
© Benis Arapovic
Wer sich für den Platzhirsch unter den Monitoring-Lösungen entscheidet, hat bei der Erst-Inbetriebnahme viel zu lernen und zu tun, kommt dank der vielen Plugins aber auch sehr weit. Läuft irgendwann alles, kann der Admin damit ruhig schlafen.
Wer zu jedem Papiertaschentuch “Tempo” sagt, denkt beim Monitoring zuerst an “Nagios” [1]. Ethan Galstad hatte die Software vor 15 Jahren unter dem Namen Netsaint erstmals veröffentlicht, heutigen Admins gilt sie inmitten der entstandenen Vielfalt an quelloffenen Monitoring-Lösungen weiterhin als Referenz. Das Projekt verdankt seine Bekanntheit nicht nur seiner Flexibilität und Leistungsfähigkeit, sondern auch der Streitlust seiner Protagonisten. Sichtbarste Auswirkung dessen ist der viel diskutierte Fork Icinga [2].
Neuere Projekte mögen innovativer oder offener sein – die anderen Artikel im Schwerpunkt werden das zeigen –, mit dem grundsoliden Nagios zu beginnen, erscheint trotzdem naheliegend. Und das, obwohl das Überwachen großer Netze und Enterprise-Features wie das SQL-Backend angesichts der überschaubaren Aufgabenstellung unnötig komplex vorkommt. Denn auch nach 15 Jahren gilt das, was der “Advice for Beginners” [3] Einsteigern mit auf den Weg gibt: Die Features und Möglichkeiten von Nagios sind komplex, und das Einarbeiten braucht Zeit und Energie, kurz: “Es wird ein wenig dauern”.
Eine Nagios-Installation besteht aus mehreren Komponenten (Abbildung 1):
Core – die Kernkomponente arbeitet die konfigurierten Checks ab und behandelt deren Resultate entsprechend der Konfiguration. Der Core verwaltet das Scheduling und das Ausführen der einzelnen Checks, des Weiteren die resultierenden Events und Alerts.
Plugins – eine der großen Stärken zieht Nagios aus seiner Erweiterbarkeit durch Check-Skripte. Bei diesen Plugins handelt es sich zumeist um Shell-, Perl- oder Python-Skripte, die Nagios mit Parametern aus seiner Config aufruft und die in einem definierten Format den Status des zu prüfenden Dienstes zurückgeben. Das Paket »nagios-plugins« bringt als Teil der verschiedenen Linux-Distributionen eine Auswahl von Plugins auf die überwachten Systeme. Darüber hinaus stellen Portale hunderte Check-Plugins bereit.
Frontends – Teil der Standardinstallation ist ein einfaches Web-GUI mit verschiedene Ansichten von überwachten Maschinen und Diensten sowie einem Interface, um auf Fehler und Warnungen zu reagieren.
Configtools – diese Werkzeuge helfen, Nagios zu konfigurieren. Das können Perl-Skripte sein, die Config-Dateien generieren oder komfortable Webtools mit Datenbank-Backends, wie beispielsweise NagioSQL [4].
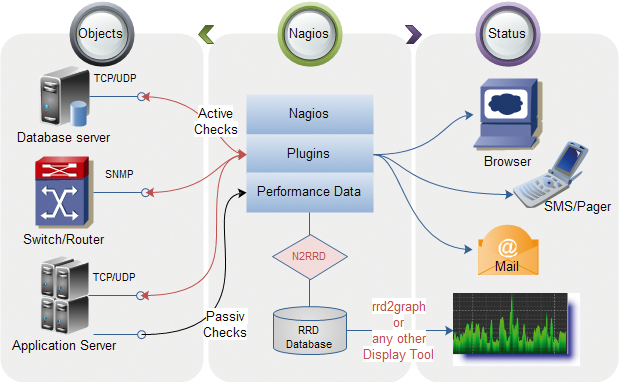
Abbildung 1: Der üblichen Struktur eines Nagios-Setups wohnt eine gewisse Komplexität inne.
Installation und Grundsetup
Als Grundlage diente den Testern ein Ubuntu 12.04.4 LTS in der Installationsart LAMP-Server. Um Zugriff auf den kompletten Satz an Nagios-Plugins zu erhalten und weil Ubuntu keine fertigen Pakte dafür vorhält, entschieden sich die Tester gegen das neue Nagios Core 4 und installierten die stabile Version 3:
sudo apt-get install -y nagios3
Der dabei ausgelöste Dialog fragt Basisinformationen ab, beispielsweise ob und wie Nagios E-Mails versenden soll oder ein Passwort für das Web-GUI.
