
© Giuseppe Anello, 123RF.com
Die Auswahl an verteilten Dateisystemen unter Linux kann sich sehen lassen. Über die Basisfunktionalität verfügen sie alle, die Unterschiede für den Einsatz liegen im Detail. Das Linux-Magazin hat sich die wichtigsten genauer angesehen und ihre Eigenschaften zusammengetragen.
In Sachen verteilte Dateisysteme nehmen Suse und Red Hat unterschiedliche Positionen ein. Während RHEL voll auf Gluster-FS [1] setzt, bringt SLES das bereits in den Linux-Kernel integrierte Ceph [2] mit (siehe den Artikel “Speicher satt” in dieser Titelstrecke).
Neben den beiden Platzhirschen gibt es einige Projekte, die für spezielle Szenarien erfolgversprechendere Ansätze verfolgen. Dieser Artikel stellt Ceph und Gluster in einem breiten Überblick an die Seite von Xtreem-FS [3], FHG-FS [4], Lustre [5] und Open AFS [6]. Tabelle 1 fasst die wichtigen Eigenschaften der sechs Kandidaten übersichtlich zusammen.
Tabelle 1
Verteilte Dateisysteme für Linux im Vergleich
|
Eigenschaft |
Ceph und Ceph-FS |
Gluster-FS |
Xtreem-FS |
FHG-FS |
Lustre |
Open AFS |
|---|---|---|---|---|---|---|
|
Lizenz |
GPL |
GPL |
BSD |
GPL, FHG FS EULA |
GPL |
IBM Public License |
|
Server |
||||||
|
Server-Implementierung |
Usermode |
Usermode |
Usermode |
Usermode |
Usermode |
Usermode |
|
Sprache |
C |
C |
Java |
Java und C |
C |
C |
|
Server-Plattform |
Linux |
Linux |
Linux |
Linux |
Linux, Solaris |
Linux, Unix |
|
Zugriffsprotokoll(e) |
nativ |
nativ und NFS |
nativ |
nativ |
nativ |
nativ |
|
Blockgeräte-Zugriff |
ja |
nein |
nein |
nein |
nein |
nein |
|
Qemu-Integration |
ja |
nein (in Arbeit) |
nein |
nein |
nein |
nein |
|
Interconnect |
IP-basiert |
IP-basiert und Infiniband |
IP-basiert |
IP-basiert und Infiniband |
IP-basiert und Infiniband |
IP-basiert |
|
Dateiverschlüsselung |
nein |
nein (Prototyp vorhanden) |
nein |
nein |
nein |
nein |
|
Backend-Dateisystem |
XFS, Btr-FS, Ext 4 |
XFS, Ext 4 |
beliebig |
XFS, Ext 4 |
Ldisk-FS (Ext 4), ZFS |
Ext 2, 3, 4, XFS, JFS, … |
|
Speicherobjekt |
Stripe (4096 KByte) |
Datei (außer beim Striping) |
Stripe (128 KByte) |
Stripe (512 KByte) |
Stripe (4096 KByte) |
Datei |
|
Online-Größenänderung |
ja |
ja |
ja |
ja |
ja |
ja |
|
NAS-Ersatz |
ja |
ja |
ja |
ja |
ja |
ja |
|
SAN-Ersatz |
ja |
nein (in Arbeit) |
nein |
nein |
nein |
nein |
|
Ausfallsicherheit |
ja |
ja |
ja |
nein (geplant) |
ja |
ja |
|
GUI verfügbar |
nein |
ja (kommerziell) |
teilweise |
ja |
teilweise |
nein |
|
Hadoop-Integration |
ja |
ja |
ja |
k.A. |
ja |
ja |
|
Open-Stack-Integration |
ja |
ja |
nein (theoretisch möglich) |
nein (theoretisch möglich) |
nein (theoretisch möglich) |
nein (theoretisch möglich) |
|
Produktionsreif |
Blockgeräte-Schicht |
Posix-Schicht |
n/a |
Posix-Schicht |
Posix-Schicht |
Dateisystem-Schicht |
|
Client |
||||||
|
Client-Implementierung |
Kernel- und Usermode |
Usermode |
Usermode |
Kernelmode |
Kernelmode |
Kernelmode |
|
Client-Plattform |
Linux |
Linux, Unix |
Linux, Mac OS X, Windows |
Linux |
Linux, Solaris |
Linux, Unix, Mac OS X, Windows |
|
Posix-konform |
ja |
größtenteils |
größtenteils |
ja |
ja |
nein |
|
WAN-Verteilung |
nein |
ja |
nein |
nein |
nein |
ja |
|
Enterprise-Support |
ja |
ja |
nein |
ja |
ja |
ja |
|
Integration in Enterprise-Linux |
ja |
ja |
nein |
nein |
nein |
nein |
Aus dem Grid: Xtreem-FS
Die Entwicklung von Xtreem-FS begann im Rahmen eines europäischen Forschungsprojekts, das an einem Linux-basierten Grid-Betriebssystem arbeitete. Dieses Xtreem-OS [7] soll die Brücke zwischen den Vorteilen des Grid-Computing und der einfachen Verwaltung einzelner Rechner schlagen.
