
© Olena Buyskyh, 123RF.com
Riesige und ausbaufähige Speicher sind das A und O in modernen Unternehmen. NAS und SAN sind der Standard, doch Trends wie Cloud Computing und Big Data lassen die Grenzen zwischen Storage und Server verschwimmen und bringen neue Ansätze hervor.
Daten im Netz verteilt abzulegen bringt dem Administrator viele Vorteile: Es ist einfach sicherer, schneller und flexibler als jeder Fileserver. Fast alle im Storage-Umfeld tätigen Hersteller bieten entsprechende Produkte an, viele davon erfolgreich. Die Linux-Unix-Community hatte mit dem Andrew File System (AFS, [1]) einen technischen Vorreiter in den eigenen Reihen. Und sie generierte – wie so oft typisch für Open Source – gleich unzählige interessante Projekte: Ceph [2], Gluster [3], Xtreem-FS [4], FHG-FS [5] sind die wichtigsten.
Gemeinsame Ansätze
Trotz vieler Gemeinsamkeiten rund um die verteilte Datenspeicherung unterscheiden sich die Produkte nicht nur in technischen Belangen, sondern gerade in ihrer Ausrichtung und der ursprünglichen Motivation der Entwickler: Xtreem-FS ist quasi ein Nebenprodukt eines europäischen Grid-Computing-Projekts mit dem Betriebssystem Xtreem-OS [6]. Bei FHG-FS hat die Performance eine höhere Priorität als beispielsweise die Ausfallsicherheit. Gluster und Ceph haben besonders viele Benutzer gewinnen können, nicht zuletzt weil Enterprise-Linux-Distributoren darauf basierende Produkte auf den Markt gebracht haben ([7], [8]) oder daran arbeiten ([9], [10]).
Datenspeicher im Netz
Lokale Dateisysteme ohne Netzwerkfunktion hat das Linux-Magazin in einer der letzten Ausgaben [11] unter die Lupe genommen. Die in diesem Artikel behandelten Ablagen entspringen alle der Familie der so genannten Shared File Systems, bei denen zwei oder mehr Rechner Zugriff auf dieselben Daten haben. Dafür verwenden die Entwickler grundverschiedene Implementierungsansätze.
Die bekanntesten Network-Filesysteme basieren auf Netzwerkprotokollen wie den verschiedenen Versionen von NFS ([12] bis [14]) sowie CIFS oder SMB-FS [15]. Einen ähnlichen Ansatz verfolgen die so genannten parallelen oder auch verteilten Cluster-Dateisysteme, die vor allem in Hochverfügbarkeitsszenarien Einsatz finden. Hierher gehören Lustre [16], Google-FS [17] und Moose-FS [18]. Bei der zweiten Untergruppe, den Shared-Disk-Cluster-Dateisystemen wie GFS2 [19] und OCFS2 [20] haben dagegen die Mitgliedserver des Clusters Datenzugriff auf Blockgerätebene.
Verteilte Dateisysteme trennen Daten von Metadaten
Anders die neue Generation der verteilten Dateisysteme: Sie setzt auf eine Trennung der Verwaltung der Daten selbst und die der Metadaten, etwa der Dateirechte oder Dateinamen, also ähnlich wie bei den in einer Inode des lokalen FS gespeicherten Daten. Für Operationen wie Löschen oder Umbenennen kommuniziert der Rechner mit den Metadaten-Instanzen des verteilten Systems. Das Lesen und Schreiben der eigentlichen Daten findet auf den Storage-Komponenten statt, hier kommt der objektbasierte Ansatz zur Datenverwaltung ins Spiel.
Zum gegenwärtigen Zeitpunkt gibt es besonders zwei große Anwendungsgebiete für verteilten Storage: zum einen als Ersatz für die traditionellen NAS-Lösungen, zum anderen als unbegrenzten, skalierbaren, sicheren und flexiblen Datenspeicher für virtuelle Server.
Intelligenter Speicher
Bis zur Jahrtausendwende war Storage nicht sonderlich intelligent. Den Großteil der zur Speicherung von Daten relevanten Aufgaben erledigten Programme und Controller-Hardware außerhalb der Platte. Die Schnittstelle war einfach und mit Standards wie SCSI dokumentiert. Die zunehmende Leistungsstärke der Storage-Hardware warf aber die Frage neu auf, welche Aufgaben ein Fileserver übernehmen kann und soll. War bislang der Rechner für die Speicherverwaltung verantwortlich, sollte dies künftig der Storage selbst erledigen.
Im neuen Ansatz tauschen sich Rechner und Speicher nicht mehr über Blöcke, sondern über so genannte Storage-Objekte aus. Blockallokierung und Platzverwaltung erledigt der Storage, nicht mehr der Rechner. Die Objekte sind recht allgemeinen Charakters, es können einfache Dateien, aber auch Partitionen sein. Die entsprechende Erweiterung des SCSI-Standards – die Object-based Storage Device (OSD) Commands – genehmigte das T10-Kommitee des Incits (International Committee for Information Technology Standards) im Jahre 2004 [21].
