
© Dagmar Fischer, Photocase.com
Perls Git-Repository enthält alle Commits, seit Larry Wall Perl 1987 aus der Taufe hob. Das Statistik-Tool R gewinnt aus den historischen Daten überraschende Informationen und stellt sie grafisch dar.
Es kann vielleicht nicht jeder nachvollziehen, aber zumindest für mich hat es etwas Erhebendes, die vollständige Historie des Perl-Kerns vor Augen zu haben. Welche Dateien hat Larry Wall anno 1987 eingecheckt? Wer schickte das erste Patch ein? Was enthielt es? Das Kommando »git log« zeigt erste Ergebnisse sofort an (Abbildung 1) und benötigt nur wenige Sekunden, um sich bis zum Anfang des Projekts vorzuarbeiten. Das funktioniert sogar ohne Internetverbindung und selbst auf einem Netbook. Alle Informationen sind in einem 120 MByte großen Repository versteckt, das »git« von [git://perl5.git.perl.org/perl.git] bezieht. Dass Git herkömmliche Versionskontrollsysteme wie Subversion aus dem Feld schlägt, wundert nur Unwissende.
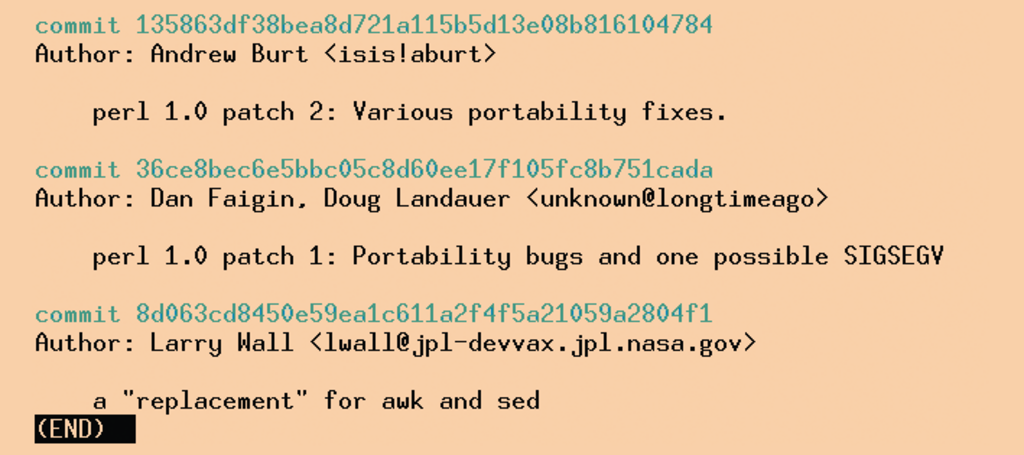
Abbildung 1: Das Git-Repository des Perl-Projekts enthält alle Commits, seit Larry Wall 1987 es aus der Taufe hob. Für die Zeitreise braucht die Versionskontrolle nur Sekunden.
Geballte Information
Die geballte Informationsladung des Perl-Repository hilft nicht nur interessierten Programmierern die Entwicklung des Projekts mitzuverfolgen. Moderne Statistiktools extrahieren daraus Trends und stellen sie grafisch ansprechend dar. Bereits mit Shell-Bordmitteln wie
git log --oneline | wc -l
git log --name-status --date=raw --pretty='format:commit,%ae,%at,%ce' > perl-git-log.txt
produziert eine umfangreichere Ausgabe. Jeder Commit enthält in diesem Format eine oder mehrere Dateien, die Git unterhalb der Kopfzeile jeweils nach einem Change-Flag (»M«: modified, »A«: added, »R«: removed) zeilenweise auflistet. Kopfzeilen beginnen mit »commit«, damit der später gebaute Parser sie leicht von Dateizeilen unterscheiden kann. Nach dem Aufruf des obigen Shell-Einzeilers schnappt sich Listing 1 die Daten und formt sie in ein CSV-Format um, mit dem das Statistiktool R später weiterarbeitet.