Für die Ablage der Daten wollten die Entwickler ein verteiltes Dateisystem verwenden. Zu Projektbeginn 2006 erwies sich aber die Auswahl an möglichen Kandidaten unter Linux als recht dünn, auch weil die Anforderungen von Xtreem-OS – Verteilung, Sicherheit und Skalierbarkeit – das Feld deutlich einengten. So beschloss das Projekt, auch ein eigenes Dateisystem zu schaffen.
Knapp drei Jahre später erschien Version 1.0, die bereits parallele Lese- und Schreibzugriffe bot, ebenso die Replikation von Daten im Lese-Modus. Mitte 2011 kam Version 1.3 heraus, die auch die Replikation im Schreib-Modus erlaubt. Zu dieser Zeit vollzogen die Entwickler des Dateisystems auch den Wechsel von der GPLv2 zur BSD-Lizenz.
Die Unterstützung für Hadoop, die Re-Integration von Windows als Client, verbesserte Stabilität und asynchrone Schreibzugriffe folgten erst mit der Version 1.4, die bei Redaktionsschluss dieses Artikels erschien. Mit der stellen die Entwickler zudem die Bibliothek »libxtreemfs« für Java bereit. Anwendungen können sie nutzen, um direkt mit Xtreem-FS zu kommunizieren. Ein explizites Mounten ist dann nicht nötig.
Made in Germany: Fraunhofer-FS
Die Wiege des Fraunhofer Gesellschaft File System (FHG-FS, manchmal auch Fraunhofer-FS) steht im Institut für Techno- und Wirtschaftsmathematik. Im Jahr 2004 beschlossen dessen Mitarbeiter, das bisher benutzte Lustre durch eine Eigenentwicklung abzulösen. Im Pflichtenheft fanden sich unter anderem folgende Anforderungen: keine Notwendigkeit für Kernelpatches, verteilte Metadaten sowie die Wahlmöglichkeit zwischen Ethernet und Infiniband für die Interconnects. Drei Jahre später konnten die Entwickler die erste Version von FHG-FS vorzeigen. Mittlerweile liegt das es in der Version 2011.04 vor.
Neben den oben genannte Punkten war und sind den Entwicklern HPC-Tauglichkeit und einfaches Verwalten des Dateisystems sehr wichtig. Der Aspekt Hochverfügbarkeit hingegen ist von geringer Priorität und soll erst in der nächsten Version mehr Beachtung finden.
Zum gegenwärtigen Zeitpunkt ist nur der FHG-FS-Client weitestgehend im Quelltext verfügbar und unter der GPLv2 lizenziert. Leider haben Fraunhofers dem Clientcode auch ein paar Binärobjekte beigefügt, die wie manche anderen Komponenten einem End User Licence Agreement (EULA) für FHG-FS [8] unterliegen, aber kostenlos erhältlich sind.
Daten über Daten
Xtreem-FS und FHG-FS bauen auf ähnlichen Komponenten auf. Gemeinsamkeiten gibt es beispielsweise bei den Instanzen, die sich komplett um die Verwaltung der Metadaten kümmern. Beide Dateisysteme implementieren sie als Prozesse im Userspace. Zum Starten und Stoppen benutzt der Admin Init-Skripte. Xtreem-FS verwendet dafür den nicht privilegierten Account »xtreemfs« , bei FHG-FS läuft alles mit Rootrechten.
Bei Xtreem-FS hört die Instanz auf den Namen MRC – Meta data and Replication Catalogue. Wie der Name impliziert, kümmert sich diese Verwaltungseinheit auch um das Replizieren von Daten, um so die Ausfallsicherheit zu erhöhen. Auch die MRC-Server selbst kann der Admin als eine Art Farm mit Failover-Funktionalität aufsetzen. Es sind mindestens drei Instanzen nötig, da die beteiligten Rechner die gültige Dateiversion per Mehrheitsentscheidung bestimmen.
Die Metadaten selbst legt Xtreem-FS in der eingebetteten, dateibasierten Babu DB [9] ab. Deren Daten liegen lokal auf den einzelnen MRC-Servern. Damit im Fall eines Failover auch dem neuen Master alle Informationen vorliegen, muss Xtreem-FS diese immer synchron halten. Glücklicherweise müssen die Entwickler dazu fast gar nichts machen: Babu DB bringt die entsprechenden Kopiermechanismen bereits mit.
Das Fraunhofer-FS hingegen kennt zwei Möglichkeiten für die Ablage der Metadaten: in einer normalen Datei oder in erweiterten Attributen. Während Ersteres dem Admin mehr Auswahlmöglichkeiten bei der Auswahl des Dateisystems erlaubt, ist der zweite Ansatz deutlich performanter.