Nach vollbrachter Installation wartet dieses einfache GUI unter »http://Nagios-Server/nagios3« darauf, dass sich der Admin anmeldet. Ihn leuchtet unter »Tactical Overview« gleich eine rote Warnung an: Die Basiskonfiguration von Nagios beinhaltet nämlich sechs vorbereitete Services, die den Nagios-Server selbst überwachen. Der dazugehörige SSH-Daemon fehlt in der Standardinstallation von Ubuntu jedoch. Nach einem »sudo apt-get install -y openssh-server« startet der SSH-Dienst. Jetzt erkennt Nagios, dass Port 22 erreichbar ist und listet unter »Services« zum »localhost« sechs Dienste mit dem Status »OK« auf.
Weitere Hosts und Services konfigurieren
Die Logik von Nagios basiert auf Objekten wie Hosts, Services, Kontakten und so weiter [5]. Ein Host beispielsweise ist gewöhnlich ein physisches Gerät mit einer IP-Adresse, das ein oder mehrere Dienste im Netzwerk bereitstellt, die Nagios überwachen kann. Alle Objekte, deren Definitionen, Bestandteile et cetera spiegeln sich in einer Ansammlung von Ascii-Dateien mit der Endung »cfg« wider, die in Verzeichnissen wie »/etc/nagios3« , »/etc/nagios-plugins/config« und einigen mehr liegen. Um die Logik zu veranschaulichen, zeigt Listing 1 einen Auszug aus der Datei »/etc/nagios3/conf.d/localhost_nagios2.cfg« .
Der »define host« -Block bestimmt den Host mit Namen sowie IP-Adresse und zieht per »use« dafür die Vorlage »generic-host« hinzu. Vorlagen definieren Überwachungsparameter und bestimmen das Verhalten. Für den Anfang genügt es, die richtige Vorlage zu benutzen auch ohne sie im Detail verstanden zu haben.
Nagios prüft Standard-Hosts üblicherweise zuerst per Ping darauf, ob sie im Netzwerk erreichbar sind. Dies bildet die Grundlage für Prüfungen von Diensten – wie sollte ein nicht-verbundener Host auch Netzwerkdienste bereitstellen?! Der Block »define service« bezieht sich per Parameter »host_name« in Zeile 11 auf den zuvor definierten Host und legt den zu überwachenden Dienst sowie den Befehl fest, mit dem dies geschehen soll.
Listing 1
localhost_nagios2.cfg
01 [...]
02 define host{
03 use generic-host
04 host_name localhost
05 alias localhost
06 address 127.0.0.1
07 }
08
09 define service{
10 use generic-service
11 host_name localhost
12 service_description Disk Space
13 check_command check_all_disks!20%!10%
14 }
15
16 define service{
17 use generic-service
18 host_name localhost
19 service_description Memory
20 check_command
21 check_memory!50%!25%
22 }
23 [...]
Plugins benutzen
Die Zeile 13 von Listing 1 bezieht sich auf ein Nagios-Plugin, welches mit dem Paket »nagios-plugins« auf den Server (bei Ubuntu ins Verzeichnis »/usr/lib/nagios/plugins/« ) gelangt ist. Die Implementierung des Command »check_all_disks« findet in der Datei »/etc/nagios-plugins/config/disk.cfg« (Listing 2) statt.
Die Zeile »check_command« in Listing 1 definiert, welches Kommando Nagios mit welchen Parametern aufruft, um den »service« zu prüfen. Die mit Rufzeichen abgetrennten Parameter bekommt das »check_disk« -Skript als »$ARGx$« -Variablen intern übergeben: »/usr/lib/nagios/plugins/check_disk -w 20% -c 10% -e« . Zurück kommen Information wie:
DISK OK| /=1293MB;4734;5326;0;5918/dev=0MB;792;891;0;991/run=0MB;320;360;0;400/run/lock=0MB;4;4;0;5/run/shm=0MB;800;900;0;1000
Das Ausgabeformat ist für das Nagios-System interpretierbar und liefert unter Anderem den Status »OK« – die Werte liegen also innerhalb der vom Admin festgelegten Schwellen für Warnung (»-w« , Warning) und kritischen Zustand (»-c« , Critical). Wer den Check dagegen mit »/usr/lib/nagios/plugins/check_disk -w 80% -c 10% -e« formuliert, löst auf demselben System eine Warnung aus:
DISK WARNING - free space: / 4301 MB(76% inode=84%);|/=1294MB;1183;5326;0;5918[...]
da eine der Festplatten das Warnungslimit überschreitet.