|
Listing 1: |
|---|
01 #!/usr/local/bin/perl -w
02 use strict;
03 use local::lib;
04 use Text::CSV;
05
06 my $logfile = "perl-git-log.txt.bz2";
07 my $csvfile = "perl-git-log.csv";
08
09 my $csv = Text::CSV_XS->new ( { binary => 1, eol => $/ } ) or
10 die "Cannot use CSV: ", Text::CSV->error_diag();
11
12 open my $logfh, "bzip2 -dc $logfile |" or die "$logfile: $!";
13 open my $csvfh, ">$csvfile" or die "$csvfile: $!";
14
15 my($dummy, $author, $time, $committer);
16
17 $csv->print( $csvfh, ["time", "file", "author", "committer"] );
18
19 while( <$logfh> ) {
20 if( /^commit/ ) {
21 chomp;
22 ($dummy, $author, $time, $committer) = split /,/, $_;
23 } elsif( /^(w)s+(.*)/ ) {
24 my $file = $2;
25 $csv->print( $csvfh, [$time, $file, $author, $committer] ) or
26 die "print failed: ", Text::CSV->error_diag();
27 }
28 }
29
30 close $logfh or die "$logfile: $!";
31 close $csvfh or die "$csvfile: $!";
|
Perl als Hilfsarbeiter
Auch der Perl-Snapshot kann sich nicht immer nur auf die Sprache Perl beschränken. Im Bereich der Statistik glänzt die Sprache R [2] mit geschwindigkeitsoptimierten Datentransformationen, einer reichen Auswahl an Grafikbibliotheken und einem CPAN-ähnlichen Entwicklernetzwerk namens CRAN.
In R geschriebene Skripte sind erstaunlich kompakt, allerdings dauert es einige Zeit, bis Neulinge die neuen Paradigmen und Datenstrukturen durchschauen [3]. Perl hingegen glänzt im Umwandeln von Datenformaten, daher arbeitet es hier mit dem Skript »log2csv« in Listing 1 nur als Zubringer, indem es die Logdaten des Git-Repository in kommaseparierte Einträge wie in Abbildung 2 umformt [4].
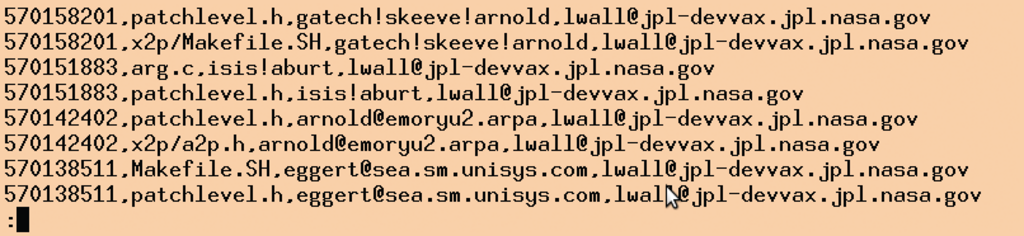
Abbildung 2: Die erzeugte CSV-Datei, die Commits in einzelne Dateien aufspaltet und die Grundlage zur statistischen Analyse in R darstellt.
Hierzu kämmt sich »log2csv« zeilenweise durch die vorher von 5 MByte auf ein halbes MByte komprimierte Logdatei »perl-git-log.txt.bz2«. Trifft es in Zeile 20 auf die Kopfzeile eines Commit, speichert es dessen Eckdaten wie den Autor des Patch, den Unix-Zeitstempel und die E-Mail-Adresse des ausführenden Committers in drei außerhalb der While-Schleife deklarierten Variablen.
Entdeckt Zeile 23 dann eine Zeile mit einem Dateivermerk (zum Beispiel »M Dateiname«), trennt sie das vorangehende Flag mittels eines regulären Ausdrucks ab und speichert den Namen der modifizierten Datei in »$file«. Die Methode »print()« des CPAN-Moduls Text::CSV in Zeile 25 reicht die durch Kommata getrennten Felder anschließend an die Ausgabedatei »perl-git-log.csv« weiter. Dort stehen dann zu jeder modifizierten Datei im Repository die Felder Autor, Committer und Zeitstempel.