Seit Kurzem ist die zweite Generation des OSD-Standards fertig und verabschiedet [22]. Er versieht jedes Objekt mit einer 64-bittigen Partitions-ID und einer 64-bittigen Objekt-ID. Der Zugriff des Rechners auf die Daten erfolgt über diese IDs. Die bekannten Datei-Operationen funktionieren wie gehabt, die Verwaltung erledigt aber OSD und nicht mehr der am Storage angeschlossene Rechner. Die von traditionellen Inode-basierten Dateisystemen bekannten Metadaten sind direkt im OSD-Objekt gespeichert, da sie aber nur für den angeschlossenen Rechner von Bedeutung sind, interpretiert die OSD-Platte diese erst gar nicht (Abbildung 1).
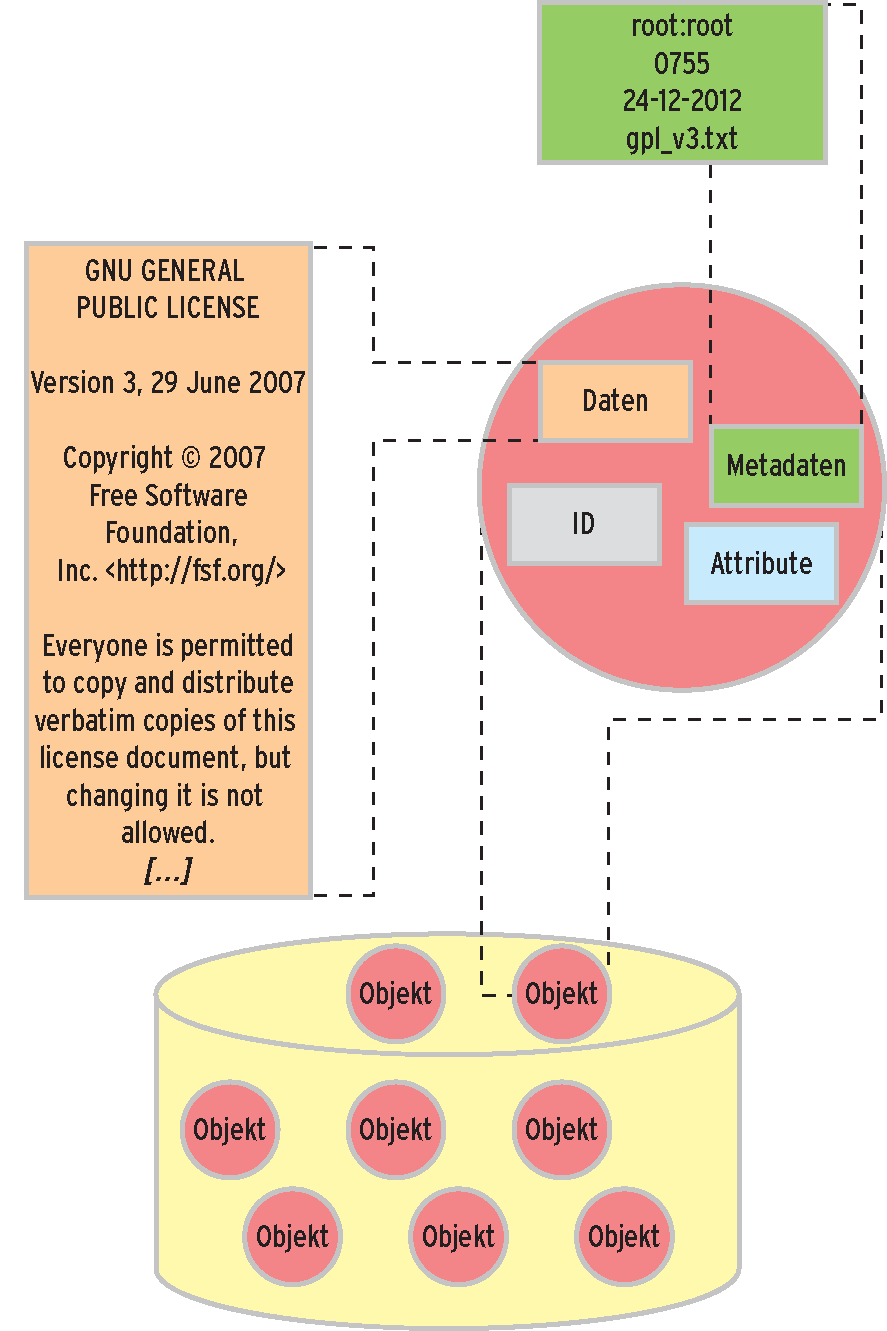
Abbildung 1: Bei der objektbasierten Datenverwaltung interessieren den Server die Metadaten des FS nicht.
