
© serezniy, 123RF.com
Kernelupdates: Fluch oder Segen, Notwendigkeit oder einfach nur ein Ärgernis? Welche Fallstricke gibt es und wie kann der Systemadministrator Aufwand und Risiko minimieren? Das Linux-Magazin weiß Rat.
Der Austausch des Linux-Kernels ist wie ein Motorwechsel beim Auto. Er lässt sich nicht zwischen Tür und Angel erledigen und erfordert Vorbereitung. Dem Eingriff folgt häufig ein kompletter Reboot des Servers. Linux-Installationen mit Systemen von drei-, vier- oder gar fünfstelliger Anzahl sind keine Seltenheit mehr. Der operative Aufwand, ein Kernelupgrade in dieser Größenordnung durchzuführen, ist entsprechend groß und erfordert erheblichen Zusatzaufwand für das Gelingen. Aber sogar im kleinen Rahmen stellt sich die Frage, welche ungewollten oder unerwarteten Änderungen der neue Betriebssystemkern mitbringt.
Touch a running System
Gründe für einen Wechsel des Kernels gibt es gleich mehrere: Typische Szenarien sind Bugfixes oder das Stopfen von Sicherheitslöchern (Update), daneben aber auch externe Anforderungen, etwa durch Software, die nicht zum Lieferumfang der Linux-Distribution zählt und neuere Kernelfeatures verlangt (Upgrade). Die manchmal rasante Entwicklung der Hardware erfordert nicht selten ebenfalls einen neueren Betriebssystemkern. Nur in den seltensten Fällen kann ein Admin das Kernelupgrade aus seinem Aufgabenkatalog streichen, also sollte er es richtig machen. Der folgende grobe Vorgehensplan betrachtet drei Aspekte: Wie, Wann und Wo.
Kernelupdates lassen sich in zwei Arten unterteilen: offline und online. Zur letzteren zählt der Austausch einzelner Kernelmodule oder sogar ganzer Funktionen, was das Tool Ksplice ermöglicht. Einfacher ist aber zunächst die Offline-Variante zu erklären. Hier wandert der neue Kernel auf das System und ein Reboot aktiviert ihn.
Die Fragestellungen lauten dabei: Wie den neuen Kernel erzeugen? Wie wandert er auf den Server und wann? Wann findet der Reboot zur Aktivierung statt und auf welchen Systemen (wo)? Das Offline-Verfahren ist technisch die beste Variante, weil sich das System danach in einem sauberen und definierten Zustand befindet. Allerdings bedeutet der Reboot einen Ausfall der Dienste des neu zu startenden Servers.
Lassen Dienstleistungsverträge und Wartungsfenster dies nicht zu, müssen Alternativen her. Ist ein Dienst wichtig, sichert man ihn meist ohnehin durch Hochverfügbarkeits-Setups. Im Fall des Kernelupdate kann der Admin auf diesen Mechanismus zurückgreifen. Bis zum fertigen Kernel-Rollout befindet sich der HA-Verbund dabei in einem Mischbetrieb: Systeme, die identische Aufgaben wahrnehmen, unterscheiden sich in der Schlüsselkomponente Kernel. Aus mehreren Gründen empfiehlt es sich, diesen Zustand möglichst kurz zu halten.
Rückfahrkarte
Das Testen eines neuen Kernels vor dem Rollout gehört für Sysadmins zum guten Ton. Neben dem eigentlichen Funktionstest gehört das Ausprobieren des Upgrade-Prozesses selbst dazu, ebenso ein Fallback. Sind Kernelmodule von Drittherstellern im Spiel, lohnt es sich, deren Kompatibilitätsmatrix zu prüfen. Die Theorie kann aber den Praxistest nicht ersetzen.
Die Eleganz von Linux besteht darin, dass das System problemlos mehrere Betriebssystemkerne vorhält (Abbildung 1). So kann der Admin den Rechner bequem in den vorherigen Zustand zurückversetzen, falls nötig. Es empfiehlt sich, Kernelupdates vom Patchen der sonstigen Systemkomponenten so weit wie möglich zu trennen. Zum einen lässt sich der Userspace online patchen, was den Betrieb deutlich geringer stört als der Austausch des Kernels. Zweitens bleiben die Änderungen am System dadurch klar separiert. Im Falle eines Fehlverhaltens lässt sich einfacher feststellen, ob es auf den neuen Kernel oder auf andere Systemänderungen zurückzuführen ist.