Listing 2
disk.cfg
01 # 'check_all_disks' command definition
02 define command{
03 command_name check_all_disks
04 command_line /usr/lib/nagios/plugins/check_disk -w '$ARG1$' -c '$ARG2$' -e
05 }
Eigene Tests schreiben
Die mitgelieferten Plugins decken ein weites Feld an Prüfungen ab. Noch viel, viel mehr finden Nagios-Admins aber auf Portalen wie Nagios-plugins.org oder Monitoring-plugins.org. Eine schnelle Recherche zum Realisieren der gestellten Aufgabe, die RAM-Auslastung des Servers zu überwachen, führt zum Skript »check_memory.pl« [7]. Nach Installation des zugehörigen Perl-Moduls Nagios::Plugin liefert »/usr/lib/nagios/plugins/check_memory.pl« auf der Shell bereits eine brauchbare Antwort:
CHECK_MEMORY OK - 1853M free |free=1944035328b;;
Damit Nagios etwas mit anfangen kann, bedarf es einer »command« -Definition wie in Listing 3, zu der [7] eine Anleitung parat hatte. Jetzt definiert der Admin in der bekannten Datei »localhost_nagios2.cfg« einen weiteren Service (Listing 1 ab Zeile 16). Nach einem beherzten
sudo /etc/init.d/nagios3 reload
zeigt das Web-GUI unter »Services« das soeben definierte »Memory« . Der Service befindet sich vorerst im Status »PENDING« , da Nagios ihn noch nicht geprüft hat. Wer das nicht abwarten will, erzwingt ein »Re-schedule the next check of this service« . Nun stellt das GUI die interpretierte Ausgabe des Perl-Skriptes dar: Der Service ist grün, also okay, und im Feld »Status Information« erscheint der Wert des freien RAM.
Listing 3
memory.cfg
01 # 'check_memory' command definition
02 define command{
03 command_name check_memory
04 command_line perl /usr/lib/nagios/plugins/check_memory.pl -w $ARG1$ -c $ARG2$
05 }
Remote- und VM-Checks
Das Monitoring auf anderen Hosts erfordert, dass dort Plugins ausgeführt werden. Der Daemon NRPE (oder der NSCA, für Windows-Maschinen der NS Client++ [8]) vereinfacht dies, wenn der Admin ihn gemeinsam mit den gewünschten Plugins auf jedem zu überwachenden Host installiert. In der Datei »/etc/nagios/nrpe.cfg« legt er fest, für welche Monitoring-Hosts NRPE erreichbar sein soll und welche Prüfkommandos dort zulässig sind. Dies verringt gegenüber anderen Varianten wie Check_ssh die Gefahr, dass der Server schädliche Kommandos ausführt.
Ein Kommando aus »nrpe.cfg« für den entfernten Server kann so aussehen:
command[check_load]=/usr/lib64/nagios/plugins/check_load -w 15,10,5 -c 30,25,20
Der Monitoring-Server kann nach:
define service{
use generic-service
host_name Host.Domain.com
check_command check_nrpe!check_loadAndere Parameter
}
»check_nrpe« -Anfragen an den entfernten NRPE-Daemon stellen.
Üblicherweise vollführt Nagios aktive Checks, also solche, die der Nagios Core auslöst. Daraufhin läuft ein Plugin ab und meldet seine Resultate an den Core zurück. Für das Monitoring entfernter Maschinen spielen aber auch passive Checks eine Rolle. Dabei löst ein externer Prozess den Check aus, weil der Nagios-Server das Plugin zum Beispiel einer Firewall wegen nicht erreichen kann.
Auf ähnliche Weise wie ein Remote-Host lässt sich auch ein virtualisierter Gast monitoren. Der Admin installiert wieder NRPE und die »nagios-plugins« . In »/etc/nagios/nrpe.cfg« definiert er den berechtigten Nagios-Server und die erlaubten Checks (Listing 4). Auf Nagios-Core-Server hinterlegt er den entsprechenden Host mit dessen IP sowie die abzufragenden NRPE-Checks (Listing 5).
Irgendwann eine zweite VM hinzu zu fügen, gelingt recht schnell. In größeren Umgebungen greifen zudem die Vorzüge der Objektstruktur in der Nagios-Logik: Mehrere Hosts lassen sich zu Hostgroups vereinen, um gleichartige Server mit denselben Checks zu überwachen. Über Templates können zudem Objekte Eigenschaften voneinander erben.
