
© Mario Heinemann, Pixelio
Besonders die Statistik ist dem freien R auf den Leib geschrieben – einen Basisvorrat an Kommandos erweitern Tausende Zusatzpakete. Auch anspruchsvolle Grafiken gehen leicht von der Hand.
R – der Name könnte nicht knapper sein, doch er steht für das Gegenteil von Beschränkung, nämlich für eine verschwenderische Fülle an Funktionen zur Bearbeitung, grafischen Darstellung und vornehmlich statistischen Analyse von Daten. Zu R gehören eine eigene vollwertige, objektorientierte und funktionale Programmiersprache mit Interpreter, eine Laufzeitumgebung mit Grafikausgabe, ein Debugger und weitreichende Skripting-Möglichkeiten.
Die Software bietet mächtige Grafikfeatures, von denen die Graph Gallery unter [1] einen sehenswerten Eindruck vermittelt. Dazu kommt eine Vielzahl klassischer und sehr moderner statistischer und numerischer Werkzeuge für Datenanalyse oder Modellierung. Viele sind bereits in die Basisumgebung integriert, zahlreiche weitere stehen noch in den aktuell rund 1460 Zusatzpaketen zur Verfügung. Für besonders rechenaufwändige Aufgaben lässt sich außerdem C-, C++- oder Fortran-Code einbinden und zur Laufzeit aufrufen.
R wird seit 1998 im Comprehensive R Archive Network (CRAN, [4]) in kompilierter Form und als Quellcode sowohl für unterschiedliche Plattformen und Linux-Derivate als auch für Windows und Mac OS X bereitgehalten. CRAN stellt zudem die oben erwähnten Zusatzpakete zur Verfügung und bietet in seinen Task Views nützliche Übersichten über den Leistungsumfang ganzer themenverwandter Paketfamilien.
Präferenz für die Kommandozeile
Die R-Umgebung ist kommandozeilenorientiert. Es gibt zwar einige unterschiedlich mächtige GUIs, aber meist bleibt die Kommandozeile trotzdem der bevorzugte Eingabeweg – selbst beim Einstieg über ein GUI führt an dieser Form der Befehlseingabe kein Weg vorbei.
Wichtiger und nützlich sind daher Editoren, die spezielle Modi für die Arbeit mit R bieten, etwa Emacs mit dem Paket Emacs Speaks Statistics oder unter Windows Win Edt mit der entsprechenden Erweiterung R Win Edt (weitere Hinweise dazu gibt der Abschnitt “Productivity Tools” in [8]).
Nach dem Start von R erscheint eine Begrüßungsmeldung, die auch erläutert, wie der Benutzer Informationen über und Onlinehilfe zu R bekommt. Das dann folgende »>«-Zeichen ist der R-Prompt, der anzeigt, dass R auf die Befehlseingabe wartet. Hier lässt sich durch »help.start()« sofort die Browser-gestützte Onlinehilfe aufrufen.
Überdimensionaler Taschenrechner
Alles in R ist ein Objekt. Bei den Objektnamen unterscheidet das Programm übrigens Groß- und Kleinschreibung. Auch jeder Befehl ist ein Objekt und besteht aus einem Ausdruck oder einer Zuweisung. Er wird, da es sich bei R um einen Interpreter handelt, ausgeführt, sobald er eingegeben und syntaktisch korrekt und vollständig ist.