Das CPAN-Modul Text::CSV (beziehungsweise die geschwindigkeitsoptimierte Version Text::CSV_XS) maskiert eventuell auftretende Sonderzeichen automatisch, damit das kommaseparierte Ausgabeformat intakt bleibt. Der Konstruktoraufruf in Zeile 9 setzt das Flag »binary«, damit sämtliche Ascii-Zeichen erlaubt sind. Die EOL-Option legt den Zeilentrenner im Ausgabeformat fest und erhält den Wert »$/« zugewiesen, also den in der jeweiligen Perl-Installation gültigen Zeilenumbruch.
Eine Testfahrt mit R
Die 8,5 MByte große CSV-Datei lässt sich nun mit dem Statistiktool R einlesen und weiterverarbeiten. Der in Abbildung 3 gezeigte Testlauf mit R illustriert, wie das Tool von der Unix-Kommandozeile aus anläuft. Nach einigen einführenden Informationen wartet der Interpreter mit dem Prompt »>« auf Eingaben.
Das obligatorische »print(“hello r”)« ruft die Print-Funktion auf, die den ihr überreichten String an die Standardausgabe weiterleitet. Zu beachten ist, dass R bei Funktionsaufrufen stets auf Klammern beharrt und am Zeilenende eines Kommandos kein Semikolon steht. Die Ausgabe des »print()«-Kommandos besteht aus einer Zeile, was R mit einem vorangestellten »[1]« anzeigt. Hier bestätigt sich gleich ein übler Verdacht: Arrays – oder “Vektoren” in R-Sprech – beginnen in R bei 1 und nicht bei 0.
Um eines der vorgestellten R-Skripte abzuspielen, dient der Aufruf »source(“testprog.r”)« im R-Interpreter, wie die dritte Eingabe in Abbildung 3 zeigt. Alternativ liegt der R-Distribution das Programm »Rscript« bei, das man als »#!/usr/bin/Rscript« an den Kopf eines ausführbaren Skripts stellen kann, damit der Kernel bei dessen Start automatisch den R-Interpreter aufruft und ihm den Programmcode zur Ausführung übergibt.

Abbildung 3: Der Testlauf mit R führt über den Aufruf der Print-Funktion und das Ausführen der Datei »testprog.r«.
Eine interaktive Interpreter-Session beendet der User mit der Funktion »q()«, woraufhin R nachfragt, ob es den aktuellen Interpreter-Status auf der Festplatte ablegen soll. Antwortet der User mit »y«, schreibt R den Wert aller bekannten Daten in ein Verzeichnis ».RData« und liest sie nach einem Neustart wieder ein, damit der User genau dort fortfahren kann, wo er vorher aufgehört hat.
Mit Daten jonglieren
Das Kommando »read.csv()« in Abbildung 4 liest die CSV-Datei in R ein. Punkte in Funktions- oder Variablennamen in R dienen lediglich der Strukturierung und haben keine syntaktische Bedeutung. Die Funktion gibt im Erfolgsfall eine Datenstruktur vom Typ Dataframe zurück, einer Art Datenbanktabelle. Die Spalten geben die Struktur vor, die Zeilen entsprechen jeweils einem Datensatz. Die Zuweisung zur Variablen »commits« erfolgt mit dem Operator »<-«, den R-Puristen dem äquivalenten »=« vorziehen, um der Verwechselung mit einem Vergleich (»==«) vorzubeugen.
