
© Sergey Jarochkin, 123RF.com
Die Round Trip Time (RTT) von Pings verlängert sich, wenn die Pakete Netzwerkgeräte oder lange Leitungen durchlaufen. Der Autor zeigt mit Messreihen und einem eigenen Programm, wie er damit Switches und transparente Bridges aufspürt und Kabellängen ermittelt.
Das Ping-Kommando ist jedem Linux-Anwender vertraut. Er verwendet es, um festzustellen, ob ein bestimmter Host im Netzwerk erreichbar ist und mit welcher Paketumlaufzeit, meist Round Trip Time (RTT) genannt. Gebräuchliche Ping-Programme unter Linux wie das aus dem Iputils-Paket [1] erstellen auch Statistiken mit dem RTT-Mittelwert. Allerdings schwankt dabei der Mittelwert von Tausenden Pings so stark, dass man allein damit keine Hochauflösung im Rahmen von wenigen Mikrosekunden bis Nanosekunden erhalten kann.
Dabei sind diese Feinheiten interessant, um das Netzwerk und die Geräte darin zu erkunden. Hier hilft die fachgerechte Auswertung, also das Ausfiltern von RTT-Ausreißern vor der Mittelwertberechnung, um eine Auflösung von unter einer Mikrosekunde zu erhalten. Daneben bieten einige Ping-Programme zusätzliche Features, die meist ungenutzt bleiben, beispielsweise die Möglichkeit, ein Bitmuster im Ping-Paket zu schicken und damit auch Data Rot (Datenfäule) festzustellen, also die Beschädigung von Daten im Netzwerk.
Der Artikel beschäftigt sich mit dem klassischen ICMP-Ping mit IPv4. Das meiste lässt sich aber auch auf andere Pings wie Arping [2], Httping [3] und Ipmiping [4] übertragen – im Grunde auf alles, was eine RTT ergibt, etwa der Download einer kleinen Datei mit Wget oder die Zeit für das Auslesen des USB-Registers eines USB-Adapters.
Störenfriede
Pingen im Gigabit-LAN liefert mehrheitlich annähernd Gauß-verteilte RTT-Messwerte, die vorwiegend um 200 Mikrosekunden liegen. Daneben treten aber einige Ausreißer mit sehr viel höheren Werten zu Tage, die den Mittelwert verschieben. Listing 1 zeigt ein Beispiel mit nur einem Ausreißer bei 100 Messwerten. Es stammt vom Pingen zwischen zwei vier Jahre alten PCs, der eine unter Debian mit Kernel 3.1.0-1-amd64, der andere unter Ubuntu mit Kernel 3.5.0-18-generic sowie von einem Gigabit-Switch zwischen den Rechnern.
Listing 1
Ping über Gigabit-Switch
01 [...] 02 64 bytes from 192.168.1.1: icmp_req=63 ttl=64 time=0.232 ms 03 64 bytes from 192.168.1.1: icmp_req=64 ttl=64 time=0.158 ms 04 64 bytes from 192.168.1.1: icmp_req=65 ttl=64 time=508 ms 05 64 bytes from 192.168.1.1: icmp_req=66 ttl=64 time=0.204 ms 06 64 bytes from 192.168.1.1: icmp_req=67 ttl=64 time=0.166 ms 07 --- 192.168.1.1 ping statistics --- 08 100 packets transmitted, 100 received, 0% packet loss, time 98998ms 09 rtt min/avg/max/mdev = 0.097/5.297/508.262/50.549 ms
Ein einzelner Ausreißer verschiebt hier den Mittelwert »avg« um über 1000 Prozent, von rund 0,2 auf über 5 Millisekunden. Wie mehrere Messungen zeigen, schwanken die RTT-Mittelwerte auch dann noch stark, wenn man die Anzahl der Pings (n) auf mehrere Tausend erhöht. Das geschieht, weil die Ausreißer nicht nur relativ groß sind, sondern zusätzlich so stark streuen, dass der Mittelwert auch bei n = 86400 um zirka 50 Prozent variiert.
Diese extrem hohen Ausreißer würden bei einem Pendel mit einer Schwingungsdauer von rund 1 Sekunde (Sekundenpendel) bedeuten, dass es zu 99 Prozent wirklich etwa eine Sekunde pro Schwingung benötigt, aber gelegentlich so extrem abbremst, dass es für eine Schwingung eine ganze Stunde oder länger braucht.
