
© Piotr Gatlik, 123RF.com
Selbst Linux-Systeme mit riesigen Mengen an Hauptspeicher sind nicht vor Engpässen und zum Teil drastischen Performance-Einbußen durch Speicherknappheit geschützt. Dieser Artikel geht den komplexen Ursachen auf den Grund und stellt mögliche Lösungsansätze auf die Probe.
Moderne Software wie große Datenbanken oder SAP laufen heutzutage auf Linux-Maschinen, in denen nicht selten viele Hundert GByte Hauptspeicher stecken. Auf Systemen, auf denen die SAP-Datenbank Hana produktiv laufen soll, sind bereits Hauptspeicher von bis zu 4 TByte zu finden [1]. Bei diesen Größen sollte man erwarten, dass speicherbedingte Engpässe keine Rolle mehr spielen. Doch die Erfahrung von Anwendern und Herstellern solcher Softwarelösungen zeigt, dass dieses Problem noch nicht vollständig gelöst ist und weiterhin der Aufmerksamkeit bedarf.
Immer wieder stellen sie fest, dass die Performance selbst eingeschwungener Anwendungen unter bestimmten Bedingungen durch zu wenig verfügbaren Hauptspeicher massiv beeinträchtigt werden kann. Das Standardverfahren in solchen Situationen, mehr RAM, hilft offenbar nicht nachhaltig. Dieser Artikel beschreibt zunächst das Problem etwas genauer, analysiert die Hintergründe und erprobt dann Lösungsmöglichkeiten.
Speicherschweine und Plattensäue
Viele der großen Anwendungen wie etwa SAP-Applikationsserver oder Datenbanken benötigen primär CPU und Hauptspeicher. Plattenzugriffe sind hier selten und zudem speziell optimiert. Damit sollte beispielsweise ein parallel laufender Kopiervorgang großer Dateien kaum Auswirkungen auf solche Anwendungen haben, da unterschiedliche Ressourcen nachgefragt sind.
Abbildung 1 zeigt jedoch, dass diese Annahme nicht stimmt. Das Diagramm demonstriert, wie sich der (synthetische) Durchsatz eines SAP-Applikationsservers verändert, wenn parallel zum Benchmark noch zusätzlich Datei-Operationen anfallen: Als 100-Prozent-Referenzwert wird der Testlauf ohne parallele Plattenzugriffe angenommen. In den nächsten Testläufen schreibt das Kommando »dd« jeweils eine Datei in der angegebenen Größe auf die Festplatte.
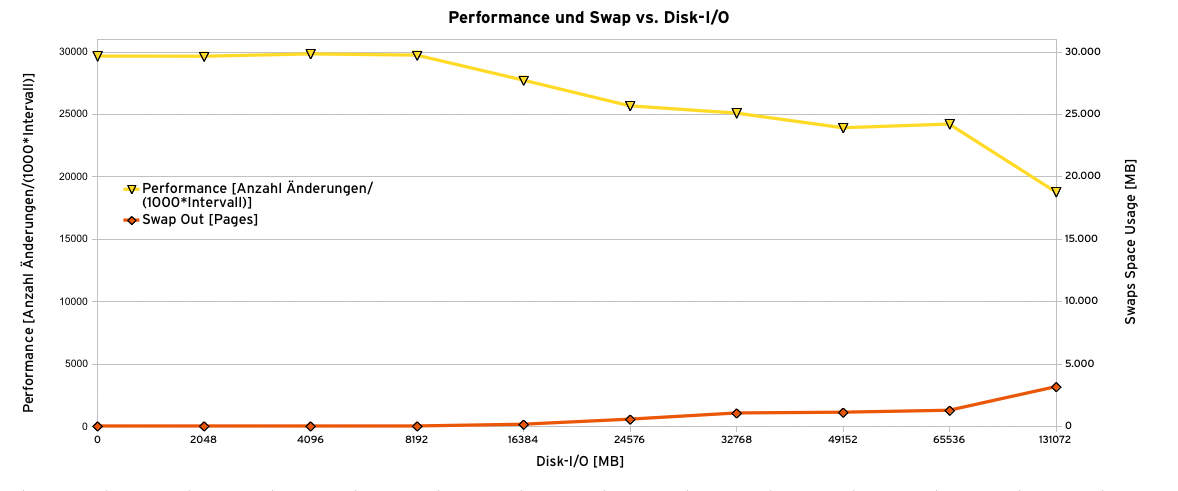
Abbildung 1: Performanceverlust in Abhängigkeit vom Disk-I/O auf einem SAP-Applikationsserver.