Einen Ausdruck wie »17 + 2« wertet R also aus, zeigt das Resultat am Bildschirm an und vergisst es. Die »[1]« vor der Ausgabe bedeutet, dass die Antwort von R mit dem ersten Element eines (hier nur einelementigen Vektors) beginnt:
> 17 + 2 [1] 19
Eine Zuweisung kennzeichnet der Operator »<-« (bestehend aus den beiden Zeichen »<« und »-«). Er wertet den rechts von ihm stehenden Ausdruck aus und weist das Resultat dem Objekt links zu. Das Ergebnis erscheint nicht automatisch. Erst die Eingabe des Objektnamens, der selbst ein Ausdruck ist, veranlasst die Auswertung und liefert als Antwort den Wert des Objekts:
> x <- 119 + 2 > x [1] 121
Dieses zweischrittige Vorgehen kann der Anwender abkürzen, indem er die Zuweisung in runde Klammern packt. Damit erzwingt er, das Objekt, das sich aus der Auswertung des Klammerausdrucks ergibt, automatisch auszugeben:
> (x <- 170 + 2) [1] 172
Mehrere Befehle lassen sich gemeinsam in einer Zeile eintippen, getrennt durch ein Semikolon. Befindet sich irgendwo in der Zeile das Doppelkreuz, ignoriert R jeglichen Text rechts davon bis zum Ende dieser Zeile als Kommentar:
> (Kehrwert <- 1/x); (wurzel <- sqrt( x))# Ignorierter Kommentar [1] 0.005813953 [1] 13.11488
Ist ein Befehl nach Eingabe von Return oder am Ende der Zeile syntaktisch noch nicht vollständig, liefert R als Befehlsfortsetzung-Prompt ein »+« und erwartet weitere Eingaben. Dies geschieht so lange, bis der Befehl syntaktisch korrekt abgeschlossen ist. Das folgende Beispiel verwendet Pi , das R als Konstante kennt, und »^«, den Potenzoperator:
> sqrt( pi * x^2 # Die schliessende Klammer fehlt! + ) # Das "+" kommt von R; die Klammer vom Benutzer. [1] 304.8621
Alle Objekte in R sind Vektoren, also geordnete, endliche Mengen, die sowohl einen Modus als auch eine nicht-negative endliche Anzahl an Elementen – ihre Länge – haben. Vektoren der Länge null heißen leer und Vektoren der Länge eins nennen sich Skalare. Auf die Vektorelemente greift der Benutzer durch einen in eckigen Klammern angehängten Index zu. So bezeichnet »x[5]« also das fünfte Element von »x«, falls es existiert; andernfalls ergibt der Zugriff den reservierten Ausdruck »NA« für “Not Available”.
Automatisch aufgefüllt
Die einfachste Vektorform ist die atomare. Sie zeichnet sich dadurch aus, dass alle ihre Vektorelemente vom selben Modus sind, etwa wie in einem Numeric-Vektor. Das ist ein Oberbegriff, der zwei Modi einschließt: Integer (ganze Zahlen) und Double (Fließkommazahlen wie »3.5« oder »8.472e-10«).
Die R-Arithmetik und viele ergänzende Funktionen für Vektoren operieren elementweise, was gelegentlich etwas gewöhnungsbedürftig, aber auf jeden Fall sehr leistungsstark ist.
Vektoren, die im selben Ausdruck auftreten, brauchen nicht die gleiche Länge zu haben. Kürzere Vektoren füllt R durch zyklische, möglicherweise unvollständige Wiederholung ihrer Elemente auf die Länge des längsten Vektors auf. Das erfolgt übrigens ohne Warnung, wenn die kleinere Vektorlänge ein Teiler der größeren ist! Das gilt auch für Skalare. Bei unterschiedlichen Längen der beteiligten Vektoren hat das Resultat daher immer die Länge des längsten Vektors.
Als Beispiel soll hier eine Schaltfunktion f : {0, 1}^4 -> {0, 1} und die Bestimmung ihrer Wertetafel dienen, wobei die Funktion selbst mit Hilfe der Booleschen Algebra ({0, 1},_,^,~) als der folgende logische Ausdruck definiert ist:
In R schreibt man die logischen Operatoren »v«, »^« und »~« als »&«, »|« beziehungsweise »!«. Außerdem identifiziert R automatisch den Wahrheitswert »true« mit »1« und »false« mit »0« und wandelt in arithmetischen oder logischen Ausdrücken von einem ins andere um, und zwar ohne Warnung.
Matrix füllt sich dank Vektor-Verdopplung
Für die Lösung der Beispielaufgabe mit der gezeigten Funktion befüllt der Anwender zunächst die Vektoren »x1« bis »x4« mit unterschiedlich langen Folgen aus Nullen und Einsen. Dabei fasst erst die Funktion »c()« (von to concatenate, also verketten) die Werte »0« und »1« zunächst in einem zweielementigen Numeric-Vektor »x1« zusammen und »rep(x1, each = 2)« vervielfältigt anschließend jedes der Elemente von »x1« zweimal, um »x2« zu erzeugen – was sich dann gewissermaßen rekursiv für »x3« und »x4« fortsetzt.