Hochpassfilter
Angesichts dessen liegt es nahe, einen Störfilter einzusetzen, der solche extremen Werte aussortiert. Der übliche Ansatz, den manche noch aus dem Physik-Praktikum an der Uni kennen, besteht darin, in erster Näherung eine Gaußverteilung der RTT-Messwerte (RTT) anzunehmen und jene Werte zu verwerfen, die vom Mittelwert (ohne Ausreißer) mehr als 3 * Sigma entfernt sind. Da sich solche Ausreißer nach unten hin nicht zeigen und sie zudem aufgrund der geringen Größe einen geringen Einfluss hätten, braucht man nur die Ausreißer nach oben abzuschneiden, nimmt also eine Hochpass-Filterung vor.
Da das Ping-Kommando aus dem Paket Iputils die Standardabweichung Sigma im Feld »mdev« liefert, genügen wenige Messungen mit jeweils ein paar Dutzend Pings ohne Ausreißer, um Sigma per Kommandozeile zu erhalten.
Im verwendeten Gigabit-LAN mit einem Switch, an den mehrere Rechner angeschlossen sind, zeigte sich ein Sigma um 45 Mikrosekunden. Damit empfiehlt sich das Ausfiltern von Werten oberhalb 200 + 3 * 45, also von 335 Mikrosekunden. In der Praxis sollte man zur Sicherheit etwas aufrunden, denn auch danach werden die meisten Ausreißer, die ja typisch im Bereich mehrerer 100 Millisekunden bis Sekunden liegen, noch ausgefiltert. Im Beispiel wären 400 Mikrosekunden eine gute Wahl, also das Doppelte des Mittelwerts ohne Ausreißer.
Diesen Abschneide-Wert (Cut-off) kann man auch automatisch ermitteln lassen – mittels Ausreißer-Tests oder dem Bestimmen des Werts mit der höchsten Dichte der RTT – und diesen einfach mit 2 multiplizieren. So etwas kann ein Programm mit einer kurzen Aufwärmphase vor der eigentlichen Messung automatisch erledigen.
Nach dieser Rauschfilterung zeigt sich, dass der mittlere Fehler des Mittelwerts ungefähr Sigma dividiert durch die Quadratwurzel von n beträgt, wie bei einer Gaußverteilung zu erwarten. Dadurch wird der mittlere Fehler des Mittelwerts mit wachsendem n kleiner, bei n = 100 um den Faktor 10, bei n = 106 um den Faktor 1000 und so weiter.
Für die RTT in dem gemessenen Gigabit-LAN bedeutet das, dass man sie mit einer Standardabweichung von 4,5 Mikrosekunden beziehungsweise 45 Nanosekunden erhält. Die Messung ist also so hoch aufgelöst, dass sie einen zwischengeschalteten Switch oder auch ein längeres oder kürzeres Netzwerkkabel registriert.
Das Programm Pinger
Um diese Beobachtungen in der Praxis für die Langzeitüberwachung von Netzwerkverbindungen einzusetzen, hat der Autor das Kommandozeilen-Programm Pinger [5] geschrieben. Es ruft das auf dem System installierte Ping-Executable auf, und zwar in der aktuellen Version nur einmal pro Sekunde.
Damit erreicht es im Gigabit-LAN mit dem RTT-Tagesmittel eine normalerweise ausreichende Auflösung von (bis herab zu) 153 Nanosekunden, was rund 15 Metern Kabellänge entspricht. Das 1000-Sekunden-Mittel bietet eine Auflösung von (bis herab zu) 1,5 Mikrosekunden, entsprechend einem Zwanzigstel der zusätzlichen Latenz durch einen Gigabit-Switch. Zum Überwachen von 1000 Verbindungen mit 28 Byte großen Pings braucht das C-Programm nur 2 * 28 KByte/s Bandbreite. Für eine höhere Auflösung kann der Anwender Pinger im Quelltext anpassen und schneller pingen lassen, beispielsweise jede Millisekunde.