Dabei lässt sich erkennen, dass bei einem eingeschwungenen System der Durchsatz anfangs nicht weiter von den Datei-Operationen beeinflusst wird, ab einem gewissen Wert (zum Beispiel 16384 MByte) die Performance jedoch einbricht. Wie die Abbildung zeigt, sinkt der Durchsatz des Systems mit wachsender Dateigröße um knapp 40 Prozent. Auch wenn die Zahlen im Normalbetrieb anders sein dürften, liegt hier doch ein merkliches Problem vor.
Ein solches Verhalten findet sich im täglichen Betrieb oft dann, wenn ein Backup zeitgleich Daten bewegt oder über Nacht bewegt hat oder allgemein große Dateien kopiert werden. Eine genauere Betrachtung dieser Situationen ergibt, dass zeitgleich das Paging zunimmt (Abbildung 1). Es scheint also, dass sich rege Plattenzugriffe eines Prozesses, die eigentlich wenig CPU- und Speicher-lastig sind, unter Umständen auch deutlich auf die Performance solcher Anwendungen auswirken, die von Haus aus kaum auf die Disks zugreifen.
Anatomie des Speichers
Das beschriebene Verhalten lässt sich nur verstehen, wenn man die Verwaltung von Hauptspeicher durch den Linux-Kernel betrachtet. Linux unterscheidet wie alle modernen Systeme zwischen dem virtuellen Speicher, den Betriebssystem und Anwendungen sehen, und dem physischen Hauptspeicher, der durch die Hardware der Maschine und/oder den Virtualisierer gegeben ist ([2], [3]). Beide Speicherformen sind in Einheiten gleicher Größe organisiert. Beim virtuellen Speicher nennt man diese Einheiten Pages, beim physischen Speicher Pageframes. Auf modernen Systemen sind beide häufig immer noch 4 KByte groß.
Die Hardware-Architektur bestimmt weiterhin auch die maximale Größe des virtuellen Speichers: Auf einer 64-Bit-Architektur ist der virtuelle Adressraum maximal 264 Byte groß – auch wenn aktuelle Implementierungen auf Intel und AMD nur 248 Byte unterstützen [4].
Virtuell und physisch
Wenn Software – und dazu zählt in diesem Fall auch der Linux-Kernel selbst – auf die Speicherinhalte zugreifen will, muss eine Abbildung von virtuellen Adressen auf die Adressen im physischen Hauptspeicher geschehen. Diese Abbildung ist durch prozessspezifische Pagetabellen realisiert und entspricht letztlich einer Ersetzung der Page, in der die Speicherinhalte virtuell stehen, durch den Pageframe, in dem sie faktisch lagern (Abbildung 2).

Abbildung 2: Bestandteile der Speicherverwaltung unter Linux.
Während der virtuelle Adressraum von Anwendungen sich in Bereiche für Code, statische Daten, dynamische Daten (Heap) sowie den Stack aufteilt, nimmt das Betriebssystem große Bereiche an Pageframes für seine internen Caches in Anspruch [1]. Einer der wichtigsten Caches ist dabei der Pagecache, der zunächst einmal nur ein Speicherbereich ist, in dem spezielle Pages zwischengespeichert sind. Zu diesen Pages gehören die Seiten, die bei Dateizugriffen beteiligt sind. Wenn solche Seiten im Hauptspeicher liegen, vermeidet das System viele Zugriffe auf die langsamen Platten: Wird zum Beispiel ein »read()« -Zugriff auf einen Plattenbereich nötig, überprüft der Linux-Kernel zunächst, ob die gewünschten Daten im Pagecache liegen. Wenn ja, liest er sie von dort.
Schneller lesen
Der Pagecache ist also ein Cache für Filedaten, die in Pages eingelesen wurden. Seine Verwendung beschleunigt den Plattenzugriff um Größenordnungen. Deshalb nutzt Linux diesen Cache sehr intensiv und versucht ihn stets auf maximal möglicher Größe zu halten [5].
In den Pagecache sind noch zwei weitere Bereiche integriert, die in alten Linux-Zeiten (Kernel 1.x und 2.x) getrennt verwaltet wurden. Zum einen ist das der Buffer Cache, der Blöcke von Platten und anderen Blockdevices im Hauptspeicher verwaltet. Heute verwendet der Linux-Kernel aber durchweg keine Blöcke als Speichereinheiten, sondern Pages. Der Buffercache speichert deshalb nur noch die Abbildung von Pages auf Plattenblöcke, da diese nicht unbedingt die gleiche Größe wie Pages haben müssen. Er besitzt heute nur noch eine geringe Bedeutung.