Beim zeilenweisen Zusammensetzen zu einer Matrix mit »rbind()« ergibt sich so durch automatische zyklische Replikation die 4-mal-16-Matrix aller möglichen Eingabetupel für f:
> x1 <- c(0, 1); x2 <- rep(x1, each = 2) > x3 <- rep(x2, each = 2); U x4 <- rep(x3, each = 2); x1; x2; x3; x4 [1] 0 1 [1] 0 0 1 1 [1] 0 0 0 0 1 1 1 1 [1] 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 > rbind( x1, x2, x3, x4) # Zeilenweises U Zusammensetzen zu einer Matrix [,1] [,2] [,3] .... [,14] [,15] [,16] x1 0 1 0 1 0 .... 1 0 1 0 1 x2 0 0 1 1 0 .... 1 0 0 1 1 x3 0 0 0 0 1 .... 0 1 1 1 1 x4 0 0 0 0 0 .... 1 1 1 1 1
Die eigentliche Auswertung von »f« bedarf gar nicht der Matrix von eben, sondern kann als Einzeiler in »x1« bis »x4« formuliert werden. Auch die Klammern um die Konjunktion sind nicht nötig, da die Operatorpräzedenzen eindeutig sind:
> (x1&(x2|x3)) | x4 4 [1] FALSE FALSE FALSE TRUE FALSE U TRUE FALSE TRUE TRUE TRUE TRUE TRUE [13] TRUE TRUE TRUE TRUE
|
R-Historie |
|---|
|
In den späten 1970er Jahren entwickelten die damaligen AT&T-Bell-Laboratorien die Statistiksprache S als Umgebung für statistische Datenanalyse, Simulation und Grafik. 1991 erschien eine Implementation von S, für die heute die Bezeichnung “S engine 3” (kurz S3) in Gebrauch ist. Unter dem Namen S-Plus entstand dann eine kommerzielle Version von S mit zahlreichen zusätzlichen Funktionen sowie einer grafischen Nutzeroberfläche. Urheber war zunächst die Firma Statsci, dann übernahm Mathsoft und heute kümmert sich die Insightful Corporation um S-Plus [2]. 1998 erschien eine völlig neu konzipierte “S engine 4” (kurz S4) , auf der die S-Plus-Versionen 5.x und höher basieren. Seit 2007 existiert S-Plus 8 mit mehreren Tausend Statistik- und anderen Funktionen R ist ebenfalls eine Implementation der Sprache S – gewissermaßen ein Dialekt – und entstand ab 1992 als kostenlose Open-Source-Software unter der GNU General Public License. R ähnelt S äußerlich sehr stark und steht semantisch der Sprache Lisp nahe. Im Jahr 2000 erschien die zu S3 voll kompatible R-Version 1.0.0 und im Jahr 2004 die R-Version 2.0.0, die die neuen S4-Methoden zur Verfügung stellt. Ende Juni 2008 kam Version 2.7.1 heraus. Faktisch gibt es derzeit also drei Implementationen von S: die alte S3, die neue S4 und R. Auf der offiziellen Homepage des R-Projekts [3] finden sich immer die aktuellen Informationen, viele Skripte und die Manuals, von denen insbesondere die beiden Titel “R Installation and Administration” und “An Introduction to R” nützlich sind. Außerdem sind dort die Ausgaben des Newsletter erhältlich und es gibt Informationen zu sehr hilfreichen, zum Teil sehr aktiven E-Mail-Listen sowie die FAQs. Zusätzlich bietet die Seite mehr als 60 Verweise auf Bücher unterschiedlichen Niveaus und unterschiedlicher Breite und Tiefe zu R selbst und zu statistischen Anwendungen mit R. Darunter auch [5], [6] und [7], die nicht nur für den Einstieg in R hervorragend geeignet sind. |
Grafiken zeichnen
R taugt auch als grafischer Taschenrechner. Vor allem stetige Funktionen lassen sich sehr einfach mit »curve()« zeichnen und mit Hilfe von »polygon()« sind geschlossene Polygonzüge im Nu skizziert. Das erste Argument von »curve()« ist der Name einer eingebauten oder selbst definierten Funktion oder eines Ausdrucks. Die Argumente »from« und »to« spezifizieren den Bereich, in dem R die Funktion an 101 äquidistanten Stützstellen (Voreinstellung) auswertet und zeichnet. Ist »add = TRUE«, zeichnet R ein bestehendes Koordinatensystem, wobei dessen x-Achsen-Ausschnitt verwendet wird. Die Argumente »col« und »lty« bestimmen die Linienfarbe beziehungsweise den Linientyp:
> curve( sin(x)/x, from = -20, to = 20, n = 200) > curve( abs(1/x), add = TRUE, col = "red",lty = "dashed")
Die Funktion »polygon()« des folgenden Beispiels kann ein Polygon nur in ein bereits bestehendes Koordinatensystem einzeichnen, weshalb durch »plot()« mit »type = “n”« (für no) zuerst ein leeres erzeugt wird. Die ersten beiden Argumente von »polygon()« erwarten die Koordinaten der Polygonecken, die durch Kanten zu verbinden sind, wobei die letzte Ecke automatisch eine Verbindung mit der ersten erhält. Die Innen- und Randfarben werden durch »col« beziehungsweise »border« festgelegt:
> x <- c(1:7, 6:1); y <- c(1, 10, 8, 5, 1, -1, 3:9) # Das leere Koordinatensystem > plot(x, y, type = "n") # Der Polygonzug > polygon(x, y, col = "orange", border = "red")> # Nummerierung der Ecken text(x, y)
Die fertige Zeichnung ist in der Abbildung 1 zu sehen.