Das Programm besteht aus einem Main-Thread, der zehn Threads startet, die in jeweils einer anderen Sekunde einen Ping abschicken und auswerten. Dazu kommen ein paar Funktionen zur Auswertung und Ausgabe. Damit sich die Pings nicht verfälschen lassen, füllt das Programm sie jeweils mit einer 128 Bit langen Zufallszahl. Zudem sind sie mit dem »don’t fragment« -Flag versehen, damit Ping sie am Stück als Paket verschickt.
Geglättet
Pinger gibt in der aktuellen Version nur die exponentiell gleitenden Mittelwerte aus. Verglichen mit den arithmetischen Mittelwerten, also denen der n letzten Messwerte, erreicht man dadurch eine wesentlich kürzere Verzögerung bei gleicher Glättung oder umgekehrt bei gleicher Verzögerung wesentlich bessere Glättung. Der Nachteil ist, dass die exponentielle Glättung alte Werte noch längere Zeit – exponentiell abklingend – mitschleppt, während die arithmetischen Mittelwerte die alten Werte nach n Messungen nicht mehr berücksichtigen.
Um kurzzeitige, mittelzeitige und langzeitige Änderungen bei der RTT und den Rückgabewerten von Ping sichtbar zu machen, erfolgt die Mittelung mit den Glättungsfaktoren 0,1 und 0,001 sowie 1/86400 für (exponentielle) 10-Sekunden-Mittel, 1000-Sekunden-Mittel und Tagesmittel. Wer möchte, kann daraus auch weitere Parameter berechnen, beispielsweise die Standardabweichung und andere Momente der Verteilungsfunktion, auf Wunsch auch geglättet.
Programmstart
Der Pinger-Quelltext [5] lässt sich mit der Kommandozeile aus Listing 2 in das Executable »pinger« übersetzen. Der Anwender startet das resultierende Programm als Root, um hohe Priorisierung zu erhalten. Es nimmt drei Parameter entgegen: die IP des Zielrechners, die Abschneide-RTT in Nanosekunden und die Netto-Ping-Größe in Byte:
Listing 2
Pinger kompilieren
01 gcc -D_REENTRANT -Wall -O3 -lm -pthread -o pinger pinger.c && strip pinger
./pinger 192.168.1.1 400000 16
Das Programm schreibt die Laufzeiten in »rtt*« -Dateien, die Return-Werte der Pings zur Fehlersuche in »retval*« -Dateien im Arbeitsverzeichnis. Zum Auswerten in Form eines 2-D-Plots dient das Gnuplot-Skript »plotting3.sh« [5]:
./plotting3.sh rtt_10s_16B_192.168.1.1.txt| gnuplot
Es aktualisiert die Anzeige sekündlich, sodass man eine laufende Messung auch live verfolgen kann.
Rückgabewerte
Das Ping-Kommando liefert neben der RTT auch einen Rückgabewert, und der nimmt allerhand Werte an, weil Pong, die Antwort auf das Ping, verschiedene Nachrichten enthalten kann. Von A für »communication with destination network administratively prohibited« bis Z für »communication with destination host administratively prohibited« . Zudem gibt es weitere Fälle wie beschädigte Daten und ICMP-Fehlermeldungen.
Die Ping-Programme unterscheiden die Fälle aber leider nicht besonders, sodass auch die ganz brauchbare Version aus dem Iputils-Paket nur drei verwendet, wie in der Manpage nachzulesen ist: “Empfängt Ping gar keine Antwortpakete, terminiert es mit Code 1. Bei anderen Fehlern terminiert es mit Code 2. In allen anderen Fällen beendet es sich mit dem Code 0.”
Da gibt es noch Optimierungspotenzial, denn wenn ein Fehler auftritt, möchte der Anwender zumindest die Fehlerart als Rückgabewert genannt bekommen. Kurz gefasst liefert das Iputils-Ping den Code 1 bei einem Timeout oder Verlust, 2 bei allen anderen Fehlern und 0, wenn das Ping ohne Fehler zurückkam. Darum lassen sich verloren gegangene Pings, etwa durch Leitungsunterbrechungen, am Rückgabewert 1 erkennen und andere Fehler an 2.