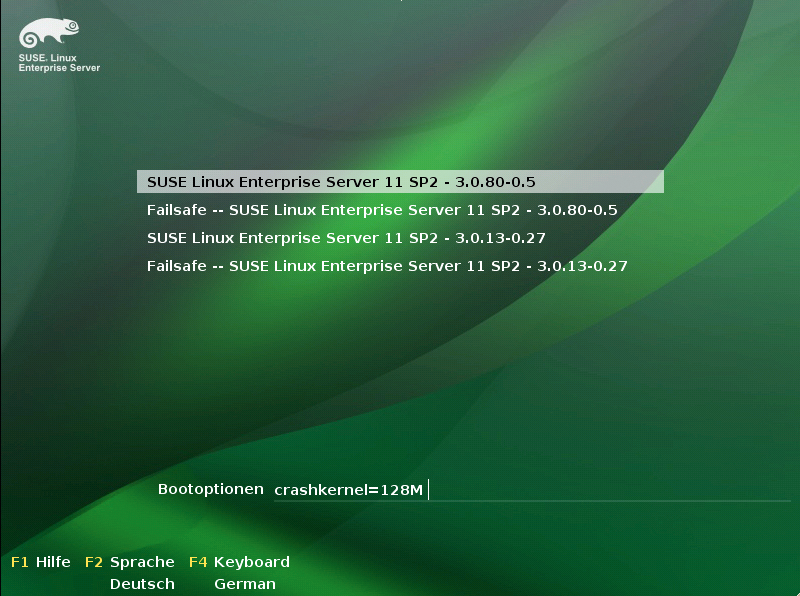
Abbildung 1: Beim Booten kann der Admin den zu startenden Kernel auswählen und gegebenenfalls wieder auf die bewährte Version zurückgreifen, hier beim SLES 11 SP2.
Alles neu
Woher weiß der Admin, welche Änderungen seine Server durch den neuen Kernel erfahren? Etwas zu optimistisch ist der Ansatz, einfach den Betriebssystemkern auszutauschen und hinterher zu prüfen, ob der Fix wirkt oder die Software nun erwartungsgemäß arbeitet. Gibt es Release-Notes des Linux-Distributors, empfiehlt sich deren Lektüre. Wer es ganz genau wissen möchte, der organisiert sich den Quelltext der zu vergleichenden Kernel und holt sich die gewünschten Informationen auf diesem Level ab.
Kommt vorwiegend eine bestimmte Distribution zum Einsatz, lohnt es sich, Informationen bezüglich ABI- und API-Stabilität einzuholen. Im günstigsten Fall verfügt der Hersteller über eine Liste von Funktionen, deren Schnittstellen für einen bestimmten Releasezyklus konstant bleiben. Für Software, die genau dieses ABI benutzt, ist eine Änderung des Kernels an sich transparent. Alle anderen Programme müssen sich wohl oder übel Tests unterziehen.
In Enterprise-Setups finden sich grundsätzlich zwei Ansätze zum Thema Schnittstellen-Stabilität. Red Hat publiziert eine Liste von Funktionen (siehe Listing 1), die der Distributor während einer Major-Release konstant hält [1]. Mit Lebenszyklen von zehn Jahren für aktuelle RHEL-Versionen [2] bedeutet dies zumindest erheblichen Aufwand und kann sogar hinderlich sein. Beispielsweise basiert RHEL 6 auf dem Kernel 2.6.32. Bestimmte Funktionen und Features aus neueren Kernels lassen sich rückportieren, aber ein echter 3.x-Kernel wird trotzdem nicht daraus.
Listing 1
ABI-Whitelist für RHEL 6.3 (x86_64)
01 [root@rhel]# head /lib/modules/kabi-rhel63/kabi_whitelist_x86_64 02 [rhel6_x86_64_whitelist] 03 ___pskb_trim 04 __alloc_pages_nodemask 05 __alloc_percpu 06 __alloc_skb 07 __bdevname 08 __bitmap_and 09 __bitmap_complement 10 __bitmap_empty 11 __bitmap_weight 12 [root@rhel ~]# wc -l /lib/modules/kabi-rhel63/kabi_whitelist_x86_64 13 1607 /lib/modules/kabi-rhel63/kabi_whitelist_x86_64
Oracle und auch Suse gehen einen anderen Weg. Hier lautet das Versprechen, das Userspace-ABI konstant zu halten, nicht aber unbedingt die Schnittstellen innerhalb des Kernels ([3], [4]). Das ermöglicht diesen Distributoren, neuere Kernel einzusetzen und den Aufwand fürs Backporting deutlich zu reduzieren. Das hat aber auch seinen Preis, der sich in vermehrten Tests mit Software von Drittherstellern niederschlägt, wenn diese Kernelmodule benutzt.
