
© ariadna de raadt, 123RF.com
Auch gut 40 Jahre nach der ersten E-Mail gibt es immer noch gute Gründe, einen eigenen IMAP- oder SMTP-Server zu betreiben, zumal diverse Linux-Projekte das so einfach wie nie zuvor machen. Aber Mailserver, die selbst moderne redundante Storage-Backends nutzen, sucht der Admin vergebens.
Kleinere Unternehmen mit weniger als 100 E-Mail-Benutzern und ohne allzu strenge Sicherheitsrichtlinien können es sich wahrscheinlich leisten, einen der Clouddienste von Google&Co. für ihre Mails in Anspruch zu nehmen. Doch auch gut vier Jahrzehnte nach der Erfindung der E-Mail ist das Ende des eigenen Mailservers im Unternehmen noch lange nicht gekommen.
Server ohne Storage-Anbindung
Stichwörter wie Patriot Act und Compliance, aber auch das Sicherheitsbedürfnis von Admins, Unternehmen und Daten liefern Argumente genug, einen skalierbaren, hochverfügbaren Mailserver vor Ort zu betreiben – und die gängigen Linux-Tools machen das mittlerweile einfach. Eigentlich hat sich ja auch in Sachen Storage-HA dank Cloud Computing und der vielen Managementtools viel getan. Schade nur, dass die gängigen Mailserver diese neuen, flexiblen Funktionen nicht nutzen. Dieser Artikel zeigt, wie sich einfache Mailserver mit Hochverfügbarkeitsfunktionen aufsetzen lassen, und erklärt, woran es fehlt, was Scale-out bedeutet und warum beim IMAP-Server alles so schwierig ist, zumindest wenn er ohne größere Vorausplanung kommen soll.
Sendmail, Exim, Postfix, Cyrus, Courier, Dovecot
Ausgereift – dieses Attribut dürfte das am besten passende für alle Server sein, die auf Linux die klassischen Dienste rund um E-Mail anbieten. SMTP erledigen Sendmail, Exim oder Postfix; für POP3 existieren ebenso viele Lösungen wie für IMAP-Server. Selbst Groupware-Suites greifen oft genug auf die Oldies zurück. Nur die integrierten HA- oder Scale-out-Konzepte sucht man bei diesen Lösungen immer noch und durch die Bank vergeblich. Es gilt deshalb, vorhandene Komponenten wie den Linux-HA-Clusterstack [1] so mit den alteingesessenen Lösungen zu kombinieren, dass am Ende eine zuverlässige und stabile Gesamtkonstruktion entsteht.
Wer als Administrator die Installation eines hochverfügbaren und ordentlich skalierbaren Mail-Setups vor sich hat, tut gut daran, zunächst die konkreten Anforderungen an die Umgebung zu definieren. Die Möglichkeiten sind hier fast grenzenlos; doch bringt es niemandem etwas, ein Monster-Setup für den Installateursbetrieb mit 20 Mitarbeitern zu schaffen. Denn das ist deutlich komplexer und schwieriger zu warten, als es ein Standard-Setup wäre, das die gestellten Anforderungen genauso gut erfüllt.
Ein simples HA-Beispiel
Das folgende Beispiel geht zunächst von einem einfachen Mailserver mit Postfix und Dovecot aus, dem es schlicht an der Verfügbarkeit fehlt. Wer einen klassischen Mailserver hochverfügbar machen möchte, muss sich zunächst mit den Daten selbst beschäftigen. Um die geht es bei Mailservern ja vorrangig, die Software selbst ist nur dazu da, Mails zu empfangen oder zu versenden (SMTP) und sie den Benutzern anschließend zur Verfügung zu stellen (POP3 oder IMAP). Die gewünschte Redundanz erreicht der Admin bei Mailservern schon dadurch, dass er zwei gleichwertige Systeme bereithält, von denen jeweils eines den aktiven Knoten gibt, auf dem die benötigten E-Mail-Dienste laufen. Solche Aktiv-passiv-Cluster sind aber weder effizient noch in irgendeiner Weise sinnvoll. Obwohl ein Anachronismus, bieten sie aber trotzdem eine verbreitete, weil einfache Lösung des Problems.
DRBD
Damit das Prinzip funktioniert, müssen beide Knoten eines solchen Clusters unabhängig voneinander über den gleichen Datensatz verfügen. Dahin führen heute zwei Wege: Wer ein klassisches SAN oder NAS sein Eigen nennt und sich auf die interne Redundanz der Lösung verlässt, kann dieses Problem schon als gelöst betrachten, denn viele Hersteller proprietärer Produkte machen das. Solange der Speicher seine Daten per NFS oder I-SCSI zur Verfügung stellt, lässt sich das Datenverzeichnis von beiden Servern aus als Mount (NFS) oder Target (I-SCSI) einbinden.
