
© jock+scott, photocase.com
Github mit seiner einfach zu bedienende Weboberfläche lässt sich über seine Code-Archiv-Funktion hinaus für ganz und gar artfremde Dinge benutzen. Perlmeister Schilli zum Beispiel pflanzt mit Github ein Contentmanagement-System für einfache Webseiten in die Landschaft.
Auf Github.com arbeitet die Open-Source-Gemeinde an ihren Projekten, und die ehemalige Startup-Firma aus San Francisco hat auf diese Weise einige Berühmtheit erlangt. Mittlerweile stellen sich sogar finanzielle Erfolge ein. Auch gilt die Firma im erweiterten Silicon Valley schon als Vorzeigebeispiel dafür, wie man talentierte Entwickler anlockt [2]. So nimmt es nicht Wunder, dass die in der offenen Basisversion kostenlos angebotenen Repositories, der damit verbundene Plattenplatz und zuverlässiges Webhosting für allerlei Daten herhalten, die bei der Verleihung des Titels “Open-Source-Projekt des Jahres” niemand auf dem Zettel hat.
Wer hat sich nicht schon darüber geärgert, dass auf einem neuen Rechner die eigenen, über Jahre gepflegten Konfigurationsdateien wie ».bashrc« oder ».vimrc« noch nicht installiert sind? Da diese Dateien selten Geheimnisse enthalten, hat es sich eingebürgert, sie auf Github in einem Repository namens »dotfiles« einzubunkern. Wer jetzt in einer unterkonfigurierten Umgebung strandet, braucht nur einen Browser, um die vertrauten Dateien von einer leicht zu findenden Internetseite nachzuholen.
Hosting für lau
Aber es geht noch mehr. Nicht jeder Github-Nutzer weiß zum Beispiel, dass Entwickler dort auch ganz normale Webseiten hosten können. Wer auf dynamisch generierte Inhalte verzichtet und sich auf HTML, Javascript und Fotos beschränkt, kann mit einem kostenlosen Github-Account durchaus eine private Webseite zusammenstellen und online halten [3]. Vermeintlicher Nachteil: Auf Github gehostete Inhalte sind öffentlich als Open Source zugänglich – aber das sind sie auf einer statischen Webseite implizit sowieso.
Für seine Website legt der Github-Nutzer in einem neu angelegten Repository einen neuen Branch namens »gh-pages« an, stellt eine Datei »index.html« hinein und führt ein »git commit« mit anschließendem »push« aus. Jetzt darf er unter »http://Username.github.com/Repository-Name« staunend mit ansehen, wie seine neue Website auf einmal im Internet steht. Das Ganze ist kostenlos, und die Github-Infrastruktur hält die Site zuverlässig am Laufen.
Abbildung 1 zeigt den im Github-Repository »perlsnapshot« im Zweig »gh-pages« angelegten “Sourcecode” einer statischen HTML-Seite. Github erzeugt daraus automatisch – unmittelbar nach einem Push – eine auf einem öffentlich zugänglichen Webserver liegende und unter einer recht kurzen URL abrufbare Projektseite, Abbildung 2 zeigt sie.
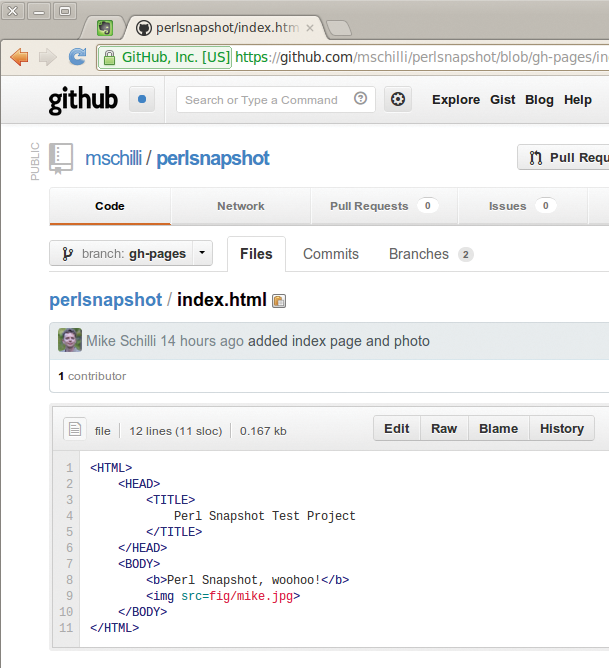
Abbildung 1: Github.com eröffnet Technikmuffeln die Möglichkeit, Textdateien direkt im Browser zu editieren und hosten zu lassen.