Die Entwickler empfehlen übrigens als lokales Dateisystem Ext 4, und zwar mit einer Inode-Größe von 512 Byte. In diesem Fall kann FHG-FS die Metadaten direkt im Inode ablegen. Fällt der Metadaten-Server aus, hängen alle Systemaufrufe, die auf eben jene Informationen zugreifen wollen, beispielsweise auch »stat()« .
Die Ablage
Die eigentlichen Daten verwalten bei Xtreem-FS und FHG-FS die Storage-Server, auch OSD (Object-based Storage Device) genannt. Auch dort laufen normale Prozesse im User Mode eines Linux-Systems, Init-Skripte übernehmen das Starten und Stoppen. Beide Dateisysteme organisieren die OSDs in Farmen, allerdings mit etwas unterschiedlichen Zielen. Sowohl Xtreem-FS als auch FHG-FS können die Last über mehrere Storage-Server verteilen. Sie unterteilen Dateien dazu in Häppchen von 128 KByte (Xtreem-FS) beziehungsweise 512 KByte (FHG-FS) und legen diese so genannten Chunks (Stücke) auf der konfigurierten Anzahl von OSDs ab. Die Größe dieser Häppchen kann der Anwender auch nach seinen Wünschen konfigurieren.
Xtreem-FS nutzt zusätzliche OSDs für Kopien der Daten, um die Ausfallsicherheit zu erhöhen. Die beteiligten Server wählen dazu einen Master, der sich durch ein Lease den anderen gegenüber als Chef zu erkennen gibt. Über ihn laufen sowohl Lese- als auch Schreibzugriffe. Bei neuen Anfragen kommt es erneut zum Auswahlprozess, gegebenenfalls gibt es ein neues Ober-OSD. Fällt der Master aus, bestimmen die verbliebenen Storage-Server einen neuen Chef. Macht eines der übrigen OSDs Probleme, verfügt Xtreem-FS über zwei Möglichkeiten, darauf zu reagieren: kompletter Fehlschlag oder Nutzung der verbliebenen Storage-Instanzen. Welchen Weg das Dateisystem wählt, bestimmt der Admin per Konfiguration.
OSDs besitzen eine Art Zwitter-Funktionen. Sie sind einerseits Teile eines objektbasierten Storage-Systems und verwenden andererseits eine normales Dateisystem zur internen Datenverwaltung. FHG-FS empfiehlt die Verwendung von XFS, im Projekt-Wiki finden sich zahlreiche Tuning-Tipps für die Storage-Server: Mount-Optionen, optimale I/O-Scheduler sowie Einstellungen für die Speicherverwaltung. Xtreem-FS ist bei der Wahl der Backend-Datenablage flexibler, denn Funktionen wie Copy on Write oder Snapshotting haben die Entwickler bereits im eigenen Dateisystem eingebaut.