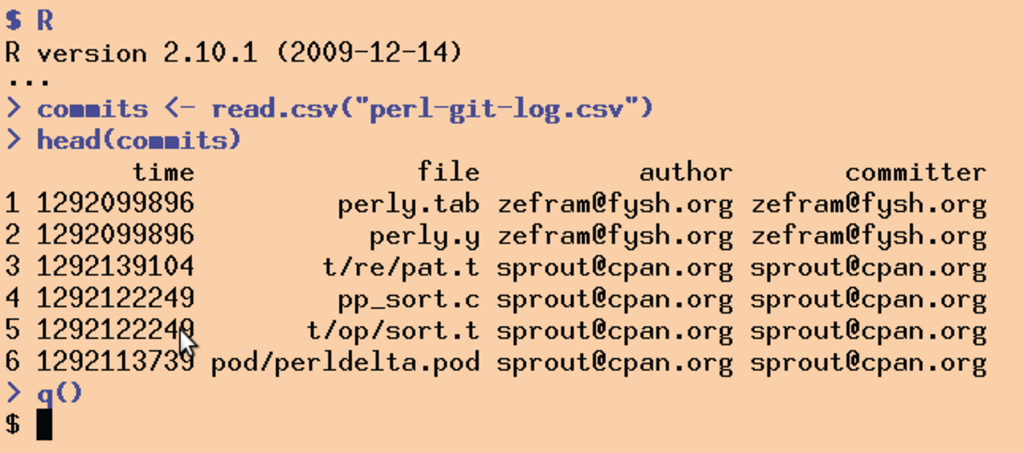
Abbildung 4: In R lässt sich die CSV-Datei leicht einlesen und in eine Datenstruktur verwandeln.
Wenn die Daten aus 23 Jahren Perl-Entwicklung nach einigen Sekunden in der Variablen »commits« liegen, gibt der Aufruf »head(commits)« (Abbildung 4) die ersten sechs Datenreihen aus. Entsprechend brächte »tail(commits)« die letzten Zeilen ans Licht. Um die Spalte »files« des Dataframe in einen Vektor zu übertragen, weist das erste Kommando in Abbildung 5 den Ausdruck »commits$file« der Variablen »files« zu.
Frequenzzähler
Die R-Funktion »table()« nimmt einen Vektor entgegen und gibt eine Datenstruktur zurück, die jedem eindeutigen Element einen Zähler zuweist, der angibt, wie oft das Element im Vektor enthalten ist:
> data=c("one", "two", "three",
"two", "one", "two")
> table(data)
data
one three two
2 1 3
Das Codestück oben zeigt außerdem, wie R mit der Funktion »c()« (von “concatenate”) einen Vektor aus Einzelelementen zusammenbaut. Die zweite Kommandozeile in Abbildung 5 setzt das eben Gelernte in einer Zeile zusammen und zeigt die am häufigsten veränderten Dateien im Repository an. Dazu klassifiziert »table(files)« die in den Commits aufgelisteten Dateien und legt für jede einen Zähler an, der die Anzahl ihrer Nennungen kumuliert.
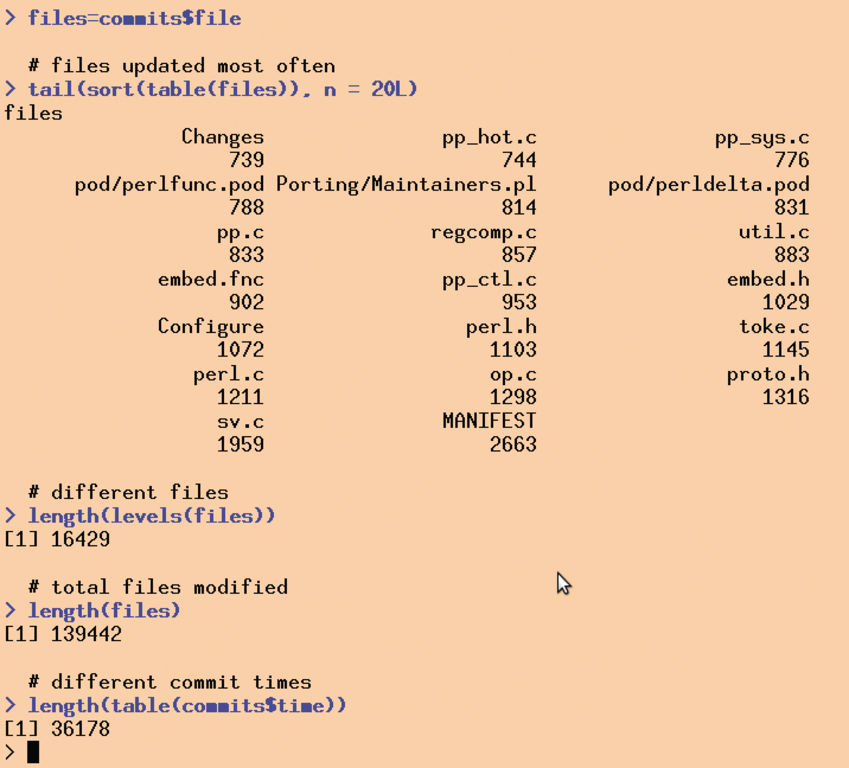
Abbildung 5: Erste Schritte in R mit den importierten CSV-Daten aus Perls Git-Repository.