Unterbrechungsfrei
Das Linux-Magazin 08/08 [5] stellte das Ksplice-Verfahren [6] vor. Unter bestimmten Voraussetzungen kann der Admin damit den Kernel ohne den lästigen Reboot patchen. Das Tool analysiert dabei alten und neuen Code auf der Objektebene. Auszutauschende Funktionen landen in einem Kernelmodul, das das Werkzeug in den laufenden Kernel lädt und aktiviert (Abbildung 2).

Abbildung 2: Paradoxes auf einem per Ksplice gepatchten System: Die effektive Kernelversion ist höher als die des eigentlich installierten Pakets.
Seit 2011 gehört diese Technologie Oracle [7]. Fedora und Ubuntu-Desktop-Benutzer können kostenfrei der Online-Patcherei frönen. Im Enterprise-Umfeld bekommt es der zahlende Oracle-Linux-Admin als kostenlose Zugabe zum UEK (Unbreakable Enterprise Kernel). Auch die Red-Hat-Fans sparen sich gegen Entgelt einige Reboots.
Suse- beziehungsweise SLES-Fans schienen lange Zeit außen vor. Die Teilnehmer der Susecon 2012 durften aber schon mal durch das Schlüsselloch einen Blick auf Version 12 der Enterprise-Produkte werfen: Ksplice – besser gesagt die zugrunde liegende Technik – soll es dann dort ebenfalls geben, und zwar direkt aus dem Hause Suse. Unabhängig vom verwendeten Linux sollte dem Admin aber klar sein, dass die Aufgabe von Ksplice primär das schnelle und schmerzfreie Patchen von Sicherheitslücken im Kernel ist. Operative Notwendigkeiten und Sicherheitsanforderungen lassen sich damit unter einen Hut bringen.
Das Online-Patchen ist dazu gedacht, einen Kernel jahrelang laufen zu lassen und immer neue Ksplice-Updates draufzupacken. Dennoch gibt es technische Grenzen für Online-Updates. Generell lässt sich sagen, dass ein Upgrade von Kernelversion 3.x auf 3.y in Ksplice nicht vorgesehen ist. Größere Umbauten im Kernel würden den Aufwand ins Unermessliche treiben und fallen daher ebenfalls flach. Auf der Habenseite bleibt das größere Zeitfenster bis zum unausweichlichen Reboot, während aktuelle Sicherheitslücken dennoch geschlossen sind.
Beispiel Sicherheitslücke
Die in CVE-2013-2094 [8] dokumentierte Sicherheitslücke eignet sich hervorragend zum Durchspielen der verschiedenen Ansätze beim Kernelupdate. Der Einfachheit halber beschränken sich die weiteren Ausführungen auf Red Hat und Suse. Das genügt für diesen Artikel, heißt aber nicht, dass die anderen Distributionen von dem Sicherheitsproblem verschont geblieben sind.
Ausgangspunkt ist ein Fehler in der Funktion »perf_swevent_init()« , durch den ein lokaler Anwender Rootrechte erlangen kann. Als im Mai 2013 ein passender Exploit veröffentlicht wurde, waren 3.x-Kernel betroffen, wenn sie älter als Version 3.8.9 waren. SLES 11 SP1 basierte auf 2.6.32 und blieb damit außen vor. RHEL 6, ebenfalls mit einem Kernel auf 2.6.32-Basis ausgestattet, hatte diesen Bug allerdings rückportiert und stand dadurch unter Zugzwang. Analoges galt für die RHEL-Klone oder den auf 3.0 beruhenden SLES 11 SP2. Eine recht vollständige Liste der betroffenen Linuxe findet sich unter [8].
Kurz nach Bekanntwerden der Sicherheitslücke stellten die Distributoren aktualisierte Pakete bereit, die einen neuen Betriebssystemkern enthielten ([9], [10]). Dank Open Source kann der kundige, aber misstrauische Admin prüfen, ob der Fehler auch tatsächlich behoben ist (Listing 2). Im vorliegenden Fall gab es keinen Grund zur Beanstandung, der Fix war identisch mit der entsprechenden Änderung im Vanilla-Kernel.