Krakenhaft, aber GPL: Ceph
Der Name des Dateisystems hat seinen Ursprung im Tierreich. Ceph ist eine gebräuchliche Bezeichnung für einen als Haustier gehaltenen Kraken, den Cephalopoden. Die Fähigkeit der Tiere, viele Tätigkeiten gleichzeitig auszuführen, erinnerte die Entwickler an die gewünschte hohe Parallelität ihres Dateisystems.
Der Initiator Sage Weil begann das Projekt als Teil seiner Doktorarbeit an der University of California in Santa Cruz. Im Jahr 2006 stellte er es auf der Usenix-Konferenz OSDI erstmals vor, seit Version 2.6.34 ist der Posix-Client offizieller Bestandteil des Linux-Kernels.
In der Folge konzentrierten sich die Entwickler auf den Ausbau der Datenmaschinerie von Ceph. Insider kennen sie unter dem Name Rados (Reliable Autonomic Distributed Object Storage, [23]). Seit Kernel 2.6.37 kann der Anwender über eine Blockgeräte-Schnittstelle – also ohne die Posix-Schicht – Daten in Ceph verwalten. Die Tatsache, dass Ceph Bestandteil des Linux-Kernels ist, impliziert die Implementierung in C und unter der GPL.
FHG und Gluster
Dies trifft übrigens für alle Komponenten des Dateisystems zu und ist nicht bei allen verteilten Dateisystemen der Fall. Bei FHG-FS beispielsweise steht nur der Client unter der GPL, nicht aber die restlichen Bestandteile. Die Entwicklung von Gluster-FS (Abbildung 2) begann mehr oder weniger hinter den verschlossenen Türen der gleichnamigen Firma. Mit der Übernahme durch Red Hat im Oktober 2011 änderte sich dies aber grundlegend. Seit Januar 2012 gibt es ein Board und einen Community-Manager. Beide bemühen sich vor allem um erhöhte Präsenz von Gluster-FS in Distributionen.
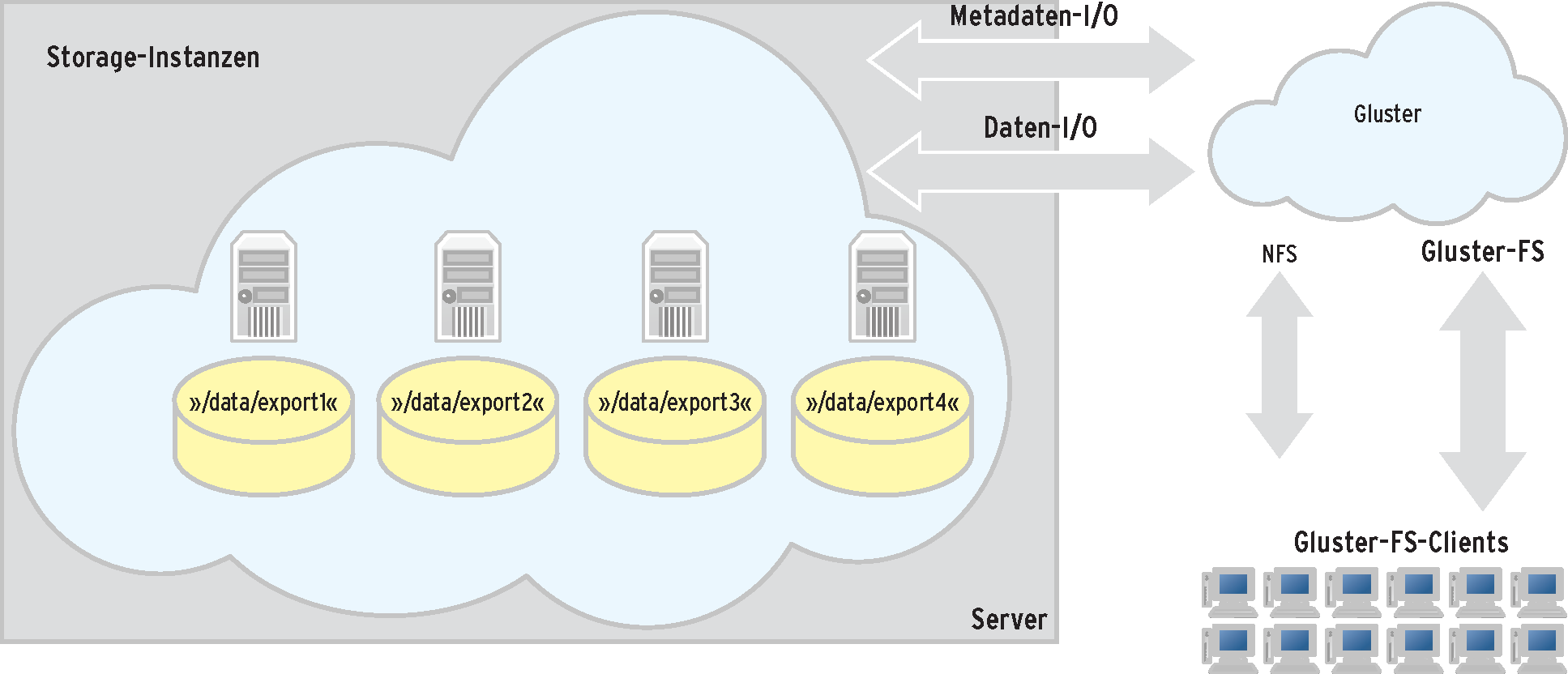
Abbildung 2: Gluster-FS wird vor allem von Red Hat getrieben, ist aber noch nicht im Linux-Kernel angekommen. Als Fallback für den Client dient NFS.
