
© Buchachon Petthanya, 123RF
Die Graphdatenbank Neo4j eignet sich viel besser als relationale Datenbanken, um Knoten und deren Beziehungen zueinander zu speichern und gezielt abzufragen. Wessen Freundeskreis nicht verworren genug ist, um als Graph-basierter Anwendungsfall durchzugehen, inventarisiert eben sein LAN damit.
Konstrukte wie der Social Graph von Facebook, der Verbindungen von Freunden und deren Bekanntschaften abbildet, oder die Follower-Struktur von Twitter sträuben sich hartnäckig, wenn es darum geht, ihre Daten persistent in traditionelle Datenbanken zu packen: Überführt man einen Pfad, der sich auf einem Whiteboard sehr einfach mit Kringeln und Pfeilen darstellen lässt, in ein relationales Modell, kommen Performance fressende Join-Anweisungen heraus – was sich mit den Anforderungen an eine schnell antwortende Website beißt.
Die Graphdatenbank Neo4j [2] dagegen speichert Graphmodelle nativ und legt dabei eine sagenhafte Performance hin – solange man es mit der Komplexität der Queries nicht übertreibt. Ihr generisches Speichermodell besteht aus Nodes (Knoten) mit Relationships (Kanten). Beide dürfen Attribute führen, so könnte ein Node, der eine Person repräsentiert, ein »name« -Feld zum Speichern des Namens enthalten oder eine Beziehung »is_friends_with« und deren Gütegrad (»best_friend« , »casual_friend« ).
Online PLUS
In einem Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/news/der-perl-screencast-zum-linux-magazin-2014-06/
Abfragesprache Cypher
Die in der Datenbank liegenden Daten nimmt der Query-Prozessor von Neo4j in der SQL-ähnlichen Sprache Cypher entgegen und liefert reihenweise Ergebnisse, die Cypher ebenfalls im Stile von SQL filtert und aufbereitet (also sortiert, gruppiert et cetera).
Nach dem Installieren des GPL-lizenzierten Neo4j-Community-Servers (eine kostenpflichtige Enterprise-Version gibt’s auch) lauscht dieser auf Port 7474 auf Kommandos, die entweder über REST eingehen oder den neueren simplen Json-Prozessor nutzen. Programmieren lässt sich ein Client in mehreren Dutzend Sprachen, unter anderem mit dem CPAN-Modul REST::Neo4p.
Dem auf [2] angebotenen Debian-Paket liegt darüber hinaus eine praktische Kommandoshell bei: »neo4j-sh« . Mit ihr kann jedermann ähnlich wie mit dem interaktiven MySQL-Client Anweisungen absetzen, um neue Daten in das Modell einzufügen und gespeicherte Informationen über Cypher-Queries zu extrahieren.
Mächtig deklarativ
Cypher gibt sich, ähnlich wie SQL, deklarativ: Der User bestimmt, welche Ergebnisse er sucht, macht aber zugleich keine prozeduralen Angaben darüber, wie diese genau zu finden sind. Match-Anweisungen bestimmen, welche Daten interessieren (beispielsweise “Finde alle Daten” oder “Finde alle Relationen vom Typ »is_friends_with« ). Where-Klauseln reduzieren anschließend die Anzahl der Treffer, zum Beispiel könnten den anfragenden User nur Personen interessieren, die älter als 18 Jahre sind.
Am Ende modeln später einsetzende Aufbereitungsschritte die Daten um, sortieren oder fassen sie zusammen. Aber auch weitere Match-Anweisungen auf die Ergebnisliste und sogar zwischendurch einsetzende Aktionen zum Erzeugen neuer Daten sind erlaubt.
Zur Illustration einiger praktischer Abfragen soll der Graph eines Heimnetzwerks in Abbildung 1 dienen. Netze mit Knoten und Verbindungskanten stellen tatsächlich ein beliebtes Aufgabenfeld für Neo4j dar. Denn um festzustellen, ob ein Router über andere Knoten problemlos das offene Internet erreicht, muss die Datenbank einen offenen Pfad von A nach B über n oft trickreich verbundene Knoten finden, was auf relationalen Systemen eine Performance-Implosion verursacht, aber sich auf Graphdatenbanken oft in den Griff bekommen lässt.