Die Funktion »sort()« sortiert die »table()«-Zähler dann in aufsteigender Reihenfolge, und »tail« mit der Option »n = 20L« holt die letzten 20 Einträge, also die mit den höchsten Zählern, hervor. Wie im interaktiven R-Interpreter üblich, zeigt dieser das Ergebnis schön strukturiert an, falls der Rückgabewert einer Funktion keiner Variablen zugewiesen wurde. R verfügt außerdem über eine brauchbare Hilfefunktion, die ein Fragezeichen, gefolgt von einer Funktion (etwa »?tail«) in Marsch setzt.
Ein Bild sagt mehr
Diese kurze Einführung in R sollte genügen, um einige interessante Graphen zu zeichnen, die die Aktivitäten im Perl-Repository erhellen. Listing 2 erzeugt aus der Datenstruktur mit den 20 meistgeänderten Dateien ein Diagramm als Datei im PNG-Format. Zeile 5 bereitet die Ausgabe der nachfolgenden Plot-Funktion durch »png(file=”files.png”)« vor und leitet das Diagramm in die Datei »files.png« um. Ohne diese Zeile würde R ein Grafikfenster öffnen und das Schaubild dort ohne Umschweife anzeigen.
|
Listing 2: |
|---|
1 commits <- read.csv("perl-git-log.csv")
2 files <- commits$file
3 data=tail(sort(table(files)), n = 20L)
4 data=rev(data)
5 png(file="files.png")
6 plot(data, type="h", main="File Commits in Perl Git Repo",
7 xlab="Most modified files",
8 ylab="Number of commits per file")
|
Die ab Zeile 6 aufgerufene Funktion »plot()« aus dem R-Standardrepertoire macht klar, dass R keine ellenlangen Parameterlisten braucht, um professionell aussehende Diagramme zu zeichnen. Achsenbeschriftung, maximale und minimale Werte – für alles findet es sinnvolle Standardwerte. Dies heißt jedoch nicht, dass R unflexibel wäre, im Gegenteil, jedes Detail einer Grafik wie die Achsenform und -lage, die Werteanzahl pro Skala, Farben, Fonts und so weiter kann der User nach Gusto umdefinieren. Parameter nehmen R-Funktionen im Format »par=value«, durch Kommata getrennt, entgegen. Abbildung 6 zeigt den Dataframe »data« im Histogrammformat.
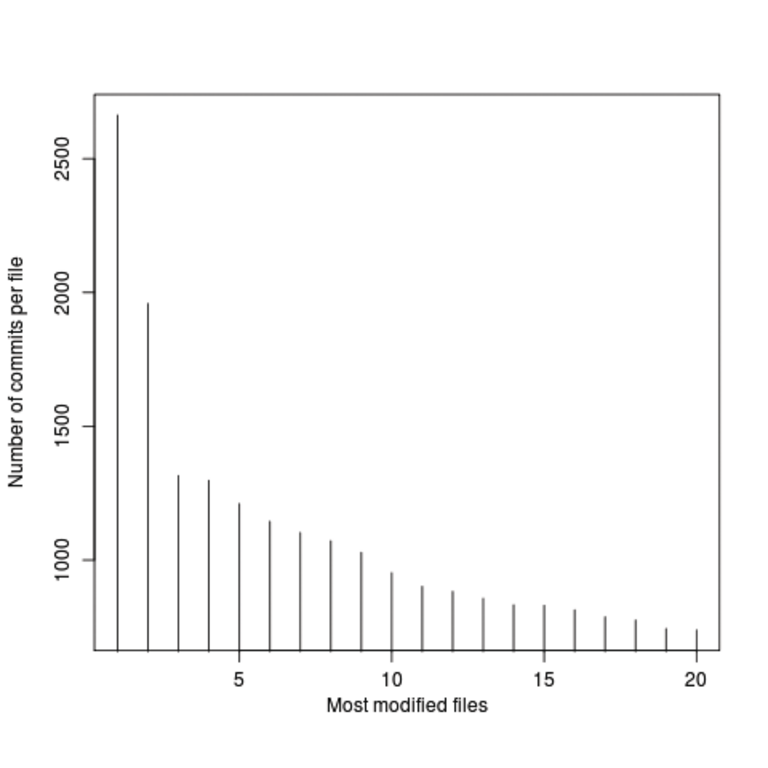
Abbildung 6: Meistmodifizierte Dateien als Histogramm.