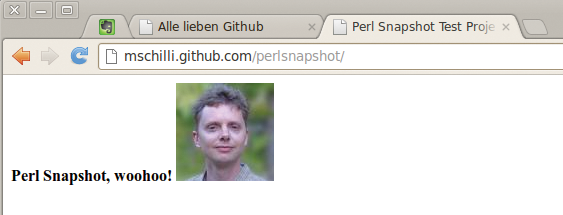
Abbildung 2: Technisch und optisch ein Highlight: Die automatisch von Github aus der Source im Branch »gh-pages« generierte Projektseite.
Online PLUS
In einem Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/plus/2013/01.
Los geht’s mit einem Klon
Um den erforderlichen Branch »gh-pages« in einem neu generierten Repository anzulegen, klont
git clone git@github.com/user/repo.git
dieses zunächst, und der User führt im Branch »master« einen einzigen Commit aus, zum Beispiel den einer Readme-Datei. Den für die Projektseite notwendigen Branch »gh-pages« erzeugt:
git checkout -b gh-pages
In diesem Branch legt der Webentwickler die Datei »index.html« und eventuell von dort referenzierte Bilder ab, zum Beispiel in einem Unterverzeichnis »fig« , und zimmert sie mit »git add« und »git commit« im Repository fest. Die neuesten Branch-Daten landen mit
git push origin gh-pages
bei Github. Der Dienst stößt daraufhin die automatische Seitengenerierung an.
Grafisch und intuitiv
Natürlich weiß jeder Software-Entwickler, der sein Geld wert ist, wie er »git« von der Kommandozeile aus zu bedienen hat und Updates ins Github-Repository hochlädt. Diese Fähigkeit technikmuffligem Personal beizubringen, wäre harte Arbeit. Zum Glück bietet Github jedermann eine leicht zu bedienende Weboberfläche, die auf Knopfdruck Textdateien im Repository anzupassen hilft.
Ein Klick auf den »Edit« -Button in Abbildung 1, und schon präsentiert der Browser ein intuitiv bedienbares Editierfenster, in das der User seine Änderungen am HTML-Code der Webseite eintippt. Zum Schluss drückt er »Save« und trägt optional noch einen Änderungskommentar ins Nachrichtenfeld ein. Github löst daraufhin einen Commit im Github-Repository mit der aktuellen Textversion aus und hält die Änderung damit samt Historie fest. Das Verfahren funktioniert allerdings nur bei Textdateien, Fotos checkt man entweder von der Kommandozeile oder mittels einer der auch für Linux verfügbaren grafischen Git-Frontends ein.
Wo ist der Web-Haken?
Dynamische Webseiten à la PHP bietet das Verfahren nicht, da der Github-Webserver keinen passenden Interpreter offeriert. Wem aber HTML zu unhandlich erscheint und wer lieber kompakte Plaintexte wie in einem Contentmanagement-System verwaltet, das die Rohinhalte automatisch mit HTML umrankt, dem wird im Folgenden geholfen.
Nach jedem erfolgreichen »push« von lokalen Commits ins öffentliche Github-Repository springt der Github-Server konfigurierte Service-Hooks an [4]. So erfährt zum Beispiel der Continuous-Integration-Service Travis-ci.org über einen Post-Receive-Webhook sofort von Änderungen im Entwicklungsbaum und kann die Testsuite anwerfen, um zu sehen, ob der Build mit dem neuesten Code noch funktioniert [5].