Im Gegensatz zu Ceph (Abbildung 3) ist das verteilte Dateisystem aus dem Hause Red Hat aber nicht Bestandteil des Linux-Kernels und lebt komplett im Userspace. Obwohl ebenfalls modular aufgebaut, ist ein Betrieb ohne die Posix-Schicht nicht möglich. Projekte wie Heka-FS ([24], früher Cloud-FS) setzen auf Gluster-FS auf und fügen diesem interessante Funktionen hinzu, im Falle von Heka-FS ist dies die Mandantenfähigkeit.
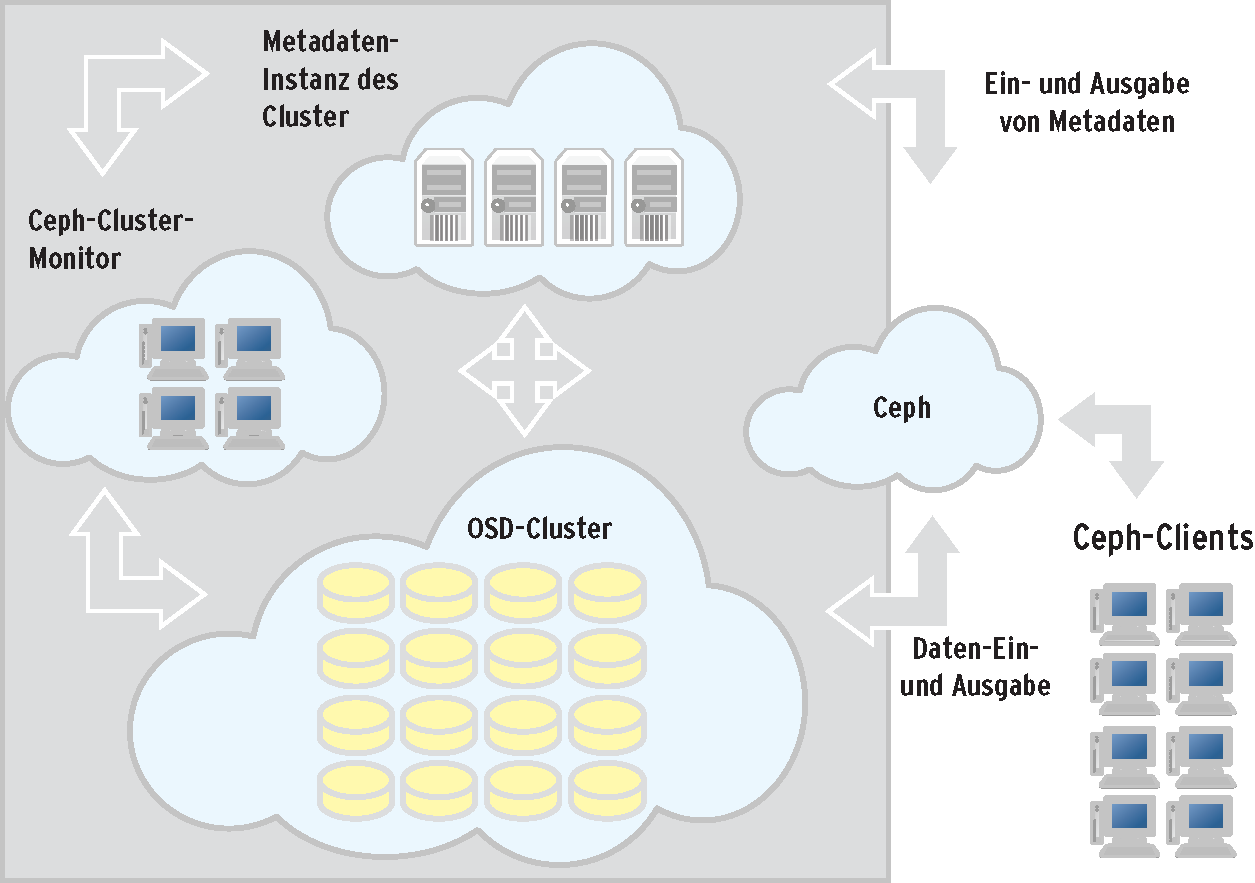
Abbildung 3: Ceph verdankt seinem Namen vielarmigen Tintenfischen und ist voll im Kernel integriert.