Das große Ganze
Ergänzend zur Daten- und Metadaten-Verwaltung ist eine Instanz mit Gesamtverantwortung erforderlich. Der Client soll einerseits recht wenig von der Topologie im Hintergrund wissen, muss aber andererseits einen Einstiegspunkt ins Dateisystem haben. Bei Xtreem-FS ist das der Dir-Server (Dir, Directory). Dieser dient als Zentralregistratur für die Dienste des Dateisystems, OSD, MRC und Volumes. Abbildung 1 zeigt die Architektur von Xtreem-FS im Überblick.
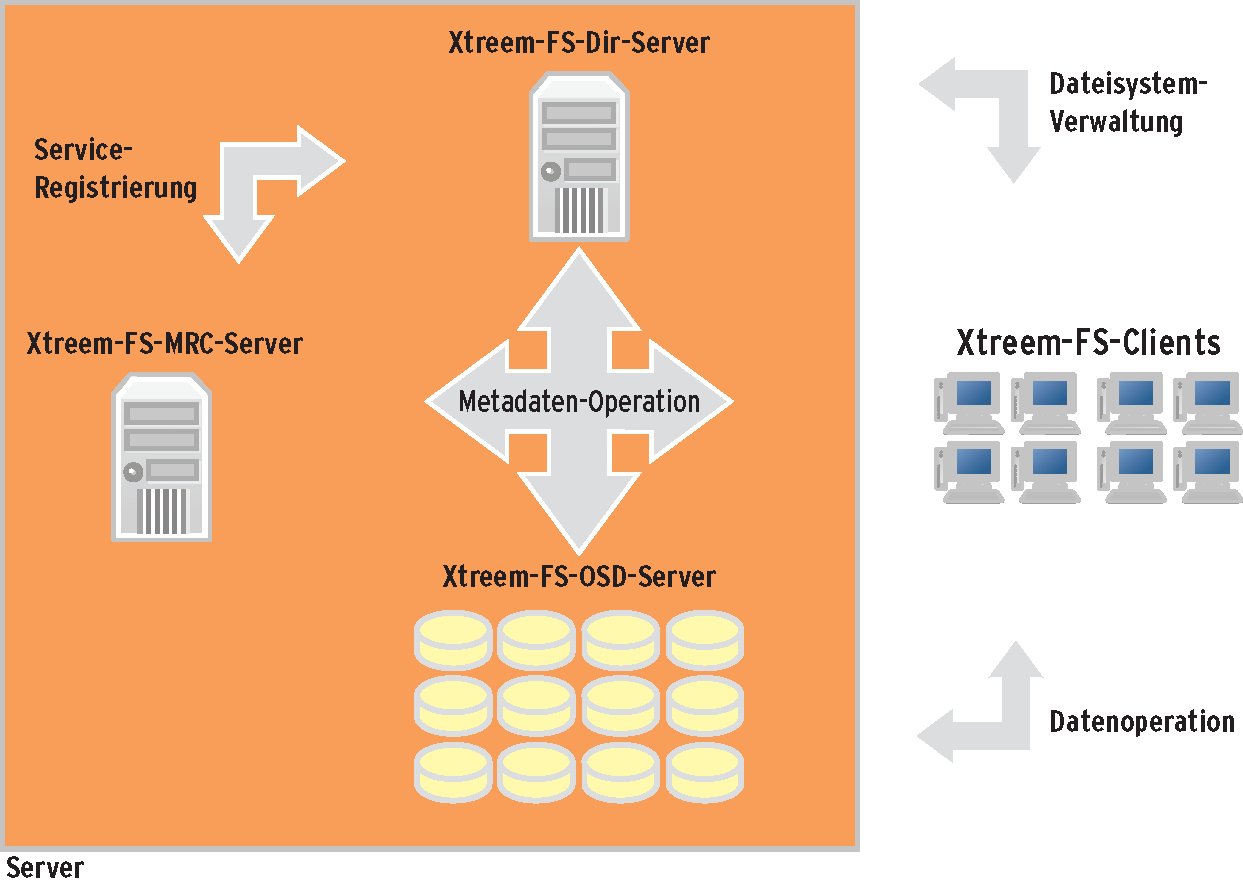
Abbildung 1: Die Architektur von Xtreem-FS: Die Nutzdaten liegen in den OSDs, die Metadaten im MRC, und den Einstiegspunkt für die Clients stellt der Dir-Server da.
Die Entwickler verwenden zur Ablage der Informationen der Dir-Instanz wiederum Babu DB. Auch ein Failover ist theoretisch – und analog zu den MRC-Servern – möglich. In den Tests des Linux-Magazins wollte dies aber nicht funktionieren. Für den produktiven Einsatz muss der Admin hier auf andere Mittel, etwa auf Pacemaker & Co. zurückgreifen.
Beim Fraunhofer-Dateisystem übernimmt der Management-Server analoge Aufgaben. Metadaten- und OSD-Instanzen kommunizieren ständig mit ihm, denn er kennt die Konfiguration des FHG-FS-Verbunds (Abbildung 2). Auch hier besitzt das Dateisystem implizite Methoden, die Ausfällen vorbeugen sollen, aber bis die nächste Version die versprochene Besserung bringt, muss der Admin zusätzlich externe Maßnahmen ergreifen. Bei beiden Dateisystemen sind die Management-Instanzen wieder Prozesse im Usermode.
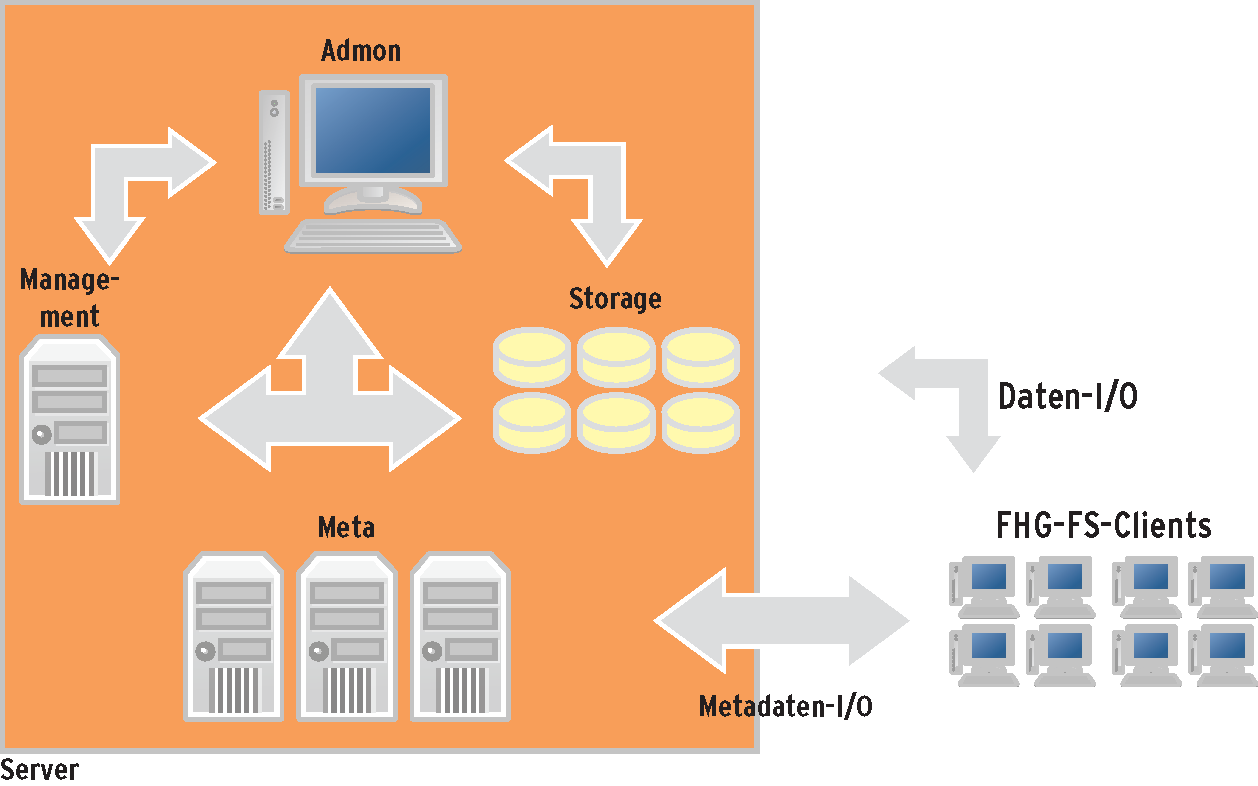
Abbildung 2: Die Komponenten von FHG-FS: Metadaten-Server und OSDs kommunizieren ständig mit dem Management-Server, der Admin-Monitor dient zum Steuern der Dienste und gibt Statusinformationen aus.