Zum anderen gibt es den Swapcache, der auch ein Cache für Pages ist, die von einem Datenträger stammen. Er operiert allerdings auf Pages, die nicht in normalen Dateien liegen, sondern auf Pages, die im Swapbereich liegen, den so genannten Anonymous Pages. Wenn eine Page in den Swapbereich ausgelagert wurde und später wieder eingelagert wird, ist sie zunächst einmal auch nur eine ganz normale Page von einer Platte. Sie sollte also gecached werden.
Der Swapcache enthält nun primär nur solche Pages, die zwar vom Swap eingelagert, aber danach noch nicht wieder verändert wurden. Am Swapcache kann Linux also erkennen, ob eine erneute Auslagerung ein Schreiben auf Platte (Swapbereich) erfordert. Eine der wichtigsten Aufgaben des Swapcache ist damit das Einsparen von (Schreib-)Zugriffen. Hier zeigt sich ein deutlicher Unterschied zum eigentlichen Pagecache, der primär Lesevorgänge beschleunigt [5].
Wenn nun viele Plattenzugriffe geschehen, versucht der Kernel den Pagecache an diese Anforderungen anzupassen. Im oben skizzierten Test wächst er, weil die geschriebene Datei größer wird. Da die Anzahl der verfügbaren Pageframes aber begrenzt ist (im Test auf 10 GByte freien Speicher), geht dieses Wachstum auf Kosten der Pages, die Anwendungen für sich selbst im physischen Speicher halten können.
Alte Pages
Bei wachsendem Pagecache versuchen die Auslagerungsstrategien des Kernels (Page Replacement Strategies, [1]) Platz zu schaffen. Bei Linux geschieht dies durch eine vereinfachte LRU-Strategie, die vor allem länger ungenutzte Pages – eben Least Recently Used Pages – als Auslagerungskandidaten identifiziert und den »kswapd« -Kernelthread für die faktische Auslagerung nutzt.
Leider fallen viele anwendungsspezifische Pufferbereiche in diese Kategorie. So kann ein typischer SAP-Applikationsserver viele GByte in diesen Puffern und temporären Bereichen verwalten. Die Unterschiedlichkeit der Anfragen führt aber dazu, dass weite Teile daraus weder sehr oft noch sehr zeitnah, aber eben immer mal wieder verwendet werden: Die Anfragen besitzen eine geringe Lokalität. Der Linux-Kernel opfert die zugehörigen Pages je nach Swapping-Aggressivität dem Wachstum des Pagecache und lagert sie aus. Wodurch die Performance der Anwendung allerdings sinkt, da Linux Speicherzugriffe nun unter Umständen nicht mehr direkt aus dem Hauptspeicher, sondern erst nach einem erneuten Einlagern aus dem Swapbereich bedient.
Diese Überlegungen bieten den Rahmen, um das oben gezeigte und empirisch festgestellte Verhalten zu erklären. Wenn durch Backups oder das Kopieren großer Dateien viele Plattenzugriffe geschehen, kann das Betriebssystem Pages der Anwendungspuffer zugunsten eines größeren Pagecache auslagern. Ist dies geschehen und greift die Anwendung wieder auf den ausgelagerten Speicher zu, werden ihre Zugriffe im Mittel langsamer. Wer den physischen Speicher durch Einbau weiterer Hauptspeichermodule vergrößert, löst das Problem nicht grundsätzlich, sondern kann das Eintreten bestenfalls verzögern.
Lösungsansätze
Die Ausführungen der vorigen Abschnitte zeigen, dass die beobachteten Performance-Einbußen auf die Knappheit des physischen Speichers zurückzuführen sind. Die möglichen Lösungsansätze lassen sich dadurch unterscheiden, auf welche Weise sie hinreichend viel Platz für eine Anwendung im physischen Speicher sicherstellen:
- Fokus eigene Anwendung: Verhindere das Auslagern der eigenen Pages.
- Fokus andere Anwendungen: Reduziere oder begrenze den Speicherverbrauch anderer Anwendungen.
- Fokus Kernel: Verändere die Verwaltung des physischen Speichers durch den Kernel.
Diese unterschiedlichen Ansätze sind in Abbildung 3 grafisch zusammengestellt.

Abbildung 3: Ansätze zum Schutz der Pages einer Anwendung.
Die eigene Anwendung
Eine ganz naheliegende Maßnahme, um den Speicherdruck zu reduzieren, ist sicherlich, die eigene Anwendung klein zu halten und immer wieder Speicher freizugeben. Dies erfordert aber in der Regel eine sehr aufwändige und individuelle Planung. Aus Entwicklersicht mag es deshalb verlockend erscheinen, das Auslagern der eigenen Anwendungspages aus dem physischen Speicher zu verhindern. Dazu gibt es sowohl Verfahren, die ein Eingreifen in den Code notwendig machen, als auch Verfahren, die aus Sicht der Anwendung transparent sind und nur ein wenig Administrationsarbeit erfordern.