Zahn der Zeit
Um die Aktivität im Repository über die vergangenen 23 Jahre aufzuzeigen, erweitert Listing 3 die im Unix-Sekunden-Format vorliegende Zeitstempelkolumne »commits$time« um eine neue Spalte »commits$year«, die das 4-stellige Jahr des jeweiligen Zeitstempels anzeigt. Hierzu wandelt die eingebaute R-Funktion »as.POSIXlt()« den Unix-Zeitstempel unter Angabe des Referenzdatums »1970-01-01« in den nativen Datumstyp »POSIXlt« (Posix local time) um. Aus diesem extrahiert dann die Funktion »format()« unter Angabe des Platzhalters »%Y« die vierstellige Jahreszahl des jeweiligen Datums.
|
Listing 3: |
|---|
01 commits <- read.csv("perl-git-log.csv")
02
03 commits$year <- format(
04 as.POSIXlt(
05 commits$time,
06 origin="1970-01-01"),
07 "%Y"
08 )
09
10 files.per.year <- table( commits$year )
11
12 png(file="files-per-year.png")
13 plot( files.per.year,
14 xlab="Year", ylab="Files Modified", type = "b" )
|
Wer genau hinsieht, der bemerkt, dass die Linien die eingezeichneten Datenpunkte nicht berühren, sondern kurz vorher aus- und hinterher wieder einsetzen. Dies ist ein Merkmal der Option »type=”b”«, wer durchgezogene Linien bevorzugt, nimmt »o«.
Weitere Optionen finden sich auf der Manualseite, die per Kommando »?plot« im R-Interpreter erscheint. Dort erfährt der Interessierte auch, dass »plot()« keineswegs nur »table()«-Ausgaben druckt, sondern auch mit zwei Vektoren für die X- und Y-Werte des Graphen arbeitet. Allgemein versucht R zu erraten, was der User meinen könnte, und nimmt diesem dabei oft erstaunlich viel Arbeit ab.
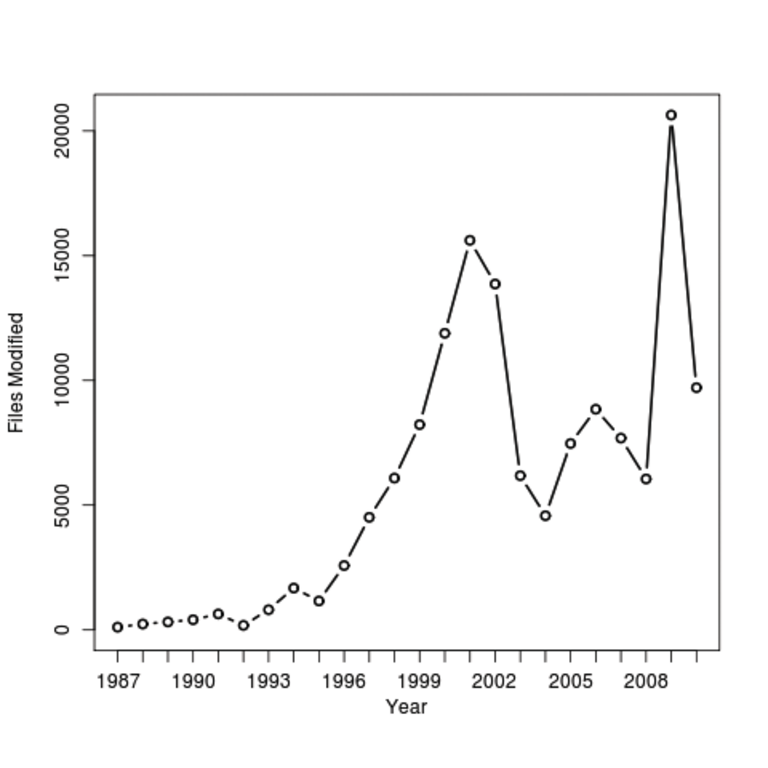
Abbildung 7: Die Grafik zeigt die Anzahl der pro Jahr modifizierten Dateien.