In der Praxis zeigen sich aber Abweichungen davon: Ist etwa das Netzwerk des Zielrechners nicht erreichbar, meldet Ping »Network is unreachable« und gibt als Rückgabewert 2 aus. Damit kann der Benutzer Leitungsunterbrechungen nicht richtig von anderen Fehlern unterscheiden, aber Unterbrechungen, beispielsweise zum Zwischenschalten von Spionageboxen, bewirken in jedem Fall einen Rückgabewert ungleich Null.
Erfolgsquote
Das Programm Pinger erstellt deshalb zu den Rückgabewerten ebenso wie zu den RTTs exponentiell gleitende Mittelwerte in der Einheit Prozent, sodass der Rückgabewert 0 normalerweise nahe 100 liegt und die Codes 1 oder 2 bei Fehlern wie Leitungsunterbrechungen deutlich über 0 ansteigen. Ein Vorteil gegenüber der Überwachung mit den üblichen Monitoring-Programmen wie etwa MRTG [6] ist, dass Pinger die Werte sekündlich ermittelt, während MRTG & Co. sie üblicherweise nur alle 5 Minuten (300 Sekunden) messen.
Abgesehen davon kann der Linuxer Leitungsunterbrechungen am lokalen Rechner anhand der Kernelmeldungen nachvollziehen, wie Listing 3 zeigt. Den aktuellen Status bei Ethernet erhält er mit dem Programm »ethtool« .
Listing 3
Kernelmeldungen
01 $ dmesg | grep -i eth | grep -i down 02 [1394543.075998] e1000e: eth0 NIC Link is Down
Ähnlich verhält es sich es bei anderen Rechnerkomponenten, beispielsweise bei der Tastatur, zu der es unter anderem das Timeout-Flag »0x40« auf Port »0x64« gibt – auch bei PS/2-Tastaturen, zu denen der Kernel keine Meldungen liefert.
Elektrisches
Wünschenswert wären neben diesen Informationen auch elektrische Daten, denn mit ihnen kann der Netzwerk-Admin nicht selten auch passives Leitungsanzapfen aufspüren oder Leitungsunterbrechungen genauer lokalisieren. Nur die wenigsten Netzwerkgeräte stellen sie allerdings zur Verfügung. Nur einzelne Karten mit Marvell-Chip können mit spezieller Software wie dem Marvell Virtual Cable Tester einige elektrische Daten liefern, aber die Ausgaben sind nicht sehr detailliert, sondern von der Art »Gut (Link established)« , »Fehlanpassung (Impedance Mismatch)« oder »Leitungsbruch in n Metern Entfernung« (auf zirka 1 Meter genau).
Etwas mehr zeigt die 3Com Advanced Server Control Suite zu Netzwerkkarten wie der 3Com 3C996B, zum Beispiel die Frequenzabhängigkeit der Kabeldämpfung sowie der Rückflussdämpfung, sodass man damit auch kleine Manipulationen wie den Austausch eines Kabels durch ein anderes gleicher Länge, aber mit anderen Eigenschaften, auch im Nachhinein nachweisen kann.
Switch oder Bridge aufspüren
Pinger lässt sich in der Praxis beispielsweise einsetzen, um einen Switch oder eine transparente Bridge im Gigabit-LAN aufzuspüren. Ein solches Gerät ist im Netzwerk kaum bemerkbar, weil es die Datenpakete beim Durchleiten nicht verändert. Dennoch könnte ein Angreifer damit den Datenverkehr mitschneiden (kopieren), auswerten oder manipulieren. Ein reines Mithören bleibt anhand der Daten unerkannt.
Allerdings gibt es zu Daten im Netzwerk auch Metadaten wie die Latenz einer Verbindung, und ein Switch bedeutet zusätzliche Latenz: Er ist ein Verzögerungsglied mit einer Verzögerung, die mit der Paketgröße steigt. Der Grund ist, dass er ein Datenpaket erst nach vollständigem Empfangen und Verarbeiten weiterleitet, sodass zumindest die Paketempfangszeit als längere Laufzeit erkennbar wird. Theoretisch sollte man daher mit möglichst großen und unfragmentierten Datenpaketen überwachen. In der Praxis hat sich erwiesen, dass meist schon 44 Byte große Pings genügen, wie ein Test in einem Gigabit-LAN mit Switch zeigt.