Ein selbst gestecktes Ziel von Xtreem-FS war es, möglichst plattformunabhängig zu sein. Dies schlägt sich auch in der Auswahl von Java als Programmiersprache nieder, verhindert aber gleichzeitig eine Integration in den Linux-Kernel. Das Dateisystem greift daher auf das Userspace-Dateisystem Fuse [10] zurück. Obwohl Performance nicht das Hauptaugenmerk der Entwickler ist, empfehlen sie doch, möglichst aktuelle Fuse-Bibliotheken zu verwenden.
Das Fraunhofer-FS hingegen ist in C geschrieben, was unter anderem einen schnelleren Client im Kernel-Mode möglich macht. Die teilweise proprietäre Lizenzierung verhindert aber den Einbau in den Mainline-Kernel. Das Programmpaket kann aber vorhandene Schnittstellen benutzen, um das entsprechende Modul zu bauen. Dazu darf der Linux-Kernel nicht älter als Version 2.6.16 sein.
Java im GUI
An anderer Stelle verwendet aber auch FHG-FS Java – beim Admin-GUI (Abbildung 3). Es vereinfacht die Installation der Software, die Integration neuer Rechner, das Starten und Stoppen von Instanzen und gibt sogar Einblick in Statistiken des Dateisystems. Eine Anforderung der Xtreem-FS-Entwickler war die Skalierbarkeit auf WAN-Ebene.
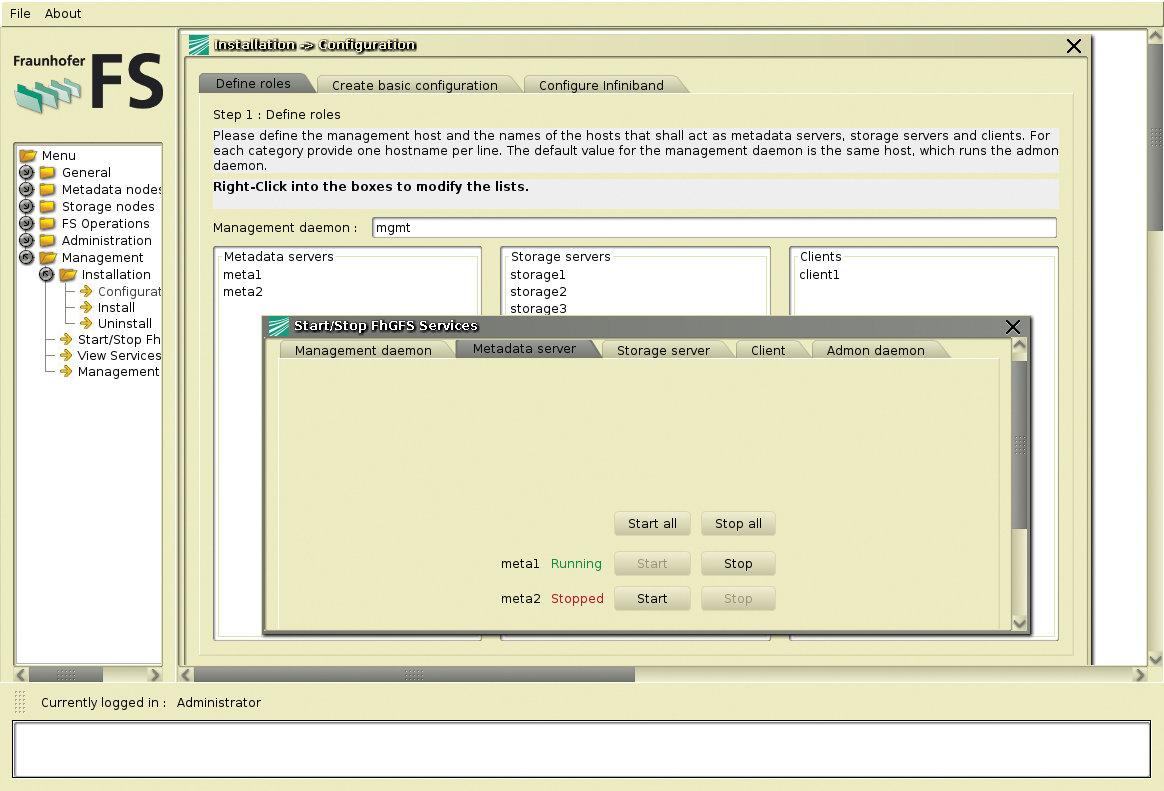
Abbildung 3: Das in Java umgesetzte Admin-GUI von FHG-FS heißt Admon. Es hilft bei der Installation, der Administration der Dienste und gibt Informationen zum Dateisystem aus.
Das Schicken von Daten über öffentliche Netzwerke ruft selbstverständlich Sicherheitsexperten und Datenschützer auf den Plan, deshalb erhielt das Dateisystem ein SSL-Modul. Das kann der Admin in zwei Modi betreiben: Zum Authentisieren oder zum Verschlüsseln der Kommunikationskanäle. Die notwendigen Zertifikate müssen lokal vorliegen, eine Integration in vorhandene PKIs ist nicht möglich. Das Verschlüsseln der Kommunikation erfolgt nach dem Prinzip “Alles oder Nichts”. Daher müssen alle Xtreem-FS-Komponenten die zugehörigen Zertifikate lokal installiert haben.