Listing 2
Patch für CVE-2013-2094
01 $ diff -Nur linux-2.6.32-358.6.1.el6/ linux-2.6.32-358.6.2.el6/
02 --- linux-2.6.32-358.6.1.el6/kernel/events/core.c 2013-03-29 17:57:44.000000000 +0100
03 +++ linux-2.6.32-358.6.2.el6/kernel/events/core.c 2013-05-14 21:09:32.000000000 +0200
04 @@ -5198,7 +5198,7 @@
05
06 static int perf_swevent_init(struct perf_event *event)
07 {
08 - int event_id = event->attr.config;
09 + u64 event_id = event->attr.config;
10
11 if (event->attr.type != PERF_TYPE_SOFTWARE)
12 return -ENOENT;
Damit war der Weg frei zum Offline-Patchen der Systeme. Was sollten aber Admins tun, wenn ein Reboot nicht so schnell möglich war? Die Versorgung der Ksplice-Benutzer erfolgte zügig [11]. Daneben gibt es aber Systeme, für die weder Ksplice noch Reboot in Frage kommen. Nichtstun ist nur eine Option, wenn die Sicherheit und Integrität der Systeme absolut keine Rolle spielt. Selbst eine Post-mortem-Analyse wäre bei dieser Lücke nicht trivial, da das Ausnutzen der betroffenen Kernelfunktion keinen Eintrag im normalen Systemprotokoll erzeugt. Selbst für diese Nachforschungen braucht der Admin daher die Software Systemtap [12] und muss Vorbereitungen treffen [13].
Eine genaue Analyse des Problems zeigt, dass sich das Sicherheitsrisiko auch ohne Reboot und Ksplice minimieren lässt: Das Setzen der Sysctl-Variablen »kernel.perf_event_paranoid« auf den Wert »2« schließt zwar nicht das Loch an sich, macht aber den bekannten Exploit wirkungslos (Abbildung 3). Damit sind die entsprechenden Server wenigstens vor Sikript-Kiddies und Attacken von Anfängern sicher. Ein Reboot ist damit nicht unmittelbar notwendig – aber nur aufgeschoben: Im hier dargestellten Beispiel empfiehlt es sich, die Syscontrol-Änderung nach Aktivieren eines aktualisierten Kernels rückgängig zu machen.
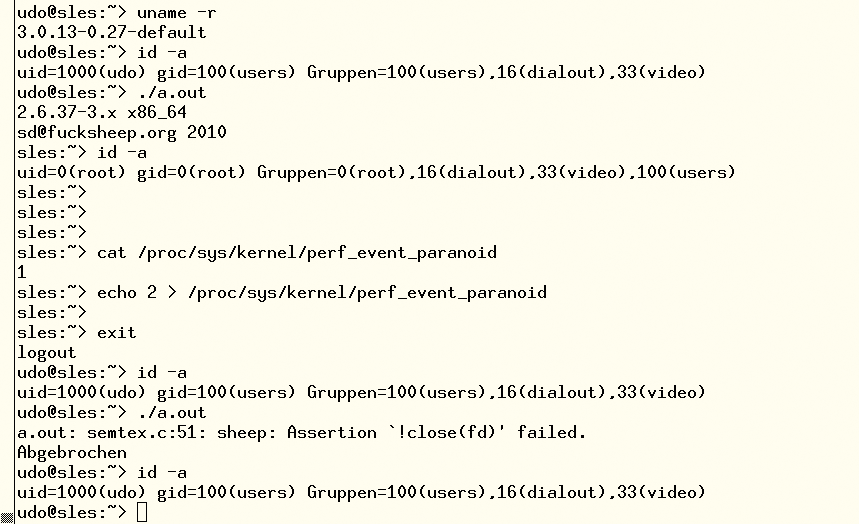
Abbildung 3: Der öffentlich zugängliche Exploit für CVE-2013-2094 besorgt einem lokalen Anwender eine Rootshell. Linderung schafft eine Änderung der Sysctl-Konfiguration.
Das Ausliefern und Aktivieren neuer Kernel auf laufenden Systemen ist nur ein Teil der notwendigen Arbeit. Daneben gibt es Systeme, die zu einem späteren Zeitpunkt ein Linux bekommen oder auf anderem Wege im Rechnerverbund auftauchen. Es steht außer Frage, dass solche Rechner ebenfalls den als aktuell eingestuften Betriebssystemkern verwenden sollten. Voraussetzung dafür ist, Kernelupgrades in die Installationsprozesse und -routinen zu integrieren.