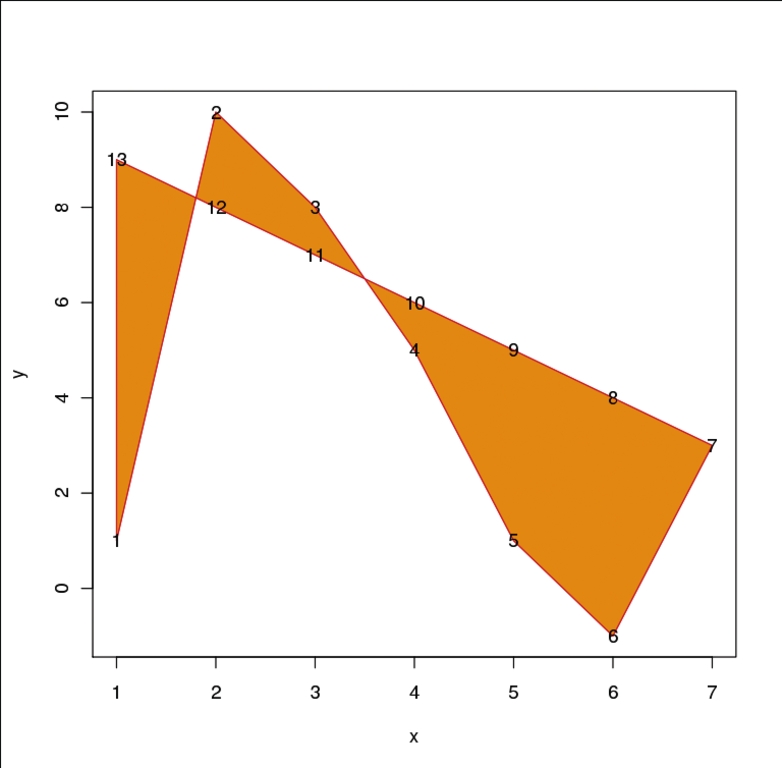
Abbildung 1: R als grafischer Taschenrechner: Mit wenigen Kommandos lassen sich komplexe Graphen visualisieren. Dazu verfügt R über zahlreiche Funktionen wie zum Beispiel »curve()« oder »polygon()«.
|
Alternative SPSS |
|---|
|
Wer ein Komplettpaket für schnelle statistische Analysen sucht und Anwendungen am liebsten mit der Maus dirigiert, für den ist nicht R, sondern vielleicht die kommerzielle Statistiksoftware SPSS die richtige Wahl. Die aktuelle Version 17 läuft auch unter Linux. SPSS bietet alle gängigen Grund-Tests und -Analysen, zum Beispiel T-Test, Anova, lineare Regression, Korrelations- und Faktoranalysen, K-Mittel, Multivariate und andere. Das über 500 Seiten starke SPSS-Handbuch versucht die Intention jedes statistischen Verfahrens auch dem vielleicht weniger Vorgebildeteten verständlich zu beschreiben. Erfahrene Benutzer wählen aus einer großen Palette an Zusatzmodulen, die sich automatisch ins GUI integrieren. Sie decken Spezialgebiete der Statistik ab, darunter SPSS Conjoint, das häufig bei der Analyse von Kundenvorlieben verwendet wird, oder SPSS Categories für kategoriale Daten, das die Produktforschung für Einstellungsmessung benutzt, oder SPSS Classification Trees zur Gruppenidentifikation. SPSS Missing Value Analysis eignet sich für die Arbeit mit unvollständigen Datensätzen, auch ein Textmining-Modul ist im Angebot. Datamining realisiert SPSS mit Hilfe der Produkte der Clementine-Familie. Die Tabelle 1 stellt einige vergleichbare Module von SPSS und R einander gegenüber. SPSS Base kostet derzeit etwa 1000 Euro, die Zusatzmodule schlagen mit jeweils 120 bis 2700 Euro zu Buche. Die tatsächlich relativ geringen Systemvoraussetzungen sind:
Der Hersteller macht deutlich darauf aufmerksam, dass sein Support nur die Linux-Distributionen Red Hat Enterprise Linux 4 und Debian 3.1 unterstützt. (Volker Schmitt) |
Einfache statistische Analysen
Eine häufige Aufgabe in der Statistik ist der Test einer Hypothese auf Gleichheit zweier Populationsmittelwerte. Nimmt man an, dass die Daten zweier unabhängiger Stichproben jeweils aus einer normalverteilten Population stammen, wobei die Varianzen in den beiden Populationen unbekannt sind, leistet dies die Welch-Modifikation des T-Tests, die in der Funktion »t.test()« implementiert ist. Die (erfundenen) Daten zweier solcher Stichproben »A« und »B«
> A <- c(146, 102, 124, 129, 84, 149, 126, 127, 100, 115, 117, 104) > B <- c(103, 75, 86, 112, 107, 109, 91)
sind bereits erfasst, nun soll zunächst eine grafische, explorative Datenanalyse (EDA) folgen.