Unter »Admin« und der Sektion »Service Hooks« darf der Repository-Besitzer einen so genannten Webhook definieren, den Github jedes Mal anspringt, falls neue Commits per »git push« im Online-Repository gelandet sind (Abbildung 3). So erfahren fremde Webseiten allgemein von den Änderungen. Als so genannte Payload (bezahlte Fracht) legt Github jedes Mal Json-formatierte Metadaten bei, die darüber Auskunft geben, in welchem Repository Änderungen eingingen, welche Dateien betroffen waren und wie die SHA1-IDs vor und nach dem Commit aussehen.
Dabei darf in einem Push nicht nur ein Commit ankommen, es sind sogar mehrere erlaubt. Für jeden findet sich ein Eintrag im Feld »commits« , das ein Array von Einzel-Commits enthält. Abbildung 4 zeigt die Json-Daten nach einer Commit-Push-Kombination der Projektseite »index.html« . Ein in Perl geschriebenes CGI-Skript wie das in Listing 1 nimmt den Request entgegen, fieselt mit einem Json-Parser interessante Details heraus und startet dazu passende Aktionen.
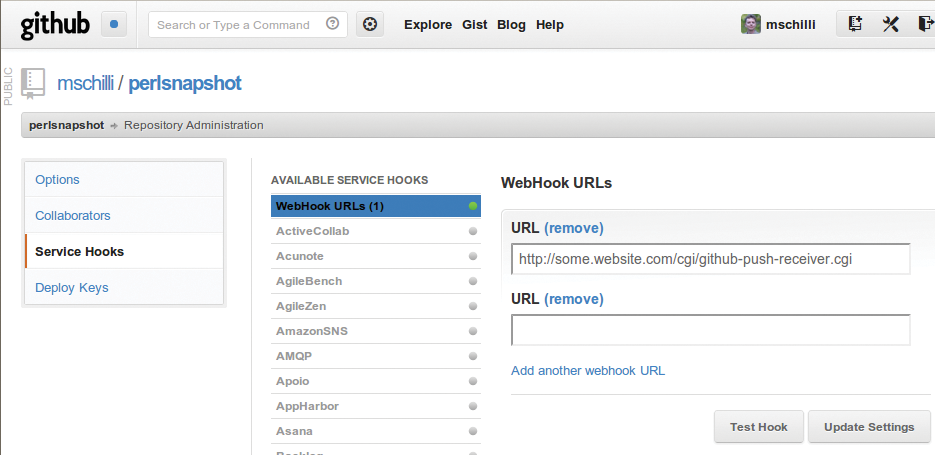
Abbildung 3: Der Webhook auf Github schickt eine Nachricht an einen beliebigen Webserver, falls Änderungen am Repository erfolgen.
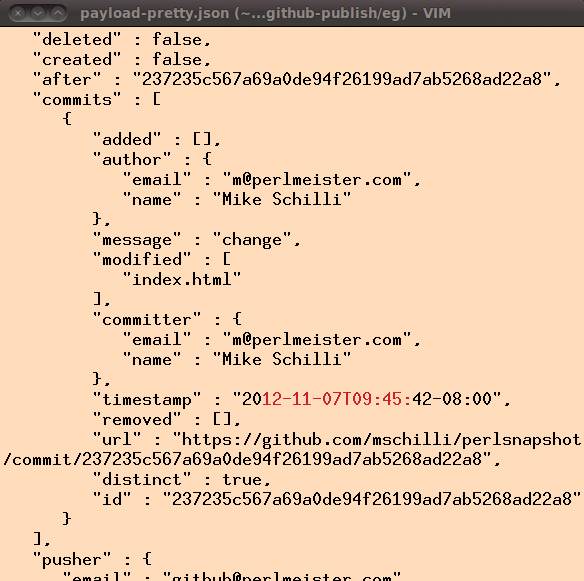
Abbildung 4: Die Payload des Commit im Json-Format signalisiert der Website, welche Dateien sich im Repository verändert haben.
Contentmanagement für Arme
Listing 1 implementiert ein simples Contentmanagement-System, das seine Sourcen auf Github ablegt. Es baut mit Perls auf dem CPAN erhältlichen »Template« -Modul Textbausteine mit Templates zusammen und bietet sie auf dem eigenen Webserver an. Auch Technik-Laien schaffen es, auf dem Github-UI die Textdateien »001.txt« , »002.txt« und so weiter zu editieren (Abbildung 5).