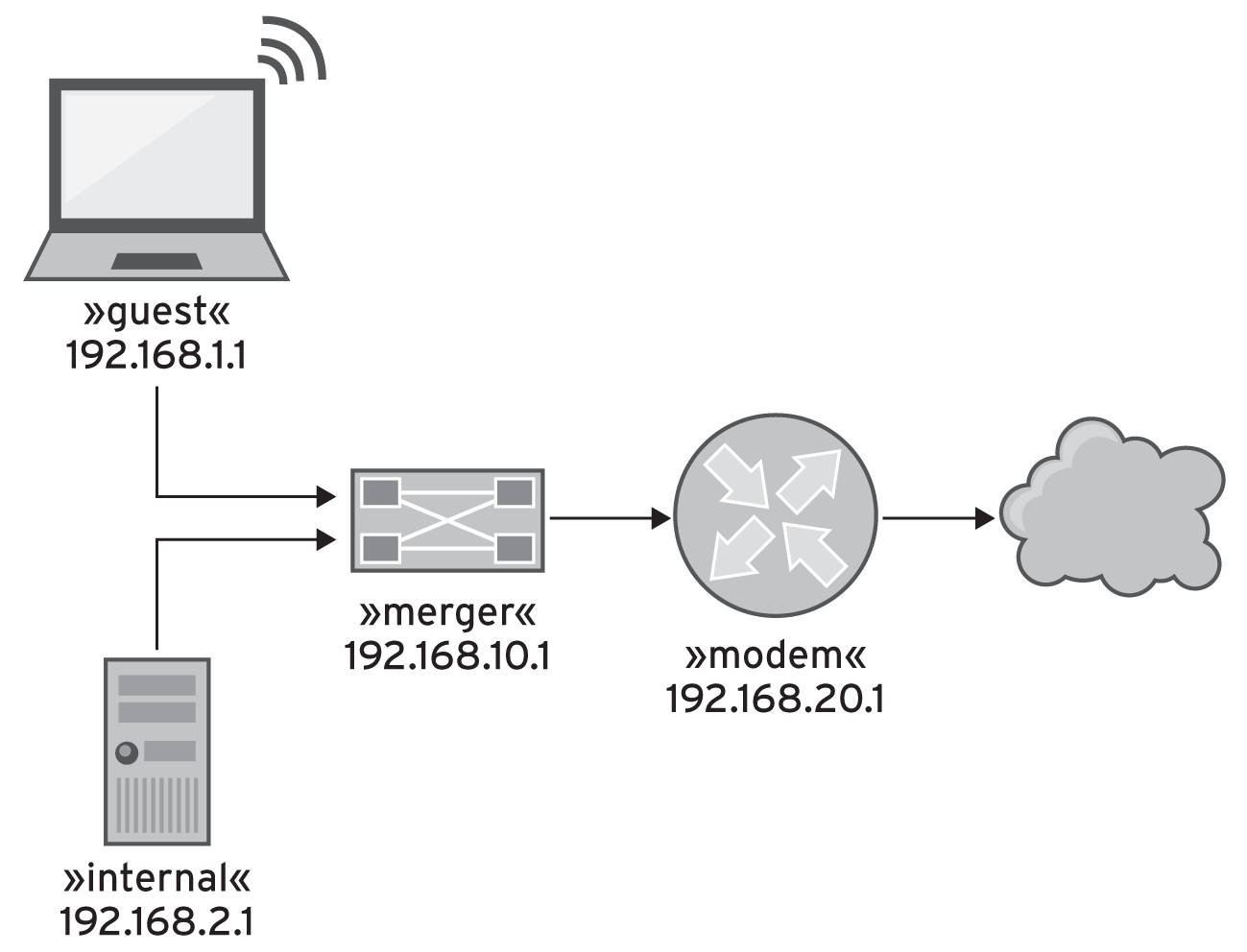
Abbildung 1: Die Komponenten eines Home-Netzwerks – für die Analyse füttert sie der Perl-Snapshot in eine Graphdatenbank ein.