Ein aufwändiges Bild sagt noch mehr
Abbildung 9 zeigt die fleißigsten Perl-Autoren und ihre Aktivitäten über die im Repository erfassten 23 Jahre Perl. Da es Git 1987 noch nicht gab, wurden die Daten natürlich rückwirkend aus dem bis dahin benutzten Versionskontrollsystem eingespielt. Listing 4, dessen R-Code das Mehrfachdiagramm erzeugt, sucht zunächst die fleißigsten Autoren und merkt sich nur jene, die für mehr als 5000 File-Commits verantwortlich zeichnen. Die Funktion »subset()« erledigt dies elegant mittels »subset(au, au > 5000)« in Zeile 14.
|
Listing 4: |
|---|
01 library("lattice")
02
03 commits <- read.csv("perl-git-log.csv")
04
05 commits$year <- format(
06 as.POSIXlt(
07 commits$time,
08 origin="1970-01-01"),
09 "%Y"
10 )
11 # Authors with more than 5000
12 # file commits
13 au=table(commits$author)
14 au = sort(subset( au, au > 5000 ))
15
16 files.by.auth.year =
17 table( commits$author, commits$year )
18 files.by.auth.year =
19 as.data.frame( files.by.auth.year )
20 names( files.by.auth.year ) =
21 c("author", "year", "files")
22
23 files.by.auth.year = subset(
24 files.by.auth.year,
25 files.by.auth.year$author %in% names(au)
26 )
27
28 png(file="authors-by-year.png")
29 xyplot( files ~ year | author,
30 data = files.by.auth.year,
31 layout = c(1, 5),
32 scales = list(x = list(rot = 45)),
33 type = "l",
34 xlab = "Year",
35 ylab = "File Commits",
36 title = "Authors with > 5000 Commits"
37 )
|
Die Variable »au« ist vom Datentyp »table« mit allen Autoren aller Commits. Die als zweiter Parameter hereingereichte Bedingung filtert alle nicht darauf passenden Einträge aus. Als Spezialität von R gelten Vektoroperationen wie »au > 5000«, die nicht nur kurz und bündig, sondern auch hocheffizient Massenoperationen vornehmen.
Zeile 17 ruft »table()« mit zwei Parametern, »commits$author« und »commits$year«, auf und erzeugt damit eine Datenstruktur, die allen Kombinationen aus Autor und Jahr einen Zähler zuordnet. Zum einfacheren Zeichnen formen Zeile 18 und 19 mittels »as.data.frame()« einen Dataframe, die Zeilen 20 und 21 weisen den noch unbenannten Kolumnen durch einen linksseitigen »names()«-Aufruf die Namen »author«, »year« und »files« zu. Zu diesem Zeitpunkt enthält die Variable »files.by.auth.year« noch die Daten aller Autoren, aber die Zeile 23 extrahiert daraus die Untergruppe der vorher in »au« ermittelten fleißigsten Autoren und weist das Ergebnis wieder »files.by.auth.year« zu. Das hintere Ende des Zwischenergebnisses zeigt die Abbildung 8.
Abbildung 8: Das hintere Ende des Dataframe kurz vor dem Plotten.
