
© Bernardo Ertl, 123RF
Mathematische Rätsel mit bedingten Wahrscheinlichkeiten knackt der Fachmann mit der Bayes-Formel oder auch mit diskreten Verteilungen – erzeugt von kurzen Perl-Skripten.
Das bei Statistikern gut bestallte Ziegenproblem [2] eignet sich bestens, um mehr praktisch als mathematisch Begabte reihenweise zu blamieren – besonders wenn sie leidenschaftlich gegen die richtige Lösung wettern. Im Kern geht es um eine Spielshow, bei der ein Kandidat auf eine Tür deutet und der Moderator eine Tür öffnet, hinter der entweder eine Ziege oder ein Gewinn wartet (Abbildung 1). Wer hätte gedacht, dass sich Wahrscheinlichkeiten in offensichtlich festgezimmerten Fernsehstudios dramatisch ändern, nur weil der Moderator eine Tür ohne Preis öffnet?
Das menschliche Gehirn scheint sich schwer zu tun mit so genannten bedingten Wahrscheinlichkeiten, die zufällige Ereignisse mit Vorbedingungen beschreiben. So auch bei der schon vor 15 Jahren im Perl-Snapshot [3] gestellten Aufgabe: Gegeben ist ein Zylinder, in dem drei Karten liegen. Die erste ist vorne und hinten schwarz, die zweite vorne und hinten rot, die dritte auf der einen Seite schwarz und auf der anderen rot (Abbildung 2). Eine Karte wird gezogen. Man sieht die Vorderseite, die ist rot. Wie hoch ist die Wahrscheinlichkeit, dass auch die Rückseite der gezogenen Karte rot ist?
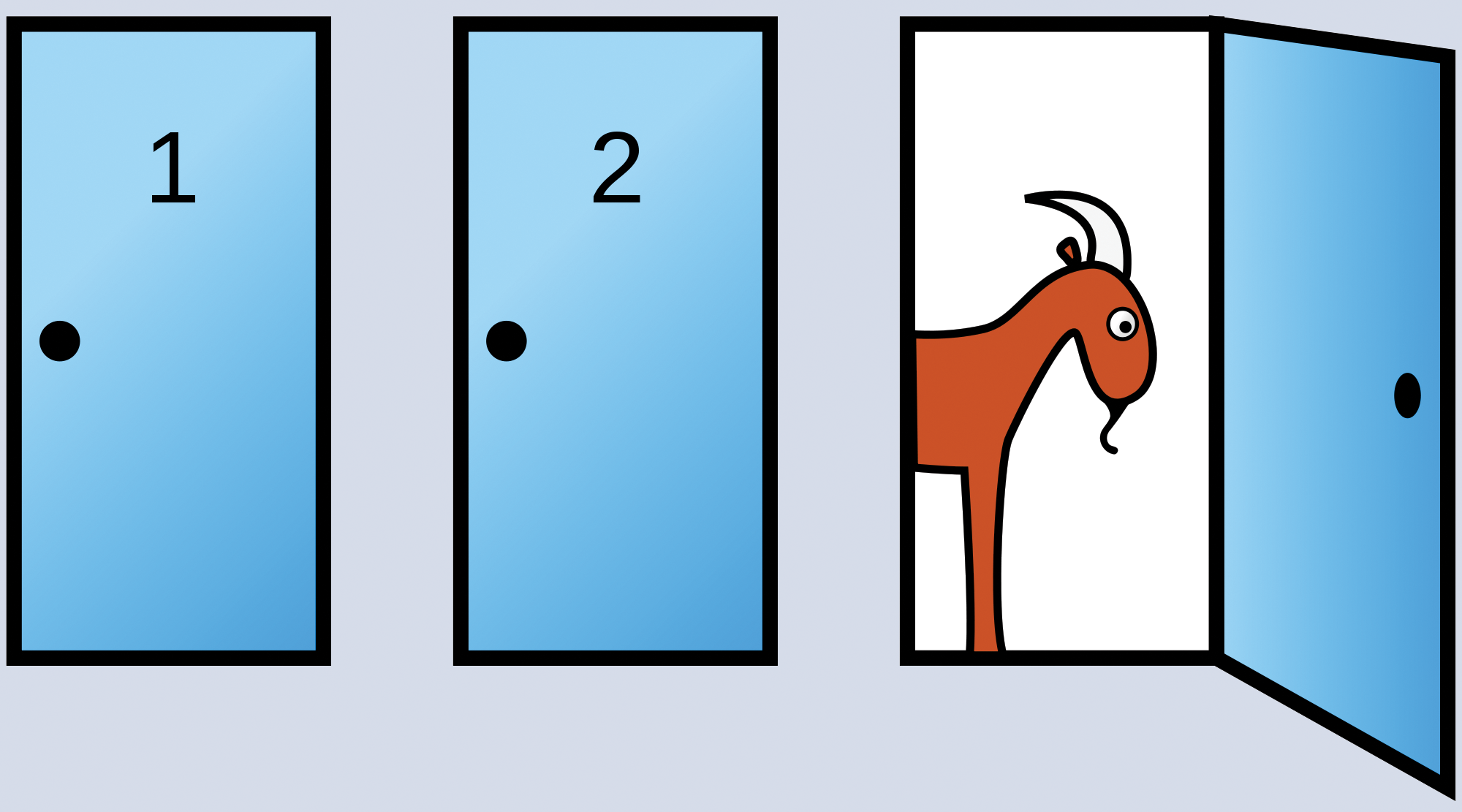
Abbildung 1: In der Hoffnung, das Auto zu gewinnen, wählt der Kandidat die Tür 1. Der Showmaster, der weiß, hinter welcher Tür das Auto steht, öffnet daraufhin Tür 3, hinter der eine Ziege steht. Er bietet dem Kandidaten an, die Tür zu wechseln. Ist es vorteilhaft für den Kandidaten, seine erste Wahl zu ändern und sich für Tür 2 zu entscheiden? (Quelle: Wikipedia)

Abbildung 2: Aus einem Zylinder mit einer schwarz-roten, einer schwarz-schwarzen und einer rot-roten Karte zieht ein Proband eine Karte.
