, sondern in der Ausprägung SMB 2 auch in Sachen Geschwindigkeit. Wer moderne Linux-Distributionen und keine Clients vor Windows Vista im Netzwerk hat einsetzt, sollte nicht davor zurückschrecken, die Direktive »max protocol = SMB2« in der »[global]« -Sektion der »smb.conf« einzutragen.
Die Newcomer Ceph-FS und Gluster-FS legen offenbar beide den Fokus auf die Skalierbarkeit – und das kostet bei einfachen Dateisystemoperationen Performance. Ceph-FS schlägt sich hier viel wackerer als Gluster-FS, bei dem die Entwickler in dieser Hinsicht nacharbeiten sollten. Zur Ehrenrettung des Duos soll betont sein, dass der parallele Clusterbetrieb, also das Skalieren in die Breite, insbesondere bei HPC-Anwendern, nicht Gegenstand dieses Tests war. Mit einem Mehr an Servern lassen sich Performance-Nachteile in großen Produktivumgebungen vermutlich nicht nur kompensieren, sondern sogar zum Vorteil ummünzen.
Generation Dauerlauf
Da Fileserver zur Infrastruktur zählen, bei der bekanntlich Stabilität als ein sehr zentrales Kriterium gilt, eignet sich ein Abfallprodukt der unternommenen umfangreichen Benchmark-Tests als Lieferant der guten Nachricht zum Schluss: Bei keinem einzigen Test und keinem Testteilnehmer traten Locks oder Abstürze auf, auch nicht bei Ceph-FS, immerhin eine experimentelle Implementierung. Hier heißt es für alle: Sieg! (jk)
Infos
- NFS 3, RFC 1813: http://tools.ietf.org/html/rfc1813
- NFS 4, RFC 3010: http://tools.ietf.org/html/rfc3010
- CIFS-SMB: http://tools.ietf.org/html/draft-heizer-cifs-v1-spec-00
- CIFS-SMB 2: http://download.microsoft.com/download/a/e/6/ae6e4142-aa58-45c6-8dcf-a657e5900cd3/[MS-SMB2].pdf
- Gluster-FS: http://www.gluster.org
- Ceph: http://ceph.com
- NFS Utilities: http://nfs.sourceforge.net
- Microsoft-Referenz zum Common Internet File System: http://technet.microsoft.com/en-us/library/cc939973.aspx
- Quickstart-Anleitung für Ceph: http://ceph.com/docs/master/start/quick-start/
- Ceph auf dem Open Suse Build Service: https://build.opensuse.org/package/show?project=home%3Anick_at_seakr%3Amisc&package=ceph
- Michael Kromer, “Linux-Dateisysteme im Leistungstest”, Linux-Magazin 07/12, S. 28
Der Autor

Michael Kromer (http://medozas.de) ist Leiter Professional Services Deutschland bei Zarafa und ist anderem für Large-Scale-Implementationen und Architekturen der Groupware verantwortlich. Privat engagiert er sich in diversen Open-Source-Projekten, zum Beispiel dem Linux-Kernel, Open NX, Asterisk, Virtualbox und ISC Bind. Seine persönlichen Leidenschaften gelten Open Suse, allen möglichen Virtualisierungstechnologien und Prozessorarchitekturen.