Dies hat einen faden Beigeschmack, da insbesondere die Clientrechner möglicherweise in Bereichen mit recht niedrigem Sicherheitslevel stehen. Glücklicherweise lassen sich die Zertifikate mit Passwörtern schützen. Dabei gibt sich die Software aber eine peinliche Blöße: Solange der Client Zugriff auf Xtreem-FS hat, läuft ein entsprechender Mountprozess, und in dessen Parameterliste taucht das Passwort im Klartext auf.
Alter Andrew
Der Aufschwung verteilter Dateisystem in den letzten Jahren ist genau genommen schon der zweite – wenn nicht sogar dritte – Frühling dieser Technologie. Das Zusammenfassen lokaler Verzeichnisse in einem gemeinsamen Namensraum ist nicht wirklich neu, auch nicht unter Linux. Wer schon länger in der IT unterwegs ist, hat sicher schon vom Andrew File System (AFS) gehört.
Die Entwicklung begann an der Carnegie Mellon Universität als Teil des Andrew-Projekts. Nach einer kommerziellen Phase in den 1990ern veröffentlichte IBM im Jahr 2000 schließlich den Quelltext. Dieser Termin gilt heute als Geburtsstunde von Open AFS, das unter IBM Public License steht. Analog zu Xtreem-OS und Xtreem-FS war AFS als verteiltes Dateisystem nur als Hilfsmittel für das eigentliche Projekt gedacht. Ziel von Andrew war es, Dokumente, Programme und E-Mails einfach und sicher auszutauschen.
Auch bei AFS und Open AFS gibt es Fileserver, deren Aufgabe das Verwalten der Dateien ist. Dafür läuft eine Reihe von Prozessen, die jeweils spezielle Aufgaben haben. Dazu gehören die Verwaltung des Platzes an sich, aber auch das Anfertigen und Verfolgen von (Sicherungs-)Kopien und die Zugriffskontrolle. Im Grunde besteht der Namensraum von (Open) AFS aus zwei Teilen: Auf den globalen Part können alle Rechner im Verbund zugreifen, er ist über einen einheitlichen Pfad zu erreichen. Jeder Client verfügt zudem über einen lokalen Teil und verwaltet dort Daten, die nur für diesen Rechner von Interesse sind.
Von jeher sind AFS-Verbünde recht groß, Tausende von Clientrechnern sind keine Seltenheit. Damit das Dateisystem für die verschiedenen Bedürfnisse und Anforderung verwaltbar ist, findet typischerweise eine Unterteilung in so genannte Zellen statt. Die Administration und Konfiguration von Zelle A ist dabei weitestgehend unabhängig von Zelle B.