Unter den Objekten: XFS, Ext 4 oder Btr-FS
Moderne verteilte Dateisysteme basieren letztlich auf den Ideen der objektbasierten Datenverwaltung. Folglich gibt es ab einer gewissen Abstraktionsschicht viele Gemeinsamkeiten. So arbeiten sie alle nach dem Client-Server-Modell, aber auch eine Schicht tiefer hören die Gemeinsamkeiten nicht auf. Ceph und Gluster-FS verfügen beide über Speicherinstanzen, die für das Lesen und Schreiben der Daten zuständig sind. Für diese Aufgabe verwenden die OSDs (Ceph) beziehungsweise Storage-Bricks (Gluster-FS) ein ganz ordinäres Linux-Dateisystem.
Für den Einsatz in produktiven Umgebungen empfehlen beide Projekte wärmstens XFS [25], erlauben aber auch die Verwendung von Ext 4 [26]. Die Ceph-Entwickler favorisieren mittelfristig das Linux-Dateisystem der Zukunft: Btr-FS [27]. Die Speicherinstanz selbst läuft als ganz normaler Prozess im Userspace.
Ein Tintenfisch-Verwalter oder einfach ohne?
Eine weitere gemeinsame Komponente verteilter Dateisysteme ist der Metadaten-Verwalter. Die Implementierung ist aber teilweise unterschiedlich. Bei Ceph gibt es dedizierte Serverinstanzen, die Metadaten lesen und schreiben, aber auch bereitstellen und empfangen.
Die Performance der Metadaten-Verwaltung erweist sich oft als Engpass. Ceph umgeht dies durch gewichtete Lastverteilung über mehrere Server mit teilweise überlappenden Verantwortlichkeiten. Gluster-FS wählt einen anderen Weg und benutzt keinen expliziten Serverprozess. Metadaten wie Zeitstempel oder Zugriffsrechte liest das Dateisystem einfach 1:1 aus dem Backend-Dateisystem. Gluster-FS-spezifische Informationen muss das Dateisystem nicht nachschauen, sondern berechnet sie gegebenenfalls (siehe Kasten “Verteilte Hashtabelle in Gluster-FS”). Sowohl Ceph als auch Gluster-FS verwenden keinen eigenen Speicher zum Ablegen, sondern nutzen OSDs beziehungsweise die Storage-Bricks.
Verteilte Hashtabelle in Gluster-FS
Distributed Hashtables verwenden so genanntes konsistentes Hashing. Ganz allgemein ordnet Gluster-FS jedem Datenobjekt zunächst einen Hashwert zu. Anhand dieses Hash entscheidet das Dateisystem, welcher Storage-Server für die Daten zuständig ist. Für die Partitionierung des Namensraums verwendet Gluster-FS dessen Dateinamen beziehungsweise den Hashwert.
Verändert sich die Anzahl der Storage-Server oder der Name des Datenobjekts, dann wird das Umverteilen der Daten nötig. Der sauberste Weg wäre das Kopieren oder Verschieben der entsprechenden Objekte. Da dies aber auch dank neu zu erzeugender Hashes nicht unbedingt der performanteste Ansatz ist, wählt Gluster-FS einen Kompromiss und “verlinkt” den Storage-Server.
Monitoring
Der aktuelle Zustand der Server im Dateisystemverbund, also die Information, welche Server welche Aufgaben wahrnehmen sollen und ob sie das auch tun, ist wichtig für den reibungslosen Betrieb. Bei Ceph gibt es so genannte Monitor-Instanzen, die diese Überwachungsfunktion wahrnehmen. Gluster-FS ist weniger umsichtig und verteilt die Überwachung und Handlungsprozeduren auf Server- und Client-Komponenten. Fällt eine Storage-Instanz weg, dann muss der Admin manuell den gewünschten Replikations-Level erneut herstellen – Ceph erledigt dies automatisch.
Eine weitere ähnliche Komponente der Architekturen von Ceph und Gluster-FS liegt außerhalb des Serverteils: der Client. Um auf die Dateisystemschicht zuzugreifen, verfügen beide über eine Fuse-basierte Implementierung. Wie bereits weiter oben erwähnt, kann Ceph bei neueren Kerneln auch auf dessen Userspace-Anteil verzichten. Außerdem erlaubt der Krake den direkten Zugriff auf die Storage-Schicht und eröffnet damit ganz neue Möglichkeiten.