Online PLUS
In einem Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/2014/07/plus
Kontra-intuitiv
Die meisten Leute antworten darauf mit “50 Prozent”, denn scheinbar gibt es zwei gleich wahrscheinliche Fälle, die rot-schwarze und die rot-rote Karte, und einmal ist die Kehrseite schwarz und einmal rot. Verrät der Kundige dem Zuhörer aber dann, dass die korrekte Lösung “66 Prozent” lautet, reagieren die meisten verblüfft. Der Kniff liegt in den Vorbedingungen des Experiments: Die rot-rote Karte zählt einfach doppelt im Vergleich zur rot-schwarzen, weil sie die Vorbedingung des Experiments “Eine Seite ist rot” doppelt erfüllt.
Schon vor 250 Jahren hatte sich der Mathematiker Thomas Bayes bemüht, solche intuitiv fehlerträchtigen Probleme in eine Formel zu fassen, an der sich nicht rütteln lässt. Der “Satz von Bayes” [4] beschreibt in seiner “diachronischen Interpretierung”, wie sich die Wahrscheinlichkeiten von Hypothesen im Lauf der Zeit verändern, falls in einem Experiment neue Daten auftauchen. Die Formel
P(H|D) = P(H) * P(D|H) / P(D)
definiert die Wahrscheinlichkeit P einer Hypothese H, zum Beispiel “Ich habe die rot-rote Karte gezogen”, in Abhängigkeit von neu auftauchenden Daten D wie “Die Vorderseite der gezogenen Karte ist rot” (Abbildung 3).
Auf der rechten Seite der Gleichung ist P(H) die Ausgangswahrscheinlichkeit der Hypothese, noch bevor neue Daten vorliegen. Bayes multipliziert sie mit P(D|H), also der Wahrscheinlichkeit, dass die Daten unter der Hypothese vorliegen. Wie wahrscheinlich ist es dann, dass der Kartenfreund tatsächlich auf eine rote Vorderseite blickt, falls er die rot-rote Karte gezogen hat?
Im Nenner der rechten Seite steht schließlich mit P(D) die Wahrscheinlichkeit der vorliegenden Daten, unabhängig von irgendeiner Hypothese. Wie wahrscheinlich ist es, dass der Proband nach dem Ziehen irgendeiner Karte auf eine rote Vorderseite starrt?