Listing 4
nrpe.cfg
01 # Welche IPs duerfen den NRPE-Daemon befragen? 02 allowed_hosts=127.0.0.1,172.31.99.12 03 04 # Checks ... 05 command[check_users]=/usr/lib/nagios/plugins/check_users -w 5 -c 10 06 command[check_load]=/usr/lib/nagios/plugins/check_load -w 15,10,5 -c 30,25,20 07 command[check_sda1]=/usr/lib/nagios/plugins/check_disk -w 20% -c 10% -p /dev/sda1 08 command[check_ntp]=/usr/lib/nagios/plugins/check_ntp_time -H at.pool.ntp.org -w 10 -c 20
Listing 5
Core-VM-Definition
01 define host{
02 use generic-host
03 host_name VM_1
04 alias Linux-Test-VM-1
05 address 172.31.99.20
06 }
07
08 define service {
09 host_name VM_1
10 service_description Anzahl User
11 use generic-service
12 check_command check_nrpe!check_users
13 register 1
14 }
15
16 define service {
17 host_name VM_1
18 service_description Last
19 use generic-service
20 check_command check_nrpe!check_load
21 register 1
22 }
23
24 define service {
25 host_name VM_1
26 service_description Belegung Partition sda1
27 use generic-service
28 check_command check_nrpe!check_sda1
29 register 1
30 }
Alerting
Wer nicht gerade das Web-GUI betrachtet, bekommt bedrohliche Situationen nicht mit. Es ist also erforderlich und sinnvoll, verantwortliche Personen aktiv von veränderten Situationen zu informieren. Dazu verwaltet Nagios Objekte vom Typ »Contacts« . Ein solcher Kontakt ist meist eine Person verbunden mit Parametern zur Art der Kontaktaufnahme. Die erste Hälfte von Listing 6 zeigt ein Beispiel.
In Firmen sind oft mehrere Personen zu verständigen. Um die Konfiguration zu vereinfachen, gibt es die so genannte »contactgroup« , die mehrere Kontakte zusammenfasst (Listing 6 ab Zeile 11). In der »define service« -Sektion kann man sie einem Service per »contact_groups Gruppenname« zuordnen.
Erwartbar flexibel zeigt sich Nagios auch beim Benachrichtigen: Neben E-Mail informiert es über Alerts per Pager, SMS und die berühmte Nagios-Ampel [9].
Listing 6
Kontakte und Kontaktgruppen
01 define contact {
02 contact_name sgw ; Short name of user
03 use generic-contact ; Settings mit der use-Anweisung uebernehmen
04 ; von der contacts-Vorlage generic-contact
05 alias Stefan Weichinger ; Vollstaendiger Name
06 service_notification_commands notify-service-by-email
07 host_notification_commands notify-host-by-email
08 email sgw@example.com
09 }
10
11 define contactgroup {
12 contactgroup_name admins
13 alias Nagios Administrators
14 members sgw,admin2
15 }
Für Leute mit Plänen
Der Artikel verdeutlicht, dass die Einarbeitung in Nagios aufwändig ist. Für den Admin, der später Größeres vorhat, lohnt die Sache aber. Hat er erst die Konzepte verstanden und die Hürden der initialen Konfiguration genommen, tut er sich später recht leicht, weitere Server und Dienste zu ergänzen.
Der Ablauf ist stets der gleiche: Der Admin definiert einen Host, installiert darauf NRPE sowie die Nagios-Plugins. Ist bei den Standard-Nagios-Plugins der gesuchte Check bereits dabei, editiert er auf dem zu überwachenden Host nur die entsprechende Zeile in der »nrpe.cfg« und definiert den Service auf dem Nagios-Core-Server. Fehlt mal ein Check, findet er ihn meist auf gängigen Portalen. Mit etwas Geschick ist es zudem kein Problem, auf Basis eines Standard-Plugins selbst Prüfungen zu bauen.
Monitoring und Performance-Engpässe
Auch wenn Nagios oder andere Monitoring-Lösungen “Grün” signalisieren, bedeutet das nicht zwingend, dass es überall zum Besten steht. Analysten wie Forrester oder Gartner schätzen, dass die IT-Abteilung von der Hälfte aller Performance-Probleme über die Benutzer erfährt und nicht aus dem Monitoring.
Spezialangebote wie Neteye [6] versprechen, das Problem zu lösen. Das Open-Source-Monitoring implementiert Sonden auf den Systemen und realisiert damit eine Art automatische Enduser-Simulation. Der Anbieter Würth Phoenix benutzt dazu das Open-Source-Paket von Al’exa, ein Python-Modul, das auf Basis der “Open CV Vision Library” UI-Objekte wie Input-Felder oder Buttons anhand von Mustern identifiziert und mit Hilfe von passenden Testcases bedient.
Infos
- Nagios: http://nagios.org
- Nagios vs. Icinga: http://www.freesoftwaremagazine.com/articles/nagios_and_icinga
- Advice for Beginners: http://nagios.sourceforge.net/docs/3_0/beginners.html
- NagioSQL: http://www.nagiosql.org
- Objektarten: http://nagios.sourceforge.net/docs/3_0/configobject.html
- Würth Phoenix Neteye: http://www.wuerth-phoenix.com/de/loesungen/system-management/real-user-experience/uebersicht/
- »check_memory.pl« : http://blog.christosoft.de/2013/01/nagios-icinga-memory-usage/
- NS Client++: http://sourceforge.net/projects/nscplus/
- Michael Schwartzkopff, “Ampel-Koalition”: https://www.linux-magazin.de/Ausgaben/2008/06/Ampel-Koalition