Die Texte enthalten Anweisungen zum Einbinden von Template-Dateien, die einleitende und abschließende HTML-Sequenzen einbinden (Abbildung 6), ohne den User mit technischen Details zu belasten. Klickt er den »Save« -Button an, speichert Github die Änderungen im Repository ab und feuert den Webhook auf das CGI-Skript eines privaten Webservers ab. Das Skript findet über die Json-Daten heraus, welche ».txt« -Datei sich verändert hat, frischt seinen lokalen Klon des Repository auf und wirft für die betreffenden Dateien den Template-Generator an. Das Diagramm in Abbildung 7 zeigt den Ablauf.
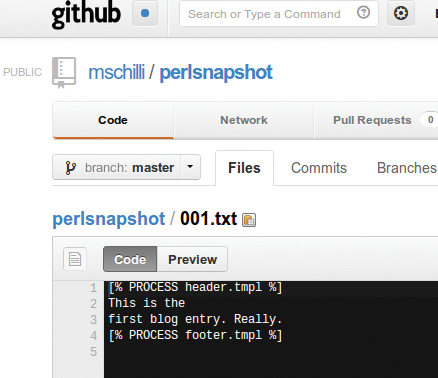
Abbildung 5: Diese sehr einfache Textdatei editiert der technisch unbedarfte User.
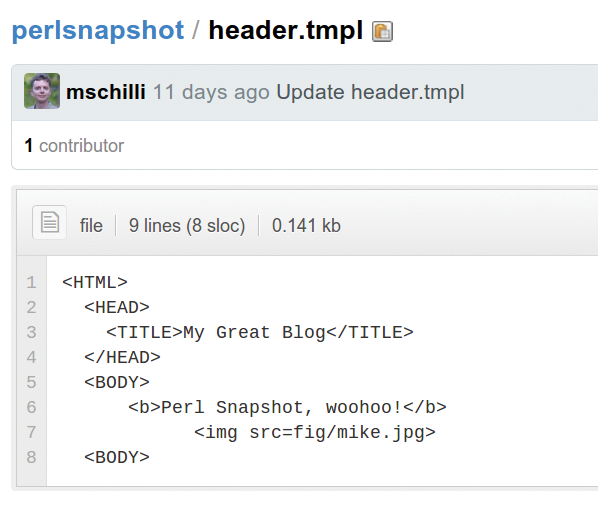
Abbildung 6: Der Template-Header enthält den HTML-Markup, der dem User erspart bleibt.
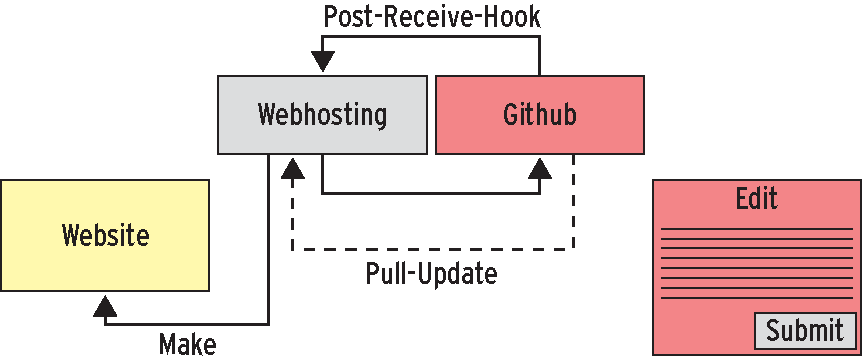
Abbildung 7: Githubs Webhook benachrichtigt die Website, die wiederum die neuen Sourcen von Github abholt und daraus formatierte Webseiten backt.
Alles protokolliert
Der Hostingservice könnte zwar bei jedem Push alle Textdateien durchforsten und neue Seiten generieren, aber bei Tausenden von Dateien spart der Webhook mit den detaillierten Änderungsinformationen viel Zeit. Das Skript in Listing 1 legt der Entwickler ausführbar im CGI-Verzeichnis des Webservers ab und konfiguriert das Github-Repository im Admin-Bereich mit der URL als Webhook, wie Abbildung 3 zeigt.