Aus Performancegründen cachen die Clients sehr stark. Lese- und Schreibzugriffe finden somit lokal statt. Änderungen an den Daten auf dem Client teilt der so genannte Cache-Manager dem Server mit. Er trägt auch dafür Sorge, dass die lokalen Daten ausreichend aktuell sind. So kann der AFS-Anwender sogar auf Daten zugreifen, wenn der entsprechende Server gerade nicht verfügbar ist. Das Sicherheitskonzept des Dateisystems beruht auf Kerberos und Zugriffskontrolllisten.
Noch ein Senior: Lustre
Im HPC-Umfeld gibt es mit Lustre ebenfalls seit einiger Zeit ein gestandenes verteiltes Dateisystem. Die bewegte Geschichte dieses Softwareprojekts begann ebenfalls an der Carnegie Mellon Universität. Es folgte der Erwerb durch Sun Microsystems 2007 und der Aufkauf durch Oracle im Jahr 2010, dann das Hin und Her bezüglich des Supports von bestimmten Versionen. Seit 2011 fährt das GPLv2-lizenzierte Lustre in ruhigeren Gewässern. Die Firma Whamcloud [11] hat sich der Weiterentwicklung der Software angenommen und beschäftigt zwei der führenden Architekten.
Die Architektur von Lustre folgt dem objektbasierten Ansatz. Dabei existieren separate Instanzen für Metadaten (MDS, Meta Data Server) und die eigentlichen Daten (OSS, Object Storage Server). Jeder MDS verfügt über ein MDT (Meta Data Target), das die Metadaten für Lustre speichert (Abbildung 4).
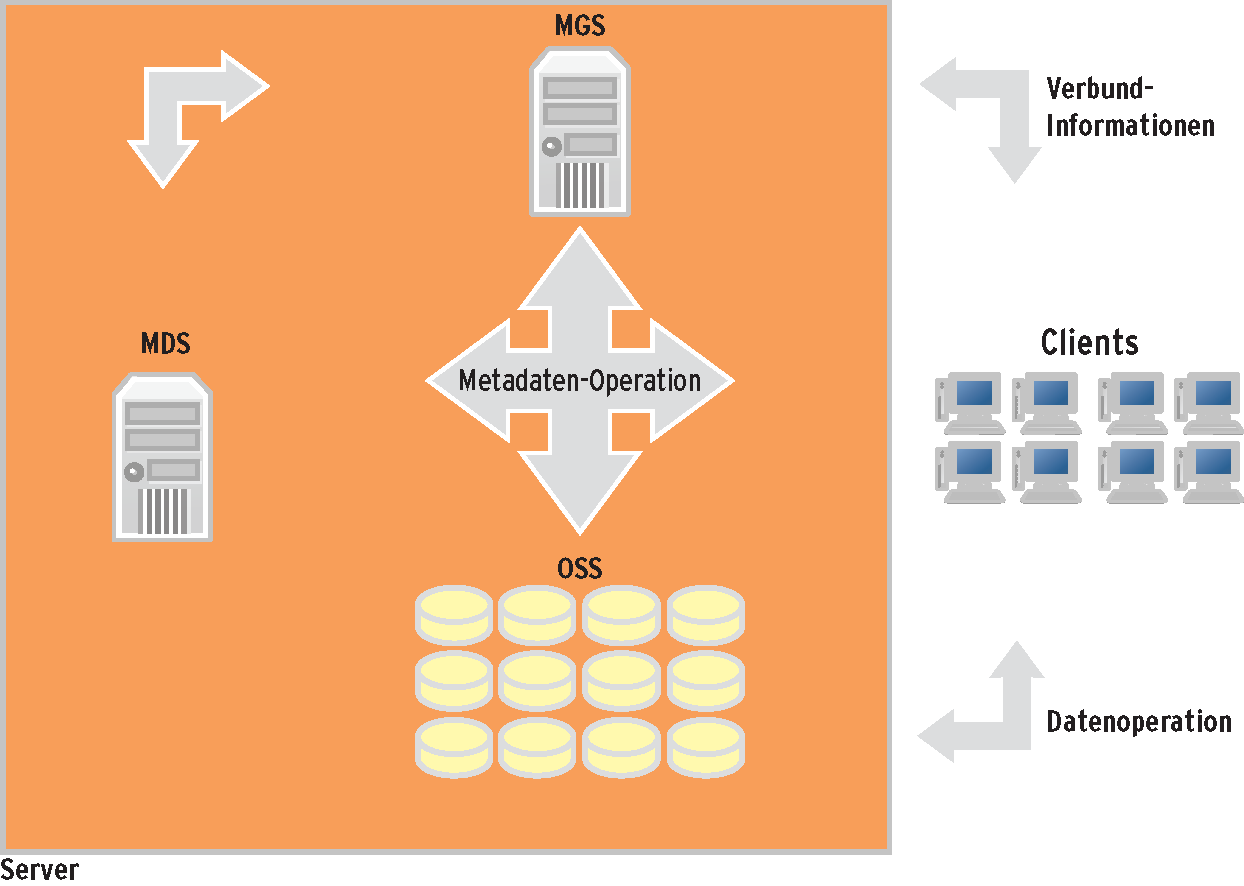
Abbildung 4: Lustre folgt dem objektbasierten Storage-Ansatz. Es speichert die Daten in den OSS, die Metadaten liegen in der separaten Instanz MDS. Der Management-Server MGS verwaltet das Dateisystem.