Abbildung 1 visualisiert die RTT zwischen zwei Linux-PCs. Anfänglich befindet sich zwischen den Rechnern ein Gigabit-Switch vom Typ D-Link DGS-1008D. Am Nachmittag wird er entfernt und durch einen nur 4 Zentimeter langen Adapter ersetzt. Im Diagramm sind über der Zeit die RTTs der sekündlichen Pings (in Millisekunden) aufgetragen, nach exponentieller Glättung mit dem Glättungsfaktor 0,001, was rund 1000 Sekunden-Mittelwerten entspricht. Das Fehlen des Gigabit-Switch ist an den 30 Mikrosekunden kürzeren RTTs klar zu erkennen. Dafür sind schon die tausend Pings ausreichend, die im Normalbetrieb im Hintergrund ablaufen.
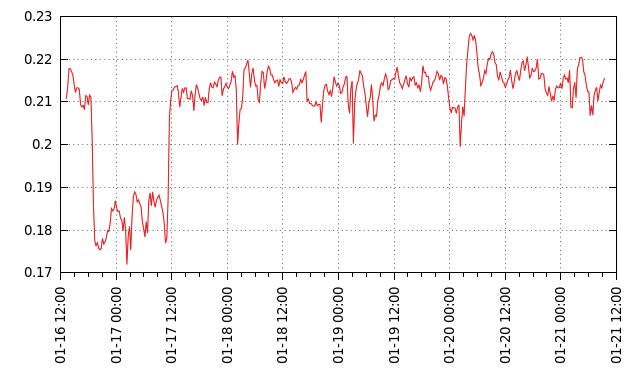
Abbildung 1: Experimentell bestimmte RTT-Mittelwerte. Der Abfall (links) trat auf, als ein Gigabit-Switch durch ein Stück Adapter ersetzt wurde.
Kurz vor 12 Uhr am Folgetag ersetzt der Autor den Adapter durch einen Netgear-Switch GS105, der die RTT schlagartig um mehr als 20 Mikrosekunden erhöht. Der Switch TP-Link TL-SG1024 dagegen zeigt im Vergleich zum Verlängerungsadapter keinen signifikanten Unterschied in der RTT, zumindest bei den 1000-Sekunden-Mittelwerten der ersten Stunden. Danach zeigt sich nur ein Anstieg um 15 Mikrosekunden.
Das bedeutet, dass dieser Switch anfänglich dem theoretischen Limit von 352 Nanosekunden Paketempfangszeit deutlich näher ist als die anderen. Hier schwanken die RTTs nur um einige Mikrosekunden, größere Ping-Pakete könnten deutlichere Ergebnisse liefern. Man benötigt aber keine Jumbo-Frames und riesige Pings, denn bereits Pings mit einer Größe von 1500 Byte erweisen sich als ausreichend. Damit beträgt die Paketempfangszeit leicht messbare 12 Mikrosekunden. Die RTT-Differenz beträgt 32 Mikrosekunden, eine Änderung von 228 Mikrosekunden auf 260 Mikrosekunden, wie die Abbildung 2 zeigt.
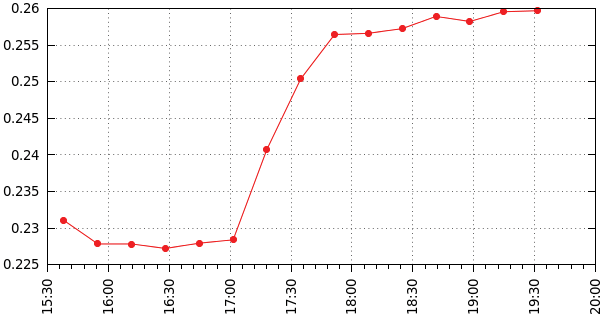
Abbildung 2: Größere Ping-Pakete offenbaren auch bei schnellen Switches bemerkbare Laufzeitverlängerungen.

Abbildung 3: Die zwei kleinen und der große Gigabit-Switch in der unteren Bildhälfte bewirken um rund 20 Mikrosekunden längere RTTs, das blaue 50-Meter-Kabel 500 Nanosekunden, das schwarze 0,5-Meter-Kabel 5 Nanosekunden und der 4 Zentimeter lange Adapter 0,2 Nanosekunden längere Laufzeiten.