Wer kein SAN hat, legt die Daten auf den Knoten des Clusters selbst ab. Dann kommen Lösungen wie DRBD in Frage, die vor allem in kleinen Setups gute Dienste leisten. Die minmale Ausführung eines solchen Mailserver-Clusters sind zwei typische 19-Zoll-Pizzaboxen, die sich im Rack in einer Höheneinheit unterbringen lassen (Abbildung 1). Zwei Platten pro Server mit jeweils 3 TByte Kapazität in einem Raid-1-Verbund bieten für kleine und mittlere Mail-Setups bereits genug Speicher.

Abbildung 1: Server im typischen 19-Zoll-Pizzabox-Format, aber mit halber Tiefe, genügen in der Regel für kleine und mittelgroße Mail-Setups völlig.
Mit Hilfe von DRBD, das eine Art Raid 1 für TCP/IP anbietet, würde der komplette Datensatz dann zwischen den Rechnern in einem synchronen Zustand gehalten. Listing 1 enthält die Konfiguration für eine beispielhafte DRBD-Ressource, wie sie in einem solchen Setup zum Einsatz kommen könnte (Abbildung 2). Genauere Informationen zu DRBD finden sich unter [2].
Listing 1
Ein DRBD-Beispiel
01 resource mail {
02 meta-disk internal;
03 device minor 1;
04
05 on host1 {
06 address ipv4 192.168.42.1:7858;
07 disk "/dev/system/mail";
08 }
09 on host2 {
10 address ipv4 192.168.42.1:7858;
11 disk "/dev/system/mail";
12 }
13 }

Abbildung 2: DRBD kümmert sich in einem Zwei-Knoten-Cluster darum, dass die Daten auf beiden Hosts gleichermaßen zur Verfügung stehen.
SMTP-, POP- und IMAP-Server
Ist das Speicherproblem gelöst, steht im nächsten Schritt die Wahl des Mailservers auf dem Programm. Wer Wert auf Hochverfügbarkeit legt, achtet weniger auf die Feature-Freudigkeit der Entwickler, sondern vielmehr auf das gute Zusammenspiel mit den üblichen Linux-HA-Tools, besonders die Kooperationsbereitschaft mit dem Clustermanager Pacemaker. Denn der ist für klassische Linux-HA-Setups das Maß aller Dinge: Lange hat es gedauert, doch jetzt steht mit ihm ein Clustermanager mit brauchbarem Funktionsumfang zur Verfügung, der über die Grenzen der Distributionen hinaus Anerkennung gefunden hat.
Genau der muss immer ran, wenn Linux-Server hochverfügbar sein sollen. Pacemaker tritt typischerweise als Wachposten auf: Er prüft, ob die Knoten des Clusters noch funktionieren und ob der Cluster alle ihm zugewiesenen Dienste wie erwartet anbietet. Ist das nicht so, versucht er von sich aus, einen funktionstüchtigen Zustand wieder herzustellen. Damit der Clustermanager das kann, muss er allerdings auch wissen, ob die verwalteten Programme funktionieren wie gewünscht (Abbildung 3). Mehr Informationen und umfangreiches Hintergrundwissen zu Pacemaker gibt es unter [3], [4] und [5].
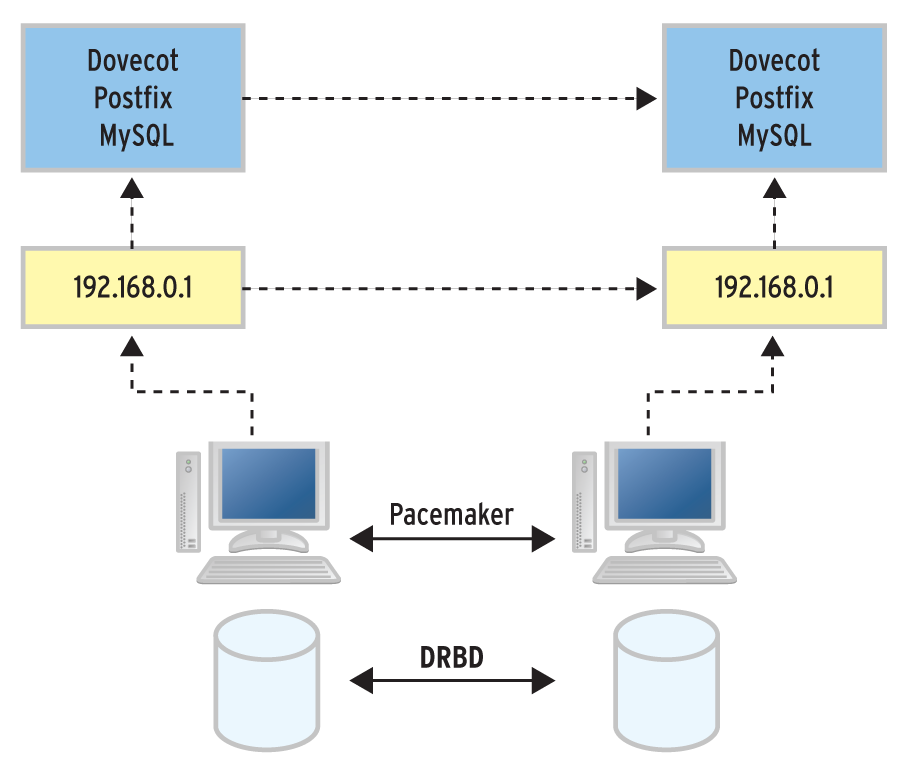
Abbildung 3: Klassische HA-Setups für Mailserver sind in Linux mit Bordmitteln gut zu konstruieren.