Die etwas komplexe Grafik zeichnet diesmal nicht »plot()«, sondern die Funktion »xyplot()« aus der Grafik-Library »lattice«, die Zeile 1 mit »library(“lattice”)« vorher eingebunden hat [5]. Am wichtigsten ist der erste Parameter, der im Format »y ~ x | g« vorliegt, wobei »x« und »y« jeweils einen Vektor mit X- beziehungsweise Y-Werten enthalten und »g« die verschiedenen Gruppen angibt, für die jeweils ein eigenes Diagramm zu zeichnen ist. Im vorliegenden Fall weisen alle drei in den Dateframe »files.by.auth.year«, der im Parameter »data« übergeben wird. Das Layout legt mit »c(1, 5)« fest, dass pro Display fünf Diagramme übereinander liegen.
Da sich die Jahreszahlen am unteren Ende ins Gehege kämen, dreht der »scales«-Parameter sie in Zeile 32 um 45 Grad. »type=l« legt den Linientyp der Grafiken fest, »xlab« bzw »ylab« bestimmen die Achsenlegende. Jedes Panel in Abbildung 9 ist dann einem der fünf fleißigsten Autoren zugeordnet, die Liniengraphen zeigen jeweils die Anzahl der vom Committer modifizierten Dateien.
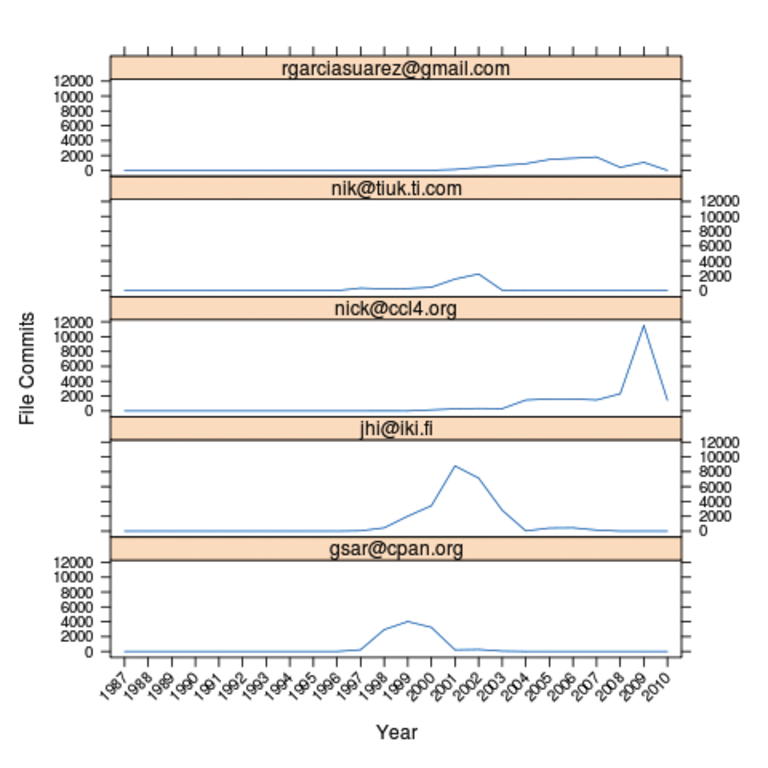
Abbildung 9: Das Diagramm zeigt die Committer mit mehr als 5000 File Commits und ihre aktiven Jahre.
Installation
Ubuntu installiert den R-Interpreter folgendermaßen:
sudo aptitude install r-base-core
Die zur Aufbereitung der Daten genutzten Perl-Module stehen ebenfalls schon fertig als »libtext-csv-perl« und »libtext-csv-xs-perl« bereit. (jcb)
|
Infos |
|---|
|
[1] Listings zu diesem Artikel: [ftp://www.linux-magazin.de/pub/listings/magazin/2011/02/Perl] [2] The R Project for Statistical Computing: [http://www.r-project.org] [3] Owen Jones, Robert Maillardet, Andrew Robinson, “Introduction to Scientific Programming and Simulation Using R”: Chapman and Hall/CRC, 2009 [4] Fun with numbers: [http://blog.moertel.com/articles/2007/06/21/talk-fun-with-numbers-r-and-perl-and-imdb-data] [5] Deepayan Sarkar, “Lattice: Multivariate Data Visualization with R (Use R)”: Springer, 2008 |
|
Der Autor |
|---|
|
|