Zwei parallele Boxplots (erzeugt durch »boxplot(…)«) überlagern mit einer geringen seitlichen Rechtsverschiebung die Strip Charts der Rohdaten, gezeichnet von »stripchart(…)«. Nach links verschoben erscheinen die arithmetischen Mittel und die zugehörigen Standardabweichungen als Fehlerbalken »errbar(…)«. Diese Darstellung erlaubt Statistikkundigen eine erste qualitative Einschätzung des Unterschieds zwischen den beiden Datensätzen.
Folgende Befehlssequenz erzeugt eine Darstellung wie in Abbildung 2:
> boxplot(list(A, B), names=c("Gruppe A", "Gruppe B"), col = "yellow")
> stripchart(list(A, B), add = TRUE, at = c(1.3, 2.3), vertical = TRUE)
> Means <- c(mean(A), mean(B)) # Vektor der zwei arithmetischen Mittel.
> SDevs <- c(sd(A), sd(B)) # Vektor der zwei Standardabweichungen.
> library(Hmisc) # Package "Hmisc" in Suchpfad einfuegen.
> errbar(x = c(0.7, 1.7), y = Means, + yplus = Means + SDevs, yminus=Means-SDevs,U
+ add = TRUE, col = "red") # Mittelwerte +/- Standardabweichungen einzeichnen.
> detach() # Zuletzt eingefuegtes Paket wieder aus Suchpfad entfernen
Auf diesen Schritt folgt anschließend der Hypothesentest:
> t.test(A, B) Welch Two Sample t-test data: A and B t = 2.7729, df = 15.971, p-value = 0.01360 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: 4.945728 37.078081 sample estimates: mean of x mean of y 118.58333 97.57143
Die von »t.test()« ausgegebenen Resultate sind der Wert der T-Teststatistik (»t«), ihre nicht abgerundeten Freiheitsgrade (»df«) und der p-Wert (»p-value«), außerdem die zweiseitige Testalternative, das 95-Prozent-Konfidenzintervall für die Differenz der zwei Populationsmittelwerte und deren Schätzwerte (Sample estimates). Die Alternative und das Konfidenzniveau wären mit den nicht gezeigten Funktionsargumenten »alternative« und »conf.level« auch anders spezifizierbar und mittels »var.equal = TRUE« wäre der T-Test von Student zu erzwingen.
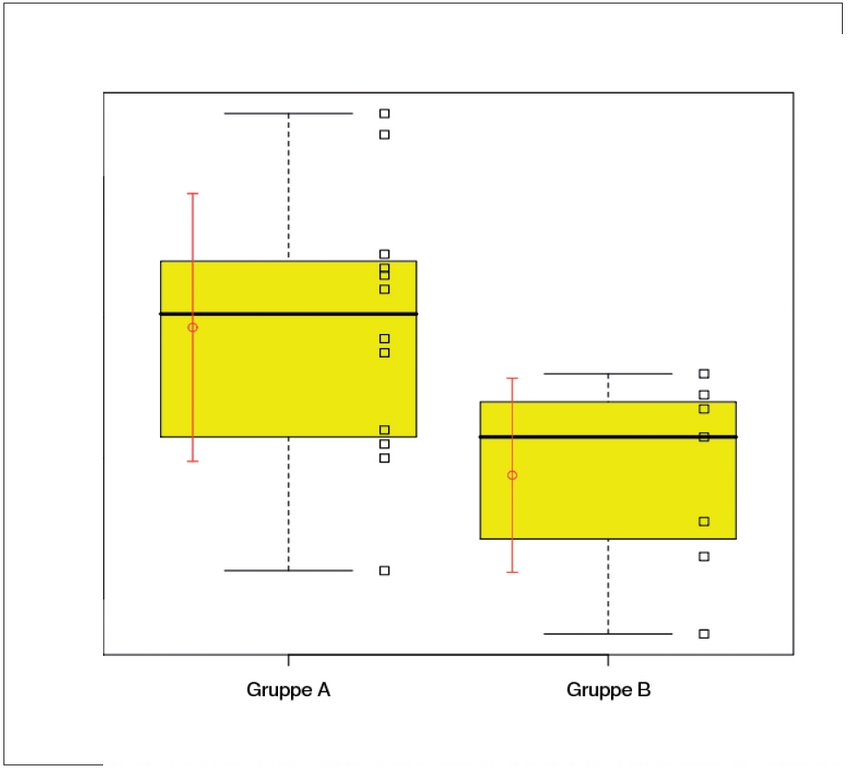
Abbildung 2: Boxplots mit überlagerten Strip Charts und Fehlerbalken erlauben dem Statistikexperten eine schnelle visuelle Beurteilung der Unterschiede zwischen den beiden Gruppen.