Zu den ersteren gehört zunächst der altbekannte Systemcall »mlock()« [6]. Mit diesem Befehl lässt sich explizit ein Bereich im virtuellen Adressraum im physischen Speicher festnageln. Ein Auslagern ist dann selbst in eventuell begründeten Ausnahmefällen nicht mehr möglich. Zudem erfordert dieses Vorgehen bei plattformübergreifender Programmierung besondere Aufmerksamkeit, da »mlock()« besondere Ansprüche an die Ausrichtung der Datenbereiche (Alignment) stellt. Dies und der Mehraufwand durch den expliziten Eingriff in den Programmcode lassen »mlock()« in vielen Umgebungen als nicht geeignet erscheinen.
Ein anderer Ansatz, der aber ebenfalls einen Eingriff in den Code und die Administration der Systeme voraussetzt, verwendet Huge Pages, die der Linux-Kernel prinzipiell seit 2003 nutzen kann [7]. Die Grundidee der Huge Pages ist einfach: Statt vieler kleiner Pages (typischerweise 4 KByte) verwendet das Betriebssystem weniger, aber dafür größere Pages – beispielsweise 2 MByte auf x86_64-Plattformen.
Das reduziert die Anzahl der notwendigen Abbildungen von Pages zu Pageframes und beschleunigt damit Speicherzugriffe unter Umständen merklich. Implementierungsbedingt kan Linux Huge Pages nicht auslagern, sodass sie auch als Schutz der eigenen Pages dienen. Leider ist die Verwendung der Huge Pages jedoch umständlich. Für die Bereitstellung von Shared Memory zum Beispiel ist extra ein Dateisystem namens »hugetlbfs« einzurichten, in dem gemeinsame Speicherbereiche als Dateien abgelegt werden, die durch Huge Pages im Hauptspeicher implementiert sind.
Problematischer ist aber, dass man die nachträgliche Allokierung von Huge Pages im laufenden Betrieb nicht garantieren kann, da sie in zusammenhängenden Bereichen im Speicher abgebildet sein müssen. Huge Pages muss man damit häufig sogar direkt nach dem Booten reservieren, womit der ihnen zugeordnete Speicher anderen Anwendungen ohne Huge-Page-Unterstützung nicht mehr zur Verfügung steht. Gerade für Hochverfügbarkeitslösungen wie Failover-Szenarien, aber auch im allgemeinen Betrieb führt dies zu verringerter Flexibilität. Die komplexe Bedienung der Huge Pages legte es nahe, ein einfacheres und weitgehend automatisches Verfahren zur Nutzung größerer Pages zu entwickeln.
Mit den Transparent Huge Pages (THP) hielt dieses Verfahren im Jahr 2011 Einzug in den 2.6er Kernel. Wie der Name andeutet, geschieht die Verwendung von THP für Anwender und Entwickler unsichtbar. Die Implementierungen zeigen generell etwas geringere Performance als mit Huge Pages. THP werden allerdings in gleicher Weise ausgelagert wie normale Pages auch.
Effizient: mmap()
Ein anderer Ansatz, der die eigene Anwendung betrifft, ist kein Schutz im eigentliche Sinne, sondern eine Strategie zur effizienteren Speichernutzung und damit indirekt zum Reduzieren des Auslagerungsdrucks. Der Mechanismus basiert auf dem bewährten »mmap()« -Aufruf ([8], [9]). Dieser Systemcall blendet Bereiche aus Dateien in den virtuellen Adressraum des Aufrufers ein, sodass er etwa Datei-Inhalte direkt im virtuellen Adressraum verändern kann.
In mancher Hinsicht ersetzt »mmap()« damit normale Datei-Operationen wie »read()« . Wie Abbildung 3 andeutet, unterscheidet sich deren Implementierung in Linux allerdings in einem wichtigen Detail: Bei »read()« und Gefährten hält das Betriebssystem die eingelesenen Daten einmal in einer Page der Anwendung und noch einmal als Daten einer Datei im Pagecache. Diese Doppelung entfällt bei »mmap()« . Linux speichert die Page nur noch im Pagecache und passt die Abbildung von Page zu Pageframe entsprechend an.
Der Einsatz von »mmap()« spart also Platz im physischen Speicher ein und reduziert damit die Wahrscheinlichkeit, dass eigene Pages ausgelagert werden – zumindest grundsätzlich und zu einem gewissen, meist geringen Anteil.