Listing 1 definiert in den Zeilen 11 bis 18 die lesende URL hin zum Original-Repository von Github (»$github_repo« ) und die Pfade zu dem lokalen Repo-Klon (»$repo _dir« ) und dem Zielverzeichnis (»$target_dir« ), von dem aus der Webserver die fertigen HTML-Dateien an die andockenden Browser ausliefert.
Damit Interessierte nachvollziehen können, was das CGI-Skript so treibt und wo Fehler auftreten, schaltet Zeile 20 das Log4perl-Modul an und lässt die Applikation die Arbeitsschritte in der Logdatei »gpr.log« im Homeverzeichnis des Webserver-Users mitprotokollieren. Wie Abbildung 8 zeigt, loggen nicht nur die explizit im Code sichtbaren Log4perl-Anweisungen (»DEBUG« , »INFO« und so weiter), sondern auch die im Sysadm::Install-Modul versteckten. So schreibt das Skript mit, welche Git-Befehle mit »tap« und »sysrun« gelaufen sind, welchen Returncode sie zurücklieferten und was sie auf Stdout und Stderr zum Besten gaben.
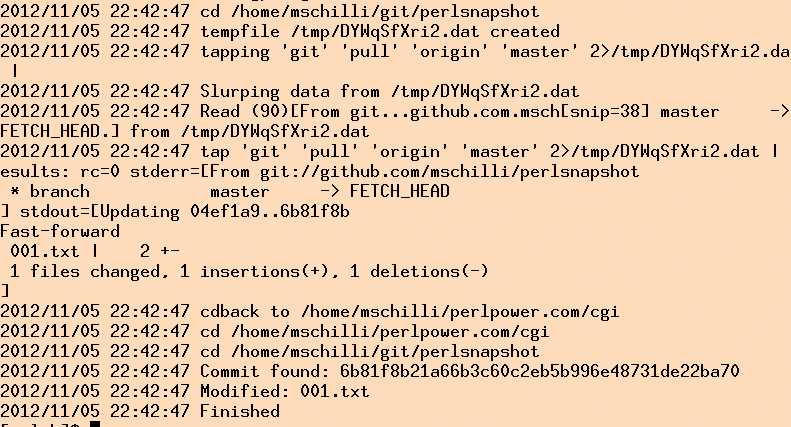
Abbildung 8: Die Logdatei zeigt an, was nach dem Push auf dem Webhoster passiert ist. So lassen sich eventuell auftauchende Fehler schnell finden.
Listing 1
github-push-receiver.cgi
01 #!/usr/bin/perl -w
02 use strict;
03 use CGI qw( :all );
04 use Log::Log4perl qw(:easy);
05 use JSON qw( from_json );
06 use Sysadm::Install qw( :all );
07 use File::Basename;
08
09 my( $home ) = glob "~";
10
11 my $target_dir =
12 "$home/htdocs/perlsnapshot";
13 my $repo_dir =
14 "$home/perlsnapshot.git";
15 my $github_repo =
16 # read-only
17 "git://github.com/mschilli" .
18 "/perlsnapshot.git";
19
20 Log::Log4perl->easy_init( {
21 file => ">>$home/gpr.log",
22 level => $DEBUG,
23 });
24
25 print header( 'text/txt' );
26
27 my $json = param( 'payload' );
28
29 if( !defined $json ) {
30 LOGDIE "Parameter payload missing";
31 }
32
33 if( ! -d $repo_dir ) {
34 cd dirname $repo_dir;
35 tap qw( git clone ), $github_repo,
36 basename $repo_dir;
37 cdback;
38 }
39
40 # Get latest update from Github
41 cd $repo_dir;
42 tap "git", "pull", "origin", "master";
43 cdback;
44
45 my $payload = from_json( $json );
46
47 cd $repo_dir;
48
49 for my $commit (
50 @{ $payload->{ commits } } ) {
51
52 INFO "Commit found: $commit->{ id }";
53
54 for my $file (
55 @ { $commit->{ modified } } ) {
56
57 INFO "Modified: $file";
58
59 if( $file =~ m#^(\d{3}\.txt)$# ) {
60
61 ( my $html_file = $file ) =~
62 s/\.txt$/.html/;
63
64 sysrun "tpage $file " .