Handgefüttert
Um nun zum Beispiel den Router mit dem Namen »internal« aus Abbildung 1 in die Datenbank einzufügen und ihm die LAN-IP 192.168.2.1 zuzuweisen, genügt in der Neo4j-Shell das Kommando:
neo4j-sh (?)$ CREATE (router {name:"internal", lan_ip:"192.168.2.1"});
Um die Relation »gateway« zwischen dem Router »internal« und seinem Gateway, einem weiteren neu erzeugten Knoten namens »merger« , anzulegen, sucht ein Cypher-Query beide Knoten wieder heraus und definiert mit der Cypher-eigenen Ascii-Art-Syntax die Verbindung:
neo4j-sh (?)$ MATCH (a), (b) > WHERE a.name = "windows" and b.name ="merger" > CREATE (a)-[r:gateway]->(b);
Die Match-Operation findet zwei Knoten, denen sie die Aliasnamen »a« und »b« zuweist. Da sonst kein gesuchtes Pattern in der Match-Klausel steht, trifft dies auf alle in der Datenbank liegenden Knoten zu. Die nachfolgende Where-Klausel schränkt die Treffer aber auf zwei exakt benannte Knoten ein, und die Create-Anweisung malt mit »-[…]->« einen Pfeil mit Namen zwischen die gefundenen Knoten und kreiert somit eine Relation vom Typ »gateway« .
Fütterungsautomat
Nun wäre es äußerst mühsam, die Daten eines großen Netzwerks von Hand einzutippen. Deswegen definiert die Datei »routers.yml« in Listing 1 die Eckdaten aller Router im lesbaren Yaml-Format. Die Verknüpfung der Router untereinander als Beziehung im Graphen ergibt sich später implizit aus der Verbindung der Gateway-Adresse des einen mit der LAN-IP des nächsten Routers.
Das Skript in Listing 2 schnappt sich die Yaml-Records aller Router aus der »routers.yml« -Datei, iteriert ab Zeile 28 über die Liste und pumpt sie dank des CPAN-Moduls REST::Neo4p als Nodes in die Datenbank. Dabei sichert sie alle Referenzen auf erzeugte Node-Objekte im Hash »%lans« unter deren LAN-IP als Schlüssel. Die Gateway-IPs hingegen speichert das Skript im Array »@gateways« samt den Routern, die diese Gateway-IPs nutzen. Ab Zeile 46 nudelt eine For-Schleife über »@gateways« , sucht über den »%lans« -Hash das Zielobjekt raus und definiert in der Datenbank mit der Methode »relate_to()« je eine »gateway« -Relation vom Start- zum Zielrouter.
Kaum ist das Skript fertig, zeigt ein Blick auf das über Port 7474 bereitgestellte Browserinterface, dass die Daten ordnungsgemäß in Neo4j liegen (Abbildung 2). Mit einer Query wie »MATCH (n) RETURN n« , die alle bisher gespeicherten Knoten zurückliefert, zeigt der Datenbankbrowser im Graphmodus die Knoten als nummerierte Kringel und deren Relationships als beschriftete Pfeile, die von Knoten zu Knoten verlaufen.
Mit einem Klick auf einen Knoten ploppen dessen Attribute in einem erscheinenden Dialogfenster hoch. Im Textmodus schieben sich die in Abbildung 2 gezeigten Kästen mit den Attributwerten der Knoten ins Bild.
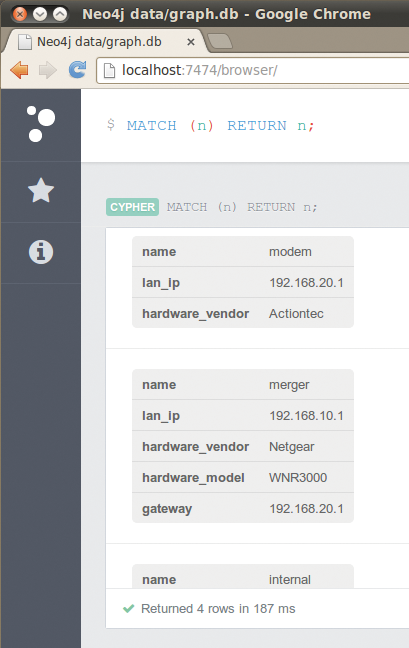
Abbildung 2: Der Neo4j-Browser stellt auf Port 7474 Cypher-Abfragen grafisch dar.