Pacemaker-Interna: Resource Agents
Genau hier wird es kompliziert – auch im Hinblick auf Mailserver. Es leuchtet ein, dass Pacemaker kein eigenes Interface für jede Software auf dem Markt haben kann, denn dann wäre der Clustermanager vor allem eins: aufgebläht. Die Pacemaker-Entwickler haben sich deshalb eine alternative Herangehensweise ausgedacht und setzen auf die so genannten Resource Agents.
Die meisten Agenten sind Shellskripte, die im Auftrag von Pacemaker die Kommunikation mit einem Stück Software übernehmen. Sie sind verantwortlich dafür, das jeweilige Programm auf Zuruf von Pacemaker zu starten oder zu stoppen; außerdem nutzt Pacemaker die Agents, um herauszufinden, ob ein Programm noch läuft.
Bei Mailservern könnte ein Resource Agent für Exim beispielsweise überprüfen, ob der Exim-Prozess existiert und ob der Mailserver überhaupt noch auf Requests am SMTP-Port reagiert. Klappt die Kommunikation, ist alles in Ordnung – schlägt sie jedoch fehl, müsste Pacemaker entsprechende Maßnahmen in Angriff nehmen.
Das System der Resource Agents ist sehr mächtig, zugleich ist es aber auch die größte Schwachstelle des Linux-HA-Stacks. Denn wie gut Pacemaker sich um ein Programm kümmert, hängt maßgeblich von der Qualität des Agenten ab. Resource Agents kommen typischerweise in drei Geschmacksrichtungen vor: Neben den veralteten Heartbeat-Agenten und den mächtigen OCF-Agents ist die noch immer wichtigste Klasse die der LSB Resource Agents, besser bekannt als Initskripte.
Problemfall Initskripte
Für alle Dienste mit Initskript lässt sich ein entsprechender Eintrag in Pacemaker anlegen. Der Pferdefuß: Liefert der Resource Agent unzuverlässige Resultate, hängt auch Pacemaker in der Luft. Gerade auf Debian-Systemen war es bis vor Kurzem ein gängiges Problem, dass Initskripte das »monitor« -Target nicht beherrschten und beim Aufruf damit eine Fehlermeldung als Rückgabewert gaben.
Die Meldung musste Pacemaker zwangsläufig so deuten, dass die Ressource selbst fehlerhaft ist. Zuverlässiges Monitoring war somit für den Clustermanager unmöglich. Zwar konnte der Administrator das Überwachen einer Ressource ganz deaktivieren, doch brachte er sich damit um einen großen Teil der Pacemaker-Funktionalität.
Agenten-Konsolidierung
Dass Initskripte dem LSB-Standard folgen müssen, ist eine Erkenntnis, die sich in den letzten Jahren glücklicherweise auch bei den Distributoren mehr und mehr durchgesetzt hat, auch bei Debian. Die Initskripte für Sendmail, Exim und Postfix unterstützen die Targets »start« , »stop« und »monitor« jedenfalls zuverlässig; das gilt auch für die gängigen POP3- und IMAP-Server. Wer diese Werkzeuge in Kombination mit einer der gängigen Distributionen einsetzt, ist hinsichtlich der Resource-Agent-Tauglichkeit der Komponenten also auf der sicheren Seite. Wie es mit anderen Mailservern, kleineren oder exotischen Distributionen aussieht, müssen Admins aber im Zweifelsfalle händisch überprüfen.
Ein weiterer, mittlerweile sehr häufig genutzter Ansatz, um dem Problem mit vielleicht defekten Pacemaker-RAs zu entkommen, beruht auf Virtualisierung. Ein Mailserver wie der hier vorgestellte kann letztlich problemlos als virtuelle Maschine laufen – die Mail-Dienste selbst würden praktisch gar nicht merken, dass sie verclustert sind.