[4])” width=”300″ height=”97″ />
Abbildung 3: Der Satz von Bayes definiert die Wahrscheinlichkeit einer Hypothese in Abhängigkeit von neu auftauchenden Daten. (Quelle: Wikipedia, [4])Bayes weiß es besser
Alle drei möglichen Hypothesen – zufällig gezogene Karten – sind in diesem Experiment offensichtlich gleich wahrscheinlich. Also ist P(H) – die Wahrscheinlichkeit, dass die rot-rote Karte gezogen wird – gleich 1/3, denn sie wird in einem Drittel aller Fälle gezogen. Bei Annahme dieser Hypothese ist die Kehrseite der gezogenen rot-roten Karte trivialerweise in exakt 100 Prozent aller Fälle ebenfalls rot, also ist P(D|H) = 1.
Unabhängig von der Hypothese einer gezogenen Karte ist die Wahrscheinlichkeit, nach dem Ziehen auf eine rote Kartenoberseite zu blicken, 50 Prozent, ergo ist P(D) = 1/2. Schließlich liegen im Zylinder sechs Kartenhälften, von denen drei rot und drei schwarz sind. In die Bayes-Formel eingesetzt ergibt sich für P(H|D) entsprechend 1/3 * 1/(1/2) = 2/3. Die Bayes-Formel sagt also mit 66 Prozent das im Experiment nachweisbar korrekte Ergebnis voraus und widerlegt die Intuition.
Wahrscheinlichkeit, diskret programmiert
Das etwa ein halbes Jahr alte Buch “Think Bayes” [5] beschreibt zusätzlich zur Bayes-Formel ein numerisches Verfahren, das sich zum Experimentieren leicht in handliche Skripte fassen lässt. Dazu legt man die Hypothesen in einer statistischen Verteilung ab, speichert sie also in einem Python-Dictionary oder Perl-Hash mit ihren Ausgangswahrscheinlichkeiten, multipliziert dann die Einzelwerte mit den bedingten Wahrscheinlichkeiten eintreffender Daten unter Annahme der jeweiligen Hypothese und normalisiert die Werte für alle Hypothesen.
Heraus kommt die Wahrscheinlichkeit der gesuchten Hypothese im Lichte neu eingetroffener Daten. Dieses Verfahren und speziell die abschließende Normalisierung funktionieren allerdings nur dann, wenn
- höchstens eine der Hypothesen wahr ist und
- es keine weiteren Möglichkeiten gibt, also mindestens eine der Hypothesen wahr ist.
Listing 1 zeigt die Implementierung des Skripts »cards« , das zuletzt die gesuchte Lösung 0,666… ausgibt. Es nutzt das Modul »Distrib.pm« (Listing 2), das die Hilfsfunktionen zur Berechnung der statistischen Verteilung bereitstellt. Die Wahrscheinlichkeiten für die Hypothesen bei der Ziehung verschiedener Karten (»BB« , »BR« , »RR« für black-black, black-red, red-red) füttern die Zeilen 7 bis 9 von mit jeweils dem Wert 1/3 ins Modul.
Die hinzugekommenen Daten, also die Oberseite der tatsächlich gezogenen Karte, geben die Zeilen 11 bis 13 von Listing 1 für jede Hypothese vor und multiplizieren die eingespeisten Hypothesenwerte damit. So ist die Wahrscheinlichkeit, dass der Proband eine rote Oberseite erblickt, bei der schwarz-schwarzen Karte gleich Null. Bei der schwarz-roten Karte beträgt sie 50 Prozent, je nachdem, wie herum die Karte aus dem Zylinder herauskommt. Und die rot-rote Karte präsentiert ihm in 100 Prozent der Fälle eine rote Seite, weshalb Zeile 13 den Multiplikator auf den Wert 1 setzt.
Abschließend gibt der Aufruf der Methode »prob(“RR”)« die normalisierte Wahrscheinlichkeit für die Hypothese “rot-rote Karte” zurück, die 2/3 beträgt.