|
Tabelle 1: SPSS- und |
|
|---|---|
|
SPSS Base |
R |
|
SPSS Textminer |
Rstem |
|
SPSS Classification Trees |
Rpart |
|
SPSS Connector |
RODBC |
|
Clementine |
Factominer |
Datenimport
Datenbanken oder Spreadsheets eignen sich viel besser zum Speichern großer Datensätze als R. Wer solche Daten mit R analysieren will, muss sie also meist zuvor importieren. Dafür kennt die Software verschiedene leistungsfähige Funktionen. Der Datenimport aus Ascii-Textdateien ist besonders einfach – die Anweisung »read.table()« reicht aus. Für andere Formate ist das Manual “R Data Import/Export” eine Anlaufstelle.
Im folgenden Beispiel geht es um eine Textdatei »Tera.txt«, die in tabellarischer Form die Rechenleistung der welt-schnellsten Computer der letzten anderthalb Jahrzehnte listet:
Datum System Teraflop 01.11.93 Numerical Wind Tunnel 0.12 01.06.94 XP/S 140 0.14 .... 01.06.08 Roadrunner 1026.00
Liest man dieses File mit »read.table()« ein, entsteht ein so genannter Data Frame, das ist eine Art Tabelle, deren Spalten Variablen und deren Zeilen Fälle repräsentieren (Listing 1).
Die Datei hat eine Kopfzeile, deren Einträge sich in Spalten-, sprich Variablennamen des Data Frame verwandeln sollen, wozu das Argument »header = TRUE« nötig ist. Die Option »sep = “t”« teilt R mit, dass das Spaltentrennzeichen der Tabulator ist.
Die nächste Zeile (Zeile 2 in Listing 1)der kurzen Befehlsfolge konvertiert die Datum-Variable, automatisch zunächst als Character-Datentyp eingelesen, in den Typ »Date« im Format »%d.%m.%y«. Dabei ist insbesondere für den nächsten Abschnitt wissenswert, dass Date-Objekte R-intern die Anzahl der Tage seit dem 1.1.1970 repräsentieren. Der Data Frame enthält nun die Variablen »Datum«, »System« und “Teraflop«, für die jeweils 30 Beobachtungen vorliegen.
Eine große Stärke von S und damit R ist die Beschreibung statistischer Modelle in einer besonderen Formelsyntax. Sie spezifiziert die Beziehung zwischen Modellvariablen auf sehr kompakte Weise und für eine Vielzahl statistischer Verfahren in einheitlicher Form – also nicht nur für einfache lineare Regressionsmodelle.
|
Listing 1: Daten |
|---|
01 > tera<-read.table("tera.txt", header=TRUE, sep="t")
02 > tera$Datum <- as.Date(tera$Datum, format = "%d.%m.%y")
03 > str(tera) # liefert zur Kontrolle Strukturinformationen zu tera
04 'data.frame': 30 obs. of 3 variables:
05 $ Datum :Class 'Date' num [1:30] 8705 8917 9070 9282 9435 ...
06 $ System : Factor w/ 11 levels "ASCI Red","ASCI Red",..: 8 11 8 8 8 10 6 2 1 1
07 ...
08 $ Teraflop: num 0.12 0.14 0.17 0.17 0.17 0.22 0.37 1.07 1.34 1.34 ...
|
Ein statistisches Modell
Das folgenden Beispiel soll damit anhand der Benchmark-Werte schätzen, wann es den ersten Exaflop-Rechner geben könnte, wenn die Entwicklung sich weiter mit der gleichen Dynamik vollzieht wie bisher. Mathematisch gilt es also, die Abhängigkeit des dekadisch logarithmierten Teraflop-Werts von der Zeit durch eine einfache lineare Regression entsprechend dem statistischen Modell »log10(Teraflopi) = ß0 + ß1 Datumi + Ei« zu bestimmen. Der Autor ignoriert in dem Beispiel bewusst, dass die Zeitreihe der Teraflop-Daten korrekterweise eigentlich mit zeitreihenanalytischen Methoden zu behandeln wäre.