Um erfolgreich zu sein, muss sich ein Softwareprojekt in das vorhandene Ökosystem integrieren. Für verteilte Datenspeicher bedeutet das Kompatibilität zu Hadoop [28], Open Stack [29] und Cloudstorage wie Amazons S3 [30]. Bei der Pflicht leistet sich keiner der Kandidaten eine Schwäche, aber in der Kür hat Ceph die Nase etwas weiter vorn. Eine REST-Schnittstelle (Representational State Transfer, [31]) gehört hier zum Lieferumfang, bei Gluster-FS ist sie noch recht jung. Außerdem kann der Admin diese bei Ceph so konfigurieren, dass sogar die von Amazon bekannten S3-Tools funktionieren.
Unterschiede
So viel zu den Ähnlichkeiten von Ceph und Gluster-FS. Unter der Haube offenbaren sich gravierende Unterschiede: Das eigentliche Herzstück von Ceph ist der Datenspeicher Rados [23]. Dessen Kernkomponente wiederum ist der Crush-Algorithmus (Controlled Replication Under Scalable Hashing, Abbildung 4, [32]), den der Kasten “Quasi-statistische Datenhäckselei” erläutert.
Quasi-statistische Datenhäckselei
Mit Crush verteilt Ceph die Daten quasi-statistisch über die OSDs. Mathematisch gesprochen und stark vereinfacht bekommt der Algorithmus einen Eingabewert n und berechnet daraus eine geordnete Liste L. Dabei ist n die so genannte Platzierungsgruppe, während L OSDs enthält.
Zu speichernde Daten nimmt Ceph entgegen, unterteilt sie in handliche Häppchen von 4 MByte Größe und bildet sie auf Storage-Objekte ab. Über einen Hashalgorithmus bekommt jedes Objekt nun eine der schon erwähnten Platzierungsgruppen zugewiesen. Die Platzierungsgruppen sind eine Abstraktionsschicht, um die Topologie der Storage-Server zu verbergen. Zur Berechnung der OSDs kommt Crush ins Spiel.
Dazu benötigt Ceph aber noch die Antworten auf zwei Fragen: Wie sieht der aktuelle Zustand des Ceph-Clusters aus? Und welche Richtlinien regeln das Platzieren der Daten?
Diese Platzierungsregeln legen zum Beispiel fest, wie viele Kopien Ceph zur Erhöhung der Ausfallsicherheit anlegt. Hierher gehören aber auch Richtlinien, etwa dass die Kopien nicht auf dem gleichen Storage-Server (dem gleichen Rack, …, der gleichen Feuerzelle) landen.
Clustermonitore
Den aktuellen Zustand des Ceph-Verbunds kennen die Clustermonitore. Sie verwalten die so genannte Clustermap. Diese enthält alle OSDs in einer hierarchischen, gewichteten Struktur. Fällt eine Storage-Instanz aus oder kommen neue dazu, aktualisieren die Monitore die Clustermap und geben sie an die OSDs weiter. Eine Veränderung im OSD-Verbund resultiert in den meisten Fällen in einer Umverteilung der Daten zwischen den Storage-Servern. Aufgrund der quasi-statistischen Natur von Crush muss Ceph im Schnitt nur 1/m der Objekte umlagern, wobei m die Anzahl der beteiligten Instanzen ist.