Listing 1
cards
01 #!/usr/local/bin/perl -w 02 use strict; 03 use Distrib; 04 05 my $distrib = Distrib->new(); 06 07 $distrib->set( "BB", 0.33 ); 08 $distrib->set( "BR", 0.33 ); 09 $distrib->set( "RR", 0.33 ); 10 11 $distrib->mult( "BB", 0 ); 12 $distrib->mult( "BR", 0.5 ); 13 $distrib->mult( "RR", 1 ); 14 15 $distrib->normalize(); 16 17 print $distrib->prob( "RR" ), "\n";
Moose im vorliegenden Fall nur ein Gimmick
Listing 2 nutzt das CPAN-Modul Moose, um sich die Definition des Distrib-Konstruktors in Perl zu ersparen. Allerdings muss der Code stattdessen mit »has« die Klassenattribute deklarieren und initialisieren. Im vorliegenden Fall nur ein netter Gimmick, bei weiteren Attributen wäre der Code deutlich schlanker als bei manueller Klassenfahrt.
Die Methode »set()« nimmt den Namen einer Hypothese (zum Beispiel »BB« ) und deren A-priori-Wahrscheinlichkeit entgegen und speichert sie in dem Objekt-internen Array »values« . Zum Multiplizieren eines Hypothesenwerts mit einem konstanten Wert bekommt »mult()« beide übergeben, findet den bislang gespeicherten Wert in »values« und multipliziert diesen mit dem hereingereichten Wert für »$prob« .
Die Methode »normalize()« iteriert über alle bislang eingespeisten Werte im Hash, summiert sie in »$sum« und dividiert dann alle Werte durch die Summe. So beträgt die neue Summe aller Wahrscheinlichkeitswerte zum Beispiel nach einer Multiplikation wieder 1. Jeder Wert lässt sich somit als Wahrscheinlichkeit zwischen 0 und 1 interpretieren. Am Ende findet »prob()« den Wert für eine gesuchte Hypothese, indem es den Werte-Hash mit der von Moose automatisch erzeugten Methode »values()« als Referenz hervorholt und unter dem Schlüssel der gesuchten Hypothese den dort abgelegten Wert extrahiert.
Listing 2
Distrib.pm
01 use Moose;
02
03 has 'values' => (is => 'rw', isa => 'HashRef',
04 default => sub { {} } );
05
06 sub set {
07 my( $self, $hypo, $prob ) = @_;
08
09 $self->values()->{ $hypo } = $prob;
10 }
11
12 sub mult {
13 my( $self, $hypo, $prob ) = @_;
14
15 $self->values()->{ $hypo } *= $prob;
16 }
17
18 sub normalize {
19 my( $self ) = @_;
20
21 my $values = $self->values();
22 my $sum = 0;
23
24 for my $hypo ( keys %$values ) {
25 $sum += $values->{ $hypo };
26 }
27 for my $hypo ( keys %$values ) {
28 $values->{ $hypo } /= $sum;
29 }
30 }
31
32 sub prob {
33 my( $self, $hypo ) = @_;
34
35 return $self->values()->{ $hypo };
36 }
37
38 1;
Abstrakter geht’s auch
Wer mehrere solcher Tests für verschiedenartige Probleme durchführt, erkennt das Muster: Nach dem Aufsetzen der Hypothesen werden die Wahrscheinlichkeiten zusätzlicher Daten stets mit allen definierten Hypothesen multipliziert. Es bietet sich darum – wie in [5] vorgemacht – an, eine von »Distrib« abgeleitete Musterklasse »HypoTest« ähnlich wie Listing 2 zu definieren, die mittels einer Methode »update()« die Werte für alle Hypothesen auffrischt.
Weiter verlässt sie sich darauf, dass wiederum von ihr abgeleitete Klassen (beispielsweise »CardHypoTest« in Listing 4) die abstrakte Methode »likelihood()« überladen und basierend auf der übergebenen Hypothese und den zusätzlich verfügbaren Daten die Wahrscheinlichkeit P(D|H) zurückgeben.
Das in Listing 3 vorgestellte Framework »HypoTest« ruft diese Methode wiederholt auf, um die Werte für einzelne Hypothesen einzuholen, bevor es sie in der Verteilung »Distrib« setzt. Das Framework bietet weiterhin eine Methode »print()« , mit der es die Werte aller aktualisierten Wahrscheinlichkeiten für die jeweilige Hypothese ausgibt.