Die R-Formel »log10(Teraflop) ~ Datum« beschreibt dieses Modell. Sie fasst die links der Tilde stehende Variable also als Response auf, die von dem rechts der Tilde stehenden Regressor abhängt. Ein multiples Regressionsmodell würde die zu verwendenden Regressoren durch »+« verknüpfen. Es gibt weitere Operatoren für komplexere Verknüpfungen von Regressoren.
Die eigentliche Anpassung des linearen Modells bewerkstelligt die Funktion »lm()«, deren erstes Argument eine Modellformel erwartet. Sie liefert ein »lm«-Objekt zurück, wofür »summary()« viele statistischen Details liefert, die Statistikkundigen dabei helfen, die Anpassungsgüte des Modells und das Modell selbst zu beurteilen (Listing 2).
|
Listing 2: Statistisches |
|---|
01 > TeraModell <- lm( log10( Teraflop) ~ Datum, data = tera) 02 > summary(TeraModell) 03 04 Call: 05 lm(formula = log10(Teraflop) ~ Datum, data = tera) 06 07 Residuals: 08 Min 1Q Median 3Q Max 09 -0.29237 -0.10512 -0.04797 0.11833 0.33052 10 11 Coefficients: 12 Estimate Std. Error t value Pr(>|t|) 13 (Intercept) -7.779e+00 2.202e-01 -35.32 <2e-16 *** 14 Datum 7.605e-04 1.919e-05 39.63 <2e-16 *** 15 --- 16 Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 17 18 Residual standard error: 0.1662 on 28 degrees of freedom 19 Multiple R-squared: 0.9825, Adjusted R-squared: 0.9819 20 F-statistic: 1570 on 1 and 28 DF, p-value: < 2.2e-16 |
Zur qualitativen Analyse der Güte der Modellanpassung und der Zulässigkeit gewisser zugrunde liegender statistischer Verteilungsannahmen liefert der simple Befehl »plot(TeraModell)« (Listing 3) vier von sechs wählbaren diagnostischen Grafiken für das angepasste Modell. Unter der Annahme, dass es ein zulässiges und auch in Zukunft gültiges Modell ist, sei es gewagt, punktweise gültige 95-Prozent-Prognoseintervalle für künftige Teraflop-Werte einzuzeichnen (Abbildung 3).
|
Listing 3: Trend |
|---|
01 > X <- seq(min(tera$Datum), as.Date("2015-01-01"), by = "months")
02 > Y <- predict(TeraModell, newdata = data.frame(Datum = X),
03 + interval = "prediction")
04 > plot(Teraflop ~ Datum, data = tera, xlab = "Jahr", las = 2,
05 + ylim = c(0, 1e4), xlim = c(min(tera$Datum), as.Date("2014-01-01")))
06 > abline(h = 10000, col = "blue")
07 > matlines(X, 10^Y, lty = "solid", lwd = 2, col = c("black", "green", "green"))
08 > egend("left", bty = "n", lwd = 2, col = c("black", "green"),
09 + legend = c("Regressionsfunktion", "95 % Prognoseintervall"))
10 Fehler: konnte Funktion "egend" nicht finden
|
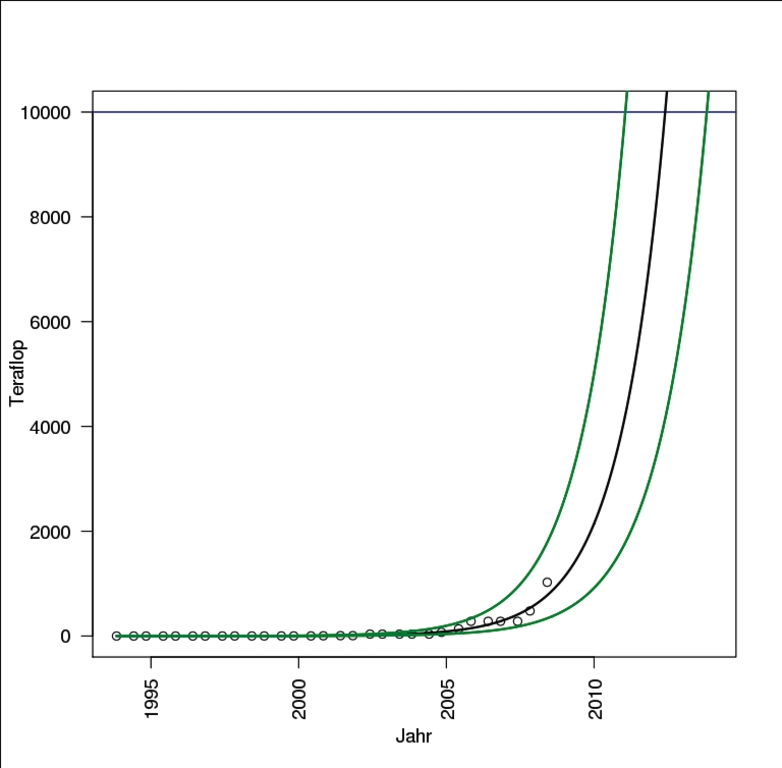
Abbildung 3: Wann kommen die Exaflop-Superrechner? Dem Trend zufolge nicht lange nach 2010. Allerdings ist eine derart einfache Interpolation immer mit mehr Vor- als Zuversicht zu interpretieren.