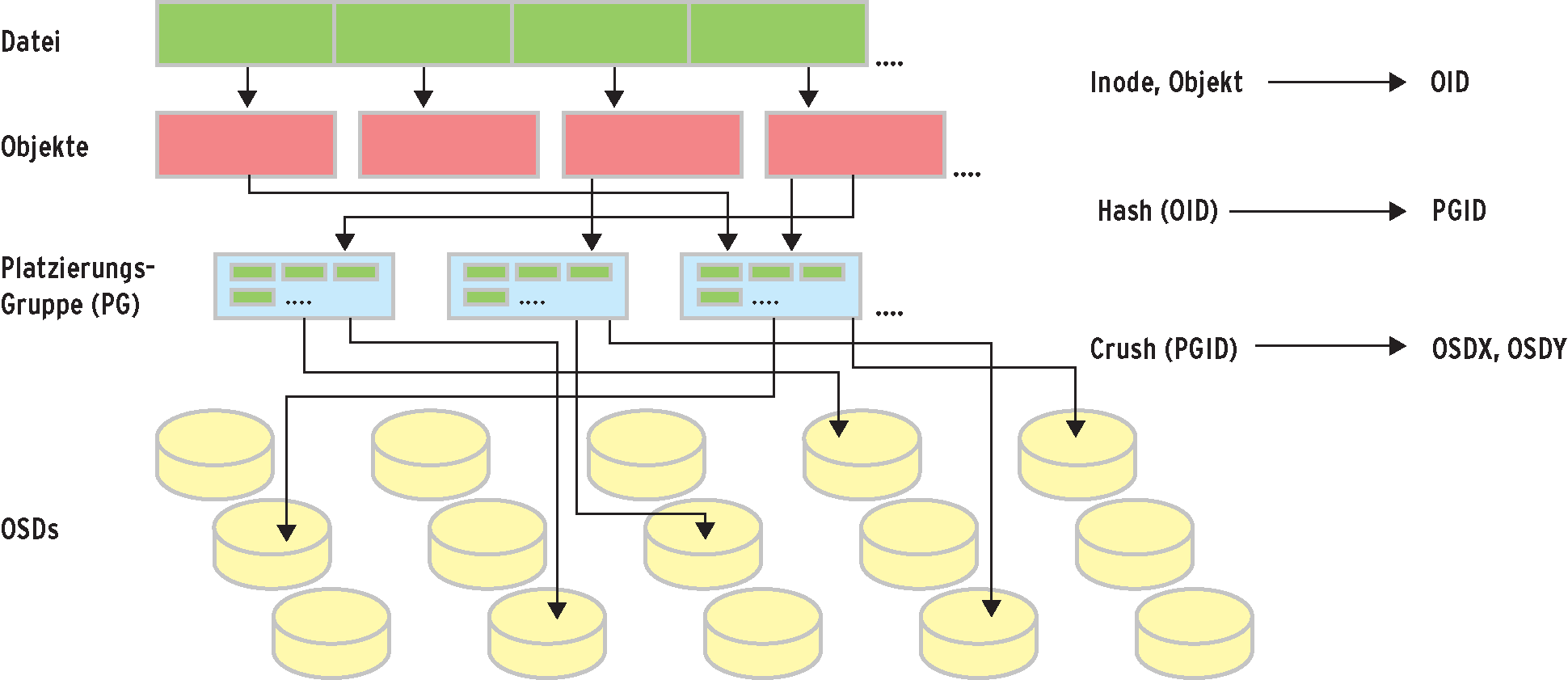
Abbildung 4: Glusters quasi-statistische Dateiablage mit Crush setzt auf Platzierungsgruppen und OSDs. Dabei landet eine Datei auch mal in mehreren Objekten.
Die Daten einer Datei verstreut Ceph mehr oder weniger über alle vorhandenen Storage-Instanzen. Mit Hilfe von Platzierungsregeln lassen sich bestimmte Server bevorzugen und andere komplett ausschließen. Ausfallsicherheit gewährleistet Ceph durch Kopieren der Daten. Wie viele Kopien vorliegen, bestimmt der Admin wiederum durch Platzierungsrichtlinien.
Ceph-Replikation
Die Replikation erfolgt innerhalb der Storage-Server und ist für den Client vollkommen transparent, sowohl für normale Zugriffe als auch für den Fall des Ausfalls von einer oder mehreren Storage-Instanzen. Prinzipiell haben alle Mitglieder im Verbund – also Serverkomponenten und Clients – volle Sicht auf Rados und alle enthaltenen Objekte. Dabei existieren prinzipiell zwei Möglichkeiten: Entweder über die Ceph-Bibliothek »librados« auf die Dateien oder über das so genannte Rados-Blockgerät (RDB, Rados Block Device) auf Blocklevel zugreifen. QEMU [33] ist schon entsprechend vorbereitet und in der Lage, die Daten der virtuellen Gäste direkt in Rados abzulegen und zu verwalten.
Aber auch ohne entsprechend angepasste Anwendungen ist die Storage-Maschine nutzbar – vorausgesetzt das System hat einen Linux-Kernel 2.6.37 oder neuer. Hier kann der Admin den Rados-Speicher als Blockgerät, also wie eine normale Festplatte, zugänglich machen. Dabei verhält sich »/dev/rbdX« wie »/dev/sda« , ist aber zusätzlich für alle Rechner im Ceph-Verbund sichtbar. Experten bemerken hier sofort die Analogie zum klassischen Fibre-Channel- oder I-SCSI-SAN. Ein sauberer Locking-Mechanismus fehlt allerdings noch, doch daran arbeiten die Ceph-Entwickler bereits.
Gluster und Translatoren
Gluster-FS hat eine deutlich einfachere Storage-Maschinerie – seine Vorteile liegen an anderer Stelle. Da ist zunächst der sehr modulare Aufbau. Die Basis bilden die Storage-Server, auch Bricks genannt. Jede einzelne Funktion, beispielsweise Replikation oder Posix-Kompatibilität, ist durch so genannte Translatoren repräsentiert. Gluster-FS reiht diese entsprechend den gewünschten Funktionen zu einem Brick-Graph zusammen. Zwar beherrsacht Gluster-FS im Moment (noch) keine Verschlüsselung, es fehlt aber nur am passenden Translator. Das Nachrüsten ist dann ganz einfach.