Listing 3
HypoTest.pm
01 package HypoTest;
02 ###########################################
03 # Hypotest - Testing hypotheses
04 # 2014, Mike Schilli <m@perlmeister.com>
05 ###########################################
06 use Moose;
07 use Distrib;
08
09 has 'distrib' => (
10 is => 'rw',
11 isa => 'Distrib',
12 default => sub { Distrib->new() } );
13
14 sub hypo_add {
15 my( $self, $hypo ) = @_;
16
17 $self->distrib()->set( $hypo, 1 );
18 }
19
20 sub update {
21 my( $self, $data ) = @_;
22
23 my $hypos = $self->distrib()->values();
24
25 for my $hypo ( keys %$hypos ) {
26 $self->distrib()->mult( $hypo,
27 $self->likelihood( $data, $hypo )
28 );
29 }
30
31 $self->distrib()->normalize();
32 }
33
34 sub print {
35 my( $self ) = @_;
36
37 my $values = $self->distrib()->values();
38
39 for my $hypo ( keys %$values ) {
40 print "$hypo: $values->{ $hypo }\n";
41 }
42 }
43
44 sub likelihood {
45 die "Subclass needs to override this";
46 }
47
48 1;
Der Hypotest
In Listing 4 nimmt »likelihood()« in »$data« vom Hauptprogramm den Buchstaben R entgegen – um eine gezogene Karte mit roter Vorderseite als Zusatzbedingung anzumelden – und rechnet dann basierend auf der ebenfalls hereingereichten Hypothese (»RR« , »RB« , »BB« ) aus, wie wahrscheinlich es ist, dass der Proband auf eine rote Vorderseite blickt: Eine glatte 1 (also 100 Prozent) für »RR« , 0,5 für »RB« und 0 für »BB« .
Die Funktion setzt dazu einen regulären Ausdruck ab, der die Anzahl der Rs in der Hypothese zählt, und dividiert das Ergebnis anschließend durch 2 als Fließkommawert, damit Perl keine Integerdivision vornimmt und den Divisionsrest unterschlägt.
Am Ende gibt »hypotest« die Wahrscheinlichkeiten für alle Hypothesen in der Verteilung mittels der Methode »print()« aus dem Modul »HypoTest« an und berichtet zu Recht, dass die rot-rote Karte in 2/3 aller Fälle erscheint:
$ ./hypotest RB: 0.333333333333333 RR: 0.666666666666667 BB: 0
Damit sieht der Proband, der gerade auf eine rote Vorderseite blickt und diese Karte umdreht, mit 2/3 Wahrscheinlichkeit eine ebenso rote Rückseite.
Listing 4
hypotest
01 #!/usr/local/bin/perl -w
02 use strict;
03 package CardHypoTest;
04 use base qw( HypoTest );
05
06 sub likelihood {
07 my( $self, $data, $hypo ) = @_;
08
09 # count the number or Rs in the string
10 my @matches = ( $hypo =~ /($data)/g );
11 return @matches / 2.0;
12 }
13
14 package main;
15 my $suite = CardHypoTest->new();
16
17 $suite->hypo_add( "RR" );
18 $suite->hypo_add( "BB" );
19 $suite->hypo_add( "RB" );
20
21 $suite->update( "R" );
22 $suite->print();
Paarhufer, fassungslos
Was mit Ziegen hinter Türen begann, endet mit der Erkenntnis, dass sich einfache Skripte für mathematisch fundierte Folgerungen eignen. Selbst wer beim Anblick einer Formel in Ohnmacht fällt, kommt auf seine Kosten und lernt dank weiterer Beispiele in [5] oder [6] (zwar in Python und nicht in Perl), dass statistische Alltagsprobleme mit Lösungen aufwarten, die intuitiv nicht zu erfassen sind.
Infos
- Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2014/07/Perl
- Ziegenproblem: http://de.wikipedia.org/wiki/Ziegenproblem
- M. Schilli, “Perl-Snapshot: Monty-Hall und andere Probleme”: Linux-Magazin 09/99
- Satz von Bayes: http://de.wikipedia.org/wiki/Satz_von_Bayes
- Allen B. Downey, “Think Bayes”: O’Reilly, 2013
- Cameron Davidson-Pilon, “Probabilistic Programming & Bayesian Methods for Hackers”: https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers
Der Autor

Michael Schilli arbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. In seiner seit 1997 erscheinenden Kolumne forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