Pacemaker müsste sich “nur noch” darum kümmern, die virtuelle Maschine zwischen den beiden Knoten des Clusters von A nach B und zurück zu verschieben, falls Probleme auftreten. Der dazu benötigte Resource Agent namens »ocf:heartbeat:VirtualDomain« genießt einen ausgezeichneten Ruf.
Und jetzt alle zusammen!
Wenn klar ist, dass für die gewünschte Kombination aus SMTP- und POP-IMAP- Server eine gelungene Pacemaker-Integration vorhanden ist und die Daten auf einer DRBD-Ressource liegen, steht der Einrichtung des Mailservers nichts mehr im Wege.
Das Listing 2 enthält ein vollständiges Beispiel, das neben den schon erwähnten Ressourcen auch eine IP-Adresse enthält. Die ist für klassische Fail-over-Setups sehr wichtig, gerät aber immer wieder in Vergessenheit: Damit der Fail-over-Vorgang nach außen transparent ist (Abbildung 4), dürfen Benutzer nichts von den Vorgängen im Hintergrund bemerken. Müssten sie in ihrem Mailclient nach einem Fail-over die IP-Adresse des Servers (oder ähnliche Einstellungen) ändern, wäre aber genau dies der Fall,
Listing 2
Pacemaker für einen kompletten Mailserver
01 primitive p_dovecot lsb:dovecot \ 02 op monitor interval="60s" timeout="30s" 03 primitive p_postfix lsb:postfix \ 04 op monitor interval="60s" timeout="30s" 05 primitive p_IP-mail ocf:heartbeat:IPaddr2 \ 06 params ip="192.168.0.1" cidr_netmask="24" iflabel="mail" \ 07 op monitor interval="30s" 08 primitive p_fs-mail ocf:heartbeat:Filesystem \ 09 params device="/dev/drbd/by-res/mail" directory="/var/lib/mail" fstype="ext4" options="noatime,nodiratime" \ 10 op start interval="0" timeout="60s" \ 11 op stop interval="0" timeout="180s" \ 12 op monitor interval="60s" timeout="60s" 13 ms ms_drbd-mail p_drbd-mail \ 14 meta notify="true" master-max="1" clone-max="2" clone-node-max="1" master-node-max="1" 15 primitive p_drbd-mail ocf:linbit:drbd \ 16 params drbd_resource="mail" \ 17 op start interval="0" timeout="90s" \ 18 op stop interval="0" timeout="180s" \ 19 op promote interval="0" timeout="180s" \ 20 op demote interval="0" timeout="180s" \ 21 op monitor interval="30s" role="Slave" \ 22 op monitor interval="29s" role="Master" 23 group g_mail p_fs-mail p_IP-mail p_postfix p_dovecot 24 colocation co_fs-mail_with_drbd inf: g_mail:Started ms_drbd-mail:Master 25 order o_drbd_before_fs-mail inf: ms_drbd-mail:promote g_mail:start
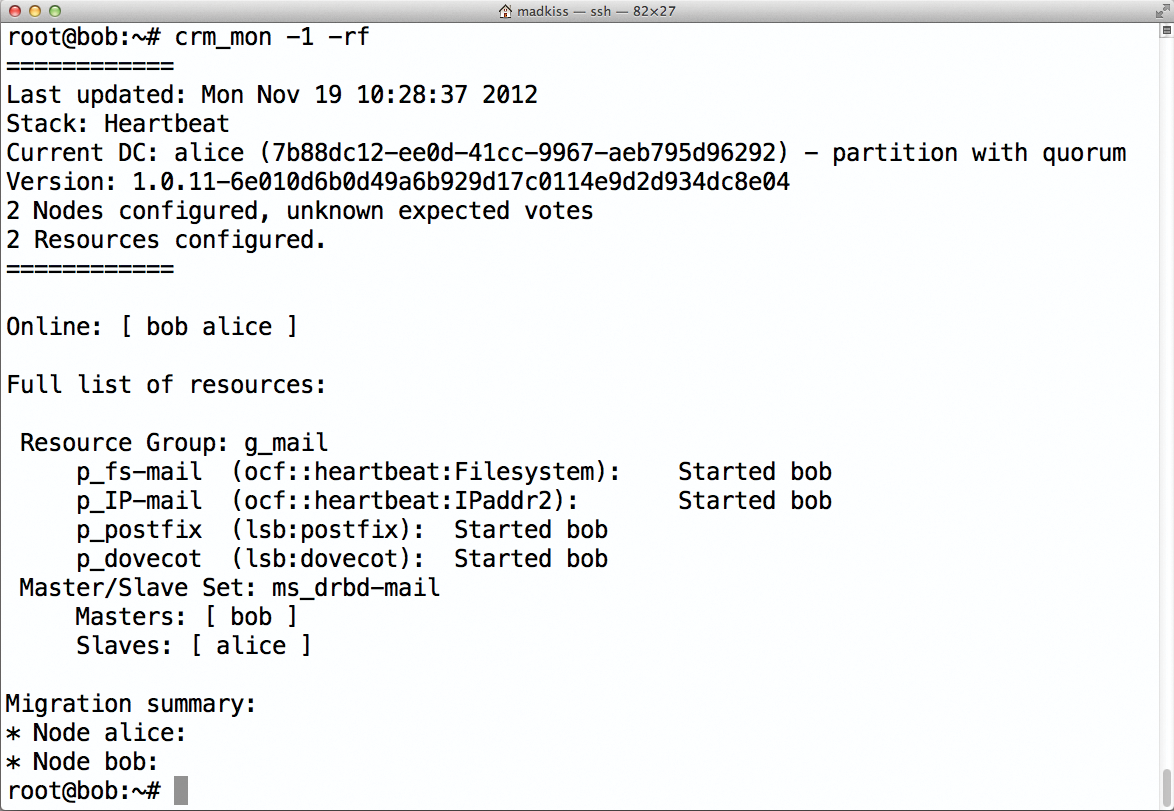
Abbildung 4: Pacemaker sorgt dafür, dass beim Ausfall eines Rechners dessen Dienste schnellstmöglich auf dem anderen Gerät gestartet werden.