65 ">$target_dir/$html_file";
66 }
67 }
68 }
69
70 print "OK\n";
71 DEBUG "Finished";
Aufgefrischter Klon
Um an den Inhalt der aktualisierten Textdateien zu gelangen, muss das Skript in Zeile 35 einen lokalen Klon des Github-Repository anlegen, falls dieser noch nicht im Zuge vorheriger Skriptaufrufe bereits entstanden ist. Andernfalls kommt Zeile 42 zum Tragen und führt ein Update zur neuesten Version durch. Die Funktionen »cd« und »cdback« des CPAN-Moduls Sysadm::Install helfen dabei, in Verzeichnisse hinein- und nach getaner Arbeit wieder herauszuspringen. Die aus dem Modul »JSON« exportierte Funktion »from_json()« dekodiert die im CGI-Parameter »payload« ankommenden Json-Daten und legt sie als Perl-Datenstruktur in »$payload« ab.
Vorsicht Angreifer!
Beim Auswerten der eingehenden Daten ist darauf zu achten, dass keineswegs sichergestellt ist, dass der Json-Salat wirklich von Github kommt. Angreifer könnten das Web-offene CGI-Skript nutzen, um den Webserver zu attackieren. Deshalb ist es wichtig, sämtliche Daten – die Namen der modifizierten Github-Dateien beispielsweise – auf Herz und Nieren zu prüfen, bevor das Skript sie weiterverarbeitet oder sie gar Kommandozeilentools übergibt. Der Schalter »-T« kann sicherstellen, dass zumindest regulärere Ausdrücke die Daten inspizieren. Doch auch dieses Verfahren findet nicht alle Lücken, die Verantwortung liegt letztendlich beim Programmierer.
Die For-Schleife ab Zeile 49 iteriert über alle Commits der vorher auf Github eingegangenen Push-Daten. Die editierten Dateien legt Github im Json-Array unter dem Eintrag »modified« ab, und die For-Schleife ab Zeile 54 nudelt sie alle durch. Passt eine Datei in das Schema »nnn.txt« , wirft Zeile 64 den Template-Expander »tpage« an.
Der Expander liegt dem Modul Template bei und kombiniert – entsprechend der Template-Anweisung »[% PROCESS %]« – die Header-, Footer- und Textdateien zu fertigen HTML-Dateien. Letztere landen wegen der Redirekt-Anweisung im Shellkommando im Verzeichnis »htdocs« des Webservers. Gespeicherte Fotos muss der Nutzer selbst dorthin kopieren. Alternativ könnte das ebenfalls Template beiliegende Skript »ttree« den gesamten Baum kopieren.
Mit etwas mehr Aufwand, als ihn dieser Artikel anstellt, könnten sich Entwickler beliebige Webseiten aus Github-Repositories generieren lassen. Die Vorteile einer Versionsverwaltung liegen auf der Hand, und die leicht zu bedienende Github-Oberfläche lädt Technik-nahe und -ferne Berechtigte gleichmaßen dazu ein, Tippfehler im Browser sofort zu korrigieren. Kurze Zeit später erscheint alles wie durch Zauberhand im Web.
Infos
- Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2013/01/Perl
- “The GitHub hiring experience”: https://github.com/blog/1269-the-github-hiring-experience
- Github: Instantly Beautiful Project Pages: https://github.com/blog/1081-instantly-beautiful-project-pages
- Github – “Post-Receive Hooks”: https://help.github.com/articles/post-receive-hooks
- Michael Schilli, “Continuous Integration ohne Klimmzüge”: Linux-Magazin 06/12,S. 94, https://www.linux-magazin.de/Heft-Abo/Ausgaben/2012/06/Perl-Snapshot
Der Autor

Michael Schilli arbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. In seinen seit 1997 erscheinenden Snapshots forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