Alle hier vorgestellten Ansätze, die eigene Anwendung sicherer gegen Auslagerungen zu machen, befriedigen nicht vollständig. Ein anderer Weg könnte deshalb sein, das Verhalten fremder Anwendungen zu ändern, um so die eigene besser zu schützen. Zwar besitzt Linux mit »setrlimit()« und ähnlichen Systemcalls seit Langem die Möglichkeit, den Ressourcenverbrauch einer Anwendung zu beschränken, doch erfordern diese Calls den Eingriff in den Code der – hier per Annahme – fremden Anwendung. Das ist in der Praxis offensichtlich kein gangbarer Weg.
Unter Kontrolle
Eine bessere Alternative könnten auf den ersten Blick die seit Linux 2.6 verfügbaren Control Groups (»cgroups« ) bilden [10]. Mit ihrer Hilfe und ausreichenden Berechtigungen lässt sich auch ein fremder Prozess einer Gruppe zuteilen, die dann die Ressourcennutzung des Prozesses kontrolliert. Leider stellen sich damit vor allem für Systemadministratoren, wie auch bereits beim Begrenzen von Ressourcen über die Shell per Ulimit, einige schwer zu beantwortende Fragen:
- Kann/darf ich wirklich eine Anwendung auf Kosten einer anderen einschränken? Eine sinnvolle Verteilung der Anwendungen auf Maschinen vorausgesetzt, wird diese Priorisierung oftmals schwer fallen.
- Welche sind vernünftige Werte für die Einschränkungen?
- Schließlich kann man die grundsätzliche Ausrichtung kritisch befragen: Ist die feste Einschränkung fremder Anwendungen wirklich das Ziel? Oder sollte der Linux-Kernel eher nur in Sonderfällen mit meiner eigenen Anwendung sorgsamer umgehen?
- Ist ein Abbruch der Anwendung bei Erreichen der Grenzen tolerierbar?
Diese Fragen zeigen, dass auch die Cgroups letztlich das zugrunde liegende Problem nicht lösen.
Die Auslagerung der Anwendungspuffer geschieht, weil der Pagecache (zu) viel Platz für sich in Anspruch nimmt. Ein möglicher Ansatz wäre es deshalb, den Pagecache nicht so weit wachsen zu lassen, dass es überhaupt zu einer Konkurrenzsituation mit dem Anwendungsspeicher kommt. Mit Unterstützung der Anwendungen ist dies auch bis zu einem gewissen Grad möglich.
Der Entwickler kann das Betriebssystem im Anwendungscode anweisen, den Pagecache entgegen seinen üblichen Vorlieben nicht zu nutzen. Dies bezeichnet man unter Linux üblicherweise als Direct-I/O [11]. Er umgeht das Caching des Betriebssystems, um etwa einer Datenbank volle Kontrolle über das Verhalten der eigenen Caches zu geben. Ein solcher direkter I/O lässt sich über Optionen bei Datei-Operationen anstoßen, etwa mit der Option »O_DIRECT« bei »open()« oder »DONT_NEED« bei »fadvise()« .
Leider verwenden nur wenige Anwendungen direkten I/O – und da eine einzelne fehlkonfigurierte Anwendung ein eingeschwungenes System aus der Balance bringen kann, können solche Strategien das Auslagern der Anwendungspuffer bestenfalls hinauszögern.
Fokus auf den Kernel
Aus administrativer Sicht wäre es aber sicherlich deutlich einfacher, den Kernel selbst so anzupassen, dass die Speicherengpässe der Anwendungen nicht mehr auftreten. Eine Einstellung im Kernel hätte dann Auswirkungen auf alle Programme und erforderte zum Beispiel gar kein anwendungsspezifisches Kodieren mehr. Dies kann man auf mehrere Arten versuchen zu erreichen.
Zunächst ließe sich der Pagecache insgesamt auf eine feste Größe begrenzen. Eine solche Grenze verhindert das Auslagern effektiv, wie Messungen gleich zeigen werden. Leider sind die dazu notwendigen Patches nicht im Standardkernel enthalten und werden es in nächster Zeit wahrscheinlich auch nicht sein. Nur wenige Enterprise-Versionen von Distributoren wie Suse warten mit diesen Anpassungen auf, und das auch nur in Sonderfällen. Für viele Umgebungen ist dies somit auch keine Lösung.
Ebenfalls nur für Sonderfälle eignet sich der nächste Weg. Wenn der Swapbereich im Vergleich zum verfügbaren Hauptspeicher sehr klein dimensioniert oder überhaupt nicht vorhanden ist, kann der Linux-Kernel im Notfall kaum noch auslagern. Die Pages der Anwendungen sind dann gezwungenermaßen gegen Auslagern geschützt – allerdings um den Preis, dass es zu Out-of-Memory-Situationen (OOM) kommen kann, wenn das System zum Beispiel wegen zeitweiser Speicherknappheit auslagern muss.