Die IP-Adresse im Beispiel wandert zusammen mit den Mail-Diensten auf den jeweils anderen Host, sodass alle Mail-verwandten Services stets über die gleiche IP-Adresse erreichbar sind.
In typischen Mail-Setups ist es oft der Fall, dass Admins die Benutzerverwaltung der Mailserver von der Verwaltung der E-Mail-Nutzer trennen. Häufig kommt dann LDAP zum Einsatz. Wer sich den Aufwand einer eigenen LDAP-Installation nicht antun möchte, greift meist zu MySQL. Das ist auch in kleinen Setups wie dem hier beschriebenen nicht weiter kompliziert – MySQL lässt sich problemlos in einen Zwei-Knoten-Cluster integrieren. Listing 3 enthält ein Beispiel für ein DRBD-MySQL-Gespann für Pacemaker. Auch hier gilt: Die Konfiguration ist nicht unbedingt der allerletzte technische Schrei, funktioniert für kleine und mittelgroße Setups aber zuverlässig.
Listing 3
MySQL in Pacemaker (mit /var/lib/mysql als DRBD-Ressource)
01 primitive p_mysql ocf:heartbeat:mysql \ 02 params binary="/usr/sbin/mysqld" additional_parameters="--bind-address=0.0.0.0" datadir="/var/lib/mysql" config="/etc/mysql/my.cnf" log="/var/log/mysql/mysqld.log" pid="/var/run/mysqld/mysqld.pid" socket="/var/run/mysqld/mysqld.sock" \ 03 op monitor interval="120s" timeout="60s" \ 04 op stop interval="0" timeout="240s" \ 05 op start interval="0" timeout="240s"
Scale-up und Scale-out
Bis hierhin hat sich der Artikel maßgeblich mit der Frage beschäftigt, wie ein Mailserver redundant wird. Wer größere Installationen mit vielen Tausend Benutzern betreibt, sieht sich im administrativen Alltag allerdings häufig mit einem zweiten Problem konfrontiert, der Skalierbarkeit. Ein Cluster mit zwei Knoten und einem klassischen Pacemaker-Setup skaliert nämlich nur behäbig – am ehesten noch in die Höhe.
Die IT unterscheidet zwei Konzepte von Skalierbarkeit: Auf der einen Seite steht das Skalieren in die Höhe, bei dem es im Wesentlichen darum geht, vorhandene Ressourcen zu erweitern. Ganz konkret kann das beispielsweise heißen, in vorhandene Server mehr RAM oder größere Platten einzubauen, um die Kapazität der Infrastruktur zu vergrößern. Dieses Konzept ist als Scale-up bekannt.
Ihm gegenüber steht das Skalieren in die Breite, also das Scale-out. Sinn und Zweck dieses zweiten Ansatzes ist es, die schon vorhandene Infrastruktur um zusätzliche Geräte zu erweitern und auf diese Weise die anfallende Last besser zu verteilen. Bezogen auf das Mail-Beispiel könnte Scale-out bedeuten, mehr Server mit SMTP- und IMAP-Diensten zu deployen, die sich in das vorhandene System integrieren.