Stochastische Simulationen
R hat für viele Wahrscheinlichkeitsverteilungen sowohl die jeweilige Dichtefunktion im Fall einer stetigen Verteilung beziehungsweise Wahrscheinlichkeitsfunktion im diskreten Fall als auch die Verteilungs- und Quantilfunktion implementiert; fallweise natürlich nur approximativ. Ebenso sind Generatoren für Pseudo-Zufallszahlen vorhanden, mit denen Stichproben aus diesen Verteilungen simuliert werden können.
Diese Generatoren wiederum basieren auf uniformen Pseudo-Zufallszahlen, die in R mit verschiedenen zur Verfügung stehenden Zufallszahlengeneratoren erzeugt werden können. Voreingestellt ist ein Generator namens Mersenne Twister mit sehr guten Eigenschaften, der eine sehr lange, aber letztendlich eben doch periodische Zahlensequenz der Länge 219937-1 in einem offenen Intervall (0, 1) erzeugt [9]. Weitere Details und zahlreiche Literaturverweise zu diesem Thema liefert die Onlinehilfe von R.
Eine sehr interessante Möglichkeit ist das automatische Verfassen von Berichten über statistische Auswertungen mit Hilfe von R-Funktionen.
Berichte mit Sweave
Dabei mischt R Latex-Code für den Text des Berichts und R-Code für die statistischen Analysen in einem Dokument. Die Auswertung übernimmt die R-Funktion »sweave()«, die die R-Resultate – seien es Textausgaben oder auch Grafiken – und den restlichen Latex-Code am Ende in einem reinen Latex-Dokument zusammensetzt, das schließlich in ein Grafik-Ausgabeformat übersetzbar ist.
Validität im Vergleich
Die Zuverlässigkeit statistischer Berechnungen muss von zentraler Bedeutung für die Akzeptanz der Ergebnisse sein, und zwar für proprietäre und Open-Source-Software gleichermaßen. Die Studie [10] berichtet über einen etwa im Jahr 2005 durchgeführten Vergleich von neun Paketen statistischer Software hinsichtlich ihrer Akkuratesse bei der Verarbeitung mehrerer besonders anspruchsvoller “Standard Reference Data Sets” des US-amerikanischen National Institute of Standards and Technology. Das freie R erwies sich in seiner damaligen Version 1.9.1 in diesem Vergleich mit etablierten, kommerziellen und häufig ziemlich teuren Produkten als in jeder Beziehung wettbewerbsfähig. (jcb)
|
Infos |
|---|
|
[1] R Graphics Gallery: [http://addictedtor.free.fr/graphiques] [2] S-Plus: [http://www.insightful.com/products/splus/default.asp] [3] Homepage des R-Projekts: [http://www.r-project.org] [4] R-CRAN: [http://cran.r-project.org] [5] Braun, W. J., Murdoch, D. J., “A First Course in Statistical Programming with R”: Cambridge University Press, 2007 [6] Daalgard, P., ” Introductory Statistics with R”: Corr. 3rd printing, Springer-Verlag, 2004 [7] Ligges, U., ” Programmieren mit R 2″, überarbeitete und aktualisierte Auflage: Springer-Verlag, 2006 [8] Wikipedia zu R: [http://en.wikipedia.org/wiki/R_(programming_language] [9] Matsumoto, M., Nishimura, T., “Mersenne Twister, A 623-dimensionally equidistributed uniform pseudo-random number generator”: ACM Transactions on Modeling and Computer Simulation, 8, 1998 [10] Keeling, K. B., Pavur, R. J., ” A comparative study of the reliability of nine statistical software packages”: Computational Statistics & Data Analysis, 51, 2007 |
|
Der Autor |
|---|
|
Dr. Gerrit Eichner arbeitet am Mathematischen Institut der Justus-Liebig-Universität Gießen. |