Bei genauerer Betrachtung offenbart Abbildung 1 auch einen tageszeitlichen Rhythmus, weil die RTT mit dem Load Average der beteiligten Rechner und der Netzwerkauslastung ansteigt. Beispielsweise zeigt sich am letzten Messtag durch einen um 1 erhöhten Load Average auf einem der Rechner eine um 5 Mikrosekunden erhöhte RTT. Das Minimum liegt nachts zwischen 2 und 3 Uhr.
Diese Einflüsse kann man zumindest in erster Näherung einfach rausrechnen, um die Netto-RTT bei einem Load Average und einer Netzwerkauslastung von 0 zu bestimmen und deutlich genauere Werte zu erhalten. Da sich bei nahezu gleichen Tagesabläufen auch nahezu gleiche Tagesmittel ergeben, kommt dieser Fall auch ohne solche Korrekturen aus, um eine hohe Auflösung zu erreichen. Das zeigt das nächste Beispiel.
Es gibt übrigens noch Alternativen dazu, mehr Pings zu verwenden. Das Pingen mit Echtzeit-Threads, unter Linux-RT (Preemption) mit weicher Echtzeit oder unter RTAI (Realtime Application Interface) mit harter Echtzeit, liefert ebenfalls höhere Auflösungen. Eine weitere Methode besteht darin, Differenzmessungen durchzuführen, das heißt, über zwei verschiedene Verbindungen zu pingen und die Differenzen der RTT-Mittelwerte auszuwerten.
Kabellängen
Mit Laufzeitanalysen lassen sich auch unterschiedliche Leitungslängen aufspüren. Datenkabel, egal ob aus Kupfer oder Glasfaser, sind stets Verzögerungsleitungen, in denen die Signale pro Nanosekunde rund 20 Zentimeter zurücklegen. Für die RTT, also die Summe aus Hin- und Rückweg, ergibt das eine Verzögerung von etwa 10 Nanosekunden pro Meter, also für ein 50 Meter langes Kabel eine halbe Mikrosekunde.
Das ist viel weniger Latenz als durch einen Gigabit-Switch und zudem unabhängig von der Paketgröße, aber noch im Rahmen des Messbaren. Sekündliches Pingen kann anhand des Tagesmittels eine auf zirka 50 Meter genaue Lokalisierung vornehmen. Abbildung 3 zeigt die besprochenen Netzwerkkomponenten im Überblick.
Die Werte in Abbildung 4 verdeutlichen allerdings, dass die Schwankung der Tagesmittelwerte praktisch ebenso groß ist wie die zusätzliche Latenz durch ein 50 statt 0,5 Meter langes Kabel. Aufgetragen ist hier die RTT in Mikrosekunden. Nach zwei Tagen hat der Autor das 0,5-Meter-Patchkabel durch ein 50 Meter langes ersetzt, das die RTT theoretisch um 0,5 Mikrosekunden erhöht.
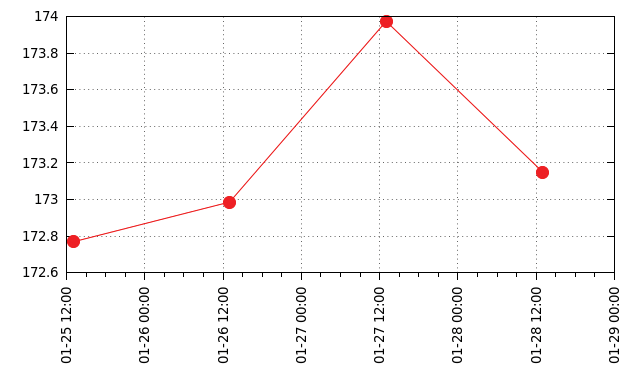
Abbildung 4: Ein rund 50 Meter längeres Ethernet-Kabel macht sich als Berg in der RTT-Kurve bemerkbar.
Mit dem 49,5 Meter längeren Kabel zeigt sich daher eine um 0,5 Mikrosekunden erhöhte RTT. Für die ersten beiden Tage mit 0,5 Metern ergibt sich eine mittlere RTT von 172,877 Mikrosekunden, für die letzten beiden mit 50 Metern eine von 173,562 Mikrosekunden, also um 685 Nanosekunden mehr.