Listing 1
routers.yml
01 - 02 name: modem 03 hardware_vendor: Actiontec 04 lan_ip: 192.168.20.1 05 - 06 name: merger 07 hardware_vendor: Netgear 08 hardware_model: WNR3000 09 lan_ip: 192.168.10.1 10 gateway: 192.168.20.1 11 - 12 name: internal 13 hardware_vendor: Linksys 14 hardware_model: WRT54GS 15 lan_ip: 192.168.2.1 16 gateway: 192.168.10.1 17 - 18 name: guest 19 hardware_vendor: Linksys 20 hardware_model: WRT54GL 21 wireless: 1 22 lan_ip: 192.168.1.1 23 gateway: 192.168.10.1
Listing 2
router-setup
01 #!/usr/bin/perl -w
02 use strict;
03 use FindBin qw( $Bin );
04 use REST::Neo4p;
05 use YAML qw( LoadFile );
06 use Log::Log4perl qw( :easy );
07
08 Log::Log4perl->easy_init();
09
10 my %lans = ();
11 my @gateways = ();
12
13 REST::Neo4p->connect(
14 'http://127.0.0.1:7474' ) or die;
15
16 # Delete all data
17 my $query = REST::Neo4p::Query->new('
18 MATCH (n)
19 OPTIONAL MATCH (n)-[r]-()
20 DELETE n,r');
21 $query->execute;
22
23 my $index = REST::Neo4p::Index->new(
24 "node", "router_index" );
25
26 my $yaml = LoadFile( "$Bin/routers.yml" );
27
28 for my $router ( @$yaml ) {
29
30 DEBUG "Adding router ",
31 "$router->{ name }/$router->{ lan_ip }";
32
33 my $node =
34 REST::Neo4p::Node->new( $router );
35 $index->add_entry( $node,
36 { name => $router->{ name } } );
37
38 if( exists $router->{ gateway } ) {
39 push @gateways,
40 [ $node, $router->{ gateway } ];
41 }
42
43 $lans{ $router->{ lan_ip } } = $node;
44 }
45
46 for my $gateway ( @gateways ) {
47 my( $node, $gateway_ip ) = @$gateway;
48
49 if( !exists $lans{ $gateway_ip } ) {
50 die "Gateway $gateway_ip not defined";
51 }
52
53 DEBUG "Adding ",
54 $node->get_property("name"),
55 " -[:gateway]-> ",
56 $lans{ $gateway_ip }->
57 get_property("name");
58
59 $node->relate_to(
60 $lans{ $gateway_ip }, "gateway" );
61 }
Gordische Knoten
Damit das Skript bei Änderungen in den Yaml-Daten die Netzwerkstruktur in der Datenbank ohne Fehler auffrischt, löscht Listing 2 zu Beginn alle bislang definierten Knoten und Kanten im Graphen. Dies ist gar nicht so einfach, denn um das Datenmodell intakt zu halten, weigert sich Neo4j Knoten zu löschen, an denen noch Beziehungen kleben. Die Cypher-Query zum Ausputzen der Datenbank heißt deshalb:
MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r
Sie passt auf alle Knoten »n« – und von ihnen eventuell ausgehende Beziehungen zu einem anderen (hier anonymen) Knoten. Die Delete-Anweisung löscht alle zum Knoten gehörigen Einträge inklusive ausgehender Kanten.
Alle in der Datenbank gespeicherten Router mit der Neo4j-Shell anzuzeigen gelingt der Query in Abbildung 3. Stünde statt der Return-Klausel mit drei interessierenden Attributwerten (»n.name« , »n.hardware_vendor« , …) dort einfach »RETURN n« , enthielte das Query-Ergebnis alle definierten Attribute, was die Lesbarkeit beeinträchtigten würde. So lassen sich mit »RETURN« nicht interessierende Werte ausblenden.
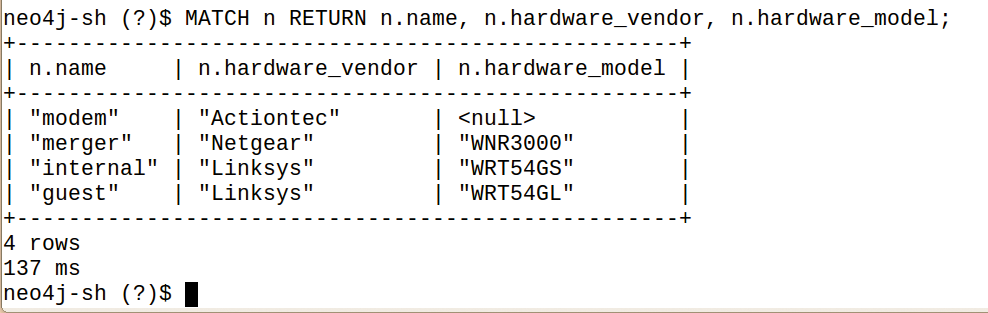
Abbildung 3: Diese Query sucht und findet alle in der Datenbank verzeichneten Geräte.