Im einfachsten Fall genügt eine Patch-Prozedur als Teil der Postinstallation. In sicherheitskritischen Umgebungen kann dies heißen, dass die Ausstattung des Servers mit Linux in einem speziellen und abgesicherten Netzwerk abläuft und die Integration in die Produktion erst nach vollständigem Patchen erfolgt.
Alternativ ist es möglich, ein bereits angepasstes Image zur Installation zu verwenden. Je nach Distribution und Deployment-Methode sind dem aber Grenzen gesetzt: Die von Suses Autoyast verwendeten Images beispielsweise sind per Prüfsumme und Signatur gesichert. Eine – wenn auch gut gemeinte – Manipulation ist ohne Herstellersupport nicht möglich.
C-Library zum Schluss
Vorsichtige Admins dehnen die Kernelupgrade-Problematik in Richtung C-Bibliothek aus. Neben dem Betriebssystemkern ist diese Library eine der tragenden Säulen eines Linux-Systems. Technisch gesehen zeigt sich die Situation hier aber entspannter. Ein Austausch ist während des Betriebs möglich. Sobald sich die Bibliothek auf dem System befindet, steht sie neu gestarteten Applikationen zur Verfügung. Bereits laufende Anwendungen verwenden allerdings bis zu einem Neustart den alten Code.
Obwohl diese Inkonsistenz selbst beim Co-Hosting von komplexen Anwendungen keine Probleme machen sollte, bleibt ein mulmiges Gefühl. Kommt noch »nscd« als Caching-Software zum Einsatz, ist dessen Neustart beim Glibc-Update ebenfalls erforderlich. Die Erfahrung zeigt außerdem, dass Kernelupdates weitaus häufiger anfallen als Libc-Patches. Wer die Betriebsunterbrechungen minimieren möchte, tauscht also die C-Bibliothek bei der nächsten fälligen Kernelauffrischung einfach mit aus. Dies gilt mit Abschwächung ebenfalls für die Ksplice-Gemeinde. Dort treten die Reboots ja seltener auf, aber eventuell häufig genug, um die Systembibliothek ebenfalls zu aktualisieren.
Fazit
Kernelupgrades greifen tief in das Linux-System ein. Bei genauerem Hinschauen zeigt sich, dass nicht jedes Update dem anderen gleicht: Ein kritischer Bug kann einen Massen-Reboot notwendig machen oder nur Konfigurationsänderungen auf Betriebssystemebene auslösen, die weit weniger schmerzvoll sind.
Wie man es auch dreht und wendet: Um Kernelupdates kommt kein Administrator herum. Idealerweise hat er mehrere Prozeduren und Arbeitsabläufe im Repertoire, um den unterschiedlichen Upgrade-Gegebenheiten zu begegnen. Wie so oft im Leben gilt: Das Glück hilft dem, der vorbereitet ist. (mhu)
Infos
- Jon Masters, “Red Hat Driver Update Packages”: http://people.redhat.com/jcm/el6/dup/docs/dup_book.pdf
- Red Hat Enterprise Linux Life Cycle: http://access.redhat.com/support/policy/updates/errata/
- “Suse releases hardened 3.0-based kernel to the enterprise”: https://www.suse.com/communities/conversations/suse-releases-hardened-3-0-based-kernel-to-the-enterprise/
- Unbreakable Enterprise Kernel: http://docs.oracle.com/cd/E37670_01/E37355/html/ol_about_uek.html
- Nils Magnus, “Zurechtgeflickt”: Linux-Magazin 08/08, S. 76
- Ksplice: http://www.ksplice.com
- Oracle kauft Ksplice: http://www.oracle.com/us/corporate/press/435791
- CVE-2013-2094: http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2013-2094
- RHSA-2013-0830: http://rhn.redhat.com/errata/RHSA-2013-0830.html
- SU-2013:0819-1: http://lists.opensuse.org/opensuse-security-announce/2013-05/msg00008.html
- “New updates available via Ksplice (CVE-2013-2094)”: http://oss.oracle.com/pipermail/el-errata/2013-May/003467.html
- Systemtap: http://sourceware.org/systemtap/
- “Does CVE-2013-2094 affect Red Hat Enterprise Linux and Red Hat Enterprise MRG?”: http://access.redhat.com/site/solutions/373743