Analog versuchen die Entwickler Gluster-FS für die Virtualisierung aufzubohren. Ein neuer Translator soll direkt mit Partitionen oder Logical Volumes umgehen und kein Backend-Dateisystem erwarten [34]. Gluster-FS kann dann diese Blockgeräte direkt als Dateien zur Verfügung stellen – sie dienen als Imagedateien für virtuelle Gäste. Für Firmen mit verteilten oder Notfall-Rechenzentren hält das Dateisystem die Geo-Replikation bereit. Sehr einfach kann der Admin damit asynchrone und inkrementelle Kopien der Daten aufsetzen. Die Technik dahinter basiert auf SSH und Rsync und lässt sich im Notfall auch vom Gluster-FS-unerfahrenen Benutzer debuggen.
Der scheinbar einfache Aufbau von Gluster-FS ist aber auch seine große Stärke. Das Analysieren und Lösen von Problemen ist sehr viel leichter möglich. Fällt die Gluster-FS-Schicht aus, greift der Admin einfach auf die Daten im Backend-Dateisystem zurück. Neben dem Zugriff übers native Protokoll ist das verteilte Dateisystem auch über NFS erreichbar. Die notwendige Serverkomponente ist Teil von Gluster-FS, funktioniert aber wie bei NFS 4 nur mit TCP.
Was bleibt, was kommt?
Verteilte Dateisystem sind unter Linux keine Mangelware. Die Grundfunktionen sind dabei nahezu identisch. Der Unterschied – und damit das Entscheidungskriterium – liegt im Detail. Die hier genauer vorgestellten Gluster und Ceph decken ein breites Feld von Anwendungsfällen ab und haben ihren Ritterschlag durch entsprechende Produkte der Enterprise-Linux-Hersteller erhalten.
Verschiedene Herausforderungen liegen aber noch vor den Dateisystemen und ihren Admins. Probleme lokaler Dateisysteme zu lösen ist schon nicht trivial, der verteilte Charakter, den Ceph durch Crush noch steigert, vereinfacht dies nicht. Ein Art »fsck.cephfs« würde den Admin sicherlich ruhiger schlafen lassen. Dennoch vollzieht sich gerade ein Paradigmenwechsel in der Welt der Datenspeicher. Die Grenzen zwischen Storage, Netz und Servern verschwimmen und damit ändern sich auch die Aufgaben der jeweiligen Admins.
Infos
- AFS: http://de.wikipedia.org/wiki/Andrew_File_System
- Ceph: http://www.ceph.com
- Gluster: http://www.gluster.org
- Xtreem-FS: http://www.xtreemfs.org
- FHG-FS: http://www.fhgfs.com
- Xtreem-OS: http://www.xtreemos.org
- Red Hat Storage Server: http://www.redhat.com/products/storage-server
- Suse-Cloud: http://www.suse.com/products/suse-cloud
- Inktank und Canonical: http://www.inktank.com/news-events/new/inktank-partners-with-canonical
- Inktank und Ceph: http://www.inktank.com/news-events/new/shuttleworth-invests-1-million-in-ceph-storage-startup-inktank/
- Titelthema “Dateisystem-Meisterschaft”, Linux-Magazin 07/12, S. 22 bis 39
- NFS: http://tools.ietf.org/html/rfc1094
- NFS 3: http://tools.ietf.org/html/rfc1813
- NFS 4: http://tools.ietf.org/html/rfc3530
- CIFS 1.0: http://tools.ietf.org/html/draft-leach-cifs-v1-spec-01
- Lustre: http://wiki.lustre.org/index.php/Main_Page
- Google-FS: http://queue.acm.org/detail.cfm?id=1594206
- Moose-FS: http://www.moosefs.org
- GFS: http://www.sourceware.org/cluster/gfs
- OCFS2: http://oss.oracle.com/projects/ocfs2/
- Die OSD-Familie: http://www.t10.org/drafts.htm#OSD_Family
- Ansi/Incits 400-2004: http://www.techstreet.com/standards/INCITS/400_2004?product_id=1204555
- Rados: http://ceph.com/docs/master/rados/
- Heka-FS: http://hekafs.org
- XFS: http://xfs.org
- Ext 4: http://ext4.wiki.kernel.org
- Btr-FS: http://btrfs.wiki.kernel.org
- Hadoop: http://hadoop.apache.org
- Open Stack: http://www.openstack.org
- AWS: http://aws.amazon.com/de/s3/
- REST: http://www.ics.uci.edu/~fielding/pubs/dissertation/rest_arch_style.htm
- Crush: http://www.ssrc.ucsc.edu/Papers/weil-sc06.pdf
- Qemu: http://wiki.qemu.org
- Gluster-FS-Translator: http://bugzilla.redhat.com/show_bug.cgi?id=805138