Ein reibungsloser Betrieb erfordert in diesem Fall eine sehr sorgfältige Planung und genaue Kontrolle des Systems. Für Rechner mit ungenau definierter Workload kann solch ein Ansatz schnell in Prozessabbrüchen und damit in einer unkontrollierbaren Umgebung enden.
Swappiness
Viel Hoffnung konzentriert sich deshalb auf eine Einstellung, die der Linux-Kernel seit Version 2.6.6 unterstützt [12]. Unter »/proc/sys/vm/swappiness« steht zur Laufzeit eine Konfigurationsmöglichkeit bereit, mit der sich das Auslagern von Pages durch den Kernel beeinflussen lässt. Der Wert von »swappiness« gibt an, wie stark der Kernel Pages auslagern soll, die nicht zum Pagecache oder anderen Betriebssystem-Caches gehören.
Eine hohe »swappiness« (maximal 100) veranlasst den Kernel, solche Anonymous Pages sehr intensiv auszulagern. Der Pagecache wird dann bestmöglich geschont. Ein Wert von 0 gibt dem Kernel dagegen die Anweisung, möglichst niemals Anwendungsseiten auszulagern. Der Standardwert ist heute in der Regel 60. Für viele Desktop-PCs hat sich dies als guter Kompromiss herausgestellt.
Eine Änderung des Wertes von »swappiness« auf 0 zur Laufzeit gelingt ganz leicht durch den Befehl:
echo 0 > /proc/sys/vm/swappiness
Diese Einstellung überlebt allerdings den Neustart des Systems nicht. Um eine permanente Änderung zu erreichen, bedarf es eines Eintrags in der Konfigurationsdatei »/etc/sysctl.conf« . Setzt der Administrator dort beispielsweise »vm.swappiness = 0« , versucht der Kernel vor allem die Pages der Anwendungen im Hauptspeicher zu halten. Damit sollte das Problem eigentlich gelöst sein.
Doch leider zeigen die Ergebnisse weiter unten, dass sich in den Implementierungen einiger Distributionen große Unterschiede auftun. Zudem verändert »swappiness« das Verhalten für alle Anwendungen in gleicher Weise. Gerade im Unternehmensumfeld sind aber einige wenige Anwendungen besonders wichtig. Der »swappiness« -Ansatz kann nicht verhindern, dass ein Verdrängungswettbewerb zwischen Anwendungen entsteht, wenn auf einem System mehrere große Anwendungen laufen. Nur eine sorgfältige Verteilung der Anwendungen kann hier Abhilfe schaffen.
Gorman-Patch
Der letzte Ansatz, der derzeit eine zumindest teilweise Lösung des Verdrängungsproblems verspricht, ist erst seit Linux 3.11 Teil des offiziellen Kernels: Das Patch des Entwicklers Mel Gorman optimiert das Verhalten der Auslagerung bei parallelem I/O [13].
Erste Ergebnisse zeigen, dass die Heuristiken, die in dieses Patch eingeflossen sind, tatsächlich die Performance der Anwendungen verbessern, wenn paralleler I/O erfolgt. Offen ist allerdings noch, ob dieses Patch das Problem auch behebt, wenn die Anwendungen zum Zeitpunkt des Platten-I/O – beispielsweise nachts – inaktiv waren. Sehen die Anwender dann morgens erst einmal deutlich verschlechterte Performance, weil die benötigten Pages ausgelagert waren?
Der praktische Nutzen dieser Ansätze lässt sich aus unterschiedlichen Perspektiven bewerten. Die obigen Abschnitte haben schon einige Kriterien genannt. Ein Patchen des Kernels verbietet sich aus organisatorischen und (Support-)rechtlichen Gründen im produktiven Betrieb per se, sodass die erste wichtige Frage ist, ob eine Änderung im Code der Anwendungen nötig wird. Alle Ansätze, die dies erfordern, sind aus Administratoren-Sicht kaum praktikabel.
Auf der anderen Seite kann man bei Änderungen am Kernel den Nutzen meist nicht direkt ablesen, sondern nur im Betrieb ermitteln. Deshalb zeigt dieser Artikel im Folgenden für das gleiche Umfeld wie oben, welche Auswirkungen die genannten Änderungen haben. Aus diesen experimentellen Ergebnissen und den grundsätzlichen Eigenschaften der Ansätze ergibt sich schließlich ein Gesamtbild, das eine Bewertung erlaubt.