Die Tagesmittelwerte schwanken deutlich, auch aufgrund der nicht konstanten Auslastung der Rechner und durch Dutzende Programme wie Ktorrent, Tor, I2P, GNU Net, Squid 3, DHCP, NTP, Kaffeine und Firefox. Der Nachweis solcher kleinen RTT-Änderungen bedarf der Mittelung mehrere Tagesmittel, wenn man nur sekündlich pingt.
Da bei Ethernet ein Segment (Kollisionsdomäne) maximal 100 Meter lang sein darf und meist deutlich kürzere Segmente verwendet werden, sind in der Praxis zumindest 100 Meter Auflösung problemlos erreichbar – schon mit 1000-Sekunden-Mittelwerten.
Durch die Lüfte
Beim WLAN sind die Messungen im Prinzip ebenso durchführbar wie im Gigabit-LAN. Allerdings zeigt sich bei der Mehrheit der WLAN-Router und Endgeräte das Problem, dass sie die Datenrate (Bandbreite) automatisch regeln, und entsprechend schwankt auch die RTT. Bei den meisten Routern lässt sich das nicht abstellen, viele zeigen die Datenrate nicht einmal an. Unter Linux darf der Admin die Datenrate beim WLAN wie folgt einstellen:
iwcofig wlan4 rate 24M fixed
Das ändert aber nichts an der Rate des Routers. Es bleibt dem neugierigen Admin also nichts anderes übrig, als darauf zu achten, dass die vom Router angezeigte Rate während des Messens konstant bleibt.
Der zweite Unterschied zum LAN liegt in der Signalgeschwindigkeit, die mit rund 30 Zentimetern pro Nanosekunde um 50 Prozent höher ist als im Kabel. Die gemessenen 1000-Sekunden-Mittelwerte lagen bei 0,7 Metern Distanz und mit zwei 30-dB-Abschwächern bei 0,985108 Millisekunden, die aus 2,5 Kilometern Entfernung gemessenen bei 1,023676 Millisekunden, also um 38,6 Mikrosekunden deutlich höher (Abbildung 5).

Abbildung 5: RTT-Messung mit einem WLAN-Router neben einem blinkenden Headlight in 2,5 Kilometern Entfernung (Pfeil) und einer darauf gerichteten 50-Zentimeter-Yagi-Antenne.
Theoretisch sollte die Differenz nur 16,7 Mikrosekunden betragen, also deutlich weniger. Hier sind offenbar noch andere Faktoren im Spiel, etwa vom Router nicht angezeigte Ratenschwankungen oder die Temperatur, denn diese lag bei 2,5 Kilometern Distanz um -2° C, während es bei 0,7 Metern Distanz 20° C waren.
Daneben hat der Autor auch getestet, ob er mit einem Linux-PC statt WLAN-Router und Ad-hoc-Modus ebenso messen kann. Hier ließen sich beide Senderaten festsetzen. Wider Erwarten zeigten sich dabei aber um den Faktor 4 stärkere Schwankungen als beim Pingen mit dem WLAN-Router.
Kommentar: Originell – aber praxistauglich?

Jens-Christoph Brendel, Redakteur bei der Medialinx AG.
Es ist ohne Zweifel eine originelle Idee, das Monitoring auf Ping-Laufzeiten zu gründen. Zudem wird die Idee vermutlich auch funktionieren – im Labor. In der Praxis scheinen sich aber doch ein paar Hürden aufzutürmen, die sicherlich nicht leicht übersprungen werden können. Welche Hürden sind das?
Die Schwankungen in der Ping Roundtrip Time, die auf das Konto unterschiedlich ausgelasteter Server gehen, können durchaus größer sein als die Laufzeitunterschiede, die zum Beispiel ein eingeschmuggelter zusätzlicher Router verursachen würde. Das müsste zu Fehlalarmen führen – es sei denn, man setzt die Triggerschwelle so hoch an, dass nie mehr eine Auffälligkeit detektiert würde.
Der Autor schlägt vor, die mittlere Serverauslastung herauszurechnen. Aber damit kommt man in gewissem Sinn vom Regen in die Traufe: Man subtrahiert dann von einer künstlich geglätteten Umlaufzeit (einer Art Mittelwert) einen anderen Mittelwert, nämlich den Durchschnitt des Tagesgangs der Lastkurve. Aber jeder Mittelwert vernichtet Information, in diesem Fall weil auch die Varianz unter den Tisch fiele. So ergibt sich ein stark idealisierter und viel zu enger Wertekorridor, der den in der Realität möglichen Ausprägungen nicht entspricht und mit etlichen Nachkommastellen bei der Zeitmessung eine Exaktheit vorspiegelt, die nicht gegeben ist.