Scale-up ist einfach: Einen Zwei-Knoten-Cluster mit mehr Hardware versorgen oder die vorhandene Hardware durch leistungsfähigere ersetzen ist leicht – solange das System in seiner neuen Konfiguration anschließend den Erwartungen wieder gerecht wird. Kritisch wird es erst, wenn – bildlich gesprochen – nach oben hin kein Platz mehr ist.
Mail-Scale-out erweist sich als schwieriger
So können Server üblicherweise nur mit einer begrenzten Anzahl gleichzeitig geöffneter TCP/IP-Verbindungen umgehen. Ist die Zahl der Verbindungen permanent größer als das, was ein einzelner Server leisten kann, ist ein Scale-out die einzig mögliche Alternative.
Einige Teile eines Mail-Setups ließen sich noch verhältnismäßig einfach in die Breite skalieren. SMTP ist ein Stateless-Protokoll, bei dem ein Client sich mit genau einem Server verbindet, um eine E-Mail zu versenden. Eine Armada von SMTP-Servern zu betreiben und die Clients mit einem vorgeschalteten Load Balancer an diesen Server anzubinden ist also kein Problem. Ganz ähnlich verhält es sich mit dem Empfang von E-Mails per SMTP: Über MX-Records lässt sich einfaches Load Balancing sogar auf DNS-Ebene realisieren, aber der Umweg über einen Load Balancer ist auch hier problemlos möglich.
Kritisch ist hingegen der Teil des Setups, der Benutzern anschließend Zugriff auf ihre E-Mails ermöglicht – und hier insbesondere das Thema Storage. Generell gilt, dass nahtlos in die Breite skalierender Storage über Tools wie DRBD oder mittels klassischer SAN- und NAS-Storages unmöglich ist, auch wenn die tatsächlichen Speichergrenzen mit Mail-Setups eher schwer zu erreichen sind.
Viel wichtiger als der Plattenplatz per se ist aber die Frage nach dem Zugriff auf die Daten, und zwar besonders im Mail-Kontext. Theoretisch spricht ja nichts dagegen, auch IMAP- oder POP-Server mit einem Load Balancer zu versehen und Clients so zugreifen zu lassen. Praktisch ist die Schwierigkeit an dieser Stelle eher, vielen IMAP-Instanzen auf diversen Servern gleichzeitigen Zugriff auf den gemeinsamen Speicher zu gewähren, denn selbstverständlich gilt in einer solchen Konstellation, dass jeder IMAP- oder POP-Server jederzeit Zugriff auf den gleichen Datensatz haben muss (Abbildung 5).
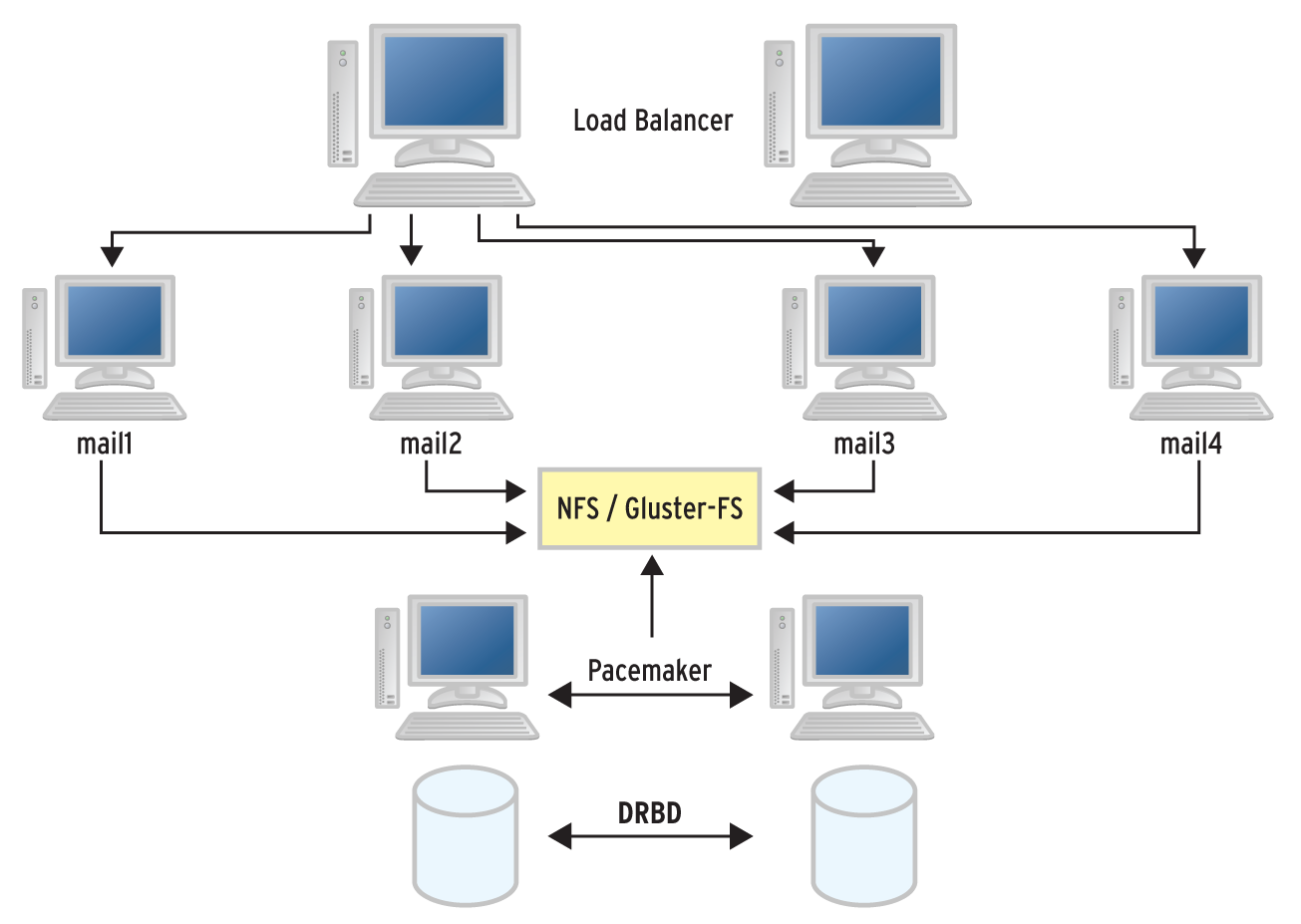
Abbildung 5: Scale-out ist im Mail-Kontext komplex. Das typische Setup beruht auf einem geteilten Dateisystem wie NFS oder Gluster, ist aber kaum erbaulich, was die Performance angeht.