Messergebnisse
Die Messergebnisse sind in Abbildung 4 dargestellt. Die Begrenzung der Größe des Pagecache zeigt das erwartete Verhalten: Die Anwendungen werden auch bei massivem parallelem I/O nicht wesentlich langsamer. Ebenso verhält sich das Kernelpatch von Mel Gorman: In SLES 11 SP 3 ist es bereits verfügbar und erlaubt eine gute, konstante Performance der Anwendungen.
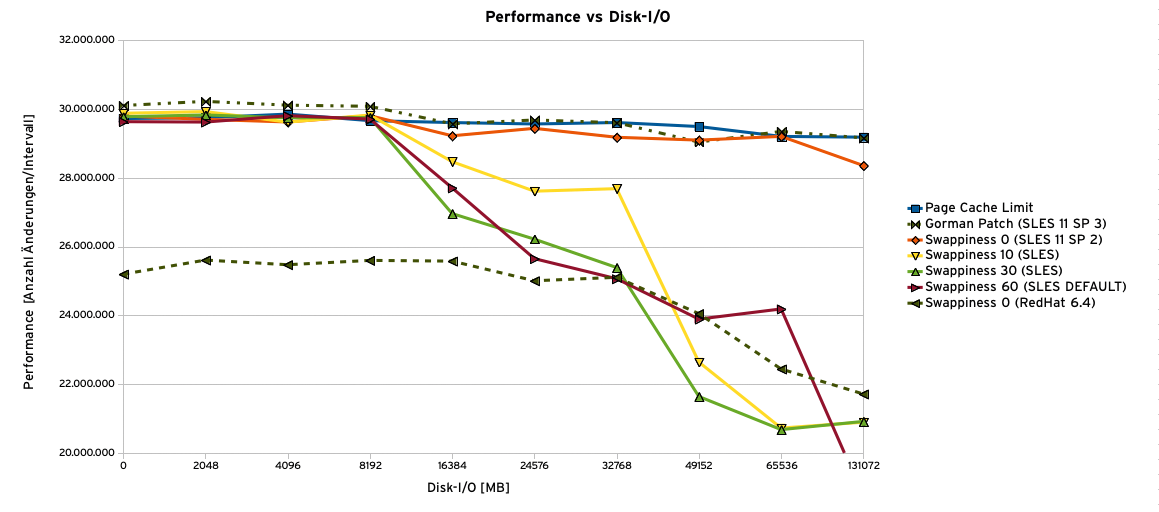
Abbildung 4: Messungen zur Bewertung der Kernelanpassungen (angegeben sind statistische Mittel über mehrere Versuchsdurchläufe).
Auch das Setzen von »swappiness = 0« unter SLES 11 SP 2 und 11 SP 3 schützt die Anwendungen offenbar ausreichend. Erstaunlicherweise verhält sich Red Hat Enterprise Linux 6.4 anders: Die Implementierung scheint merklich anders zu sein und Anwendungen nicht vor aggressivem Auslagern zu schützen, im Gegenteil. Die von 0 verschiedenen Werte von »swappiness« zeigen keine klare Tendenz. Zwar führen sie zu einer eindeutig schlechteren Leistung der Anwendung mit wachsendem I/O, man kann aber kaum systematisch zwischen den kleineren Werten wie 10 oder 30 und dem Defaultwert von 60 unterscheiden. Es scheint, als wäre die entscheidende Frage, ob »swappiness« auf 0 gesetzt wird oder nicht. Zwischenwerte wirken sich kaum aus.
Die Tabelle 1 fasst alle Ansätze zusammen und gibt einen Überblick über deren Vor- und Nachteile sowie die gemessenen Ergebnisse. Es zeigt sich, dass derzeit keine Lösung existiert, die alle Aspekte des Verdrängungsproblems beseitigt. Am nächsten scheint noch eine korrekte Implementierung von »swappiness« zu kommen – und möglicherweise in Zukunft der Ansatz von Mel Gorman. Aber selbst bei diesen beiden Methoden werden Administratoren auch bei Systemen mit sehr großem Hauptspeicher nicht umhinkommen, ein wachsames Auge auf die Speicherverwendung ihrer Anwendungen zu haben.