Auf Pfaden wandeln
Die Vorteile einer Graphdatenbank liegen aber nicht in niederen Diensten wie dem Hervorholen von Nodes, sondern im performanten Verfolgen von Verbindungen zwischen den Knoten. So erweist es sich als recht simpel herauszufinden, welche Netzverbindungen bestehen: Die Query in Abbildung 4 sucht mit »MATCH (n)« nach allen Routern im Netz. Die mit »-[r:gateway*]->« angehängte Relationsbeschreibung passt auf eine oder mehrere Relationen vom Typ »gateway« , das »(m)« am Ende der Beschreibung steht für den letzten Knoten der Kette.
Da die Cypher-Query die Ergebnisse mit einem vorangestellten »p=« in der Variablen »p« ablegt, würde ein nachfolgendes »RETURN p« alle Routingpfade mit allen durchlaufenen Routern samt deren Attributen ausgeben. Das wäre ein wahrer Datenwust, also reduziert die Return-Anweisung die Ausgabe auf den Routernamen am Anfang der Route und sammelt mit »collect(m.name)« die Namen durchlaufener Router ein.
Die Ausgabe in Abbildung 4 hat daher zwei Spalten, in der ersten steht der gefundene Startrouter, in der zweiten eine Liste mit den Namen durchlaufener Router auf dem Weg ins offene Internet.

Abbildung 4: Alle möglichen Pfade im Graphen über »gateway«-Relationen zeigt diese Query.
Kosten sparen
Ist das gespeicherte Netzwerk riesig, läuft eine Query mit beliebig langen Relationsketten meist (zu) lange, sie auf zwei oder drei Stufen zu begrenzen spart sehr viel Zeit. Auch wenn die Datenbank nicht ewig nach einem passenden Startpunkt für einen Pfad suchen muss, gehen ihr Abfragen schneller von der Hand. Steht etwa der Startknoten für die Suche schon fest, kann ihn eine Direktive wie
START n=node:router_index(name='guest')
vor dem Match-Kommando verankern. Voraussetzung ist, dass der Startrouter unter dem angegebenen Schlüssel (»name« ) vorher in einem Neo4j-Index abgelegt ist. Listing 2 erledigt dies in den Zeilen 35 und 36 mit der Methode »add_entry()« . Für einfachere Anwendungen hält der Neo4j-Server auch eine »autoindex« -Option bereit, die festlegt, welche Attribute er automatisch indiziert.
In Abbildung 5 findet die Query zunächst alle drahtlosen Router, die das Attribut »wireless« auf »1« gesetzt haben. Im Beispielnetzwerk gibt es nur einen einzigen, in einer komplexeren Installation vermutlich viele mehr und zusätzlich deren Routingpfade in Richtung Internet. Mit diesen Informationen ließen sich zum Beispiel periodisch automatische Sicherheitschecks etablieren, die verhindern, dass wegen eines Konfigurationsfehlers ein Netzwerkpaket von einem drahtlosen Netzwerk in ein geschütztes internes Netzwerk gelangt.

Abbildung 5: Vom einzigen Wireless-Router führt nur eine Verbindung zum Modem, die nicht über das interne Netzwerk läuft.
Zweiseitiger Anker
Das Suchmuster der Match-Anweisung darf auch komplexer verankert sein. Die Query in Abbildung 6 sucht im gesamten Netzwerk nach einem beliebigen Router »n« , der von zwei Seiten als Gateway verwendet wird. Hierzu schreibt der User die Query mit drei Routervariablen, im Beispiel »m« , »n« und »o« , mit einer Relation von links nach rechts zwischen den ersten beiden Routern und einer weiteren Relation von rechts nach links zwischen dem Router am Ende und dem in der Mitte. Ascii-Art macht’s möglich.
Neo4j versucht eine solche Konstellation zu finden und gibt das Ergebnis aus: Der Router »merger« entspricht den angefragten Forderungen. Die zwei Treffer haben als Äquivalent denselben Pfad in unterschiedlichen Richtungen.

Abbildung 6: Gesucht sind zwei Knoten im Graphen, die Pakete zum selben Gateway weiterleiten.