Für die Daten gilt ein ähnliches Konzept: Jedes lokale Dateisystem, das der OSS für Lustre verwendet, entspricht einem OST (Object Storage Target). Zwei oder mehr OSTs pro Storage-Server sind dabei ganz normal.
Punktueller Kontakt
Lustre sieht prinzipiell nur einen MDS pro Verbund vor. Seine Ausfallsicherheit lässt sich mit klassischen Failover-Clustern erhöhen, der MDS bleibt aber der potenzielle Engpass, wenn viele Metadaten-Zugriffe zeitgleich erfolgen. Der SPOC-Ansatz (Single Point of Contact) von Lustre steht daher auch immer wieder in der Kritik.
Zum Abspeichern der Daten auf den OSS verwendet Lustre typischerweise entweder Ext 3, Ext 4 oder ZFS – eventuell in etwas modifizierter Version. Im Falle von ZFS ist die Posix-Schicht ZPL (ZFS Posix Layer) überhaupt nicht erforderlich, denn Lustre interagiert direkt mit der ZFS-DMU (Data Management Unit). Neben dem Standard-Ext-4 kann der Admin auch eine angepasste Variante von Ext 3, das LDISKFS (Lustre DISK File System), einsetzen. Ziel dieses Backend-Dateisystems ist es, einige Schwächen von Ext 3 zu eliminieren. So findet die Allokierung der Blöcke für den Schreibzugriff im Vorhinein statt. Die Reservierung an sich erfolgt in größeren Einheiten – ähnlich dem Extent-basierten Ansatz von Ext 4.
In der Standardkonfiguration legt Lustre alle Daten einer Datei auf einem OST ab und unterteilt sie in 1 MByte große Stücke. Das Verteilen über mehrere OST ist ebenfalls möglich und sogar empfohlen. Ohne dieses Striping ist die Größe eines Objekts in Lustre durch die Größe des Backend-Dateisystems limitiert. Im anderen Falle liegt das (theoretische) Limit bei zirka 30 Petabyte.
Neben MDS und OSS gehören noch zwei weitere Komponenten zu Lustre: die Management Server (MGS) und das Lustre Network (LNET). Die MGS verwalten die Informationen über den Lustre-Verbund. Sie erhalten die notwendigen Daten von den anderen Komponenten und sind der erste Anlaufpunkt für die Clients. Analog zu den MDS muss der Admin auf externe Methoden zur Erhöhung der Ausfallsicherheit zurückgreifen. Aus Kostengründen hat sich dabei eine Doppelnutzung der Failover-Cluster bewährt: Der passive Knoten für Lustre-Verbund A ist der aktive für Lustre-Verbund B. Das LNET ist eine Schnittstelle für die Kommunikation mit den OSS und MDS. Es stellt eine Abstraktionsschicht über der eigentlichen Netzwerk-Topologie dar und vereinfacht die Sichtweise für Lustre. LNET unterstützt Ethernet und Infiniband.
Grüne Wiese oder Spezialist?
Die Auswahl an verteilten Dateisystemen für Linux ist ansehnlich, ihre Eignung für bestimmte Anwendungsszenarien unterschiedlich: Wer auf der grünen Wiese anfängt, sollte Ceph und Gluster bevorzugen. Deren Integration in Enterprise-Distributionen von Linux erleichtert ihren Einzug ins Rechenzentrum erheblich, und das aus technischer wie operativer Sicht. Die Verwendung als Unterbau für Hadoop oder die Virtualisierung sind weitere Pluspunkte, die sie für sich verbuchen können.
Um Daten recht einfach, plattformübergreifend und in großen Netzwerken auszutauschen, sind Xtreem-FS oder der Veteran Open AFS prima Kandidaten. Liegt der Schwerpunkt bei Leistung im HPC-Sinne, gilt Lustre als gesetzt, ein Blick auf FHG-FS lohnt aber auch. (mhu)
Infos
- Gluster-FS: http://www.gluster.org
- Ceph: http://www.ceph.com
- Xtreem-FS: http://www.xtreemfs.org
- FHG-FS: http://www.fhgfs.com
- Lustre: http://wiki.lustre.org
- Open AFS: http://www.openafs.org
- Xtreem-OS http://www.xtreemos.eu
- Lizenz des FHG-FS: http://www.fhgfs.com/docs/FraunhoferFS_EULA.txt
- Babu DB: http://code.google.com/p/babudb
- Fuse: http://fuse.sourceforge.net
- Whamcloud: http://wiki.whamcloud.com