Tabelle 1
Strategien im Überblick
|
Ansatz |
Werkzeug |
Vorteil |
Nachteil |
|---|---|---|---|
|
Fokus auf eigene Anwendung |
|||
|
Pages festpinnen |
»mlock()« |
erfüllt seinen Zweck |
erfordert Code-Änderung; massiver Eingrff; unflexibel |
|
Huge Pages |
Performanceverbesserung |
erfordert Code-Änderung; massiver Eingrff; unflexibel; viel Administration |
|
|
Reduktion der Größe |
»mmap()« |
eleganter Zugriff; Performancesteigerung |
erfordert Code-Änderung; verschiebt die Auslagerung nur |
|
Fokus auf andere Anwendungen |
|||
|
Ressourcenlimits setzen |
»setrlimit» |
– |
erfordert Code-Änderung in fremder Anwendung; massive Störung der Anwendung bis hin zum Abbruch; verhindert nicht Anwachsen des Pagecache |
|
Cgroups |
|
flexibel; auch ohne Code-Änderung |
Einstellungen unklar; verhindert nicht Anwachsen des Pagecache |
|
Fokus auf den Kernel |
|||
|
Pagecache klein halten |
Direct I/O |
Performancesteigerung für Anwendung möglich durch eigene Caching-Mechanismen |
erfordert Code-Änderung in fremder Anwendung; erfordert eigene Cacheverwaltung; verhindert nicht Anwachsen des Pagecache; eine einzelne Anwendung ohne Direct-I/O kann alle Vorteile zunichte machen |
|
Pagecache begrenzen |
Kernelpatch |
wirkt (belegt durch andere Unix-Systeme); keine Eingriffe in Anwendungen nötig |
kein allgemeiner Support, Verlangsamung bei massivem I/O |
|
Swapbereich klein |
Admin-Tools |
wenig Swap-out |
keine Lösung für normale Systeme; Gefahr von OOM-Situationen |
|
Auslagerung konfigurieren |
Swappiness |
keine Eingriffe in Anwendungen nötig; wirkt bei Wert 0 |
nicht bei allen Distributionen funktionsfähig; keine graduelle Anpassung |
|
Kswapd anpassen |
Kernelpatch |
erfüllt seinen Zweck;keine Eingriffe in Anwendungen nötig; geringe Nebenwirkungen |
erst ab Kernel 3.11 offiziell verfügbar; wirkt vermutlich nur bei explizit zeitgleichem I/O (“heißem Speicher”) |
Fazit
Die Verdrängung der Anwendungen aus dem RAM erweist sich selbst bei sehr gut ausgestatteten Systemen immer noch als Problem. Obwohl bei solchen Systemen Speicherknappheit kein Thema mehr sein sollte, kann die grundsätzlich sinnvolle intensive Nutzung des Speichers durch den Linux-Kernel zu merklichen Performanceproblemen bei den Anwendungen führen. Linux ist hier im Vergleich zu anderen Betrirebssystem nicht schlecht aufgestellt, doch kann es wegen der Linux-typischen Vielfalt an Lösungsansätzen sinnvoll sein, das Verhalten des Kernels und der eingesetzten Anwendungen genau zu untersuchen, um auch große Systeme mit guter, gleichbleibender Performance zu betreiben.
Erfahrungen mit solchen Systemen und den Tests, die diesem Artikel zugrunde liegen, können Interessierte beim so genannten Test-Drive machen, den das SAP Linuxlab im SAP Community Network (SCN, [14]) bereitstellt. (mhu)
Infos
- SAP HANA Enterprise-Platform 1.0 Product Availability Matrix: http://www.saphana.com/servlet/JiveServlet/previewBody/2382-102-4-7773/HANA%201.0%20PAM.pdf
- A. Siberschatz, G. Gagne, P.B. Galvin, “Operating System Concepts”: Wiley, 2005
- D. Magenheimer, C. Mason, D. McCracken, K. Hackel, “Transcendent memory and Linux”: Proceedings of the Linux Symposium 2009, pp. 191-200: http://oss.oracle.com/projects/tmem/dist/documentation/papers/tmemLS09.pdf
- AMD Inc., “AMD64 Architecture Programmer’s Manual Volume 2: System Programming”, Kap. 5.1: http://support.amd.com/TechDocs/24593.pdf
- R. Love, “Linux Kernel Development”: Addison-Wesley, 2010
- Manpage zu »mlock«
- M. Gorman, Linux Weekly News, “Huge-Pages”-Serie: http://lwn.net/Articles/374424/
- Manpage zu »mmap«
- W.R. Stevens, St. A. Rago, “Advanced Programming in the Unix Environment”: Addison-Wesley, 2008, Kap. 14.9
- Cgroups-Dokumentation: https://www.kernel.org/doc/Documentation/cgroups/cgroups.txt
- Manpage zu »open«
- J. Corbet, “2.6 swapping behaviour”: http://lwn.net/Articles/83588/
- M. Gorman, “Reduce system disruption due to kswapd”, Patchset unter: https://lkml.org/lkml/2013/3/17/50, siehe auch http://lwn.net/Articles/551643/
- SAP Linuxlab, Mini SAP:http://www.sap.com/minisap