Es gibt einige Ansätze zur Lösung dieses Problems, die meisten von ihnen sind unbefriedigend. Mit NFS etwa lässt sich ein entsprechendes Setup bauen, doch ist die NFS-Performance bei simultanem Zugriff von mehreren Seiten in den meisten Fällen wenig berauschend. Cluster-Dateisysteme wie OCFS2 oder GFS2 sind komplex und funktionieren mehr schlecht als recht, sodass im Normalfall auch diese Option wegfällt.
Verteilte Dateisysteme wie Gluster oder Object Stores wie Ceph und Swift sind hingegen vielversprechende Ansätze, um das Problem in den Griff zu kriegen. Leider existiert bisher aber nicht ein einziger IMAP- oder POP-Dienst, der Swift oder Ceph nativ benutzen könnte. Auch ist die Performance von Gluster-FS einigermaßen bescheiden, wenn sehr viele sehr kleine Dateien auf dem Dateisystem lagern – gerade das gilt aber eben für Mailserver.
Erschwerend kommt hinzu, dass Mail konzeptbedingt in vielen Fällen das genaue Gegenteil von dem erwartet, was Posix-Dateisysteme tun. Ein paar Beispiele: Posix nutzt ein hierarchisches Layout, das im Falle von Mail bedeutungslos ist. In-Place-Updates als eingebaute Eigenschaft von Posix bringen für Mails keinen praktischen Nutzen. Append-only? ACLs? Alles im Grunde überflüssig, zumindest für den E-Mail-Store.
Hilfskonstruktionen
Die beschriebenen Probleme sind nicht neu, sie existieren schon so lange, dass viele Anbieter von Mailservern sich Insellösungen gebaut haben, um die gröbsten Schwierigkeiten zu umschiffen. Ein Beispiel ist der Dovecot-Director [6], ein spezieller Load Balancer für den Dovecot-Mailserver. Dieser tut im Grunde nichts anderes, als sich zu merken, an welchen Dovecot-Server er einen Client weitergeleitet hat. Wie lange der Director diese Information im Gedächtnis behält, lässt sich konfigurieren. Der positive Effekt der Lösung ist, dass in einem Cluster aus diversen Mailservern Clients nicht zwischen den Knoten hin und her springen und die auf dem geteilten Storage anliegende Last daher um einiges geringer ist als ohne Director.
Grundsätzlich gilt aber: Der knifflige Teil bei skalierbaren Mailservern ist die Storage-Komponente. Alle anderen Dienste ließen sich wie beschrieben mittels Pacemaker auch in größeren Clustern nutzen (Pacemaker skaliert bis zu einer Clustergröße von ungefähr 25 Knoten), doch ohne performanten Speicher ist diese Fähigkeit kaum von Belang. Es bleibt zu hoffen, dass sich auch die Mailserver an den aufkommenden Trend zu Object Storages halten.