Hinzu kommt ein weiterer Aspekt: Das ICMP-Testprogramm Ping verrät nicht nur, ob ein Netzwerkgerät unter einer bestimmten Adresse erreichbar ist, sondern es erlaubt darüber hinaus eine Art Fingerprinting, das Rückschlüsse beispielsweise auf das Betriebssystem zulässt. Damit liefert es potenziellen Angreifern unter Umständen wertvolle Informationen. Administratoren, die diese nicht offenbaren möchten, verbieten ICMP-Echo-Replys per Firewallregel. Das schließt dann auch das im Artikel beschriebene Monitoring aus.
Schneller messen
Wer nur kurze Messungen durchführen kann oder möchte, passt das Programm Pinger an, um entsprechend viele Pings pro Sekunde loszuschicken statt nur eines einzigen. Hierzu braucht er im Quelltext nur ein kleineres Zeitraster einzustellen, beispielsweise 1 Millisekunden für eine um den Faktor 32 höhere Genauigkeit, und entsprechend mehr Threads. Da die Zeiten der Threads eine Auflösung von einer Mikrosekunde haben, ist dafür jedoch nicht viel umzustellen.
Neben dem Ansatz, Netzwerklatenzen mit Pings zu bestimmen, ist es auch möglich, Zeitstempel auszuwerten. Beim WLAN eignen sich die TSF-Zeitstempel, denn sie besitzen eine Auflösung von 1 Mikrosekunde und sind sogar Jitter-frei. Allerdings ist nicht jede Hardwareplattform dafür geeignet [7].
Ausblick
Das Messen der Netzwerklatenz mit Pings zeigt, dass es hier noch einiges Potenzial gibt, das bisher erstaunlicherweise ungenutzt blieb. Angriffe wie das Mithören von Mobilfunk-Telefonaten mittels zwischengeschalteter IMSI-Catcher wären damit leicht, unauffällig und praktisch kostenlos aufspürbar, selbst wenn sie mit anderen Tools wie Traceroute nicht zu entdecken sind. Zudem kann man mit Pings eine grobe Lokalisierung durchführen oder umgekehrt Kabellängen bestimmen. Misst man die Abhängigkeit der RTT von der Paketlänge, lässt sich zwischen der Latenz durch Kabel oder Distanzen und der durch Geräte wie Switches unterscheiden.
Im Prinzip können Angreifer Pings auch verfälschen, indem sie sie kopieren und mit gewünschter Verzögerung zurückschicken, oder sie filtern das Pong vom Zielrechner aus, um sich zu tarnen. Das ist aber wenig sinnvoll, da das Kopieren, Berechnen und Zurückschicken zusätzlichen Aufwand erfordert und es außerdem praktisch unmöglich ist, alle möglichen Arten von Pings zu manipulieren.
Wer sich vor Fälschungen schützen möchte, könnte mit einem verschlüsselten Zeitstempel pingen. Auf dem Zielrechner speichert er Datum und Zeit verschlüsselt in der Datei »foo.bar« , überträgt sie mit einem Ping der Art
time wget ftp://10.45.67.89/tmp/foo.bar
und überprüft, ob sie mit dem richtigen Schlüssel verschlüsselt wurde und die aktuelle Zeit enthält. (mhu)
Infos
- Linux Iputils: http://www.skbuff.net/iputils/
- Arping: http://www.habets.pp.se/synscan/programs.php?prog=arping
- Httping: http://www.vanheusden.com/httping
- Ipmiping: http://www.gnu.org/software/freeipmi/
- Pinger und Plotting-Skript: https://sslsites.de/www.true-random.com/homepage/projects/pinger/
- MRTG: http://oss.oetiker.ch/mrtg/
- Mario Haustein, “Lokalisierung durch Messung von WLAN-Signallaufzeiten”: Vortrag 2011, http://chemnitzer.linux-tage.de/2011/vortraege/653