Kanten geben
Auf der Suche nach einer Antwort auf die Frage, welche Geräte im Netz Pakete ins Internet weiterleiten, schickt Listing 3 in Perl eine Cypher-Query los und verankert das Match-Pattern am Ende mit dem zum DSL-Modem gehörenden Router. Das CPAN-Modul REST::Neo4p::Query setzt die Query ab und nimmt die per Json vom Server eintrudelnden Ergebnisse mit der Methode »fetch()« als Pfade entgegen. Letztere bestehen aus zwei Listen, eine mit Knoten und eine mit den dazwischen liegenden Kanten.
Die Methoden »nodes()« und »relationships()« kramen die Knoten und Kanten aus den Pfad-Objekten hervor. Der For-Schleife am Ende bleib nur noch, die Namen der Geräte per »get_property()« zu extrahieren und die Pfade mit Pfeilen als Symbol auszugeben:
merger->modem internal->merger->modem guest->merger->modem windows->merger->modem
Abfragen dieser Art passieren schnell und sind offenbar einfach zu formulieren.
Wie Abbildung 7 demonstriert, gelingt die Installation des Neo4j-Servers unter Ubuntu und anderen Debian-Derivaten mit Hilfe des Debian-Repository-Servers http://neo4j.org. Im Anschluss daran startet der Dämon selbstständig, was der Aufruf von »curl http://localhost:7474« bestätigt, der den Serverstatus im Json-Format zurückgibt.
Abbildung 7: Der Paketmanager Apt-get installiert den Neo4j-Server auf Ubuntu.
Listing 3
router-search
01 #!/usr/bin/perl -w
02 use strict;
03 use REST::Neo4p;
04
05 REST::Neo4p->connect(
06 "http://127.0.0.1:7474" ) or die;
07
08 my $query_string =
09 "START n=node:router_index(name='guest')
10 MATCH p =
11 (n)-[r:gateway*]->({name:'modem'})
12 RETURN p";
13
14 my $query = REST::Neo4p::Query->new(
15 $query_string );
16 $query->execute( ) or die $!;
17
18 while( my $row = $query->fetch() ) {
19 my $path = $row->[0];
20 my @nodes = $path->nodes();
21 my @rels = $path->relationships();
22
23 for my $node ( @nodes ) {
24 print $node->get_property( "name" );
25 if( @rels ) {
26 my $rel = shift @rels;
27 print "->";
28 }
29 }
30 print "\n";
31 }
Installation
Wer einen Browser zur URL dirigiert, bekommt das weiter oben erwähnte Webinterface zu sehen und kann mit Tutorials spielen oder testweise eigene Daten einfüttern. Bei Redaktionsschluss war auf Ubuntu 12.04 die Neo4j-Version 2.0.1 aktuell. Wer den Neo4j-Server in einer VM oder auf einem anderen Host betreibt und von anderer Stelle darauf zugreifen möchte, muss in der Konfigurationsdatei »/etc/neo4j/neo4j-server.properties« die Zeile
org.neo4j.server.webserver.address=0.0.0.0
auskommentieren, sonst blockiert der Webserver Abfragen, die nicht vom Localhost kommen.
Wie so oft: Lesen bildet
Als weiterführende Literatur neben den Manualseiten nennt die Neo4j-Webseite [2] zwei Bücher: Zum einen das brandneue Kindle-Buch von Neo4j-Contributor Michael Hunger [3], das eine Wirbelwindtour durch die Cypher-Syntax bietet und einige praktische Neo4j-Beispiele vorstellt. Abgesehen vom angehängten Cypher-Cheat-Sheet ist es aber kein Referenzwerk, sondern kratzt hie und da an der Oberfläche.
Als zweite Empfehlung nennt die Neo4j-Homepage das ein Jahr alte O’Reilly-Buch “Graph Databases” [4], das sich trotz des umfassend klingenden Titels praktisch nur Neo4j widmet und eine Vielzahl echter Neo4j-Anwendungen im Detail vorstellt. Aber auch ihm fehlt die sorgfältig entwickelte Struktur eines Lehrbuchs. Das Standardwerk zu diesem recht jungen Thema steht offenbar noch aus – vielleicht gelingt dies “Neo4j in Action”, das der Manning-Verlag bereits angekündigt hat.
Infos
- Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2014/06/Perl
- Neo4j: http://neo4j.org
- Michael Hunger, “Neo4j 2.0 – Eine Graphdatenbank für alle”: Schnell+kompakt, 2014
- Ian Robinson, Jim Webber, Emil Eifrem, “Graph Databases”: O’Reilly 2013
Der Autor

Michael Schilli arbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. In seiner seit 1997 erscheinenden Kolumne forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