Selbst gebastelt
Der Betrieb von Mailservern wirkt auf den ersten Blick leicht, doch gibt es einige Klippen, die Administratoren kennen sollten, um sie zu umschiffen. Hochverfügbare Mailserver lassen sich mit einer Kombination aus den gängigen Mailerdiensten und dem Linux-HA-Clusterstack mit Pacemaker und Corosync auf Linux verhältnismäßig leicht arrangieren; DRBD sorgt dafür, dass redundanter Speicher nicht zum Problem wird, falls kein SAN oder NAS parat steht.
All das sollte allerdings nicht darüber hinwegtäuschen, dass die Lösung technisch nicht besonders elegant ist. Das liegt einerseits daran, dass ein Setup dieser Art stets zwei Knoten voraussetzt, von denen einer sich immer langweilt. Andererseits erscheint Pacemaker doch als ein sehr komplexes Werkzeug für eine – zumindest in diesem Fall – relativ einfache Aufgabe. Wer sich noch an Heartbeat 2 erinnert, denkt mit Schrecken an die XML-Schnipsel, über die der Clustermanager zu kontrollieren war.
Pacemaker hat in dieser Hinsicht zwar aufgerüstet, ermöglicht es die Pacemaker-Shell »crmsh« doch mittlerweile mit eingängiger Kommandozeilensyntax, die Ressourcen-Konfiguration schnell und unkompliziert zu bearbeiten. Aber dennoch bleibt die Pacemaker-HA-Lösung umfangreich und bisweilen kompliziert. Linderung lässt sich allenfalls dadurch erreichen, dass der Admin den Mailserver per se virtualisiert und Pacemaker sich nur um die Pflege der virtuellen Maschine kümmert.
An der Aufgabe wachsen?
Auch das Thema Scale-out ist im Kontext von Mailservern kein leichtes. Das hat mehrere Gründe: Neben der schon erwähnten Tatsache, dass Mails im Grunde der ideale Anti-use-Case für Dateisysteme nach Posix-Standard sind, erlauben es typische Dateisysteme auch nicht, nahtlos in die Breite zu skalieren. Wer ein Mailserver-Setup für mehrere Zehntausend Nutzer bauen möchte, muss sich also frühzeitig vor allem Gedanken um das Thema Storage machen.
NFS ist eine Möglichkeit, die den gleichen Storage für mehrere Mailserver-Knoten bereitstellt. Um Inkonsistenzen zu verhindern, muss solche Software aber praktisch immer mit Zusatzkomponenten wie dem Dovecot-Director versehen sein, der sich darum kümmert, eingehende IMAP-Verbindungen nicht zu wild auf die verfügbaren Mailserver zu verteilen.
In die Breite skalierende Mailserver-Setups sind im Grunde immer maßgeschneiderte und von vornherein geplante Lösungen, für die generelle Empfehlungen kaum sinnvoll sind. Mit dem Aufkommen von Object Stores wie Ceph entsteht gerade allerdings jede Menge Software, die solche Probleme umschiffen könnte. Denkbar wäre beispielsweise ein IMAP-Server wie Dovecot, der unmittelbar mit Ceph spricht und dabei den Umweg über ein Dateisystem auslässt. Dann wäre die Zahl der IMAP-Server im Netz irrelevant. Leider sind Lösungen wie diese derzeit noch Zukunftsmusik.
Infos
- Linux-HA-Projekt: http://www.linux-ha.org
- DRBD-Replikation, Admin-Magazin 04/11:http://www.admin-magazin.de/Das-Heft/2011/04/DRBD-Replikation
- Pacemaker-Grundlagen, Admin-Magazin 04/11: http://www.admin-magazin.de/Das-Heft/2011/04/HA-Serie-Teil-1-Grundlagen-von-Pacemaker-und-Co
- Pacemaker-Libvirt-und-KVM, Admin-Magazin 05/11: http://www.admin-magazin.de/Das-Heft/2011/05/Pacemaker-Libvirt-und-KVM
- Pacemaker und MySQL, Admin-Magazin 05/11: http://www.admin-magazin.de/Das-Heft/2011/05/Pacemaker-und-MySQL
- Dovecot-Director: http://wiki2.dovecot.org/Director
Der Autor

Martin Gerhard Loschwitz arbeitet zurzeit als Principal Consultant bei Hastexo. Er beschäftigt sich dort ganz Cloud-affin mit Hochverfügbarkeitslösungen und Open Stack sowie mit verteilten Dateisystemen.





